
Intermodal Green p-Hub Median Problem with Incomplete Hub-Network


Abstract
1. Introduction
2. Literature Review
3. Problem Description and Formulation
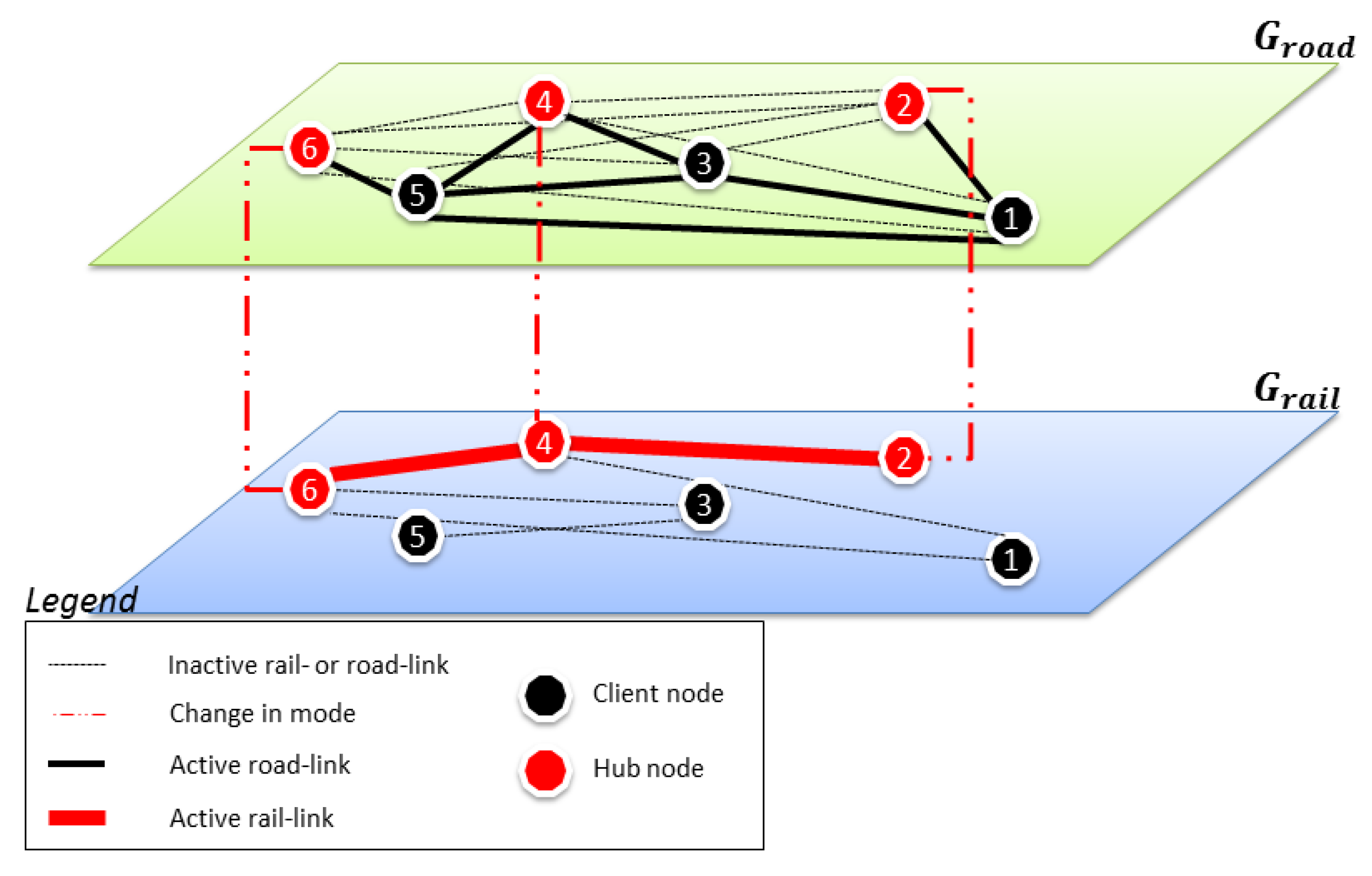
3.1. Problem Description
- Direct-links between spoke nodes are allowed.
- Demand flows are transferred on-rail between located hub nodes.
- All transportation on spoke-hub, hub-spoke and spoke-spoke direct links is performed on-road.
- In a solution, each spoke node i is allocated to only one hub node k. Nonetheless, direct on-road transportation between i and a hub node is allowed.
- Hub-networks are incomplete and at most one hub node can be visited on the route between hub nodes and .
- For any origin-destination pair, demand flows are sent either directly from i to j, directly on hub-link between hub nodes k and m, or through one intermediate hub-link with at most one hub .
