
Bearing Fault Diagnosis Using ACWGAN-GP Enhanced by Principal Component Analysis
Abstract
:1. Introduction
2. Related Theories
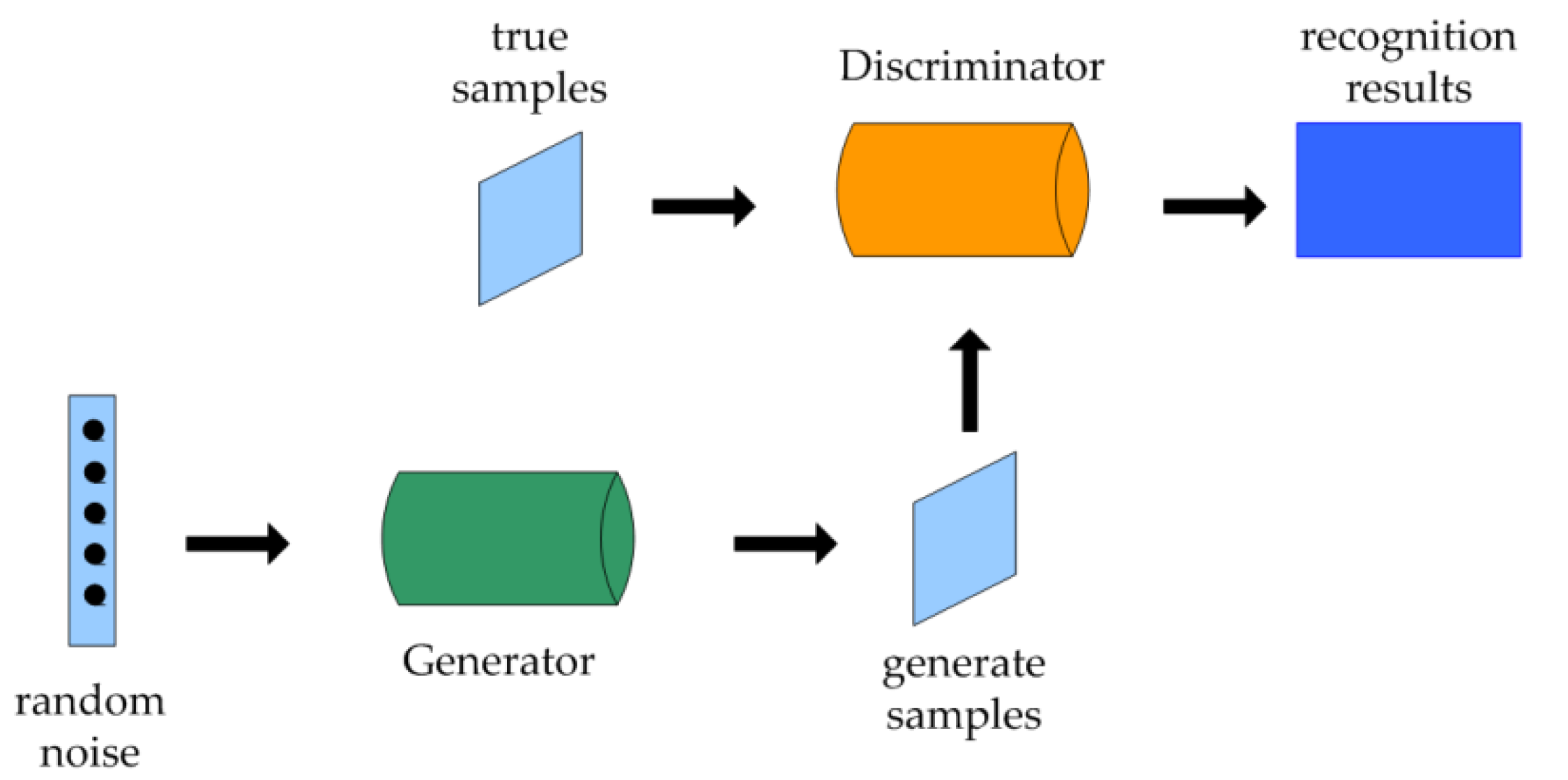
2.1. Generative Adversarial Network Model (GAN)
2.2. Auxiliary Classification Generative Adversarial Network Model (ACGAN)
2.3. WGAN-GP Model
| Algorithm 1: WGAN-GP algorithm flow |
| Parameters: gradient penalty coefficient , the number of iterations batch size m, Adam hyper-parameter , initial discriminator parameter , initial generator parameter . |
| 1: while not convergent do 2: for t = 1, …, T 3: for i = 1, …, m 4: Sample x from real sample distribution , random noise z from generator pre-random distribution , random number from uniform distribution [0, 1] |
| 5: 6: 7: 8: end for |
| 9: |
| 10: end for |
| 11: Retrieve from the generator pre-randomly distributed |
| 12: |
| 13: end while |
3. Fault Diagnosis Framework of Rolling Bearing Using Improved ACGAN
3.1. PCA-ACWGAN-GP Model
3.2. PCA-ACWGAN-GP Framework
3.3. Model Training Process
4. Experimental Setup and Results Analysis
4.1. Data Set Partition and Data Preprocessing
4.2. Parameter Settings
4.3. Similarity Effect Analysis
4.4. Data Enhancement Effect Analysis
4.5. Data Enhancement in Different Sample Scenarios
5. Conclusions and Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Wang, R.; Pan, R.; Pan, H. Imbalanced Fault Diagnosis of Rolling Bearing Using Enhanced Generative Adversarial Networks. IEEE Access 2020, 8, 185950–185963. [Google Scholar] [CrossRef]
- Mao, W.; Liu, Y.; Ding, L.; Li, Y. Imbalanced Fault Diagnosis of Rolling Bearing Based on Generative Adversarial Network: A Comparative Study. IEEE Access 2019, 7, 9515–9530. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Pract. 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Levent, E.; Turker, I.; Serkan, K. A Generic Intelligent Bearing Fault Diagnosis System Using Compact Adaptive 1D CNN Classifier. J. Signal Process Sys. 2019, 91, 179–189. [Google Scholar]
- Wang, L.; Wan, H.; Huang, D.; Liu, J.; Tang, X.; Gan, L. Sustainable Analysis of Insulator Fault Detection Based on Fine-Grained Visual Optimization. Sustainability 2023, 15, 3456. [Google Scholar] [CrossRef]
- Attouri, K.; Mansouri, M.; Hajji, M.; Kouadri, A.; Bouzrara, K.; Nounou, H. Wind Power Converter Fault Diagnosis Using Reduced Kernel PCA-Based BiLSTM. Sustainability 2023, 15, 3191. [Google Scholar] [CrossRef]
- Zeng, D.; Jiang, Y.; Zou, Y. Construction and verification of a new evaluation index for bearing life prediction characteristics. Shock Vib. 2018, 54, 94–104. [Google Scholar]
- Lei, Y.; Jia, F.; Kong, D. Opportunities and challenges of mechanical intelligent fault diagnosis in big data era. J. Mech. Eng. 2018, 54, 94–104. [Google Scholar] [CrossRef]
- Hu, T.; Tang, T.; Lin, R.; Chen, M.; Han, S.; Wu, J. A simple data augmentation algorithm and a self-adaptive convolutional architecture for few-shot fault diagnosis under different working conditions—ScienceDirect. Measurement 2020, 156, 107539. [Google Scholar] [CrossRef]
