
A Dynamic Social Network Matching Model for Virtual Power Plants and Distributed Energy Resources with Probabilistic Linguistic Information



Abstract
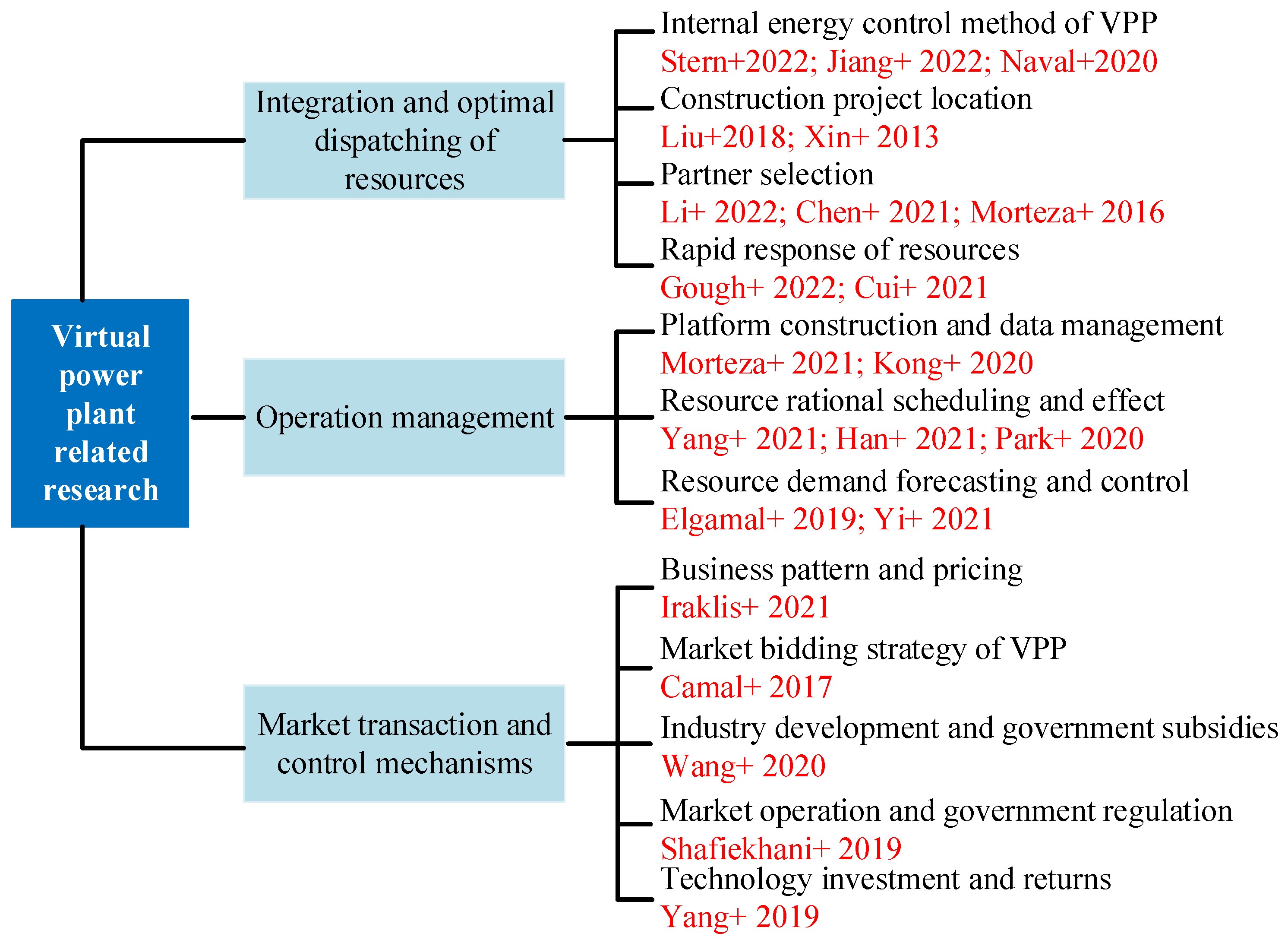
:1. Introduction
- Propose a social trust network-based probabilistic linguistic two-sided matching model that takes into account the social interaction and competition among companies;
- Put forward a new calculation method for the dynamic trust degree and the construction method of the trust network among companies.
2. Preliminaries
2.1. Probabilistic Linguistic Term Sets
- (1)
- There is the following negation operator: if ;
- (2)
- The set has the following order: if and only if .
2.2. Two-Sided Matching
3. Probabilistic Linguistic Dynamics Social Trust Degree
3.1. Matching Satisfaction Degree
3.2. Dynamics Social Trust Degree
- (1)
- Direct trust relationship
- (2)
- Indirect trust relationship
- (1)
- The most trusted company
- (2)
- The most authoritative company
4. Dynamic Two-Sided Matching Model Considering Competitive Relationships
4.1. Problem Description
4.2. Measurement of the Dynamic Competitive Satisfaction between Companies
4.3. Two-Sided Matching Model
- Stage 1. Data collection
- Stage 2. Resolution process
- Stage 3. Matching process
5. An Empirical Study of Virtual Power Plants
5.1. Decision Background
5.2. Implement
5.3. Comparison and Analysis
5.3.1. Comparison
5.3.2. Analysis
- The dynamic social trust relationship between companies is introduced into the two-sided matching model.
- 2.
- The competitive relationships between companies are incorporated into the calculation of competitive satisfaction.
- 3.
- Probabilistic linguistic term sets are applied to two-sided matching decision-making problem to imitate uncertain information.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, B.Q.; Li, Z. Towards world’s low carbon development: The role of clean energy. Appl. Energy 2022, 307, 118160. [Google Scholar] [CrossRef]
- Naval, N.; Yusta, J.M. Virtual power plant models and electricity markets—A review. Renew. Sustain. Energy Rev. 2021, 149, 111393. [Google Scholar] [CrossRef]
- Bhuiyan, E.A.; Hossain, M.Z.; Muyeen, S.M.; Fahim, S.R.; Sarker, S.K.; Das, S.K. Towards next generation virtual power plant: Technology review and frameworks. Renew. Sustain. Energy Rev. 2021, 150, 111358. [Google Scholar] [CrossRef]
- Choi, E.; Krishnan, S.; Larkin, W.W.D. Household cost-effectiveness of Tesla’s Powerwall and solar roof across America’s zip code tabulation areas. In BPRO 29000 (Energy Policy); The University of Chicago: Chicago, IL, USA, 2018. [Google Scholar]
- Gong, H.; Jones, E.S.; Alden, R.E.; Frye, A.G.; Colliver, D.; Ionel, D.M. Virtual power plant control for large residential communities using hvac systems for energy storage. IEEE Trans. Ind. Appl. 2021, 58, 622–633. [Google Scholar] [CrossRef]
- Cartwright, E.D. FERC order 2222 gives boost to DERs. Clim. Energy 2020, 37, 22. [Google Scholar] [CrossRef]
- Cano, C. FERC Order No. 2222: A New Day for Distributed Energy Resources; Faderal Energy Regulatory Commission: Washington, DC, USA, 2020.
