1. Introduction
As the world is moving towards sustainability, there is an increasing need for renewable and green energy resources. Non-renewable resources such as fossil fuels are rapidly disappearing, and their consumption is causing severe environmental hazards. Therefore, renewable energy resources such as solar energy, wind energy, and hydroelectric power are becoming more and more popular [
1]. However, the integration of these resources into the smart grid is a challenge that needs to be addressed. Almost all researchers focus on enhancing stability and control in power grid systems through the proposal of hybrid solutions, emphasizing the importance of addressing challenges associated with grid faults, and utilizing specific control strategies to improve fault ride-through capabilities, voltage regulation, and reactive power injection, supported by simulation results and comparisons, while also suggesting future directions for further research [
2,
3,
4,
5]. In the near future, smart grids such as wind, solar, biogas, and so on will need to be controlled through artificial intelligence techniques to enhance their efficiency [
6,
7]. The authors of [
8] present a novel approach using the YOLOv5 algorithm and image processing techniques to monitor photovoltaic modules in solar power plants, emphasizing the use of drones and automated detection while suggesting potential enhancements such as thermal infrared integration and robotic cleaning operations. Among renewable energy resources, solar energy has emerged as one of the most important contributors to fulfilling energy demands [
9]. Solar plants generate energy on a daily basis, and this energy is provided to national grids. Accurately predicting the energy production of solar plants is a difficult task that requires advanced techniques [
10]. Traditional methods are utilized to predict power generation and other parameters, but their accuracy is still limited [
10]. To improve the accuracy of these predictions, many researchers have received help from different machine learning models that are implemented on the dataset acquired from different energy and power plants. These machine learning models have proven to be very effective for forecasting/predicting different parameters [
11]. In [
12], only a single statistical ARIMA model is used for the prediction of solar plant parameters, but the results are not clearly understandable, whereas Ref. [
13] proposes a hybrid model of ARIMA and LSTM for short-time electric energy estimation of photovoltaic (PV) power plants. The model combines the advantages of both methods to enhance the estimation accuracy of electric power forecasting. However, the study only evaluates the performance of the model on a single PV plant, which may limit its generalizability to other plants. In [
14], a Bi-LSTM model is used only for electricity generation parameter forecasting for a solar PV plant. The model takes into account both temporal and spatial dependencies of input features to improve the accuracy of forecasting, but the study only considers one input feature (i.e., solar irradiance), which may limit the model’s ability to capture other factors that affect electricity generation. Similarly, the work of [
15] proposes an LSTM neural network for forecasting the electricity generation of a solar PV power plant. This research study executes the comparison of the performance of the LSTM model with other methods, such as ARIMA and random forest. The study only uses a limited amount of data (i.e., one year), which may not be sufficient to capture the full range of variability in electricity generation. Again, the work of [
16] compares the performance of ARIMA and LSTM models for forecasting electricity generation from a solar power plant, in which the LSTM model outperforms the ARIMA model in terms of accuracy, but here, the data size and plant capacity are very small, which may limit the generalizability of the findings. A hybrid ARIMA–LSTM model for short-term prediction of PV power output is used in [
17]. The model combines the strengths of both methods to improve the accuracy of forecasting, but, owing to limited data availability, it may not be sufficient to capture the full range of variability in PV power output. These machine learning models are also utilized in other kinds of power generation plant datasets, as Ref. [
18] compares the performance of ARIMA, LSTM, and ELM models for short-term wind power forecasting. It can be shown that the ELM technique performs better in terms of accuracy than the ARIMA and LSTM methods. The only limitation of this study is that it does not provide a comparison of the computational complexity or feasibility of the different models. In the same way, both of these models are compared with the RF model, SVR model, MLP model, and LSTM-ATT again for wind power and solar power forecasting, and these models outperform the ARIMA and LSTM models in terms of accuracy and stability. However, a lack of explanation of how the models were trained and preprocessed is observed here, which may limit the reproducibility and reliability of the results [
19,
20,
21,
22]. Additionally, these studies do not account for external factors that may affect the performance of the models, such as changes in weather patterns or policy changes affecting the energy industry. The authors of [
23] proposed a Bi-LSTM model for short-term wind power forecasting that incorporates wavelet decomposition and clustering analysis to enhance the accuracy of predictions. The model was found to outperform other models in terms of accuracy, but may not take into account extreme weather conditions, which can cause significant changes in wind power generation. Moreover, the model uses many parameters and does not compare the proposed model to other forecasting methods, which makes it difficult to assess the model’s effectiveness and leads to over fitting. In the same way, a Bi-LSTM model is used with an attention mechanism for electricity load forecasting in [
24] to highlight the relevant features in the input data and improve the model’s accuracy, as well as in [
25] to improve the capturing capacity with an attention mechanism for short-term photovoltaic power forecasting’s ability to capture complex patterns in data. Although the proposed model outperforms other models in terms of accuracy and robustness, it only focuses on electricity load forecasting for one region and may not be applicable to other regions with different load patterns [
26]. Furthermore, Bi-LSTM is used for short-term solar power forecasting for wind power generation based on multi-step ahead optimization and has been found to outperform other models in terms of accuracy, stability, and robustness [
27].
From the above discussion, it is concluded that the only potential limitation of the Bi-LSTM model is that it may be computationally expensive and require a large amount of data for training. The performance of the model may be impacted by the quality and availability of the input data. Therefore, it is important to carefully evaluate the performance of the Bi-LSTM model and consider the limitations and potential drawbacks of these models in energy forecasting applications. This research also focuses on one year of real-time solar power production data and evaluates the performance parameters of the ARIMA and Bi-LSTM models in predicting solar power production and radiance for the following year. Further research and development in this area are needed to continuously improve the accuracy and robustness of renewable energy generation prediction models to support efficient energy management and achieve sustainable energy systems.
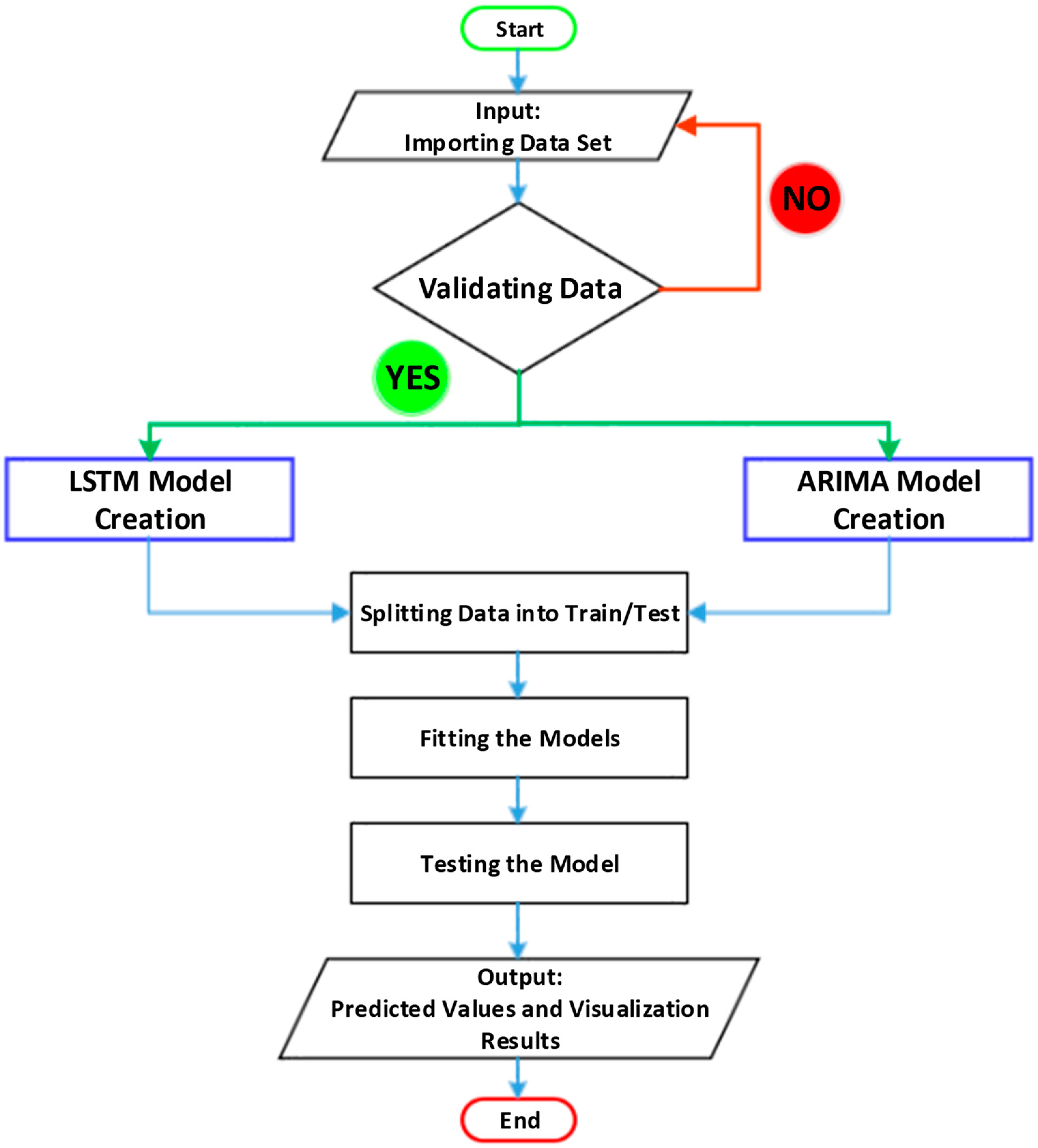
Section 2 of the study presents the framework and methodology of the proposed models, including the mathematical models, structure, and a basic comparison of the two models, while
Section 3 focuses on the case study and data description. The results of the study, including losses and predictions, are thoroughly discussed in
Section 4.
