

Machine Learning Techniques for Decarbonizing and Managing Renewable Energy Grids

Abstract
:1. Introduction
2. Related Work
2.1. The Main Challenges Facing the Power Distribution System in the Context of “Double Carbon”
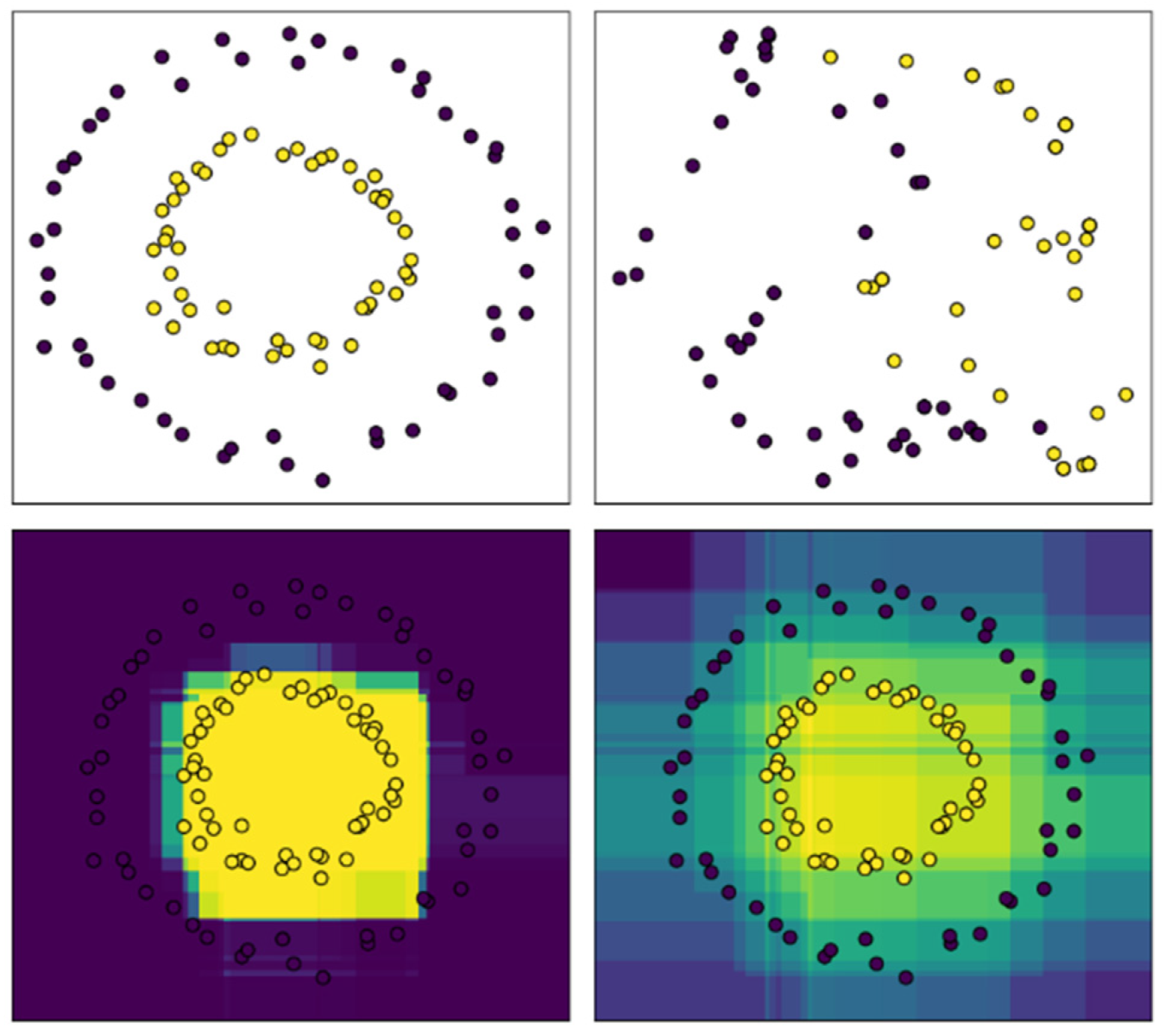
2.2. K-Means
2.3. SVM
3. Methodology
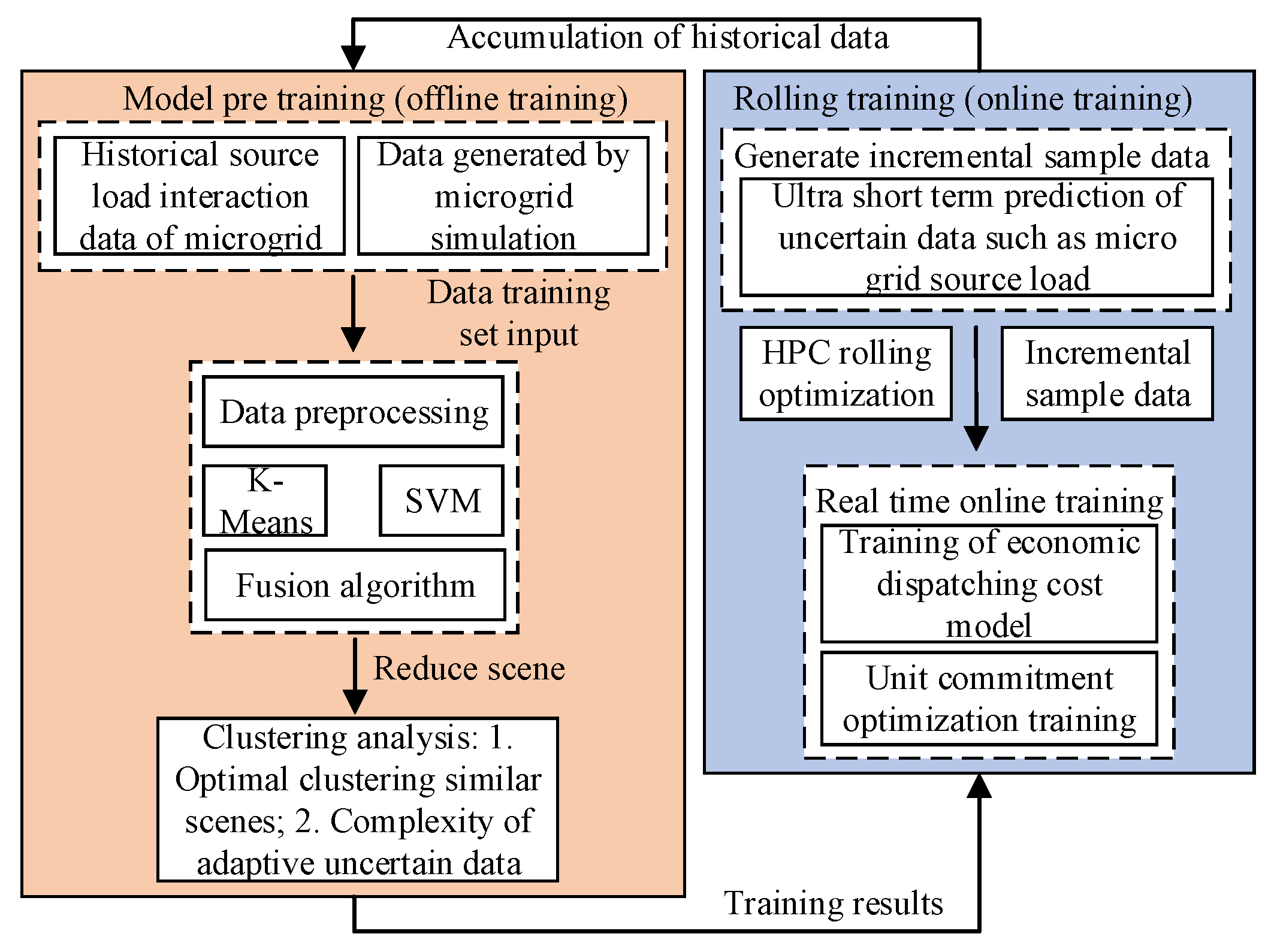
3.1. Coordination and Dispatching Framework of Renewable-Energy Grid Source and Load Based on Machine Learning
3.1.1. Renewable-Energy Grid Dispatching Optimization Framework
3.1.2. Renewable-Energy Grid Economic Dispatch Optimization Model
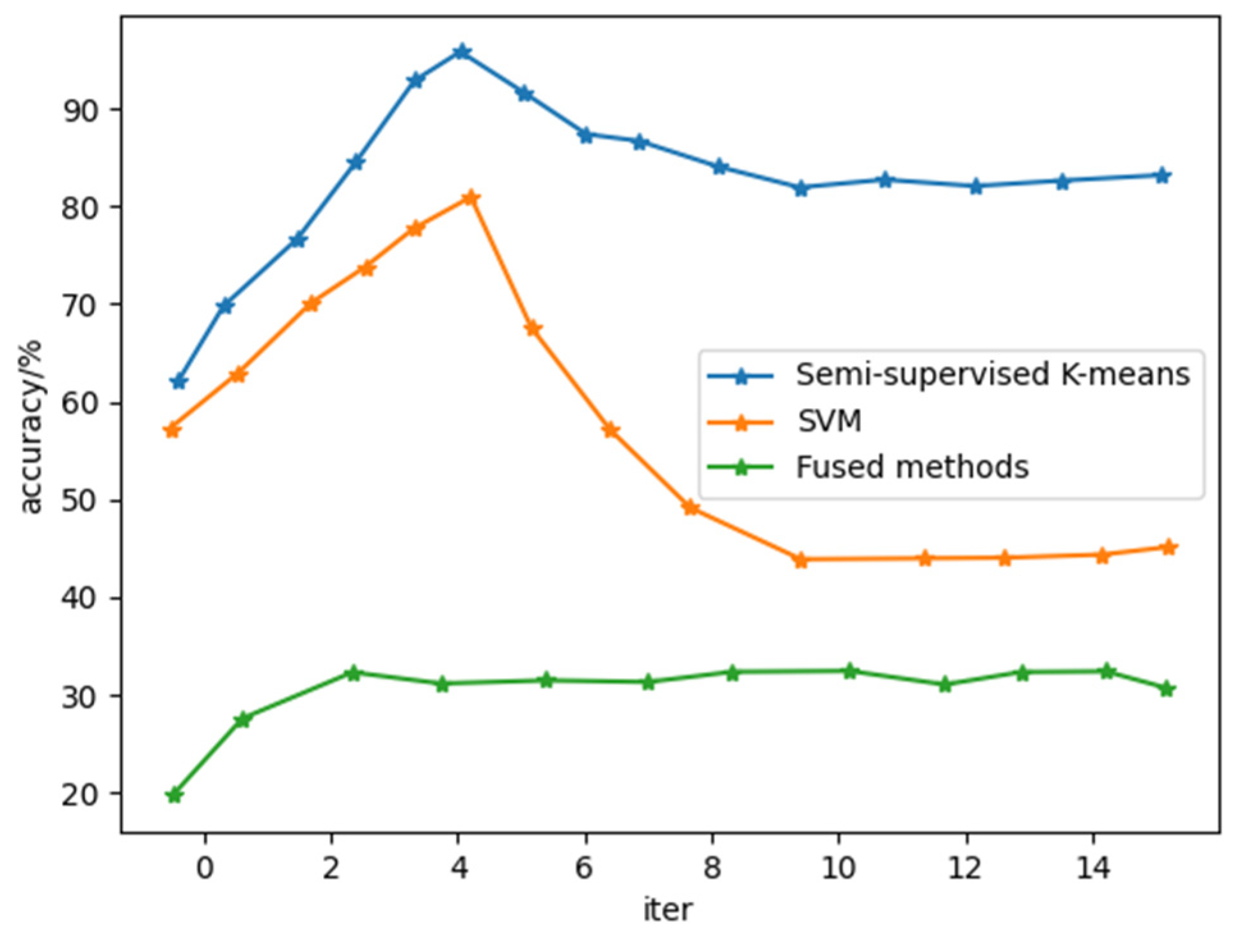
3.2. Short-Term Prediction Method Combining Semi-Supervised K-Means and SVM
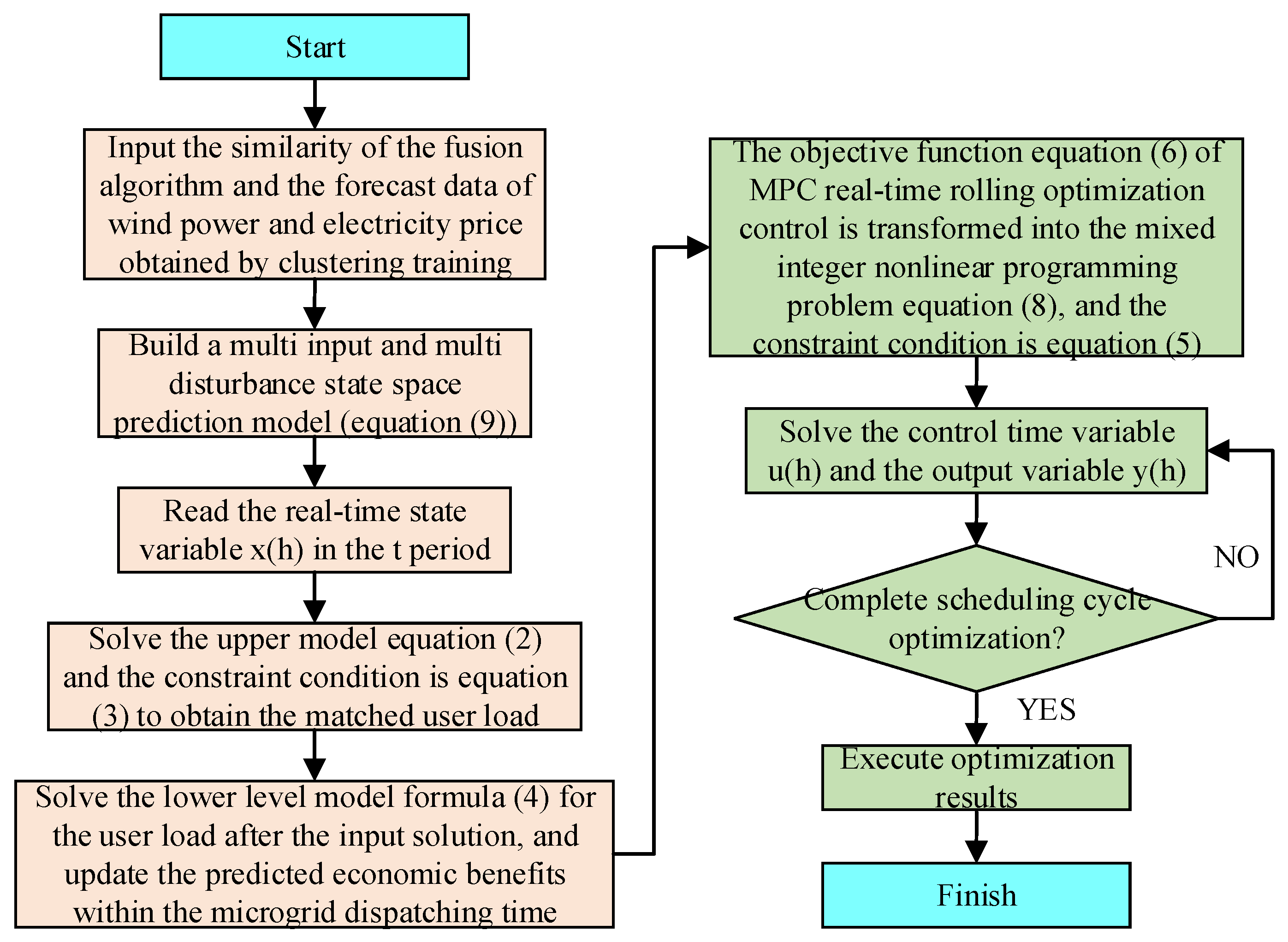
3.3. Model Solution
4. Experiments
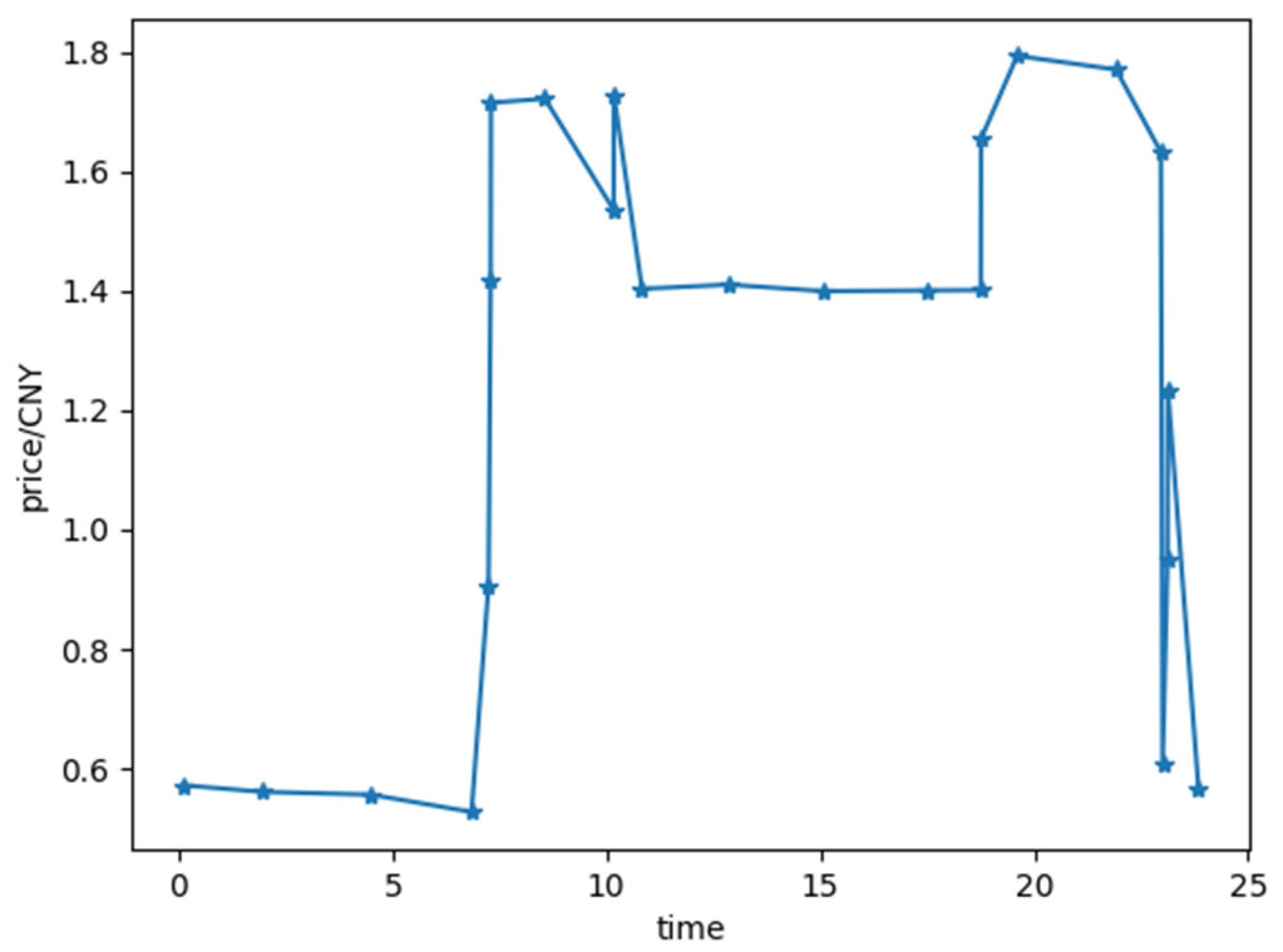
4.1. Simulation Design and Basic Data
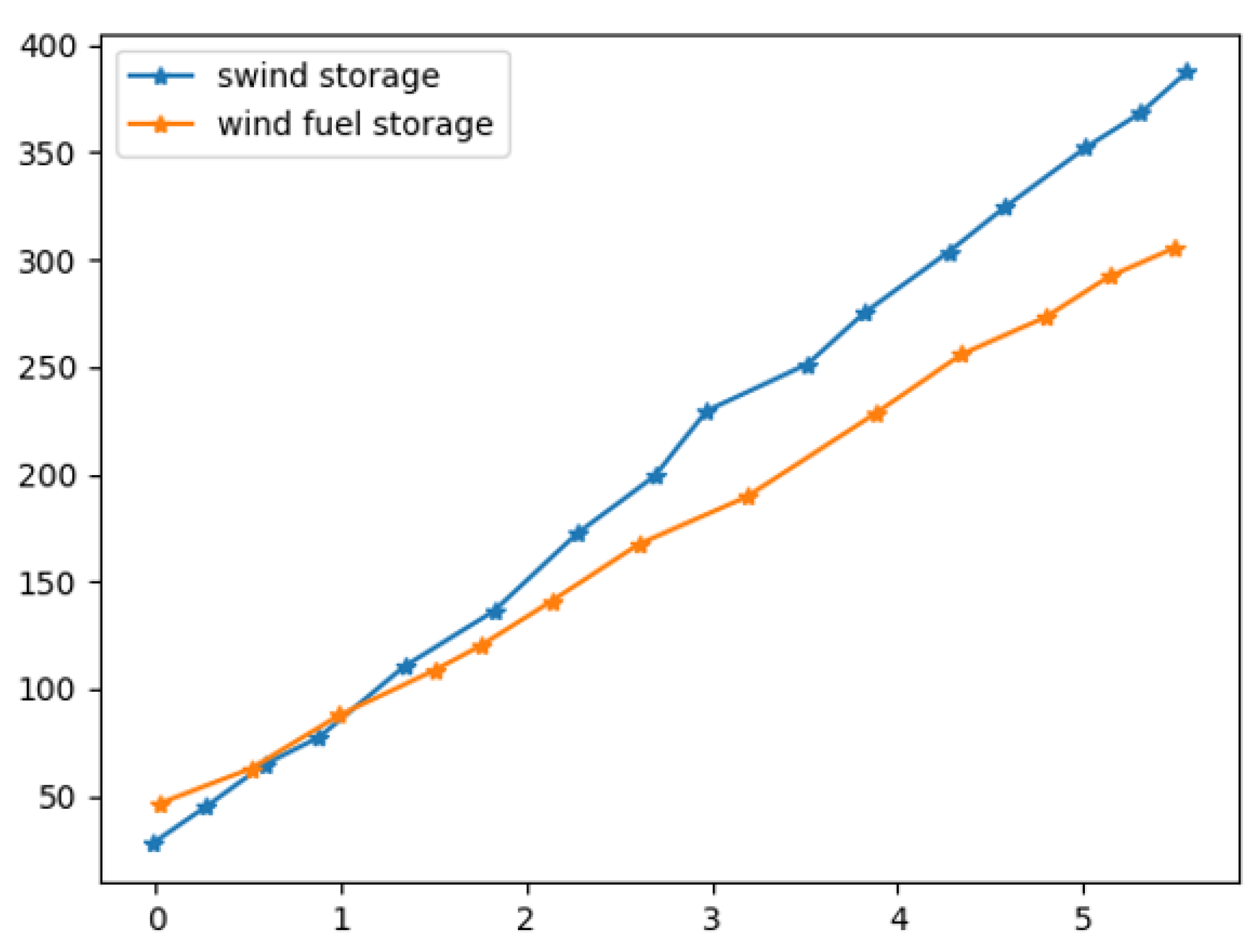
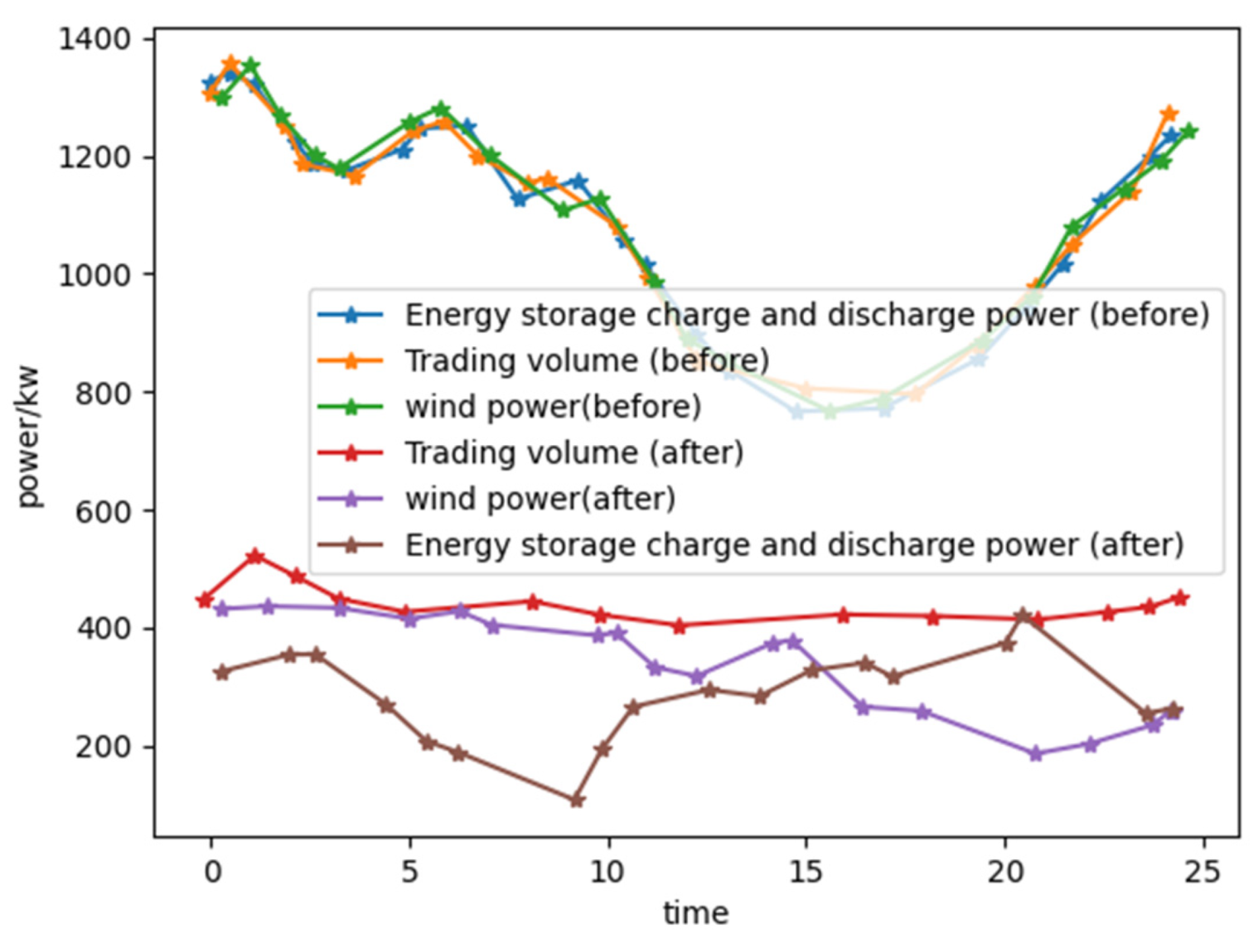