- Ninagawa, C. Outlook of the virtual power plant: A Japan perspective. In Virtual Power Plant System Integration Technology; Springer: Singapore, 2022; pp. 243–250. [Google Scholar]
- Suzuki, M.; Inoue, S.; Shigehisa, T. Field Test Result of Residential SOFC CHP System Over 10 Years, 89000 Hours. ECS Trans. 2021, 103, 25. [Google Scholar] [CrossRef]
- Fan, M.; Tang, X.; Pei, W.; Kong, L. Peer-Peer electricity transaction and integrated regulation of VPP based on Blockchain. In Proceedings of the 2020 IEEE 4th Conference on Energy Internet and Energy System Integration (EI2), Wuhan, China, 30 October–1 November 2020; pp. 727–732. [Google Scholar]
- Rai, A.; Calais, P.; Wild, K.; Williams, G.; Nelson, T. The value of flexibility in Australia’s national electricity market. In Variable Generation, Flexible Demand; Academic Press: Cambridge, MA, USA, 2021; pp. 329–354. [Google Scholar]
- National Development and Reform Commission; National Energy Administration. Notice on the Issuance of the “14th Five-Year Plan” Modern Energy System. Development and Reform Energy. No. 210. [EB/OL]. 2022. Available online: https://www.ndrc.gov.cn/xxgk/zcfb/ghwb/202203/t20220322_1320016_ext.html (accessed on 20 September 2022).
- Cameron, H.; Qi, Y.; Nicholas, S.; Bob, W.; Xie, C.P.; Dimitri, Z.H. Towards carbon neutrality and China’s 14th Five-Year Plan: Clean energy transition, sustainable urban development, and investment priorities. Environ. Sci. Ecotechnol. 2021, 8, 100130. [Google Scholar]
- Stern, N.; Xie, C. China’s new growth story: Linking the 14th Five-Year plan with the 2060 carbon neutrality pledge. J. Chin. Econ. Bus. Stud. 2022, 1–21. [Google Scholar] [CrossRef]
- Jiang, H.L.; Liu, Y.X.; Feng, Y.M.; Zhou, B.Z.; Li, Y.X. Analysis of power generation technology trend in 14th five-year plan under the background of carbon peak and carbon neutrality. Power Gener. Techno 2022, 43, 54–64. [Google Scholar]
- Naval, N.; Sánchez, R.; Yusta, J.M. A virtual power plant optimal dispatch model with large and small-scale distributed renewable generation. Renew. Energy 2020, 151, 57–69. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Li, M.; Lian, H.B.; Tang, X.W.; Liu, C.Q.; Jiang, C.W. Optimal dispatch of virtual power plant using interval and deterministic combined optimization. Int. J. Electr. Power 2018, 102, 235–244. [Google Scholar] [CrossRef]
- Xin, H.H.; Gan, D.Q.; Li, N.H.; Li, H.J.; Dai, C.S. Virtual power plant-based distributed control strategy for multiple distributed generators. IET Control Theory Appl. 2013, 7, 90–98. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.H.; Liu, M.B.; Xie, M.; Zhu, J.Q. Robust optimization approach with acceleration strategies to aggregate an active distribution system as a virtual power plant. Int. J. Electr. Power 2022, 142 Pt B, 108316. [Google Scholar] [CrossRef]
- Chen, J.R.; Liu, M.Y.; Milano, F. Aggregated model of virtual power plants for transient frequency and voltage stability analysis. IEEE Trans. Power Syst. 2021, 36, 4366–4375. [Google Scholar] [CrossRef]
- Morteza, S.; Mohammad-Kazem, S.; Mahmoud-Reza, H. A medium-term coalition-forming model of heterogeneous DERs for a commercial virtual power plant. Appl. Energy 2016, 169, 663–681. [Google Scholar]
- Gough, M.; Santos, S.F.; Lotfi, M.; Javadi, M.S.; Osório, G.J.; Ashraf, P.; Catalão, J.P. Operation of a technical virtual power plant considering diverse distributed energy resources. IEEE Trans. Ind. Appl. 2022, 58, 2547–2558. [Google Scholar] [CrossRef]
- Cui, Y.F.; Li, Z.H.; Wei, S.Y.; Li, Z.W.; Jia, Q.Q. Random selection model of thermostatically controlled load units for demand response. Auto. Electr. Power Syst. 2021, 45, 126–132. [Google Scholar]
- Morteza, S.; Abdollah, A.; Omid, H.; Miadreza, S.; João, P.S.C. Optimal bidding strategy of a renewable-based virtual power plant including wind and solar units and dispatchable loads. Energy 2021, 239 Pt D, 122379. [Google Scholar]
- Kong, X.Y.; Xiao, J.; Liu, D.H.; Wu, J.Z.; Wang, C.S.; Shen, Y. Robust stochastic optimal dispatching method of multi-energy virtual power plant considering multiple uncertainties. Appl. Energy 2020, 279, 115707. [Google Scholar] [CrossRef]
- Yang, Q.; Wang, H.; Wang, T.; Zhang, S.L.; Wu, X.X.; Wang, H. Blockchain-based decentralized energy management platform for residential distributed energy resources in a virtual power plant. Appl. Energy 2021, 294, 117026. [Google Scholar] [CrossRef]
- Han, T.; Jiang, G.D.; Sun, B.H.; Feng, R.Q.; Wang, B.W.; Cao, L.L. Source-Network-Load-Storage coordinated control system based on distribution IOT cloud platform and virtual power plant. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2021; Volume 701, p. 012039. [Google Scholar]
- Park, S.W.; Son, S.Y. Interaction-based virtual power plant operation methodology for distribution system operator’s voltage management. Appl. Energy 2020, 271, 115222. [Google Scholar] [CrossRef]
- Elgamal, A.H.; Gudrun, K.O.; Robu, V.; Andoni, M. Optimization of a multiple-scale Renew.Energy-based virtual power plant in the UK. Appl. Energy 2019, 256, 113973. [Google Scholar] [CrossRef]
