
Lessons Learned from Topic Modeling Analysis of COVID-19 News to Enrich Statistics Education in Korea


Abstract
:1. Introduction
- How were COVID-19 statistics presented in the mainstream media?
- What kinds of statistics were frequently used in the context of the COVID-19 outbreak?
- What were the topics of interest in the news articles containing “Corona” and “Statistics”?
- How did the trend of topics change over time?
- What implications for South Korean statistics education can be drawn from statistics used in the social world during the COVID-19 diffusion?
2. Literature Review
2.1. Text Mining: Focusing on Topic Modeling
2.2. Topic Modeling Analysis Related to Mathematics Education
3. Data and Methods
3.1. Data
3.2. Methods
4. Results
4.1. Keyword Analysis from Term Frequency
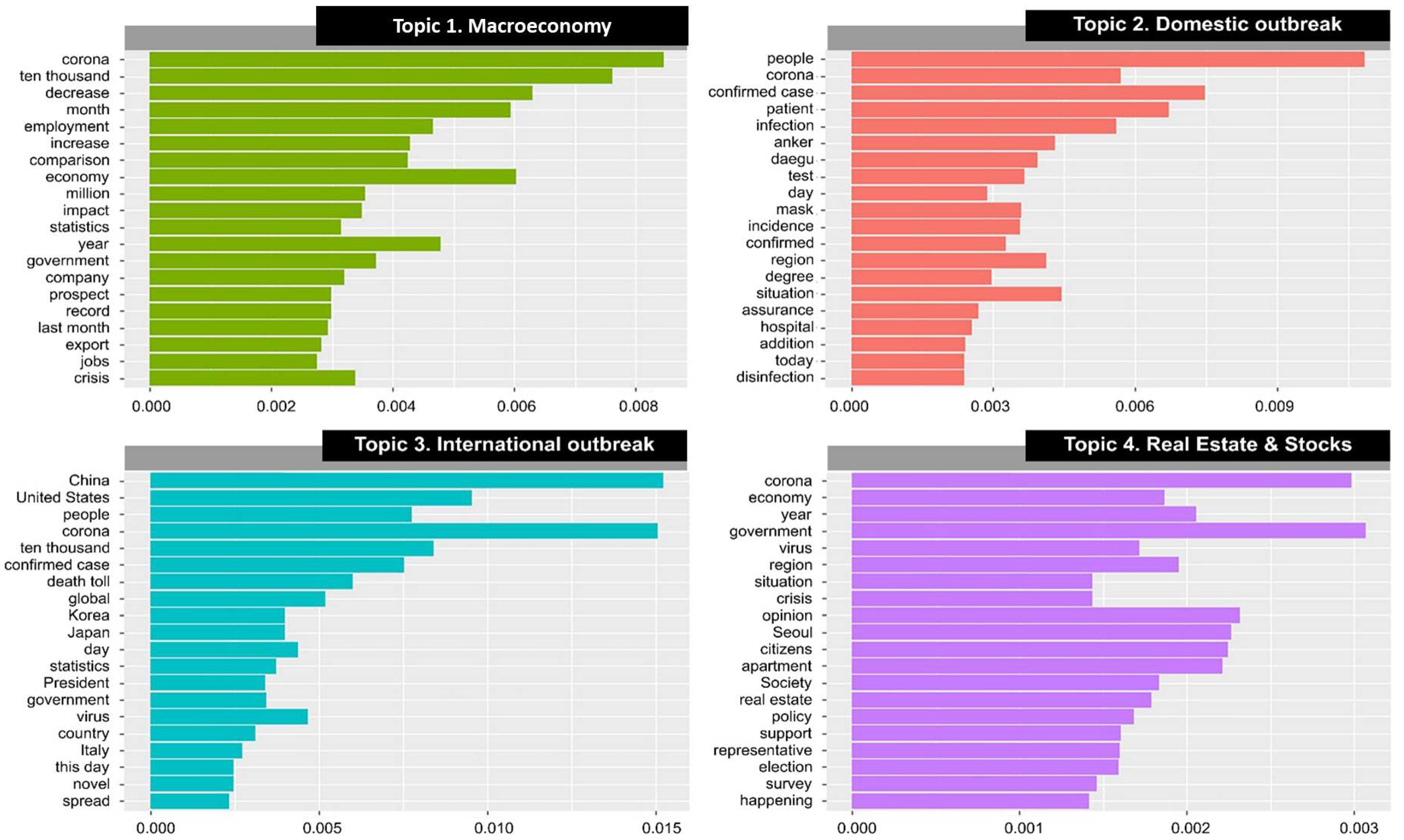
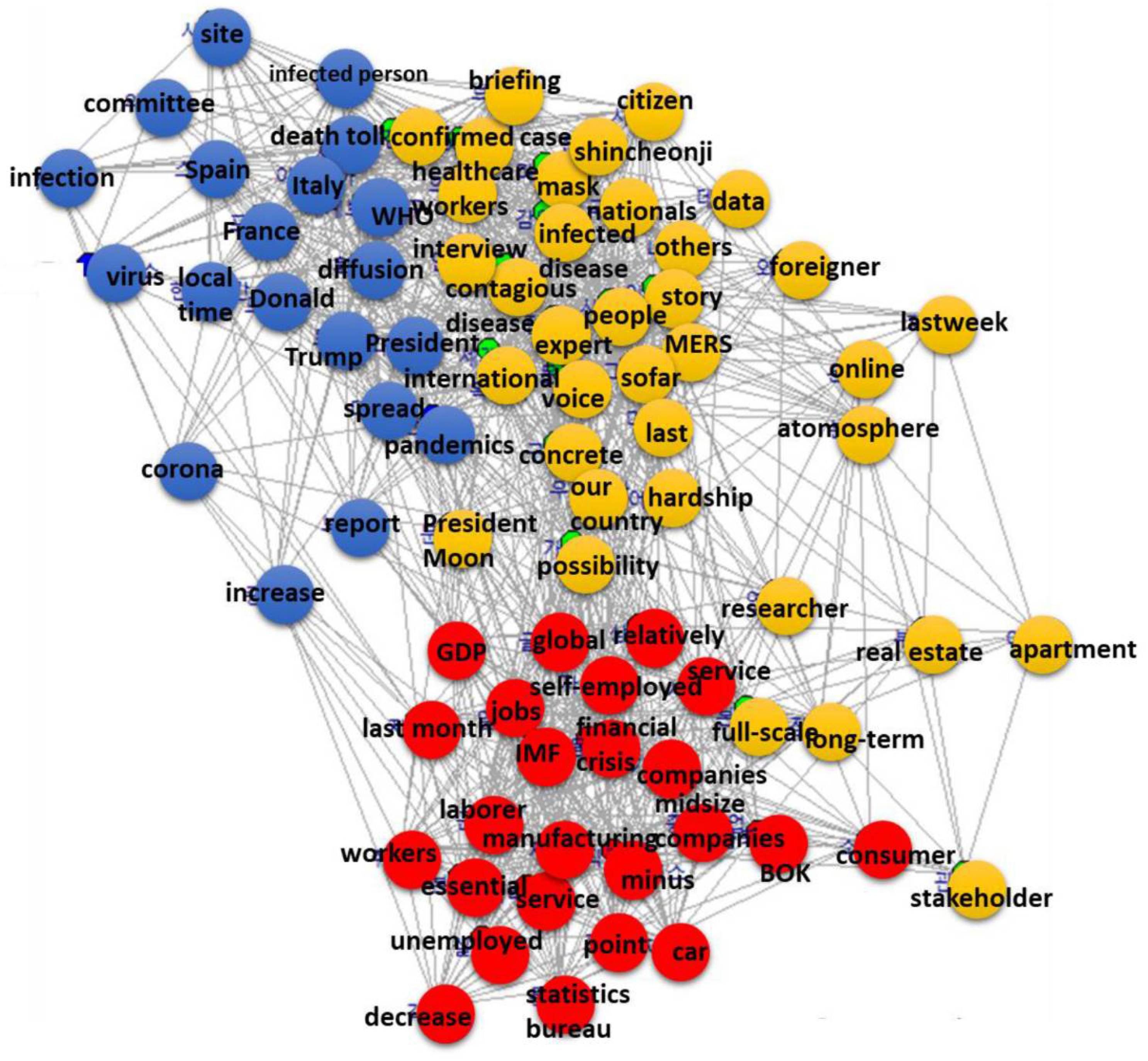