Section 5 is the detail of system and software used for the experimental results. Finally,
Section 6 presents the conclusive remarks of the study.
3. Case Study
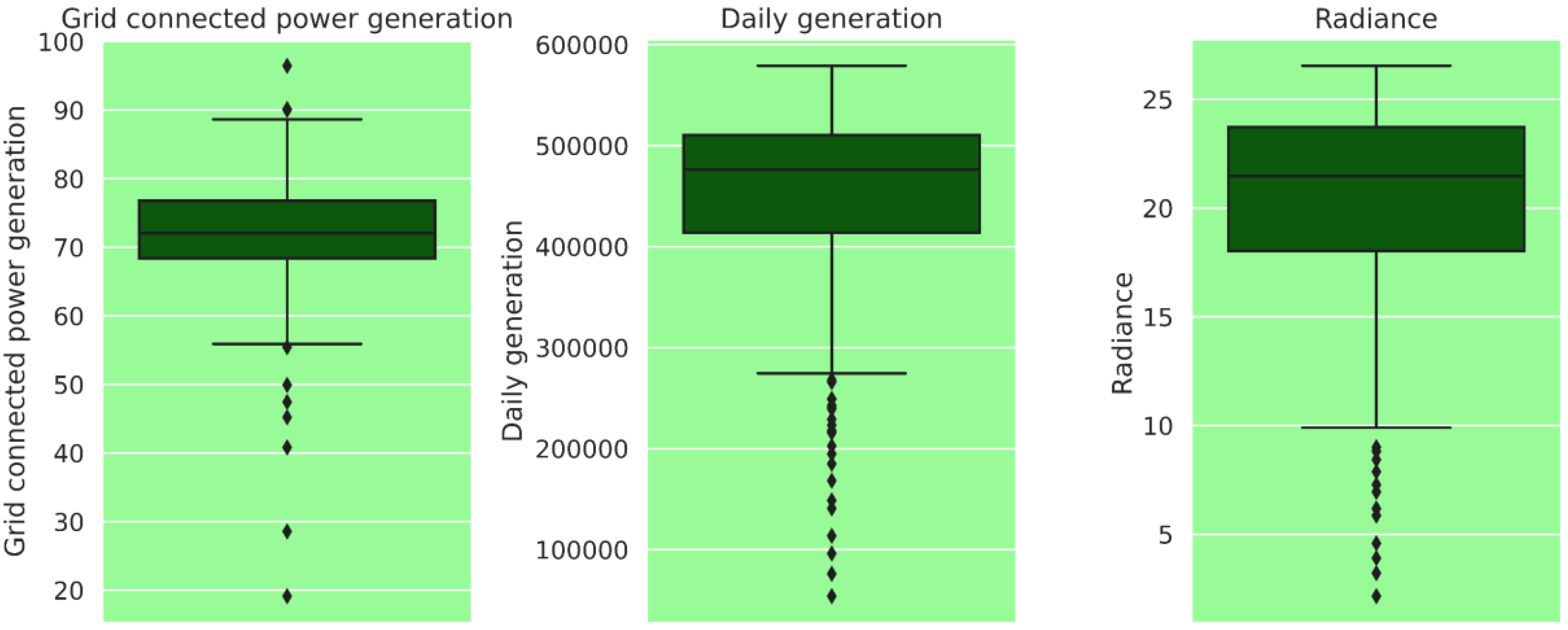
Box plots are useful for summarizing a large dataset and providing insights into its distribution.
Figure 5 shows the median (Q2), interquartile range (Q1–Q3), and outliers or extreme values of the parameters of data acquired from a large-scale solar power plant, including grid-connected power generation in MW, daily generation in kWh, and radiance in MJ·m
−2. The height of the box represents the spread of the middle 50% of the data, and the whiskers extend to the lowest and highest values that fall within 1.5 times the interquartile range. Any values outside this range are shown as individual points or circles, and can be considered potential outliers. The first box plot is “grid-connected power generation in MW”, and the
y-axis depicts the range of electric power generation (20 MW–100 MW). The range of Q1 (the first quartile) is 58–68, which implies that the lowest 25% of the data falls in this range. The range of Q2 (the second quartile) is 68–73, which indicates that the middle 50% of the data falls in this range. The range of Q3 (the third quartile) is 73–78, which signifies that the highest 25% of the data falls in this range. Finally, the range of Q4 (the fourth quartile) is 78–99, which suggests that the top 1% of the data falls in this range. In the same way, the second box plot is “daily generation in kWh”, and the
y-axis depicts the range of number of kWh units generated (100,000 kWh–600,000 kWh). The range of Q1 is 260,000–420,000, which presents that the lowest 25% of the data falls in this range. The range of Q2 is 420,000–470,000, which demonstrates that the middle 50% of the data falls in this range. The range of Q3 is 470,000–510,000, which represents that the highest 25% of the data falls in this range. Finally, the range of Q4 is 510,000–570,000, which signifies that the top 1% of the data falls in this range. The third box plot is “radiance in MJ·m
−2”, and the
y-axis represents the range of effective solar radiation (5 MJ·m
−2–30 MJ·m
−2) that has the potential to be converted into electrical energy. The range of Q1 is 10–18, which signifies that the lowest 25% of the data falls in this range. The range of Q2 is 18–22, which presents that the middle 50% of the data falls in this range. The range of Q3 is 22–24, which indicates that the highest 25% of the data falls in this range. Finally, the range of Q4 is 24–27, which implies that the top 1% of the data falls in this range, as shown in
Figure 5 below.
Figure 6 represents the correlation of the data through a heat map. A heat map is a visual representation of data that uses color-coded cells to show the relative values of different variables. In this case, the heat map shows the correlation between three variables, grid-connected power generation in MW, daily generation in kWh, and radiance in MJ·m
−2. The numbers shown in each cell are indicative of the correlation coefficient that exists between the two variables associated with the row and column that the cell represents.
The correlation coefficient ranges from −1 to +1, with values close to −1 indicating a strong negative correlation, values close to +1 indicating a strong positive correlation, and values close to 0 indicating little or no correlation. The heat map presented has three rows and three columns, corresponding to the three variables. The diagonal cells (i.e., the cells where the row and column variables are the same) are all 1, because a variable is always perfectly correlated with itself. The off-diagonal cells show the correlation between pairs of variables. For example, the cell in the first row and second column shows the correlation between grid-connected power generation in MW and daily generation in kWh, which is 0.37. This indicates a positive but relatively weak correlation between the two variables. Similarly, the cell in the second row and third column shows the correlation between daily generation (kWh) and radiance (MJ·m−2), which is 0.95. This indicates a strong positive correlation between the two variables. Overall, the heat map shows that there is some correlation between the three variables, but the strength of the correlations varies. Grid-connected power generation in MW and daily generation in MJ·m−2 are weakly correlated, while daily generation (kWh) and radiance (MJ·m−2) are strongly correlated.