3.2. Mathematical Formulation
- Hub location-allocation:
- Demand Flows Routing:
- Emission costs estimation:
- Objective cost:
4. Genetic Algorithm
| Algorithm 1: Genetic Algorithm. |
 |
4.1. Solution Encoding and Fitness Function
4.2. GA Initial Population
| Algorithm 2: best Path Search Heuristic |
 |
| Algorithm 3: Priority Allocation Heuristic |
 |
4.3. Demand Flows Routing Heuristic
4.4. Crossover and Mutation Operators
5. Computational Experiments
5.1. Effect of the Heuristic Methods
5.2. Comparison Study CPLEX and GA
5.3. Unimodal and Intermodal Transport for Complete and Incomplete Hub-Networks
5.4. Robustness of the GA
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MILP | Mixed interger linear program |
| HLP | Hub location problem |
| p-HMP | p-hub median problem |
| I-Gp-IHMP | Intermodal green p-hub median problem with incomplete hub-network |
| GA | Genetic algorithm |
| BP-CH | Best path construction heuristic |
Appendix A. The Mesoscopic Road-Rail Emission Estimation Model
- Truck expressions:
- Train expressions:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description | Typical Values |
|---|---|---|
| Truck Power Transmission Efficiency | 0.88 | |
| Optimal Truck Fuel Consumption rate (L/kwh) | 0.229 | |
| Idle Truck Fuel Consumption rate (L/h) | 3 | |
| Truck Maximal Engine Power (Kwh) | 300 | |
| g | Gravitational Constant (m/s) | 9.81 |
| Truck Average Speed (km/h) | 40 | |
| Air Density (kg/m) | 1.2 | |
| A | Truck Frontal Surface Area (m) | 3.912 |
| Average number of Acceleration | 0.2 | |
| Energy coefficient (L/kwh) | 0.0811 | |
| Efficiency rate of Diesel Locomotives | 0.38 | |
| Efficiency rate of Electric Locomotives | 0.65 | |
| Coefficient of Truck Rolling Resistance | 0.006 | |
| Coefficient of Truck Aerodynamic Drag | 0.6 | |
| Coefficient of Train Locomotive Rolling Resistance | 0.003 | |
| Train Locomotive Dead-weight (T) | 83 | |
| Coefficient of Train Rail-Car Rolling Resistance | 0.0006 | |
| Train Rail-Car Dead-weight (T) | 20 | |
| Coefficient of Train Auxiliary-1 Rolling Resistance | 0.0005 | |
| Coefficient of Train Auxiliary-2 Rolling Resistance | 0.0006 | |
| Train Average Speed (Km/h) | 73 | |
| Coefficient of Train Locomotive Aerodynamic Drag | 0.8 | |
| Coefficient of Train Rail-Car Aerodynamic Drag | 0.218 | |
| Number of Rail-Cars | - | |
| Number of Axles | - |
Appendix B
| CPLEX | GA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| |N| | p | q | UB (£) | LB (£) | %Gap | CPU Time (s) | Obj (£) | CPU Time (s) | %GapUB | %GapLB |
| 10 | 3 | 2 | 173.682 | 173.682 | 0.00 | 13.598 | 173.682 | 2.358 | 0.00 | 0.00 |
| 3 | 168.682 | 168.682 | 0.00 | 11.137 | 168.682 | 2.862 | 0.00 | 0.00 | ||
| 4 | 3 | 239.410 | 239.410 | 0.00 | 13.163 | 239.410 | 2.786 | 0.00 | 0.00 | |
| 4 | 220.802 | 220.802 | 0.00 | 7.2886 | 220.802 | 2.974 | 0.00 | 0.00 | ||
| 5 | 219.729 | 219.729 | 0.00 | 5.9424 | 219.729 | 2.658 | 0.00 | 0.00 | ||
| 6 | 219.643 | 219.643 | 0.00 | 8.0002 | 219.643 | 2.996 | 0.00 | 0.00 | ||
| 5 | 4 | 369.285 | 369.285 | 0.00 | 9.2036 | 369.285 | 3.138 | 0.00 | 0.00 | |
| 5 | 343.866 | 343.866 | 0.00 | 7.4815 | 343.866 | 3.183 | 0.00 | 0.00 | ||
| 6 | 335.377 | 335.377 | 0.00 | 11.863 | 335.377 | 3.080 | 0.00 | 0.00 | ||
| 7 | 328.251 | 328.251 | 0.00 | 12.003 | 328.251 | 3.892 | 0.00 | 0.00 | ||
| 8 | 328.140 | 328.140 | 0.00 | 8.3320 | 328.140 | 3.982 | 0.00 | 0.00 | ||
| 9 | 328.056 | 328.056 | 0.00 | 9.5765 | 328.056 | 3.561 | 0.00 | 0.00 | ||
| 10 | 327.998 | 327.998 | 0.00 | 20.528 | 327.998 | 3.759 | 0.00 | 0.00 | ||
| 20 | 3 | 2 | * | * | * | * | 643.846 | 7.010 | * | * |
| 3 | * | * | * | * | 639.674 | 3.935 | * | * | ||
