
Zero-Shot Video Grounding for Automatic Video Understanding in Sustainable Smart Cities


Abstract
:1. Introduction
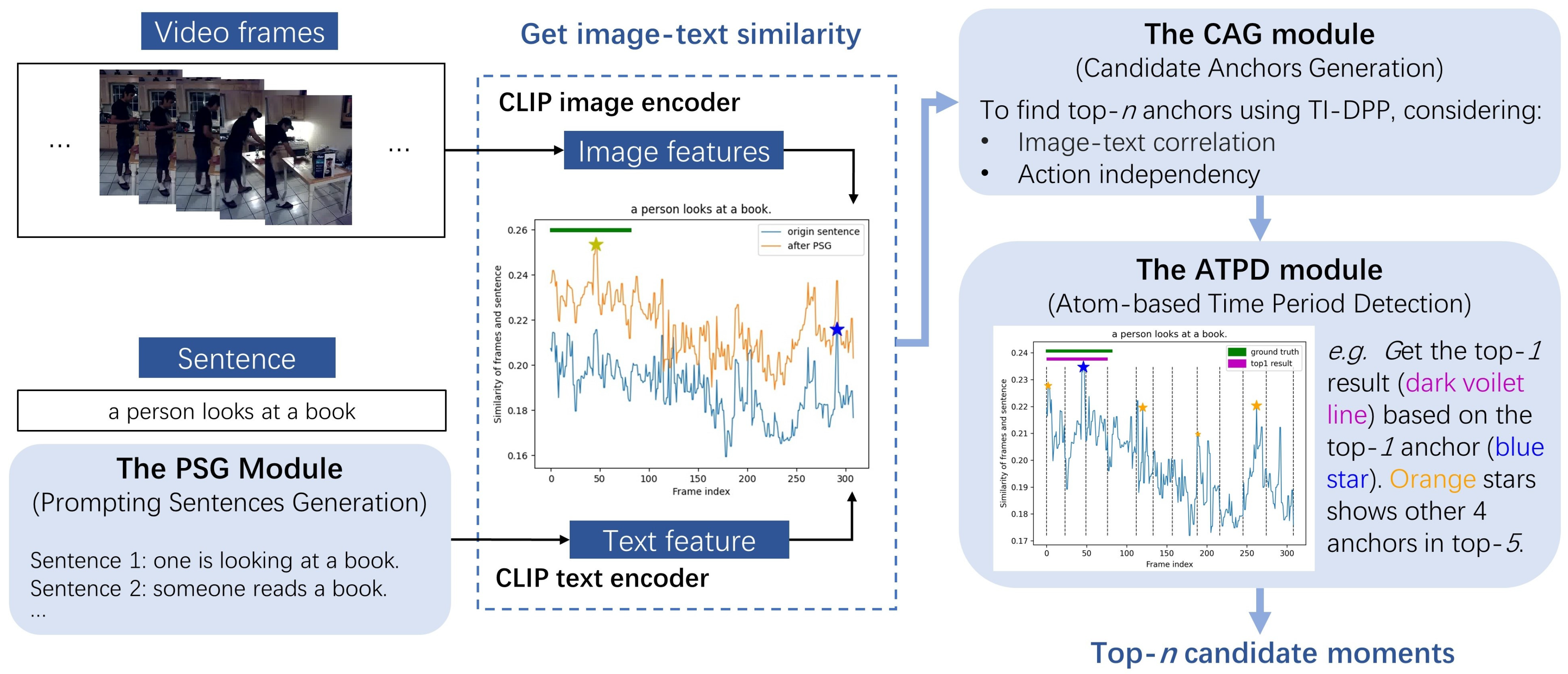
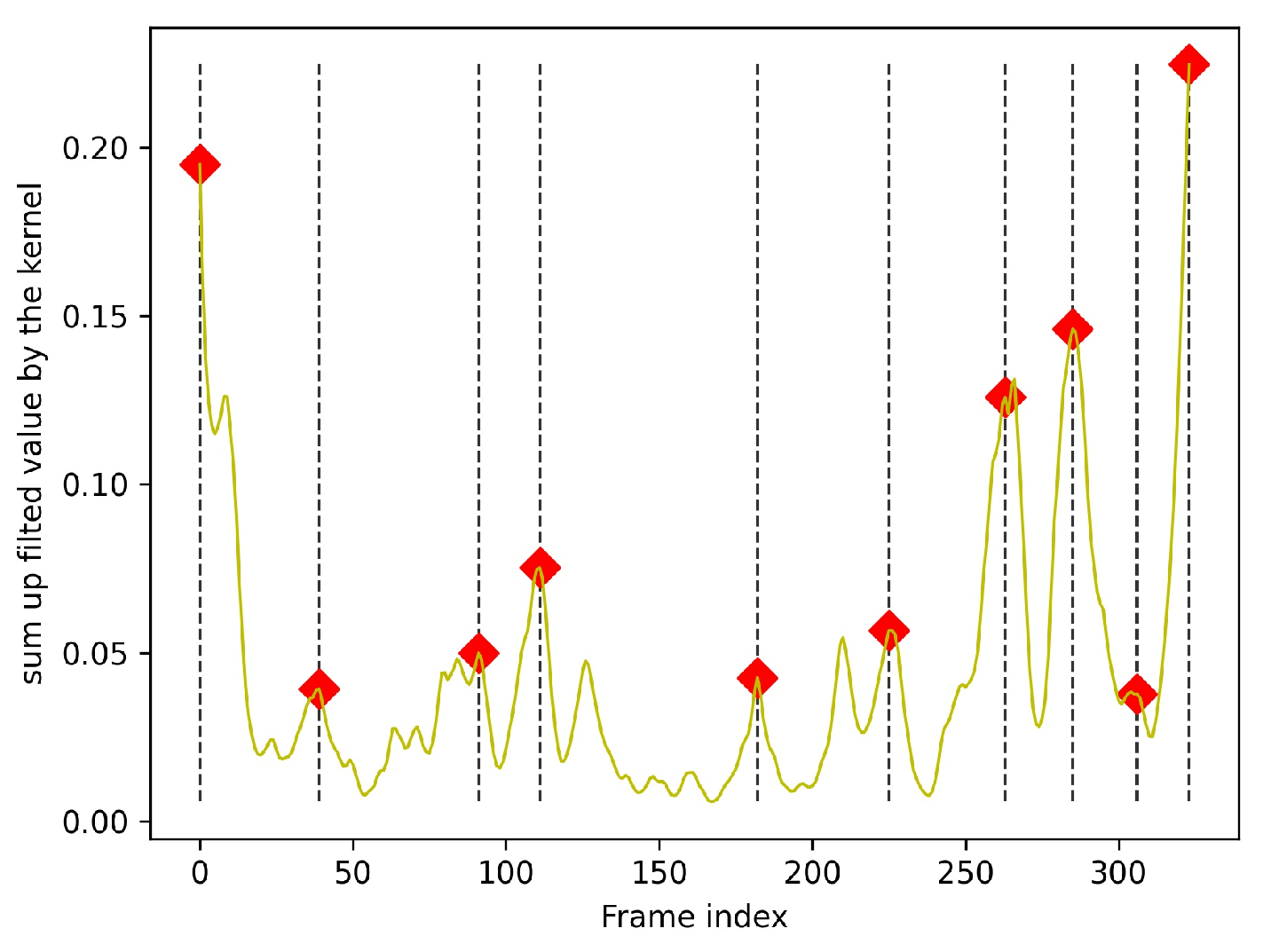
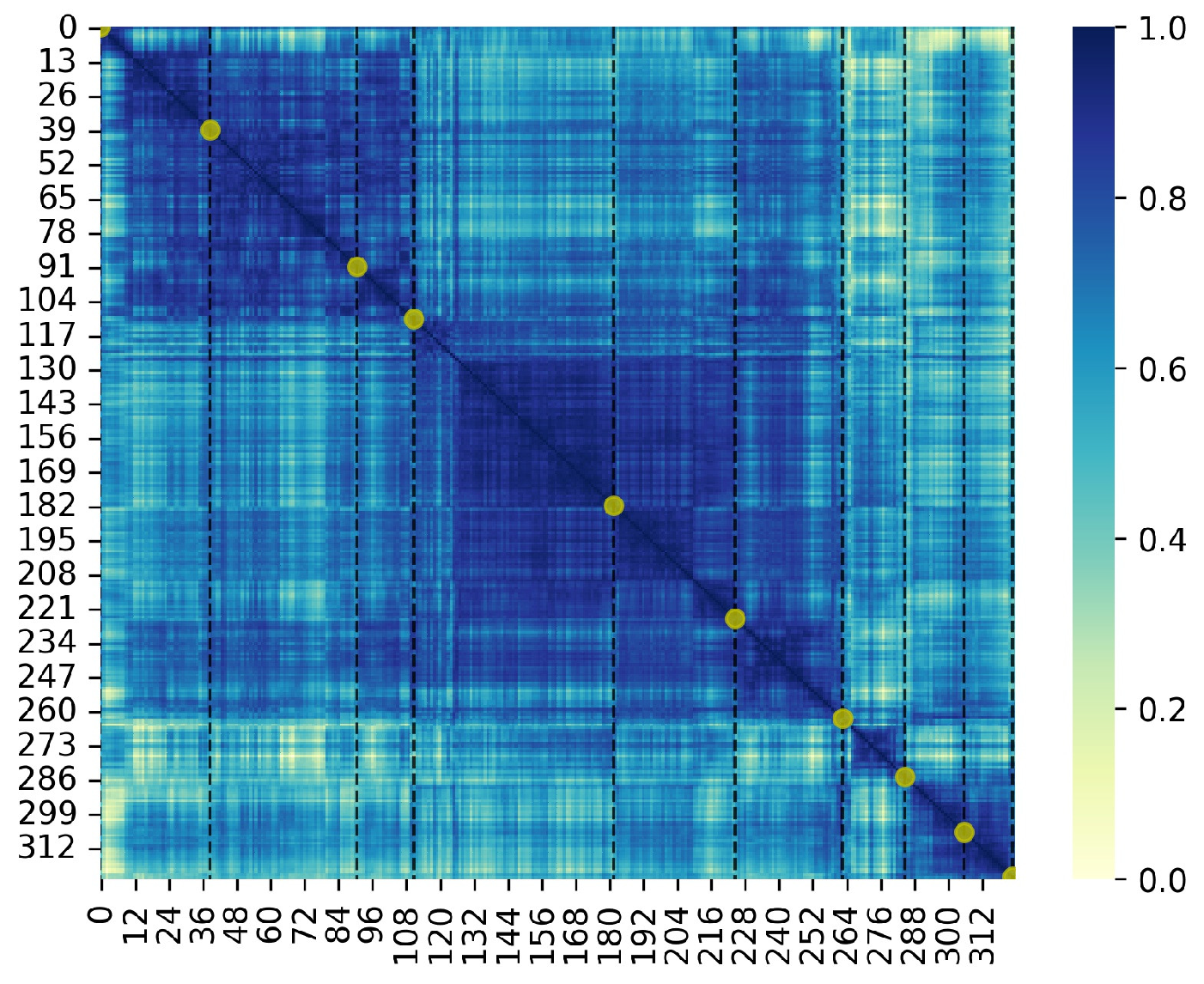
- For candidate anchor generation (CAG), we propose the time-interval determinantal point process (TI-DPP) method. The anchors for the top-n candidates should not only have high image-text similarity scores but also be mutually independent. Using TI-DPP, the top-n candidate anchors will be recommended one-by-one in a greedy manner.
