1. Introduction
Following the adaptation of specific or implicit principles of New Public Management within the academic world [
1,
2,
3], academics and researchers are no longer hermits in the Ivory Tower of science [
4], but producers of results, being compared, ranked, and financed according to market demands. Competition for research funds has become stronger and stronger, with researchers having to compete against both national and international field colleagues. This competition is not always an individual race, but rather a team one, as collaboration [
5] has a positive effect on research productivity.
While the field of scientometrics abounds with studies on the impact of this market approach on the academic field, the phrase “publish or perish” has become a mantra in some research circles. Performance is now evaluated manifold: research output, research impact, research visibility, and social relevance are all elements considered when measuring individual and institutional performance. Individuals choosing a research career nowadays must therefore come to terms with the productivity requirements of their job. This productivity should not be analysed in a vacuum, but together with structural and institutional elements facilitating or hindering research and innovation. We therefore start our analysis by subscribing to the view that “a national research system is made up of the actors within a country that jointly (i.e., in interaction with each other) produce research outcomes” [
6]. Hardeman et al. [
6] go on to describe the map of a national research system, which is made up of structural capabilities, research assets, interactions, and research excellence, elements that influence each other in dynamic ways. Policies and funding instruments that can produce the optimal conditions and environment will enable research, development, and innovation (RD&I)-performing entities to radically improve the knowledge base of the economy and society and support the digitalisation and greening of entire sectors and value-chains [
7].
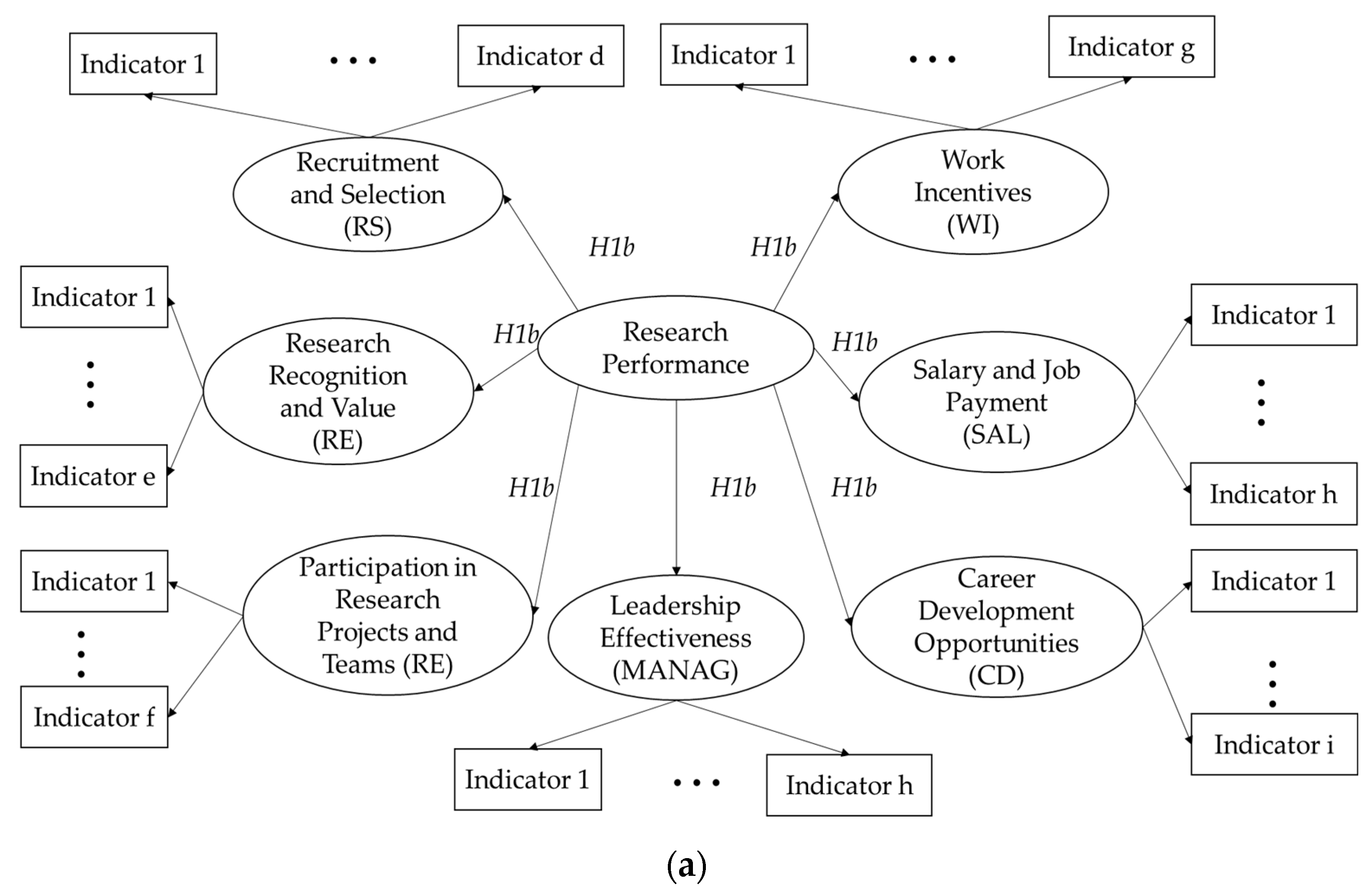
Within this context, the main purpose of this research study was to propose and test several bottom-up models of research performance in Romania. We give credit to Hardeman’s model [
6] and consider that in the Romanian context, there is also a dynamic influence and causal relation between research performance, structural capabilities, research assets, and interactions found in the system. The following sections unfold the state of play and discuss the frameworks underpinning the research. Our approach relies on several theoretical models of job satisfaction, job performance, and talent governance, arguing that research performance should be understood and approached from a multidimensional perspective. Systemic, institutional, and individual factors interact in a dynamic way and modify the research performance accordingly within the ecosystem. When informing evidence-based policies, the models we propose could achieve the goal of improving research performance through talent development as the main proxy.
