
The Sustainable Development of Intangible Cultural Heritage with AI: Cantonese Opera Singing Genre Classification Based on CoGCNet Model in China

Abstract
:1. Introduction
2. Database
2.1. Data Analysis
2.2. Data Set
3. Methods
3.1. Cantonese Opera
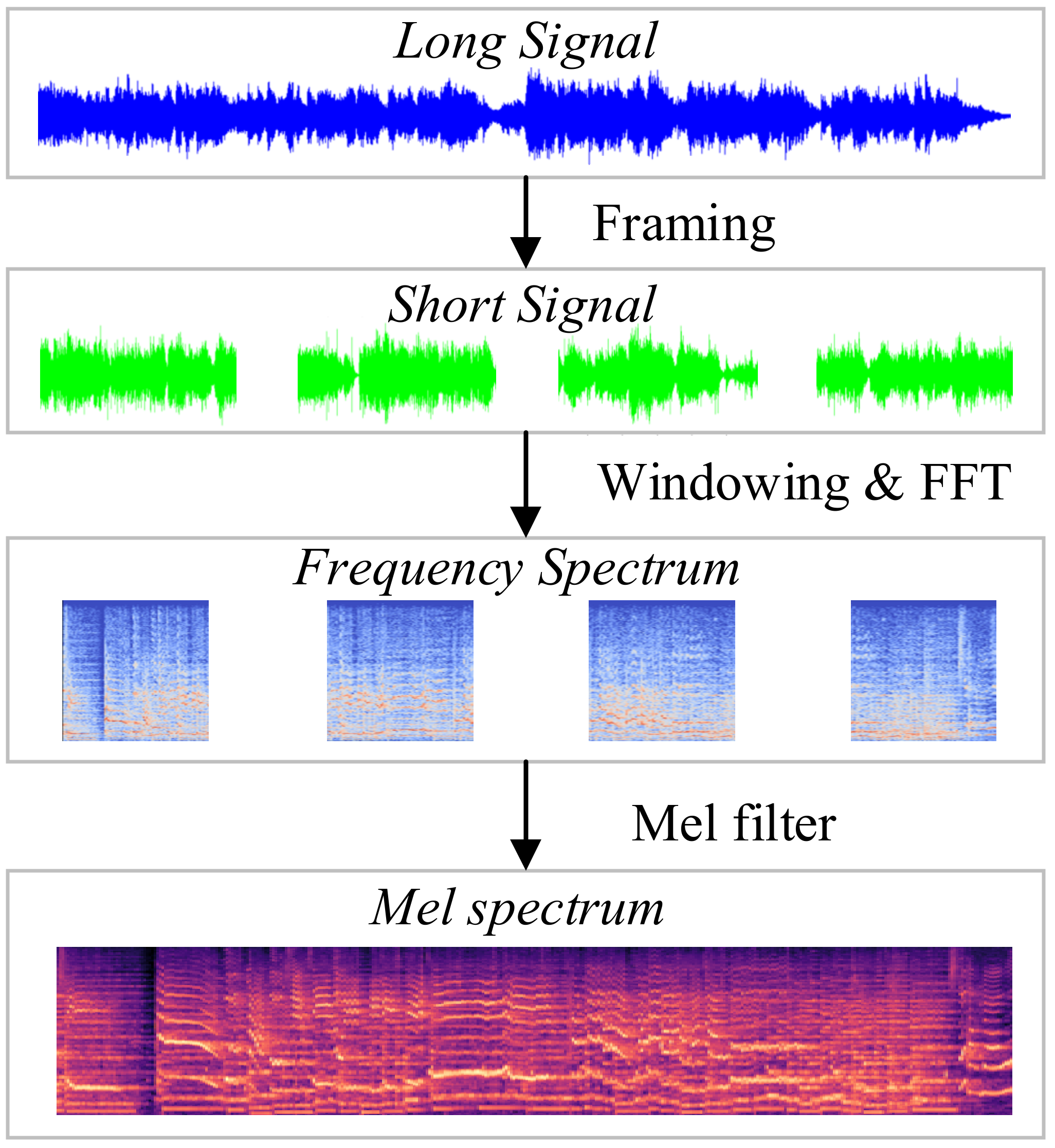
3.2. Spectrum Analysis
3.2.1. Slicing
3.2.2. Framing
3.2.3. Windowing
3.2.4. Fast Fourier Transformation
3.2.5. Mel-Frequency Cepstrum
3.3. LSTM
4. Experimental Setup
- (1)
- Data processing. It consists of data pre-processing and data augmentation. After a series of operations, such as framing, windowing and Fourier transform of the original Cantonese opera singing signal, the Mel-Frequency Cepstrum of each Cantonese opera singing signal was then obtained as model input by a Mel filter.
