




Water Quality Prediction Based on LSTM and Attention Mechanism: A Case Study of the Burnett River, Australia
 ,
,
Abstract
:1. Introduction
2. Data Source and Pre-Processing
2.1. Study Area and the Data
2.2. Missing Value Processing
2.3. Water Quality Correlation Analysis
2.4. Outlier Detection
2.5. Data Normalization
2.6. Time Series Conversion to Supervised Data
3. Theoretical Foundation and Model Construction
3.1. Long Short-Term Memory Neural Network
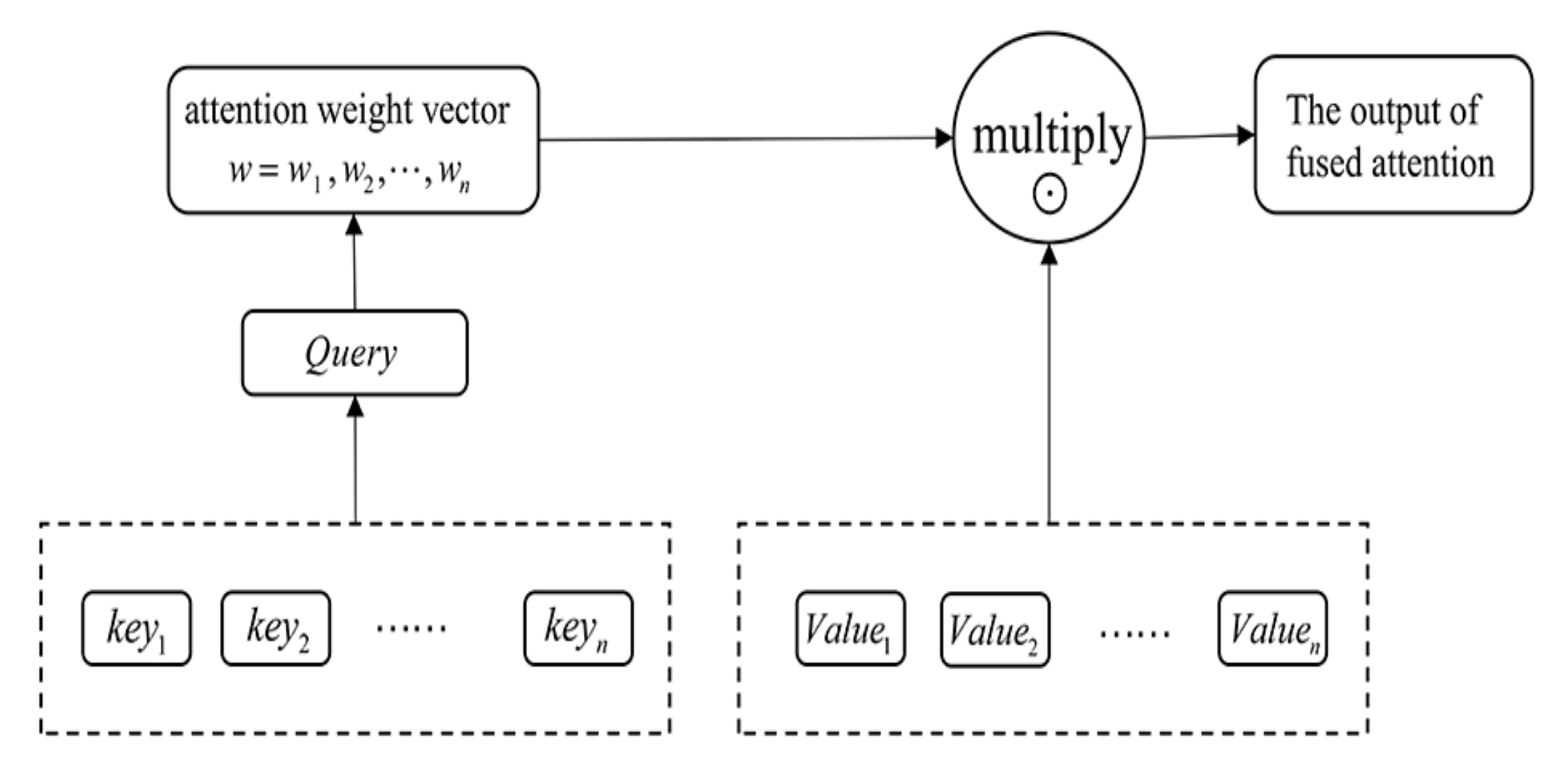
3.2. Attention Mechanism
3.3. Model Establishment
3.4. Performance Criteria
3.5. Experimental Environment
4. Results and Discussion
4.1. Comparisons of One-Step-Ahead Forecast Using LSTM and AT-LSTM Models
4.2. Comparisons of Multistep Forecasting Using the LSTM and AT-LSTM Models
4.3. Model Verification
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ho, J.Y.; Afan, H.A.; El-Shafie, A.H.; Koting, S.B.; Mohd, N.S.; Jaafar, W.Z.B.; Hin, L.S.; Malek, M.A.; Ahmed, A.N.; Melini, W.H.; et al. Towards a time and cost effective approach to water quality index class prediction. J. Hydrol. 2019, 575, 148–165. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, J.; Chen, Y.; Li, X.; Xie, Y. Water Quality Prediction Method Based on Multi-Source Transfer Learning for Water Environmental IoT System. Sensors 2021, 21, 7271. [Google Scholar] [CrossRef] [PubMed]
- Liu, P.; Wang, J.; Sangaiah, A.K.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef] [Green Version]
- Duan, W.; He, B.; Chen, Y.; Zou, S.; Wang, Y.; Nover, D.; Chen, W.; Yang, G. Identification of long-term trends and seasonality in high-frequency water quality data from the Yangtze River basin, China. PLoS ONE 2018, 13, e0188889. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.N.; Li, D.L.; He, D.X.; Wang, J.Q.; Ma, D.K.; Li, F.F. A remote wireless system for water quality online monitoring in intensive fish culture. Comput. Electron. Agric. 2010, 71, S3–S9. [Google Scholar] [CrossRef]
- Koklu, R.; Sengorur, B.; Topal, B. Water Quality Assessment Using Multivariate Statistical Methods—A Case Study: Melen River System (Turkey). Water Resour. Manag. 2010, 24, 959–978. [Google Scholar] [CrossRef]
- Ömer Faruk, D. A hybrid neural network and ARIMA model for water quality time series prediction. Eng. Appl. Artif. Intell. 2010, 23, 586–594. [Google Scholar] [CrossRef]
- Kadam, A.K.; Wagh, V.M.; Muley, A.A.; Umrikar, B.N.; Sankhua, R.N. Prediction of water quality index using artificial neural network and multiple linear regression modelling approach in Shivganga River basin, India. Model. Earth Syst. Environ. 2019, 5, 951–962. [Google Scholar] [CrossRef]
