
Predicting Online Complaining Behavior in the Hospitality Industry: Application of Big Data Analytics to Online Reviews



Abstract
:1. Introduction
- To explore the literature related to big data analytics and data mining with regard to the fields of hospitality and tourism;
- To investigate the best performance model in predicting OCB in the fields of hospitality and tourism;
- To predict the complaint attributions that significantly differ, from various hotel classes (i.e., higher star-rating and lower star-rating) of travelers in terms of their OCB.
2. Theoretical Background and Research Scope
2.1. Online Review and Complaining Behavior in the Hospitality Industry
2.2. Big Data
2.3. Data Mining
2.4. Decision Tree
2.4.1. C5.0 Algorithm
2.4.2. CHAID Algorithm
2.4.3. QUEST Algorithm
2.4.4. C&RT Algorithm
3. Materials and Methods
3.1. Data Preparation and Processing
3.1.1. Step 1: Data Collection and Sample Characteristics
3.1.2. Step 2: Coding of Online Complaining Attributes
3.1.3. Step 3: Coding Reliability Testing
3.2. Modeling of Decision Tree Algorithms
4. Empirical Results
4.1. Model Evaluations
4.2. Attribute Assessment (Sensitivity Analysis)
4.3. Online Complaining Behavior for Different Hotel Classes
5. Discussion and Practical Implications
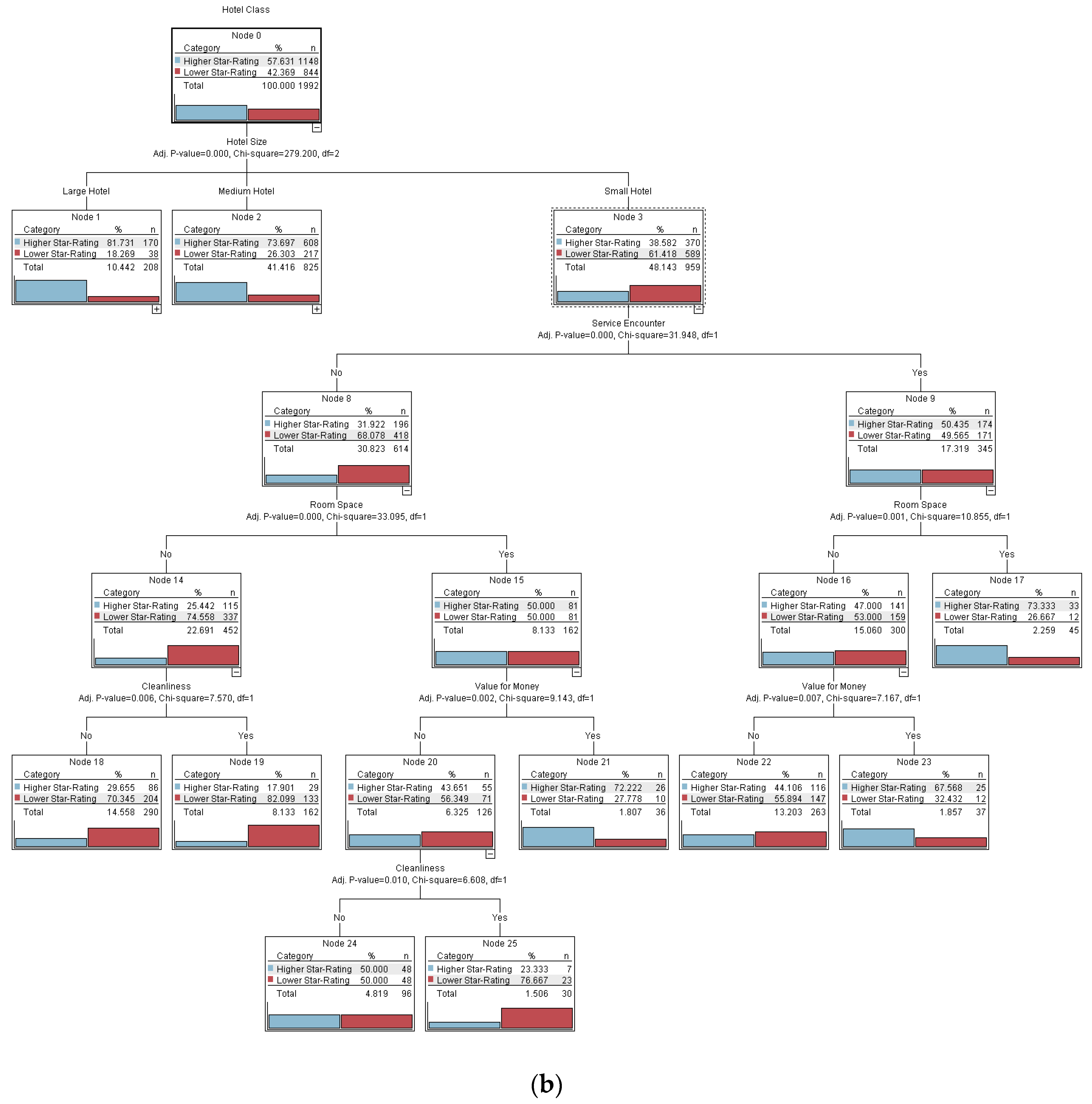
- (i)
- On average, approximately 78% of higher-star-rating hotel guests staying at medium and large hotels are likely to leave online complaints, while only around 61% of lower-star-rating hotel guests staying at small hotels leave online complaints.
- (ii)
- Guests of higher-star-rating hotels who stay at large hotels are most likely to leave online complaints about Service Encounter.
- (iii)
- Guests of higher-star-rating hotels who stay at medium-sized hotels are most likely to leave online complaints about Value for Money and also complain about Service Encounter.
- (iv)
- Guests of higher star-rating hotels who stay at small-sized hotels are more likely to leave online complaints about Room Space and also to complain about Service Encounter. Additionally, guests of lower-star-rating hotels, staying at small-sized hotels, are most likely to leave online complaints about Cleanliness, but not about Value for Money, Room Space, or Service Encounter.
“[…] however, it does not deserve its 5-star rating. The housekeeping left much to be desired. There was a 3-hour delay on receiving non-allergenic bedding despite being requested in good time … They were slow to supply … the customer care attitude was poor … Terribly cramped and no space to place luggage, etc. … and lack of security on the front door.”
“Cheap but no sleep … It’s cheap and cheerful, although the level of cleanliness could definitely be improved—some staining to pillowcases and towels etc., and a fairly unpleasant smell about the room… I still won’t recommend you to have a sleep in the 2-star…”