3. Materials and Methods
3.1. Participants
The current research study followed an exploratory, empirical, cross-sectional mixed research design. The reference population of the study was represented by persons who formally carry out research activities in universities and public RD&I institutes.
All the public higher education institutions in Romania, all the National RD&I Institutes (INCD), and the research centres and institutes of the Romanian Academy received a formal letter presenting the research project and the invitation to participate in the survey. The selection unit was the research entity. Following the General Data Protection Regulation (GDPR) requirements, the institutions forwarded the survey invitation to their employees. A total number of 72 institutions participated (43 research institutes and 29 higher education institutions). In total, 1221 responses were obtained. We only kept the complete responses to the variables under investigation in this article in the database. The responses with a completion time shorter than 10 min were excluded, given the estimated completion time was around 25 min. The exclusion of these data resulted in 553 cases, which represent an overall response rate of around 40%. That is, the sample may not be adequately representative due to missing data of non-respondents. The demographic and disciplinary profiles of the respondent sample are described below.
In terms of gender, 47% of the respondents in the sample were female. The number of respondents occupying executive positions was up to 23% of the sample. Within this subgroup, the male subjects were over-represented (62%). The demographic profile shows that more than half of the respondents (56.1%) were aged 31–50. A third of the subjects (34.4%) were aged over 51, and fewer than 10% were aged 30 or below. As concerns the institution’s profile, 70% of the sample was represented by researchers working in research institutes.
The respondents were asked about their total experience as a researcher and length of service in their current institution. The results show that more than 75% of the respondents had been researchers for more than 10 years and only 9.9% for less than 3 years (see
Table 1). More than two thirds of the respondents (70.3%) had been in their current institutions for more than 10 years (
Table 2).
The geographical distribution shows an over-representation of the respondents who were residents in the capital region (58.2%). Nevertheless, respondents from 25 counties out of 41 were sampled.
The breakdown of the respondents’ profiles by subject specialism can be seen in
Table 3. Advanced materials, energy, and environment were well-represented domains within the sample with over 10 percent. The high score computed for the ‘other’ response option is due to the great variety of domains it comprised (e.g., psychology, sciences of education, music, law, economy, communication, agriculture, architecture, and geography).
For some fields of research, the disciplinary profile was significantly gendered. For instance, the Energy and Information Technology and Telecommunications fields had a much lower proportion of female respondents (28.2% and 27.7%, respectively).
The total sample of 553 respondents was randomly divided into two sub-samples (n1 = 262, n2 = 291) to allow for cross-validation analyses.
3.2. Instrument and Measures
An ad hoc questionnaire was designed. We included variables on three hierarchical levels: system, institution, and individual levels. The identified variables were rated on an 11-point scale from −5 to +5, where −5 = very negative influence and +5 = very positive influence on researchers’ job performance. Each of the seven dimensions in the theoretical framework was operationalised with several items adapted from already existing instruments. The initial version of the questionnaire was quantitatively pretested. Purposefully selected researchers were invited to test the questionnaire through an online survey platform and to disseminate the invitation to other colleagues. The questionnaire had open fields associated with each dimension, where the respondents could comment on the clarity and relevance of the items in that dimension and made additional suggestions. A total sample of N = 117 participants filled out the test survey. The reliability analyses showed good to very good metrics of the questionnaire. Following the participants’ feedback, seven items were slightly rephrased, and two new items were added to the international recognition of research dimension.
In the following, the structure and metric qualities of the questionnaire are discussed.
At the system level, we considered the
recruitment and selection and
job payment policies. We operationalised the recruitment and selection dimension with four items following the recommendations in the IA study on the Open, transparent, and merit-based recruitment of researchers [
40] and the respective scale in the ‘Five Steps Forward’ study conducted in the United Kingdom [
33]. The reliability of the scale was good (
Table 4):
, (
—see
Appendix A, items RS1–RS4. Complementarily, the job payment and salary dimension included two items (
. The two items were translated into Romanian and adapted from the 6th European Working Conditions Survey [
41]. One item referred to the influence of salary or wage in exchange for researchers’ work on job performance. The second one touched on additional components that might be of a variable nature and their influence on job performance—see
Appendix A, items SAL1 and SAL2.
The variables associated with the institution level were seen as job resources and thematically organised in three dimensions: career development opportunities, work incentives, and leadership effectiveness. The career development opportunities dimension contained eight items (
answered in a scale ranging from −5 (very negative influence) to +5 (very positive influence). The items were translated into Romanian and adapted from the from the ‘Five Steps Forward’ study [
33]—see
Appendix A, items CD1–CD8. Similarly, the five items in the leadership effectiveness dimension (
Appendix A, items MANAG1–MANAG5) were translated and adapted from the same study [
33] and answered in a similar scale (
The work incentives dimension (
Appendix A, items WI1–WI5) included five items (
The items were extracted from the MORE2 Study [
34] and translated into Romanian.
The individual level comprised two dimensions: recognition and value of research and participation in research projects and teams. The items were translated into Romanian and adapted from the ‘Five Steps Forward’ study and included three subscales, namely appraisal and review, recognition of management activities, and recognition of researchers’ contributions. To operationalise the Recognition and Value of Research dimension, we used the 10 items with the highest factor loadings of the primary factor (. Two items with factor loadings below the 0.4 threshold were not retained in this dimension for further analyses.
We operationalised the Participation in Research Projects and Teams with seven items, with the highest factor loadings on the first factor ( Two items with factor loadings below the 0.4 threshold were not retained in this dimension for further analyses.