- To obtain the precise moment, atom-based time period detection (ATPD) is proposed. This process includes two steps: splitting the video into atom actions and using a bi-directional search to merge the anchor atom regions with surrounding regions under various rules.
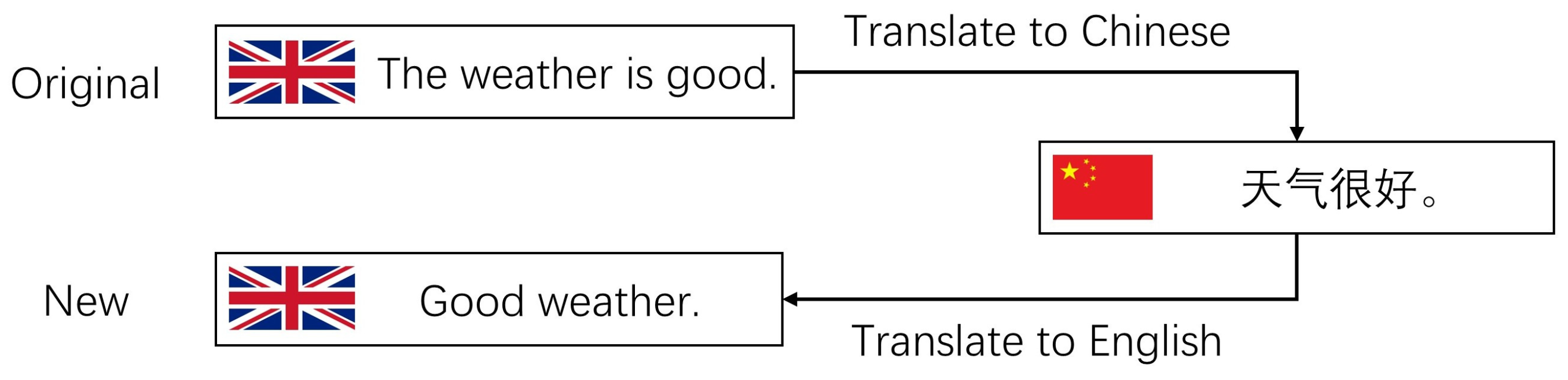
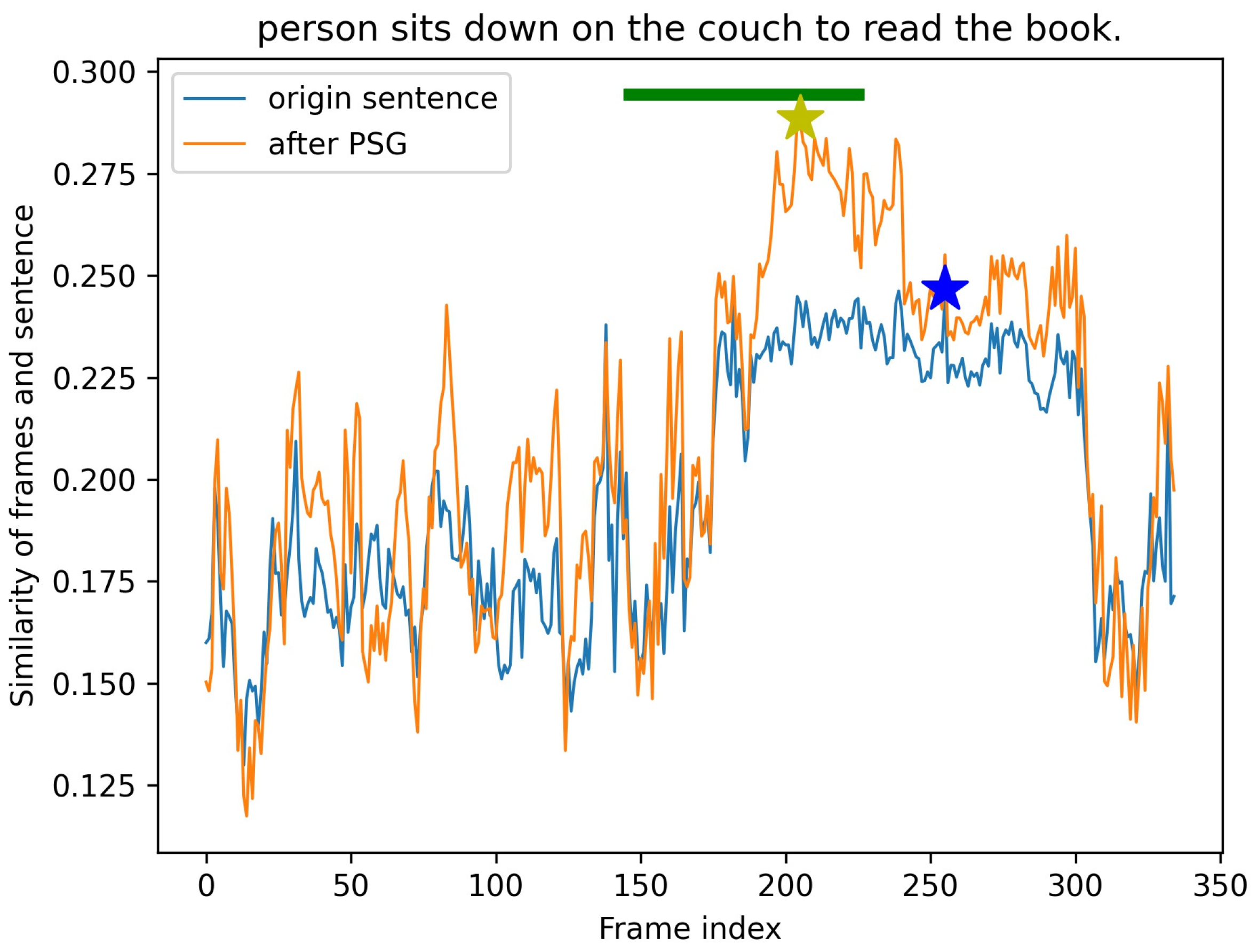
- To enhance the robustness of the expression of the input query, prompting sentences generation (PSG) is proposed to select sentences that are accurate in meaning and diverse in description.