4.2. LDA Topic Model and Semantic Network Analysis
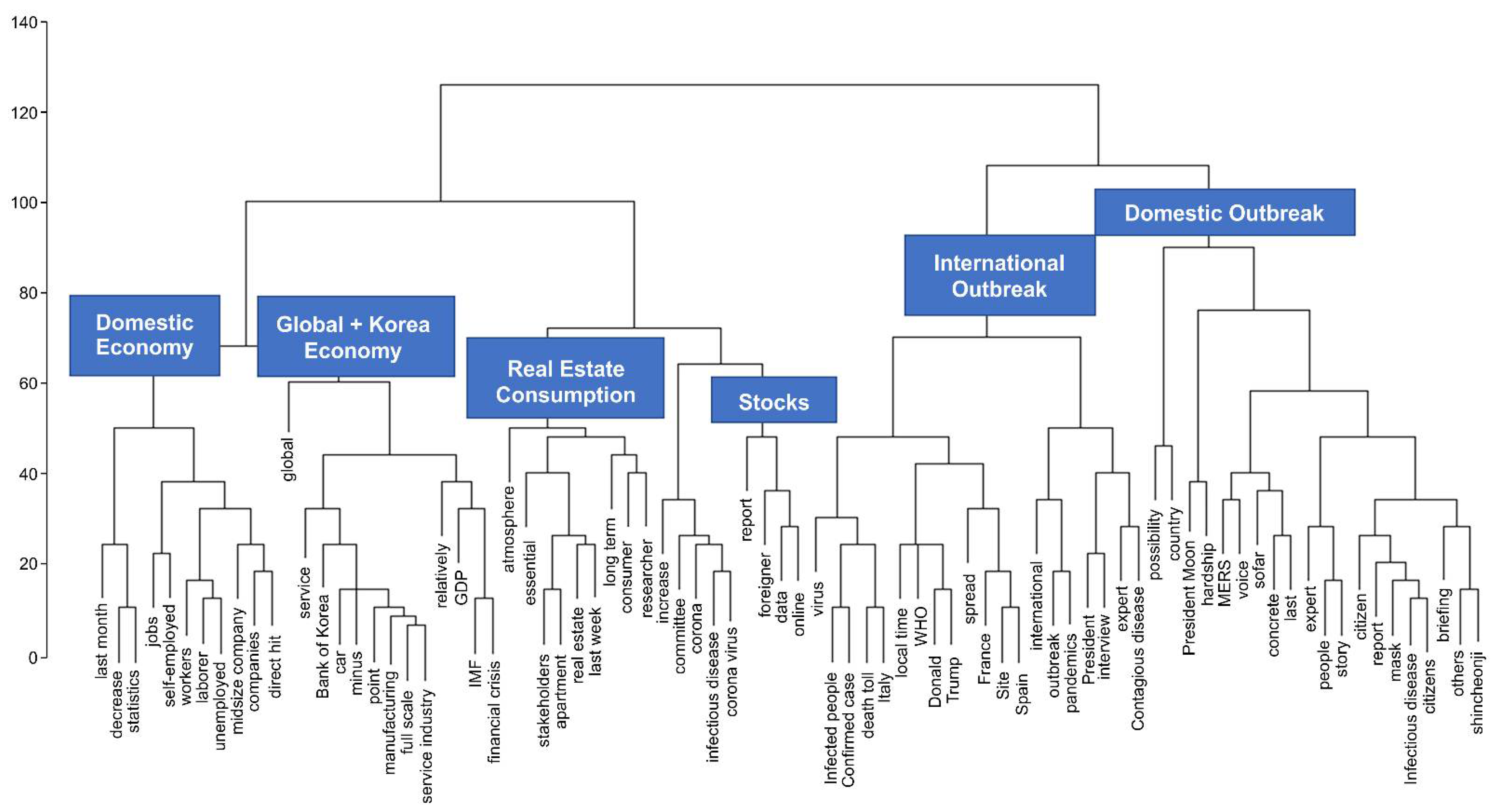
4.3. Clustering with Structural Equivalence Measure
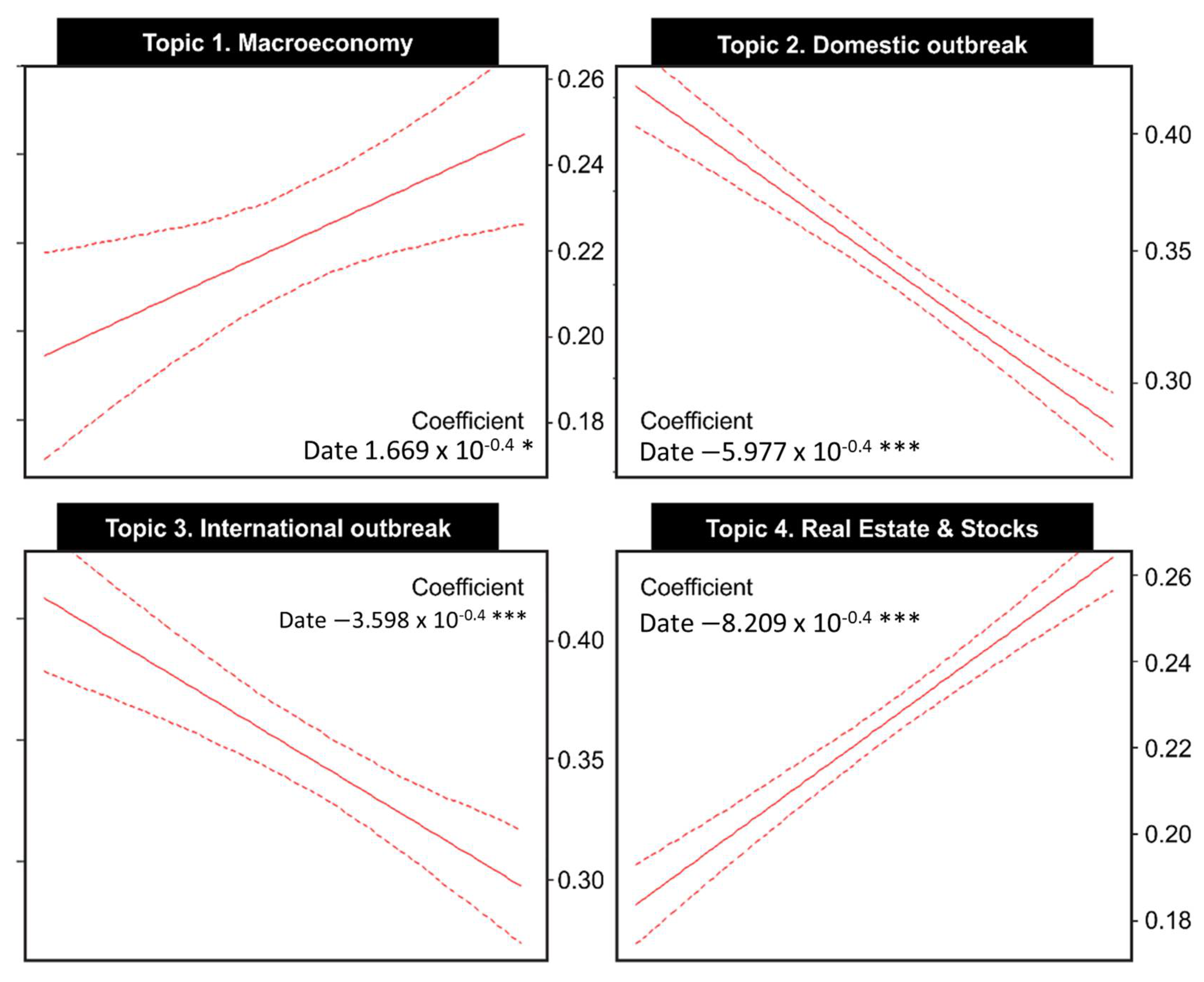
4.4. Trend in Topics: Simple Linear Regression Analysis
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Burgess, S.; Sievertsen, H.H. Schools, Skills, and Learning: The Impact of COVID-19 on Education. Available online: https://voxeu.org/article/impact-covid-19-education (accessed on 10 December 2021).
- Chang, I.H. COVID-19 Changes Education: Hope the Knowledge of Cyber Universities in Korea be Utilized. Available online: https://news.unn.net/news/articleView.html?idxno=228219 (accessed on 10 July 2020).
- Kim, H.S. The Value of Mathematics from COVID-19. Available online: http://www.busan.com/view/busan/view.php?code=2020042818574048312 (accessed on 20 December 2021).