- (2)
- Model design and prediction. The CoGCNet model based Cantonese Opera singing genre classification model consists of a first-level network (Inception-CNN) and a second-level network (CNN-2LSTM). This classification model takes advantage of the cascaded fused Inception-CNN network to fuse the shallow and deep information of each singing section so as to enhance its feature extraction capacity. The CNN-2LSTM network, which is a combination of CNN and two-layer LSTM stacking, learns the logical features among each audio segment to extract the contextual association semantics. Finally, the Majority Vote Algorithm is utilized to decide the predicted Cantonese opera singing category and output the results.
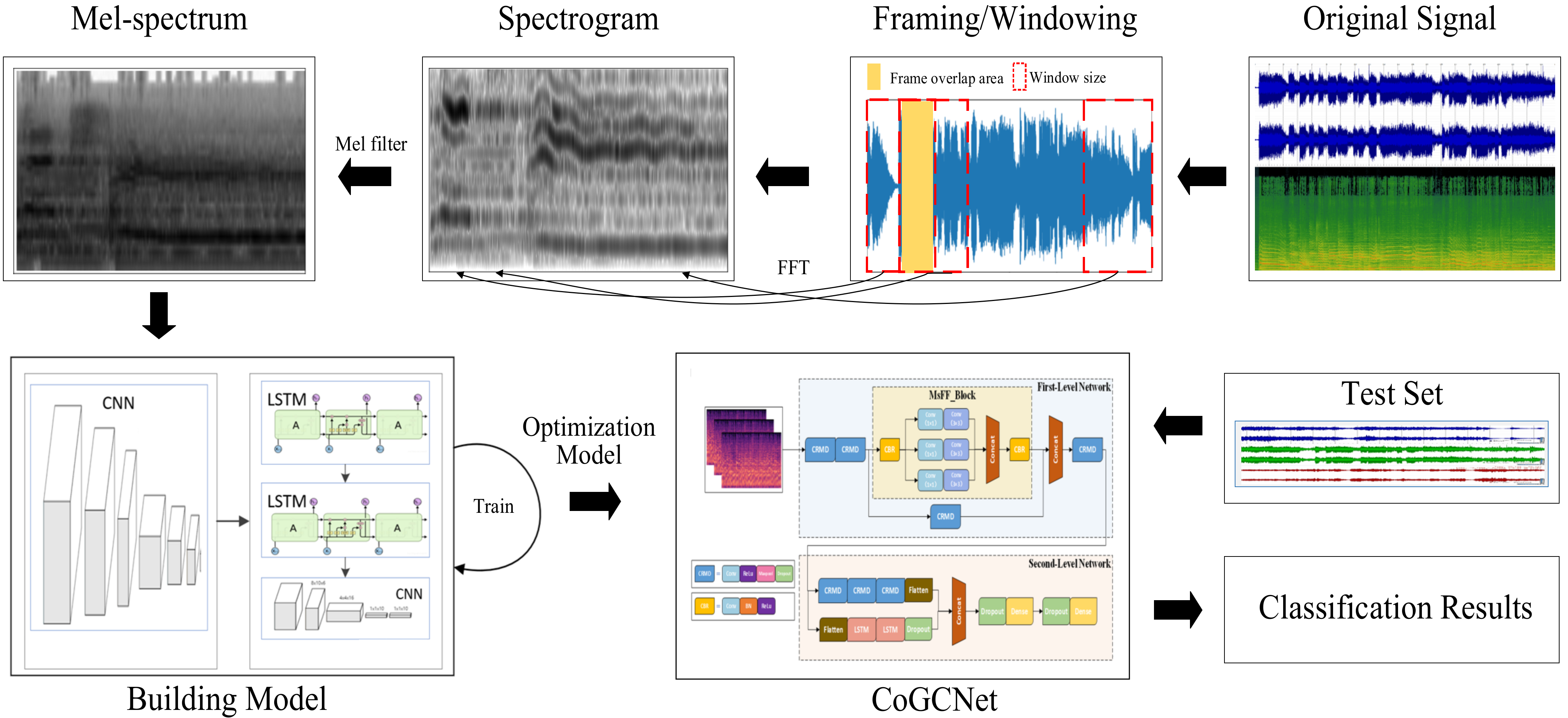
4.1. Data Processing
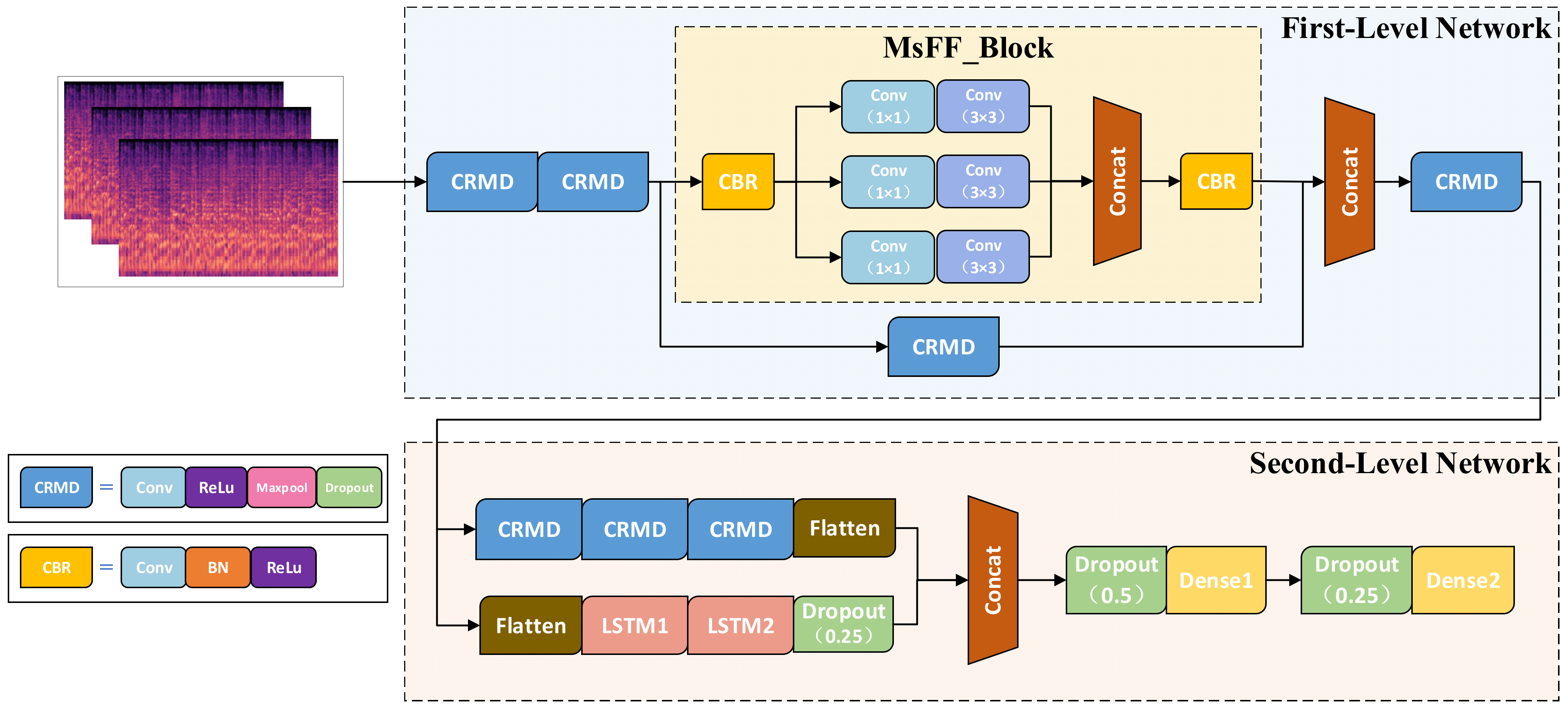
4.2. Network Architectures
4.2.1. First-Level Network Model Design
- CRMD block
- 2.
- MsFF_block
4.2.2. Second-Level Network Model Design
4.3. Training Algorithm Settings
4.4. Metrics
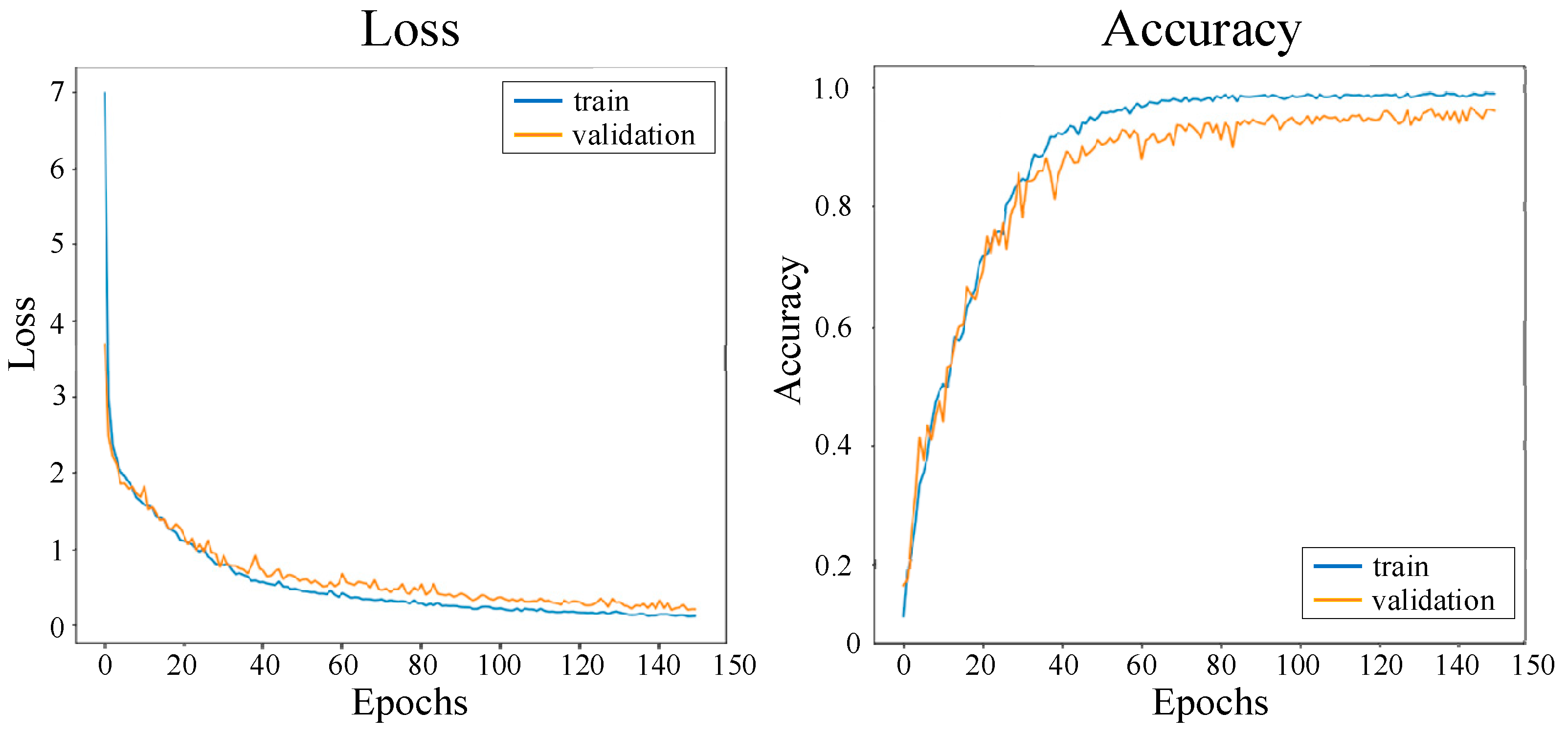
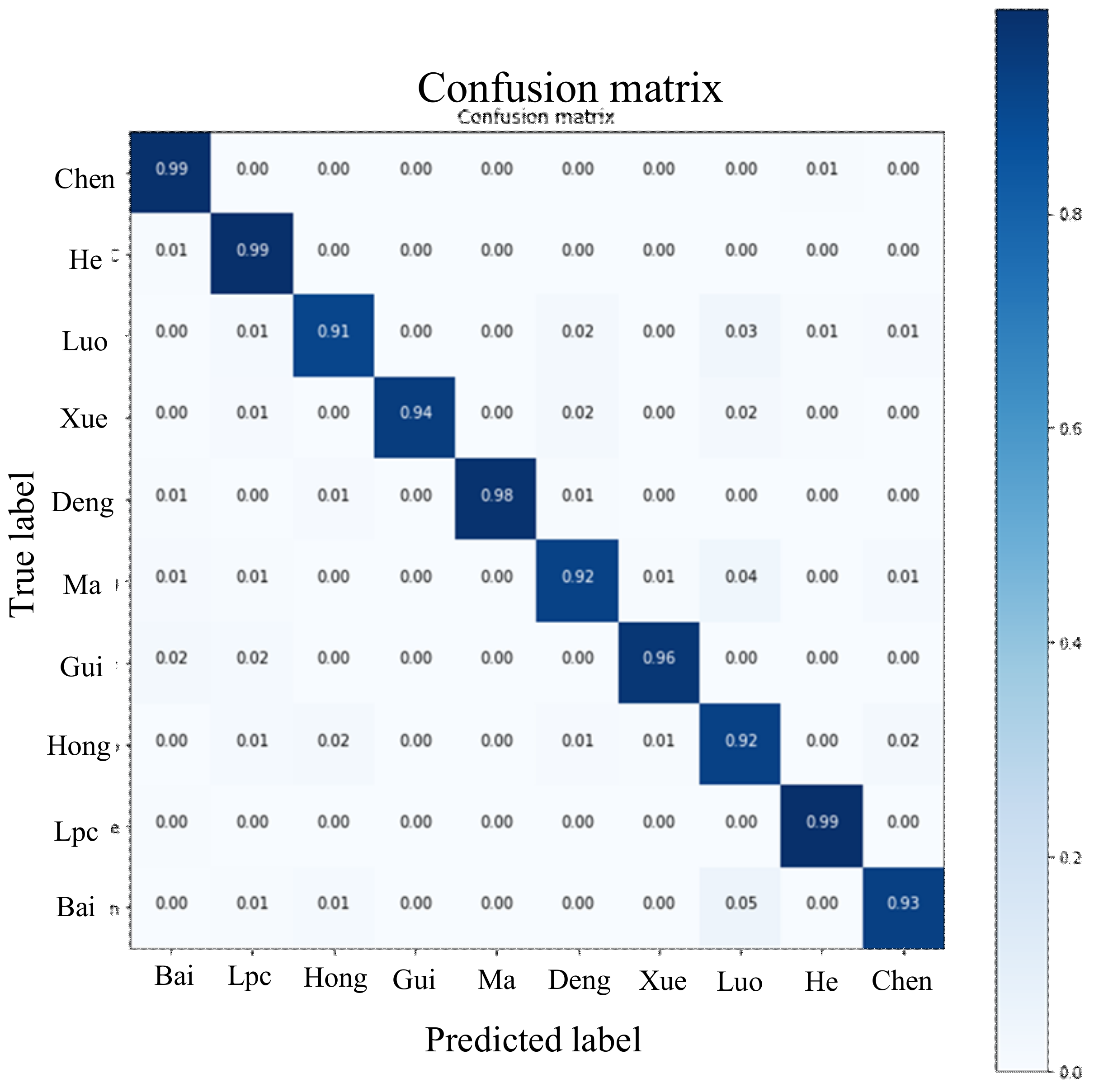
5. Experimental Results
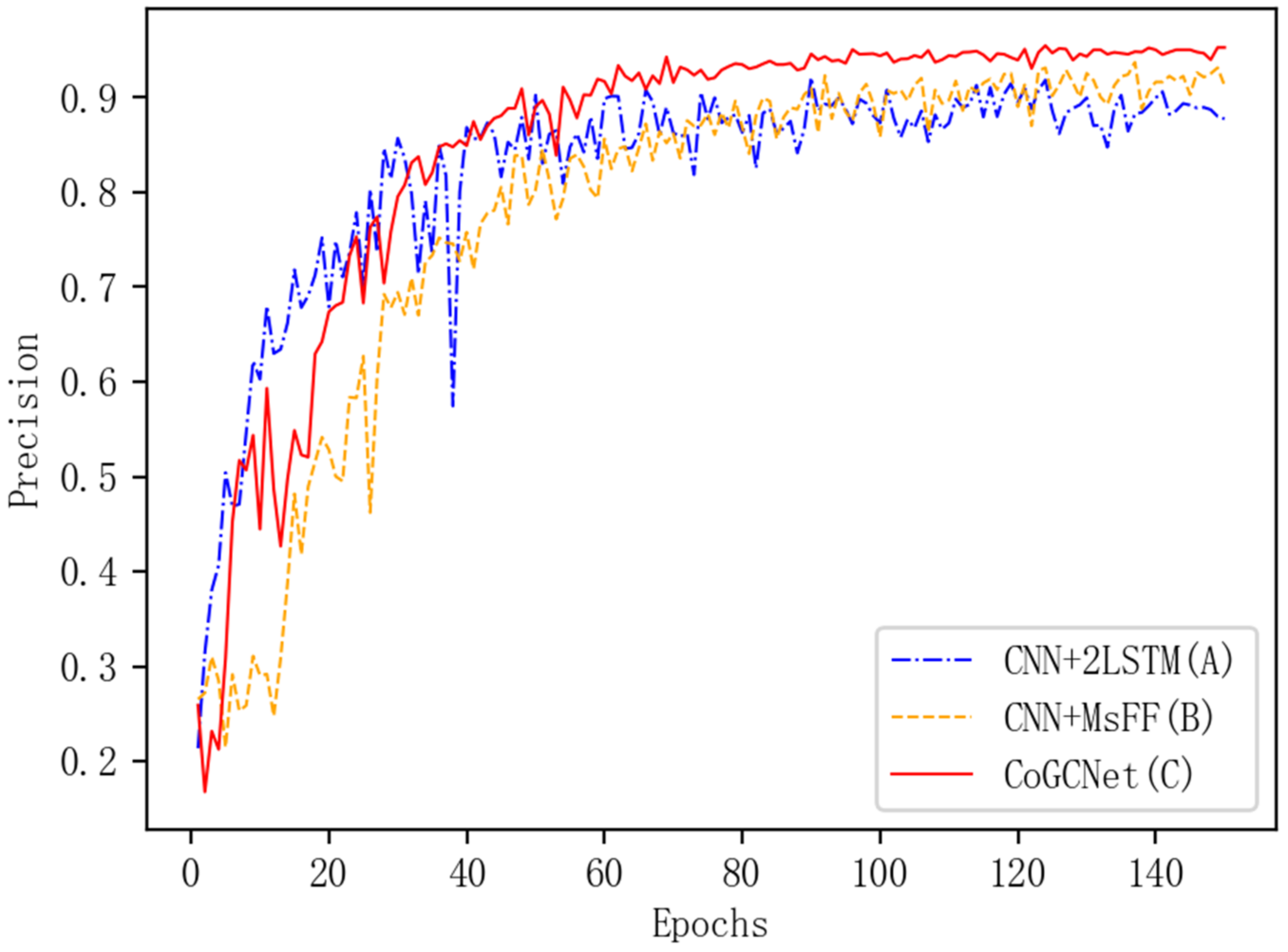
5.1. Ablation Experiment
5.2. Performance of CoGCNet in 10-Class Dataset
5.3. Discussion and Comparative Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, R.Q. Discuss on the Protection and Inheritance of Traditional Performing Arts. Chin. Cult. Res. 2019, 1–14. [Google Scholar] [CrossRef]
- Song, J.H. Some Thoughts on the Digital Protection of Intangible Cultural Heritage. Cult. Herit. 2015, 2, 1–8. [Google Scholar]
- Dang, Q.; Luo, Z.; Ouyang, C.; Wang, L.; Xie, M. Intangible Cultural Heritage in China: A Visual Analysis of Research Hotspots, Frontiers, and Trends Using CiteSpace. Sustainability 2021, 13, 9865. [Google Scholar] [CrossRef]