- Valentini, M.; dos Santos, G.B.; Muller Vieira, B. Multiple linear regression analysis (MLR) applied for modeling a new WQI equation for monitoring the water quality of Mirim Lagoon, in the state of Rio Grande do Sul—Brazil. SN Appl. Sci. 2021, 3, 70. [Google Scholar] [CrossRef]
- Liu, S.; Tai, H.; Ding, Q.; Li, D.; Xu, L.; Wei, Y. A hybrid approach of support vector regression with genetic algorithm optimization for aquaculture water quality prediction. Math. Comput. Model. 2013, 58, 458–465. [Google Scholar] [CrossRef]
- Candelieri, A. Clustering and support vector regression for water demand forecasting and anomaly detection. Water 2017, 9, 224. [Google Scholar] [CrossRef] [Green Version]
- Granata, F.; Papirio, S.; Esposito, G.; Gargano, R.; De Marinis, G. Machine learning algorithms for the forecasting of wastewater quality indicators. Water 2017, 9, 105. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.P.; Basant, A.; Malik, A.; Jain, G. Artificial neural network modeling of the river water quality—A case study. Ecol. Model. 2009, 220, 888–895. [Google Scholar] [CrossRef]
- Sundarambal, P.; Liong, S.-Y.; Tkalich, P.; Palanichamy, J. Development of a neural network model for dissolved oxygen in seawater. Indian J. Mar. Sci. 2009, 38, 151–159. [Google Scholar]
- Li, C.; Li, Z.; Wu, J.; Zhu, L.; Yue, J. A hybrid model for dissolved oxygen prediction in aquaculture based on multi-scale features. Inf. Processing Agric. 2018, 5, 11–20. [Google Scholar] [CrossRef]
- Barzegar, R.; Adamowski, J.; Moghaddam, A.A. Application of wavelet-artificial intelligence hybrid models for water quality prediction: A case study in Aji-Chay River, Iran. Stoch. Environ. Res. Risk Assess. 2016, 30, 1797–1819. [Google Scholar] [CrossRef]
- Wu, G.-D.; Lo, S.-L. Predicting real-time coagulant dosage in water treatment by artificial neural networks and adaptive network-based fuzzy inference system. Eng. Appl. Artif. Intell. 2008, 21, 1189–1195. [Google Scholar] [CrossRef]
- Hirsch, R.M.; Slack, J.R.; Smith, R.A. Techniques of trend analysis for monthly water quality data. Water Resour. Res. 1982, 18, 107–121. [Google Scholar] [CrossRef] [Green Version]
- Medsker, L.R.; Jain, L. Recurrent neural networks. Des. Appl. 2001, 5, 64–67. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Pulver, A.; Lyu, S. LSTM with Working Memory. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: New York City, NY, USA, 2017; pp. 845–851. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Andersen, R.S.; Peimankar, A.; Puthusserypady, S. A deep learning approach for real-time detection of atrial fibrillation. Expert Syst. Appl. 2019, 115, 465–473. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, J.; Chen, K.; Wang, Y.; Liu, L. Water quality prediction method based on LSTM neural network. In Proceedings of the 2017 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017; pp. 1–5. [Google Scholar]
