1. Introduction
The Daiyun Mountain Nature Reserve is a national nature reserve in China. It primarily comprises a natural
Pinus taiwanensis forest and typical mountain forest ecosystem along the southeast coast [
1,
2]. The protected areas include specimen sites for insects and plants, wild orchids, biodiversity, and endangered plant and animal species [
3,
4]. Providing real-time monitoring of the vegetation accumulation in the reserve can provide theoretical and scientific support for the study of organisms in the reserve and for the preservation of its ecology. The growing stock volume (GSV) is a key indicator of the productivity in a country or region and varies regularly with the tree species and site conditions [
5]. It is also a crucial and sensitive reference standard for assessing the dynamic changes in regional vegetation growth. The main foundation for creating forestry management plans and realizing the sustainable development of forest resources is a timely understanding of the current conditions and development trends of the GSV. The traditional techniques for monitoring GSV are based on first- and second-class forest resource surveys. These are disadvantageous due to the protracted inquiry cycle and high labor expenses involved. In recent decades, owing to transmissions from different sensors, the methods and technologies for extracting forest parameters using remote sensing technology have developed rapidly, allowing for multi-scale forest parameters to be obtained accurately and rapidly via remote sensing and showing the potential for dynamic monitoring and quantitative estimations of forest resources [
6,
7,
8]. The current remote sensing data sources for estimations of GSVs are mainly optical and microwave remote sensing data [
9,
10,
11]. Gao et al. [
12] used thematic mapper remote sensing data and explored the correlations between several remote sensing factors and the GSV. They showed that the canopy density exerted the most significant effect on the GSV. Meng et al. [
13] investigated the relationships between the GSV and each of the infrared and near-infrared bands and discovered strong correlations. Liao et al. [
14] argued that textural features could significantly improve the estimation accuracy of the GSV, particularly for high-resolution images of complex forest structures. Obata et al. [
15] conducted extensive research on estimating GSVs using Landsat series data. Their experimental results showed that the Landsat series’ remote sensing data are highly promising for estimating standard parameters.
In addition, scholars have addressed the saturation phenomenon in forest biomass estimation using remote sensing in recent years, but the studies are limited to extracting vegetation indexes [
16,
17]. However, the higher depression in forests is the main factor contributing to the saturation phenomenon in remote sensing estimations of the GSV [
18]. Neither the normalized difference vegetation index (NDVI) nor the enhanced vegetation index (EVI) can overcome the saturation phenomenon in forest biomass estimations using remote sensing. Shen et al. [
19] investigated the relationship between forest cover and the GSV and discovered that the above-ground GSV was not significantly correlated with the EVI and NDVI when the canopy cover exceeded the forest density. Therefore, in this study, environmental information and field survey data were introduced into a model to overcome the saturation phenomenon owing to the higher depressions in natural forests. The fitting accuracies of different models were derived, along with the degree of improvement from the field survey data for overcoming the saturation phenomenon on the fitting effect of the models.
Multiple linear regression (MLR) models primarily include two or more independent variables. They aim to use the best combinations of independent variables to predict dependent variables with high interpretability. Bolat et al. [
20] used MLR models and concluded that the prediction accuracy for the GSV is closely associated with the forest’s vegetation structure and spatial dependence. Additionally, they mentioned that MLR models have difficulty in finding polynomial correlations between nonlinear data or data characteristics. Machine learning models can effectively solve this problem. Thus, three machine learning regression models were used in our study.
Recently, decision tree models have been increasingly used to analyze, describe, and predict ecological data, and the logic used in these modeling decision tree models can effectively handle various types of predictor variables (such as sparse, skewed, continuous, and categorical). The predictor and dependent variables do not require that any form of distributional assumptions can handle complex interactions among the predictor variables [
21]. However, a single decision tree model has specific shortcomings, such as model instability (small changes in the data may cause large changes in the tree, thereby affecting the interpretation) and overfitting [
12]. To overcome these problems, researchers have proposed integrated learning-based random forest models, in which many decision trees are combined to form a single model, and such integrated learning-based decision tree models are typically more stable and have better predictive power than single decision tree models [
22]. Some scholars have used random forest models to analyze the sources of differences in estimating dependent variables according to various independent variables in ecology and forestry [
23,
24,
25,
26,
27], which has solved the related scientific problems quite well. Extra Trees, compared with random forests, are extremely random in the division of decision tree nodes and directly use a random feature and a random threshold on the random feature for partitioning. Extra Trees provide a significantly strong additional randomness that does not bias the entire model by a few extreme sample points [
28,
29,
30]. Therefore, in this study, three typical machine learning models were chosen for fitting: decision trees, random forests, and Extra Trees.