| 4 | 3 | * | * | * | * | 692.661 | 5.678 | * | * | |
| 4 | * | * | * | * | 680.281 | 5.743 | * | * | ||
| 5 | * | * | * | * | 678.756 | 7.086 | * | * | ||
| 6 | * | * | * | * | 678.303 | 7.014 | * | * | ||
| 5 | 4 | * | * | * | * | 763.794 | 9.970 | * | * | |
| 5 | * | * | * | * | 748.801 | 5.647 | * | * | ||
| 6 | * | * | * | * | 743.197 | 5.871 | * | * | ||
| 7 | * | * | * | * | 737.154 | 5.942 | * | * | ||
| 8 | * | * | * | * | 731.214 | 6.304 | * | * | ||
| 9 | * | * | * | * | 728.840 | 7.934 | * | * | ||
| 10 | * | * | * | * | 728.494 | 6.369 | * | * | ||
| CPLEX | GA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| |N| | p | q | UB (£) | LB (£) | %Gap | CPU Time (s) | Obj (£) | CPU Time (s) | %GapUB | %GapLB |
| 10 | 3 | 2 | 153.164 | 153.164 | 0.00 | 10.048 | 153.164 | 1.181 | 0.00 | 0.00 |
| 3 | 148.637 | 148.637 | 0.00 | 6.813 | 148.637 | 2.078 | 0.00 | 0.00 | ||
| 4 | 3 | 180.863 | 180.863 | 0.00 | 12.069 | 180.863 | 1.113 | 0.00 | 0.00 | |
| 4 | 176.654 | 176.654 | 0.00 | 14.628 | 176.654 | 8.518 | 0.00 | 0.00 | ||
| 5 | 174.212 | 174.212 | 0.00 | 13.147 | 174.212 | 11.03 | 0.00 | 0.00 | ||
| 6 | 174.174 | 174.174 | 0.00 | 9.645 | 174.174 | 4.360 | 0.00 | 0.00 | ||
| 5 | 4 | 250.244 | 250.244 | 0.00 | 10.972 | 250.244 | 5.229 | 0.00 | 0.00 | |
| 5 | 236.731 | 236.731 | 0.00 | 10.920 | 236.731 | 4.380 | 0.00 | 0.00 | ||
| 6 | 232.030 | 232.030 | 0.00 | 10.624 | 232.030 | 5.046 | 0.00 | 0.00 | ||
| 7 | 228.121 | 228.121 | 0.00 | 9.788 | 228.121 | 5.116 | 0.00 | 0.00 | ||
| 8 | 228.060 | 228.060 | 0.00 | 6.341 | 228.060 | 8.445 | 0.00 | 0.00 | ||
| 9 | 228.012 | 228.012 | 0.00 | 7.890 | 228.012 | 8.836 | 0.00 | 0.00 | ||
| 10 | 227.980 | 227.980 | 0.00 | 8.763 | 227.980 | 8.117 | 0.00 | 0.00 | ||
| 20 | 3 | 2 | * | * | * | * | 626.623 | 6.904 | * | * |
| 3 | * | * | * | * | 615.858 | 7.009 | * | * | ||
| 4 | 3 | * | * | * | * | 646.881 | 5.293 | * | * | |
| 4 | * | * | * | * | 640.478 | 13.390 | * | * | ||
| 5 | * | * | * | * | 636.171 | 7.066 | * | * | ||
| 6 | * | * | * | * | 636.102 | 5.877 | * | * | ||
| 5 | 4 | * | * | * | * | 692.067 | 9.235 | * | * | |
| 5 | * | * | * | * | 675.519 | 6.090 | * | * | ||
| 6 | * | * | * | * | 674.726 | 6.751 | * | * | ||
| 7 | * | * | * | * | 673.375 | 5.911 | * | * | ||
| 8 | * | * | * | * | 667.473 | 6.143 | * | * | ||
| 9 | * | * | * | * | 663.377 | 7.925 | * | * | ||
| 10 | * | * | * | * | 659.317 | 13.500 | * | * | ||
| CPLEX | GA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| |N| | p | q | UB (£) | LB (£) | %Gap | CPU Time (s) | Obj (£) | CPU Time (s) | %GapUB | %GapLB |
| 10 | 3 | 2 | 137.107 | 137.107 | 0.00 | 14.276 | 137.107 | 8.208 | 0.00 | 0.00 |
| 3 | 136.214 | 136.214 | 0.00 | 6.780 | 136.214 | 3.566 | 0.00 | 0.00 | ||
| 4 | 3 | 151.590 | 151.590 | 0.00 | 11.179 | 151.590 | 11.620 | 0.00 | 0.00 | |
| 4 | 148.989 | 148.989 | 0.00 | 11.794 | 148.989 | 1.062 | 0.00 | 0.00 | ||
| 5 | 147.552 | 147.552 | 0.00 | 11.945 | 147.552 | 3.590 | 0.00 | 0.00 | ||
| 6 | 147.527 | 147.527 | 0.00 | 9.183 | 147.527 | 3.411 | 0.00 | 0.00 | ||
| 5 | 4 | 190.724 | 190.724 | 0.00 | 15.554 | 190.724 | 4.366 | 0.00 | 0.00 | |
| 5 | 183.163 | 183.163 | 0.00 | 14.351 | 183.163 | 4.585 | 0.00 | 0.00 | ||
| 6 | 180.357 | 180.357 | 0.00 | 11.116 | 180.357 | 7.250 | 0.00 | 0.00 | ||
| 7 | 178.056 | 178.056 | 0.00 | 19.022 | 178.056 | 10.110 | 0.00 | 0.00 | ||
| 8 | 178.020 | 178.020 | 0.00 | 13.365 | 178.020 | 4.573 | 0.00 | 0.00 | ||
| 9 | 177.990 | 177.990 | 0.00 | 12.618 | 177.990 | 4.750 | 0.00 | 0.00 | ||
| 10 | 177.971 | 177.971 | 0.00 | 11.078 | 177.971 | 4.514 | 0.00 | 0.00 | ||
| 20 | 3 | 2 | * | * | * | * | 627.086 | 10.210 | * | * |
| 3 | * | * | * | * | 619.507 | 4.495 | * | * | ||
