
Design and Verification of Process Discovery Based on NLP Approach and Visualization for Manufacturing Industry





Abstract
:1. Introduction
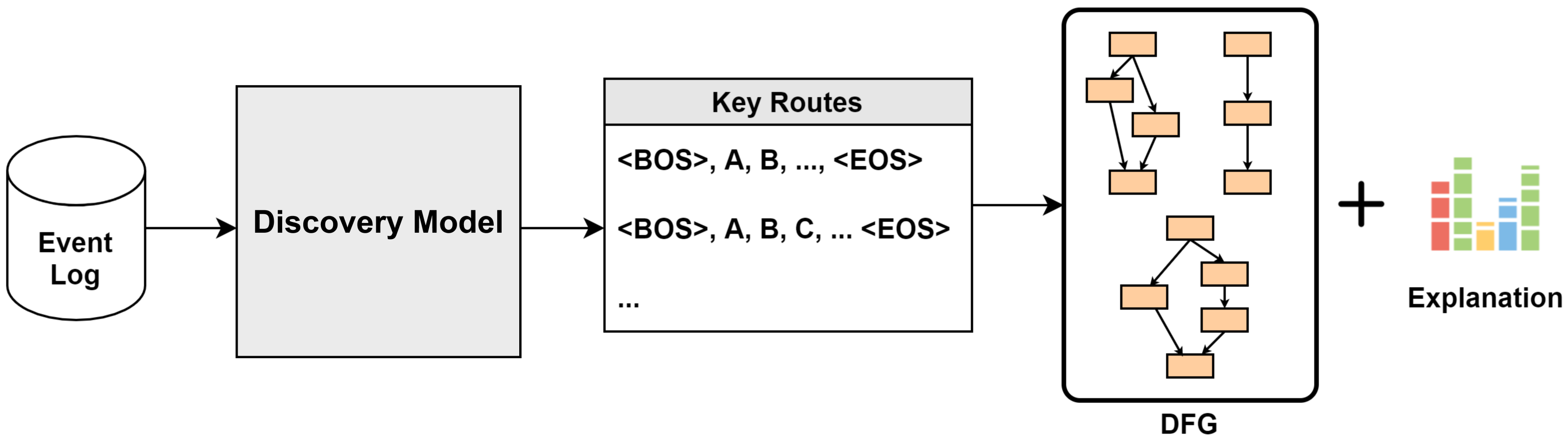
- We propose an automated process discovery framework that can be used on actual industrial sites, such as smart factory consulting, which is difficult to define recent processes. The framework includes the overall flow to be studied in this paper and provides an appropriate pre-processing process for the event log datasets, the method of applying the discovery model, and the entire process in which the visualized insights are delivered to users. Based on this framework, we propose a process-monitoring system solution that can be used in various manufacturing fields.
- Previous studies have shown that the application of powerful natural language processing (NLP) to event logs can be effectively used to predict the next event and unearth the entire process [11]. In this study, the transformer model based on the attention mechanism was applied to event prediction in various industries, and excellent research results were obtained. In this study, we were not satisfied with the detailed event prediction, but we enabled automation of the discovery of manufacturing processes in the smart factory, and through this, we wanted to help provide a more sustainable and enhanced monitoring system by introducing an automated process discovery system to the existing monitoring system that has only depended on the manual work of consultants. First, using the event log, data preprocessing suitable for effective process discovery is performed. Data preprocessing is performed in a specific manner to increase the prediction precision of the model. Subsequently, we learn from the proposed process discovery model. In conclusion, including data preprocessing in the model improves the overall performance indicators and precision. Through the discovery model, a modified version of the generative pre-training of language model 2 (GPT-2), a transformer model based on full-attention mechanism linked to previous studies, is presented. This proves that the powerful performance of the model can be applied to process discoveries.
- In addition, the model is explained using various techniques employed in eXplainable artificial intelligence (XAI), such as directly-follows graph (DFG) and local interpretable model-agnostic explanations (LIME). By explaining the model this way, it can be adopted as a meaningful indicator when consulting smart factory solutions. By visualizing the discovery process and deriving insights using the XAI technique, we want to help consultants, developers, and managers.