- Zhou, F.; Yang, S.; Fujita, H.; Chen, D.; Wen, C. Deep learning fault diagnosis method based on global optimization GAN for unbalanced data. Knowl. Based Syst. 2020, 187, 104837.1–104837.19. [Google Scholar] [CrossRef]
- Cheng, F.; Zhang, J.; Wen, C.; Liu, Z.; Li, Z. Large Cost-Sensitive Margin Distribution Machine for Imbalanced Data Classification. Neurocomputing 2017, 224, 45–57. [Google Scholar] [CrossRef]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]
- Yu, Z.Y.; Luo, T.J. Research on clothing patterns generation based on multi-scales self-attention improved generative adversarial network. Int. J. Innov. Creat. Change 2021, 14, 647–663. [Google Scholar] [CrossRef]
- Zhang, X.; He, C.; Lu, Y.; Chen, B.; Zhu, L.; Zhang, L. Fault diagnosis for small samples based on attention mechanism. Measurement 2022, 187, 110242. [Google Scholar] [CrossRef]
- Xu, Z.; Jin, J.; Li, C. New method for the fault diagnosis of rolling bearings based on a multiscale convolutional neural network. Shock Vib. 2021, 40, 212–220. [Google Scholar]
- Gong, W.; Chen, H.; Zhang, Z. Intelligent fault diagnosis for rolling bearing based on improved convolutional neural network. J. Vib. Eng. Technol. 2020, 33, 400–413. [Google Scholar]
- Shao, S.; Wang, P.; Yan, R. Generative adversarial networks for data augmentation in machine fault diagnosis. Computing 2019, 106, 85–93. [Google Scholar] [CrossRef]
- Gao, X.; Deng, F.; Yue, X. Data augmentation in fault diagnosis based on the Wasserstein generative adversarial network with gradient penalty. Neurocomputing 2020, 396, 487–494. [Google Scholar] [CrossRef]
- Ding, Y.; Ma, L.; Ma, J.; Wang, C.; Lu, C. A Generative Adversarial Network-Based Intelligent Fault Diagnosis Method for Rotating Machinery Under Small Sample Size Conditions. IEEE Access 2019, 7, 149736–149749. [Google Scholar] [CrossRef]
- Deng, M.; Deng, A.; Shi, Y.; Liu, Y.; Xu, M. Intelligent fault diagnosis based on sample weighted joint adversarial network. Neurocomputing 2022, 488, 168–182. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, T.; Yang, W.; Fu, H.; Wu, W. A Robust Fault Diagnosis Method for Rolling Bearings Based on Deep Convolutional Neural Network. In Proceedings of the 2019 Prognostics and System Health Management Conference (PHM-Qingdao), Qingdao, China, 25–27 October 2019; pp. 1–7. [Google Scholar]
- Tang, W.; Tan, S.; Li, B.; Huang, J. Automatic Steganographic Distortion Learning Using a Generative Adversarial Network. IEEE Signal. Proc. Let. 2017, 24, 1547–1551. [Google Scholar] [CrossRef]
- Su, X.; Liu, H.; Tao, L.; Lu, C.; Suo, M. An end-to-end framework for remaining useful life prediction of rolling bearing based on feature pre-extraction mechanism and deep adaptive transformer model. Comput. Ing. Eng. 2021, 161, 107531. [Google Scholar] [CrossRef]
