

Graph Embedding-Based Domain-Specific Knowledge Graph Expansion Using Research Literature Summary


Abstract
1. Introduction
2. Related Work
2.1. Automatic Knowledge Graph Generation and Expansion
2.2. Deep Learning-Based Pre-Trained Language Model
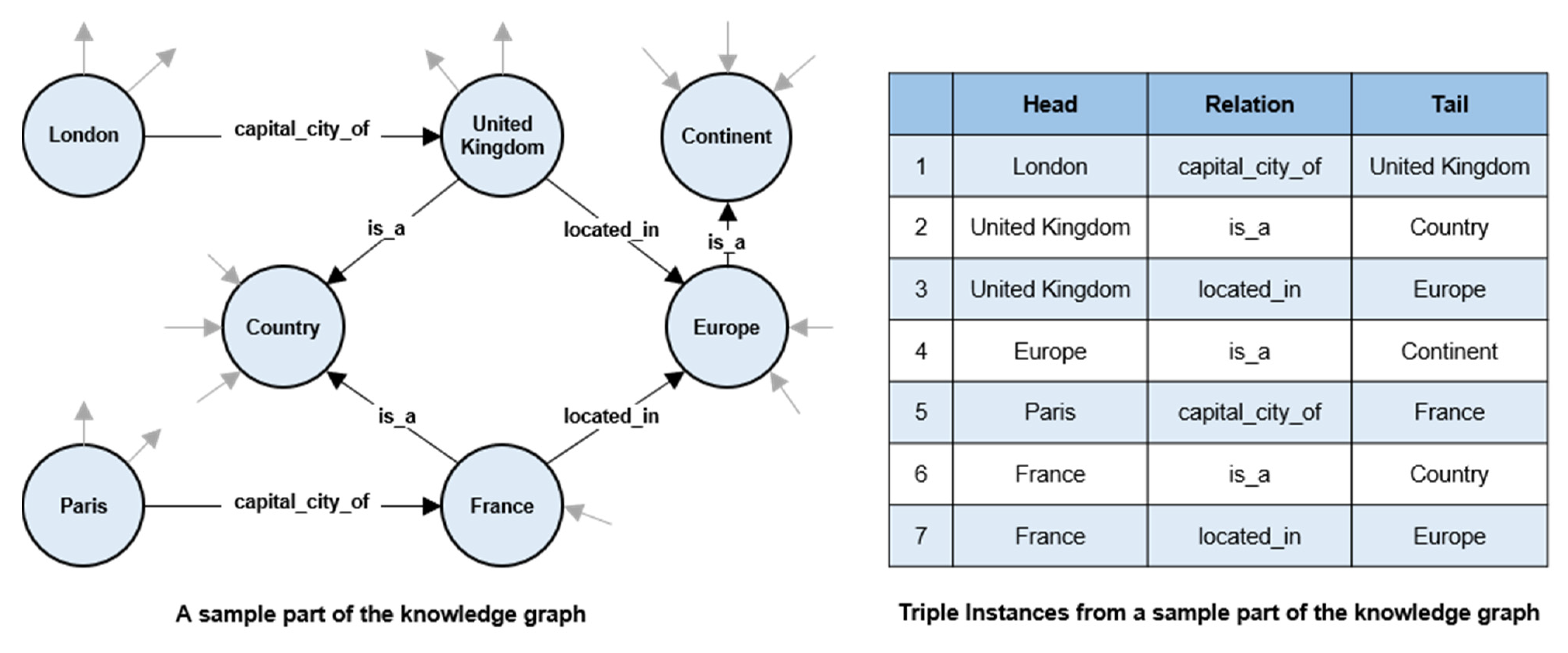
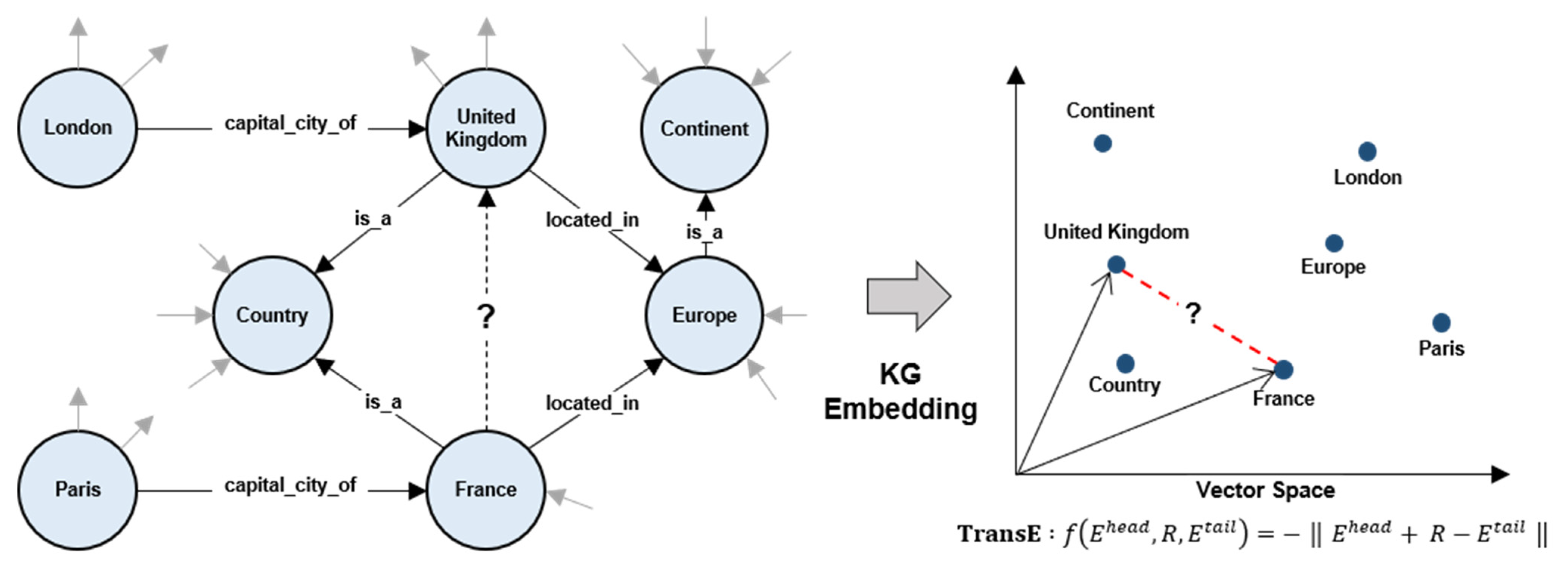
3. Graph Embedding-Based Domain-Specific Knowledge Graph Expansion
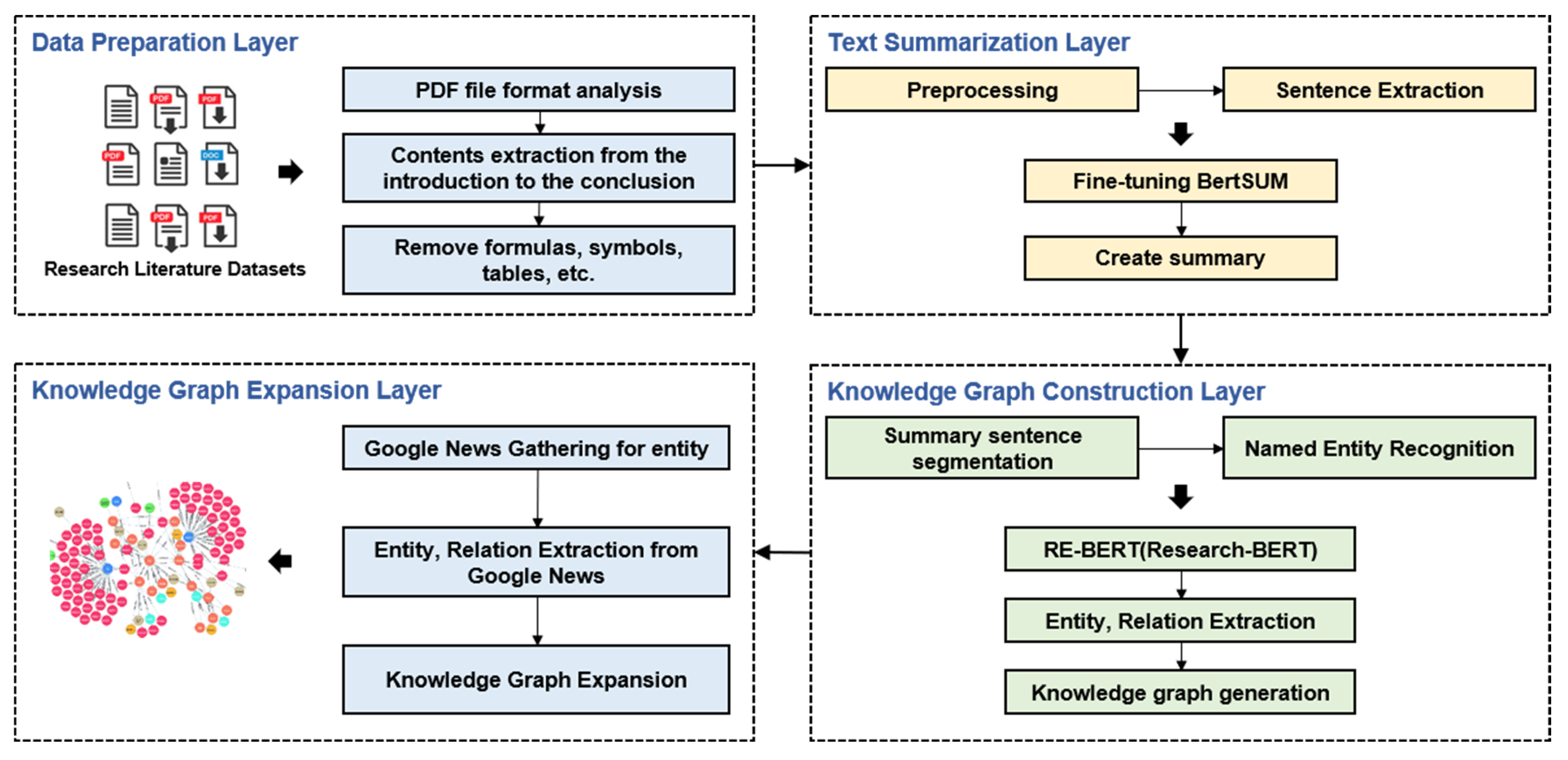
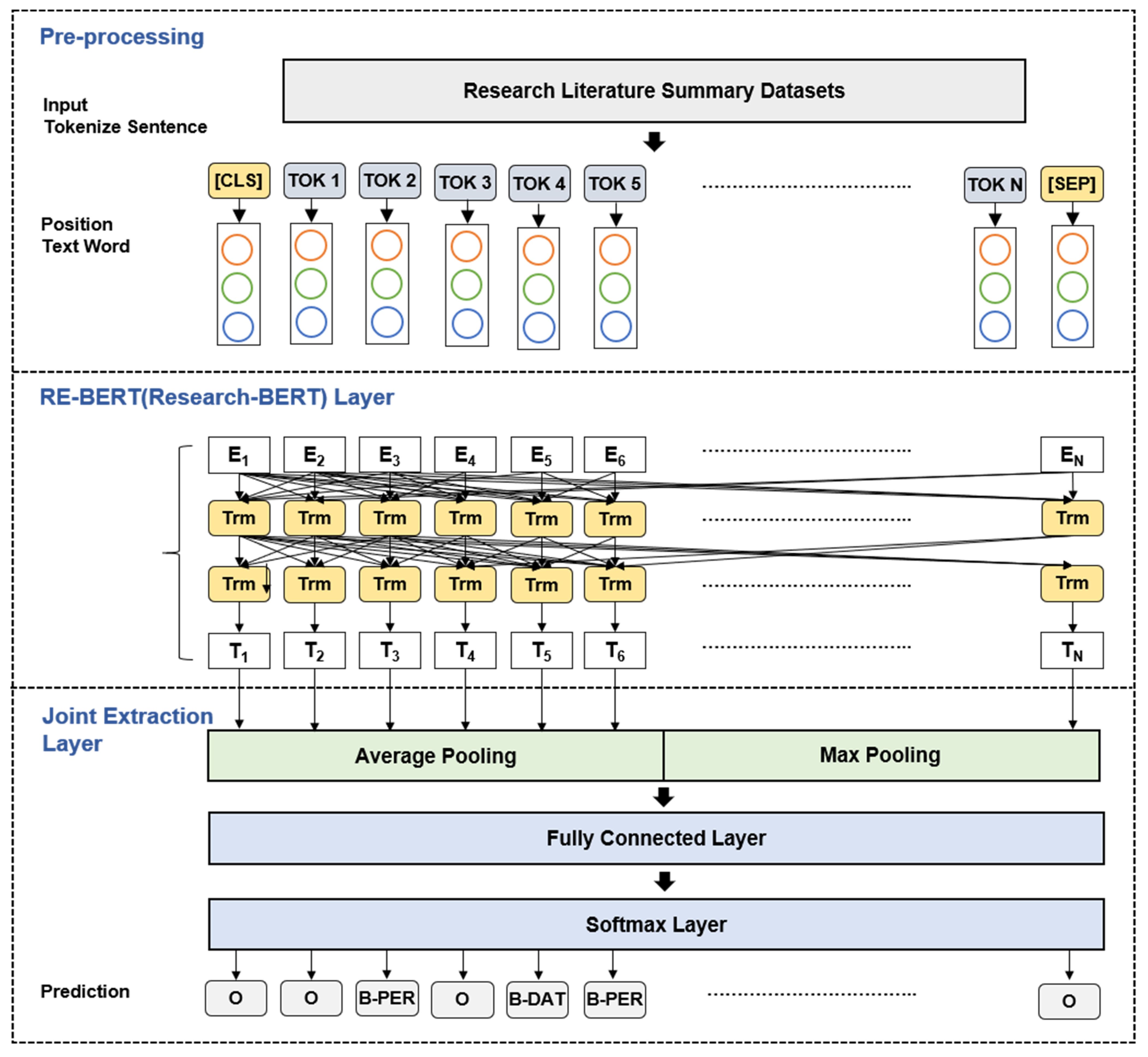
3.1. Overall Framework
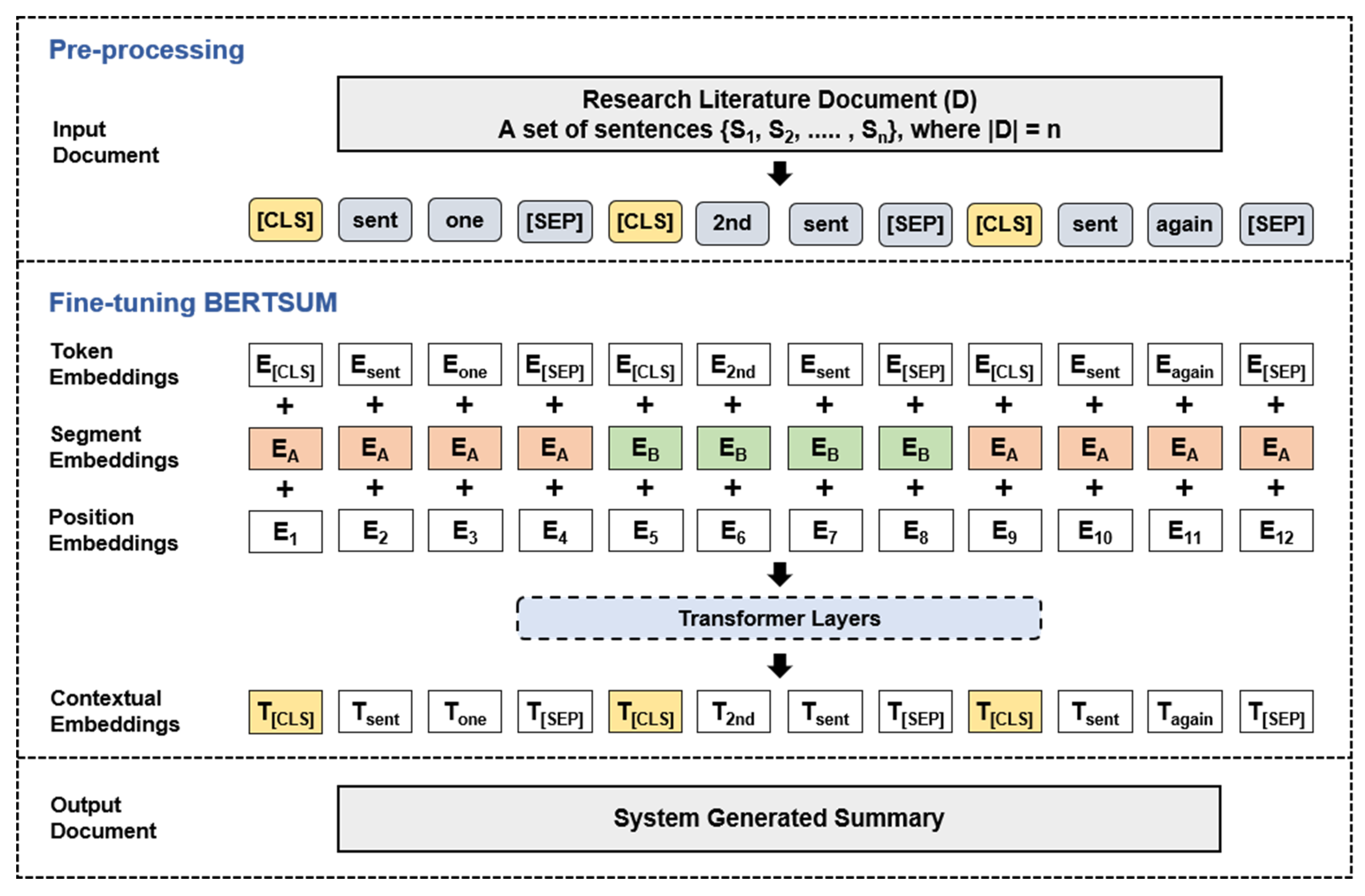
3.2. Pre-Processing and Summarization of Research Literature
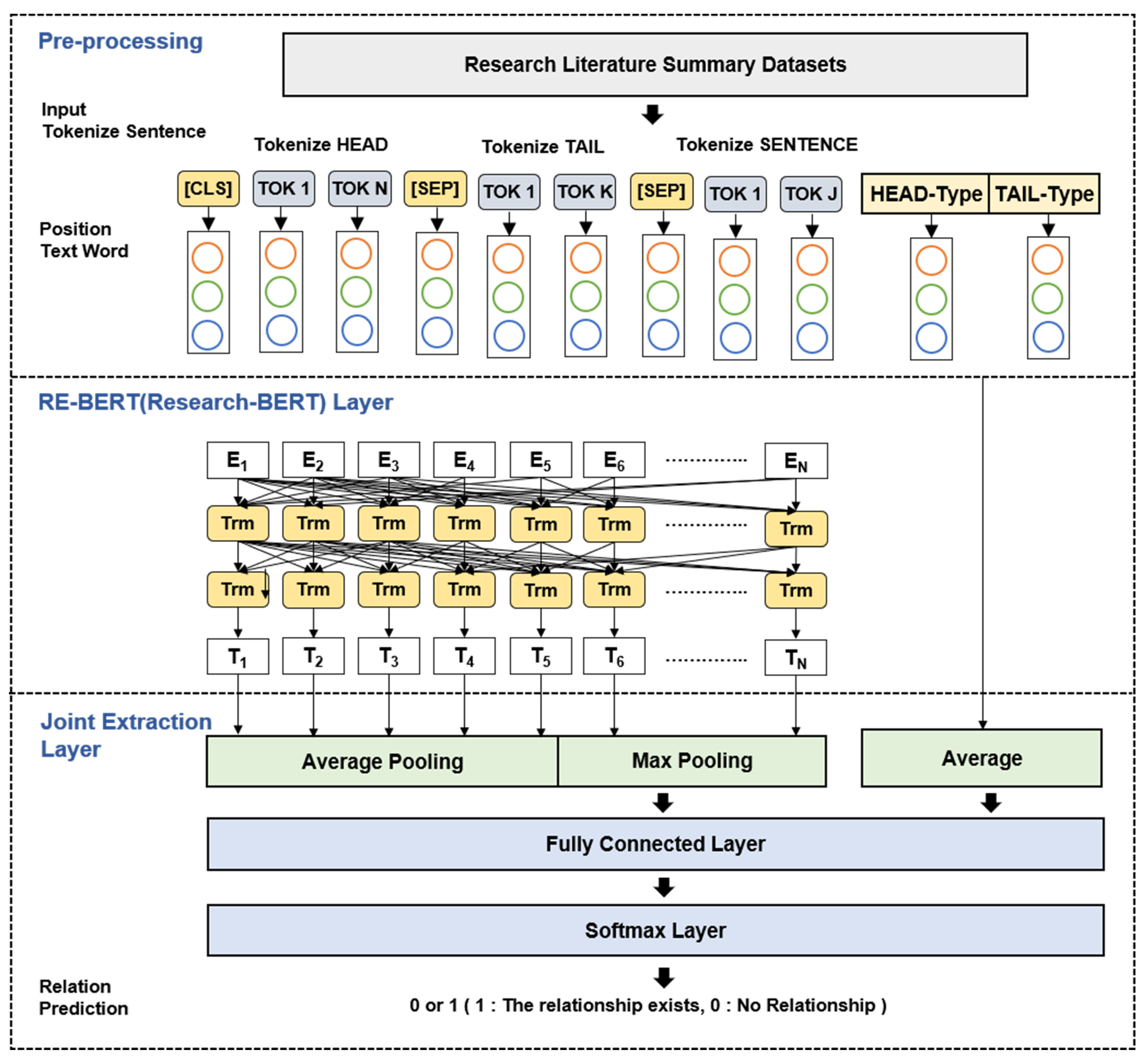
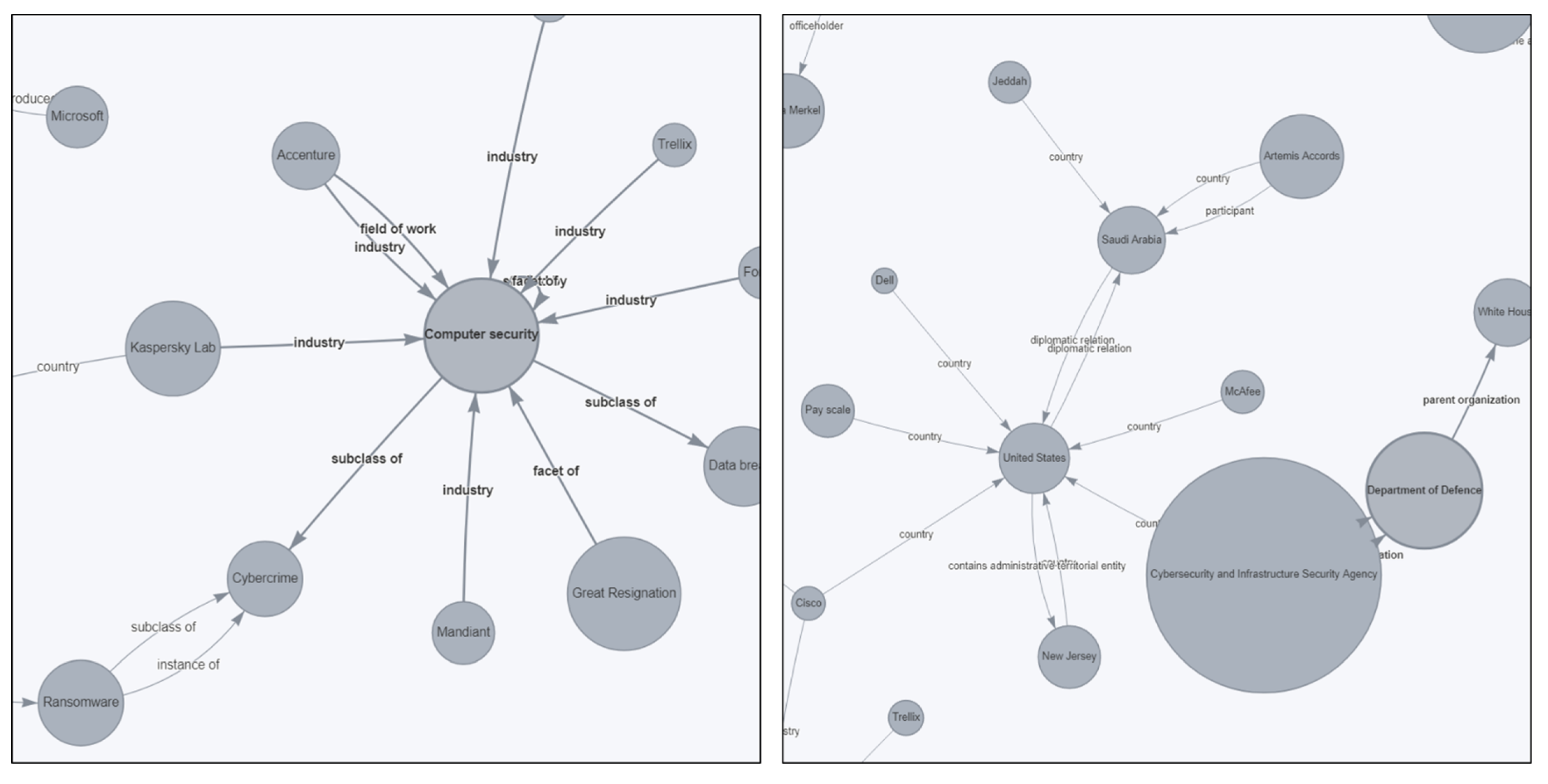
3.3. Knowledge Graph Generation and Expansion Using Research Literature
4. Experiment and Evaluation
4.1. Research Literature Summarization Experiment
4.2. Accuracy of Knowledge Graph Relation Extraction Model
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| BERTSUM | Bidirectional Encoder Representations from Transformers for Summarization |
| NER | Named Entity Recognition |
| CLS | Special Classification Token |