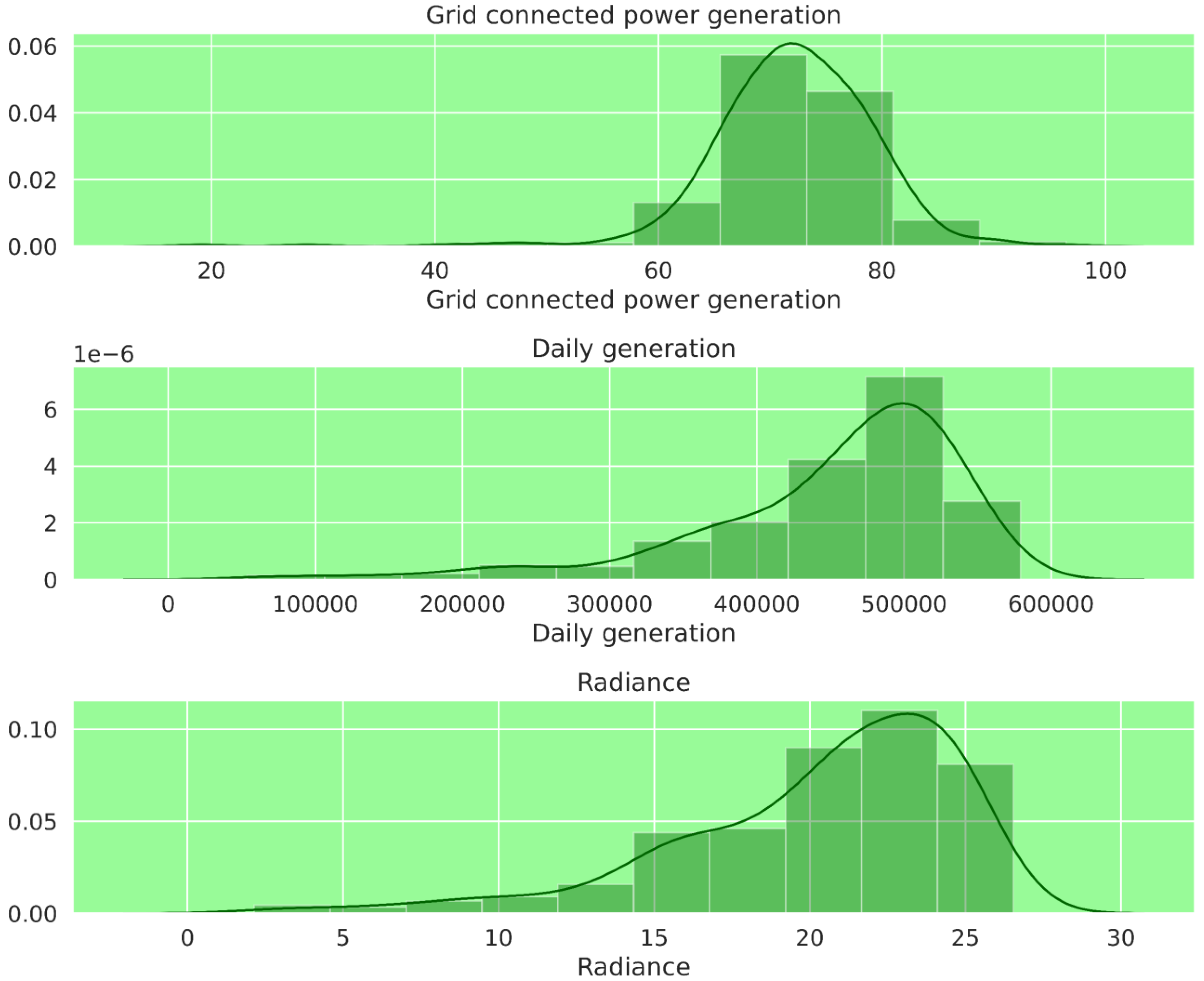
A histogram visualizes the frequency distribution of the dataset, in which the
x-axis represents the range of values in the dataset, while the
y-axis represents the frequency of those values. In
Figure 7, the
y-axis measures the frequency of occurrence of grid-connected power generation values from 0.00 to 0.06, likely in units of megawatts (MW).
The x-axis measures grid-connected power generation values from 0 to 100 MW and is divided into equal bins to create the histogram. By counting the occurrences of grid-connected power generation values within each bin and plotting the frequencies on the y-axis, the resulting histogram shows the distribution of power generation values over a specific period of time. The second part of histogram, titled “daily generation (kWh)”, represents the distribution of the number of units generated by a solar power plant on a daily basis. The y-axis range is 0.00–7.00, indicating the frequency of occurrence of the number of units generated. The x-axis range is 0–600,000 units, divided into equal intervals or bins, representing the range of values of the number of units generated. Similarly, the “radiance” histogram has a y-axis range of 0.00–0.10 and an x-axis range of 0–30. The y-axis shows the frequency or count of data in each interval, with the highest count being 0.10 and the lowest count being 0.00. The x-axis shows the range of radiance values grouped into intervals of width 1, with the last interval being 29–30. The histogram represents the distribution of radiance values, where the shape of the histogram can provide insights into the distribution of radiance values. If the histogram is skewed to the right, there are more low radiance values, and if it is skewed to the left, there are more high radiance values. A symmetrical histogram indicates an even distribution of radiance values.
4. Results and Discussion