- Yi, Z.K.; Xu, Y.L.; Wang, H.Z.; Sang, L.W. Coordinated operation strategy for a virtual power plant with multiple DER aggregators. IEEE Trans. Sustain. Energy 2021, 12, 2445–2458. [Google Scholar] [CrossRef]
- Iraklis, C.; Smend, J.; Almarzooqi, A.; Mnatsakanyan, A. Flexibility forecast and resource composition methodology for virtual power plants. In Proceedings of the 2021 International Conference on Electrical, Computer and Energy Technologies (ICECET), Cape Town, South Africa, 9–10 December 2021; pp. 1–7. [Google Scholar]
- Camal, S.; Michiorri, A.; Kariniotakis, G.; Liebelt, A. Short-term forecast of automatic frequency restoration reserve from a renewable energy based virtual power plant. In Proceedings of the 2017 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), Turin, Italy, 26–29 September 2017; pp. 1–6. [Google Scholar]
- Wang, H.; Riaz, S.; Mancarella, P. Integrated techno-economic modeling, flexibility analysis, and business case assessment of an urban virtual power plant with multi-market co-optimization. Appl. Energy 2020, 259, 114142. [Google Scholar] [CrossRef]
- Shafiekhani, M.; Badri, A.; Shafie-khah, M.; Catalão, J.P. Strategic bidding of virtual power plant in energy markets: A bi-level multi-objective approach. Int. J. Electr. Power 2019, 113, 208–219. [Google Scholar] [CrossRef]
- Yang, D.; He, S.; Chen, Q.; Li, D.Q.; Pandžić, H. Bidding strategy of a virtual power plant considering carbon-electricity trading. CSEE J. Power Energy Syst. 2019, 5, 306–314. [Google Scholar]
- Elgamal, A.H.; Vahdati, M.; Shahrestani, M. Assessing the economic and energy efficiency for multi-energy virtual power plants in regulated markets: A case study in Egypt. Sustain. Cities Soc. 2022, 83, 103968. [Google Scholar] [CrossRef]
- Baringo, A.; Baringo, L.; Arroyo, J.M. Holistic planning of a virtual power plant with a nonconvex operational model: A risk-constrained stochastic approach. Int. J. Electr. Power Energy Syst. 2021, 132, 107081. [Google Scholar] [CrossRef]
- Sadeghi, S.; Jahangir, H.; Vatandoust, B.; Golkar, M.A.; Ahmadian, A.; Elkamel, A. Optimal bidding strategy of a virtual power plant in day-ahead energy and frequency regulation markets: A deep learning-based approach. Int. J. Electr. Power 2021, 127, 106646. [Google Scholar] [CrossRef]
- Guo, W.S.; Liu, P.K.; Shu, X.L. Optimal dispatching of electric-thermal interconnected virtual power plant considering market trading mechanism. J. Clean. Prod. 2021, 279, 123446. [Google Scholar] [CrossRef]
- Gale, D.; Shapley, L.S. College admissions and the stability of marriage. Am. Math. Mon. 1962, 69, 9–15. [Google Scholar] [CrossRef]
- Chen, G.L.; Huang, S.L.; Meyer-Doyle, P.; Mindruta, D. Generalist versus specialist CEOs and acquisitions: Two-sided matching and the impact of CEO characteristics on firm outcomes. Strateg. Manag. J. 2021, 42, 1184–1214. [Google Scholar] [CrossRef]
- Yu, D.J.; Xu, Z.S. Intuitionistic fuzzy two-sided matching model and its application to personnel-position matching problems. J. Oper. Res. Soc. 2020, 71, 312–321. [Google Scholar] [CrossRef]
- Yang, Q.; You, X.S.; Zhang, Y.Y. Two-sided matching based on I-BTM and LSGDM applied to high-level overseas talent and job fit problems. Sci. Rep. 2021, 11, 12723. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.H.; Li, Y.Y.; Gu, F.; Guo, J.F.; Wu, X.J. Two-sided matching and strategic selection on freight resource sharing platforms. Phys. A Stat. Mech. Its Appl. 2020, 559, 125014. [Google Scholar] [CrossRef]
- Tong, H.G.; Zhu, J.J.; Tan, X. Two-stage consensus reaching process for matching based on the cloud model in large-scale sharing platform: A case study in the industrial internet platform. Soft Comput. 2022, 26, 3469–3488. [Google Scholar] [CrossRef]
- Tong, H.G.; Zhu, J.J.; Yi, Y. A two-sided gaming model for large-scale stable matching in sharing economy based on the probabilistic linguistic term sets. J. Intell. Fuzzy Syst. 2022, 42, 1623–1641. [Google Scholar] [CrossRef]
- Liu, P.; Zou, Y. Two-sided matching model of shared manufacturing resources considering psychological behavior of agents. Discret. Dyn. Nat. Soc. 2021, 2, 1–11. [Google Scholar] [CrossRef]
- Jiang, P.; Guo, S.S.; Du, B.G.; Guo, J. Two-sided matching decision-making model for complex product system based on life-cycle sustainability assessment. Expert Syst. Appl. 2022, 208, 118184. [Google Scholar] [CrossRef]
- Kheirabadi, S.M.N.; Sabet, S.A.; Malek-al-Sadati, S.S.; Masoud, S.R. Application of matching theory in finance; market design with the purpose of corporate finance at different stages of life cycle based on the matching theory. Monet. Financ. Econ. 2021, 28, 67–104. [Google Scholar] [CrossRef]
- Liu, Y.; Li, K.W. A two-sided matching decision method for supply and demand of technological knowledge. J. Knowl. Manag. 2017, 21, 592–606. [Google Scholar] [CrossRef]
- Han, J.; Li, B.; Liang, H.M.; Lai, K.K. A novel two-sided matching decision method for technological knowledge supplier and demander considering the network collaboration effect. Soft Comput. 2018, 22, 5439–5451. [Google Scholar] [CrossRef]
- Wan, S.P.; Li, D.F. Decision making method for multi-attribute two-sided matching problem between venture capitalists and investment enterprises with different kinds of information. Chin. J. Manag. Sci. 2014, 22, 40–47. [Google Scholar]
