
Three-Stream and Double Attention-Based DenseNet-BiLSTM for Fine Land Cover Classification of Complex Mining Landscapes

Abstract
:1. Introduction
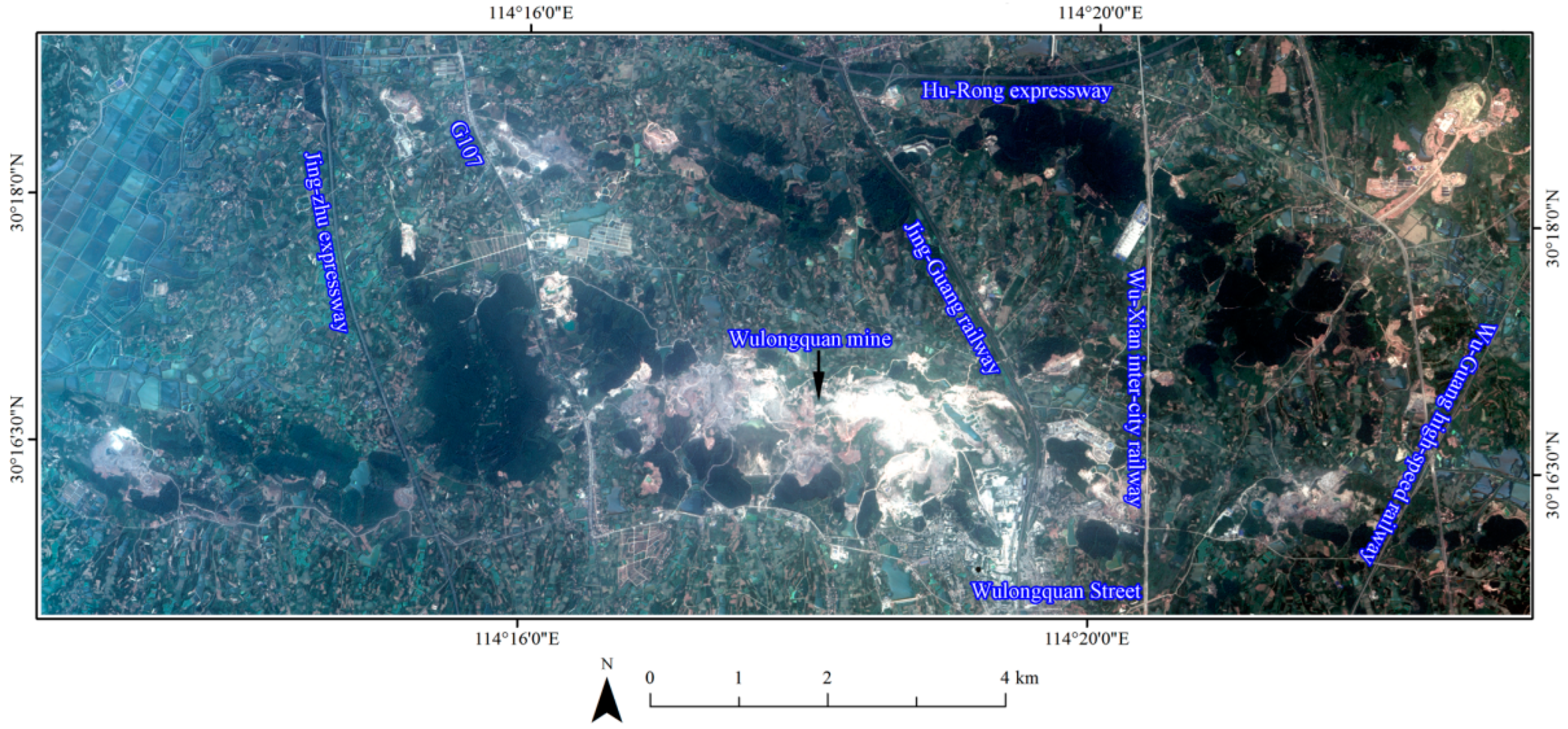
2. Study Area and Remote Sensing Datasets
3. Methods
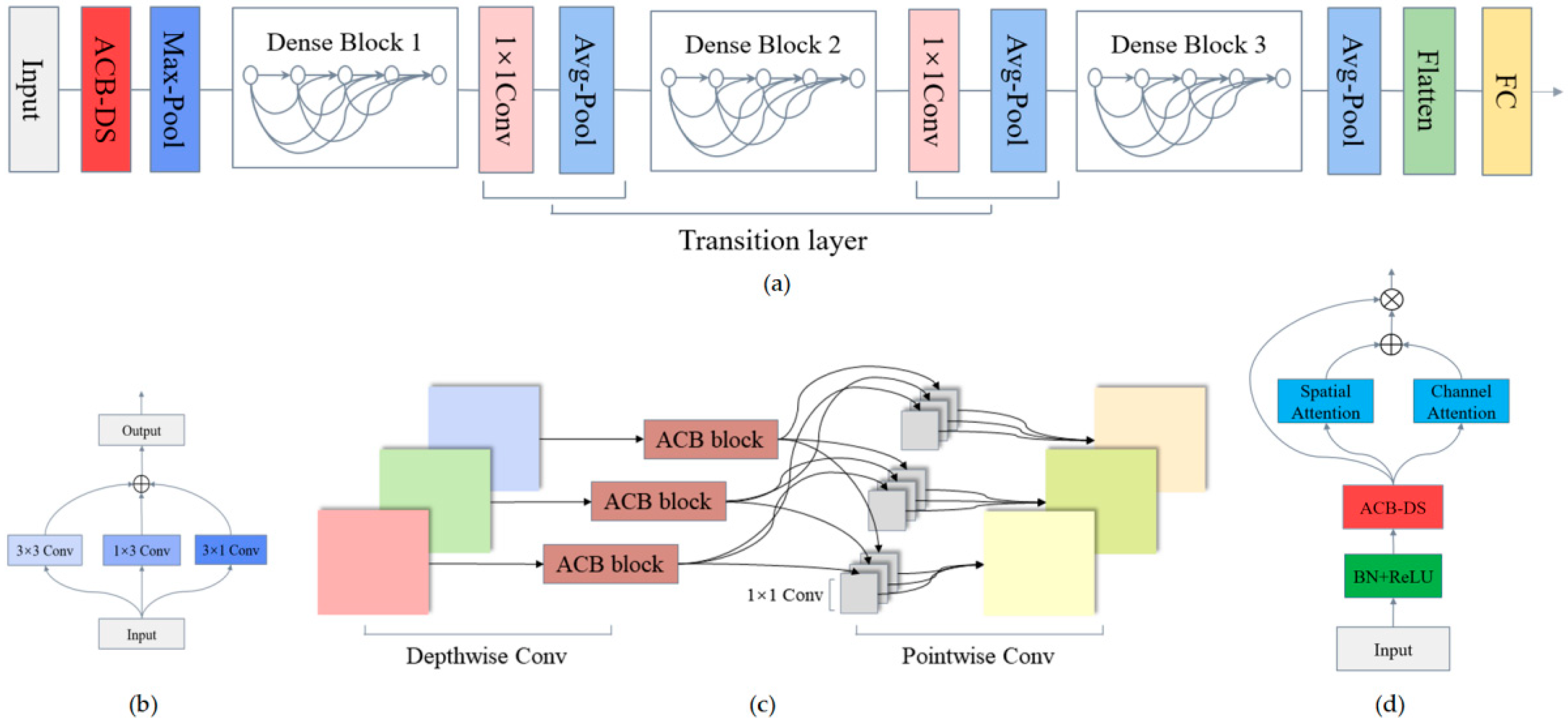
3.1. Description of the Proposed 3S-A2 DenseNet-BiLSTM
3.2. A2 DenseNet for Key Feature Extraction
3.3. BiLSTM for Extraction of Cross-Channel Context Features
3.4. Three-Stream Multimodal Feature Learning and Post-Fusion Strategy
3.5. Model Construction and Parameter Optimization
3.6. Accuracy Assessment Metrics
4. Results
4.1. Results of Parameter Optimization
4.2. Results of Accuracy Assessment
4.3. Results of Visual Prediction
- (1)
- Compared with Comparative Experiment 1, Comparative Experiment 2 introduces a parallel channel, spatial attention mechanism, and ACB-DS block, which proves the accuracy of 20 classes of land cover on a large scale for the first iteration.
- (2)
- Compared with Comparative Experiment 2, Comparative Experiment 3 adds BiLSTM based on A2 DenseNet, allowing the model to extract correlation information among the spectral channels. Therefore, the classification accuracy of fallow land, woodland, and shrubbery with similar spectral features was markedly improved for the second iteration.