2. Related Work
2.1. Multi-Modal Pretrained Models
2.2. Shot Boundary Detection
2.3. Text Augmentation
3. Materials and Methods
3.1. Candidate Anchors Generation
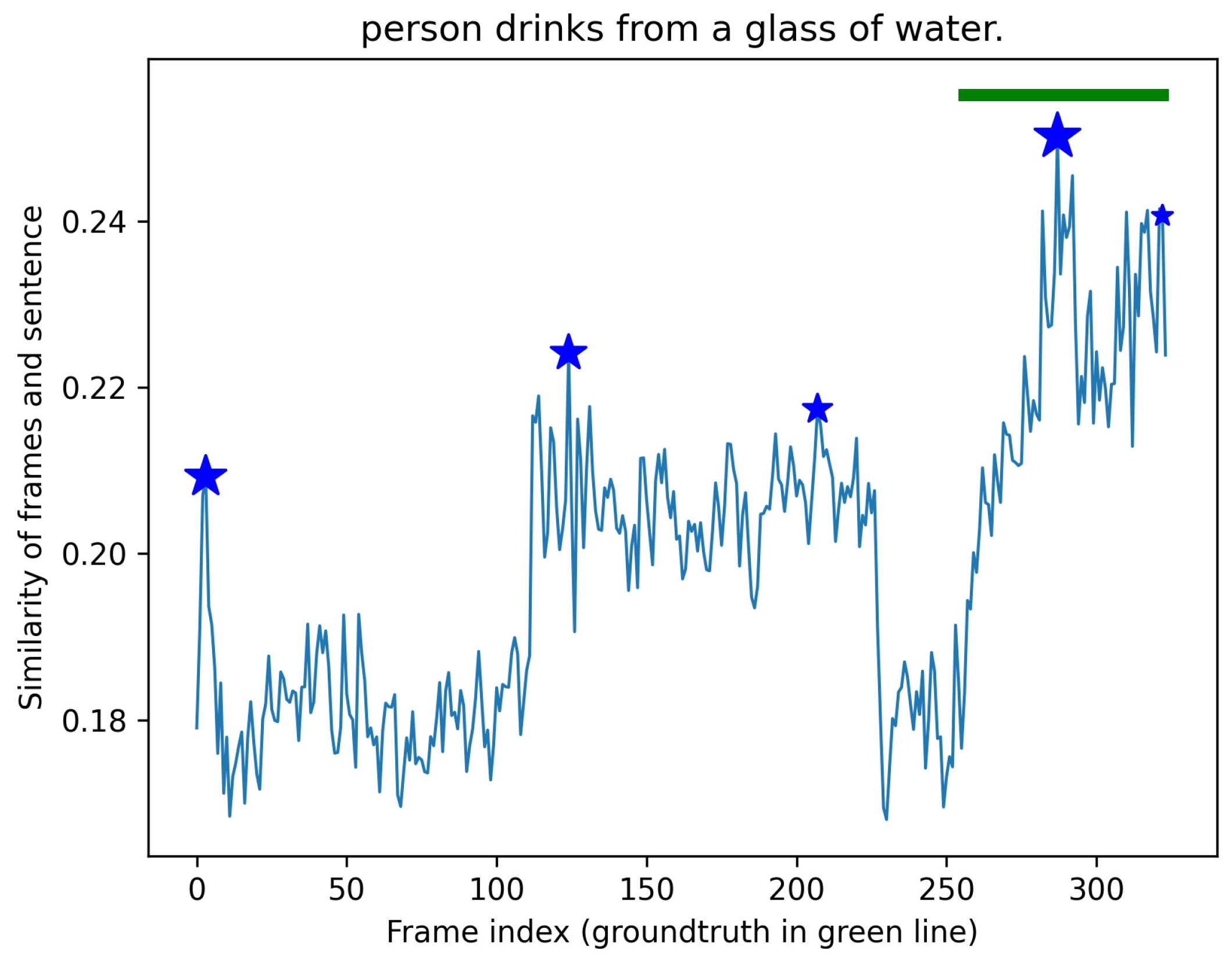
3.2. Atom-Based Time Period Detection (ATPD)
| Algorithm 1 Bi-directional search for time period |
Input:
|
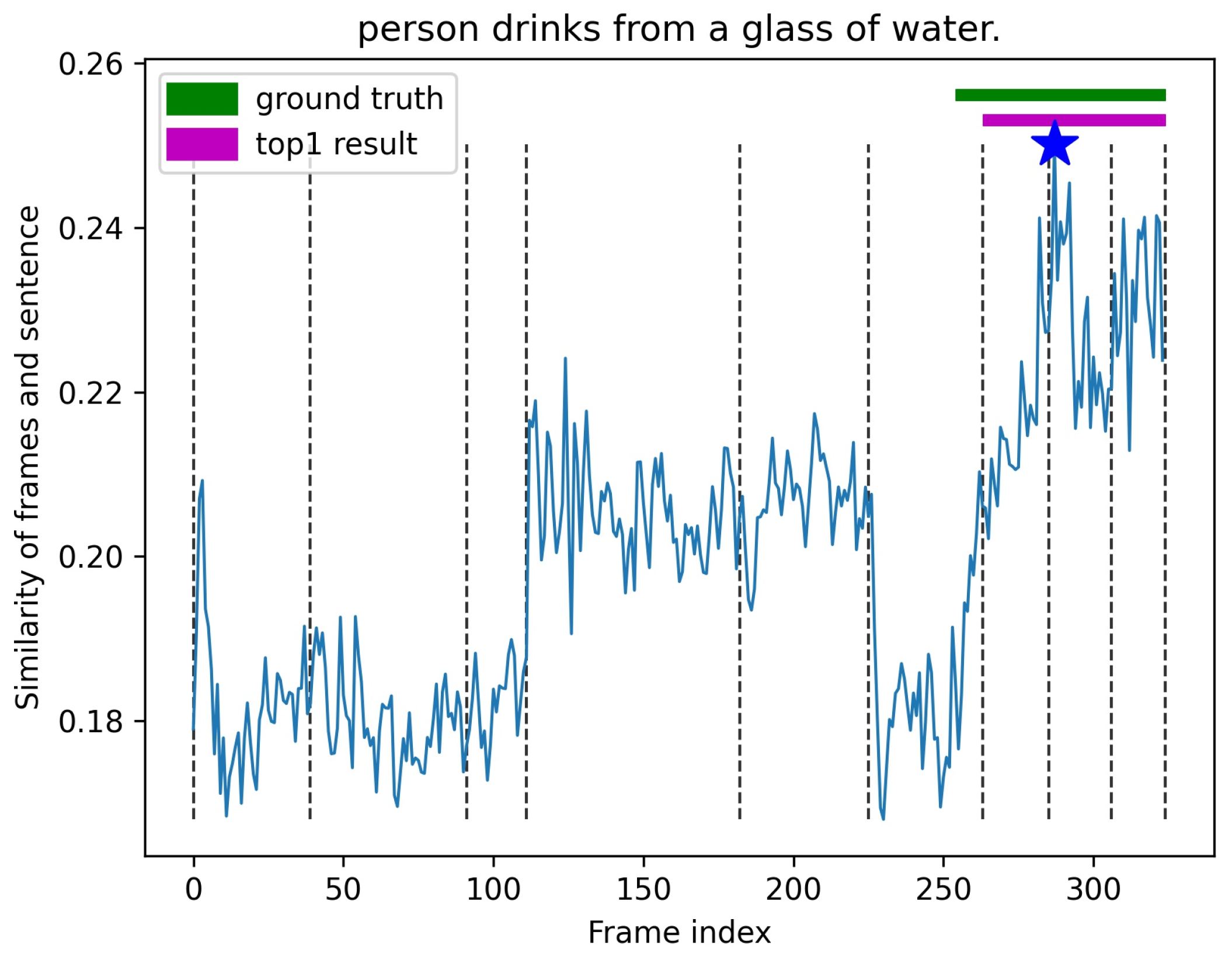
3.3. Prompting Sentences Generation (PSG)
3.3.1. Semantic Matching
3.3.2. Evaluating the Outlook Similarity of Two Sentences
- Sentence : “A man was standing in the bathroom holding glasses” can be separated into the unordered set : (a, man, was, standing, in, the, bathroom, holding, glasses).
- Sentence : “a person is standing in the bathroom holding a glass” can be separated into the unordered set : (a, person, is, standing, in, the, bathroom, holding, a, glass).
