1. Introduction
At present, there is much floating garbage in rivers, lakes and sea surfaces [
1]. If this garbage can be recycled, it will improve the ecological environment and provide economic benefits [
2,
3].
However, the manual salvaging of floating garbage on water surfaces is inefficient and costly. Therefore, mechanized salvage will be the future trend, and research into floating garbage detection algorithms on the water surface will promote mechanized salvage over manual salvage. On the basis of its processing, the floating garbage detection algorithm for deep learning on water surfaces can be divided into one-phase and two-phase processes. Common first-stage algorithms include YOLOv2, YOLOv3, YOLOv4 [
4], SSD, etc., and common second-stage algorithms include R-CNN, etc. Zhang et al. [
5] proposed a network model using a combination of low-level and high-level features that has superior real-time performance for floating garbage detection on the water surface. Lin et al. [
6] introduced Soft-NMS based on the YOLOX algorithm model to improve occlusion target detection. Wang et al. [
7] proposed a lightweight Ylov4 target detection network based on an efficient Net-B0 fusion ECA mechanism. This method improves the speed of model detection by reducing the parameters of the network model. Verma V et al. [
8] studied the use of symmetry during garbage image sampling. Because symmetry is applied to extract its features, image resizing is uniform. Ma et al. [
9] proposed an enhanced single-lens multibox detector (SSD) with a lightweight and novel feature fusion module. Deng H et al. [
10] introduced the idea of expansion convolution into the feature pyramid network to enhance the feature extraction ability of small objects. Secondly, the spatial channel attention mechanism is used to make features learn adaptively. Zheng et al. [
11] proposed inland river ship recognition based on binocular stereo vision (BSV), and taking into account the computational pressure caused by the huge network parameters of the classic YOLOv4 model, the MobileNetV1 network was used as the feature extraction module of YOLOv4 model. Dan Zeng et al. [
12] used the unsupervised area proposal generation algorithm to selectively search and non-maximum suppression (NMS) to extract the location and size of garbage areas. Li et al. [
13] in During training, the anchor boxes were re-clustered to replace the inappropriate anchor boxes. Li et al. [
14] proposed a SAR ship feature enhancement method based on high-frequency sub-band channel fusion, which makes full use of the contour information, aiming at the speckle noise and ship contour ambiguity caused by SAR special imaging mechanism. Cheng et al. [
15] proposed a saliency enhancement algorithm based on the difference of anisotropic pyramid (DoAP). Considering the limitation of IoU in small target detection, we design a detection framework based on bhattacharya-like distance (BLD). On the basis of the improved RefineDet [
16] model, Zhang et al. proposed a real-time detection approach for floating objects on the water surface. This approach exhibits a good real-time performance, but the detection accuracy, particularly for relatively small floating objects on the water surface, needs improvement. Zhang et al. [
17] introduced the structure of recursive feature pyramid (RFP) and deformable convolution network (DCN) into the learning framework in order to optimize the basic backbone of the network and construct a feature map with high-level semantics and low-level positioning information of the network. Based on YOLOv5S deep learning, Du et al. [
18] adopted the BiFPN network structure to enhance the feature extraction ability of the original PANet network for unsafe objects in transmission line images. Zeng et al. [
12] proposed a garbage detection method for airborne hyperspectral data based on multiscale CNN. Zhang et al. [
19] introduced multibranch expansion convolution to enhance the characteristic information of small targets and replaced cascade RCNN with a multilayer deformable convolution network to improve the speed of the network model. Tian et al. [
20] converted YOLOv4 into a four-scale detection method. In order to improve the detection speed, the new model was pruned.