3.3. Procedure
The research was structured in two phases, blending semi-structured interviews and quantitative surveys as primary data collection methods.
In the first phase, we explored the relevance of the conceptual framework through qualitative, semi-structured interviews. Based on the findings, a questionnaire was designed and deployed for quantitative data collection in phase 2. The present paper reports on the data collected in the second phase of the study.
Together, the two phases of the study provide empirical information on what variables and indicators affect researchers’ performance in Romania.
As described in the Participants subsection, the authors sent an official invitation to survey to all public HEIs and research institutes in Romania. The invitation extensively explained the rationale and context for the study. We relied on the institutions’ cooperation to complete the data collection process. The data were collected through an online specialised platform, Survey Alchemer®, with no compensation for participation. The average completion time was 26 min. No personal information leading to the identification of the subjects was collected. All the data were fully anonymised in compliance with GDPR regulations. Participation in the survey was voluntary and was granted clearance according to the recommended Ethics Guidelines of the university to which the three authors were affiliated at the time of data collection. The survey included electronic consent. The subjects had the option to participate or to decline participation by clicking the respective button. The ethical approval for the study was obtained from the Institutional Review Board, approval number 2552C/15.11.2019.
3.4. Data Analysis
In order to determine the factorial structure of researchers’ job performance, we carried out principal axis factoring analysis (PAF) using IBM SPSS v25.0 software. PAF was applied as an exploratory dimensionality-reduction method to deduce the main factors described by the variables in the study. Initially, the factorability of the 71 items in the questionnaire was examined. The Kaiser–Mayer–Olkin measure of sampling adequacy indicated that the strength of the relationships among variables was high:
. The dimensionality of the scales was also tested by the scree plot test and the Kaiser criterion—eigenvalues greater than 1 [
42]. Fourteen items had low communalities (
) below the 0.4 threshold. They were removed from the analysis. Sixteen items unsatisfactorily loaded on their primary factors, and five of them had cross-loadings ranging from 0.2 to 0.35. The items failed to meet the minimum criteria of having a primary factor loading of 0.4 or above [
43,
44], and no cross-loading of 0.3 or above. Consequently, PAF was re-run on 41 items. The communalities were above 0.4 (
, further confirming that each item shared some common variance with other items. The Bartlett’s test of sphericity, which tests the overall significance of all the correlations within the correlation matrix, was significant (
. Given these overall indicators, factor analysis was deemed to be suitable with all 41 items.
In the final solution, six factors with eigenvalues greater than one were extruded. Both Varimax and Oblimin rotations were performed. There was little difference between the two solutions provided, and we decided to keep the solution extracted based on the Varimax rotation with Kaiser normalisation.
Initially, by applying the factor analysis, we reduced the number of variables and tested the dimensionality of each latent variable. Subsequently, structural equation modeling was applied to validate the results of the factor analysis and to test the hypotheses. The first modelling part was implemented using IBM Amos 26.0 and maximum likelihood estimation (ML-SEM). In order to determine the factorial structure of the research performance, several models were tested. Firstly, we tested a reflective model where all items loaded on a single latent factor (Model 1 CFA 1). Secondly, as a base, we used a structure in which the six dimensions correlated with each other (Model 2 CFA2). Thirdly, Model 2 CFA 2 was cross-validated using the second sub-sample (Model 2 CFA 3). Fourthly, a new second-order reflective model was designed. The factors corresponding to research performance depended on a general second-order factor, namely job performance (Model 3 CFA 4). Similarly, it was cross-validated on the second sub-sample (Model 3 CFA5).
Following the recommendations of Hooper, Coughlan, and Mullen [
45], the normed/relative chi-square (
could take values between 2 and 5. Other fit indices were also computed and analysed:
RMSEA, RFI,
CFI, and
TLI. MacCallum, Browne, and Sugawara [
46] suggest that an
RMSEA value between 0.05 and 0.10 can be considered a fair fit. More recent scholar opinions (e.g., Steiger) report values less than 0.07 [
47] in order to consider a correct fit of the model. Regarding the
CFI and
TLI indices, the values should be close to the 0.95 threshold [
45]. Values between 0.85 and 0.95 indicate a satisfactory fit of the model to empirical data [
46]. In this paper, we followed the criteria and acceptable thresholds suggested by Hooper et al. [
45] and MacCallum et al. [
46].
To examine the relationships between the variables, a path analysis was carried out. Job payment, career development, work incentives, and participation in research projects and teams were used as mediators.
The final modeling part employed Bayesian analysis (B-SEM) with the same research framework along with Amos 26.0 software. The data were categorical ordered variables. Thus, we preferred to re-examine the data using Bayesian analysis and to compare the results for Model 2 B-SEM and Model 3 B-SEM with the maximum likelihood estimator models.
4. Results
4.1. Descriptives
Table 5 shows the descriptive statistics for the variables used in our study. High positive mean scores were computed for the variables MANAG5 (positive motivational support offered by the manager,
, CD3 (possibility to participate in international teams,
, CD1 (job security,
, MANAG3 (manager’s capability to attract research funding,
, RE3 (publications in high-impact-factor journals,
and MANAG4 (manager’s orientation toward research integrity,
The correlations between the variables in the study were positive, of low to medium intensity, and statistically significant at the 0.01 level (
—see
Supplementary Sheet S1.
4.2. Results of the Principal Axis Factoring Analysis
At first, the factorability of the 71 items in the questionnaire was tested. The correlations between items were positive, statistically significant at the 0.01 level, and of low to medium intensity. The Kaiser–Mayer–Olkin measure of sampling adequacy indicated that the strength of the relationships among variables was high: and the Bartlett’s test was statistically significant: . The communalities showed that 14 items did not prove satisfactory common variance with other items (.