3.3.3. Language-Level PSG
| Algorithm 2 Language-level PSG |
Input:
|
3.3.4. Sentence-Level PSG
| Algorithm 3 Sentence-level PSG |
Input:
|
4. Experiments and Analysis
4.1. Dataset
4.2. Experiment Settings
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Study
4.4.1. Effectiveness of Bi-Directional Search in ATPD
4.4.2. Effectiveness of PSG
4.5. Discussion
5. Conclusions and Future work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Xiong, Y.; Wang, L.; Wu, Z.; Tang, X.; Lin, D. Temporal Action Detection with Structured Segment Networks. Int. J. Comput. Vis. 2020, 128, 74–95. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Peng, H.; Fu, J.; Luo, J. Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12870–12877. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, J.; Li, Y. ActionFormer: Localizing Moments of Actions with Transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–24 October 2022. [Google Scholar]
- Zhang, C.; Yang, T.; Weng, J.; Cao, M.; Wang, J.; Zou, Y. Unsupervised Pre-training for Temporal Action Localization Tasks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 14011–14021. [Google Scholar] [CrossRef]
- Gao, J.; Sun, C.; Yang, Z.; Nevatia, R. TALL: Temporal Activity Localization via Language Query. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 5277–5285. [Google Scholar] [CrossRef] [Green Version]
- Hendricks, L.A.; Wang, O.; Shechtman, E.; Sivic, J.; Darrell, T.; Russell, B. Localizing Moments in Video with Natural Language. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 5804–5813. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Dai, X.; Wang, X.; Wang, Y.F.; Davis, L.S. MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 17–19 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 1247–1257. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Peng, H.; Fu, J.; Lu, Y.; Luo, J. Multi-Scale 2D Temporal Adjacency Networks for Moment Localization with Natural Language. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9073–9087. [Google Scholar] [CrossRef] [PubMed]
- Zeng, R.; Xu, H.; Huang, W.; Chen, P.; Tan, M.; Gan, C. Dense Regression Network for Video Grounding. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 10284–10293. [Google Scholar] [CrossRef]
- Yuan, Y.; Mei, T.; Zhu, W. To Find Where You Talk: Temporal Sentence Localization in Video with Attention Based Location Regression. Proc. AAAI Conf. Artif. Intell. 2019, 33, 9159–9166. [Google Scholar] [CrossRef] [Green Version]
- He, D.; Zhao, X.; Huang, J.; Li, F.; Liu, X.; Wen, S. Read, Watch, and Move: Reinforcement Learning for Temporally Grounding Natural Language Descriptions in Videos. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8393–8400. [Google Scholar] [CrossRef]
- Rahman, T.; Xu, B.; Sigal, L. Watch, Listen and Tell: Multi-Modal Weakly Supervised Dense Event Captioning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; IEEE: Seoul, Republic of Korea, 2019; pp. 8907–8916. [Google Scholar] [CrossRef] [Green Version]
- Duan, X.; Huang, W.; Gan, C.; Wang, J.; Zhu, W.; Huang, J. Weakly Supervised Dense Event Captioning in Videos. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Mithun, N.C.; Paul, S.; Roy-Chowdhury, A.K. Weakly Supervised Video Moment Retrieval From Text Queries. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 11584–11593. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Zhao, Z.; Zhang, Z.; Wang, Q.; Liu, H. Weakly-Supervised Video Moment Retrieval via Semantic Completion Network. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11539–11546. [Google Scholar] [CrossRef]
- Liu, D.; Qu, X.; Wang, Y.; Di, X.; Zou, K.; Cheng, Y.; Xu, Z.; Zhou, P. Unsupervised Temporal Video Grounding with Deep Semantic Clustering. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022), Vancouver, BC, Canada, 22 February–1 March 2022. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Song, R. WenLan: Efficient Large-Scale Multi-Modal Pre-Training on Real World Data. In Proceedings of the 2021 Workshop on Multi-Modal Pre-Training for Multimedia Understanding, Taipei, Taiwan, 21 August 2021; ACM: Taipei, Taiwan, 2021; p. 3. [Google Scholar] [CrossRef]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A. Zero-Shot Learning Through Cross-Modal Transfer. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Burges, C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Li, A.; Jabri, A.; Joulin, A.; van der Maaten, L. Learning Visual N-Grams from Web Data. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Venice, Italy, 2017; pp. 4193–4202. [Google Scholar] [CrossRef] [Green Version]
- Gu, X.; Lin, T.Y.; Kuo, W.; Cui, Y. Open-vocabulary Object Detection via Vision and Language Knowledge Distillation. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Montreal, QC, Canada, 2021; pp. 2065–2074. [Google Scholar] [CrossRef]
- Kim, G.; Kwon, T.; Ye, J.C. DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 2416–2425. [Google Scholar] [CrossRef]
- Luo, H.; Ji, L.; Zhong, M.; Chen, Y.; Lei, W.; Duan, N.; Li, T. CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing 2022, 508, 293–304. [Google Scholar] [CrossRef]
- Wang, M.; Xing, J.; Liu, Y. Actionclip: A new paradigm for video action recognition. arXiv 2021, arXiv:2109.08472. [Google Scholar]