Wen et al. [
21] proposed a multiframe detection method of small targets on the sea surface based on a deep convolution neural network. Zhou et al. [
22] proposed an improved YOLO-SASE detection algorithm, which combines a SASE module, SPP module and multilevel receptive field structure. GU et al. [
23] proposed a small target detection method for ocean surveillance radar based on multifeature and principal component analysis. Gao et al. [
24] proposed a high-precision detection algorithm based on feature mapping depth neural network of spindle network structure for dim targets with few pixel features in complex and diverse backgrounds. Jia et al. [
25] added a center loss function on the basis of SSD (Single Shot MultiBox Detector) network to better deal with the problem that the intra-class difference is greater than the inter-class difference. This solves the problem of insufficient sensitivity to small objects. On the basis of the SSD network, Liu et al. [
26] used residual network as the basic network of single lens multibox detector (SSD) target detection network model. Sha et al. [
27] used ResNet50 instead of VGG16 in a fast-RCNN backbone network to increase the training depth of the network, and used soft-NMS instead of NMS, and modified the classifier layer of fast-RCNN. Sharma et al. [
28], based on the fast-RCNN network model, introduced saliency detection to better detect and identify targets. On the basis of the Mask RCNN network model, Huang et al. [
29] used ResNet as a feature extraction network, and effectively combined the feature pyramid network (FPN), ROIAlign and full convolution network (FCN) and other modules. Li et al. [
30] used a high-resolution network (HRNet) as the backbone network of image feature extraction, and adopted focus loss as the classification loss and region of interest alignment instead of region of interest merging. Shi et al. [
31] introduced a cascade strategy and adaptive threshold strategy, and proposed a domain-based adaptive fast RCNN method. Li et al. [
32] put forward GPR-RCNN based on RCNN network model, which can robustly detect defective areas even in the presence of obvious noise. On the basis of Faster RCNN, Zhao et al. [
33] improved the fast regional convolution neural network model by using the characteristic pyramid network (FPNs) to realize the insulator location in complex background images. Yu et al. [
34], based on the Mask RCNN network model, took Resnet101 as the backbone network and adopted the feature pyramid network (FPN) structure for feature extraction. Han et al. [
35] proposed a real-time small traffic sign detection method based on improved Faster RCNN. Xie et al. [
36] integrated a deconvolution module on the basis of the Faster RCNN network model to provide additional context information, which is helpful to improve the detection accuracy of small-scale pedestrian examples. On the basis of the Faster RCNN network model, Sun et al. [
37] combined various strategies to improve it, including feature concatenation, hard negative mining and multiscale training. On the basis of the YOLOv3 network model, Wang et al. [
38] proposed AS-CBAM (Adaptive Selection Convolution Block Attention Module) and innovatively combined with HDC (Hybrid Extended Convolution) to maximize the receptive field and fine-tune the features, aiming to solve the problem that the original CBAM maximum pool operation can be easily used to introduce background noise. Nevertheless, some problems with complex contexts and too small a proportion of target size cannot be effectively resolved.
This paper focuses on two contributions and proposes a PC-Net-based algorithm for floating garbage detection on water surfaces. In the detection of floating garbage on the water surface, the presence of a complex background and a large aspect ratio gap between targets (such as branches and bottles) presents the first challenge.
A solution for the generation of pyramidal anchors is proposed based on the concept of the Faster R-CNN network. The fundamental concept is to generate an anchor centered on the target and to adjust the anchor’s parameter settings based on the size and aspect ratio distribution of the target in order to better match the target. This strategy effectively reduces complex background interference, improves the overlap between the positive sample and the target, and enhances the performance of the anchor mechanism. Second, to address the issue that the target in the floating garbage on the water surface has an insufficient size share in the feature map and an unbalanced foreground and background share, which can easily result in the loss of feature information during the classification stage, thereby severely affecting the classification accuracy. The purpose of the proposed new classification discrimination map is to import a classification discrimination map with a higher resolution during the RoI Pooling feature map import stage in order to improve the accuracy of floating garbage detection on water surfaces.