To reduce the number of variables included in the statistical model, PAF with Varimax rotation was conducted. PAF was applied because the primary goal was to identify the latent factors underling researchers’ job performance. The initial solution included 14 factors with eigenvalues above 1 which explained 54% of the total variance. The first extracted factor accounted for 26% of the total variance. Factors 11, 12, 13, and 14 had eigenvalues just above the 1 threshold.
Based on the results of the initial PAF analysis and the criteria for factorability, 30 variables were removed from the analysis. The removed items had low communalities (, did not meet the criteria for having a primary loading of 0.4 or above, and cross-loaded on other one or two factors (cross-loadings were below 0.3).
For the final stage, PAF was re-run for the remaining 41 items. The Varimax rotation provided the best-defined factor structure. All the 41 items included in the analysis had primary loadings over 0.4. Two items in the job payment dimensions (SAL 1 and SAL 2) had cross-loadings of 0.305 and 0.408, respectively. However, their primary loadings were 0.808 and 0.668.
The Kaiser–Mayer–Olkin measure of sampling adequacy indicated a strong relation among variables:
. All the correlations were positive and statistically significant at the 0.01 level (see
Supplementary Sheet S1).
Table 6 presents the factor loadings, communalities, variance, and eigenvalues for the final solution. Six factors with eigenvalues greater than 1 were identified and retained in the model (
Table 6), and together, they explained 58% of the total variance. Internal consistency for each of the scales was examined using Cronbach’s alpha. The coefficients proved to be good and very good (
.
The first factor extracted relates to career development opportunities. Thirteen variables loaded on this factor, which accounted for 38.355 of the total variance. The loadings ranged from 0.512 to 0.734. The factor includes variables related to job stability, access to training in research management, team leadership, and mentorship. Additionally, variables referring to leadership effectiveness in career management were found to load strongly on this factor. The variables that had the highest loadings were the leader’s skills to provide researchers with guidance to develop their research careers (0.722) and to effectively engage in research teams’ development (0.705).
The second factor we extracted was research recognition and value. Together with the first factor, they accounted for 45.246 of the total variance explained by the six-factor solution. As expected, citations of research papers (0.769) and publications in high-impact-factor journals (0.745) and international conference proceedings (0.744) loaded strongly on the second factor. Affiliation to international professional associations and societies was found to be related to the factor research recognition and value.
The third factor extracted was participation in research projects and teams. This factor was represented by seven items, which accounted for 50.475 of the total variance (cumulated with the first two factors). The loadings of the variables ranged from 0.755 to 0.479. The highest loadings were related to the coordination of international (0.755) and national research projects (0.737). The lowest loading was computed for the contribution of highly prestigious research prizes and awards to researchers’ job performance.
The fourth factor was recruitment and selection. The factor was represented by four items, which accounted for 53.661 of the total variance (cumulated with the first three factors). The item referring to the transparency of the recruitment and selection process had the highest loading of 0.844.
The fifth factor was work incentives. Five items loaded on this factor and cumulatively explained 56.403 of the total variance. The loadings ranged from 0.737 to 0.437.
Finally, the sixth factor was salary or job payment. The factor was represented by two items, which had loadings of 0.806 and 0.668, respectively. The sixth factor accounted for 2.185 of the variance.
4.3. Results of the Structural Equation Modeling
4.3.1. Model 1 Mono-Factor CFA 1 (ML-SEM)
In
Figure 2, we present the standardised estimates of the first confirmatory model (Model 1) as well as the regression weights. All estimated weights were significant (
p < 0.001) (see
Table 7). As for the fit statistics obtained for the mono-factor model, chi-square was significant, but the ratio
, the
RMSEA,
TLI, and
CFI were well outside the limits to accept the model. As suggested by the exploratory factor analysis and the research framework, researchers’ job performance could be a second-order construct underlying various primary constructs.
4.3.2. Model 2 Intercorrelated Factors CFA2 (ML-SEM)
We present the second confirmatory model in
Figure 3. The data were run through Amos with maximum likelihood estimation, and the results (
Table 8) indicate an acceptable fit (H1a). The skewness and kurtosis statistics indicated a violation of the univariate normality. Additionally, Mardia’s coefficient was
, and the critical ratio (c.r.) was
, indicating a significant multivariate non-normality. Thus, the data were bootstrapped with 2000 draws at the 95% bias-corrected confidence level.
The path diagram presents the standardised estimates of the second confirmatory model as well as the squared multiple correlations after bootstrapping. All estimated weights were significant (p < 0.001). As for the fit statistics obtained for Model 2, chi-square was significant, but the ratio and the RMSEA were inside the limits to accept the model. Nevertheless, TLI and CFI adjustment indexes indicated it was satisfactory to accept the model.
4.3.3. Model 2 Intercorrelated Factors CFA3 Cross-Validation (ML-SEM)
Sample 2 (n2 = 291) was used to carry out a cross-validation analysis. All estimated weights were significant (
p < 0.001) (see
Table 9). All the other estimates were identical with those computed for Model 2 CFA2. Therefore, the model (
Figure 4) could be accepted (H1a).
4.3.4. Model 2 Intercorrelated Factors (B-SEM)
Additionally, Bayesian SEM (B-SEM) was conducted with Markov chain Monte Carlo (MCMC) estimation. We show below that MCMC converged well with Model 2 and also resulted in a good model fit (H1a).
The default diffuse prior in Amos 26.0, a uniform over the interval
to
[
48], was placed on all parameters in the model.