6. Conclusions and Future Research Recommendations
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lee, M.; Youn, S. Electronic word of mouth (eWOM) How eWOM platforms influence consumer product judgement. Int. J. Advert. 2009, 28, 473–499. [Google Scholar] [CrossRef]
- Babić Rosario, A.; Sotgiu, F.; de Valck, K.; Bijmolt, T.H. The effect of electronic word of mouth on sales: A meta-analytic review of platform, product, and metric factors. J. Mark. Res. 2016, 53, 297–318. [Google Scholar] [CrossRef]
- Fernandes, T.; Fernandes, F. Sharing Dissatisfaction Online: Analyzing the Nature and Predictors of Hotel Guests Negative Reviews. J. Hosp. Mark. Manag. 2018, 27, 127–150. [Google Scholar] [CrossRef]
- Donthu, N.; Kumar, S.; Pandey, N.; Pandey, N.; Mishra, A. Mapping the electronic word-of-mouth (eWOM) research: A systematic review and bibliometric analysis. J. Bus. Res. 2021, 135, 758–773. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, L.; Guo, X.; Law, R. The influence of online reviews to online hotel booking intentions. Int. J. Contemp. Hosp. Manag. 2015, 27, 1343–1364. [Google Scholar] [CrossRef]
- Ladhari, R.; Michaud, M. eWOM effects on hotel booking intentions, attitudes, trust, and website perceptions. Int J. Hosp. Manag. 2015, 46, 36–45. [Google Scholar] [CrossRef]
- Casaló, L.V.; Flavián, C.; Guinalíu, M.; Ekinci, Y. Avoiding the dark side of positive online consumer reviews: Enhancing reviews’ usefulness for high risk-averse travelers. J. Bus. Res. 2015, 68, 1829–1835. [Google Scholar] [CrossRef]
- Mellinas, J.P.; Maria-Dolores, S.M.M.; Garcia, J.J.B. Effects of the Booking.com scoring system. Tour. Manag. 2016, 57, 80–83. [Google Scholar] [CrossRef]
- Guerreiro, J.; Moro, S. Are Yelp′s tips helpful in building influential consumers? Tour. Manag. Perspect. 2017, 24, 151–154. [Google Scholar] [CrossRef]
- Tsao, W.C.; Hsieh, M.T.; Shih, L.W.; Lin, T.M.Y. Compliance with eWOM: The influence of hotel reviews on booking intention from the perspective of consumer conformity. Int J. Hosp. Manag. 2015, 46, 99–111. [Google Scholar] [CrossRef]
- Abubakar, A.M.; Ilkan, M. Impact of online WOM on destination trust and intention to travel: A medical tourism perspective. J. Destin. Mark. Manag. 2016, 5, 192–201. [Google Scholar] [CrossRef]
- Liu, Y.; Teichert, T.; Rossi, M.; Li, H.X.; Hu, F. Big data for big insights: Investigating language-specific drivers of hotel satisfaction with 412,784 user-generated reviews. Tour. Manag. 2017, 59, 554–563. [Google Scholar] [CrossRef]
- Hu, N.; Zhang, T.; Gao, B.; Bose, I. What do hotel customers complain about? Text analysis using structural topic model. Tour. Manag. 2019, 72, 417–426. [Google Scholar] [CrossRef]
- Yu, F.; Li, G.; Chen, H.; Guo, Y.; Yuan, Y.; Coulton, B. A VRF charge fault diagnosis method based on expert modification C5.0 decision tree. Int. J. Refrig. 2018, 92, 106–112. [Google Scholar] [CrossRef]