- Ni, B.; Peng, H.; Chen, M.; Zhang, S.; Meng, G.; Fu, J.; Ling, H. Expanding language-image pretrained models for general video recognition. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Volume 7, pp. 1–18. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, S.; Jian, M.; Lu, Z.; Wang, D. Two Stage Shot Boundary Detection via Feature Fusion and Spatial-Temporal Convolutional Neural Networks. IEEE Access 2019, 7, 77268–77276. [Google Scholar] [CrossRef]
- Abdulhussain, S.H.; Ramli, A.R.; Mahmmod, B.M.; Saripan, M.I.; Al-Haddad, S.A.R.; Jassim, W.A. Shot boundary detection based on orthogonal polynomial. Multimed. Tools Appl. 2019, 78, 20361–20382. [Google Scholar] [CrossRef]
- Lu, Z.M.; Shi, Y. Fast Video Shot Boundary Detection Based on SVD and Pattern Matching. IEEE Trans. Image Process. 2013, 22, 5136–5145. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Song, L.; Xie, R. Shot boundary detection using convolutional neural networks. In Proceedings of the 2016 Visual Communications and Image Processing (VCIP), Munich, Germany, 27–30 November 2016; IEEE: Chengdu, China, 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, P.; Wang, X.; Xiang, C.; Meng, W. A Survey of Text Data Augmentation. In Proceedings of the 2020 International Conference on Computer Communication and Network Security (CCNS), Guilin, China, 21–23 August 2020; IEEE: Xi’an, China, 2020; pp. 191–195. [Google Scholar] [CrossRef]
- Şahin, G.G.; Steedman, M. Data Augmentation via Dependency Tree Morphing for Low-Resource Languages. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 5004–5009. [Google Scholar] [CrossRef]
- Shi, H.; Livescu, K.; Gimpel, K. Substructure Substitution: Structured Data Augmentation for NLP. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; Association for Computational Linguistics: Online, 2021; pp. 3494–3508. [Google Scholar] [CrossRef]
- Marivate, V.; Sefara, T. Improving Short Text Classification Through Global Augmentation Methods. In Machine Learning and Knowledge Extraction; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12279, pp. 385–399. [Google Scholar] [CrossRef]
- Qiu, S.; Xu, B.; Zhang, J.; Wang, Y.; Shen, X.; de Melo, G.; Long, C.; Li, X. EasyAug: An Automatic Textual Data Augmentation Platform for Classification Tasks. In Proceedings of the Companion Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; ACM: Taipei, Taiwan, 2020; pp. 249–252. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan IV, R.L.; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–18 November 2020; Association for Computational Linguistics: Online, 2020; pp. 4222–4235. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional Prompt Learning for Vision-Language Models. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 16795–16804. [Google Scholar] [CrossRef]
- Kulesza, A. Determinantal Point Processes for Machine Learning. Found. Trends® Mach. Learn. 2012, 5, 123–286. [Google Scholar] [CrossRef] [Green Version]
- Macchi, O. The coincidence approach to stochastic point processes. Adv. Appl. Probab. 1975, 7, 83–122. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, G.; Zhou, E. Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Montréal, QC, Canada, 2018; Volume 31. [Google Scholar]
- Foote, J. Automatic audio segmentation using a measure of audio novelty. In Proceedings of the 2000 IEEE International Conference on Multimedia and Expo. ICME2000. Proceedings. Latest Advances in the Fast Changing World of Multimedia (Cat. No.00TH8532), New York, NY, USA, 30 July–2 August 2000; Volume 1, pp. 452–455. [Google Scholar] [CrossRef]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. MPNet: Masked and Permuted Pre-training for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2020; Volume 33, pp. 16857–16867. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 510–526. [Google Scholar] [CrossRef] [Green Version]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Santiago, Chile, 2015; pp. 4489–4497. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? In A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017; pp. 4724–4733. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zha, Z.J.; Chen, X.; Xiong, Z.; Luo, J. Dual Path Interaction Network for Video Moment Localization. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; ACM: Seattle WA USA, 2020; pp. 4116–4124. [Google Scholar] [CrossRef]
- Zhang, S.; Su, J.; Luo, J. Exploiting Temporal Relationships in Video Moment Localization with Natural Language. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; ACM: Nice France, 2019; pp. 1230–1238. [Google Scholar] [CrossRef] [Green Version]
- Moshkov, N.; Mathe, B.; Kertesz-Farkas, A.; Hollandi, R.; Horvath, P. Test-time augmentation for deep learning-based cell segmentation on microscopy images. Sci. Rep. 2020, 10, 1–7. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Sentence |
|---|---|
| Original sentence | a man stands in the bathroom holding a glass. |
| Generated sentence 1 | A man is holding a glass in the bathroom. |
| Generated sentence 2 | a man was standing in the bathroom holding glass. |
| Generated sentence 3 | A person is standing in the bathroom holding a glass |
| Generated sentence 4 | a man is standing in the bathroom holding a glass. |
| Generated sentence 5 | someone is standing in the bathroom holding a glass. |
| Generated sentence 6 | a man is standing in the bathroom with a glass. |
| Generated sentence 7 | Someone standing in the bathroom holding a glass. |