| SEP | Special Separator Token |
| UNK | Unknown Token |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| RNN | Recurrent Neural Network |
| MRR | Mean Reciprocal Rank |
| MR | Mean Rank |
References
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2022, 1–32. [Google Scholar] [CrossRef]
- Wang, R.J.; Yan, Y.C.; Wang, J.L.; Jia, Y.T.; Zhang, Y.; Zhang, W.N.; Wang, X.B. AceKG: A Large-scale Knowledge Graph for Academic Data Mining. In Proceedings of the Cikm’18: Proceedings of the 27th Acm International Conference on Information and Knowledge Management, New York, NY, USA, 22–26 October 2018; pp. 1487–1490. [Google Scholar] [CrossRef]
- Nayyeri, M.; Vahdati, S.; Zhou, X.; Shariat Yazdi, H.; Lehmann, J. Embedding-based recommendations on scholarly knowledge graphs. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 31 May–4 June 2020; pp. 255–270. [Google Scholar]
- Rossi, R.A.; Zhou, R.; Ahmed, N.K. Deep inductive graph representation learning. IEEE Trans. Knowl. Data Eng. 2018, 32, 438–452. [Google Scholar] [CrossRef]
- Ferré, S. Link prediction in knowledge graphs with concepts of nearest neighbours. In Proceedings of the European Semantic Web Conference, Portorož, Slovenia, 2–6 June 2019; pp. 84–100. [Google Scholar]
- Rossanez, A.; dos Reis, J.C. Generating Knowledge Graphs from Scientific Literature of Degenerative Diseases. In Proceedings of the SEPDA@ ISWC, Auckland, New Zealand, 27 August 2019; pp. 12–23. [Google Scholar]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef]
- Liu, Y. DKG-PIPD: A Novel Method About Building Deep Knowledge Graph. IEEE Access 2021, 9, 137295–137308. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, S.; Xiong, N.N.; Guo, W. A survey on knowledge graph embedding: Approaches, applications and benchmarks. Electronics 2020, 9, 750. [Google Scholar]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open research knowledge graph: Next generation infrastructure for semantic scholarly knowledge. In Proceedings of the 10th International Conference on Knowledge Capture, Los Angeles, CA, USA, 19–21 November 2019; pp. 243–246. [Google Scholar]