4.2. Analysis of Optimization Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, D.; Wang, Z.; Brugger, J.; Blum, D.; Wetter, M.; Hong, T.; Piette, M.A. Site demonstration and performance evaluation of MPC for a large chiller plant with TES for renewable energy integration and grid decarbonization. Appl. Energy 2022, 321, 119343. [Google Scholar] [CrossRef]
- Lipu, M.H.; Miah, M.S.; Ansari, S.; Hannan, M.A.; Hasan, K.; Sarker, M.R.; Mahmud, M.S.; Hussain, A.; Mansor, M. Data-driven hybrid approaches for renewable power prediction toward grid decarbonization: Applications, issues and suggestions. J. Clean. Prod. 2021, 328, 129476. [Google Scholar] [CrossRef]
- Inderwildi, O.; Zhang, C.; Wang, X.; Kraft, M. The impact of intelligent cyber-physical systems on the decarbonization of energy. Energy Environ. Sci. 2020, 13, 744–771. [Google Scholar] [CrossRef]
- Sharifzadeh, M.; Sikinioti-Lock, A.; Shah, N. Machine-learning methods for integrated renewable power generation: A comparative study of artificial neural networks, support vector regression, and Gaussian Process Regression. Renew. Sustain. Energy Rev. 2019, 108, 513–538. [Google Scholar] [CrossRef]