- Delen, D.; Kuzey, C.; Uyar, A. Measuring firm performance using financial ratios: A decision tree approach. Expert Syst. Appl. 2013, 40, 3970–3983. [Google Scholar] [CrossRef]
- Hsiao, Y.H.; Chen, L.F.; Choy, Y.L.; Su, C.T. A novel framework for customer complaint management. Serv. Ind. J. 2016, 36, 675–698. [Google Scholar] [CrossRef]
- Kim, S.S.; Timothy, D.J.; Hwang, J.S. Understanding Japanese tourists’ shopping preferences using the Decision Tree Analysis method. Tour. Manag. 2011, 32, 544–554. [Google Scholar] [CrossRef]
- Choi, C. Predicting Customer Complaints in Mobile Telecom Industry Using Machine Learning Algorithms. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2018. [Google Scholar]
- Chae, Y.M.; Ho, S.H.; Cho, K.W.; Lee, D.H.; Ji, S.H. Data mining approach to policy analysis in a health insurance domain. Int J. Med. Inform. 2001, 62, 103–111. [Google Scholar] [CrossRef]
- Nourani, V.; Molajou, A. Application of a hybrid association rules/decision tree model for drought monitoring. Glob. Planet. Change 2017, 159, 37–45. [Google Scholar] [CrossRef]
- Lee, P.J.; Hu, Y.H.; Lu, K.T. Assessing the helpfulness of online hotel reviews: A classification-based approach. Telemat. Inform. 2018, 35, 436–445. [Google Scholar] [CrossRef]
- Taamneh, M. Investigating the role of socio-economic factors in comprehension of traffic signs using decision tree algorithm. J. Saf. Res. 2018, 66, 121–129. [Google Scholar] [CrossRef] [PubMed]
- Lan, T.; Zhang, Y.N.; Jiang, C.H.; Yang, G.B.; Zhao, Z.Y. Automatic identification of Spread F using decision trees. J. Atmos. Sol. Terr. Phys. 2018, 179, 389–395. [Google Scholar] [CrossRef]
- Anand, R.V.; Dinakaran, M. Handling stakeholder conflict by agile requirement prioritization using Apriori technique. Comput. Electr. Eng. 2017, 61, 126–136. [Google Scholar] [CrossRef]
- Kalgotra, P.; Sharda, R. BIARAM: A process for analyzing correlated brain regions using association rule mining. Comput. Methods Programs Biomed. 2018, 162, 99–108. [Google Scholar] [CrossRef] [PubMed]
- Spreafico, C.; Russo, D.; Spreafico, M. Investigating the evolution of pyrolysis technologies through bibliometric analysis of patents and papers. J. Anal. Appl. Pyrolysis 2021, 159, 105021. [Google Scholar] [CrossRef]
- Jabbour, S.; Mazouri, F.E.E.; Sais, L. Mining negatives association rules using constraints. Procedia Comput. Sci. 2018, 127, 481–488. [Google Scholar] [CrossRef]
- Casaló, L.V.; Flavián, C.; Guinalíu, M.; Ekinci, Y. Do online hotel rating schemes influence booking behaviors? Int J. Hosp. Manag. 2015, 49, 28–36. [Google Scholar] [CrossRef]
- Sparks, B.A.; Browning, V. The impact of online reviews on hotel booking intentions and perception of trust. Tour. Manag. 2011, 32, 1310–1323. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, Z.; Yang, Y. The power of expert identity: How website-recognized expert reviews influence travelers′ online rating behavior. Tour. Manag. 2016, 55, 15–24. [Google Scholar] [CrossRef]