- Hu, Z.; Zhang, Y.; Zhao, Y.; Xie, M.; Zhong, J.; Tu, Z.; Liu, J. A water quality prediction method based on the deep LSTM network considering correlation in smart mariculture. Sensors 2019, 19, 1420. [Google Scholar] [CrossRef] [Green Version]
- Ye, Q.; Yang, X.; Chen, C.; Wang, J. River water quality parameters prediction method based on LSTM-RNN model. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; IEEE: New York City, NY, USA, 2019; pp. 3024–3028. [Google Scholar]
- Barzegar, R.; Aalami, M.T.; Adamowski, J. Short-term water quality variable prediction using a hybrid CNN–LSTM deep learning model. Stoch. Environ. Res. Risk Assess. 2020, 34, 415–433. [Google Scholar] [CrossRef]
- Baek, S.-S.; Pyo, J.; Chun, J.A. Prediction of Water Level and Water Quality Using a CNN-LSTM Combined Deep Learning Approach. Water 2020, 12, 3399. [Google Scholar] [CrossRef]
- Sha, J.; Li, X.; Zhang, M.; Wang, Z.-L. Comparison of Forecasting Models for Real-Time Monitoring of Water Quality Parameters Based on Hybrid Deep Learning Neural Networks. Water 2021, 13, 1547. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Ma, F.; Chitta, R.; Zhou, J.; You, Q.; Sun, T.; Gao, J. Dipole: Diagnosis prediction in healthcare via attention-based bidirectional recurrent neural networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1903–1911. [Google Scholar]
- Gatt, A.; Krahmer, E. Survey of the state of the art in natural language generation: Core tasks, applications and evaluation. J. Artif. Intell. Res. 2018, 61, 65–170. [Google Scholar] [CrossRef] [Green Version]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing [Review Article]. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Galassi, A.; Lippi, M.; Torroni, P. Attention in Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4291–4308. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30, 5998–6008. [Google Scholar]
- Britz, D.; Goldie, A.; Luong, M.-T.; Le, Q. Massive exploration of neural machine translation architectures. arXiv 2017, 1442–1451. arXiv:1703.03906. [Google Scholar]
- Strubell, E.; Verga, P.; Andor, D.; Weiss, D.; McCallum, A. Linguistically-informed self-attention for semantic role labeling. arXiv 2018, 5027–5038. arXiv:1804.08199. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What does bert look at? an analysis of bert’s attention. arXiv 2019, arXiv:1906.04341. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Cho, K.; Bengio, Y. End-to-end continuous speech recognition using attention-based recurrent NN: First results. arXiv 2014, arXiv:1412.1602. [Google Scholar]