In this study, a one-year dataset is collected from a solar plant, capturing grid-connected power generation (MW), daily generation (kWh), and radiance (MJ·m−2) parameters in real time. These three parameters are utilized to forecast the following year’s grid-connected power generation, daily generation, and radiance. This prediction is accomplished using two distinct models: the autoregressive integrated moving average (ARIMA) and a machine learning bidirectional long short-term memory (Bi-LSTM) model. The selection of these models was based on a comprehensive literature review, which identified them as the most accurate and refined approaches for this purpose. While the results of both models indicate predictions that are very close to the actual real-time data values, the machine learning Bi-LSTM (bidirectional long short-term memory) model outperforms the ARIMA (auto-regressive integrated moving average) model. In this section, we discuss the results and graphical visualizations of both models, along with detailed analysis of the mean absolute error and mean square error values.
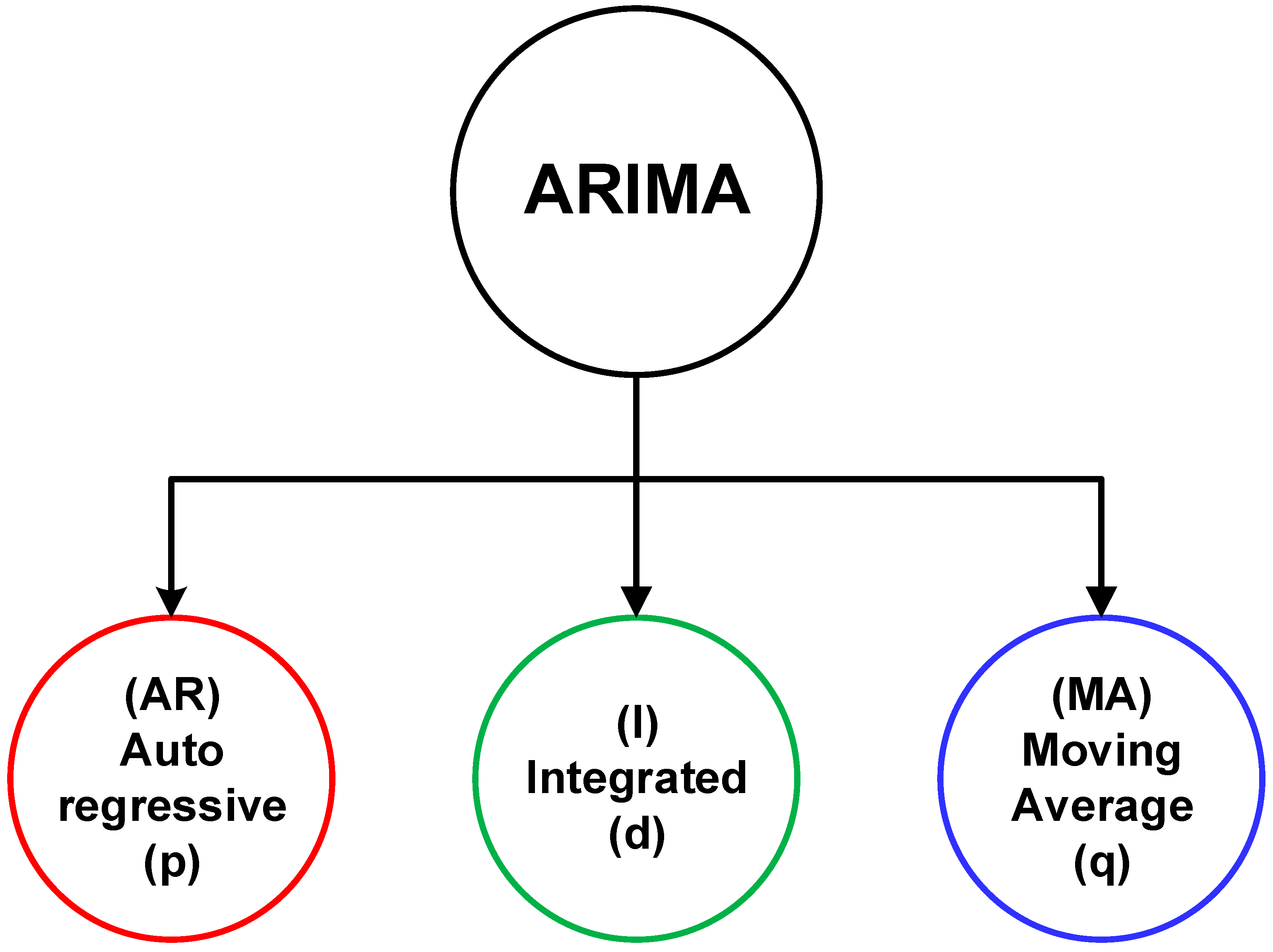
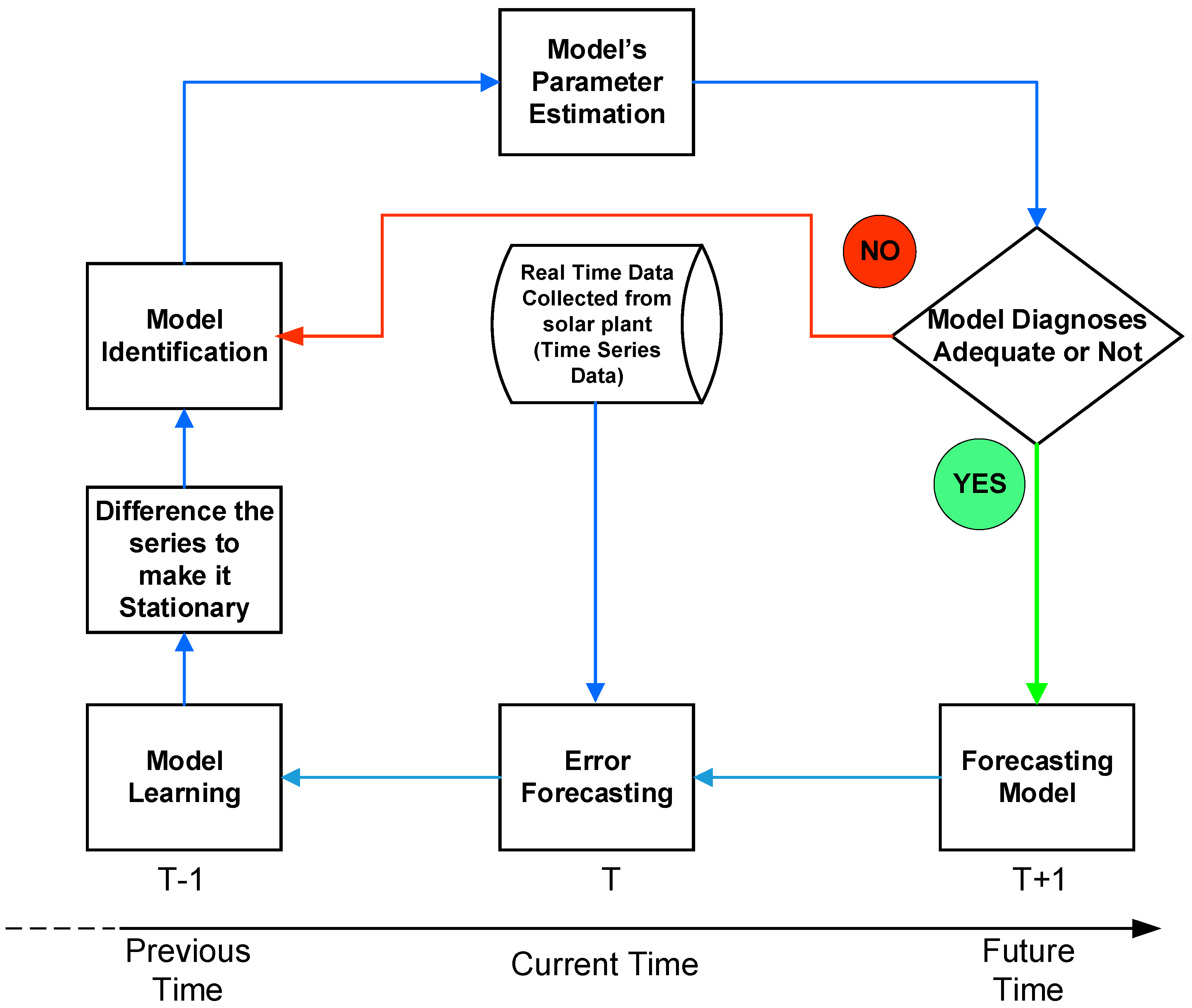
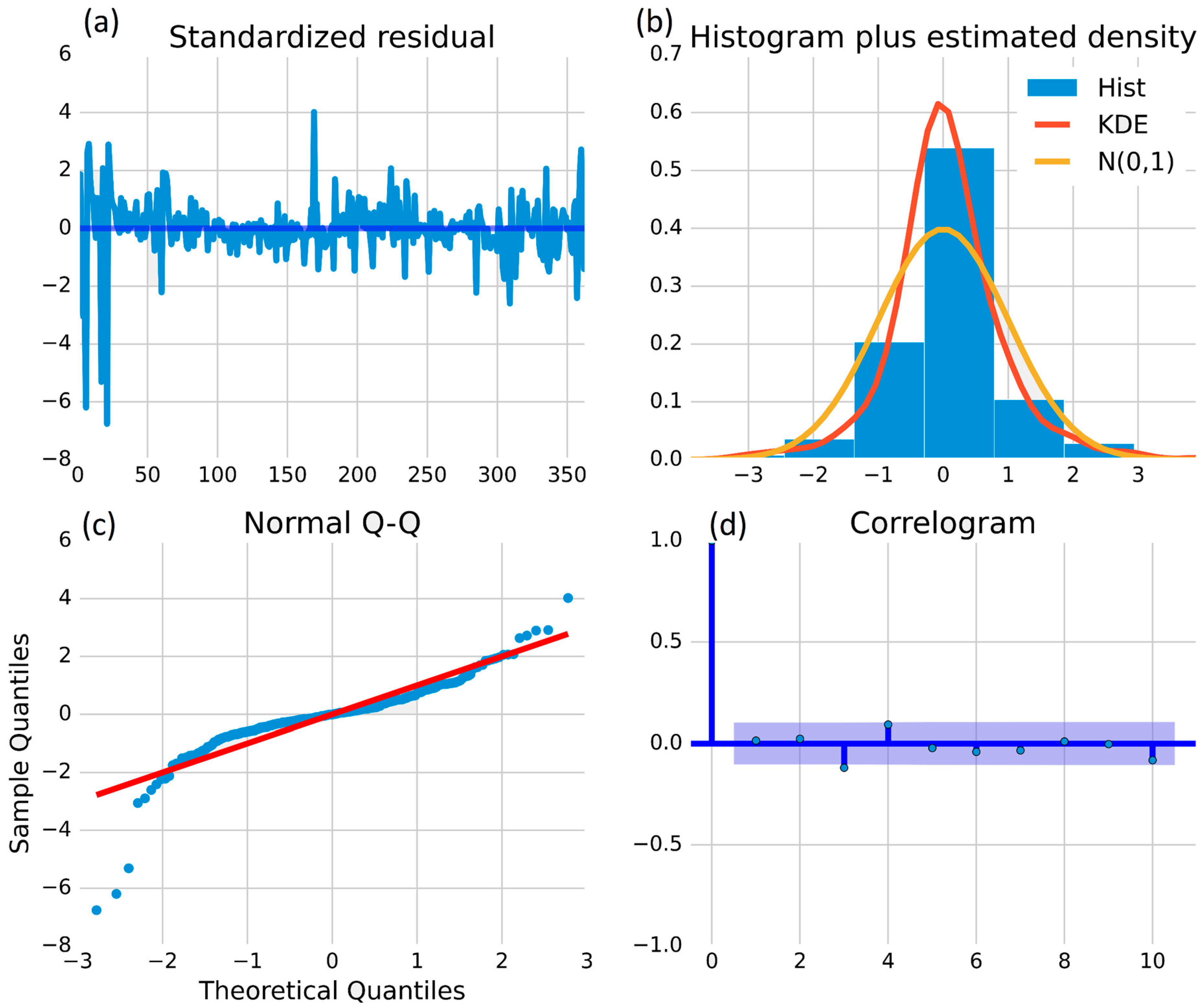
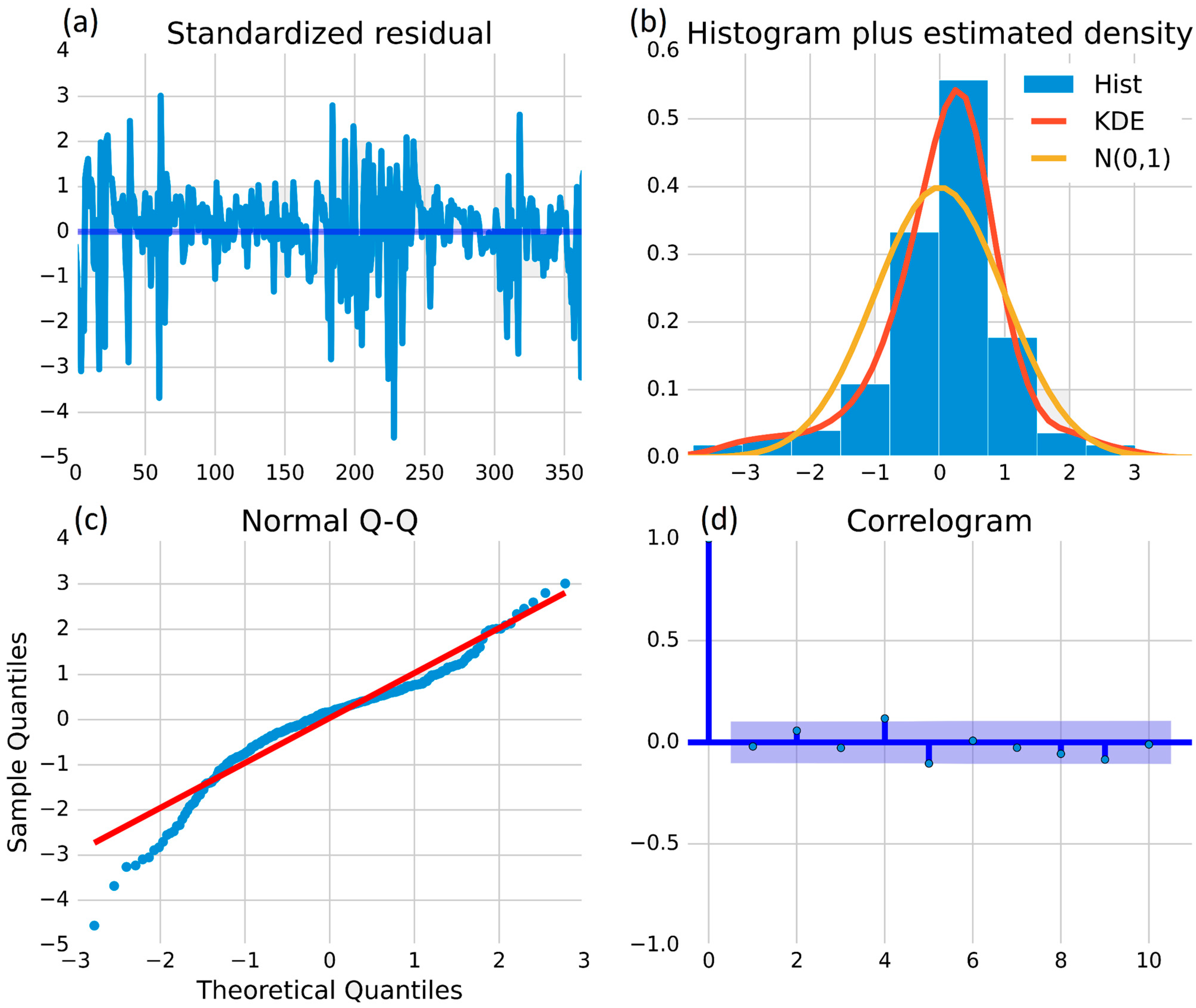
The first analysis is conducted using the ARIMA (auto-regressive integrated moving average) model, which is a statistical approach to prediction. For the purpose, data analysis was carried out between actual and predicted data through four statistical plots that are commonly used in data analysis, as shown in
Figure 8,
Figure 9 and
Figure 10. These figures contain four graphical visualizations. The first one is the standardized distribution plot, which standardizes a variable for comparison to other variables that may have different scales or units. The second is a histogram that visualizes the distribution of a variable, identifying its shape and any outliers. The third is a normal Q–Q plot, which assesses whether a sample distribution is normal. Finally, the forth is a correlogram, which helps to identify correlations between a variable and its lagged values and is also useful in time series analysis. Each plot serves a specific purpose in data analysis and can provide valuable insights into the underlying patterns and trends of the data.