- (3)
- Compared with Comparative Experiment 3, Comparative Experiment 4 introduces 106 dimensional low-level features and a multistream post-fusion strategy based on A2 DenseNet-BiLSTM. The features that were manually extracted cover the shortage of depth features extracted by the depth model in detail and have a higher resolution. Therefore, the accuracy of the 20 land cover classes was improved to a certain extent.
5. Discussion
5.1. Effectiveness of the Proposed 3S-A2 DenseNet-BiLSTM Model
- (1)
- 3S-A2 DenseNet-BiLSTM can learn the joint representation of low-level spectral–spatial, deep spectral–spatial, and deep topographic features. It can also capture the complete information of different emphases of the same object landscape under different imaging methods that cannot be perceived by a single form of data.
- (2)
- Compared with the classic DenseNet method, the A2 DenseNet module used the ACB-DS block and a double attention mechanism to extract more discriminative features. Simultaneously, the number of parameter calculations was reduced, and the speed of network convergence was accelerated. As the spatial regions of various ground objects are not always symmetrical, traditional symmetric convolution was not suitable for extracting the features of irregularly shaped land covers. However, the ACB-DS method solved the problem well, and was able to extract richer and more detailed spatial information.
- (3)
- BiLSTM was used to model the contextual features of correlations across different channels. It supplemented the global features extracted by A2 DenseNet and outputted more abundant spectral–spatial and topographic features, respectively.
- (4)
- A multistream post-fusion strategy was used to further fuse the low-level spectral–spatial features and multimodal deep features extracted by the A2 DenseNet-BiLSTM model. This strategy took full advantage of the spectral, spatial, and topographic information to obtain joint representations.
- (1)
- The model training time was too long. During the performance of the FLCC experiments, each model training process took approximately 30 h, which is unfavorable for the real-time monitoring of mining activities. A large amount of time hinders the process of industrializing the research. To assess the complexity of the model, both the performance of the model and the difficulty of training must be considered. On the one hand, the model must be as accurate as possible, which requires it to have a higher expression ability; therefore, it is easier to achieve this goal using a model with a higher complexity. On the other hand, if the complexity of the deep model is too high, it will increase the difficulty of training, thus wasting computing resources. Therefore, reducing the training time as much as possible without reducing the expression ability of the deep model requires further research.
- (2)
- An insufficient sample size was employed. For the data used for model training, only 2000 sample points were used for each class of land cover. For more complex deep models, the nonglobal features of the training data can be learned by the model. However, in the field of remote sensing, it is usually difficult and costly to obtain labeled data; thus, reducing the complexity of the model without reducing its classification accuracy requires further research.
- (3)
- The generalization performance is unknown. Normally, many illegal mining activities may be carried out at night; however, the current study only monitored mining activities during the day. The performance of the model on remote sensing satellite images at night still requires further transfer learning research.
5.2. Effects of Different Models
- (1)
- Open pit, bare surface land, fallow land, woodland, and shrubbery have relatively similar spectral features, but neither the DBN-based model nor the 3M-CNN-Magnify considers the contextual correlation among spectral bands. Accordingly, it is impossible to distinguish between land covers with similar spectral features and visually similar colors.
- (2)
- The DBN-based model classifies dark roads into land covers that are similar to this class in terms of geographical space. Although they do not have similar spectral features, the dark road passes through bare surface land and open pits. 3M-CNN-Magnify uses a multiscale kernel-based convolution block, which can select different convolution kernel sizes according to the multi-size data input, making full use of spatial neighborhood information. The proposed 3S-A2 DenseNet-BiLSTM model introduces an ACB-DS block, which can extract the features of irregularly shaped land covers, making the extracted spatial features more abundant. However, DBN-S and DBN-SVM do not have a structure that is more conducive to the extraction of spatial features; thus, they cannot distinguish land covers with strong spatial correlation.