- Zeyer, A.; Irie, K.; Schlüter, R.; Ney, H. Improved training of end-to-end attention models for speech recognition. arXiv 2018, arXiv:1805.03294. [Google Scholar]
- Song, H.; Rajan, D.; Thiagarajan, J.; Spanias, A. Attend and diagnose: Clinical time series analysis using attention models. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Tran, D.T.; Iosifidis, A.; Kanniainen, J.; Gabbouj, M. Temporal Attention-Augmented Bilinear Network for Financial Time-Series Data Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1407–1418. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Zhang, Y.; Yang, L.; Liu, Q.; Yan, K.; Du, Y. Short-Term Photovoltaic Power Forecasting Based on Long Short Term Memory Neural Network and Attention Mechanism. IEEE Access 2019, 7, 78063–78074. [Google Scholar] [CrossRef]
- Hipel, K.W.; McLeod, A.I. Time Series Modelling of Water Resources and Environmental Systems; Elsevier: Amsterdam, The Netherlands, 1994. [Google Scholar]
- Zhang, Q.; Wang, R.; Qi, Y.; Wen, F. A watershed water quality prediction model based on attention mechanism and Bi-LSTM. Environ. Sci. Pollut. Res. Int. 2022, 29, 75664–75680. [Google Scholar] [CrossRef]
- Lee Rodgers, J.; Nicewander, W.A. Thirteen Ways to Look at the Correlation Coefficient. Am. Stat. 1988, 42, 59–66. [Google Scholar] [CrossRef]
- Chambers, J.M.; Cleveland, W.S.; Kleiner, B.; Tukey, P.A. Graphical Methods for Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]
- Rathnayake, D.; Perera, P.B.; Eranga, H.; Ishwara, M. Generalization of LSTM CNN ensemble profiling method with time-series data normalization and regularization. In Proceedings of the 2021 21st International Conference on Advances in ICT for Emerging Regions (ICter), Colombo, Sri Lanka, 2–3 December 2021; pp. 1–6. [Google Scholar]
- Shin, H.H.; Stieb, D.M.; Jessiman, B.; Goldberg, M.S.; Brion, O.; Brook, J.; Ramsay, T.; Burnett, R.T. A temporal, multicity model to estimate the effects of short-term exposure to ambient air pollution on health. Environ. Health Perspect. 2008, 116, 1147–1153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salehinejad, H.; Sankar, S.; Barfett, J.; Colak, E.; Valaee, S. Recent advances in recurrent neural networks. arXiv 2017, arXiv:1801.01078. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; Zhang, C. DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding. In Proceedings of the AAAI’18: AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temp (°C) | EC (uS·cm−1) | pH | DO (mg·L−1) | Turbidity (NTU) | Chl-a (ug·L−1) | |
|---|---|---|---|---|---|---|
| Count | 39,601 | 39,752 | 39,752 | 39,752 | 39,752 | 39,752 |
| Mean | 24.31 | 37,536.07 | 7.86 | 6.63 | 14.96 | 9.23 |