- Mi, Z.; Jiang, X.; Sun, T.; Xu, K. GAN-Generated Image Detection with Self-Attention Mechanism against GAN Generator Defect. IEEE J. Sel. Top. Signal Process. 2020, 14, 969–981. [Google Scholar] [CrossRef]
- Ouchi, T.; Tabuse, M. Effectiveness of Data Augmentation in Pointer-Generator Model. ICAROB 2020, 25, 390–393. [Google Scholar] [CrossRef]
- Cheng, P.; Chen, D.; Wang, J. Research on prediction model of thermal and moisture comfort of underwear based on principal component analysis and Genetic Algorithm–Back Propagation neural network. Int. J. Nonlin. Sci. Num. 2021, 22, 607–619. [Google Scholar] [CrossRef]
- Shakya, A.; Biswas, M.; Pal, M. Classification of Radar data using Bayesian optimized two-dimensional Convolutional Neural Network. In Radar Remote Sensing; Elsevier: Amsterdam, The Netherlands, 2022; pp. 175–186. [Google Scholar]
- Gao, S.; Wang, Q.; Zhang, Y. Rolling Bearing Fault Diagnosis Based on CEEMDAN and Refined Composite Multi-Scale Fuzzy Entropy. IEEE T. Instrum. Meas. 2021, 70, 3514908. [Google Scholar] [CrossRef]
- Zhang, W. Research on Bearing Fault Diagnosis Algorithm Based on Convolutional Neural Network; Harbin Institute of Technology: Harbin, China, 2017. [Google Scholar]
- Baranilingesan, I. Optimization algorithm-based Elman neural network controller for continuous stirred tank reactor process model. Curr. Sci. 2021, 120, 1324–1333. [Google Scholar] [CrossRef]
- Cao, H.; Sun, P.; Zhao, L. PCA-SVM method with sliding window for online fault diagnosis of a small pressurized water reactor. Ann. Nucl. Energy 2022, 171, 109036. [Google Scholar] [CrossRef]
- Mao, Y.; Qin, G.; Ni, P.; Liu, Q. Analysis of road traffic speed in Kunming plateau mountains: A fusion PSO-LSTM algorithm. Int. J. Urban Sci. 2021, 7, 87–107. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Label | Fault Mode | Fault Size/Inch | Load/hp | Sample Size |
|---|---|---|---|---|
| 0 | Normal | - | 0/1/2/3 | 400 |
| 1 | Slight wear of inner ring | 0.007 | 400 | |
| 2 | Moderate wear of inner ring | 0.014 | 400 | |
| 3 | Severe wear of inner ring | 0.021 | 400 | |
| 4 | Slight wear of rolling element | 0.007 | 400 | |
| 5 | Moderate wear of rolling element | 0.014 | 400 | |
| 6 | Severe wear of rolling element | 0.021 | 400 | |
| 7 | Slight wear of outer ring | 0.007 | 400 | |
| 8 | Moderate wear of outer ring | 0.014 | 400 | |
| 9 | Severe wear of outer ring | 0.021 | 400 |
| Fault Label | Sample Set A (Training Set) | Sample Set B (Test Set) |
|---|---|---|
| 0 | 150 | 100 |
| 1~9 | 1350 | 900 |
| Fault Label | ACGAN | ACWGAN-GP | PCA-ACWGAN-GP | |||
|---|---|---|---|---|---|---|
| ED | CD | ED | CD | ED | CD | |
| 0 | 0.55195 | 0.96437 | 0.53709 | 0.97003 | 0.45187 | 0.97517 |
| 2 | 0.56080 | 0.96095 | 0.53887 | 0.96250 | 0.46480 | 0.96491 |
| 4 | 0.60844 | 0.95151 | 0.52806 | 0.96346 | 0.50844 | 0.97150 |
| 6 | 0.76558 | 0.92160 | 0.86297 | 0.89894 | 0.76508 | 0.91161 |