In recent years, many GSV estimation experiments have been conducted based on forest farms and plots; however, studies considering subcompartments and combinations of remote sensing images and field survey data in such subcompartments remain limited. Therefore, this study compared the performances of traditional regression and machine learning models in the Daiyun Mountain Reserve and the fitting accuracy changes before and after adding the field survey data of the subcompartments to the models.
2. Methods
The Daiyun Mountain Reserve is located in Dehua County, Fujian Province, China (118°05′22″ to 118°20′15″ E, 25°38′07″ to 25°43′40″ N). The location of the study site within Fujian Province as well as the location of Fujian Province with respect to China is shown in the
Figure 1. The total reserve is 13,472.4 ha, and 5514.1 ha are occupied by the core area [
31]. The highest elevation of the Daiyun Mountain Reserve is 1856 m, the lowest elevation is 650 m, and the relative elevation difference is 1206 m, resulting in significant vertical changes in climate and vegetation. The annual average temperature in the reserve is 15.6–19.5 °C, the annual average sunshine duration is 1875.4 h, and the annual average rainfall is 1700–2000 mm. The zonal vegetation type is the south subtropical monsoon evergreen broad-leaved forest. It comprises a narrow coniferous broad-leaved mixed forest belt at an altitude of 1000–1200 m, a
Pinus taiwanensis coniferous forest at an altitude of 1200 m, and mountain shrubs at the top of the mountain, with a forest coverage rate of 93.4%.
2.1. Establishment of Daiyun Mountain Reserve Database
The GSV data used in this study were forest management inventory data of the Daiyun Mountain Reserve acquired by the Fujian Forestry Bureau in 2018. The GSVs of the broad-leaved forests and pine forests (moso bamboo was not counted) were calculated for each subcompartment in the Daiyun Mountain Reserve in the
Figure 2.
In this study, SPTOOLS in the Arcgis 10.8 software (Environmental Systems Research Institute, Inc. RedLands, CA, USA) was used to obtain the weighted averages of the annual rainfall dataset with a resolution of 1 km in China (Chinese National Earth System Science Data Center) [
32] and a digital elevation model dataset with a resolution of 90 m in the Fujian province in 2018 (Resource and Environment Science and Data Center) [
33] on a small-class scale. An annual average rainfall, altitude, slope gradient, and slope direction were then assigned to each subcompartment.
2.2. Normalized Difference Vegetation Index (NDVI) Extraction and Data Preprocessing
The remote sensing images used in this study were captured from Landsat 8 operational land imager (OLI) data (Geospatial Data Cloud) [
34] at path No. 119 and row No. 42 on 5 October 2018. ENVI5.3 software was used to preprocess the remote sensing data, including clipping, radiation calibration, and atmospheric correction. The NDVI was selected as the vegetation index, and its weighted average was assigned to each subcompartment. In this study, the NDVI was calculated as the sum of the values of the near-infrared (NIR) and visible red bands over the difference between the values of the NIR band (NIR < 0.7 mm) and visible red band (0.4 mm < R < 0.7 mm).
In the above, NIR is the reflectance of the near-infrared band, and R is the reflectance of the visible red band.
In this study, the extracted environmental factors (
Figure 3 and
Figure 4) were normalized to ensure that each feature vector was treated equally by the classifier. The normalization formulas shown in
Table 1 were used to normalize the annual rainfall, altitude, slope gradient, slope direction, tree height, diameter at breast height (DBH), and tree age.
2.3. Selection of Regression Model
2.3.1. Multiple Linear Regression (MLR) (Model 1)
In the above, y is the GSV per ha; β0, β1, ···, βn is the model-fitting parameter; x0, x1, ···, xn is the environmental information regarding the remote sensing and field measurement data; and n is the number of variables.
2.3.2. Decision Tree Regression (Model 2)
A continuous value prediction model using a tree structure divides the samples arriving at the node based on a specific attribute, and each subsequent branch of the node corresponds to a possible value of the attribute.
2.3.3. Random Forests (Model 3)
Many decision trees are generated in this process based on the modeling data set, sample observation, and characteristic variables. By performing random sampling, each time that the sampling results are based on a tree and a tree is generated based on its own attributes rules and values, the forest integrates all of the rules of the decision tree and the final judgment value.
2.3.4. Extra Trees (Model 4)
The “extra trees” algorithm is highly similar to the random forest algorithm. The random forest approach obtains the best bifurcation attribute in a random subset, whereas the extra trees approach obtains a bifurcation value randomly to bifurcate the decision tree.