| Generated sentence 8 | the man is standing in the bathroom with a bottle. |
| Generated sentence 9 | Someone stands in the bathroom holding a glass. |
| Generated sentence 10 | someone standing in the bathroom holding a glass. |
| Type | Sentence |
|---|---|
| Original sentence | a man stands in the bathroom holding a glass. |
| Generated sentence 1 | a person stands in the bathroom holding a glass. |
| Generated sentence 2 | the man is standing in the bathroom with a bottle. |
| Generated sentence 3 | The man is holding a glass in the bathroom. |
| Generated sentence 4 | a person standing in the bathroom with a glass in his hand. |
| Generated sentence 5 | a man was standing in the bathroom holding a glass. |
| Generated sentence 6 | A person stands holding a mirror in the bathroom. |
| Generated sentence 7 | someone is standing in the bathroom holding a glass. |
| Generated sentence 8 | man stands in the bathroom with a glass. |
| Generated sentence 9 | a person is in the bathroom with a glass. |
| Generated sentence 10 | man standing in the bathroom and holding a glass. |
| Description | Method | R@1 IoU = 0.5 | R@1 IoU = 0.7 | R@5 IoU = 0.5 | R@5 IoU = 0.7 |
|---|---|---|---|---|---|
| Supervised | CTRL [5] | 23.63 | 8.89 | 58.92 | 29.52 |
| MAN [7] | 41.24 | 20.54 | 83.21 | 51.85 | |
| 2D-TAN [2] | 39.81 | 23.25 | 79.33 | 52.15 | |
| MS-2D-TAN [8] | 60.08 | 37.39 | 89.06 | 59.17 | |
| Weakly Supervised | TGA [14] | 19.94 | 8.84 | 65.52 | 33.51 |
| SCN [15] | 23.58 | 9.97 | 71.80 | 38.87 | |
| Unsupervised | DSCNet [16] | 28.73 | 14.67 | 70.68 | 35.19 |
| Zero-shot | Ours | 39.01 | 17.55 | 73.04 | 36.99 |
| Description | Method | R@1 IoU = 0.3 | R@1 IoU = 0.5 | R@5 IoU = 0.3 | R@5 IoU = 0.5 |
|---|---|---|---|---|---|
| Supervised | CTRL [5] | 47.43 | 29.01 | 75.32 | 59.17 |
| CMIN [48] | 63.61 | 43.40 | 80.54 | 67.95 | |
| 2D-TAN [2] | 59.45 | 44.51 | 85.53 | 77.13 | |
| MS-2D-TAN [8] | 61.16 | 46.56 | 86.91 | 78.02 | |
| Weakly Supervised | SCN [15] | 47.23 | 29.22 | 71.45 | 55.69 |
| Unsupervised | DSCNet [16] | 47.29 | 28.16 | 72.51 | 57.24 |
| Zero-shot | ours | 47.37 | 25.25 | 73.78 | 51.45 |
| Bi-Directional Search | R@1 IoU = 0.5 | R@1 IoU = 0.7 | R@5 IoU = 0.5 | R@5 IoU = 0.7 |
|---|---|---|---|---|
| 13.39 | 4.70 | 8.76 | 29.81 | |
| ✓ | 37.01 | 16.85 | 72.72 | 36.85 |
| Bi-Directional Search | R@1 IoU = 0.3 | R@1 IoU = 0.5 | R@5 IoU = 0.3 | R@5 IoU = 0.5 |
|---|---|---|---|---|
| 14.44 | 7.33 | 30.29 | 15.40 | |
| ✓ | 46.88 | 25.07 | 70.89 | 46.99 |
| PSG Type | Diversity | Exactness | R@1 IoU = 0.5 | R@1 IoU = 0.7 | R@5 IoU = 0.5 | R@5 IoU = 0.7 |
|---|---|---|---|---|---|---|
| Language-level | ✓ | ✓ | 39.01 | 17.55 | 73.04 | 36.99 |
| ✓ | 38.16 | 17.32 | 72.49 | 37.19 | ||
| ✓ | 37.42 | 16.94 | 72.74 | 36.85 | ||
| Sentence-level | ✓ | ✓ | 38.68 | 17.58 | 72.63 | 36.88 |
| ✓ | 38.44 | 17.23 | 72.34 | 37.04 | ||
| ✓ | 37.47 | 16.94 | 72.77 | 36.91 | ||
| Random selection | 37.98 | 17.45 | 72.66 | 36.99 | ||
| Without PSG | 37.01 | 16.85 | 72.72 | 36.85 |
| PSG Type | Diversity | Exactness | R@1 IoU = 0.3 | R@1 IoU = 0.5 | R@5 IoU = 0.3 | R@5 IoU = 0.5 |
|---|---|---|---|---|---|---|
| Language-level | ✓ | ✓ | 47.37 | 25.25 | 73.78 | 51.45 |
| ✓ | 47.18 | 25.25 | 73.04 | 50.98 | ||
| ✓ | 46.92 | 25.11 | 71.67 | 47.91 | ||
| Sentence-level | ✓ | ✓ | 47.21 | 25.43 | 73.69 | 51.58 |
| ✓ | 47.08 | 25.31 | 70.49 | 46.94 | ||
| ✓ | 47.11 | 25.18 | 70.33 | 46.57 | ||
| Random selection | 47.03 | 25.13 | 71.53 | 47.89 | ||
| Without PSG | 46.88 | 25.07 | 70.89 | 46.99 |
| PSG Type | Fusion | R@1 IoU = 0.5 | R@1 IoU = 0.7 | R@5 IoU = 0.5 | R@5 IoU = 0.7 |
|---|---|---|---|---|---|
| Language-level | Middling | 39.01 | 17.55 | 73.04 | 36.99 |
| Averaging | 38.31 | 17.12 | 72.47 | 36.29 | |
| Sentence-level | Middling | 38.68 | 17.58 | 72.63 | 36.88 |
| Averaging | 38.04 | 17.58 | 72.20 | 36.80 | |
| Random selection | Middling | 37.98 | 17.45 | 72.66 | 36.99 |
| Averaging | 37.80 | 17.39 | 72.71 | 36.64 | |
| Without PSG | 37.01 | 16.85 | 72.72 | 36.85 |
| PSG Type | Fusion | R@1 IoU = 0.3 | R@1 IoU = 0.5 | R@5 IoU = 0.3 | R@5 IoU = 0.5 |
|---|---|---|---|---|---|
| Language-level | Middling | 47.37 | 25.25 | 73.78 | 51.45 |
| Averaging | 46.82 | 25.31 | 70.61 | 47.00 | |
| Sentence-level | Middling | 47.21 | 25.43 | 73.69 | 51.58 |
| Averaging | 47.10 | 25.32 | 71.03 | 47.31 | |
| Random selection | Middling | 47.03 | 25.13 | 71.53 | 47.89 |
| Averaging | 46.96 | 25.14 | 71.33 | 47.32 | |
| Without PSG | 46.88 | 25.07 | 70.89 | 46.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang , P.; Sun, L.; Wang, L.; Sun, J. Zero-Shot Video Grounding for Automatic Video Understanding in Sustainable Smart Cities. Sustainability 2023, 15, 153. https://doi.org/10.3390/su15010153
Wang P, Sun L, Wang L, Sun J. Zero-Shot Video Grounding for Automatic Video Understanding in Sustainable Smart Cities. Sustainability. 2023; 15(1):153. https://doi.org/10.3390/su15010153
Chicago/Turabian StyleWang , Ping, Li Sun, Liuan Wang, and Jun Sun. 2023. "Zero-Shot Video Grounding for Automatic Video Understanding in Sustainable Smart Cities" Sustainability 15, no. 1: 153. https://doi.org/10.3390/su15010153
APA StyleWang , P., Sun, L., Wang, L., & Sun, J. (2023). Zero-Shot Video Grounding for Automatic Video Understanding in Sustainable Smart Cities. Sustainability, 15(1), 153. https://doi.org/10.3390/su15010153