- (3)
- All models confuse the three classes of land cover: fallow land, woodland, and shrubbery; this may be due to the small spectral differences between them. Moreover, it is difficult to perform visual distinction; however, their height difference is large. Therefore, the model can only extract the discriminative features according to the topographic height difference of the DEM data. However, the 3S-A2 DenseNet-BiLSTM model only extracts the neighborhood size of topographic data instead of a complete image, which may weaken the advantage of topographic information.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hussain, S.; Mubeen, M.; Ahmad, A.; Majeed, H.; Qaisrani, S.A.; Hammad, H.M.; Amjad, M.; Ahmad, I.; Fahad, S.; Ahmad, N.; et al. Assessment of land use/land cover changes and its effect on land surface temperature using remote sensing techniques in Southern Punjab, Pakistan. Environ. Sci. Pollut. Res. 2022, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Wang, Y.; Li, X.; Zou, Y.; Liao, Y.; Yang, J. Land use/land cover change and driving effects of water environment system in Dunhuang Basin, northwestern China. Environ. Earth Sci. 2016, 75, 1027. [Google Scholar] [CrossRef]
- Wang, S.; Lu, X.; Chen, Z.; Zhang, G.; Ma, T.; Jia, P.; Li, B. Evaluating the feasibility of illegal open-pit mining identification using insar coherence. Remote Sens. 2020, 12, 367. [Google Scholar] [CrossRef]
- Pan, Z.-W.; Shen, H.-L. Multispectral image super-resolution via RGB image fusion and radiometric calibration. IEEE Trans. Image Process. 2018, 28, 1783–1797. [Google Scholar] [CrossRef]
- Wang, C.; Guo, Z.; Wang, S.; Wang, L.; Ma, C. Improving hyperspectral image classification method for fine land use assessment application using semisupervised machine learning. J. Spectrosc. 2015, 2015, 969185. [Google Scholar] [CrossRef]
- Li, X.; Chen, G.; Liu, J.; Chen, W.; Cheng, X.; Liao, Y. Effects of RapidEye imagery’s red-edge band and vegetation indices on land cover classification in an arid region. Chin. Geogr. Sci. 2017, 27, 827–835. [Google Scholar] [CrossRef]
- Qian, M.; Sun, S.; Li, X. Multimodal Data and Multiscale Kernel-Based Multistream CNN for Fine Classification of a Complex Surface-Mined Area. Remote Sens. 2021, 13, 5052. [Google Scholar] [CrossRef]
- Wu, C.; Li, X.; Chen, W.; Li, X. A review of geological applications of high-spatial-resolution remote sensing data. J. Circuits Syst. Comput. 2020, 29, 2030006. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction From High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Chen, W.; Cheng, X.; Liao, Y.; Chen, G. Comparison and integration of feature reduction methods for land cover classifi-cation with RapidEye imagery. Multimed. Tools Appl. 2017, 76, 23041–23057. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1330. [Google Scholar] [CrossRef]
- Zhou, G.; Chen, W.; Gui, Q.; Li, X.; Wang, L. Split Depth-Wise Separable Graph-Convolution Network for Road Extraction in Complex Environments from High-Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614115. [Google Scholar] [CrossRef]
- Zheng, H.; Shen, L.; Jia, S. Joint spatial and spectral analysis for remote sensing image classification. MIPPR 2011 Multispectral Image Acquis. Process. Anal. 2011, 8002, 352–356. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, J.; Liu, P.; Choo, K.-K.R.; Huang, F. Spectral–spatial multi-feature-based deep learning for hyperspectral remote sensing image classification. Soft Comput. 2017, 21, 213–221. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; He, H.; Wang, L. A Review of Fine-Scale Land Use and Land Cover Classification in Open-Pit Mining Areas by Remote Sensing Techniques. Remote Sens. 2018, 10, 15. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; He, H.; Wang, L. Assessing Different Feature Sets’ Effects on Land Cover Classification in Complex Sur-face-Mined Landscapes by ZiYuan-3 Satellite Imagery. Remote Sens. 2018, 10, 23. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Wang, X.; Guo, Y.; He, J.; Du, L. Fusion of HJ1B and ALOS PALSAR data for land cover classification using machine learning methods. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 192–203. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Liu, J.; Xiang, J.; Jin, Y.; Liu, R.; Yan, J.; Wang, L. Boost Precision Agriculture with Unmanned Aerial Vehicle Remote Sensing and Edge Intelligence: A Survey. Remote Sens. 2021, 13, 4387. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P. Joint Deep Learning for land cover and land use classi-fication. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef]
- Li, X.; Tang, Z.; Chen, W.; Wang, L. Multimodal and Multi-Model Deep Fusion for Fine Classification of Regional Complex Landscape Areas Using ZiYuan-3 Imagery. Remote Sens. 2019, 11, 2716. [Google Scholar] [CrossRef]
- Li, M.; Tang, Z.; Tong, W.; Li, X.; Chen, W.; Wang, L. A multi-level output-based dbn model for fine classification of complex geo-environments area using ziyuan-3 TMS Imagery. Sensors 2021, 21, 2089. [Google Scholar] [CrossRef] [PubMed]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Xu, S.; Mu, X.; Zhao, P.; MA, J. Scene classification of remote sensing image based on multi-scale feature and deep neural network. Acta Geod. Cartogr. Sin. 2016, 45, 834. [Google Scholar]
- Chen, W.; Zhou, G.; Liu, Z.; Li, X.; Zheng, X.; Wang, L. NIGAN: A Framework for Mountain Road Extraction Integrating Remote Sensing Road-Scene Neighborhood Probability Enhancements and Improved Conditional Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5626115. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tao, Y.; Xu, M.; Lu, Z.; Zhong, Y. DenseNet-based depth-width double reinforced deep learning neural network for high-resolution remote sensing image per-pixel classification. Remote Sens. 2018, 10, 779. [Google Scholar] [CrossRef]
- Li, F.; Feng, R.; Han, W.; Wang, L. High-resolution remote sensing image scene classification via key filter bank based on con-volutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8077–8092. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. Convolutional neural networks for multimodal remote sensing data classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5517010. [Google Scholar] [CrossRef]
- Hang, R.; Li, Z.; Ghamisi, P.; Hong, D.; Xia, G.; Liu, Q. Classification of hyperspectral and LIDAR data using coupled CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4939–4950. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Gao, Y.; Li, W.; Zhang, M.; Wang, J.; Sun, W.; Tao, R.; Du, Q. Hyperspectral and multispectral classification for coastal wetland using depthwise feature interaction network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5512615. [Google Scholar] [CrossRef]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A deep translation (GAN) based change detection network for optical and SAR remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- Zhang, F.; Bai, J.; Zhang, J.; Xiao, Z.; Pei, C. An optimized training method for GAN-based hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1791–1795. [Google Scholar] [CrossRef]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L.; Zhang, F. A Band grouping based LSTM algorithm for hyperspectral image classification. In Proceedings of the CCF Chinese Conference on Computer Vision, Tianjin, China, 11–14 October 2017; pp. 421–432. [Google Scholar] [CrossRef]
- Zhou, F.; Hang, R.; Liu, Q.; Yuan, X. Hyperspectral image classification using spectral-spatial LSTMs. Neurocomputing 2019, 328, 39–47. [Google Scholar] [CrossRef]
- Yin, J.; Qi, C.; Chen, Q.; Qu, J. Spatial-Spectral Network for Hyperspectral Image Classification: A 3-D CNN and Bi-LSTM Framework. Remote Sens. 2021, 13, 2353. [Google Scholar] [CrossRef]