- Liang, Z.C.; Yang, Y.; Liao, S.G. Interval-valued intuitionistic fuzzy two-sided matching model considering level of automation. Appl. Soft Comput. 2022, 116, 108252. [Google Scholar] [CrossRef]
- Li, B.D.; Yang, Y.; Su, J.F.; Liang, Z.C.; Wang, S. Two-sided matching decision-making model with hesitant fuzzy preference information for configuring cloud manufacturing tasks and resources. J. Intell. Manuf. 2020, 31, 2033–2047. [Google Scholar] [CrossRef]
- Zhang, Z.; Kou, X.Y.; Yu, W.Y.; Gao, Y. Consistency improvement for fuzzy preference relations with self-confidence: An application in two-sided matching decision making. J. Oper. Res. Soc. 2020, 72, 1914–1927. [Google Scholar] [CrossRef]
- Liang, D.C.; He, X.; Xu, Z.S. Multi-attribute dynamic two-sided matching method of talent sharing market in incomplete preference ordinal environment. Appl. Soft Comput. 2020, 93, 106427. [Google Scholar] [CrossRef]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Jia, X.; Wang, X.F.; Wang, Y.M.; Zhou, L. A two-sided matching decision-making approach based on prospect theory under the probabilistic linguistic environment. Soft Comput. 2022, 26, 3921–3938. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, J.L.; Gao, Y.; Yu, W.Y. Two-sided matching decision making with multi-granular hesitant fuzzy linguistic term sets and incomplete criteria weight information. Expert Syst. Appl. 2021, 168, 114311. [Google Scholar] [CrossRef]
- Yu, B.; Yue, Q. Extend TOPSIS-based two-sided matching decision in incomplete indifferent order relations setting considering matching aspirations. Eurasia J. Math. Sci. Technol. Educ. 2017, 13, 8155–8168. [Google Scholar] [CrossRef]
- Delaram, J.; Fatahi, V.O.; Houshamand, M.; Ashtiani, F. A matching mechanism for public cloud manufacturing platforms using intuitionistic Fuzzy VIKOR and deferred acceptance algorithm. Int. J. Manag. Sci. Eng. Manag. 2021, 16, 107–122. [Google Scholar] [CrossRef]
- Huang, X.; Chen, H. To select suitable supplier for complex equipment military-civilian collaborative design based on fuzzy preference information that from matching perspective. J. Intell. Fuzzy Syst. 2022, 42, 3805–3825. [Google Scholar] [CrossRef]
- Jia, X.; Wang, X.F.; Zhu, Y.F.; Zhou, L.; Zhou, H. A two-sided matching decision-making approach based on regret theory under intuitionistic fuzzy environment. J. Intell. Fuzzy Syst. 2021, 4, 11491–11508. [Google Scholar] [CrossRef]
- Sun, S.L.; Ionita, S.; Volná, E.; Gavrilov, A.; Liu, F. Decision method for two-sided matching with interval-valued intuitionistic fuzzy sets considering matching aspirations. J. Intell. Fuzzy Syst. 2016, 31, 2903–2910. [Google Scholar]
- Wang, N.N.; Li, P. A new multi-granularity probabilistic linguistic two-sided matching method considering peer effect and its application in pension services. Int. J. Mach. Learn. Cybern. 2022, 13, 1907–1926. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, Z.S.; Wang, Z. Two-sided matching and game on investing in carbon emission reduction technology under a cap-and-trade system. J. Clean. Prod. 2021, 282, 124436. [Google Scholar] [CrossRef]
- Lu, Y.L.; Xu, Y.J.; Qu, S.J.; Xu, Z.S.; Ma, G.; Li, Z.W. Multiattribute social network matching with unknown weight and different risk preference. J. Intell. Fuzzy Syst. 2021, 38, 4031–4048. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z.S. Probabilistic linguistic term sets in multi-attribute group decision making. Inform. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Zhao, H.Y.; Li, B.Q.; Li, Y.Y. Probabilistic linguistic group decision-making method based on attribute decision and multiplicative preference relations. Int. J. Fuzzy Syst. 2018, 23, 2200–2217. [Google Scholar] [CrossRef]
- Jin, C.; Wang, H.; Xu, Z.S. Uncertain probabilistic linguistic term sets in group decision making. Int. J. Fuzzy Syst. 2019, 21, 1241–1258. [Google Scholar] [CrossRef]
- Mi, X.M.; Liao, H.C.; Wu, X.L.; Xu, Z.S. Probabilistic linguistic information fusion: A survey on aggregation operators in terms of principles, definitions, classifications, applications, and challenges. Int. J. Intell. Syst. 2020, 35, 529–556. [Google Scholar] [CrossRef]
- Liu, P.D.; Teng, F. Some Muirhead mean operators for probabilistic linguistic term sets and their applications to multiple attribute decision-making. Appl. Soft Comput. 2018, 68, 396–431. [Google Scholar] [CrossRef]
- Saha, A.; Senapati, T.; Yager, R.R. Hybridizations of generalized Dombi operators and Bonferroni mean operators under dual probabilistic linguistic environment for group decision-making. Int. J. Intell. Syst. 2021, 36, 6645–6679. [Google Scholar] [CrossRef]
- Shen, F.; Liang, C.; Yang, Z.Y. Combined probabilistic linguistic term set and ELECTRE II method for solving a venture capital project evaluation problem. Econ. Res.-Ekon. Istraživanja 2022, 35, 60–82. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Wang, X.K.; Peng, J.J.; Zhang, H.Y.; Wang, J.Q. An integrated probabilistic linguistic projection method for MCGDM based on ELECTRE III and the weighted convex median voting rule. Expert Syst. 2020, 37, e12593. [Google Scholar] [CrossRef]