- Xia, H.; Chen, T.; Hou, G. Study on Collaboration Intentions and Behaviors of Public Participation in the Inheritance of ICH Based on an Extended Theory of Planned Behavior. Sustainability 2020, 12, 4349. [Google Scholar] [CrossRef]
- Xue, Y.F. The Inheritance and development path of Local Opera based on digital resources—Comment on The Digital Protection and Development of Zhejiang Opera Art Resources. Chin. Educ. J. 2021, 10, 138. [Google Scholar]
- Liu, J.K. The Inheritance and Development of Cantonese Opera Singing. Drama Home 2017, 10, 22–24. [Google Scholar]
- Zhang, Z.L. Cantonese Opera: Connecting the past and innovating the Future. China Art Daily 2021, 2536, 3–4. [Google Scholar]
- Nbca, B.; Sgk, A. Dialect Identification using Chroma-Spectral Shape Features with Ensemble Technique. Comput. Speech Lang. 2021, 70, 101230. [Google Scholar]
- Yu, W.; Hua, M.; Zhang, Y. Audio Classification using Attention-Augmented Convolutional Neural Network. Knowl. Based Syst. 2018, 161, 90–100. [Google Scholar]
- Cao, Y.; Huang, Z.L.; Sheng, Y.J.; Liu, C.; Fei, H.B. Noise Robust Urban Audio Classification Based on 2-Order Dense Convolutional Network Using Dual Features. J. Beijing Univ. Posts Telecommun. 2021, 44, 86–91. [Google Scholar]
- Ye, H.L.; Zhu, W.N.; Hong, L. Music Style Conversion Method with Voice Based on CQT and Mayer Spectrum. Comput. Sci. 2021, 48, 326–330. [Google Scholar]
- Gao, L.; Xu, K.; Wang, H.; Peng, Y. Multi-representation knowledge distillation for audio classification. Multimed. Tools Appl. 2020, 81, 5089–5112. [Google Scholar] [CrossRef]