| 4 | 3 | * | * | * | * | 630.553 | 8.622 | * | * | |
| 4 | * | * | * | * | 629.833 | 10.140 | * | * | ||
| 5 | * | * | * | * | 626.689 | 16.710 | * | * | ||
| 6 | * | * | * | * | 623.416 | 5.137 | * | * | ||
| 5 | 4 | * | * | * | * | 637.955 | 12.360 | * | * | |
| 5 | * | * | * | * | 633.632 | 8.431 | * | * | ||
| 6 | * | * | * | * | 631.553 | 8.209 | * | * | ||
| 7 | * | * | * | * | 629.473 | 8.889 | * | * | ||
| 8 | * | * | * | * | 626.973 | 8.867 | * | * | ||
| 9 | * | * | * | * | 626.072 | 10.380 | * | * | ||
| 10 | * | * | * | * | 625.386 | 7.077 | * | * | ||
| Road | Road-Rail | Road | Road-Rail | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p | |N| | Obj (£) | Hubs | Obj (£) | Hubs | %GapRail | p | |N| | Obj (£) | Hubs | Obj (£) | Hubs | %GapRail |
| 3 | 10 | 128.05 | 1, 9, 2 | 173.68 | 3 , 8 , 5 | 35.63 | 6 | 10 | Infeasible | ||||
| 20 | 609.27 | 8 , 3 , 17 | 643.84 | 1 , 2 , 3 | 5.67 | 20 | 634.63 | 2 , 16 , 4 , 13 , 8 , 10 | 877.79 | 10 , 16 , 4 , 13 , 15 , 8 | 38.31 | ||
| 30 | 1302.43 | 22 , 16 , 8 | 1324.06 | 29 , 16 , 8 | 1.66 | 30 | 1326.67 | 8 , 16 , 3 , 10 , 0 , 1 | 1488.88 | 12 , 2 , 14 , 28 , 22 , 10 | 12.23 | ||
| 40 | 2449.25 | 14 , 33 , 27 | 2377.43 | 33 , 1 , 3 | −2.93 | 40 | 2506.11 | 6 , 1 , 4 , 8 , 10 , 3 | 2673.55 | 13 , 15 , 36 , 8 , 11 , 2 | 6.68 | ||
| 50 | 3570.29 | 19 , 34 , 5 | 3434.24 | 4 , 39 , 25 | −3.81 | 50 | 3638.55 | 1 , 17 , 9 , 4 , 13 , 12 | 3603.97 | 49 , 10 , 13 , 32 , 18 , 9 | −0.95 | ||
| 4 | 10 | 127.82 | 5, 9, 2, 6 | 242.07 | 4 , 8 , 3 , 5 | 89.38 | 7 | 10 | Infeasible | ||||
| 20 | 621.17 | 19 , 18 , 14 , 16 | 693.20 | 8 , 16 , 13 , 15 | 11.59 | 20 | 645.11 | 1 , 16 , 4 , 10 , 13 , 8 , 15 | 1079.41 | 1 , 16 , 4 , 10 , 13 , 8 , 15 | 67.32 | ||
| 30 | 1314.83 | 8 , 16 , 1 , 24 | 1365.23 | 28 , 2 , 12 , 22 | 3.83 | 30 | 1313.23 | 17 , 2 , 8 , 12 , 14 , 15 , 18 | 1651.73 | 10 , 2 , 28 , 12 , 6 , 26 , 22 | 25.78 | ||
| 40 | 2471.21 | 6 , 35 , 39 , 38 | 2392.69 | 26 , 1 , 33 , 3 | −3.18 | 40 | 2483.59 | 6 , 1 , 2 , 4 , 10 , 24 , 17 | 2683.94 | 3 , 1 , 33 , 4 , 8 , 10 , 17 | 8.07 | ||
| 50 | 3600.86 | 2 , 17 , 6 , 21 | 3486.94 | 22 , 17 , 13 , 31 | −3.16 | 50 | 3646.38 | 11 , 10 , 9 , 19 , 17 , 4 , 18 | 3826.88 | 11 , 9 , 42 , 12 , 17 , 4 , 18 | 4.95 | ||
| 5 | 10 | 130.12 | 1, 9, 5, 6, 2 | 369.28 | 4 , 8 , 3 , 5 , 9 | 183.79 | |||||||
| 20 | 621.44 | 2 , 16 , 13 , 15 , 10 | 765.11 | 4 , 15 , 8 , 13 , 16 | 23.12 | ||||||||
| 30 | 1314.09 | 8 , 16 , 0 , 1 , 22 | 1436.61 | 16 , 8 , 0 , 1 , 27 | 9.32 | ||||||||
| 40 | 2509.27 | 35 , 1 , 21 , 10 , 3 | 2458.93 | 33 , 1 , 4 , 8 , 3 | −2.01 | ||||||||
| 50 | 3693.26 | 32 , 9 , 17 , 11 , 15 | 3459.26 | 3 , 10 , 9 , 32 , 18 | −6.33 | ||||||||
| Road | Road-Rail | Road | Road-Rail | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p | |N| | Obj (£) | Hubs | Obj (£) | Hubs | %GapRail | p | |N| | Obj (£) | Hubs | Obj (£) | Hubs | %GapRail |
| 3 | 70 | 7110.67 | 56 , 32 , 1 | 6930.06 | 34 , 43 , 39 | −2.54 | 6 | 70 | 7114.49 | 1 , 49 , 12 , 7 , 15 , 0 | 6940.99 | 1 , 5 , 14 , 15 , 4 , 19 | −2.44 |
| 80 | 9413.57 | 16 , 23 , 42 | 8774.45 | 27 , 14 , 39 | −6.79 | 80 | 9492.73 | 17 , 1 , 11 , 14 , 6 , 4 | 8998.17 | 17 , 6 , 11 , 14 , 1 , 4 | −5.21 | ||
| 90 | 11,956.51 | 8 , 74 , 38 | 11,202.51 | 13 , 23 , 79 | −6.31 | 90 | 12,216.99 | 10 , 12 , 13 , 5 , 6 , 40 | 11,356.99 | 10 , 12 , 13 , 5 , 6 , 7 | −7.04 | ||
| 100 | 14,712.19 | 34 , 53 , 4 | 14,014.15 | 14 , 16 , 17 | −4.74 | 100 | 14,887.98 | 8 , 1 , 52 , 17 , 0 , 4 | 13,642.29 | 58 , 16 , 59 , 8 , 1 , 12 | −8.37 | ||
| 200 | 58,326.36 | 40 , 122 , 19 | 55,621.22 | 87 , 163 , 111 | −4.64 | 200 | 58,450.54 | 16 , 11 , 12 , 14 , 57 , 18 | 52,264.68 | 19 , 13 , 3 , 18 , 6 , 9 | −10.58 | ||