- Kim, J.; Kim, K.; Sohn, M.; Park, G. Deep Model-Based Security-Aware Entity Alignment Method for Edge-Specific Knowledge Graphs. Sustainability 2022, 14, 8877. [Google Scholar] [CrossRef]
- Kejriwal, M. Domain-Specific Knowledge Graph Construction; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Chen, X.; Xie, H.; Li, Z.; Cheng, G. Topic analysis and development in knowledge graph research: A bibliometric review on three decades. Neurocomputing 2021, 461, 497–515. [Google Scholar]
- Berrendorf, M.; Faerman, E.; Vermue, L.; Tresp, V. Interpretable and Fair Comparison of Link Prediction or Entity Alignment Methods. In Proceedings of the 2020 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Melbourne, Australia, 14–17 December 2020; pp. 371–374. [Google Scholar]
- Lissandrini, M.; Pedersen, T.B.; Hose, K.; Mottin, D. Knowledge graph exploration: Where are we and where are we going? ACM SIGWEB Newsl. 2020, 1–8. [Google Scholar] [CrossRef]
- Sun, Z.; Huang, J.; Hu, W.; Chen, M.; Guo, L.; Qu, Y. Transedge: Translating relation-contextualized embeddings for knowledge graphs. In Proceedings of the International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; pp. 612–629. [Google Scholar]