2. Related Work
2.1. Event Log for Manufacturing
2.2. Process Discovery for Manufacturing
2.3. NLP Approach
2.3.1. Attention Mechanism
2.3.2. Transformer
3. Transformer-Based Process Discovery
3.1. Process Discovery Framework
3.2. Discovery Model
4. Experiment and Results
4.1. Datasets
4.2. Data Pre-Processing
4.2.1. Sequence
4.2.2. Attribute
4.3. Analysis of Visualization on Process Discovery
4.4. Results
4.4.1. Discovery Verification
4.4.2. LIME Verification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Furstenau, L.B.; Sott, M.K.; Kipper, L.M.; Machado, E.L.; Lopez-Robles, J.R.; Dohan, M.S.; Cobo, M.J.; Zahid, A.; Abbasi, Q.H.; Imran, M.A. Link between sustainability and industry 4.0: Trends, challenges and new perspectives. IEEE Access 2020, 8, 140079–140096. [Google Scholar] [CrossRef]
- Li, J.; Wang, H.J.; Bai, X. An intelligent approach to data extraction and task identification for process mining. Inf. Syst. Front. 2015, 17, 1195–1208. [Google Scholar] [CrossRef]
- Pfeiffer, P.; Lahann, J.; Fettke, P. Multivariate Business Process Representation Learning utilizing Gramian Angular Fields and Convolutional Neural Networks. arXiv 2021, arXiv:2106.08027. [Google Scholar]
- Lugaresi, G.; Matta, A. Automated manufacturing system discovery and digital twin generation. J. Manuf. Syst. 2021, 59, 51–66. [Google Scholar] [CrossRef]
- Chambers, A.J.; Stringfellow, A.M.; Luo, B.B.; Underwood, S.J.; Allard, T.G.; Johnston, I.A.; Brockman, S.; Shing, L.; Wollaber, A.; VanDam, C. Automated Business Process Discovery from Unstructured Natural-Language Documents. In International Conference on Business Process Management; Springer: Cham, Switzerland, 2020; pp. 232–243. [Google Scholar]
- Neu, D.A.; Lahann, J.; Fettke, P. A systematic literature review on state-of-the-art deep learning methods for process prediction. In Artificial Intelligence Review; Springer: New York, NY, USA, 2021; pp. 1–27. [Google Scholar]
- Di Francescomarino, C.; Ghidini, C.; Maggi, F.M.; Petrucci, G.; Yeshchenko, A. An eye into the future: Leveraging a-priori knowledge in predictive business process monitoring. In International Conference on Business Process Management; Springer: Cham, Switzerland, 2017; pp. 252–268. [Google Scholar]
- Evermann, J.; Rehse, J.R.; Fettke, P. Predicting process behaviour using deep learning. Decis. Support Syst. 2017, 100, 129–140. [Google Scholar] [CrossRef] [Green Version]
- Mehdiyev, N.; Evermann, J.; Fettke, P. A novel business process prediction model using a deep learning method. Bus. Inf. Syst. Eng. 2020, 62, 143–157. [Google Scholar] [CrossRef] [Green Version]
- Baiyere, A.; Salmela, H.; Tapanainen, T. Digital transformation and the new logics of business process management. Eur. J. Inf. Syst. 2020, 29, 238–259. [Google Scholar] [CrossRef]
- Moon, J.; Park, G.; Jeong, J. POP-ON: Prediction of Process Using One-Way Language Model Based on NLP Approach. Appl. Sci. 2021, 11, 864. [Google Scholar] [CrossRef]
- Saura, J.R. Using data sciences in digital marketing: Framework, methods, and performance metrics. J. Innov. Knowl. 2021, 6, 92–102. [Google Scholar] [CrossRef]
- De Leoni, M.; van der Aalst, W.M.; Dees, M. A general process mining framework for correlating, predicting and clustering dynamic behavior based on event logs. Inf. Syst. 2016, 56, 235–257. [Google Scholar] [CrossRef]
- Philipp, P.; Georgi, R.X.M.; Beyerer, J.; Robert, S. Analysis of control flow graphs using graph convolutional neural networks. In Proceedings of the 2019 6th International Conference on Soft Computing & Machine Intelligence (ISCMI), Johannesburg, South Africa, 19–20 November 2019; pp. 73–77. [Google Scholar]
- Van der Aalst, W.M.; Schonenberg, M.H.; Song, M. Time prediction based on process mining. Inf. Syst. 2011, 36, 450–475. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, D.R.; Vasilyev, E. Using logical decision trees to discover the cause of process delays from event logs. Comput. Ind. 2015, 70, 194–207. [Google Scholar] [CrossRef]
- Verenich, I.; Dumas, M.; La Rosa, M.; Nguyen, H. Predicting process performance: A white-box approach based on process models. J. Softw. Evol. Process. 2019, 31, e2170. [Google Scholar] [CrossRef] [Green Version]
- Pan, Y.; Zhang, L. Automated process discovery from event logs in BIM construction projects. Autom. Constr. 2021, 127, 103713. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. Roles of artificial intelligence in construction engineering and management: A critical review and future trends. Autom. Constr. 2021, 122, 103517. [Google Scholar] [CrossRef]
- De Leoni, M.; Van der Aalst, W.M.; Dees, M. A general framework for correlating business process characteristics. In International Conference on Business Process Management; Springer: Cham, Switzerland, 2014; pp. 250–266. [Google Scholar]
- Polato, M.; Sperduti, A.; Burattin, A.; de Leoni, M. Data-aware remaining time prediction of business process instances. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 816–823. [Google Scholar]
- Tax, N.; Verenich, I.; La Rosa, M.; Dumas, M. Predictive business process monitoring with LSTM neural networks. In International Conference on Advanced Information Systems Engineering; Springer: Cham, Switzerland, 2017; pp. 477–492. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 20 November 2021).