- Dinçer, M.Z.; Alrawadieh, Z. Negative word of mouse in the hotel industry: A content analysis of online reviews on luxury hotels in Jordan. J. Hosp. Mark. Manag. 2017, 26, 785–804. [Google Scholar] [CrossRef]
- Yuksel, A.; Kilinc, U.; Yuksel, F. Cross-national analysis of hotel customers’ attitudes toward complaining and their complaining behaviours. Tour. Manag. 2006, 27, 11–24. [Google Scholar] [CrossRef]
- Ngai, E.W.T.; Heung, V.C.S.; Wong, Y.H.; Chan, F.K.Y. Consumer complaint behaviour of Asians and non-Asians about hotel services—An empirical analysis. Eur. J. Mark. 2007, 41, 1375–1391. [Google Scholar] [CrossRef]
- Koc, E. Service failures and recovery in hospitality and tourism: A review of literature and recommendations for future research. J. Hosp. Mark. Manag. 2019, 28, 513–537. [Google Scholar] [CrossRef]
- Arora, S.D.; Chakraborty, A. Intellectual structure of consumer complaining behavior (CCB) research: A bibliometric analysis. J. Bus. Res. 2021, 122, 60–74. [Google Scholar] [CrossRef]
- Tosun, P.; Sezgin, S.; Uray, N. Consumer complaining behavior in hospitality management. J. Hosp. Mark. Manag. 2021, 31, 247–264. [Google Scholar] [CrossRef]
- Cantallops, A.S.; Salvi, F. New consumer behavior: A review of research on eWOM and hotels. Int J. Hosp. Manag. 2014, 36, 41–51. [Google Scholar] [CrossRef]
- Xiang, Z.; Du, Q.; Ma, Y.; Fan, W. A comparative analysis of major online review platforms: Implications for social media analytics in hospitality and tourism. Tour. Manag. 2017, 58, 51–65. [Google Scholar] [CrossRef]
- Xiang, Z.; Fesenmaier, D.R.; Werthner, H. Knowledge Creation in Information Technology and Tourism: A Critical Reflection and an Outlook for the Future. J. Travel Res. 2021, 60, 1371–1376. [Google Scholar] [CrossRef]
- Erevelles, S.; Fukawa, N.; Swayne, L. Big Data consumer analytics and the transformation of marketing. J. Bus. Res. 2016, 69, 897–904. [Google Scholar] [CrossRef]
- Cheng, M.; Jin, X. What do Airbnb users care about? An analysis of online review comments. Int J. Hosp. Manag. 2019, 76, 58–70. [Google Scholar] [CrossRef]
- Golmohammadi, A.R.; Jahandideh, B.; O′Gorman, K.D. Booking on-line or not: A decision rule approach. Tour. Manag. Perspect. 2012, 2, 85–88. [Google Scholar] [CrossRef]
- Moro, S.; Rita, P.; Coelho, J. Stripping customers′ feedback on hotels through data mining: The case of Las Vegas Strip. Tour. Manag. Perspect. 2017, 23, 41–52. [Google Scholar] [CrossRef]
- Khade, A.A. Performing customer behavior analysis using big data analytics. Procedia Comput. Sci. 2016, 79, 986–992. [Google Scholar] [CrossRef]
- Christodoulou, E.; Gregoriades, A.; Pampaka, M.; Herodotou, H. Combination of Topic Modelling and Decision Tree Classification for Tourist Destination Marketing; Springer International Publishing: Cham, Switzerland, 2020; pp. 95–108. [Google Scholar]