- Xie, X.; Pan, X.; Zhang, W.; An, J. A context hierarchical integrated network for medical image segmentation. Comput. Electr. Eng. 2022, 101, 108029. [Google Scholar] [CrossRef]
- Elavarasan, R.M.; Pugazhendhi, R.; Irfan, M.; Mihet-Popa, L.; Khan, I.A.; Campana, P.E. State-of-the-art sustainable approaches for deeper decarbonization in Europe–An endowment to climate neutral vision. Renew. Sustain. Energy Rev. 2022, 159, 112204. [Google Scholar] [CrossRef]
- Mrówczyńska, M.; Skiba, M.; Leśniak, A.; Bazan-Krzywoszańska, A.; Janowiec, F.; Sztubecka, M.; Grech, R.; Kazak, J.K. A new fuzzy model of multi-criteria decision support based on Bayesian networks for the urban areas’ decarbonization planning. Energy Convers. Manag. 2022, 268, 116035. [Google Scholar] [CrossRef]
- Xie, X.; Pan, X.; Shao, F.; Zhang, W.; An, J. MCI-Net: Multi-scale context integrated network for liver CT image segmentation. Comput. Electr. Eng. 2022, 101, 108085. [Google Scholar] [CrossRef]
- Rosero, D.; Díaz, N.; Trujillo, C. Cloud and machine learning experiments applied to the energy management in a microgrid cluster. Appl. Energy 2021, 304, 117770. [Google Scholar] [CrossRef]
- Waldron, J.; Rodrigues, L.; Gillott, M.; Naylor, S.; Shipman, R. The Role of Electric Vehicle Charging Technologies in the Decarbonisation of the Energy Grid. Energies 2022, 15, 2447. [Google Scholar] [CrossRef]
- Yilmaz, H.; Kimbrough, S.O.; van Dinther, C.; Keles, D. Power-to-gas: Decarbonization of the European electricity system with synthetic methane. Appl. Energy 2022, 323, 119538. [Google Scholar] [CrossRef]
- Xie, X.; Zhang, W.; Wang, H.; Li, L.; Feng, Z.; Wang, Z.; Wang, Z.; Pan, X. Dynamic adaptive residual network for liver CT image segmentation. Comput. Electr. Eng. 2021, 91, 107024. [Google Scholar] [CrossRef]
- Ahmad, T.; Madonski, R.; Zhang, D.; Huang, C.; Mujeeb, A. Data-driven probabilistic machine learning in sustainable smart energy/smart energy systems: Key developments, challenges, and future research opportunities in the context of smart grid paradigm. Renew. Sustain. Energy Rev. 2022, 160, 112128. [Google Scholar] [CrossRef]