| 4 | 70 | 7099.11 | 62 , 43 , 2 , 31 | 6807.44 | 67 , 22 , 20 , 61 | −4.11 | 7 | 70 | 7237.68 | 14 , 5 , 15 , 16 , 4 , 11 , 19 | 7141.30 | 1 , 5 , 14 , 15 , 16 , 19 , 4 | −1.33 |
| 80 | 9416.52 | 41 , 11 , 4 , 26 | 8862.34 | 51 , 9 , 2 , 58 | −5.88 | 80 | 9556.25 | 18 , 11 , 9 , 10 , 15 , 6 , 8 | 9329.63 | 12 , 2 , 8 , 9 , 15 , 18 , 52 | −2.37 | ||
| 90 | 11,979.31 | 72 , 34 , 82 , 59 | 11,552.08 | 17 , 7 , 2 , 39 | −3.57 | 90 | 12,331.64 | 6 , 2 , 5 , 7 , 9 , 12 , 1 | 11,307.59 | 13 , 12 , 6 , 10 , 19 , 1 , 5 | −8.30 | ||
| 100 | 14,680.19 | 15 , 5 , 3 , 16 | 13,819.99 | 2 , 23 , 17 , 11 | −5.86 | 100 | 14,910.92 | 6 , 28 , 19 , 18 , 17 , 10 , 4 | 13,739.38 | 14 , 16 , 2 , 9 , 4 , 12 , 8 | −7.85 | ||
| 200 | 58,257.59 | 26 , 30 , 156 , 84 | 54,720.44 | 48 , 98 , 161 , 140 | −6.07 | 200 | 58,227.65 | 6 , 126 , 12 , 14 , 18 , 3 , 4 | 51,657.53 | 16 , 11 , 12 , 14 , 147 , 3 , 6 | −11.28 | ||
| 5 | 70 | 7087.00 | 3 , 11 , 1 , 14 , 12 | 6912.58 | 58 , 5 , 15 , 14 , 19 | −2.46 | |||||||
| 80 | 9508.47 | 17 , 6 , 1 , 4 , 14 | 9017.04 | 13 , 6 , 9 , 14 , 17 | −5.17 | ||||||||
| 90 | 12,174.17 | 1 , 7 , 18 , 9 , 17 | 11,365.97 | 10 , 12 , 1 , 6 , 13 | −6.64 | ||||||||
| 100 | 14,610.50 | 64 , 17 , 14 , 19 , 4 | 13,653.37 | 5 , 16 , 2 , 4 , 12 | −6.55 | ||||||||
| 200 | 58,882.66 | 3 , 135 , 11 , 12 , 18 | 53,206.54 | 19 , 13 , 12 , 18 , 9 | −9.64 | ||||||||



References
- Basallo-Triana, M.J.; Vidal-Holguín, C.J.; Bravo-Bastidas, J.J. Planning and design of intermodal hub networks: A literature review. Comput. Oper. Res. 2021, 136, 105469. [Google Scholar] [CrossRef]
- Szmelter-Jarosz, A.; Ghahremani-Nahr, J.; Nozari, H. A neutrosophic fuzzy optimisation model for optimal sustainable closed-loop supply chain network during COVID-19. J. Risk Financ. Manag. 2021, 14, 519. [Google Scholar] [CrossRef]
- Nozari, H.; Tavakkoli-Moghaddam, R.; Gharemani-Nahr, J. A neutrosophic fuzzy programming method to solve a multi-depot vehicle routing model under uncertainty during the COVID-19 pandemic. Int. J. Eng. 2022, 35, 360–371. [Google Scholar]
- Sörensen, K.; Vanovermeire, C.; Busschaert, S. Efficient metaheuristics to solve the intermodal terminal location problem. Comput. Oper. Res. 2012, 39, 2079–2090. [Google Scholar] [CrossRef]
- Salhi, S.; Rand, G.K. The effect of ignoring routes when locating depots. Eur. J. Oper. Res. 1989, 39, 150–156. [Google Scholar] [CrossRef]
- O’Kelly, M.E. The location of interacting hub facilities. Transp. Sci. 1986, 20, 92–106. [Google Scholar] [CrossRef]
- Campbell, J.F. Integer programming formulations of discrete hub location problems. Eur. J. Oper. Res. 1994, 72, 387–405. [Google Scholar] [CrossRef]
- Ernst, A.T.; Krishnamoorthy, M. Efficient algorithms for the uncapacitated single allocation p-hub median problem. Locat. Sci. 1996, 4, 139–154. [Google Scholar] [CrossRef]
- Kara, B.Y.; Tansel, B.C. On the single-assignment p-hub center problem. Eur. J. Oper. Res. 2000, 125, 648–655. [Google Scholar] [CrossRef]
- O’kelly, M.E. A quadratic integer program for the location of interacting hub facilities. Eur. J. Oper. Res. 1987, 32, 393–404. [Google Scholar] [CrossRef]
- Skorin-Kapov, D.; Skorin-Kapov, J.; O’Kelly, M. Tight linear programming relaxations of uncapacitated p-hub median problems. Eur. J. Oper. Res. 1996, 94, 582–593. [Google Scholar] [CrossRef]
- O’Kelly, M.E.; Miller, H.J. The hub network design problem: A review and synthesis. J. Transp. Geogr. 1994, 2, 31–40. [Google Scholar] [CrossRef]
- Campbell, J.F.; Ernst, A.T.; Krishnamoorthy, M. Hub arc location problems: Part I—introduction and results. Manag. Sci. 2005, 51, 1540–1555. [Google Scholar] [CrossRef]