2.3.5. Selection of Hyperparameters for Machine Learning Models
In the above machine learning model, the parameters (
Table 2) to be set are: the (a) minimum number of samples for internal node splitting, (b) minimum number of samples for the leaf nodes, (c) maximum depth of the tree, and (d) maximum number of leaf nodes. If the sample size of an internal node is less than (a), no further splitting is performed. If the sample size of a leaf node is less than (b), it is pruned with its sibling nodes. The splitting stops when the depth of the tree reaches (c) to avoid infinite downward division. The number of leaf nodes stops splitting when it reaches (d) to avoid an infinite number of division categories. In addition, the random forest and limit tree models must also set the (e) number of decision trees. Increasing the number of decision trees improves the fitting ability, but it increases the computation time and overfitting probability. In addition, the sample size of the study data is large; thus, each decision tree is sampled with put-back.
2.4. Evaluation Indicator
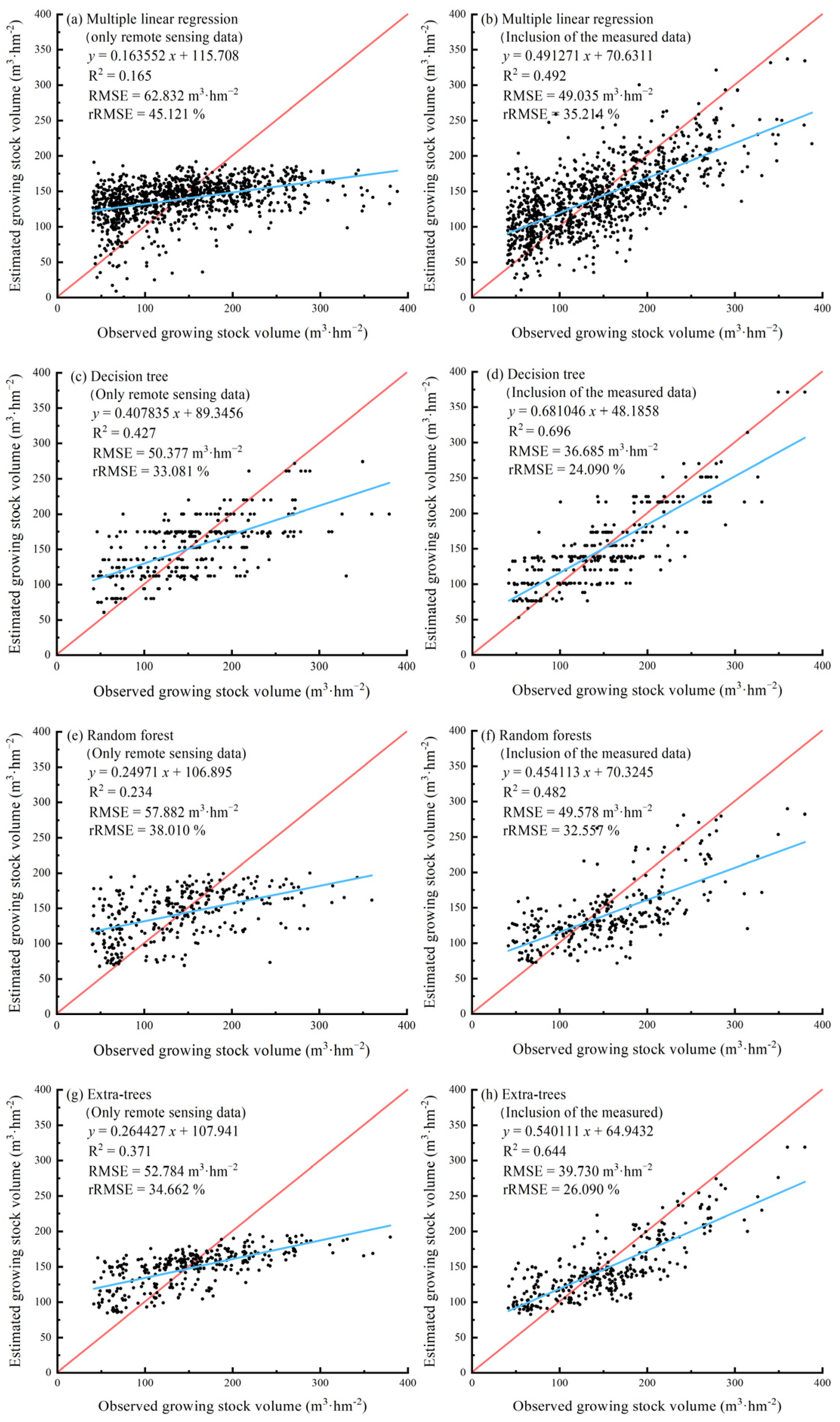
In this study, the IBM SPSS Statistics 26 software was used to process the GSV per ha from the forest management inventory data from Daiyun Mountain Reserve in 2018. It was combined with remote sensing and field measurement data to fit Models 1 to 4. In the machine learning models (Models 2–4), to evaluate the estimation abilities of the different models, the data were randomly segregated into training data (70%) and verification data (30%), and the coefficient of determination (R
2), root-mean-square error (RMSE), and relative root-mean-square error (rRMSE) were selected as evaluation indexes. The R
2, RMSE, and rRMSE were calculated as follows:
Here, yi is the measured value of the GSV per ha of the subcompartment, is the estimated value of the GSV per ha of the subcompartment, is the average measured value of the GSV per ha of the subcompartment, and n is the test sample size.