- Zhu, Q.; Zhou, X.; Zhang, P.; Shi, Y. A neural translating general hyperplane for knowledge graph embedding. J. Comput. Sci. 2019, 30, 108–117. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar]
- Zhang, W.; Deng, S.; Chen, M.; Wang, L.; Chen, Q.; Xiong, F.; Liu, X.; Chen, H. Knowledge graph embedding in e-commerce applications: Attentive reasoning, explanations, and transferable rules. In Proceedings of the 10th International Joint Conference on Knowledge Graphs, Bangkok, Thailand, 6–8 December 2021; pp. 71–79. [Google Scholar]
- Lakshika, M.; Caldera, H. Knowledge Graphs Representation for Event-Related E-News Articles. Mach. Learn. Knowl. Extr. 2021, 3, 802–818. [Google Scholar] [CrossRef]
- Sun, Z.; Deng, Z.-H.; Nie, J.-Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Nguyen, D.Q. A survey of embedding models of entities and relationships for knowledge graph completion. arXiv 2017, arXiv:1703.08098. [Google Scholar]
- Ma, J.; Qiao, Y.; Hu, G.; Wang, Y.; Zhang, C.; Huang, Y.; Sangaiah, A.K.; Wu, H.; Zhang, H.; Ren, K. ELPKG: A high-accuracy link prediction approach for knowledge graph completion. Symmetry 2019, 11, 1096. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Kazemi, S.M.; Poole, D. SimpleE embedding for link prediction in knowledge graphs. Adv. Neural Inf. Processing Syst. 2018, 31. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. arXiv 2019, arXiv:1908.08345. [Google Scholar]
- Liu, Y.; Luo, Z.; Zhu, K. Controlling length in abstractive summarization using a convolutional neural network. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4110–4119. [Google Scholar]
- Khatri, C.; Singh, G.; Parikh, N. Abstractive and extractive text summarization using document context vector and recurrent neural networks. arXiv 2018, arXiv:1807.08000. [Google Scholar]
- Mao, X.; Yang, H.; Huang, S.; Liu, Y.; Li, R. Extractive summarization using supervised and unsupervised learning. Expert Syst. Appl. 2019, 133, 173–181. [Google Scholar] [CrossRef]
- Kim, T.; Yun, Y.; Kim, N. Deep learning-based knowledge graph generation for COVID-19. Sustainability 2021, 13, 2276. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948.1–112948.21. [Google Scholar] [CrossRef]