- Campbell, J.F.; Ernst, A.T.; Krishnamoorthy, M. Hub arc location problems: Part II—formulations and optimal algorithms. Manag. Sci. 2005, 51, 1556–1571. [Google Scholar] [CrossRef]
- Yoon, M.G.; Current, J. The hub location and network design problem with fixed and variable arc costs: Formulation and dual-based solution heuristic. J. Oper. Res. Soc. 2008, 59, 80–89. [Google Scholar] [CrossRef]
- Alumur, S.; Kara, B.Y. A hub covering network design problem for cargo applications in Turkey. J. Oper. Res. Soc. 2009, 60, 1349–1359. [Google Scholar] [CrossRef][Green Version]
- Alumur, S.A.; Kara, B.Y.; Karasan, O.E. The design of single allocation incomplete hub networks. Transp. Res. Part B Methodol. 2009, 43, 936–951. [Google Scholar] [CrossRef]
- Gelareh, S.; Nickel, S. Hub location problems in transportation networks. Transp. Res. Part Logist. Transp. Rev. 2011, 47, 1092–1111. [Google Scholar] [CrossRef]
- Calık, H.; Alumur, S.A.; Kara, B.Y.; Karasan, O.E. A tabu-search based heuristic for the hub covering problem over incomplete hub networks. Comput. Oper. Res. 2009, 36, 3088–3096. [Google Scholar] [CrossRef]
- Akgün, İ.; Tansel, B.Ç. p-hub median problem for non-complete networks. Comput. Oper. Res. 2018, 95, 56–72. [Google Scholar] [CrossRef]
- Racunica, I.; Wynter, L. Optimal location of intermodal freight hubs. Transp. Res. Part B Methodol. 2005, 39, 453–477. [Google Scholar] [CrossRef]
- Alumur, S.A.; Kara, B.Y.; Karasan, O.E. Multimodal hub location and hub network design. Omega 2012, 40, 927–939. [Google Scholar] [CrossRef]
- Mokhtar, H.; Redi, A.P.; Krishnamoorthy, M.; Ernst, A.T. An intermodal hub location problem for container distribution in Indonesia. Comput. Oper. Res. 2019, 104, 415–432. [Google Scholar] [CrossRef]
- de Sá, E.M.; Morabito, R.; de Camargo, R.S. Benders decomposition applied to a robust multiple allocation incomplete hub location problem. Comput. Oper. Res. 2018, 89, 31–50. [Google Scholar] [CrossRef]
- Vural, D.; Aygün, S. Capacited P-hub location problem allowing direct flow between spokes in intermodal transportation network. Sādhanā 2019, 44, 203. [Google Scholar] [CrossRef]
- Marín, A. Formulating and solving splittable capacitated multiple allocation hub location problems. Comput. Oper. Res. 2005, 32, 3093–3109. [Google Scholar] [CrossRef]
- Osorio-Mora, A.; Núñez-Cerda, F.; Gatica, G.; Linfati, R. Multimodal capacitated hub location problems with multi-commodities: An application in freight transport. J. Adv. Transp. 2020, 2020, 2431763. [Google Scholar] [CrossRef]
- Oudani, M. Modelling the Incomplete Intermodal Terminal Location Problem. IFAC-PapersOnLine 2019, 52, 184–187. [Google Scholar] [CrossRef]
- Oudani, M. A Simulated Annealing Algorithm for Intermodal Transportation on Incomplete Networks. Appl. Sci. 2021, 11, 4467. [Google Scholar] [CrossRef]
- Maiyar, L.M.; Thakkar, J.J. Modelling and analysis of intermodal food grain transportation under hub disruption towards sustainability. Int. J. Prod. Econ. 2019, 217, 281–297. [Google Scholar] [CrossRef]
- Dukkanci, O.; Peker, M.; Kara, B.Y. Green hub location problem. Transp. Res. Part E Logist. Transp. Rev. 2019, 125, 116–139. [Google Scholar] [CrossRef]
- Alumur, S.; Kara, B.Y. Network hub location problems: The state of the art. Eur. J. Oper. Res. 2008, 190, 1–21. [Google Scholar] [CrossRef]
- Campbell, J.F.; O’Kelly, M.E. Twenty-five years of hub location research. Transp. Sci. 2012, 46, 153–169. [Google Scholar] [CrossRef]
- Alumur, S.A.; Campbell, J.F.; Contreras, I.; Kara, B.Y.; Marianov, V.; O’Kelly, M.E. Perspectives on modeling hub location problems. Eur. J. Oper. Res. 2021, 291, 1–17. [Google Scholar] [CrossRef]