- Chen, W.; Ouyang, S.; Tong, W.; Li, X.; Zheng, X.; Wang, L. GCSANet: A global context spatial attention deep learning network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1150–1162. [Google Scholar] [CrossRef]
- Chen, W.; Ouyang, S.; Yang, J.; Li, X.; Zhou, G.; Wang, L. JAGAN: A Framework for Complex Land Cover Classification Using Gaofen-5 AHSI Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1591–1603. [Google Scholar] [CrossRef]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Sumbul, G.; Demİr, B. A deep multi-attention driven approach for multi-label remote sensing image classification. IEEE Access 2020, 8, 95934–95946. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Wei, Y.; Chen, Z.; Xie, P. Water Body Extraction from Sentinel-3 Image with Multiscale Spatiotemporal Super-Resolution Mapping. Water 2020, 12, 2605. [Google Scholar] [CrossRef]
- Waleed, M.; Mubeen, M.; Ahmad, A.; Habib-ur-Rahman, M.; Amin, A.; Farid, H.U.; Hussain, S.; Ali, M.; Qaisrani, S.A.; Nasim, W.; et al. Evaluating the efficiency of coarser to finer resolution multi-spectral satellites in mapping paddy rice fields using GEE implementation. Sci. Rep. 2020, 12, 13210. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Chen, W.; Cheng, X.; Wang, L. A comparison of machine learning algorithms for mapping of complex surface-mined and agricultural landscapes using ZiYuan-3 stereo satellite imagery. Remote Sens. 2016, 8, 514. [Google Scholar] [CrossRef]
- Guan, R.; Li, Z.; Li, T.; Li, X.; Yang, J.; Chen, W. Classification of Heterogeneous Mining Areas Based on ResCapsNet and Gaofen-5 Imagery. Remote Sens. 2022, 14, 3216. [Google Scholar] [CrossRef]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Mei, X.; Pan, E.; Ma, Y.; Dai, X.; Huang, J.; Fan, F.; Du, Q.; Zheng, H.; Ma, J. Spectral-spatial attention networks for hyperspectral image classification. Remote Sens. 2019, 11, 963. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Wang, C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; p. 28. [Google Scholar]
- Lo, S.-Y.; Hang, H.-M.; Chan, S.-W.; Lin, J.-J. Efficient dense modules of asymmetric convolution for real-time semantic segmentation. In Proceedings of the 2019 ACM Multimedia Asia, Beijing, China, 15–18 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Y.; Xie, L.; Qiao, S.; Zhang, Y.; Zhang, W.; Yuille, A.L. Multi-scale spatially-asymmetric recalibration for image classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 523–539. [Google Scholar] [CrossRef]
- Zhu, M.; Fan, J.; Yang, Q.; Chen, T. SC-EADNet: A Self-Supervised Contrastive Efficient Asymmetric Dilated Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5519517. [Google Scholar] [CrossRef]
- Wang, L.; Peng, J.; Sun, W. Spatial–spectral squeeze-and-excitation residual network for hyperspectral image classification. Remote Sens. 2019, 11, 884. [Google Scholar] [CrossRef]
- Roy, S.K.; Dubey, S.R.; Chatterjee, S.; Chaudhuri, B.B. FuSENet: Fused squeeze-and-excitation network for spectral-spatial hy-perspectral image classification. IET Image Process. 2020, 14, 1653–1661. [Google Scholar] [CrossRef]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent spatial and channel ‘squeeze & excitation’ in fully convolutional networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 421–429. [Google Scholar]
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ding, Q. Multiple feature reweight densenet for image classification. IEEE Access 2019, 7, 9872–9880. [Google Scholar] [CrossRef]
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ma, Z.; Zhao, Z. Channel-wise and feature-points reweights densenet for image classifi-cation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 410–414. [Google Scholar]
- Liu, C.; Tao, R.; Li, W.; Zhang, M.; Sun, W.; Du, Q. Joint classification of hyperspectral and multispectral images for mapping coastal wetlands. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 982–996. [Google Scholar] [CrossRef]