- Birajdar, G.K.; Patil, M.D. Speech and music classification using spectrogram based statistical descriptors and extreme learning machine. Multimed. Tools Appl. 2019, 78, 15141–15168. [Google Scholar] [CrossRef]
- Fu, W.; Yang, Y. Sound frequency Classification method based on coiling neural network and Random forest. J. Comput. Appl. 2018, 38, 58–62. [Google Scholar]
- Asif, A.; Mukhtar, H.; Alqadheeb, F.; Ahmad, H.F.; Alhumam, A. An approach for pronunciation classification of classical Arabic phonemes using deep learning. Appl. Sci. 2022, 12, 238. [Google Scholar] [CrossRef]
- Cao, P. Identification and classification of Chinese traditional musical instruments based on deep learning algorithm. In Proceedings of the the 2nd International Conference on Computing and Data Science, Palo Alto, CA, USA, 28 January 2021; pp. 1–5. [Google Scholar]
- Zhang, K. Music style classification algorithm based on music feature extraction and deep neural network. Wirel. Commun. Mob. Comput. 2021, 2021, 1–7. [Google Scholar] [CrossRef]
- Alvarez, A.A.; Gómez, F. Motivic Pattern Classification of Music Audio Signals Combining Residual and LSTM Networks. Int. J. Interact. Multi. 2021, 6, 208–214. [Google Scholar] [CrossRef]
- Iloga, S.; Romain, O.; Tchuenté, M. A sequential pattern mining approach to design taxonomies for hierarchical music genre recognition. Pattern Anal. Appl. 2018, 21, 363–380. [Google Scholar] [CrossRef]
- Wang, J.J.; Huang, R. Music Emotion Recognition Based on the Broad and Deep Learning Network. J. East China Univ. Sci. Technol. Nat. Sci. 2021, 1–8. [Google Scholar] [CrossRef]
- Jia, N.; Zheng, C.J. Music theme recommendation Model based on attentional LSTM. Comput. Sci. 2019, 46, 230–235. [Google Scholar]