| 8 | 0.59120 | 0.95339 | 0.56240 | 0.95920 | 0.51920 | 0.96339 |
| Fault Label | Generate Sample Set 1 | Generate Sample Set 2 | Generate Sample Set 3 | Expanded Sample Set 4 | Expanded Sample Set 5 | Expanded Sample Set 6 |
|---|---|---|---|---|---|---|
| 0 | 1350 | 1350 | 1350 | 1500 | 1500 | 1500 |
| 1~9 | 12,150 | 12,150 | 12,150 | 13,500 | 13,500 | 13,500 |
| Number of Layers | Layer | Convolution Kernel/Filter/Step Size |
|---|---|---|
| 1 | 2D convolution layer | 5/32/5 |
| 2 | Maximum pooling layer | 2/-/2 |
| 3 | 2D convolution layer | 3/64/3 |
| 4 | Maximum pooling layer | 2/-/2 |
| 5 | 2D convolution layer | 3/128/3 |
| 6 | Maximum pooling layer | 2/-/2 |
| 7 | 2D convolution layer | 3/256/3 |
| 8 | Maximum pooling layer | 2/-/2 |
| 9 | Full connection layer | 256-128 |
| 10 | Full connection layer | 128-1 |
| 11 | SoftMax layer | - |
| ACGAN Expanded Sample Set 4 | ACWGAN-GP Expanded Sample Set 5 | PCA-ACWGAN-GP Expanded Sample Set 6 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Fault Label | Precision Rate | Recall Rate | F1 Score | Precision Rate | Recall Rate | F1 Score | Precision Rate | Recall Rate | F1 Score |
| 0 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 1.000 |
| 1 | 0.901 | 1.000 | 0.948 | 0.985 | 1.000 | 1.000 | 0.999 | 1.000 | 0.998 |
| 2 | 0.786 | 0.983 | 0.889 | 0.970 | 1.000 | 0.991 | 1.000 | 0.997 | 0.999 |
| 3 | 1.000 | 0.989 | 0.995 | 0.991 | 0.980 | 0.989 | 0.998 | 1.000 | 1.000 |
| 4 | 0.972 | 0.979 | 0.915 | 0.973 | 0.970 | 0.972 | 0.996 | 0.997 | 1.000 |
| 5 | 0.895 | 0.669 | 0.759 | 0.956 | 0.922 | 0.956 | 0.992 | 0.959 | 0.981 |
| 6 | 0.992 | 1.000 | 0.996 | 0.948 | 0.899 | 0.923 | 0.991 | 1.000 | 0.987 |
| 7 | 0.952 | 1.000 | 0.974 | 0.966 | 0.973 | 0.968 | 0.983 | 1.000 | 0.974 |
| 8 | 0.986 | 0.981 | 0.983 | 0.989 | 1.000 | 0.994 | 1.000 | 0.980 | 0.982 |
| 9 | 0.884 | 0.912 | 0.893 | 0.919 | 0.876 | 0.923 | 0.982 | 1.000 | 0.999 |
| Accuracy | 94.6% | 97.8% | 99.2% | ||||||
| Proportion of Sample | 100% | 90% | 80% | 70% | 60% | 50% | 40% |
|---|---|---|---|---|---|---|---|
| Total number of training samples | 1500 | 1350 | 1200 | 1050 | 900 | 750 | 600 |
| Number of samples per category | 150 | 135 | 120 | 105 | 90 | 75 | 60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, B.; Tao, C.; Tao, J.; Jiang, Y.; Li, P. Bearing Fault Diagnosis Using ACWGAN-GP Enhanced by Principal Component Analysis. Sustainability 2023, 15, 7836. https://doi.org/10.3390/su15107836
Chen B, Tao C, Tao J, Jiang Y, Li P. Bearing Fault Diagnosis Using ACWGAN-GP Enhanced by Principal Component Analysis. Sustainability. 2023; 15(10):7836. https://doi.org/10.3390/su15107836
Chicago/Turabian StyleChen, Bin, Chengfeng Tao, Jie Tao, Yuyan Jiang, and Ping Li. 2023. "Bearing Fault Diagnosis Using ACWGAN-GP Enhanced by Principal Component Analysis" Sustainability 15, no. 10: 7836. https://doi.org/10.3390/su15107836