- Ge, C.; Gu, I.Y.; Jakola, A.S.; Yang, J. Deep learning and multi-sensor fusion for glioma classification using multistream 2D con-volutional networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 5894–5897. [Google Scholar]
- Kwan, C.; Gribben, D.; Ayhan, B.; Li, J.; Bernabe, S.; Plaza, A. An accurate vegetation and non-vegetation differentiation approach based on land cover classification. Remote Sens. 2020, 12, 3880. [Google Scholar] [CrossRef]
- Goldblatt, R.; You, W.; Hanson, G.; Khandelwal, A.K. Detecting the boundaries of urban areas in India: A dataset for pixel-based image classification in google earth engine. Remote Sens. 2016, 8, 634. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, X.; Ding, C.; Liu, S.; Wu, C.; Wu, L. Mapping rice paddies in complex landscapes with convolutional neural net-works and phenological metrics. Gisci. Remote Sens. 2019, 57, 37–48. [Google Scholar] [CrossRef]
- Li, K.; Yu, N.; Li, P.; Song, S.; Wu, Y.; Li, Y.; Liu, M. Multi-label spacecraft electrical signal classification method based on DBN and random forest. PLoS ONE 2017, 12, e0176614. [Google Scholar] [CrossRef]
- Jiang, M.; Liang, Y.; Feng, X.; Fan, X.; Pei, Z.; Xue, Y.; Guan, R. Text classification based on deep belief network and softmax regression. Neural Comput. Appl. 2016, 29, 61–70. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Z.; Ma, S.; Lu, S.; Zhang, H.; Ding, G.; Li, S. Deep learning for signal demodulation in physical layer wireless communications: Prototype platform, open dataset, and analytics. IEEE Access 2019, 7, 30792–30801. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First-Level Land Cover Type | Second-Level Land Cover Type | Description |
|---|---|---|
| Mining land | Open pit Ore processing site Dumping ground | An ore deposit formed by stripping the soil and rock covering the upper part of the ore body A factory that processes ore A place where mining wastes are discharged in a centralized manner |
| Farmland | Paddy Greenhouse Green dry land Fallow land | Cultivated land for planting rice Facilities that can transmit light and keep warm, which are used to cultivate plants Cultivated land not planted with rice Uncultivated land |
| Woodland | Woodland Shrubbery Coerced forest Nursery | Tall macrophanerophytes Low vegetation Vegetation with restricted growth Economic trees artificially cultivated in nurseries and orchards |
| Waters | Pond and stream Mine pit pond | Natural waters A place where groundwater is discharged during mining |
| Road | Dark road Light gray road Bright road | Asphalt driveway Dirt road Cement road |
| Residential land | Blue roof White roof Red roof | Urban land Land for rural residents Other construction land |
| Unused land | Bare surface land |
| Feature Parameter Type | Feature Parameter Name | Number |
|---|---|---|
| Spectral features | Spectral bands | 4 |
| Principal component features | First and second principal components of spectral bands | 2 |
| Vegetation index | Normalized vegetation index eliminating, with the difference between the two channel reflectors | 1 |
| Filter features | Gaussian low-pass, mean, and standard deviation filtering in the spectral band with a core size of 3 × 3, 5 × 5, and 7 × 7 pixels | 36 |
| Texture features | Gray level co-occurrence matrix texture in the spectral band, including the contrast, correlation, angular second moment, homogeneity and entropy. Core size 3 × 3, 5 × 5, and 7 × 7 pixels | 60 |
| Topographic features | DEM, slope, aspect | 3 |
| Comparative Experiment 1 | Other Experiments | ||
|---|---|---|---|
| DenseNet depth | DenseNet121 | ACB-DS | 1, 2, 3, 4 |
| DenseNet161 | Convergent epoch | 1–200 | |
| DenseNet169 | Fully connected layer | 1, 2, 3 | |
| DenseNet201 | |||
| Convergent epoch | 1–200 | ||
| Fully connected layer | 1, 2, 3 | ||
| Experiment | F1-Score | Kappa | OA |
|---|---|---|---|
| Comparative Experiment 1 | 94.82 ± 0.04 | 94.56 ± 0.04 | 94.83 ± 0.04 |