- Grolemund, G.; Wickham, H. A cognitive interpretation of data analysis. Int. Stat. Rev. 2014, 82, 184–204. Available online: http://www.jstor.org/stable/43299753 (accessed on 25 January 2022). [CrossRef]
- Siegelman, N.; Frost, R. Statistical learning as an individual ability: Theoretical perspectives and empirical evidence. J. Mem. Lang. 2015, 81, 105–120. [Google Scholar] [CrossRef] [PubMed]
- Ministry of Education. Mathematics Curriculum. Available online: https://www.moe.go.kr/boardCnts/view.do?boardID=141&boardSeq=60747&lev=0&searchType=null&statusYN=W&page=20&s=moe&m=040401&opType=N (accessed on 25 January 2022).
- Kuem, J.H. An Impact Analysis of Content Reduction in High School Mathematics Curriculum on Preparing Next Generation STEM Majors; KAST Research Report #125; KAST: Sungnam, Korea, 2018. [Google Scholar]
- Na, G.S.; Park, M.M.; Kim, D.W.; Kim, Y.; Lee, S.J. Exploring the direction of mathematics education in the future age. J. Educ. Res. Math. 2018, 28, 437–478. [Google Scholar] [CrossRef]
- Lee, H.S.; Park, J.K.; Jung, E.J. ‘AI Mathematics’ Is a Global Craze, but It’s Been Deleted from High School Curriculum in Korea. Available online: https://www.hankyung.com/it/article/2019100661071 (accessed on 10 July 2020).
- Woo, J.H. The Educational Foundation of School Mathematics; Seoul National University Press: Seoul, Korea, 2007. [Google Scholar]
- Woo, J.H. An exploration of the reform direction of teaching statistics. Sch. Math. 2000, 2, 1–27. [Google Scholar]
- Ministry of Education. The 2nd Comprehensive Mathematics Education Plan (2015–2019). Available online: https://www.moe.go.kr/boardCnts/view.do?boardID=294&boardSeq=58701&lev=0&searchType=null&statusY (accessed on 8 March 2022).
- Youm, J.H. What Is the Direction of Statistical Education in the Era of the Fourth Industrial Revolution? Available online: http://dongascience.donga.com/news.php?idx=9528 (accessed on 25 January 2022).
- Franklin, C.G.; Kader, G.; Mewborn, D.; Moreno, J.; Peck, R.; Perry, M.; Scheaffer, R. Guidelines for Assessment and Instruction in Statistics Education Report; American Statistical Association: Alexandria, VA, USA, 2007. [Google Scholar]
- Jang, H.J. Effects of Statistical Project Based Learning on the Information Processing Competencies and Communication Competencies of High School Students. Master’s Thesis, Korea University, Seoul, Korea, 2018. [Google Scholar]
- Russo, L.S.; Passannante, M.R. Statistics fever. Math. Teach. Middle Sch. 2001, 6, 370–376. [Google Scholar] [CrossRef]
- Wild, C.J.; Pfannkuch, M. Statistical thinking in empirical enquiry. Int. Stat. Rev. 1999, 67, 223–265. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models: Surveying a suite of algorithms that offer a solution to managing large document archives. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Hofmann, T. Probabilistic Latent Semantic Analysis. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence; Laskey, K.B., Prade, H., Eds.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1999; pp. 289–296. [Google Scholar]
- Mohr, J.W.; Bogdanov, P. Introduction-topic models: What they are and why they matter. Poetics 2013, 41, 545–569. [Google Scholar] [CrossRef]
- Shin, K.S. Topic model analysis of research trend on renewable energy. J. Korea Acad. Ind. Coop. Soc. 2015, 16, 6411–6418. [Google Scholar]
- Baker, S.R.; Bloom, N.; Davis, S.J. Measuring economic policy uncertainty. Q. J. Econ. 2016, 131, 1593–1636. [Google Scholar] [CrossRef]