- Guo, L.; Zhang, Q.; Ge, W.; Hu, W.; Qu, Y. DSKG: A deep sequential model for knowledge graph completion. In Proceedings of the China Conference on Knowledge Graph and Semantic Computing, Tianjin, China, 14–18 August 2018; pp. 65–77. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Metrics | Recall | Precision | F1-Score |
|---|---|---|---|---|
| BERTSUM Classifier | ROUGE-1 | 9.34% | 57.86% | 16.08% |
| ROUGE-2 | 4.25% | 16.53% | 6.76% | |
| ROUGE-L | 6.67% | 39.12% | 11.40% | |
| Transformer | ROUGE-1 | 9.56% | 58.34% | 16.43% |
| ROUGE-2 | 4.87% | 14.91% | 7.34% | |
| ROUGE-L | 5.89% | 39.87% | 10.26% | |
| RNN | ROUGE-1 | 8.65% | 53.26% | 14.88% |
| ROUGE-2 | 4.35% | 14.61% | 6.70% | |
| ROUGE-L | 5.79% | 35.18% | 9.94% |
| Model | MRR | MR | HITS@10 | HITS@3 | HITS@1 | |
|---|---|---|---|---|---|---|
| RE-BERT | Experiment-1 | 0.38 | 218.91 | 0.53 | 0.42 | 0.37 |
| Experiment-2 | 0.47 | 131.67 | 0.61 | 0.57 | 0.42 | |
| TransE | Experiment-1 | 0.29 | 531.87 | 0.46 | 0.36 | 0.31 |