- Lin, M.W.; Chen, Z.Y.; Xu, Z.S.; Gou, X.J.; Herrera, F. Score function based on concentration degree for probabilistic linguistic term sets: An application to TOPSIS and VIKOR. Inform. Sci. 2021, 551, 270–290. [Google Scholar] [CrossRef]
- Teng, F.; Liu, P.D. A large group decision-making method based on a generalized Shapley probabilistic linguistic Choquet average operator and the TODIM method. Comput. Ind. Eng. 2021, 151, 106971. [Google Scholar] [CrossRef]
- Jia, X.; Wang, Y.M. A multi-participant two-sided matching decision-making approach under probabilistic linguistic environment based on prospect theory. Int. J. Fuzzy Syst. 2022, 24, 2005–2023. [Google Scholar] [CrossRef]
- Li, B.; Xu, Z.S.; Zhang, Y.X. Two-stage multi-sided matching dispatching models based on improved BPR function with probabilistic linguistic term sets. Int. J. Mach. Learn. Cybern. 2021, 12, 151–169. [Google Scholar] [CrossRef]
- Zhao, N.; Hu, S.Q.; Wen, G.F. Prospect outranking method based on stochastic dominance in probabilistic linguistic multi-attribute risk decision-making for application in evaluation of public health emergency plan. 2022; in press. [Google Scholar]
- Han, J. From the customer satisfaction strategy to the customer confidence strategy. Inform. Dev. Econ. 2006, 16, 118–120. [Google Scholar]
- Li, X.; Ma, H.; Yao, W.; Gui, X.L. Data-driven and feedback-enhanced trust computing pattern for large-scale multi-cloud collaborative services. IEEE Trans. Serv. Comput. 2018, 11, 671–684. [Google Scholar] [CrossRef]
- Christakis, N.A.; Fowler, J.H. Connected: The Surprising Power of Our Social Networks and How They Shape Our Lives; China Renmin University Press: China, Beijing, 2013. [Google Scholar]
- Wang, W.Z.; Liu, X.W. Intuitionistic fuzzy geometric aggregation operators based on Einstein operations. Int. J. Intell. Syst. 2011, 26, 1049–1075. [Google Scholar] [CrossRef]
- Liu, Y.J.; Liang, C.Y.; Chiclana, F.; Wu, J. A knowledge coverage-based trust propagation for recommendation mechanism in social network group decision making. Appl. Soft Comput. 2021, 101, 107005. [Google Scholar] [CrossRef]
- Gyöngyi, Z.; Garcia-Molina, H.; Pedersen, J. Combating Web Spam with TrustRank. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004; pp. 576–587. [Google Scholar]
- Jin, Z.M.; Liu, J.G. The effects of E-business on industry structure. J. Tsinghua Univ. (Philos. Soc. Sci.) 2003, 18, 5. [Google Scholar]
- Ren, L.; Ren, M.L. One-to-many two-sided matching method of wisdom manufacturing task based on competition and synergy effect. Comput. Integr. Manuf. Syst. 2018, 24, 1110–1123. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| b1 | b2 | b3 | b4 | ||
|---|---|---|---|---|---|
| a1 | c1 | {s−2(0.1), s−1(0.05), s0(0.25), s1(0.2), s2(0.4)} | {s−2(0.2), s−1(0.25), s0(0.2), s1(0.3), s2(0.05)} | {s−2(0.25), s−1(0.2), s0(0.2), s1(0.3), s2(0.05)} | {s−2(0.1), s−1(0.3), s0(0.35), s1(0.2), s2(0.05)} |
| c2 | {s−2(0.05), s−1(0.3), s0(0.1), s1(0.1), s2(0.45)} | {s−2(0.1), s−1(0.05), s0(0.25), s1(0.2), s2(0.4)} | {s−2(0.1), s−1(0.3), s0(0.1), s1(0.4), s2(0.1)} | {s−2(0.3), s−1(0.2), s0(0.3), s1(0.1), s2(0.1)} | |
| c3 | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.25), s2(0.2)} | {s−2(0.15), s−1(0.15), s0(0.2), s1(0.3), s2(0.2)} | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.25), s2(0.25)} | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.25), s2(0.2)} | |
| c4 | {s−2(0.05), s−1(0.15), s0(0.3), s1(0.1), s2(0.4)} | {s−2(0.2), s−1(0.05), s0(0.25), s1(0.35), s2(0.15)} | {s−2(0.1), s−1(0.2), s0(0.2), s1(0.1), s2(0.4)} | {s−2(0.2), s−1(0.2), s0(0.35), s1(0.15), s2(0.1)} | |
| a2 | c1 | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.25), s2(0.25)} | {s−2(0.05), s−1(0.15), s0(0.25), s1(0.4), s2(0.15)} | {s−2(0.25), s−1(0.2), s0(0.15), s1(0.3), s2(0.1)} | {s−2(0.1), s−1(0.25), s0(0.1), s1(0.35), s2(0.2)} |
| c2 | {s−2(0.15), s−1(0.05), s0(0.35), s1(0.1), s2(0.35)} | {s−2(0.15), s−1(0.3), s0(0.1), s1(0.2), s2(0.25)} | {s−2(0.1), s−1(0.35), s0(0.1), s1(0.25), s2(0.2)} | {s−2(0.15), s−1(0.25), s0(0.2), s1(0.1), s2(0.3)} | |
| c3 | {s−2(0.1), s−1(0.05), s0(0.4), s1(0.15), s2(0.3)} | {s−2(0.2), s−1(0.35), s0(0.2), s1(0.15), s2(0.1)} | {s−2(0.25), s−1(0.1), s0(0.15), s1(0.25), s2(0.25)} | {s−2(0.25), s−1(0.2), s0(0.1), s1(0.15), s2(0.3)} | |
| c4 | {s−2(0.15), s−1(0.4), s0(0.05), s1(0.2), s2(0.2)} | {s−2(0.1), s−1(0.25), s0(0.15), s1(0.3), s2(0.2)} | {s−2(0.1), s−1(0.25), s0(0.2), s1(0.1), s2(0.35)} | {s−2(0.1), s−1(0.05), s0(0.5), s1(0.25), s2(0.1)} | |
| a3 | c1 | {s−2(0.05), s−1(0.35),s0(0.25), s1(0.3), s2(0.05)} | / | {s−2(0.2), s−1(0.05), s0(0.15), s1(0.35), s2(0.25)} | {s−2(0.1), s−1(0.15), s0(0.2), s1(0.4), s2(0.15)} |
| c2 | {s−2(0.1), s−1(0.2), s0(0.15), s1(0.05), s2(0.5)} | {s−2(0.1), s−1(0.35), s0(0.35), s1(0.1), s2(0.1)} | {s−2(0.1), s−1(0.05), s0(0.2), s1(0.3), s2(0.35)} | {s−2(0.2), s−1(0.25), s0(0.15), s1(0.25), s2(0.15)} | |
| c3 | {s−2(0.15), s−1(0.05), s0(0.1), s1(0.2), s2(0.5)} | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.05), s2(0.45)} | {s−2(0.3), s−1(0.1), s0(0.25), s1(0.25), s2(0.1)} | {s−2(0.25), s−1(0.2), s0(0.15), s1(0.1), s2(0.3)} | |