- Liu, J.W. Using big data database to construct new GFuzzy text mining and decision algorithm for targeting and classifying customers. Comput. Ind. Eng. 2019, 128, 1088–1095. [Google Scholar] [CrossRef]
- SPSS. IBM SPSS Modeler 16 User′s Guide; SPSS: Chicago, IL, USA, 2013. [Google Scholar]
- Bhandari, A.; Gupta, A.; Das, D. Improvised Apriori Algorithm Using Frequent Pattern Tree for Real Time Applications in Data Mining. Procedia Comput. Sci. 2015, 46, 644–651. [Google Scholar] [CrossRef]
- Lee, W.H.; Cheng, C.C. Less is more: A new insight for measuring service quality of green hotels. Int J. Hosp. Manag. 2018, 68, 32–40. [Google Scholar] [CrossRef]
- Kass, G.V. An Exploratory Technique for Investigating Large Quantities of Categorical Data. Appl. Stat. 1980, 29, 119–127. [Google Scholar] [CrossRef]
- SPSS. IBM SPSS Modeler 18.0 Algorithms Guide; SPSS: Chicago, IL, USA, 2016. [Google Scholar]
- Hung, C. Tree Model: CHAID, C&RT, Boosted Trees & Random; The Data-Shack Limited: London, UK, 2018d; pp. DM0002–DM0003 & DM0005–DM0006. [Google Scholar]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Cart. Classification and Regression Trees; Wadsworth and Brooks/Cole: Monterey, CA, USA, 1984. [Google Scholar]
- SPSS. IBM SPSS Modeler 18.0 Modeling: Nodes; SPSS: Chicago, IL, USA, 2016. [Google Scholar]
- TripAdvisor London 2018: Best of London, England Tourism—TripAdvisor Hotel Statistics. Available online: https://www.tripadvisor.com/Tourism-g186338-London_England-Vacations.html (accessed on 9 November 2018).
- Stringam, B.B.; Gerdes, J. An Analysis of Word-of-Mouse Ratings and Guest Comments of Online Hotel Distribution Sites. J. Hosp. Mark. Manag. 2010, 19, 773–796. [Google Scholar] [CrossRef]
- Huang, J. The dining experience of Beijing Roast Duck: A comparative study of the Chinese and English online consumer reviews. Int J. Hosp. Manag. 2017, 66, 117–129. [Google Scholar] [CrossRef]
- Gerdt, S.O.; Wagner, E.; Schewe, G. The relationship between sustainability and customer satisfaction in hospitality: An explorative investigation using eWOM as a data source. Tour. Manag. 2019, 74, 155–172. [Google Scholar] [CrossRef]
- Lombard, M.; Snyder-Duch, J.; Bracken, C.C. Content analysis in mass communication: Assessment and reporting of intercoder reliability. Hum. Commun. Res. 2002, 28, 587–604. [Google Scholar] [CrossRef]
- Cenni, I.; Goethals, P. Negative hotel reviews on TripAdvisor: A cross-linguistic analysis. Discourse Context Media 2017, 16, 22–30. [Google Scholar] [CrossRef]
- SPSS. IBM SPSS Decision Tree 2; SPSS: Chicago, IL, USA, 2012. [Google Scholar]
- Sann, R.; Lai, P.-C.; Chang, H.-C. Does Culture of Origin Have an Impact on Online Complaining Behaviors? The Perceptions of Asians and Non-Asians. Sustainability 2020, 12, 1838. [Google Scholar] [CrossRef]