The Bayesian results for the measurement model are presented in
Table S1. Before discussing the results, we first checked the convergence of MCMC chains using Amos 26.0 (
Figure 5). The PSRF value was 1.0003. Since the value was less than the default cutoff of 1.002 in Amos 26.0 [
48], the chains were likely sampling from the target distributions. For example, as shown in the convergence plots of some model parameters in
Figure 5, the chains mixed well after a few thousand iterations and after 100,000 iterations in each case [
49]. Since the trace plots for the six-factor model appeared to sample consistently from the same range of values over the course of the iterations, the chains were likely sampling from their target distributions.
The results of the B-SEM analysis are discussed in terms of posterior predictive
p-values (
ppp), posterior distributions, and autocorrelation. The hypothesised model produced a
ppp value around 0.5,
[
50]; Model 2 appeared to fit the data well (H1a).
The posterior mean and the posterior SD are presented in
Table 10 and
Table S1. The loadings were all statistically significant at the 5% level, as noted by the low standard deviation. The results from the structural model are presented in
Table 10. For each relationship, we show the posterior mean and standard deviation [
49], as well as 95% higher posterior densities.
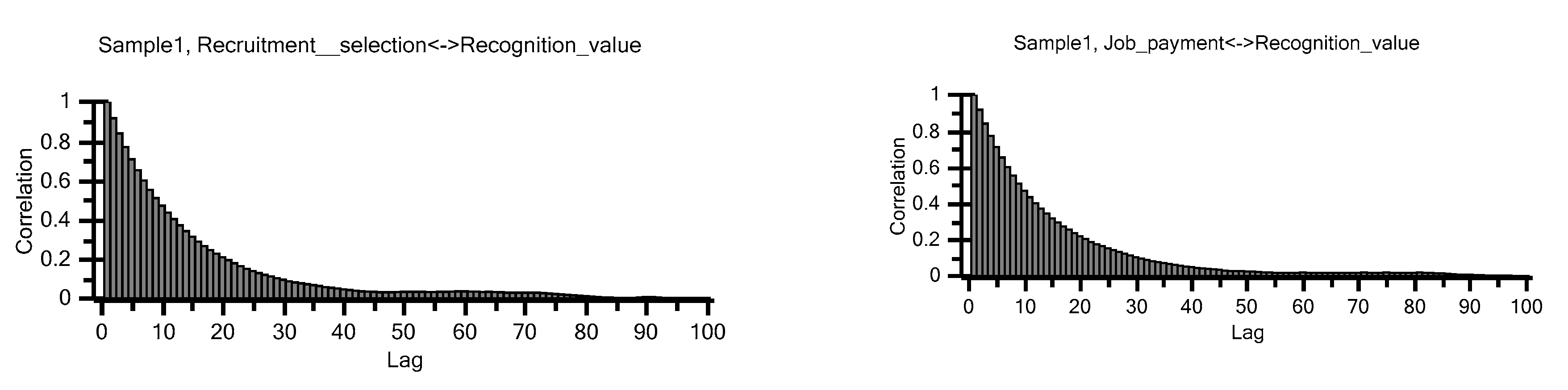
Figure 6 also presents the plots of the empirical posterior distributions for some of these relationships. The histograms from Model 2 exhibited gradual changes in the height of adjacent frequency bars over the parameter space. Thus, the chains likely represent the posterior distributions well.
The autocorrelation was low with increasing lags for all parameters (
Figure 7). Therefore, the chains were likely sampling well from their target distributions.
As one final analysis of Model 2, we compared the unstandardised regression weights in ML and Bayesian approaches. The listing is presented in
Table 11, and it is continued in
Supplementary Table S2. The values of the estimates are very close, confirming the validity of the hypothesised structure in Model 2 (H1a).
4.3.5. Model 3 Hierarchical CFA 4 (ML-SEM)
The aim of this analysis was to test whether the six first-order factors corresponding to the six groups of research performance drives were indicators of a general construct named
research performance (H1b). To mitigate the violation of univariate and multivariate normality, Bollen–Stine bootstrapping with 2000 draws at the 95% bias-corrected confidence level was performed.
Figure 8 shows the model and standardised estimates after bootstrapping. All the regression weights were statistically significant (
. As it can be seen in
Table 12, this model showed a goodness of fit, better than Model 2 CFA2 and CFA3. Chi-square was significant, but the ratio
, the
RMSEA,
TLI, and
CFI adjustment indexes were well inside the limits that allowed the model to be accepted.
4.3.6. Model 3 Hierarchical CFA 5 Cross-Validation (ML-SEM)
Sample 2 (n2 = 291) was used to cross-validate Model 3 (see
Figure 9). All the estimated weights indicated a good fit of the model (see
Table 13). Therefore, the model could be accepted.
4.3.7. Model 3 Hierarchical B-SEM
To check for further validation, B-SEM was conducted with MCMC estimation. We show below that MCMC converged well with Model 3 and resulted as well in a good model fit (H1b).
The default diffuse prior in Amos 26.0, a uniform over the interval
to
[
48], was placed on all parameters in the model.
The Bayesian results for the measurement model are presented in
Supplementary Table S3. As presented in
Figure 10, we checked the convergence of MCMC chains using Amos 26.0. The PSRF value was 1.0001, which was below the cut point of 1.002 in Amos 26.0 [
48], thereby indicating convergence. Thus, the chains were likely sampling from the target distributions. For example, as shown in the convergence plots of some model parameters in
Figure 10, the chains mixed well after a few thousands of iterations and after 100,000 iterations in each case. Since the trace plots for the six-factor model appeared to sample consistently from the same range of values over the course of the iterations, the chains were likely sampling from their target distributions.
The posterior predictive value produced by Model 3 was around 0.5,
[
50]. Therefore, Model 3 appeared to fit the data well (H1b).
The posterior mean and the posterior SD are presented in
Table 14 and
Table S3. The loadings were all statistically significant at the 5% level, as noted by the low standard deviation. For each relationship, we show the posterior mean and standard deviation [
49], as well as 95% higher posterior densities.