Figure 8a is the standardized residual graph, which is a plot of the residuals against the standardized values of the independent variable of the grid-connected power generation data of the solar plant. In the case of grid-connected power generation data, the
y-axis range is −8 to 6 and the
x-axis range is 0–350. The first three negative peaks appear at −6, −5.2, and −7, indicating significant deviations from the predicted values. However, after the third peak, the residuals are within the range of −2 to 4 up to day 350, suggesting that the model fits the data well. The standardized residual graph can help identify any outliers or unusual data points that may require further investigation.
Figure 8b is a histogram showing the distribution of power generation from a grid-connected solar power plant. The
y-axis represents the frequency of power generated, which ranges from 0.0 MW to 0.7 MW, while the
x-axis represents the deviation of power generated from its mean value. The highest peak of the histogram bar indicates that the most frequent power generation lies between 0 and 0.55 MW. The KDE and N (0, 1) density curves estimate the probability density function, and their highest peaks indicate that the most probable power generation lies in the range of 0.6 MW and 0.4 MW, respectively. This graph provides a visual representation of the distribution of power generated by a solar power plant. The normal Q–Q plot in
Figure 8c is used to assess the normality of residuals in statistical models, such as the ARIMA (auto-regressive integrated moving average) model for predicting power generation (MW) in a solar power plant. The
y-axis depicts the observed residuals and the
x-axis shows the expected residuals based on a normal distribution. The straight red line represents the line of normality and deviation from this line indicates non-normality. In the given plot, the residuals have a positive skew, but more than 90% of the data falls close to the straight red line, indicating that the residuals are approximately normally distributed. The normal Q–Q plot is a useful tool for assessing the accuracy of the ARIMA (auto-regressive integrated moving average) model predictions.
Figure 8d is a correlogram, which is used for the autocorrelation function (ACF) of a time series at different lags in ARIMA (auto-regressive integrated moving average) modeling to identify the appropriate order of the model by examining the decay of the ACF. Most of the data points in the correlogram indicate no significant correlation between the time series and its lagged versions, but a few data points deviate from the 0.0 line, which may indicate the presence of some autocorrelation. Further investigation is needed to determine the appropriate ARIMA (auto-regressive integrated moving average) model order.
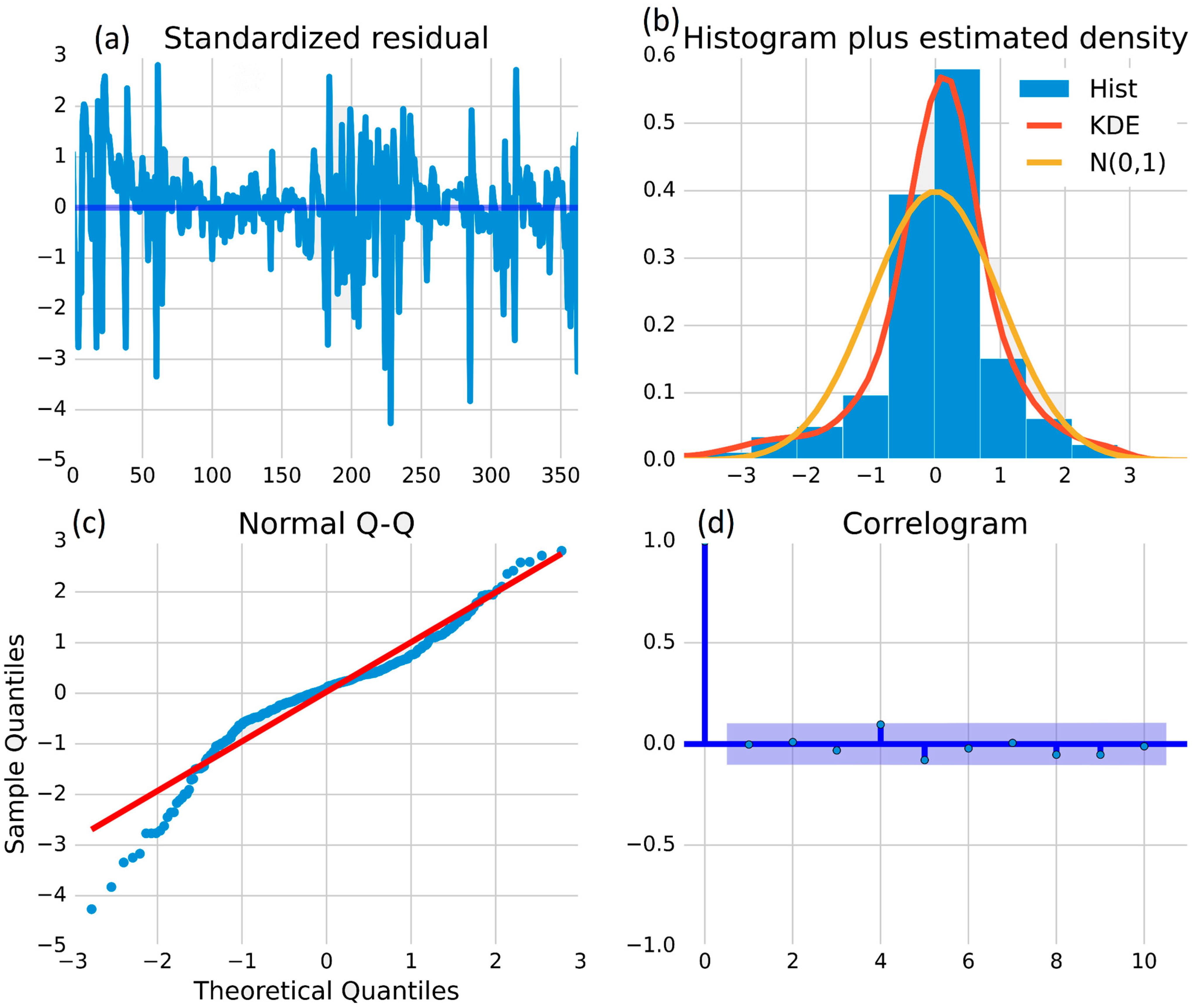
Similarly,
Figure 9a is the standardized residual graph plotting the residuals against the standardized values of the independent variable. In the case of a daily solar power plant’s daily generation (kWh), the
y-axis range is −5 to 3 and the
x-axis range is 0–350. The highest negative peak appears at −4.2 and the highest positive peak appears at 2.9, indicating significant deviations from the predicted values on those days. After the highest peaks, all of the residuals are within the range of −4.2 to 2.8 up to day 350, indicating that the model fits the data well. The standardized residual graph can help identify any outliers or unusual data points that may require further investigation. The graph in
Figure 9b represents the distribution of the grid daily generation (kWh) of a solar power plant using a histogram, a kernel density estimation (KDE) plot, and a normal distribution plot. The histogram shows that the highest peak of the histogram bar is nearly equal to 0.6, indicating that the solar power plant generates power close to 0.6 most of the time. The KDE plot shows the probability density function of the data, with the highest positive peak appearing at 0.55 in the red line. The yellow line represents the normal distribution, with the highest positive peak appearing at 0.4. Comparing the distribution of the solar power plant to the normal distribution provides insight into how the solar power plant’s generation behaves relative to a standard distribution. The normal Q–Q plot in
Figure 9c is a graphical method used to assess the normality assumption of errors in the ARIMA (auto-regressive integrated moving average) model implementation on the real-time data of grid-connected power generation (MW) of a solar power plant. The
y-axis represents sample quintiles, the
x-axis represents theoretical quintiles, and a red line represents the line of perfect agreement. Initially, there is some scattering of data, indicating that the data may not follow a normal distribution. However, from the point (−2.5, −2.5), the data points align more closely with the red line, suggesting that the errors of the ARIMA (auto-regressive integrated moving average) model follow a normal distribution from this point onwards. In the same way,
Figure 9d is a correlogram that shows how much each past observation of a time series is related to the current observation. When using the ARIMA (auto-regressive integrated moving average) model on solar power plant data, the correlogram helps to determine the correlation between current and past power generation values. The
y-axis shows the strength and direction of the correlation, while the
x-axis represents the number of lagged values being compared. Most data points are near the 0.0 line, but deviations suggest correlation at specific lags and can inform the choice of ARIMA (auto-regressive integrated moving average) model parameters.