- Pinto, G.; Piscitelli, M.S.; Vázquez-Canteli, J.R.; Nagy, Z.; Capozzoli, A. Coordinated energy management for a cluster of buildings through deep reinforcement learning. Energy 2021, 229, 120725. [Google Scholar] [CrossRef]
- Horak, D.; Hainoun, A.; Neugebauer, G.; Stoeglehner, G. A review of spatiotemporal urban energy system modeling for urban decarbonization strategy formulation. Renew. Sustain. Energy Rev. 2022, 162, 112426. [Google Scholar] [CrossRef]
- Avanija, J.; Konduru, S.; Kura, V.; NagaJyothi, G.; Dudi, B.P. Designing a Fuzzy Q-Learning Power Energy System Using Reinforcement Learning. Int. J. Fuzzy Syst. Appl. 2022, 11, 1–12. [Google Scholar] [CrossRef]
- Perera, A.T.D.; Kamalaruban, P. Applications of reinforcement learning in energy systems. Renew. Sustain. Energy Rev. 2021, 137, 110618. [Google Scholar] [CrossRef]
- Wei, T.; Chu, X.; Yang, D.; Ma, H. Power balance control of RES integrated power system by deep reinforcement learning with optimized utilization rate of renewable energy. Energy Rep. 2022, 8, 544–553. [Google Scholar] [CrossRef]
- Hannan, M.A.; Faisal, M.; Ker, P.J.; Begum, R.A.; Dong, Z.Y.; Zhang, C. Review of optimal methods and algorithms for sizing energy storage systems to achieve decarbonization in microgrid applications. Renew. Sustain. Energy Rev. 2020, 131, 110022. [Google Scholar] [CrossRef]
- Taleb, I.; Guerard, G.; Fauberteau, F.; Nguyen, N. A Flexible Deep Learning Method for Energy Forecasting. Energies 2022, 15, 3926. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fan | Rated Power/kW | ||
|---|---|---|---|
| 1 | 3 | 20 | 150 |
| 2 | 3 | 20 | 150 |
| 3 | 3 | 20 | 150 |
| 4 | 3 | 20 | 200 |
| 5 | 3 | 25 | 200 |
| 6 | 3 | 25 | 200 |
| 7 | 3 | 25 | 250 |
| 8 | 3 | 25 | 250 |
| Parameter | Charge and Discharge Efficiency/% | |||
|---|---|---|---|---|
| Numerical value | 150.00 | 95.00 | 0.15 | 0.90 |
| Equipment Type | |
|---|---|