| Standard deviation | 3.69 | 13,618.6 | 0.69 | 0.98 | 44.77 | 28.93 |
| Temp | EC | pH | DO | Turbidity | Chl-a | |
|---|---|---|---|---|---|---|
| Temp | 1 | −0.247 | −0.153 | −0.411 | 0.248 | 0.403 |
| EC | −0.247 | 1 | 0.056 | −0.091 | −0.453 | −0.301 |
| pH | −0.153 | 0.056 | 1 | 0.430 | −0.085 | 0.054 |
| DO | −0.411 | −0.091 | 0.430 | 1 | 0.053 | 0.209 |
| Turbidity | 0.248 | −0.453 | −0.085 | −0.053 | 1 | 0.468 |
| Chl-a | 0.403 | −0.301 | 0.054 | 0.209 | 0.468 | 1 |
| Layers | Output Shape | Hidden Dimension |
|---|---|---|
| Input layer | (64, 100, 4) | |
| LSTM | (64, 100, 100) | 100 |
| Dense | (64, 100, 100) | 100 |
| Activation (softmax) | (64, 100, 100) | |
| Multiply | (64, 100, 100) | |
| Flatten | (64, 10000) | |
| Dense | (64, 1) | 1 |
| Activation (sigmoid) | (64, 1) |
| Models | RMSE | MAE | R2 |
|---|---|---|---|
| LSTM | 0.171 | 0.130 | 0.918 |
| AT-LSTM | 0.130 | 0.094 | 0.953 |
| Time (Hour) | RMSE | MAE | R2 | |||
|---|---|---|---|---|---|---|
| LSTM | AT-LSTM | LSTM | AT-LSTM | LSTM | AT-LSTM | |
| 4 | 0.229 | 0.201 | 0.178 | 0.152 | 0.853 | 0.887 |
| 8 | 0.271 | 0.238 | 0.212 | 0.178 | 0.794 | 0.841 |
| 12 | 0.295 | 0.228 | 0.232 | 0.173 | 0.757 | 0.854 |
| 16 | 0.297 | 0.229 | 0.234 | 0.171 | 0.753 | 0.853 |
| 20 | 0.317 | 0.254 | 0.248 | 0.191 | 0.719 | 0.820 |
| 24 | 0.335 | 0.263 | 0.267 | 0.194 | 0.686 | 0.806 |
| 28 | 0.365 | 0.346 | 0.280 | 0.256 | 0.626 | 0.664 |
| 32 | 0.374 | 0.357 | 0.292 | 0.271 | 0.607 | 0.644 |
| 36 | 0.367 | 0.355 | 0.282 | 0.269 | 0.623 | 0.647 |
| 40 | 0.406 | 0.374 | 0.315 | 0.288 | 0.538 | 0.608 |
| 44 | 0.446 | 0.378 | 0.348 | 0.288 | 0.443 | 0.601 |
| 48 | 0.422 | 0.405 | 0.333 | 0.312 | 0.501 | 0.541 |
| Average errors | 0.344 | 0.302 | 0.268 | 0.229 | 0.659 | 0.730 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Yang, J.; Fu, X.; Zheng, Q.; Song, X.; Fu, Z.; Wang, J.; Liang, Y.; Yin, H.; Liu, Z.; et al. Water Quality Prediction Based on LSTM and Attention Mechanism: A Case Study of the Burnett River, Australia. Sustainability 2022, 14, 13231. https://doi.org/10.3390/su142013231
Chen H, Yang J, Fu X, Zheng Q, Song X, Fu Z, Wang J, Liang Y, Yin H, Liu Z, et al. Water Quality Prediction Based on LSTM and Attention Mechanism: A Case Study of the Burnett River, Australia. Sustainability. 2022; 14(20):13231. https://doi.org/10.3390/su142013231
Chicago/Turabian StyleChen, Honglei, Junbo Yang, Xiaohua Fu, Qingxing Zheng, Xinyu Song, Zeding Fu, Jiacheng Wang, Yingqi Liang, Hailong Yin, Zhiming Liu, and et al. 2022. "Water Quality Prediction Based on LSTM and Attention Mechanism: A Case Study of the Burnett River, Australia" Sustainability 14, no. 20: 13231. https://doi.org/10.3390/su142013231