- Park, S.U. Analysis of social media contents about broadcast media through topic modeling. J. Inform. Technol. Serv. 2016, 15, 81–92. [Google Scholar]
- Seol, Y.H. A Discourse Analysis on Articles About Gifted Education and the Gifted in Major Newspapers of Korea; Unpublished Dissertation, Konkuk University: Seoul, Korea, 2017. [Google Scholar]
- Chung, W.J. Keyword and topic analysis on the THAAD conflict between South Korea and China: Based on a time-series topic modeling and a semantic network analysis. Korean J. Advert. Public. Relat. 2018, 20, 143–196. [Google Scholar] [CrossRef]
- Kim, Y.W.; Ham, S.K.; Kim, Y.J.; Choi, J.M. A critical discourse analysis on a social issue—Focusing on the THAAD deployment big data analysis. Commun. Theor. 2017, 13, 40–91. [Google Scholar]
- Lee, S.H.; Lee, Y.K.; Song, E.R.; Kim, H.W. Comparative analysis of happiness and unhappiness using topic modeling: Korea, U.S., U.K., and Brazil. Knowl. Manag. Rev. 2017, 18, 101–124. [Google Scholar]
- Lee, S.S. Analysis of social issues of the newspaper articles on Gyeongju earthquakes. J. Korean Libr. Inf. Sci. Soc. 2017, 48, 53–72. [Google Scholar]
- Lee, J.W.; Kim, S.H. News frames in the coverage of fine-dust disaster—Application of structural topic modeling. Korean J. Journal. Commun. Stud. 2018, 62, 125–158. [Google Scholar]
- Chandelier, M.; Steuckardt, A.; Mathevet, R.; Diwersy, S.; Gimenez, O. Content analysis of newspaper coverage of wolf recolonization in France using structural topic modeling. Biol. Conserv. 2018, 220, 254–261. [Google Scholar] [CrossRef]
- Eskici, H.B.; Koçak, N.A. A text mining application on monthly price developments reports. Cent. Bank Rev. 2018, 18, 51–60. [Google Scholar] [CrossRef]
- Choi, J.H.; Lee, H.S.; Jin, E.H. A topic modeling analysis of the news topic on the 4th Industrial Revolution in Korea: Focusing on the difference by media type and each major period. J. Cyber. Commun. Acad. Soc. 2019, 36, 173–219. [Google Scholar]
- Han, B.A.; Ostfeld, R.S. Topic modeling of major research themes in disease ecology of mammals. J. Mammal. 2019, 100, 1008–1018. [Google Scholar] [CrossRef]
- Feldman, R.; Sanger, J. The Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Methodology; Sage Publications: Washington, DC, USA, 2013. [Google Scholar]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An introduction to latent semantic analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Turney, P.D.; Pantel, P. From frequency to meaning: Vector space models of semantics. J. Artif. Intell. Res. 2010, 37, 141–188. [Google Scholar] [CrossRef]
- DiMaggio, P.; Nag, M.; Blei, D. Exploiting affinities between topic modeling and the sociological perspective on culture: Application to newspaper coverage of US government arts funding. Poetics 2013, 41, 570–606. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. A correlated topic model of science. Ann. Appl. Stat. 2007, 1, 17–35. [Google Scholar] [CrossRef] [Green Version]
- Inglis, M.; Foster, C. Five decades of mathematics education research. J. Res. Math. Educ. 2018, 49, 462–500. [Google Scholar] [CrossRef]
- Choi, J.A.; Kwak, M.H. Topic changes in mathematics educational research based on LDA. J. Educ. Cult. 2019, 25, 1149–1176. [Google Scholar]
- Jin, M.R.; Ko, H.K. Analysis of trends in mathematics education research using text mining. Commun. Math. Educ. 2019, 33, 275–294. [Google Scholar]
- Bicker, L. Coronavirus in South Korea: How ‘Trace, Test and Treat’ May Be Saving Lives. Available online: https://www.bbc.com/news/world-asia-51836898 (accessed on 25 January 2022).