| Fan | 0.0307 |
| Gas turbine | 0.0658 |
| Battery pack | 0.0316 |
| Data Set | Number of Initial Screening Samples | Characteristic Number | Number of Categories |
|---|---|---|---|
| Wind power output | 600 | 21 | 10 |
| User load | 150 | 9 | 4 |
| Scene Sequence Number | Probability |
|---|---|
| 1 | 0.3779 |
| 2 | 0.0884 |
| 3 | 0.1368 |
| 4 | 0.0028 |
| 5 | 0.0124 |
| 6 | 0.0951 |
| 7 | 0.0441 |
| 8 | 0.2224 |
| 9 | 0.0121 |
| 10 | 0.0120 |
| Scheduling Method | Daily Planned Dispatching Cost/CNY | Daily Real-Time Control Cost/CNY | Total Cost of Two Stages/CNY | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Fuel Unit | Planned Transaction with Main Grid | Energy Storage | Total Cost | Fuel Unit Control | Real Time Transaction Regulation with Main Power Grid | Energy Storage Regulation | Punishment for Abandoning the Wind | Total Cost | ||
| Traditional method | 1,842,679 | −1,479,531 | 60,426 | 423,574 | 561,385 | 579,452 | 31,587 | 20,367 | 1,192,791 | 1,616,365 |