- Sann, R.; Lai, P.C. Understanding homophily of service failure within the hotel guest cycle: Applying NLP-aspect-based sentiment analysis to the hospitality industry. Int J. Hosp. Manag. 2020, 91, 102678. [Google Scholar] [CrossRef]
- Feickert, J.; Verma, R.; Plaschka, G.; Dev, C.S. Safeguarding your customers: The guest’s view of hotel security. Cornell Hotel. Restaur. Adm. Q. 2006, 47, 224–244. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hotel Category | Frequency | % |
|---|---|---|
| Hotel Size | ||
| Large Hotel | 208 | 10.4 |
| Medium Hotel | 825 | 41.4 |
| Small Hotel | 959 | 48.1 |
| Hotel Star-Rating | ||
| 2-Star | 297 | 14.9 |
| 3-Star | 547 | 27.5 |
| 4-Star | 603 | 30.3 |
| 5-Star | 545 | 27.4 |
| Hotel Class | ||
| Higher Star-Rating | 1148 | 57.6 |
| Lower Star-Rating | 844 | 42.4 |
| Total | 1992 | 100.0 |
| Source | Data Type | Variables | Coding Descriptions |
|---|---|---|---|
| Hotel | Numerical | Rooms | The amount of hotel rooms. |
| Hotel | Categorical | Hotel Size | Small (less than 99 rooms), Medium (100–299 rooms), Large (300 room-ups) |
| Hotel | Numerical | Hotel Star Rating | The average of hotel ratings (2 to 5 stars) |
| Hotel | Categorical | Hotel Class | Higher star-rating (4 to 5 stars) and lower star-rating (2 to 3 stars) |
| Coding | Categorical | Service Encounter | Unfriendly Staff, Impoliteness, Poor Customer Service, Lack of Responsiveness, Check-in and Check-out Matters, Reservation Difficulties, Insufficient Information, Less Social Interaction, Poor Courtesy, Poor Competency, Personal Bias |
| Coding | Categorical | Room Issue | Inadequate Amenities, Poor Layout, Few Welcoming Extra, Poor Décor/Design, Less Lighting |
| Coding | Categorical | Hotel Facility | Wi-Fi Problem, Insufficient Public Facilities, Dated Hotel/Building |
| Coding | Categorical | Cleanliness | Poor Cleanliness in General, Bedroom Uncleanliness, Poor Public Areas Cleanliness, Filthy Toilet |
| Coding | Categorical | Location Accessibility | Far from City Center/CBD *, Far from Public Transportation, Away from Attractions, Far from Airport, Inconvenient Location, Poor Accessibility |
| Coding | Categorical | Value for Money | Unreasonable Price for QP *, Expensive Room Price, Food Overpriced, Not Value for Money, Expensive in General |
| Coding | Categorical | Safety | Less Safe, Not Feeling Safe, Unsafe Neighborhood |
| Coding | Categorical | Room Space | Small Room Space, Small Toilet Space |
| Coding | Categorical | F & B Issue | Poor Dining Environment, Lack of Special Food Service, No Innovative Menu, Limited Variety, Disappointing Breakfast, Poor Upselling of RFF *, Bad Tasty Food |
| Coding | Categorical | Miscellaneous Issue | Annoying Insects, Uncomfortable Bedding, Disgusting Smell, Lack of Facility Maintenance, Noise, Bad Outside Views |
| No | Codename | 5% of Corpus | 10% of Corpus | ||||
|---|---|---|---|---|---|---|---|