In the case of a solar power plant, a standard residual graph can be used to predict the radiance (MJ·m
−2) that the plant will receive based on various factors. In
Figure 10a, the
y-axis ranges from −5 to 4, indicating that the standardized residuals range from −5 standard deviations below the mean to 4 standard deviations above the mean. The
x-axis ranges from 0 to 350, which represents the predicted radiance values. The fact that the highest negative peak appears at −4.5 and the highest positive peak appears at 3 suggests that the model is doing a good job of predicting the radiance values. A well-fitted model will have residuals that are randomly distributed around zero with no apparent pattern and will not have any extreme outliers or clusters of outliers. Similarly, in
Figure 10b, the graph represents the distribution of the radiance of a solar power plant using a histogram, a kernel density estimation (KDE) plot, and a normal distribution plot. The
x-axis ranges from −3 to 3, while the
y-axis ranges from 0.0 to 0.6. The histogram shows that the highest peak of the histogram bar during 0 to 1 is nearly equal to 0.55, indicating that most of the radiance values fall between 0 and 1. The KDE plot shows the probability density function of the data, with the highest positive peak appearing at 0.53 in the red line. This means that the probability density is highest around 0.53, indicating that the radiance values are concentrated around this value. The yellow line represents the normal distribution, with the highest positive peak appearing at 0.4. Comparing the distribution of the radiance of the solar power plant to the normal distribution shows that the radiance values are skewed to the right, with more values falling in the higher range. Overall, the graph provides insight into the distribution of the radiance values of the solar power plant, with the histogram showing the frequency of occurrence of each value and the KDE plot and normal distribution plot showing the probability density function of the data. The normality assumption of errors in the ARIMA (auto-regressive integrated moving average) model implementation on the real-time data of grid-connected power generation of a solar power plant assessed using a normal Q–Q plot is shown in
Figure 10c.
The
y-axis represents sample quantiles, the
x-axis represents theoretical quantiles, and a red line represents the line of perfect agreement. Initially, there is some scattering of data, indicating that the data may not follow a normal distribution. However, from the point (−2.5, −2.5), the data points align more closely with the red line, suggesting that the errors of the ARIMA (auto-regressive integrated moving average) model follow a normal distribution from this point onwards. In the same way, the correlogram obtained from implementing an ARIMA (auto-regressive integrated moving average) model on real-time-series data of grid-connected power generation (MW) of a solar power plant shows the correlation coefficients between lagged values of the time series in
Figure 10d. The
y-axis range is −1 to 1, with 0 indicating no correlation and −1 and 1 indicating perfect negative and positive correlations, respectively. The
x-axis range is 0 to 10, representing the number of lagged values being compared to the current value. The data points are mostly clustered around the 0.0 line, indicating little to no correlation between the current power generation and past values, with only a few deviations suggesting some correlation at specific lags. These deviations can be used to inform parameter choices for the ARIMA (auto-regressive integrated moving average) model.
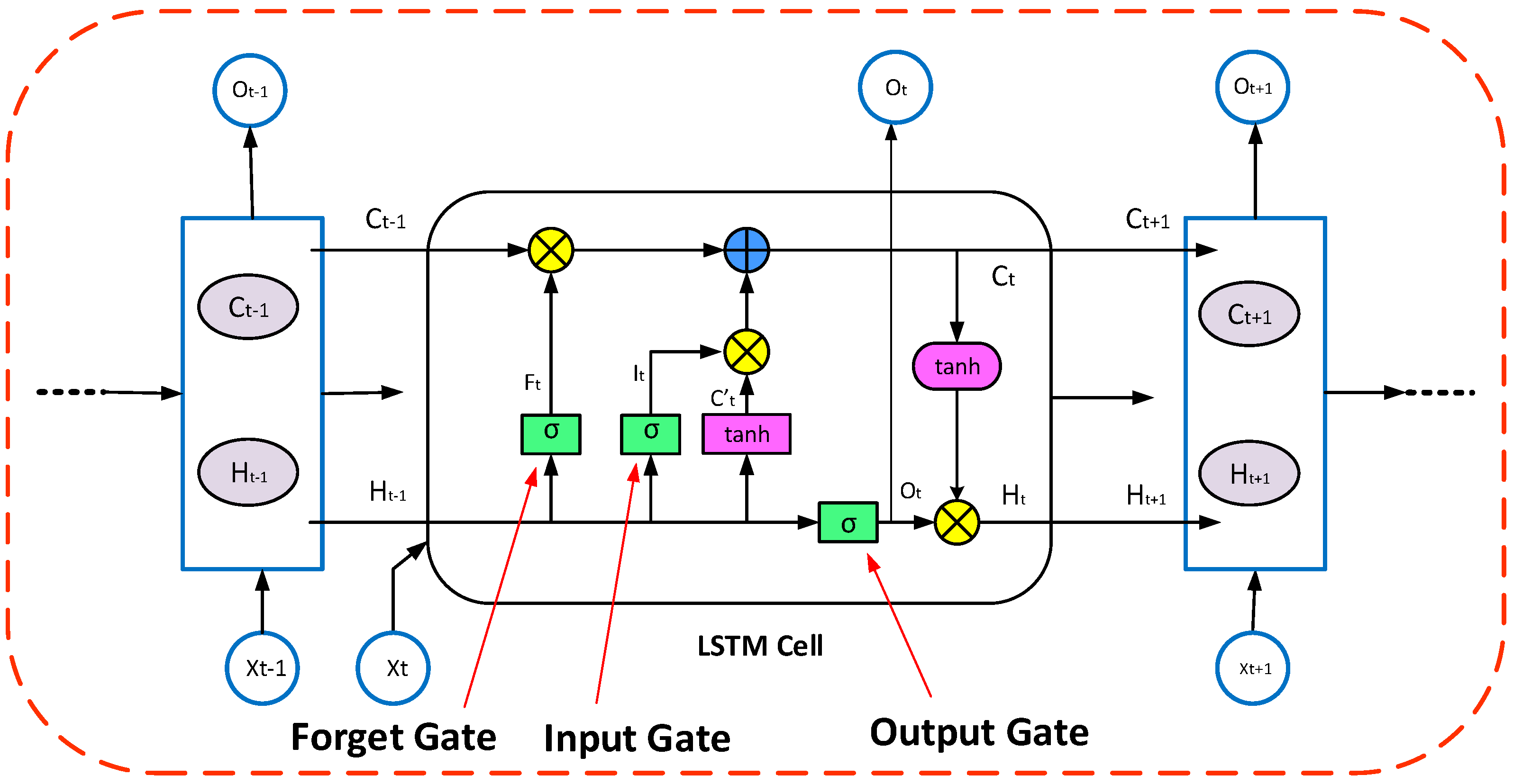
Secondly, the Bi-LSTM (bidirectional long short-term memory) model architecture is a sequential model, with several bidirectional layers followed by dropout and dense layers. The prediction results, MAE loss, and RMSE loss from this model are also discussed in this section and represented in graphical visualizations.