Figure 11 also presents the plots of the empirical posterior distributions for some of these relationships. The histograms and polygons from Model 3 exhibited gradual changes in the height of adjacent frequency bars over the parameter space. From the display in the plots in
Figure 11, it can be observed that the two distributions were almost identical, thereby suggesting the successful identification of important features of the posterior distributions of the analysed items. Thus, the chains likely represented the posterior distributions well.
The autocorrelation was low with increasing lags for all parameters (some examples are presented in
Figure 12). Therefore, the chains were likely sampling well from their target distributions.
Finally, we compared the unstandardised regression weights for the ML-SEM method versus the Bayesian posterior distribution estimates. A listing of both sets of estimates is presented in
Table 15 and it is continued in
Supplementary Table S4. As expected, based on the review of the diagnostic plots, these estimates are very close. We can, therefore, conclude that the hypothesised structure (H1b) is valid.
4.3.8. Path Analysis
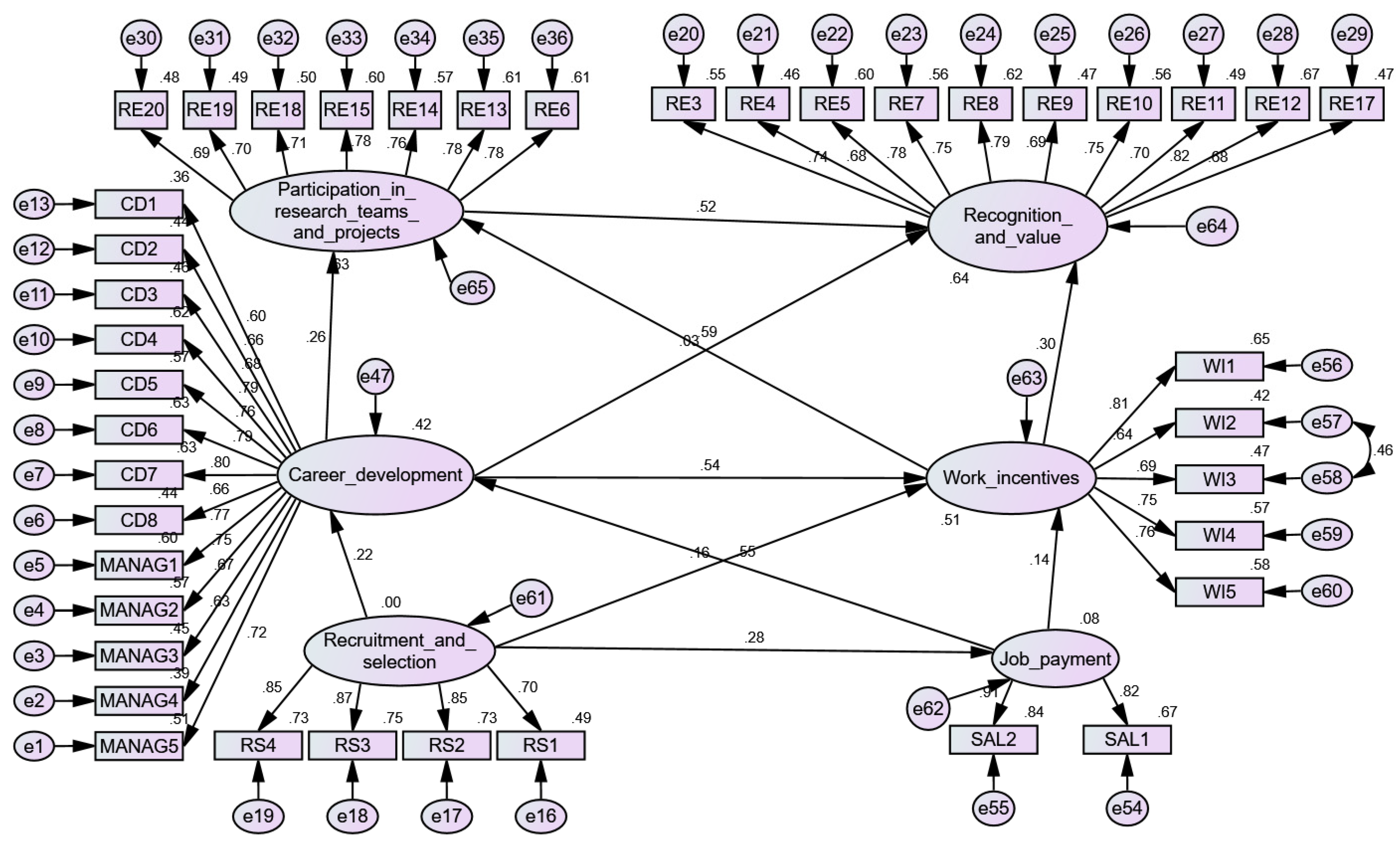
Figure 13 shows the path analysis and
Table 16 the fit indices of the model. The aim of the analysis was to determine the nature of the relationships between the six variables considered to be drivers of
research performance. As it can be seen, the results confirmed the H2a and H2b hypotheses. The relationships and their implications are discussed in
Section 5. All the regression weights were statistically significant (
. The fit indices in
Table 16 fit into the acceptance limits. The skewness and kurtosis statistics indicated a violation of the univariate normality. Additionally, Mardia’s coefficient was
, and the critical ratio (c.r.) was
, indicating a significant multivariate non-normality. Thus, the data were bootstrapped with 2000 draws at the 95% bias-corrected confidence level.