- Benaini, A.; Berrajaa, A.; Boukachour, J.; Oudani, M. Solving the uncapacitated single allocation p-hub median problem on gpu. In Bioinspired Heuristics for Optimization; Springer: Berlin/Heidelberg, Germany, 2019; pp. 27–42. [Google Scholar]
- Kirschstein, T.; Meisel, F. GHG-emission models for assessing the eco-friendliness of road and rail freight transports. Transp. Res. Part B Methodol. 2015, 73, 13–33. [Google Scholar] [CrossRef]
- Holland, J. Adaption in Natural and Artifical Systems; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]




| Works | Green | Hub | Incomplete | Intermodal | Direct-Links | Load | Speed | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [6] | ✓ | |||||||||||||
| [7] | ✓ | |||||||||||||
| [8] | ✓ | |||||||||||||
| [9] | ✓ | |||||||||||||
| [10] | ✓ | |||||||||||||
| [11] | ✓ | |||||||||||||
| [12] | ✓ | ✓ | ✓ | |||||||||||
| [13,14] | ✓ | ✓ | ||||||||||||
| [15] | ✓ | ✓ | ||||||||||||
| [16] | ✓ | ✓ | ||||||||||||
| [17] | ✓ | ✓ | ||||||||||||
| [18] | ✓ | ✓ | ||||||||||||
| [19] | ✓ | ✓ | ||||||||||||
| [20] | ✓ | ✓ | ||||||||||||
| [21] | ✓ | ✓ | ||||||||||||
| [22] | ✓ | ✓ | ||||||||||||
| [23] | ✓ | ✓ | ✓ | |||||||||||
| [24] | ✓ | ✓ | ✓ | |||||||||||
| [25] | ✓ | ✓ | ✓ | |||||||||||
| [27] | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [28] | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [30] | ✓ | ✓ | ✓ | ✓ | ||||||||||
| [31] | ✓ | ✓ | ✓ | ✓ | ||||||||||
| Our work | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Decision Variables | |
| Binary variable equal to 1 if node is allocated to hub node , 0 otherwise. | |
| Binary variable equal to 1 if a rail-link between hub nodes is active, 0 otherwise. | |
| Binary variable that takes value 1 only if hub nodes are connected through active intermediate rail-links with hub node . | |
| Binary variable equal to 1 if demand flows are routed on-road directly from node to node , 0 otherwise. | |
| Binary variable equal to 1 only if demand flows are routed on-road from node to hub node , directly on rail-link between hub nodes , then on-road from hub node to node . | |
| Binary variable equal to 1 only if demand flows are routed on-road from node to hub node , between hub nodes through rail-links with hub node , then on-road from hub node to node . | |
| Dependant Variables | |
| The estimated emission costs when routing demand flows directly on-road from node to node . | |
| The estimated emission costs when routing demand flows on road-rail network from node to node , and directly on rail-link between hub nodes . | |
| The estimated emission costs when routing demand flows on road-rail network from node to node , and between hub nodes through rail-link with hub node . |
| Model Parameters | |
| N | Set of all nodes |
| H | Set of potential terminals |
| R | Set of speed levels |
| The distance between nodes and | |
| The amount of demand flow to be routed from node to node | |
| p | The number of hubs to locate |
| q | the number of active rail-links |
| The maximum payload of Train transferring demand flows between hub nodes | |
| The inter-hub cost discount factor for travel on rail-links between open hub nodes | |
| M | A large number |
| The total flow originated from the node i, | |
| The total flow destined to the node i, |
| Cross-over operators | |
| Mutual Exchange | For selected parents and , produce new off-spring such as and . |
| Link-Hub Exchange | For selected parents and , produce new off-spring such as and . Then, exchange link-hub in with link-hub in |
| Non Link-Hub Exchange | For selected parents and , produce new off-spring such as and . Then, exchange one non-link hub in with one non-link hub in . |
| Mutation operators | |