- Kotu, V.; Deshpande, B. Data Science: Concepts and Practice, 2nd ed.; Morgan Kaufmann: Burlington, MA, USA, 2018. [Google Scholar]
- Ramos, J. Using TF-IDF to determine word relevance in document queries. Proc. First Instr. Conf. Mach. Learn. 2003, 242, 133–142. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Doerfel, M.L. What constitutes semantic network analysis? A comparison of research and methodologies. Connections 1998, 21, 16–26. [Google Scholar]
- Drieger, P. Semantic network analysis as a method for visual text analytics. Procedia Soc. Behav. Sci. 2013, 79, 4–17. [Google Scholar] [CrossRef] [Green Version]
- Lima, M.N.; Soares, W.L.; Silva, I.R.; Fagundes, R.A.D.A. A combined model based on clustering and regression to predicting school dropout in higher education institution. Int. J. Comput. Appl. 2020, 176, 1–8. [Google Scholar]
- Ntani, G.; Inskip, H.; Osmond, C.; Coggon, D. Consequences of ignoring clustering in linear regression. BMC Med. Res. Methodol. 2021, 21, 139. [Google Scholar] [CrossRef] [PubMed]
- Rouzbahman, M.; Jovicic, A.; Chignell, M. Can cluster-boosted regression improve prediction of death and length of stay in the ICU? IEEE J. Biomed. Health Inform. 2017, 21, 851–858. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Physic. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [Green Version]
- Shim, H.J. Characteristics of Household Assets in Korea Through International Comparison. Available online: https://investpension.miraeasset.com/file/pdfView.do?fileNm=1538614770775.pdf (accessed on 5 May 2021).
- Ministry of Health and Welfare. COVID-19, Central Disaster and Safety Countermeasures Headquarters Briefing. Available online: http://www.mohw.go.kr/eng/nw/nw0101vw.jsp?PAR_MENU_ID=1007&MENU_ID=100701&page=1&CONT_SEQ=355256 (accessed on 25 January 2022).
- Yang, J.I. A Development of the Project Learning Materials for Improving Statistical Thinking. Master’s Thesis, Gyeongin National University of Education, Incheon, Korea, 2017. [Google Scholar]
- Lee, D.Y.; Jung, J.I. The effects of middle school mathematical statistics area and Python programming STEAM instruction on problem solving ability and curriculum interest. J. Korea Acad. Ind. Coop. Soc. 2019, 20, 336–344. [Google Scholar]
- Douglas, S.F. A Teacher’s Guide to Project-Based Learning; Scarecrow Education: Blue Ridge Summit, PA, USA, 2000. [Google Scholar]
- Kim, H.W.; Ko, H.K. Effectiveness of math-social science conjoined program on students’ attitudes toward in mathematics. J. Kor. Sch. Math. Soc. 2017, 20, 239–254. [Google Scholar]
- Lee, J.H.; Lee, D.B. Extreme Choices Increase with Each Financial Crisis: Education Saves Lives. Available online: https://biz.chosun.com/site/data/html_dir/2020/01/03/2020010300428.html (accessed on 25 January 2022).
- Esmonde, I.; Caswell, B. Teaching mathematics for social justice in multicultural, multilingual elementary classrooms. Can. J. Sci. Math. Technol. Educ. 2010, 10, 244–254. [Google Scholar] [CrossRef]
- Gutstein, E. Teaching and learning mathematics for social justice in an urban, Latino school. J. Res. Math. Educ. 2003, 34, 37–73. [Google Scholar] [CrossRef]
- Gutstein, E. Reading and Writing the World with Mathematics: Toward a Pedagogy for Social Justice; Routledge: New York, NY, USA, 2006. [Google Scholar]
- Osler, J. A Guide for Integrating Issues of Social and Economic Justice into Mathematics Curriculum. Available online: https://irenepark420.files.wordpress.com/2019/04/sjmathguide-1.pdf (accessed on 25 January 2022).
- Kim, J.S.; Park, M.G. The influences of teaching mathematics for social justice on students’ interest towards mathematics and perceptions of mathematical values. J. Elem. Math. Educ. 2015, 19, 409–434. [Google Scholar]
- Park, M.G. A program development of social justice for mathematics education. J. Elem. Math. Educ. 2018, 22, 47–67. [Google Scholar]
- Wager, A.A.; Stinson, D.W. (Eds.) Teaching Mathematics for Social Justice: Conversations with Educators; NCTM: Reston, VA, USA, 2012. [Google Scholar]
- Institute of Education Sciences. Trends in International Mathematics and Science Study (TIMSS). Available online: https://nces.ed.gov/TIMSS/ (accessed on 25 January 2022).
- Organization for Economic Co-Operation and Development. PISA 2015 Draft Collaborative Problem Solving Framework. Available online: https://www.oecd.org/callsfortenders/Annex%20ID_PISA%202015%20Collaborative%20Problem%20Solving%20Framework%20.pdf (accessed on 25 January 2022).