Table 17 shows the mediator variables, the variance explained, and the total, direct, and indirect effects. Recruitment and selection and job payment explain 42% of career development variance. The effect of recruitment and selection is mediated through job payment. Participation in research projects and teams depends (63%) on career development and work incentives, but the effect of career development is mediated through work incentives, as the path diagram in
Table 17 suggests. The effect of career development is particularly noteworthy. If this predictor is removed, the work incentives variable explains 0% of participation is research variation. Career development has a total effect of 0.581 on participation in research projects and teams. Therefore, by increasing career development the participation in research activities would increase as well. It is estimated that the predictors of recognition and value explain 64 percent of its variance. Career development has a total effect on recognition and value of 0.497. Participation in research projects and teams mediates the effect of career development on recognition and value.
In closing out this section, we point out the importance of our comparative analysis of research performance factorial structure from two perspectives: ML and Bayesian estimations. Given that items comprised in the research instrument are based on an eleven-point scale, the argument could be made that analyses should be based on a methodology that takes this ordinality into account. In this case, Models 2 and 3 were well specified, the was scaling based on more than three categories and, therefore, we did not find very much difference between the findings.
5. Discussion
This study aimed to design and examine bottom-up models of research performance by applying ML-SEM and B-SEM. In order to do so, a seven-dimension theoretical framework, echoing the JD-R model and partially the Framework of academic satisfaction developed by Hagedorn [
32], was designed. The development of such models of research performance is necessary because research performance is at the heart of national, European, and international policies and initiatives aimed to tackle global challenges [
38,
51,
52]. The context surrounding research performance in RD&I institutions is manifold. For example, the positive momentum for open science [
53], the exponential growth of data and data science [
38], and the inception of new generation metrics [
39] shape new pathways for strategic development. In this context subject of change, the models we propose shed light on potentially effective RD&I policies and inform the decision-making process.
Although much research has focused on analysing research performance, there are not so many studies modelling this construct with SEM and particularly with B-SEM. This is particularly true when factors such as career development, leadership, and recruitment and selection policies are included in the analysis.
Overall, we observed that systemic factors such as recruitment and selection and job payment policies positively and significantly influence institutional factors, which have a positive and significant effect on individual factors related to achieving value and recognition in research. Moreover, in line with the initial assumptions, all three categories of factors were proved to depend on higher-order construct, namely research performance.
In the current study, PAF was initially applied to explore the factorability of the variables. The results showed that six factors explain more than 58% of the variance of research performance: (1) recruitment and selection, (2) participation in research projects and teams, (3) work incentives, (4) salary, (5) career development opportunities, and (6) recognition and value. Thereby, all the indicators associated with the seven dimensions were re-grouped in six factors. All indicators associated with the leadership effectiveness dimension were loaded on the career development dimension. Therefore, they were kept and included in the career development factor, and the number of dimensions was reduced to six. The finding is consistent with the results of previous research [
10,
12,
29,
54], pointing out that comprehensive career development policies, (inter-sectoral) mobility, and dedicated human resources policies could significantly contribute to research performance [
55,
56].
Following the PAF analysis, ML-SEM was applied as a parametric analysis for testing the relationships among the observed variables and their respective factors, as well as among the latent variables. Comparatively, B-SEM was carried out as a nonparametric analysis.
Thus, three reflective models were tested: M1 mono-factor; M2 intercorrelated dimensions; M3 hierarchical. The estimates and statistics computed proved that the hypothesised relations in Model 2 and Model 3 were valid. The indicators that were found to be significant in explaining the latent factors considered in this study are as follows.
As regards the career development factor, the items loaded on this factor indicate more challenging pathways for both institutions and researchers. In addition to sharpening their scientific profile, R3 and R4 researchers need to play more varied roles such as mentors, career advisors, and grant managers. As models M2 CFA 2 and CFA 3 showed, career orientation plays a key role in career development (factor loading = 0.723) and by effectively engaging in research team development (factor loading = 0.705). In addition, integrating a set of skills related to project management (factor loading = 0.734) and the motivation of research team members (factor loading = 0.731) is expected to have considerable potential to support career development and, thus, to positively influence the research performance. Within this context, ‘particular priority should be given to the organisation’s working and training conditions in the early stage of the researchers’ careers, as it contributes to the future choices and attractiveness of a career in R&D’, as the European Charter and Code for Researchers states [
22].
Within the research recognition and value dimension, citations of research papers (factor loading = 0.772) and publications in journals indexed in internationally recognised databases and in internationally recognised conference proceedings (factor loading = 0.746) are the most important indicators. This is probably since, in Romania, the mechanisms for evaluating the performance of employees in the RD&I sector are merely based on bibliometric indicators. Although it was not the purpose of this paper to address new generation metrics, we argue that a new narrative of research performance is needed. New metrics oriented towards science openness, public engagement and outreach, and contributions to sustainability could better align RD&I institutions to society and employers’ needs and consolidate their role in innovation ecosystems [
38,
39].
In terms of participation in research projects and teams, the coordination of international (factor loading = 0.751) and national research projects (factor loading = 0.737) are strong indicators. The lowest factor loading was computed for the contribution of highly prestigious research prizes and awards to research performance (factor loading = 0.476). Awards can bring appreciation from those awarded for the recognition received and can represent a symbol of excellence, giving confidence and credibility to those awarded. However, awards do not necessarily bring significant changes in performance at work [
57]. The effects may not always be in the desired direction, or they can even destroy the value [
58].
At the level of recruitment and selection process, the transparency of the recruitment and selection process (factor loading = 0.844) followed by openness of the available positions to any candidate who matches the profile (factor loading = 0.836) are the most important indicators. Thus, it can be appreciated that the existence and quality of information sources regarding vacancies jobs in RD&I, the high level of transparency in the recruitment and selection process, but also open positions for any candidate are aspects necessary from a formal point of view but are not actually enough to attract the best candidates in the RD&I sector. In relation to
recruitment and selection, we strongly advocate for the adherence to the principles of the European Charter and Code for Researchers [
22].