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. 2014. Available online: https://proceedings.neurips.cc/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf (accessed on 5 December 2021).
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. arXiv 2015, arXiv:1506.07503. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.cs.ubc.ca/amuham01/LING530/papers/radford2018improving.pdf (accessed on 29 October 2021).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI blog 2019, 1, 9. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Belinkov, Y.; Glass, J. Analysis methods in neural language processing: A survey. Trans. Assoc. Comput. Linguist. 2019, 7, 49–72. [Google Scholar] [CrossRef]
- Ethayarajh, K. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. arXiv 2019, arXiv:1909.00512. [Google Scholar]
- Klinkmüller, C.; Weber, I. Analyzing control flow information to improve the effectiveness of process model matching techniques. Decis. Support Syst. 2017, 100, 6–14. [Google Scholar] [CrossRef]
- Kuss, E.; Stuckenschmidt, H. Automatic classification to matching patterns for process model matching evaluation. In CEUR Workshop Proceedings; RWTH: Aachen, Germany, 2017; Volume 1979, pp. 306–319. [Google Scholar]
- Safitri, L.N.; Sarno, R.; Budiawati, G.I. Improving Business Process by Evaluating Enterprise Sustainability Indicators using Fuzzy Rule Based Classification. In Proceedings of the 2018 International Seminar on Application for Technology of Information and Communication, Kuala Lumpur, Malaysia, 23–25 July 2018; pp. 55–60. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, Z. Ensemble Methods: Foundations and Algorithms; Chapman & Hall/Crc Machine Learning: New York, NY, USA, 2012. [Google Scholar]
- Levy, D. Production Analysis with Process Mining Technology. Dataset. 2014. Available online: https://data.4tu.nl/articles/dataset/Production_Analysis_with_Process_Mining_Technology/12697997/1 (accessed on 10 October 2021).
- Colombo, A.W.; Bangemann, T.; Karnouskos, S.; Delsing, J.; Stluka, P.; Harrison, R.; Jammes, F.; Lastra, J.L. Industrial cloud-based cyber-physical systems. Imc-Aesop Approach 2014, 22, 4–5. [Google Scholar]
- Tello-Leal, E.; Roa, J.; Rubiolo, M.; Ramirez-Alcocer, U.M. Predicting activities in business processes with LSTM recurrent neural networks. In Proceedings of the 2018 ITU Kaleidoscope: Machine Learning for a 5G Future (ITU K), Santa Fe, Argentina, 26–28 November 2018; pp. 1–7. [Google Scholar]
- Riedl, M.; Biemann, C. Using semantics for granularities of tokenization. Comput. Linguist. 2018, 44, 483–524. [Google Scholar] [CrossRef]
- Van Der Aalst, W.M. A Practitioner’s Guide to Process Mining: Limitations of the Directly-Follows Graph; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Van Der Aalst, W. Data science in action. In Process Mining; Springer: Berlin, Germany, 2016; pp. 3–23. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery: San Francisco, CA, USA, 2016; pp. 1135–1144. [Google Scholar]
- Ryo, M.; Angelov, B.; Mammola, S.; Kass, J.M.; Benito, B.M.; Hartig, F. Explainable artificial intelligence enhances the ecological interpretability of black-box species distribution models. Ecography 2021, 44, 199–205. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case ID | Activity | Resource | Start Timestamp | … | Part Desc |