| Link-Hub Change | For selected individual X, produce new off-spring such as and . Then, select one client node in and replace link-hub node in . |
| Non Link-Hub Change | For selected individual X, produce new off-spring such as and . Then, select one client node in and replace one non link-hub node in . |
| Link-Hub Swap | For selected individual X, produce new off-spring such as and . Then, select one non link-hub in and replace link-hub node in . |
| Non-Link Hub Swap | For selected individual X, produce new off-spring such as and . Then, select two non link-hubs in and swap all their respective client nodes. |
| Reallocate Client | For selected individual X, produce new off-spring such as and . Then, select one client node in and allocate it to a different open hub. |
| Swap Clients | For selected individual X, produce new off-spring such as and . Then, swap two client nodes in each allocated to a different hub. |
| Notations | ||
| Obj | The objective cost of a solution as returned by our GA. | |
| UB | The objective cost of the best upper bound found by CPLEX. | |
| LB | The value of the lower bound found by CPLEX. | |
| %Gap | The deviation in % for each instance between the UB and LB. | |
| %GapUB | The deviation in % for each instance between the Obj and UB returned by our GA and CPLEX respectively. | |
| %GapLB | The deviation in % for each instance between the Obj and LB returned by our SAA meta-heuristic and CPLEX respectively. | |
| %GapRail | The deviation in % for each instance between the objective cost of the road-rail case and the objective cost of the road-only case. |
| GA | Variant 1 | Variant 2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| |N| | p | Obj (£) | Obj (£) | %GapGA | Obj (£) | %GapGA | |||
| 10 | 3 | 173.68 | 174.07 | 0.22 | 174.46 | 0.45 | |||
| 5 | 369.28 | 369.28 | 0.00 | 369.56 | 0.07 | ||||
| 20 | 3 | 643.84 | 656.26 | 1.93 | 691.10 | 7.34 | |||
| 5 | 765.11 | 777.39 | 1.60 | 774.08 | 1.17 | ||||
| 40 | 3 | 2377.43 | 2499.75 | 5.14 | 2546.11 | 7.09 | |||
| 5 | 2458.93 | 2672.57 | 8.69 | 2810.61 | 14.30 | ||||
| 50 | 3 | 3434.24 | 3614.85 | 5.26 | 3688.55 | 7.40 | |||
| 5 | 3459.26 | 3743.21 | 8.21 | 3834.08 | 10.83 | ||||
| Small-Sized Instances | Medium-Sized Instances | Large-Sized Instances | All Instances | |||||
|---|---|---|---|---|---|---|---|---|
| Heavy | incomplete | road-rail | 0 | 7 | 25 | 32 | ||
| road | 13 | 3 | 0 | 16 | ||||
| Complete | road-rail | 0 | 5 | 25 | 30 | |||
| road | 13 | 5 | 0 | 18 | ||||
| Medium | incomplete | road-rail | 2 | 10 | 25 | 37 | ||
| road | 11 | 0 | 0 | 11 | ||||
| Complete | road-rail | 3 | 9 | 25 | 37 | |||
| road | 10 | 1 | 0 | 11 | ||||
| Light | incomplete | road-rail | 7 | 10 | 25 | 42 | ||
| road | 6 | 0 | 0 | 6 | ||||
| Complete | road-rail | 7 | 10 | 25 | 42 | |||
| road | 6 | 0 | 0 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibnoulouafi, E.M.; Oudani, M.; Aouam, T.; Ghogho, M. Intermodal Green p-Hub Median Problem with Incomplete Hub-Network. Sustainability 2022, 14, 11714. https://doi.org/10.3390/su141811714
Ibnoulouafi EM, Oudani M, Aouam T, Ghogho M. Intermodal Green p-Hub Median Problem with Incomplete Hub-Network. Sustainability. 2022; 14(18):11714. https://doi.org/10.3390/su141811714
Chicago/Turabian StyleIbnoulouafi, El Mehdi, Mustapha Oudani, Tarik Aouam, and Mounir Ghogho. 2022. "Intermodal Green p-Hub Median Problem with Incomplete Hub-Network" Sustainability 14, no. 18: 11714. https://doi.org/10.3390/su141811714
APA StyleIbnoulouafi, E. M., Oudani, M., Aouam, T., & Ghogho, M. (2022). Intermodal Green p-Hub Median Problem with Incomplete Hub-Network. Sustainability, 14(18), 11714. https://doi.org/10.3390/su141811714