Regarding the work incentives factor, financial incentives have the greatest positive influence on this variable. Specifically, internal competitions to win funding for scientific events (factor loading = 0.737) and internal competitions for participation in training programmes (0.686) or international mobilities are the most important indicators.
Finally, for the salary and job payment factor, employers and/or funders of researchers should ensure that researchers enjoy fair and attractive conditions of funding and/or salaries (factor loading = 0.806) with adequate and equitable social security provisions (factor loading = 0.668).
Through SEM, we tested the structure and the relationships among those factors. As the first model M1 CFA1 proved a poor fit, it was not cross-validated, and the Bayesian analysis was not performed either. As shown in M2 CFA2, M2 CFA 3, and M2 B-SEM models, all six latent variables positively and significantly correlated with each other, which provides a confirmation of the H1a hypothesis. High levels of participation in research projects and teams and of achieving research recognition are closely related to significant career development policies and opportunities. Similarly, work incentives such as international mobilities or prizes strongly correlate with research participation and recognition. As well as this, intense participation in research is associated with significant recognition of research. The results are intrinsically related to the knowledge-based economy framework. RD&I entities crucially need to invest in talent to drive participation and recognition [
55,
59]. By addressing the six factors in comprehensive policies, systems and institutions could nurture researchers to perform better in their careers [
11,
59]. Moreover, research leadership and mentorship can be understood as pillars of career development and addressed accordingly [
1,
7,
10].
One of our hypotheses postulated that the six factors will depend on a general construct, research performance (H1b)—Model 3. This relationship was validated through ML and Bayesian estimations. Therefore, the higher the value in the research performance, the more the researchers achieve recognition and value, participate in research projects and teams, are incentivised and rewarded, and engage in their career development [
12,
13,
54].
Moving forward in our analysis, we intended to find empirical evidence about the relationship between the six factors of research performance and their respective effects (H2a and H2b). As shown in the path analysis model, system factors, recruitment and selection and salary and job payment, respectively, have a significant and moderate effect on the institutional factors, confirming H2a. Furthermore, researchers’ recognition and value and their participation in research activities (understood as individual drives of performance) are affected by the institutional factors, namely career development and incentives, confirming H2b. A powerful feature of the path analysis model is that it gives centrality to career development in boosting research performance [
25,
34]. In line with other scholars’ opinions [
55], we argue that RD&I institutions are responsible for ensuring the leadership towards boosting the career of researchers in line with the principles in the European Charter and Code for Researchers [
9,
40]. Providing researchers with well-structured career perspectives, career development support, training, and mentorship would consequently develop researchers’ skillsets and would be associated with more significant rewards. In terms of rewards and incentives, institutions could consider mobility stages, internal grant competitions, or performance bonuses. Moreover, work incentives positively influence participation in research projects and teams which, further, leads to the recognition of research.
6. Conclusions
This paper aimed to design and examine bottom-up models of research performance by building upon the specific context of RD&I landscape in Romania. In order to do so, maximum likelihood SEM and Bayesian SEM estimations were carried out.
The results highlighted that recruitment and selection, salary and job payment, career development, work incentives, participation in research projects and teams, and recognition and value strongly and positively corelate with each other and depend on a higher-order construct named research performance. System factors, recruitment and selection, and job payment and salary, respectively, have a positive predictive power over institutional factors of research performance, and the institutional factors, namely career development and work incentives, have a positive predictive power over individual factors of research performance. As argued in the previous sections, an essential feature of the models we developed is career development and its effect on participation in research projects and teams and achieving research recognition and value. Therefore, the models we propose could be used to develop national and institutional research policies in which career development, research leadership, and co-careering gain centrality. At the national level, the paper could inform the implementation of specific reforms and initiatives proposed in the National Plan for Resilience and Recovery [
60]. More importantly, the models provide a common ground and inspiration for research-performing entities to design their internal policies to support a sustainable research culture. As the factors influencing research performance largely exceed the participation in research projects and teams and researchers’ payment, the proposed models open a perspective in which leadership and research career governance complement the role of career development practices. Even if it was not the purpose of this paper, the models may also be relevant for the assessment of individual researchers in the context of career advancement.
Thus, it can be concluded that the RD&I institutions need to play a dynamic role and firmly engage to support their researchers, throughout their careers, in their development and career choices. This requires coherent but distinct sets of skills training programmes, career support structures, and human resources policies for various career phases to boost research performance and thoroughly support the ‘Lisbon Strategy’.
We acknowledge several limitations of the study.
Firstly, it is important to mention that sample and sampling limitations need to be considered in the interpretation of the results. Although all public research entities in the country received the invitation to participate in the survey, the authors were not able to control the dissemination of the survey within the institutions.
Secondly, we acknowledge that some limitations may arise as consequences of the administered scales and data collection procedures. Since the questionnaire was self-administered through an online platform, some of the responses were incomplete or proved to be of poor quality and were removed from the database.
Finally, it is important to note that even though the models were in agreement with the empirical data and provided a theoretically consistent set of findings, there may be other equivalent models that fit the data equally well.
In conclusion, our study represents a step forward toward a better understanding of research performance. The main contributions of the paper are twofold. Primarily, the paper designs a framework for the conceptualisation and inception of relevant practices to ensure a sustainable, multidimensional pathway towards research performance.
Furthermore, we point out the importance of our comparative analysis of research performance factorial structure from two perspectives: ML and Bayesian estimations. The analyses conducted demonstrate the potential of ML-SEM and B-SEM approaches in modelling research performance. The results of this study could be used as priors for future studies applying Bayesian estimations. Complementarily, future studies could test formative models of research performance. Although there are some limitations, comparative studies can be conducted to model research performance across the European Research Area.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}