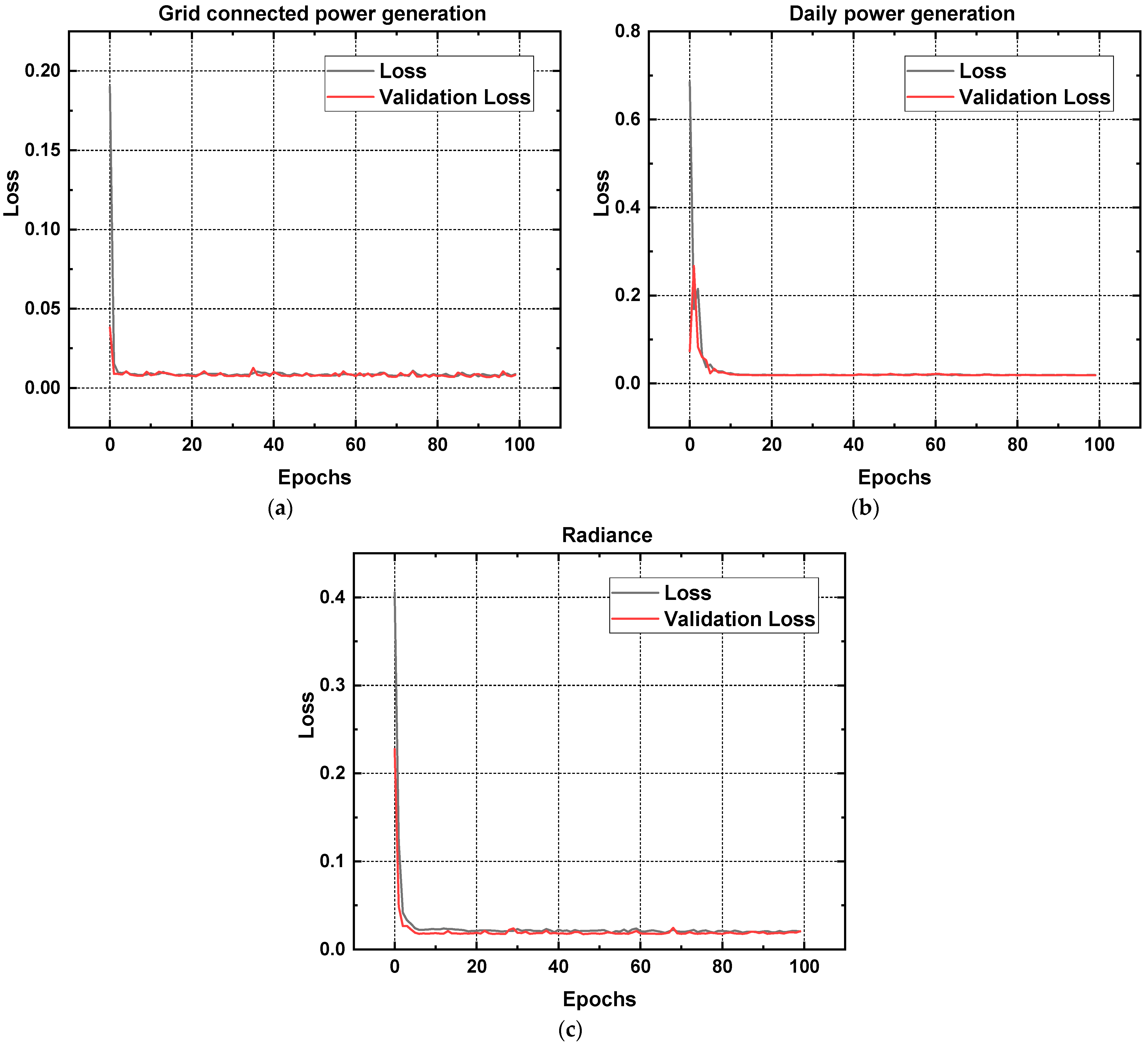
Table 1 describes the Bi-LSTM (bidirectional long short-term memory) model’s structure, in which bidirectional layers have 200 units each and are stacked on top of each other. The final bidirectional layer outputs a tensor of shape (none, 200), which is then passed through a dropout layer with a rate of 0.5. The output of the dropout layer is then fed to a dense layer with one output unit, which is the final prediction. The summary table provides the output shape and the number of determinable parameters included in every layer of the simulated model. The simulated model has a total of 1,045,001 trainable parameters. The second part of the output shows the keys of the history object returned by the model.fit() method during training. These include the training loss, mean squared error (MSE), and mean absolute error (MAE), as well as the validation loss, MSE, and MAE.
The training and validation results of the Bi-LSTM (bidirectional long short-term memory) model are compared in
Figure 11a–c using parameters of data collected from a solar power plant. As can be shown in
Table 2, the model achieves the lowest loss on “grid-connected power generation (MW)” at 0.00872, followed by “daily generation (kWh)” at 0.01951, and “radiance (MJ·m
−2)” at 0.02041. Grid-connected power generation seems to be the most reliably predicted variable in our model. Similar patterns may be seen in the validation loss values, which are used to evaluate the model’s adaptability to fresh inputs. Further, the model’s validation loss is smallest for the parameter “grid-connected power generation (MW)” at 0.00822, followed by “daily generation (kWh)” at 0.0187 and “radiance (MJ·m
−2)” at 0.02067. Based on these findings, “grid-linked power generation” seems to be the model’s sweet spot in terms of generalizability to fresh data. Prediction accuracy and generalizability to new data are best, as shown by the model’s lower validation loss relative to its actual loss. Losses and validation losses for “daily generation (MW)” and “radiance (MJ·m
−2)” are likewise not too far off the best-performing parameter, indicating that the model performs rather well for these two scenarios.
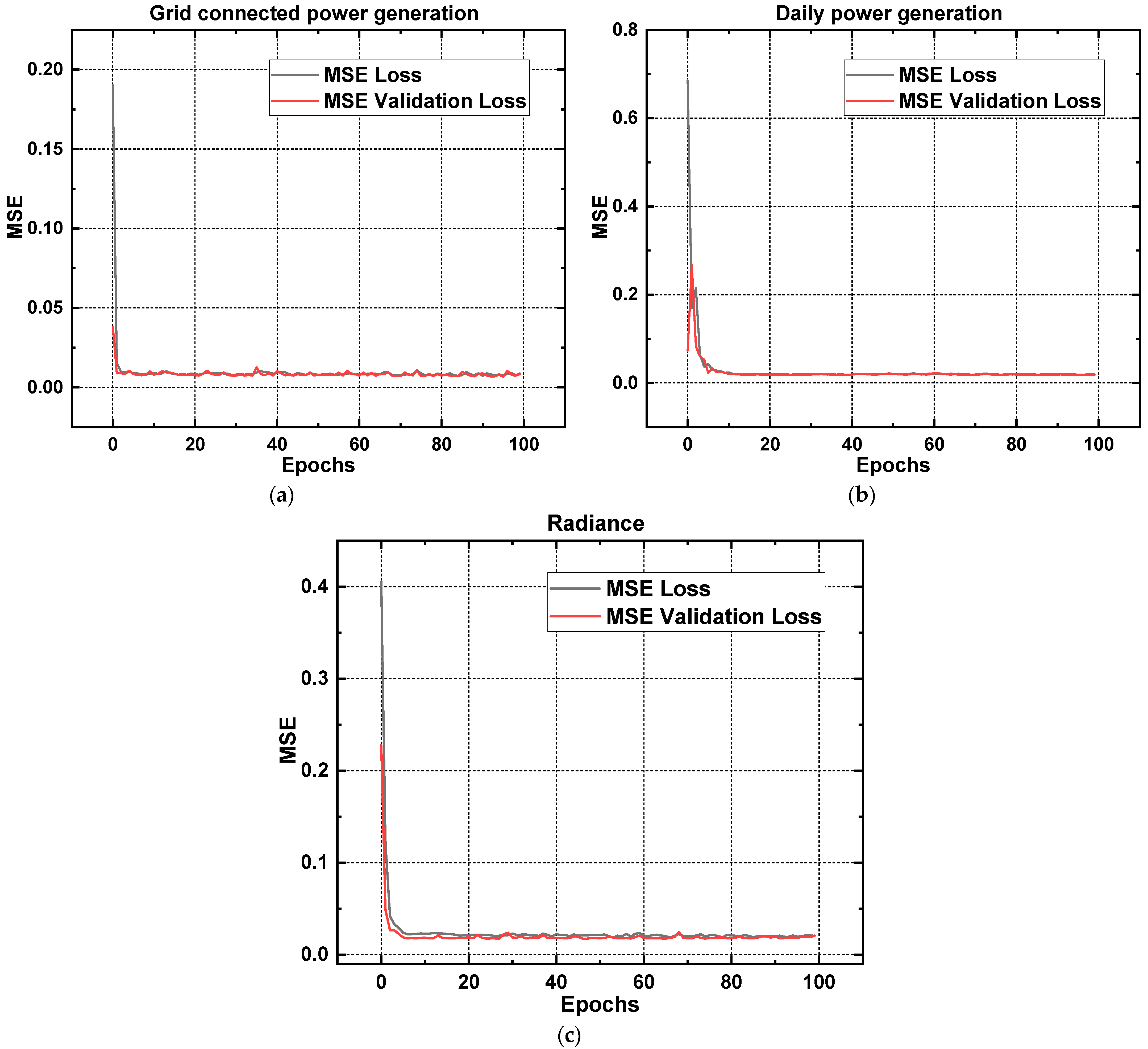
Table 2 displays the results of a comparison between the training and validation mean absolute errors (MAEs) for a Bi-LSTM (bidirectional long short-term memory) model trained with data from a solar power plant’s three major parameters. The MAE loss values for “grid-connected power generation (MW)”, “daily generation (kWh)”, and “radiance (MJ·m
−2)” are shown in
Figure 12a–c, respectively, and show that the Bi-LSTM (bidirectional long short-term memory) model performs best on “grid-connected power generation (MW)”, with a loss of 0.05932. These findings imply that “grid-connected power generation (MW)” is the parameter for which the model’s predictions are most accurate. Similarly, the model has a lower mean absolute error (MAE) for “grid-connected power generation (MW)” (0.06027), “daily generation (kWh)” (0.08906), and “radiance (MJ·m
−2)” (0.0925) than their respective benchmarks. This suggests that, of the three factors, “grid-connected power generation (MW)” benefits most from the model’s capacity to generalize to new data. The model’s performance is better at predicting this parameter than the other two based on the comparison of MAE loss and validation MAE values.
Figure 13a–c compare the root mean squared error (RMSE) loss and validation RMSE values for a Bi-LSTM machine learning model trained on three distinct parameters of a solar power plant. With a validation RMSE of 0.0073 and an RMSE loss of 0.00872 on “grid-connected power generation (MW)”, this model outperforms. After “radiance (MJ·m
−2)”, which has an RMSE loss of 0.02041, “daily generation (kWh)” has an RMSE loss of 0.01951 and a validation RMSE of 0.01884. These findings indicate that, among the three factors, “grid-connected power generation (MW)” has the best model predictions in terms of training and generalization to new data. Both the RMSE loss and validation RMSE values for “daily generation (kWh)” and “radiance (MJ·m
−2)” are similar to the best-performing parameter, indicating that the model’s performance in these areas is likewise quite excellent.
Table 2 presents all of the actual and validated loss values acquired from the Bi-LSTM model implementation on the data of a solar plant.