- Xia, Y.T.; Jiang, Y.W.; Li, T.R.; Ye, T. Deep Learning Network for The Classification of Beethoven’s piano sonata creation period. Fudan J. Nat. Sci. 2021, 60, 353–359. [Google Scholar]
- Zhang, Z.; Chen, X.; Wang, Y.; Yang, J. Accent Recognition with Hybrid Phonetic Features. Sensors 2021, 21, 186258. [Google Scholar] [CrossRef] [PubMed]
- Mishachandar, B.; Vairamuthu, S. Diverse ocean noise classification using deep learning. Appl. Acoust. 2021, 181, 108141. [Google Scholar] [CrossRef]
- Lhoest, L.; Lamrini, M.; Vandendriessche, J.; Wouters, N.; da Silva, B.; Chkouri, M.Y.; Touhafi, A. MosAIc: A Classical Machine Learning Multi-Classifier Based Approach against Deep Learning Classifiers for Embedded Sound Classification. Appl. Sci. 2021, 11, 8394. [Google Scholar] [CrossRef]
- Farooq, M.; Hussain, F.; Baloch, N.K.; Raja, F.R.; Yu, H.; Zikria, Y.B. Impact of feature selection algorithm on speech emotion recognition using deep convolutional neural network. Sensors 2020, 20, 6008. [Google Scholar] [CrossRef]
- Li, W.; Li, Z.J.; Gao, Y.W. Understanding digital music—A review of music information retrieval technology. J. Fudan Univ. (Nat. Sci.) 2018, 57, 271–313. [Google Scholar]
- Huang, X. Research on Opera Classification Method Based on Deep Learning. Master’s Thesis, South China University of Technology, Guangzhou, China, 2020. [Google Scholar]
- Huang, J.; Lu, H.; Meyer, P.L. Acoustic scene classification using deep learning-based ensemble averaging. In Proceedings of the the 4th Workshop on Detection and Classification of Acoustic Scenes and Events, New York, NY, USA, 25–26 October 2019; pp. 94–98. [Google Scholar]