2. PC-Net
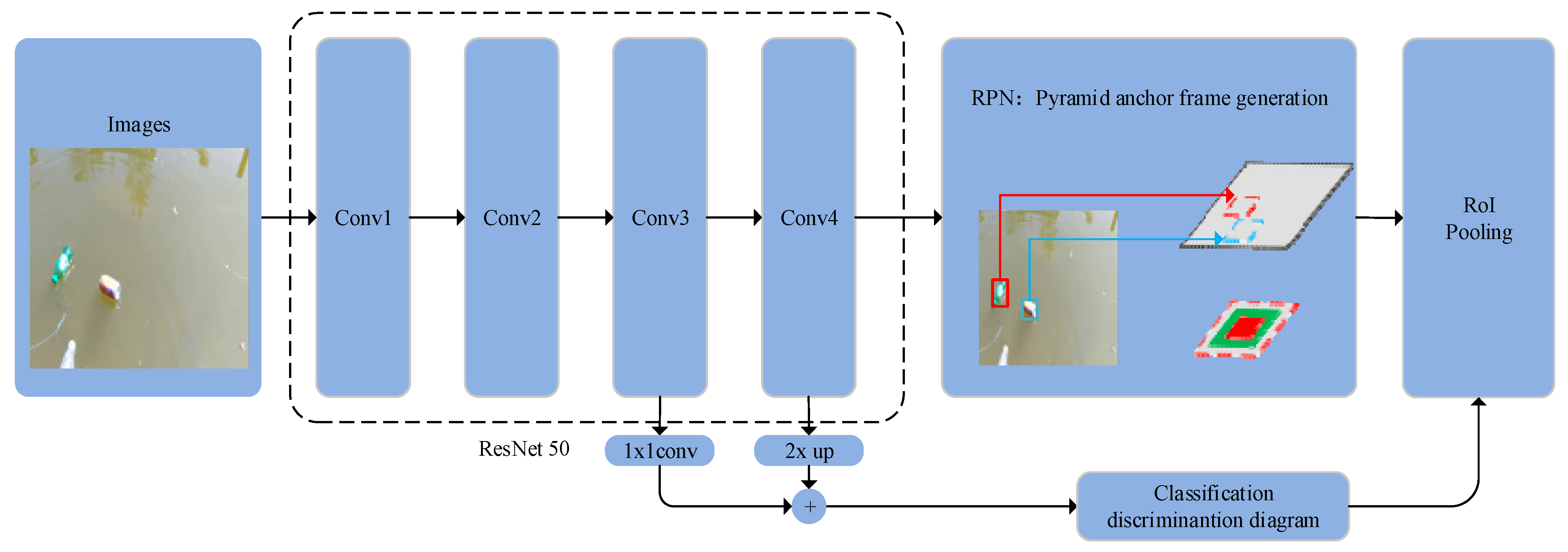
In this paper, we employ the idea of a Faster R-CNN network, and
Figure 1 depicts the model structure. First, ResNet-50 is used as the feature extraction network in this paper [
39]. Second, a pyramidal anchor generation approach is employed during the anchor generation phase. Third, during the RoI pooling feature map import stage, in order to provide clearer features for the upcoming classification operation, the classification discrimination map is lead into the RoI pooling stage. The details of these three strategies are given in the following sections.
2.1. Feature Extraction Network
ResNet-50 is used as the feature extraction network in this paper.
Figure 2 displays the network structure of ResNet-50, which includes residual learning and applies the concept of directly connected channels to the feature extraction network. Before ResNet-50, the feature extraction network transforms each layer nonlinearly before proceeding to the next layer of operation. The directly connected channel concept, on the other hand, permits a specific percentage of information from the previous levels to be transmitted to the subsequent layers; i.e., a jump connection is accomplished. Prior to ResNet-50, feature extraction networks suffer from issues such as the loss of feature information when extracting features and, in some circumstances, gradient disappearance and explosion, making it impossible to train deeper-layer feature networks. Additionally, ResNet-50 effectively overcomes the aforementioned issue by transferring the original data to the output and thus indirectly addressing the issue of feature information loss.
2.2. Pyramidal Anchor Generation Approach
In floating garbage identification on the water surface, the complicated water surface background results in inaccurate target detection. The fundamental problem is that ripples on the water surface, uneven illumination, and other various interfere with the extraction of positive and negative sample feature information, resulting in significant discrepancies between the retrieved feature information and the target. Based on this, this research proposes an approach for generating pyramidal anchors. This approach employs the semantic knowledge of image features to guide the construction of anchors. In other words, we jointly estimate the probable locations and shapes of the target centers, build anchors with associated locations, grades, and forms, and then forecast based on these anchors.
2.2.1. Center Area Selection
As indicated in
Figure 3, the central area was selected. Using the label information, we first extracted the coordinate value of the center point, the length, and the width of the object to be detected. This information was then utilized for center area selection.
The implementation process can be divided into the following three steps.
Step 1: The coordinate information of the labeled box is used to build a binarized label map for each image, where the portion of the labeled box containing the target is coded as 1 and the remainder is coded as 0; i.e., the foreground portion is labeled as 1 and the background portion is labeled as 0.
Step 2: Apply the coordinate location information of the designated box to various feature map scales yields the coordinate position information , where is the horizontal coordinate of the box’s center and is the vertical coordinate of the box’s center. The box is then divided into three categories: ignore area, center area, and outer area.