- Lee, S.M. Mathematical Connection in Teaching Correlation—Analysis of 2015 Revised Mathematics Curriculum and Textbooks. Master’s Thesis, Seoul National University, Seoul, Korea, 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TF | TF-IDF | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| corona | 18,827 | stakeholders | 1054 | contagious disease | 574 | confirmed case | 9828.8 | story | 3155.8 | infection | 2244.4 |
| confirmed case | 8373 | online | 944 | local time | 566 | death toll | 7118.1 | manufacturing | 3011.0 | midsize companies | 2242.8 |
| death toll | 3905 | real estate | 941 | Midsize companies | 556 | mask | 6310.9 | Russia | 2916.5 | MERS | 2160.8 |
| last month | 2677 | Statistics Bureau | 920 | Chinese | 540 | President | 6197.4 | foreigner | 2835.1 | infectious disease | 2094.1 |
| virus | 2564 | manufacturing | 887 | Jobless | 536 | jobs | 5638.2 | Statistics Bureau | 2831.2 | unemployed | 2092.9 |
| president | 2455 | service | 864 | International | 534 | Shincheonji | 5105.4 | infected disease | 2745.4 | democratic party | 2068.7 |
| mask | 2200 | infected disease | 834 | hardship | 534 | apartment | 4671.0 | data | 2702.3 | next | 2027.9 |
| jobs | 2003 | story | 814 | pandemics | 531 | Trump | 4665.2 | service | 2672.6 | laborer | 1986.6 |
| infection | 1968 | France | 804 | MERS | 520 | workers | 4660.5 | France | 2667.5 | employee | 1943.5 |
| people | 1649 | expert | 768 | committee | 517 | Italy | 4563.4 | Spain | 2638.3 | pandemics | 1942.2 |
| possibility | 1642 | foreigners | 759 | laborers | 491 | virus | 4546.7 | stakeholders | 2530.1 | President Moon. | 1933.9 |
| Italy | 1565 | Spain | 738 | increase | 491 | people | 4085.8 | Chinese | 2502.4 | SMEs | 1918.5 |
| infected person | 1534 | data | 701 | companies | 471 | last month | 4080.8 | service industry | 2436.1 | consumer | 1913.4 |
| global | 1360 | service industry | 660 | citizens | 469 | infected person | 4076.8 | healthcare workers | 2365.2 | Arrivals | 1907.6 |
| Trump | 1318 | minus | 656 | consumers | 450 | real estate | 3684.9 | corona | 2349.9 | citizens | 1886.1 |
| Shincheonji | 1256 | car | 625 | SMEs | 435 | possibility | 3463.6 | GDP | 2321.5 | bonds | 1837.6 |
| Workers | 1256 | Russia | 623 | direct hit | 434 | global | 3404.1 | minus | 2310.6 | hardship | 1825.4 |
| apartment | 1172 | Healthcare workers | 617 | briefing | 431 | national | 3343.3 | self-employed | 2273.1 | patients | 1785.2 |
| National | 1092 | GDP | 614 | employee | 431 | online | 3223.2 | expert | 2261.4 | international | 1765.7 |
| points | 1068 | self-employed | 588 | democratic party | 428 | point | 3207.6 | car | 2254.1 | IMF | 1762.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, S.; Kim, S. Lessons Learned from Topic Modeling Analysis of COVID-19 News to Enrich Statistics Education in Korea. Sustainability 2022, 14, 3240. https://doi.org/10.3390/su14063240
Kang S, Kim S. Lessons Learned from Topic Modeling Analysis of COVID-19 News to Enrich Statistics Education in Korea. Sustainability. 2022; 14(6):3240. https://doi.org/10.3390/su14063240
Chicago/Turabian StyleKang, Seokmin, and Sungyeun Kim. 2022. "Lessons Learned from Topic Modeling Analysis of COVID-19 News to Enrich Statistics Education in Korea" Sustainability 14, no. 6: 3240. https://doi.org/10.3390/su14063240
APA StyleKang, S., & Kim, S. (2022). Lessons Learned from Topic Modeling Analysis of COVID-19 News to Enrich Statistics Education in Korea. Sustainability, 14(6), 3240. https://doi.org/10.3390/su14063240