| c4 | {s−2(0.25), s−1(0.3), s0(0.25), s1(0.05), s2(0.15)} | {s−2(0.2), s−1(0.1), s0(0.2), s1(0.3), s2(0.2)} | {s−2(0.2), s−1(0.35), s0(0.1), s1(0.15), s2(0.2)} | {s−2(0.15), s−1(0.05), s0(0.1), s1(0.15), s2(0.55)} | |
| a4 | c1 | {s−2(0.25), s−1(0.1), s0(0.15), s1(0.05), s2(0.45)} | {s−2(0.1), s−1(0.35), s0(0.25), s1(0.15), s2(0.15)} | {s−2(0.2), s−1(0.15), s0(0.2), s1(0.25), s2(0.2)} | {s−2(0.25), s−1(0.15), s0(0.25), s1(0.1), s2(0.25)} |
| c2 | {s−2(0.15), s−1(0.15), s0(0.05), s1(0.35), s2(0.3)} | {s−2(0.1), s−1(0.05), s0(0.2), s1(0.25), s2(0.4)} | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.15), s2(0.3)} | {s−2(0.1), s−1(0.1), s0(0.25), s1(0.35), s2(0.2)} | |
| c3 | {s−2(0.05), s−1(0.4), s0(0.25), s1(0.15), s2(0.15)} | {s−2(0.05), s−1(0.35), s0(0.15), s1(0.1), s2(0.35)} | {s−2(0.1), s−1(0.2), s0(0.25), s1(0.2), s2(0.25)} | {s−2(0.05), s−1(0.2), s0(0.15), s1(0.5), s2(0.1)} | |
| c4 | {s−2(0.1), s−1(0.2), s0(0.35), s1(0.05), s2(0.3)} | {s−2(0.2), s−1(0.35), s0(0.1), s1(0.2), s2(0.15)} | {s−2(0.1), s−1(0.05), s0(0.1), s1(0.25), s2(0.5)} | {s−2(0.1), s−1(0.15), s0(0.35), s1(0.1), s2(0.3)} |
| a1 | a2 | a3 | a4 | ||
|---|---|---|---|---|---|
| b1 | d1 | {s−2(0.2), s−1(0.25), s0(0.1), s1(0.1), s2(0.35)} | {s−2(0.05), s−1(0.25), s0(0.2), s1(0.25), s2(0.25)} | {s−2(0.25), s−1(0.15), s0(0.35), s1(0.1), s2(0.15)} | {s−2(0.2), s−1(0.1), s0(0.15), s1(0.2), s2(0.35)} |
| d2 | {s−2(0.25), s−1(0.2), s0(0.15), s1(0.1), s2(0.3)} | {s−2(0.1), s−1(0.15), s0(0.4), s1(0.2), s2(0.15)} | {s−2(0.15), s−1(0.05), s0(0.25), s1(0.35), s2(0.2)} | {s−2(0.1), s−1(0.25), s0(0.15), s1(0.35), s2(0.15)} | |
| d3 | {s−2(0.15), s−1(0.05), s0(0.35), s1(0.4), s2(0.05)} | {s−2(0.05), s−1(0.35), s0(0.15), s1(0.1), s2(0.35)} | {s−2(0.05), s−1(0.1), s0(0.15), s1(0.35), s2(0.35)} | {s−2(0.2), s−1(0.15), s0(0.05), s1(0.1), s2(0.5)} | |
| d4 | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.15), s2(0.3)} | {s−2(0.25), s−1(0.1), s0(0.1), s1(0.25), s2(0.3)} | {s−2(0.05), s−1(0.05), s0(0.1), s1(0.1), s2(0.7)} | {s−2(0.25), s−1(0.15), s0(0.2), s1(0.25), s2(0.15)} | |
| b2 | d1 | {s−2(0.05), s−1(0.35), s0(0.15), s1(0.15), s2(0.3)} | {s−2(0.1), s−1(0.15), s0(0.15), s1(0.2), s2(0.4)} | {s−2(0.35), s−1(0.2), s0(0.1), s1(0.2), s2(0.15)} | {s−2(0.05), s−1(0.15),s0(0.05), s1(0.35), s2(0.4)} |
| d2 | {s−2(0.3), s−1(0.1), s0(0.2), s1(0.2), s2(0.2)} | {s−2(0.35), s−1(0.1), s0(0.3), s1(0.15), s2(0.1)} | {s−2(0.25), s−1(0.1), s0(0.1), s1(0.35), s2(0.2)} | {s−2(0.2), s−1(0.1), s0(0.15), s1(0.2), s2(0.35)} | |
| d3 | {s−2(0.15), s−1(0.3), s0(0.05), s1(0.05), s2(0.45)} | {s−2(0.25), s−1(0.15), s0(0.2), s1(0.05), s2(0.35)} | {s−2(0.1), s−1(0.15), s0(0.1), s1(0.05), s2(0.6)} | {s−2(0.1), s−1(0.1), s0(0.15), s1(0.1), s2(0.55)} | |
| d4 | {s−2(0.2), s−1(0.15), s0(0.1), s1(0.15), s2(0.4)} | {s−2(0.15), s−1(0.2), s0(0.05), s1(0.1), s2(0.5)} | {s−2(0.15), s−1(0.2), s0(0.15), s1(0.35), s2(0.15)} | {s−2(0.05), s−1(0.15), s0(0.2), s1(0.05), s2(0.55)} | |
| b3 | d1 | {s−2(0.1), s−1(0.15), s0(0.25), s1(0.1), s2(0.4)} | {s−2(0.1), s−1(0.05), s0(0.35), s1(0.1), s2(0.4)} | / | {s−2(0.2), s−1(0.1), s0(0.15), s1(0.2), s2(0.35)} |
| d2 | {s−2(0.05), s−1(0.2), s0(0.5), s1(0.15), s2(0.1)} | {s−2(0.15), s−1(0.05), s0(0.25), s1(0.35), s2(0.2)} | {s−2(0.2), s−1(0.15), s0(0.05), s1(0.05), s2(0.55)} | {s−2(0.1), s−1(0.15), s0(0.35), s1(0.05), s2(0.35)} | |
| d3 | {s−2(0.2), s−1(0.25), s0(0.2), s1(0.15), s2(0.2)} | {s−2(0.2), s−1(0.15), s0(0.05), s1(0.2), s2(0.4)} | {s−2(0.2), s−1(0.35), s0(0.2), s1(0.2), s2(0.05)} | {s−2(0.35), s−1(0.25), s0(0.05), s1(0.15), s2(0.2)} | |
| d4 | {s−2(0.15), s−1(0.05), s0(0.15), s1(0.2), s2(0.45)} | {s−2(0.05), s−1(0.2), s0(0.15), s1(0.1), s2(0.5)} | {s−2(0.05), s−1(0.1), s0(0.15), s1(0.1), s2(0.6)} | {s−2(0.2), s−1(0.05), s0(0.15), s1(0.1), s2(0.5)} | |
| b4 | d1 | {s−2(0.1), s−1(0.15), s0(0.4), s1(0.2), s2(0.15)} | {s−2(0.1), s−1(0.2), s0(0.25), s1(0.35), s2(0.1)} | {s−2(0.15), s−1(0.1), s0(0.2), s1(0.25), s2(0.3)} | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.2), s2(0.25)} |
| d2 | {s−2(0.15), s−1(0.05), s0(0.35), s1(0.25), s2(0.2)} | {s−2(0.05), s−1(0.25), s0(0.1), s1(0.05), s2(0.55)} | {s−2(0.1), s−1(0.1), s0(0.35), s1(0.15), s2(0.3)} | {s−2(0.2), s−1(0.15), s0(0.35), s1(0.1), s2(0.2)} | |
| d3 | {s−2(0.15), s−1(0.1), s0(0.25), s1(0.05), s2(0.45)} | {s−2(0.1), s−1(0.05), s0(0.2), s1(0.05), s2(0.6)} | {s−2(0.25), s−1(0.15), s0(0.1), s1(0.05), s2(0.45)} | {s−2(0.1), s−1(0.25), s0(0.15), s1(0.1), s2(0.4)} | |
| d4 | {s−2(0.05), s−1(0.05), s0(0.15), s1(0.3), s2(0.45)} | {s−2(0.15), s−1(0.3), s0(0.15), s1(0.1), s2(0.3)} | {s−2(0.05), s−1(0.1), s0(0.35), s1(0.1), s2(0.4)} | {s−2(0.05), s−1(0.1), s0(0.05), s1(0.15), s2(0.65)} |
| a1 | a2 | a3 | a4 | ||
|---|---|---|---|---|---|
| a1 | f1 | / | / | {s−2(0.2), s−1(0.3), s0(0.25), s1(0.1), s2(0.15)} | {s−2(0.25), s−1(0.15), s0(0.35), s1(0.2), s2(0.1)} |
| f2 | / | {s−2(0.2), s−1(0.25), s0(0.2), s1(0.15), s2(0.2)} | {s−2(0.15), s−1(0.2), s0(0.05), s1(0.2), s2(0.4)} | {s−2(0.05), s−1(0.05), s0(0.2), s1(0.3), s2(0.4)} | |
| f3 | / | {s−2(0.05), s−1(0.05), s0(0.3), s1(0.1), s2(0.5)} | {s−2(0.35), s−1(0.15), s0(0.1), s1(0.25), s2(0.15)} | {s−2(0.2), s−1(0.05), s0(0.15), s1(0.35), s2(0.25)} | |