The center area (CA) = defines the central region of the annotation box, i.e., the yellow portion of the region in the image above, which is the most central portion of the annotation box and the anchor box constructed with this portion as its center corresponds to the positive sample.
is the ignore area (IA). IA is a broader region, represented in the picture above by the green area. If the anchor point center is created in this section, its IoU is rather low. Hence, this section is disregarded and used as a buffer.
The outer area (OA) is where CA and IA are removed in the whole feature map. If its center is in this part, the anchor is a negative sample.
Step 3: The above is mapped to other feature maps; i.e., this method realizes selects the central area of all feature maps.
2.2.2. Anchor Grade Classification
In the detection process of floating garbage on the surface of the water, there is an issue with the aspect ratio and size of the target, such as branches, plastic bags, and bottles, etc. Therefore, in this paper, the anchor grade approach is adopted to generate an anchor with corresponding sizes according to the different sizes of targets to be detected. As shown in
Figure 4, it is a schematic diagram of anchor grade. The square is the set length and width, and the rectangular length and width are, respectively, enlarged by two times and reduced by one half. Refer to Formula (1) for the specific setting method.
In addition, as stated in
Table 1, each level generates three sizes of anchor boxes. Each anchor box size is generated in three proportions: 1:1, 1:2, and 2:1. Formula (1) for grade classification is as follows:
where
represents the smallest width
and height
values of the target g.
is the hyperparameter, while
represents the anchor generation level. When
is equal to or greater than 3, the third rank is also chosen.
The anchors generated in this manner, regardless of whether they are positive or negative samples, are still mostly clustered around the target. So, the strategy efficiently eliminates background interference. In addition, anchors of a particular size and aspect ratio are formed based on the size of the target to be identified, so the approach effectively implements the anchor mechanism.
2.3. Classification Discrimination Diagram
In the detection of floating garbage on the surface of the water, there are many problems in the data set used in this paper; for example, the size of floating garbage is too small, and the information features retrieved during the feature extraction step are insufficiently distinct, hence reducing the accuracy of the categorization of floating garbage. This paper proposes a classification discrimination map to aid the classification of floating garbage on the water surface.
First of all, during the conventional processing of the classification operation in RoI Pooling, generating about 300 suggestion boxes after the feature map is processed by RPN. After that, these suggestion boxes are pooled and become the characteristic diagram of size 7 × 7. Finally, they are identified and classified.
The structure of the RPN network is shown in
Figure 5. Its main function is to generate an anchor based on the feature graph, and screen out candidate anchors that may contain targets from the generated anchor.
As a result, for a normal-sized target, as depicted in
Figure 6a, when d is more than 102, the size of its labeled box is approximately the same as the feature network processing, and the subsequent operation will not result in the loss of feature data. However, if the designated box is too small for small targets, as depicted in
Figure 6b, when m is less than 64, then after the feature network processing, its m1 value will be less than 4. Because 4 × 4 is smaller than 7 × 7, an interpolation-based modification (bilinear interpolation in this case) is required for the feature map. Obviously, the semantic content of the image will be lost after such processing, and the original feature information will not be sufficiently clear, which will result in a less robust model after training, leading to misdetection and a reduction in detection accuracy. Therefore, when a target is to be detected but its length and width are less than a certain threshold, misdetection will occur. In addition, an evaluation of the dataset revealed that there are more small targets than large ones (the definition of small targets for the dataset in this paper is described in detail in
Section 3.1).
This paper proposes a classification discrimination diagram for the above problems (as shown in
Figure 7). In the first step of the specific implementation procedure, Conv4 executes the upsampling operation, utilizing nearest-neighbor interpolation. In the second phase, Conv3 is processed by 1 × 1 convolution kernel to adjust the number of channels, so that the number of channels is the same as that of Conv4 convolution layer. In the third phase, the concat operation is executed to complete the feature fusion of Conv3 and Conv4 in order to generate the classification discrimination map. In the fourth phase, the suggestion box generated by RPN processing is expanded and mapped to the classification discrimination diagram in the same proportion. In the fifth phase, the classification discrimination diagram is imported into RoI Pooling stage for subsequent classification operation.
The modification is intended to increase the resolution of the discrimination map. The reason of this modification is based on the assumptions that the object detection network requires less information to establish if a proposal is a foreground object compared to identifying the type of object in the proposal region. Therefore, when the proposal is a foreground object, better results can be achieved by evaluating the class of objects with higher-resolution features.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}