| Comparative Experiment 2 | 97.13 ± 0.29 | 96.99 ± 0.30 | 97.14 ± 0.28 |
| Comparative Experiment 3 | 97.69 ± 0.08 | 97.57 ± 0.08 | 97.70 ± 0.08 |
| Overall Experiment | 98.65 ± 0.05 | 98.65 ± 0.05 | 98.65 ± 0.05 |
| Class | Overall Experiment | Comparative Experiment 1 | Comparative Experiment 2 | Comparative Experiment 3 |
|---|---|---|---|---|
| Open pit | 99.75 ± 0.22 | 95.80 ± 0.20 | 97.90 ± 1.02 | 97.90 ± 0.50 |
| Ore processing site | 99.45 ± 0.09 | 92.92 ± 0.28 | 97.35 ± 1.17 | 98.20 ± 0.20 |
| Dumping ground | 99.70 ± 0.17 | 96.90 ± 0.10 | 99.20 ± 0.14 | 99.20 ± 0.00 |
| Paddy | 99.75 ± 0.09 | 96.20 ± 0.20 | 98.75 ± 0.70 | 99.00 ± 0.20 |
| Greenhouse | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.55 ± 0.09 | 100.00 ± 0.00 |
| Green dry land | 99.35 ± 0.22 | 93.20 ± 2.00 | 96.85 ± 1.19 | 96.90 ± 0.10 |
| Fallow land | 96.90 ± 0.59 | 87.70 ± 0.10 | 91.80 ± 2.78 | 94.00 ± 0.60 |
| Woodland | 95.30 ± 0.30 | 90.80 ± 0.20 | 92.20 ± 1.07 | 93.00 ± 0.20 |
| Shrubbery | 92.35 ± 0.52 | 80.30 ± 0.70 | 86.90 ± 2.34 | 89.70 ± 0.10 |
| Coerced forest | 99.55 ± 0.09 | 96.20 ± 0.00 | 99.00 ± 0.45 | 99.00 ± 0.00 |
| Nursery | 98.20 ± 0.62 | 90.70 ± 2.10 | 96.85 ± 1.36 | 98.40 ± 0.20 |
| Pond and stream | 99.15 ± 0.41 | 95.40 ± 0.20 | 98.35 ± 0.57 | 99.10 ± 0.10 |
| Mine pit pond | 100.00 ± 0.00 | 99.90 ± 0.10 | 99.85 ± 0.09 | 99.80 ± 0.00 |
| Dark road | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.70 ± 0.17 | 100.00 ± 0.00 |
| Light gray road | 99.70 ± 0.17 | 97.10 ± 0.50 | 98.50 ± 0.71 | 98.80 ± 0.20 |
| Bright road | 99.95 ± 0.09 | 98.70 ± 0.50 | 98.75 ± 0.80 | 99.60 ± 0.20 |
| Blue roof | 99.80 ± 0.00 | 99.10 ± 0.10 | 99.75 ± 0.09 | 99.70 ± 0.10 |
| White roof | 94.85 ± 0.43 | 91.80 ± 0.40 | 94.50 ± 1.68 | 93.40 ± 0.20 |
| Red roof | 99.75 ± 0.09 | 97.40 ± 0.40 | 99.55 ± 0.26 | 99.50 ± 0.10 |
| Bare surface land | 99.55 ± 0.17 | 96.50 ± 0.30 | 97.15 ± 2.17 | 98.70 ± 0.10 |
| Model | F1-Score | Kappa | OA | Description |
|---|---|---|---|---|
| 3S-A2 DenseNet-BiLSTM | 98.65 ± 0.05 | 98.65 ± 0.05 | 98.65 ± 0.05 | The proposed network |
| Single-scale CNN [7] | 93.76 ± 0.76 | Multimodal and single-scale kernel-based multistream CNN | ||
| 3M-CNN [7] | 95.11 ± 0.48 | Multimodal and multiscale kernel-based multistream CNN | ||
| 3M-CNN-Magnify [7] | 96.60 ± 0.22 | Multimodal and multiscale kernel-based multistream CNN with the selected parameter value | ||
| DBN-ML [24] | 95.07 | 94.84 | 95.10 | Multi-level output-based deep belief network |
| RF [23] | 88.85 ± 0.22 | 88.31 ± 0.22 | 88.90 ± 0.20 | Random forest |
| SVM [23] | 77.79 ± 0.54 | 76.72 ± 0.55 | 77.88 ± 0.53 | Support vector machine |
| FS-SVM [23] | 91.75 ± 0.57 | 91.34 ± 0.60 | 91.77 ± 0.57 | SVM with feature fusion method |
| DBN-S [23] | 94.22 ± 0.67 | 93.93 ± 0.70 | 94.23 ± 0.67 | DBN with Softmax classifier |
| DBN-RF [23] | 94.05 ± 0.34 | 93.76 ± 0.36 | 94.07 ± 0.34 | DBN with feature fusion method |
| DBN-SVM [23] | 94.72 ± 0.35 | 94.46 ± 0.37 | 94.74 ± 0.35 | DBN with SVM classifier |
| CNN [24] | 90.15 ± 1.66 | 89.68 ± 1.75 | 90.20 ± 1.64 | VGG network |
| DCNN [24] | 95.00 | 94.76 | 95.02 | VGG with deformable convolutions |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Leng, J.; Li, X.; He, W.; Chen, W. Three-Stream and Double Attention-Based DenseNet-BiLSTM for Fine Land Cover Classification of Complex Mining Landscapes. Sustainability 2022, 14, 12465. https://doi.org/10.3390/su141912465
Zhang D, Leng J, Li X, He W, Chen W. Three-Stream and Double Attention-Based DenseNet-BiLSTM for Fine Land Cover Classification of Complex Mining Landscapes. Sustainability. 2022; 14(19):12465. https://doi.org/10.3390/su141912465
Chicago/Turabian StyleZhang, Diya, Jiake Leng, Xianju Li, Wenxi He, and Weitao Chen. 2022. "Three-Stream and Double Attention-Based DenseNet-BiLSTM for Fine Land Cover Classification of Complex Mining Landscapes" Sustainability 14, no. 19: 12465. https://doi.org/10.3390/su141912465