| Agreement (%) | Coder A and Not B (%) | Coder B and Not A (%) | Agreement (%) | Coder A and Not B (%) | Coder B and Not A (%) | ||
| Avg. Overall Inter-Coder Reliability | 98.56% | 97.74% | |||||
| 1 | Cleanliness | 98.97 | 0.84 | 0.19 | 98.74 | 1.01 | 0.25 |
| 2 | F & B Issue | 99.09 | 0.86 | 0.05 | 98.18 | 1.66 | 0.16 |
| 3 | Hotel Facility | 99.20 | 0.67 | 0.13 | 98.79 | 0.91 | 0.30 |
| 4 | Location Accessibility | 99.82 | 0.18 | 0.01 | 99.79 | 0.18 | 0.03 |
| 5 | Miscellaneous Issue | 98.12 | 1.43 | 0.45 | 97.02 | 1.89 | 1.09 |
| 6 | Room Issue | 98.54 | 1.28 | 0.18 | 97.60 | 1.64 | 0.76 |
| 7 | Safety | 99.49 | 0.36 | 0.16 | 99.36 | 0.36 | 0.29 |
| 8 | Room Space | 98.90 | 0.94 | 0.15 | 98.28 | 1.25 | 0.47 |
| 9 | Service Encounter | 94.62 | 5.07 | 0.31 | 91.34 | 6.93 | 1.73 |
| 10 | Value for Money | 98.88 | 1.05 | 0.07 | 98.28 | 1.57 | 0.14 |
| Title | Predicted | ||
|---|---|---|---|
| Higher Star-Rating | Lower Star-Rating | ||
| Actual | Higher Star-Rating | True Negative (TN) | False Positive (FP) |
| Lower Star-Rating | False Negative (FN) | True Positive (TP) | |
| Model Type | Sample | AC | Sensitivity/Recall/TP | Specificity/TN | FP | FN | P | F-Measure | AUC |
|---|---|---|---|---|---|---|---|---|---|
| CHAID | Training Set | 0.7141 | 0.7189 | 0.7058 | 0.2942 | 0.2811 | 0.8083 | 0.7610 | 0.754 |
| Testing Set | 0.7085 | 0.7494 | 0.6391 | 0.3609 | 0.2506 | 0.7793 | 0.7640 | 0.745 | |
| C&RT | Training Set | 0.7141 | 0.7189 | 0.7058 | 0.2942 | 0.2811 | 0.8083 | 0.7610 | 0.723 |
| Testing Set | 0.7085 | 0.7494 | 0.6391 | 0.3609 | 0.2506 | 0.7793 | 0.7640 | 0.720 | |
| C5.0 | Training Set | 0.7104 | 0.7198 | 0.6950 | 0.3050 | 0.2802 | 0.7953 | 0.7557 | 0.724 |
| Testing Set | 0.7069 | 0.7513 | 0.6340 | 0.3660 | 0.2487 | 0.7713 | 0.7612 | 0.709 | |
| QUEST | Training Set | 0.7009 | 0.7071 | 0.6901 | 0.3099 | 0.2929 | 0.8005 | 0.7509 | 0.715 |
| Testing Set | 0.7085 | 0.7419 | 0.6468 | 0.3532 | 0.2581 | 0.7952 | 0.7677 | 0.728 |
| Model Type | Sample | Title | Predicted | Per-Class Accuracy (%) | Title | Overall Accuracy (%) | |||
|---|---|---|---|---|---|---|---|---|---|
| Higher Star-Rating | Lower Star-Rating | ||||||||
| CHAID | Training Set | Actual | Higher Star-Rating | 624 | 148 | 80.829 | Correct | 979 | 71.41 |
| Lower Star-Rating | 244 | 355 | 59.265 | Wrong | 392 | 28.59 | |||
| Sum | 868 | 503 | 1371 | ||||||
| Testing Set | Actual | Higher Star-Rating | 293 | 83 | 77.926 | Correct | 440 | 70.85 | |
| Lower Star-Rating | 98 | 147 | 60.000 | Wrong | 181 | 29.15 | |||
| Sum | 391 | 230 | 621 | ||||||
| C&RT | Training Set | Actual | Higher Star-Rating | 624 | 148 | 80.829 | Correct | 979 | 71.41 |
| Lower Star-Rating | 244 | 355 | 59.265 | Wrong | 392 | 28.59 | |||
| Sum | 868 | 503 | 1371 | ||||||
| Testing Set | Actual | Higher Star-Rating | 293 | 83 | 77.926 | Correct | 440 | 70.85 | |
| Lower Star-Rating | 98 | 147 | 60.000 | Wrong | 181 | 29.15 | |||