- Ba Wazir, A.S.; Karim, H.A.; Abdullah, M.H.L.; AlDahoul, N.; Mansor, S.; Fauzi, M.F.A.; See, J.; Naim, A.S. Design and implementation of fast spoken foul language recognition with different end-to-end deep neural network architectures. Sensors 2021, 21, 710. [Google Scholar] [CrossRef]
- Liu, H. Analysis of Cantonese opera singing music. Chin. Theatre 2016, 8, 70–71. [Google Scholar]
- Liu, Y.S.; Wang, Z.H.; Hou, Y.R.; Yan, H.B. A feature extraction method for malicious code based on probabilistic topic model. J. Comput. Res. Dev. 2019, 56, 2339–2348. [Google Scholar]
- Zhu, H.; Ding, M.; Li, Y. Gibbs phenomenon for fractional Fourier series. IET Signal Process. 2011, 5, 728–738. [Google Scholar] [CrossRef]
- Hasija, T.; Kadyan, V.; Guleria, K.; Alharbi, A.; Alyami, H.; Goyal, N. Prosodic Feature-Based Discriminatively Trained Low Resource Speech Recognition System. Sustainability 2022, 14, 614. [Google Scholar] [CrossRef]
- Huang, G.X.; Tian, Y.; Kang, J.; Liu, J.; Xia, S.H. Long short term memory recurrent neural network acoustic models using i-vector for low resource speech recognition. Appl. Res. Comput. 2017, 34, 392–396. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num | Class | Label | Operas Num | Number of Files (.Wav) |
|---|---|---|---|---|
| 1 | Luo Jiabao | Luo | 34 | 100 |
| 2 | Hong Xiannv | Hong | 32 | 100 |
| 3 | Ma Shizeng | Ma | 34 | 100 |
| 4 | Deng Zhiju | Deng | 29 | 100 |
| 5 | He Feifan | He | 33 | 100 |
| 6 | Bai Jurong | Bai | 27 | 100 |
| 7 | Chen Xiaofeng | Chen | 31 | 100 |
| 8 | Luo Pinchao | Lpc | 28 | 100 |
| 9 | Xue Juexian | Xue | 29 | 100 |
| 10 | Gui Mingyang | Gui | 28 | 100 |
| Dataset | Labels | Num | Train/Test |
|---|---|---|---|
| CoD1 | Luo, Hong, Ma, Deng, He | 165 | 70%/30% |
| CoD2 | Luo, Hong, Ma, Deng, He, Bai, Chen, Lpc, Xue, Gui | 305 | 70%/30% |
| Num | Name | Parameter | Value |