| f4 | / | {s−2(0.2), s−1(0.15), s0(0.35), s1(0.25), s2(0.05)} | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.35), s2(0.15)} | {s−2(0.1), s−1(0.2), s0(0.25), s1(0.05), s2(0.4)} | |
| a2 | f1 | {s−2(0.05), s−1(0.15), s0(0.05), s1(0.25), s2(0.5)} | / | {s−2(0.15), s−1(0.15), s0(0.05), s1(0.2), s2(0.45)} | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.15), s2(0.3)} |
| f2 | {s−2(0.1), s−1(0.4), s0(0.35), s1(0.05), s2(0.1)} | / | {s−2(0.2), s−1(0.1), s0(0.35), s1(0.25), s2(0.1)} | {s−2(0.35), s−1(0.05), s0(0.05), s1(0.1), s2(0.45)} | |
| f3 | {s−2(0.15), s−1(0.2), s0(0.25), s1(0.2), s2(0.2)} | / | {s−2(0.25), s−1(0.2), s0(0.05), s1(0.15), s2(0.35)} | {s−2(0.2), s−1(0.3), s0(0.35), s1(0.15), s2(0.0)} | |
| f4 | {s−2(0.1), s−1(0.1), s0(0.15), s1(0.05), s2(0.6)} | / | {s−2(0.05), s−1(0.25), s0(0.2), s1(0.15), s2(0.35)} | {s−2(0.05), s−1(0.35), s0(0.05), s1(0.2), s2(0.35)} | |
| a3 | f1 | {s−2(0.15), s−1(0.2), s0(0.25), s1(0.05), s2(0.35)} | {s−2(0.2), s−1(0.15), s0(0.25), s1(0.05), s2(0.35)} | / | {s−2(0.05), s−1(0.15), s0(0.2), s1(0.25), s2(0.35)} |
| f2 | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.15), s2(0.3)} | {s−2(0.15), s−1(0.2), s0(0.1), s1(0.2), s2(0.35)} | / | {s−2(0.3), s−1(0.25), s0(0.1), s1(0.25), s2(0.1)} | |
| f3 | {s−2(0.25), s−1(0.15), s0(0.2), s1(0.15), s2(0.25)} | {s−2(0.2), s−1(0.25), s0(0.25), s1(0.05), s2(0.25)} | / | {s−2(0.1), s−1(0.15), s0(0.15), s1(0.05), s2(0.55)} | |
| f4 | {s−2(0.15), s−1(0.2), s0(0.15), s1(0.2), s2(0.3)} | {s−2(0.15), s−1(0.05), s0(0.1), s1(0.25), s2(0.45)} | / | {s−2(0.15), s−1(0.2), s0(0.1), s1(0.1), s2(0.45)} | |
| a4 | f1 | {s−2(0.4), s−1(0.2), s0(0.25), s1(0.05), s2(0.1)} | {s−2(0.1), s−1(0.15), s0(0.25), s1(0.2), s2(0.3)} | {s−2(0.1), s−1(0.2), s0(0.2), s1(0.25), s2(0.25)} | / |
| f2 | {s−2(0.35), s−1(0.05), s0(0.2), s1(0.1), s2(0.3)} | {s−2(0.2), s−1(0.2), s0(0.2), s1(0.15), s2(0.25)} | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.05), s2(0.45)} | / | |
| f3 | {s−2(0.25), s−1(0.15), s0(0.15), s1(0.2), s2(0.25)} | {s−2(0.15), s−1(0.35), s0(0.15), s1(0.05), s2(0.35)} | {s−2(0.25), s−1(0.2), s0(0.1), s1(0.1), s2(0.35)} | / | |
| f4 | {s−2(0.15), s−1(0.1), s0(0.1), s1(0.25), s2(0.4)} | {s−2(0.15), s−1(0.1), s0(0.1), s1(0.25), s2(0.4)} | {s−2(0.2), s−1(0.25), s0(0.1), s1(0.35), s2(0.1)} | / |
| b1 | b2 | b3 | b4 | ||
|---|---|---|---|---|---|
| b1 | f1 | / | {s−2(0.4), s−1(0.2), s0(0.15), s1(0.2), s2(0.05)} | {s−2(0.25), s−1(0.25), s0(0.1), s1(0.2), s2(0.2)} | {s−2(0.05), s−1(0.25), s0(0.15), s1(0.1), s2(0.45)} |
| f2 | / | {s−2(0.35), s−1(0.25), s0(0.2), s1(0.1), s2(0.1)} | {s−2(0.2), s−1(0.25), s0(0.15), s1(0.2), s2(0.2)} | {s−2(0.2), s−1(0.1), s0(0.2), s1(0.2), s2(0.3)} | |
| f3 | / | {s−2(0.05), s−1(0.2), s0(0.25), s1(0.2), s2(0.3)} | {s−2(0.25), s−1(0.05), s0(0.15), s1(0.1), s2(0.45)} | {s−2(0.25), s−1(0.1), s0(0.25), s1(0.1), s2(0.3)} | |
| f4 | / | {s−2(0.25), s−1(0.1), s0(0.1), s1(0.25), s2(0.3)} | {s−2(0.1), s−1(0.2), s0(0.2), s1(0.2), s2(0.3)} | {s−2(0.2), s−1(0.25), s0(0.25), s1(0.15), s2(0.15)} | |
| b2 | f1 | {s−2(0.2), s−1(0.25), s0(0.05), s1(0.1), s2(0.4)} | / | {s−2(0.05), s−1(0.3), s0(0.35), s1(0.25), s2(0.05)} | {s−2(0.05), s−1(0.15), s0(0.05), s1(0.25), s2(0.5)} |
| f2 | {s−2(0.1), s−1(0.25), s0(0.1), s1(0.2), s2(0.35)} | / | {s−2(0.1), s−1(0.25), s0(0.05), s1(0.2), s2(0.4)} | {s−2(0.1), s−1(0.05), s0(0.15), s1(0.1), s2(0.6)} | |
| f3 | {s−2(0.2), s−1(0.05), s0(0.25), s1(0.05), s2(0.45)} | / | {s−2(0.25), s−1(0.15), s0(0.25), s1(0.2), s2(0.15)} | {s−2(0.2), s−1(0.15), s0(0.2), s1(0.25), s2(0.2)} | |
| f4 | {s−2(0.1), s−1(0.15), s0(0.1), s1(0.2), s2(0.45)} | / | {s−2(0.05), s−1(0.1), s0(0.2), s1(0.05), s2(0.6)} | {s−2(0.05), s−1(0.1), s0(0.05), s1(0.25), s2(0.55)} | |
| b3 | f1 | {s−2(0.2), s−1(0.2), s0(0.15), s1(0.35), s2(0.1)} | {s−2(0.2), s−1(0.25), s0(0.1), s1(0.1), s2(0.35)} | / | {s−2(0.25), s−1(0.15), s0(0.1), s1(0.25), s2(0.25)} |
| f2 | {s−2(0.15), s−1(0.15), s0(0.1), s1(0.25), s2(0.35)} | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.15), s2(0.3)} | / | {s−2(0.15), s−1(0.2), s0(0.2), s1(0.15), s2(0.3)} | |
| f3 | {s−2(0.1), s−1(0.35), s0(0.25), s1(0.15), s2(0.15)} | {s−2(0.05), s−1(0.2), s0(0.15), s1(0.3), s2(0.3)} | / | {s−2(0.1), s−1(0.2), s0(0.15), s1(0.05), s2(0.5)} | |
| f4 | {s−2(0.1), s−1(0.2), s0(0.15), s1(0.1), s2(0.45)} | {s−2(0.1), s−1(0.15), s0(0.2), s1(0.25), s2(0.3)} | / | {s−2(0.1), s−1(0.25), s0(0.2), s1(0.15), s2(0.3)} | |
| b4 | f1 | {s−2(0.15), s−1(0.25), s0(0.25), s1(0.15), s2(0.2)} | {s−2(0.15), s−1(0.35), s0(0.25), s1(0.15), s2(0.12)} | {s−2(0.25), s−1(0.1), s0(0.25), s1(0.2), s2(0.2)} | / |
| f2 | {s−2(0.2), s−1(0.1), s0(0.15), s1(0.1), s2(0.45)} | {s−2(0.15), s−1(0.1), s0(0.2), s1(0.15), s2(0.4)} | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.15), s2(0.35)} | / | |
| f3 | {s−2(0.25), s−1(0.2), s0(0.2), s1(0.2), s2(0.15)} | {s−2(0.1), s−1(0.2), s0(0.15), s1(0.2), s2(0.35)} | {s−2(0.3), s−1(0.1), s0(0.2), s1(0.15), s2(0.25)} | / | |
| f4 | {s−2(0.35), s−1(0.25), s0(0.15), s1(0.1), s2(0.15)} | {s−2(0.15), s−1(0.2), s0(0.1), s1(0.15), s2(0.4)} | {s−2(0.35), s−1(0.25), s0(0.15), s1(0.05), s2(0.2)} | / |