4. Discussion
In past studies, the climate, topography, human disturbance, and forest management activities have influenced changes in forest structure and accumulation to some extent. Zeng [
35] developed a climate-sensitive individual tree biomass model by combining the mean annual temperature (T) and annual precipitation (P) to analyze the influence of climatic factors on biomass estimation, and the results showed that mean annual precipitation influences the predicted biomass. Propastin [
36] used geographically weighted regression to conclude that a strong correlation exists between the vegetation and rainfall in central Sulawesi by modeling the relationship between the vegetation and climate. In addition, Propastin [
37] included elevation effects in geographically weighted regression (GWR) when estimating the accuracy of above-ground biomass (ABG) models using spectral data from remote sensing. The results showed that geographically and altitudinal weighted regression (GAWR) significantly improved the prediction of ABG in the study area. Katherine [
38] surveyed plant communities and measured key abiotic variables across forest–tundra ecotones in six alpine valleys. The results showed that plant communities vary more in slope direction and gradient than in elevation. Due to local laws, the Daiyun Mountain Reserve is not open to the public; thus, the influence of human factors and operations in this study area can be excluded. Therefore, this study chose to introduce the environmental information of rainfall, elevation, slope gradient, and slope direction to improve the accuracy of the estimated storage model.
Gherardo [
39] compared the accuracy of k-nn algorithms with non-parameters in two study areas, the Mediterranean and Alpine ecosystems, using remotely sensed imagery combined with field measurements, testing 3500 different algorithm configurations and yielding rRMSEs between 22% and 28% and GSV estimates between 44% and 63% for the two study areas. No significant difference was observed between the rRMSE derived by Gherardo using a k-nn algorithm with parameters and the rRMSE from this study using the learning algorithm. Li [
40] estimated the GSV of coniferous forests using multiple high-resolution remote sensing images and compared their model accuracy, and the results showed that the rRMSE based on four image datasets (GF-2, ZY-3, Sentinel-2, and Landsat 8) were 22.16%, 22.44%, 20.06%, and 24.73%, respectively. Li’s study obtained a model with high accuracy using only remote sensing imagery at high resolutions, but his experiments were conducted on planted conifer forests with weak saturation phenomena. In Hawrylo’s study [
41], the prediction accuracy of the model created using only Sentinel-2A imagery was low, characterized by a high rRMSE of 35.14% and a low R
2 of 0.24. The fusion of IPC data with Sentinel-2 reflectance values provided the most accurate model: rRMSE = 16.95% and R
2 = 0.82. However, a significant accuracy was obtained using only the IPC-based model: rRMSE% = 17.26% and R
2= 0.81. The results suggest that the IPC data from this experiment played a decisive role in estimating the model. This indirectly illustrates the value of including measured data in this study to improve the accuracy of the estimation model.
The study area was located in a subtropical monsoon zone, and the selected samples represented the dominant tree species in the study area. Therefore, the experimental results are beneficial for GSV estimation in the above-mentioned climatic zone; however, their applicability to other regions and other tree species requires further investigation.
In this study, in addition to the environmental factors of the rainfall, topography, and elevation, the saturation of all estimation models was weakened after adding the measured data of the DBH and tree age to the models. Moreover, the difference between the inversion values of low and high levels and the observed values in the estimation model with measured data was significantly reduced; thus, the inclusion of the measured data can be considered to effectively alleviate the saturation caused by highly dense natural forests, to an extent. By comprehensively investigating the resource environment of the Daiyun Mountain Reserve, the GSV model can be even further improved by combining more environmental information, such as data regarding temperature, soil, natural disasters, and human interference.
This study selected the parameters of the machine learning models by manually adjusting the hyperparameters. The selection principle was that each parameter did not vary too much among the models while satisfying the good fitting effect of the models. Although this manual selection method does not guarantee the full performance of the model’s fitting ability [
42], by manually adjusting the parameters between models several times, a trade-off can be obtained in determining the best combination of parameters and comparing the parameters with other models. This makes the models more comparable and generalizable [
43,
44].
In this study, Landsat 8 OLI data were used as the remote sensing data source; however, the information provided by the data was limited. Although various environmental information and field measurement data were used in this study, the saturation of the GSVs could not be entirely overcome. In future studies, we will investigate the use of synthetic aperture radar data-fusion methods to estimate the accumulation, which can subsequently be used to reduce the interference from saturation.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}