| The method of this paper | 1,678,340 | −1,165,752 | −16,897 | 492,691 | 741,165 | 31,254 | −6200 | 4786 | 771,005 | 1,263,696 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, M.; He, Q.; Liu, Y.; Zhang, Z.; Shi, Z.; He, Y. Machine Learning Techniques for Decarbonizing and Managing Renewable Energy Grids. Sustainability 2022, 14, 13939. https://doi.org/10.3390/su142113939
Wu M, He Q, Liu Y, Zhang Z, Shi Z, He Y. Machine Learning Techniques for Decarbonizing and Managing Renewable Energy Grids. Sustainability. 2022; 14(21):13939. https://doi.org/10.3390/su142113939
Chicago/Turabian StyleWu, Muqing, Qingsu He, Yuping Liu, Ziqiang Zhang, Zhongwen Shi, and Yifan He. 2022. "Machine Learning Techniques for Decarbonizing and Managing Renewable Energy Grids" Sustainability 14, no. 21: 13939. https://doi.org/10.3390/su142113939
APA StyleWu, M., He, Q., Liu, Y., Zhang, Z., Shi, Z., & He, Y. (2022). Machine Learning Techniques for Decarbonizing and Managing Renewable Energy Grids. Sustainability, 14(21), 13939. https://doi.org/10.3390/su142113939