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| a1 | {s−2(0.25), s−1(0.2), s0(0.3), s1(0.2), s2(0.05)} | {s−2(0.3), s−1(0.2), s0(0.3), s1(0.1), s2(0.1)} | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.25), s2(0.2)} | {s−2(0.2), s−1(0.2), s0(0.35), s1(0.15), s2(0.1)} |
| a2 | {s−2(0.25), s−1(0.2), s0(0.15), s1(0.3), s2(0.1)} | {s−2(0.15), s−1(0.3), s0(0.15), s1(0.2), s2(0.2)} | {s−2(0.25), s−1(0.3), s0(0.2), s1(0.15), s2(0.1)} | {s−2(0.15), s−1(0.4), s0(0.1), s1(0.25), s2(0.1)} |
| a3 | {s−2(0.3), s−1(0.25), s0(0.25), s1(0.15), s2(0.05)} | {s−2(0.2), s−1(0.25), s0(0.35), s1(0.1), s2(0.1)} | {s−2(0.3), s−1(0.15), s0(0.2), s1(0.25), s2(0.1)} | {s−2(0.25), s−1(0.3), s0(0.25), s1(0.05), s2(0.15)} |
| a4 | {s−2(0.25), s−1(0.2), s0(0.25), s1(0.15), s2(0.15)} | {s−2(0.25), s−1(0.1), s0(0.2), s1(0.25), s2(0.2)} | {s−2(0.1), s−1(0.35), s0(0.25), s1(0.2), s2(0.1)} | {s−2(0.2), s−1(0.35), s0(0.1), s1(0.2), s2(0.15)} |
| d1 | d2 | d3 | d4 | |
|---|---|---|---|---|
| b1 | {s−2(0.25), s−1(0.2), s0(0.3), s1(0.1), s2(0.15)} | {s−2(0.25), s−1(0.2), s0(0.2), s1(0.2), s2(0.15)} | {s−2(0.2), s−1(0.2), s0(0.15), s1(0.4), s2(0.05)} | {s−2(0.25), s−1(0.15), s0(0.2), s1(0.25), s2(0.15)} |
| b2 | {s−2(0.35), s−1(0.2), s0(0.1), s1(0.2), s2(0.15)} | {s−2(0.35), s−1(0.1), s0(0.3), s1(0.15), s2(0.1)} | {s−2(0.25), s−1(0.2), s0(0.15), s1(0.05), s2(0.35)} | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.35), s2(0.15)} |
| b3 | {s−2(0.2), s−1(0.15), s0(0.15), s1(0.15), s2(0.35)} | {s−2(0.2), s−1(0.15), s0(0.4), s1(0.15), s2(0.05)} | {s−2(0.35), s−1(0.2), s0(0.1), s1(0.2), s2(0.15)} | {s−2(0.2), s−1(0.2), s0(0.1), s1(0.2), s2(0.15)} |
| b4 | {s−2(0.25), s−1(0.1), s0(0.3), s1(0.25), s2(0.1)} | {s−2(0.2), s−1(0.15), s0(0.35), s1(0.1), s2(0.2)} | {s−2(0.25), s−1(0.15), s0(0.1), s1(0.1), s2(0.4)} | {s−2(0.15), s−1(0.3), s0(0.15), s1(0.1), s2(0.3)} |
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| a1 | {s−2(0.2), s−1(0.3), s0(0.25), s1(0.15), s2(0.1)} | {s−2(0.2), s−1(0.25), s0(0.2), s1(0.15), s2(0.2)} | {s−2(0.35), s−1(0.15), s0(0.1), s1(0.25), s2(0.15)} | {s−2(0.2), s−1(0.15), s0(0.35), s1(0.25), s2(0.05)} |
| a2 | {s−2(0.3), s−1(0.15), s0(0.1), s1(0.15), s2(0.3)} | {s−2(0.35), s−1(0.15), s0(0.35), s1(0.05), s2(0.1)} | {s−2(0.25), s−1(0.25), s0(0.35), s1(0.15), s2(0)} | {s−2(0.1), s−1(0.3), s0(0.1), s1(0.15), s2(0.35)} |
| a3 | {s−2(0.2), s−1(0.25), s0(0.15), s1(0.05), s2(0.35)} | {s−2(0.3), s−1(0.25), s0(0.1), s1(0.25), s2(0.1)} | {s−2(0.35), s−1(0.1), s0(0.25), s1(0.05), s2(0.25)} | {s−2(0.2), s−1(0.15), s0(0.2), s1(0.15), s2(0.3)} |
| a4 | {s−2(0.4), s−1(0.2), s0(0.25), s1(0.05), s2(0.1)} | {s−2(0.35), s−1(0.05), s0(0.2), s1(0.15), s2(0.25)} | {s−2(0.25), s−1(0.2), s0(0.15), s1(0.15), s2(0.25)} | {s−2(0.25), s−1(0.2), s0(0.1), s1(0.35), s2(0.1)} |
| d1 | d2 | d3 | d4 | |
|---|---|---|---|---|
| b1 | {s−2(0.4), s−1(0.2), s0(0.15), s1(0.2), s2(0.05)} | {s−2(0.35), s−1(0.25), s0(0.25), s1(0.1), s2(0.05)} | {s−2(0.25), s−1(0.1), s0(0.25), s1(0.1), s2(0.3)} | {s−2(0.25), s−1(0.2), s0(0.25), s1(0.15), s2(0.15)} |
| b2 | {s−2(0.2), s−1(0.25), s0(0.25), s1(0.25), s2(0.05)} | {s−2(0.1), s−1(0.25), s0(0.1), s1(0.2), s2(0.35)} | {s−2(0.25), s−1(0.2), s0(0.2), s1(0.2), s2(0.15)} | {s−2(0.1), s−1(0.2), s0(0.05), s1(0.25), s2(0.4)} |
| b3 | {s−2(0.25), s−1(0.2), s0(0.1), s1(0.35), s2(0.1)} | {s−2(0.25), s−1(0.2), s0(0.2), s1(0.1), s2(0.15)} | {s−2(0.15), s−1(0.3), s0(0.25), s1(0.15), s2(0.15)} | {s−2(0.2), s−1(0.15), s0(0.2), s1(0.15), s2(0.3)} |
| b4 | {s−2(0.25), s−1(0.25), s0(0.25), s1(0.15), s2(0.1)} | {s−2(0.25), s−1(0.1), s0(0.15), s1(0.15), s2(0.35)} | {s−2(0.3), s−1(0.15), s0(0.2), s1(0.2), s2(0.15)} | {s−2(0.35), s−1(0.25), s0(0.15), s1(0.1), s2(0.15)} |
| b1 | b2 | b3 | b4 | |
|---|---|---|---|---|
| a1 | 42 | 28 | 17 | 33 |
| a2 | 50 | 20 | 40 | 20 |
| a3 | 31 | 27 | 25 | 18 |
| a4 | 46 | 34 | 58 | 55 |
| Two-Sided Matching Method | Optimal Matching Alternative |
|---|---|
| Wang et al.’s model considering peer effects [65] (model I) | |
| Lu et al.’s model considering social network relationships [67] (model II) | |
| Model considering agent behavior factors (The proposed model, model III) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, M.; Hu, S.; Wang, Y.; Xiao, J. A Dynamic Social Network Matching Model for Virtual Power Plants and Distributed Energy Resources with Probabilistic Linguistic Information. Sustainability 2022, 14, 14920. https://doi.org/10.3390/su142214920
Cai M, Hu S, Wang Y, Xiao J. A Dynamic Social Network Matching Model for Virtual Power Plants and Distributed Energy Resources with Probabilistic Linguistic Information. Sustainability. 2022; 14(22):14920. https://doi.org/10.3390/su142214920
Chicago/Turabian StyleCai, Mei, Suqiong Hu, Ya Wang, and Jingmei Xiao. 2022. "A Dynamic Social Network Matching Model for Virtual Power Plants and Distributed Energy Resources with Probabilistic Linguistic Information" Sustainability 14, no. 22: 14920. https://doi.org/10.3390/su142214920
APA StyleCai, M., Hu, S., Wang, Y., & Xiao, J. (2022). A Dynamic Social Network Matching Model for Virtual Power Plants and Distributed Energy Resources with Probabilistic Linguistic Information. Sustainability, 14(22), 14920. https://doi.org/10.3390/su142214920