| Experiment-2 | 0.44 | 152.31 | 0.68 | 0.42 | 0.45 | |
| HolE | Experiment-1 | 0.26 | 198.46 | 0.48 | 0.31 | 0.28 |
| Experiment-2 | 0.37 | 156.14 | 0.42 | 0.39 | 0.26 | |
| ConvE | Experiment-1 | 0.24 | 763.56 | 0.39 | 0.28 | 0.21 |
| Experiment-2 | 0.28 | 356.10 | 0.43 | 0.34 | 0.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J. Graph Embedding-Based Domain-Specific Knowledge Graph Expansion Using Research Literature Summary. Sustainability 2022, 14, 12299. https://doi.org/10.3390/su141912299
Choi J. Graph Embedding-Based Domain-Specific Knowledge Graph Expansion Using Research Literature Summary. Sustainability. 2022; 14(19):12299. https://doi.org/10.3390/su141912299
Chicago/Turabian StyleChoi, Junho. 2022. "Graph Embedding-Based Domain-Specific Knowledge Graph Expansion Using Research Literature Summary" Sustainability 14, no. 19: 12299. https://doi.org/10.3390/su141912299
APA StyleChoi, J. (2022). Graph Embedding-Based Domain-Specific Knowledge Graph Expansion Using Research Literature Summary. Sustainability, 14(19), 12299. https://doi.org/10.3390/su141912299