|---|---|---|---|
| 1 | sampling_rate | sampling rate | 44,100 Hz |
| 2 | duration | duration | 30 s |
| 3 | n_mels | Number of Mel filter banks | 128 |
| 4 | n_fft | FFT Window length | 1024 |
| 5 | hop_length | Window sliding length per frame | 128 |
| 6 | spe_width | The duration of the spectrum map | 1.5 s |
| Block | Hyperparameters |
|---|---|
| CRMD | Conv2D (kernel size = (3, 3), strides = (1, 1)); MaxPooling2D (pool_size = (2, 2), strides = (2, 2)); Dropout (discard rate = 0.25) |
| CBR | Conv2D (kernel size = (3, 3), strides = (2, 2)) |
| LSTM | LSTM1 (units = 256, return_sequences = True); LSTM2 (units = 128, return_sequences = False) |
| Dense | Dense1 (units = 512, activation = ‘relu’, kernel_regularizer = tf.keras.regularizers.l2 (0.02)); Dense2 (units = 10, activation = ‘softmax’, kernel_regularizer = tf.keras.regularizers.l2 (0.02)) |
| Number | CNN | 2LSTM | MsFF | Model |
|---|---|---|---|---|
| A | √ | √ | — | CNN+2LSTM |
| B | √ | — | √ | CNN+MsFF |
| C | √ | √ | √ | CoGCNet |
| Model | F1/% | F1/% | P/% | R/% | ||||
|---|---|---|---|---|---|---|---|---|
| Luo | Hong | Deng | He | Ma | ||||
| CNN+2LSTM | 82.64 | 79.04 | 78.26 | 96.08 | 99.01 | 87.01 | 89.38 | 87.20 |
| CNN+MsFF | 86.81 | 86.89 | 86.15 | 93.43 | 99.00 | 90.46 | 90.80 | 91.00 |
| CoGCNet | 87.56 | 92.46 | 90.25 | 96.55 | 99.01 | 93.16 | 93.18 | 93.20 |
| Num | Class | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| 1 | Luo | 95.19 ± 0.48 | 99.00 ± 0.50 | 97.06 ± 0.48 |
| 2 | Lpc | 93.40 ± 0.88 | 99.00 ± 0.01 | 96.12 ± 0.99 |
| 3 | Hong | 95.79 ± 2.06 | 91.92 ± 3.54 | 93.82 ± 1.64 |
| 4 | Gui | 99.93 ± 0.04 | 94.95 ± 1.01 | 97.38 ± 1.76 |
| 5 | Ma | 99.95 ± 0.03 | 97.03 ± 0.49 | 98.46 ± 0.98 |