|---|---|---|---|---|---|
| Case 1 | Turning & Milling—Machine 4 | Machine 4—Turning & Milling | 29 January 2012 23:24 | … | Cable Head |
| Case 1 | Turning & Milling—Machine 4 | Machine 4—Turning & Milling | 30 January 2012 5:44 | … | Cable Head |
| Case 1 | Turning & Milling—Machine 4 | Machine 4—Turning & Milling | 30 January 2012 6:59 | … | Cable Head |
| Case 1 | Lapping—Machine 1 | Machine 1—Lapping | 14 February 2012 0:00 | … | Cable Head |
| Case 1 | Lapping—Machine 1 | Machine 1—Lapping | 14 February 2012 9:05 | … | Cable Head |
| Case 1 | Lapping—Machine 1 | Machine 1—Lapping | 14 February 2012 9:05 | … | Cable Head |
| Case 1 | Round Grinding—Machine 3 | Machine 3—Round Grinding | 14 February 2012 9:13 | … | Cable Head |
| Case 1 | Round Grinding—Machine 3 | Machine 3—Round Grinding | 14 February 2012 13:37 | … | Cable Head |
| Case 1 | Final Inspection Q.C. | Quality Check 1 | 16 February 2012 6:59 | … | Cable Head |
| Case 1 | Packing | Packing | 17 February 2012 0:00 | … | Cable Head |
| Case 1 | … | … | … | … | … |
| Event Name | Full Log Number of Occurrences | Number of Cases with Events |
|---|---|---|
| Change Version | 1 | 1 |
| Deburring | 1 | 1 |
| Final Inspection | 1 | 1 |
| Final Inspection Q.C. | 164 | 122 |
| Fix | 2 | 2 |
| Fix EDM | 1 | 1 |
| Flat Grinding | 46 | 41 |
| Grinding Rework | 17 | 14 |
| Lapping | 109 | 85 |
| Laser Marking | 119 | 112 |
| Milling | 6 | 5 |
| Milling Q.C. | 1 | 1 |
| Nitration Q.C. | 1 | 1 |
| Packing | 128 | 121 |
| Rework Milling | 1 | 1 |
| Round Q.C. | 2 | 1 |
| Round Grinding | 90 | 67 |
| SETUP Turning & Milling | 3 | 3 |
| Setup | 2 | 2 |
| Turn & Mill. & Screw Assembly | 3 | 1 |
| Turning | 19 | 15 |
| Turning & Milling | 168 | 109 |
| Turning & Milling Q.C | 172 | 114 |
| Turning Q.C. | 24 | 17 |
| Wire Cut | 2 | 2 |
| Token | ID |
|---|---|
| <PAD> | 0 |
| <BOS> | 1 |
| <EOS> | 2 |
| A | 3 |
| B | 4 |
| C | 5 |
| D | 6 |
| Input Sequence | [‘<BOS>’, ‘SETUP Turning & Milling’, ‘Turning & Milling’, ‘Laser Marking’] | |
|---|---|---|
| Target Token | ‘Turning & Milling Q.C’ | |
| Input Attribute | Work Order Qty | |
| Machine | Quality Check 1 | |
| Part Desc | Cable Head | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moon, J.; Park, G.; Yang, M.; Jeong, J. Design and Verification of Process Discovery Based on NLP Approach and Visualization for Manufacturing Industry. Sustainability 2022, 14, 1103. https://doi.org/10.3390/su14031103
Moon J, Park G, Yang M, Jeong J. Design and Verification of Process Discovery Based on NLP Approach and Visualization for Manufacturing Industry. Sustainability. 2022; 14(3):1103. https://doi.org/10.3390/su14031103
Chicago/Turabian StyleMoon, Junhyung, Gyuyoung Park, Minyeol Yang, and Jongpil Jeong. 2022. "Design and Verification of Process Discovery Based on NLP Approach and Visualization for Manufacturing Industry" Sustainability 14, no. 3: 1103. https://doi.org/10.3390/su14031103
APA StyleMoon, J., Park, G., Yang, M., & Jeong, J. (2022). Design and Verification of Process Discovery Based on NLP Approach and Visualization for Manufacturing Industry. Sustainability, 14(3), 1103. https://doi.org/10.3390/su14031103