| Sum | 391 | 230 | 621 | ||||||
| C5.0 | Training Set | Actual | Higher Star-Rating | 614 | 158 | 79.534 | Correct | 974 | 71.04 |
| Lower Star-Rating | 239 | 360 | 60.100 | Wrong | 394 | 28.96 | |||
| Sum | 853 | 518 | 1371 | ||||||
| Testing Set | Actual | Higher Star-Rating | 290 | 86 | 77.128 | Correct | 439 | 70.69 | |
| Lower Star-Rating | 96 | 149 | 60.816 | Wrong | 182 | 29.31 | |||
| Sum | 386 | 235 | 621 | ||||||
| QUEST | Training Set | Actual | Higher Star-Rating | 618 | 154 | 80.052 | Correct | 961 | 70.09 |
| Lower Star-Rating | 256 | 343 | 57.262 | Wrong | 410 | 29.91 | |||
| Sum | 874 | 497 | 1371 | ||||||
| Testing Set | Actual | Higher Star-Rating | 299 | 77 | 79.521 | Correct | 440 | 70.85 | |
| Lower Star-Rating | 104 | 141 | 57.551 | Wrong | 181 | 29.15 | |||
| Sum | 403 | 218 | 621 | ||||||
| Online Complaining Attributes | Decision Tree Models | ||||
|---|---|---|---|---|---|
| CHAID | C&RT | C5.0 | QUEST | V (Fused) * | |
| Hotel Size | 0.5412 | 0.5503 | 0.6744 | 0.6053 | 2.3712 |
| Service Encounter | 0.2040 | 0.1275 | 0.2148 | 0.1086 | 0.6549 |
| Room Space | 0.0893 | 0.0901 | 0.0765 | 0.0437 | 0.2996 |
| Value for Money | 0.0272 | 0.0576 | 0.0167 | 0.0805 | 0.1820 |
| Cleanliness | 0.0349 | 0.0514 | 0.0177 | 0.0540 | 0.1580 |
| Room Issue | 0.0645 | 0.0256 | 0.0000 | 0.0000 | 0.0901 |
| Miscellaneous Issue | 0.0000 | 0.0325 | 0.0000 | 0.0540 | 0.0865 |
| Location Accessibility | 0.0000 | 0.0325 | 0.0000 | 0.0540 | 0.0865 |
| Hotel Facility | 0.0390 | 0.0325 | 0.0000 | 0.0000 | 0.0715 |
| The Confusion Matrix | Predicted | |||
|---|---|---|---|---|
| Higher Star-Rating | Lower Star-Rating | Total | ||
| Actual | Higher Star-Rating | 930 | 218 | 1148 |
| Lower Star-Rating | 366 | 478 | 844 | |
| Total | 1296 | 696 | 1992 | |
| Risk Statistics | ||||
| Risk Estimate | 0.2931 | |||
| SE of Risk Estimate | 0.0101 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sann, R.; Lai, P.-C.; Liaw, S.-Y.; Chen, C.-T. Predicting Online Complaining Behavior in the Hospitality Industry: Application of Big Data Analytics to Online Reviews. Sustainability 2022, 14, 1800. https://doi.org/10.3390/su14031800
Sann R, Lai P-C, Liaw S-Y, Chen C-T. Predicting Online Complaining Behavior in the Hospitality Industry: Application of Big Data Analytics to Online Reviews. Sustainability. 2022; 14(3):1800. https://doi.org/10.3390/su14031800
Chicago/Turabian StyleSann, Raksmey, Pei-Chun Lai, Shu-Yi Liaw, and Chi-Ting Chen. 2022. "Predicting Online Complaining Behavior in the Hospitality Industry: Application of Big Data Analytics to Online Reviews" Sustainability 14, no. 3: 1800. https://doi.org/10.3390/su14031800
APA StyleSann, R., Lai, P.-C., Liaw, S.-Y., & Chen, C.-T. (2022). Predicting Online Complaining Behavior in the Hospitality Industry: Application of Big Data Analytics to Online Reviews. Sustainability, 14(3), 1800. https://doi.org/10.3390/su14031800