| 6 | Deng | 93.88 ± 2.01 | 92.00 ± 0.97 | 92.93 ± 1.94 |
| 7 | Xue | 97.96 ± 1.02 | 96.00 ± 1.00 | 96.97 ± 1.50 |
| 8 | Luo | 86.79 ± 5.47 | 92.93 ± 3.03 | 89.76 ± 0.48 |
| 9 | He | 98.02 ± 0.49 | 99.95 ± 0.48 | 99.00 ± 0.48 |
| 10 | Chen | 95.88 ± 0.80 | 93.00 ± 3.50 | 94.42 ± 2.03 |
| - | Average | 95.68 ± 0.76 | 95.58 ± 0.75 | 95.60 ± 0.74 |
| Model | Recall (%) | Precision (%) | F1 (%) | Parameters (M) | FLOPs (G) | CPU Test Time (ms) | GPU Test Time (ms) |
|---|---|---|---|---|---|---|---|
| AlexNet | 89.52 | 89.6 | 89.43 | 162.46 | 1.35 | 47.98 | 26.88 |
| VGG16 | 91.98 | 92.51 | 92.00 | 408.32 | 20.60 | 118.51 | 62.06 |
| VGG19 | 92.04 | 92.51 | 92.50 | 428.59 | 26.20 | 128.11 | 65.83 |
| GoogLeNet | 92.75 | 93.30 | 92.85 | 22.78 | 1.48 | 13.14 | 7.63 |
| ResNet50 | 95.00 | 95.07 | 94.98 | 122.41 | 5.19 | 37.48 | 22.16 |
| CoGCNet | 95.58 | 95.69 | 95.60 | 37.56 | 0.40 | 7.44 | 4.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Zhao, W.; Wang, Q.; Zhao, Y. The Sustainable Development of Intangible Cultural Heritage with AI: Cantonese Opera Singing Genre Classification Based on CoGCNet Model in China. Sustainability 2022, 14, 2923. https://doi.org/10.3390/su14052923
Chen Q, Zhao W, Wang Q, Zhao Y. The Sustainable Development of Intangible Cultural Heritage with AI: Cantonese Opera Singing Genre Classification Based on CoGCNet Model in China. Sustainability. 2022; 14(5):2923. https://doi.org/10.3390/su14052923
Chicago/Turabian StyleChen, Qiao, Wenfeng Zhao, Qin Wang, and Yawen Zhao. 2022. "The Sustainable Development of Intangible Cultural Heritage with AI: Cantonese Opera Singing Genre Classification Based on CoGCNet Model in China" Sustainability 14, no. 5: 2923. https://doi.org/10.3390/su14052923