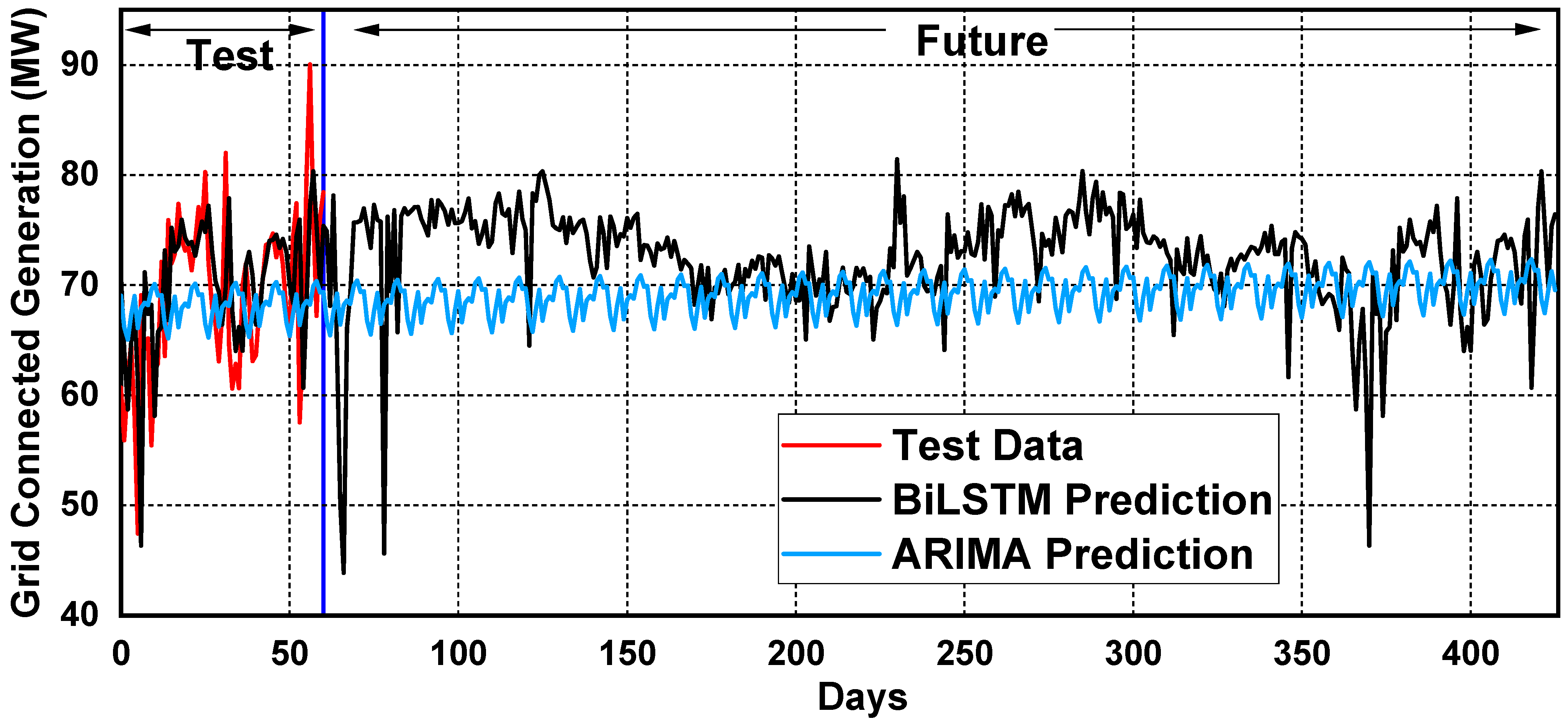
The prediction outcomes of a data analysis project conducted on a 100 MW solar plant are visually represented in
Figure 14,
Figure 15 and
Figure 16. This study involved training two machine learning models, namely ARIMA (auto-regressive integrated moving average) and Bi-LSTM (bidirectional long short-term memory), utilizing 80% of one year’s real-time data on three crucial parameters: grid-connected power generation (MW), daily power generation (kWh), and radiance (MJ·m
−2). The remaining 20% of the data was used for testing and validation purposes. The two models’ performances were compared by analyzing the 10-month training data against the 2-month test data. Additionally, one-year future predictions were generated for all three parameters using both models. The graphical visualizations in
Figure 14,
Figure 15 and
Figure 16 provide a comparative analysis of the two models’ results and future predictions for all three parameters within a single graph. The first section of the visualizations depicts the comparison among the actual prediction dataset and the 60-day test dataset of the solar plant. The second part of the graph shows one-year future projections of the solar plant based on each parameter.
Figure 14 displays the “grid-connected power generation (MW)” parameter’s range of 40 MW to 100 MW on the
y-axis, with the number of days on the
x-axis. The comparison of predicted data using ARIMA (auto-regressive integrated moving average) and Bi-LSTM (bidirectional long short-term memory) and the remaining actual 60-day test data shows that Bi-LSTM’s prediction is approximately in sync with the test results, while ARIMA’s results have a minor deviation. After this comparison, both trained prediction models are used to manipulate the grid-connected power generation data for the next 12 months (365 days). It is evident in
Figure 14 that Bi-LSTM (bidirectional long short-term memory) initially shows an abrupt decrease and then achieves a continuous pattern, indicating that the grid-connected power generation will remain smooth and upgraded most of the time for the next year. Meanwhile, a slight increase in grid-connected power generation is observed in ARIMA’s prediction, with a continuity trend.
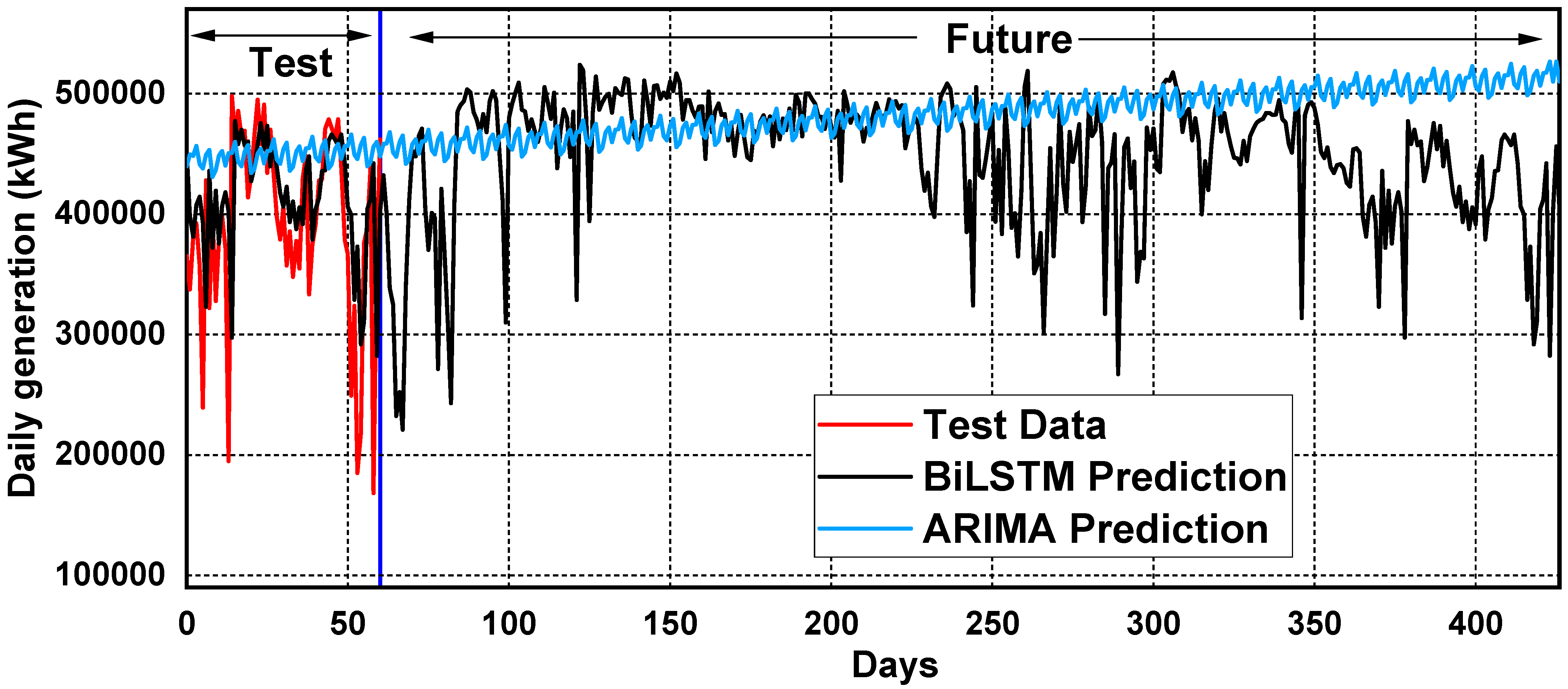
Figure 15 exhibits the “daily generation (kWh)” parameter’s range of 100,000 to 500,000 units on the
y-axis, with the number of days on the
x-axis. The comparison of predicted data using ARIMA (auto-regressive integrated moving average) and Bi-LSTM (bidirectional long short-term memory) and the remaining actual 60-day test data shows that Bi-LSTM’s prediction is almost synchronized with the test results, with minor deviations at certain points. However, ARIMA’s results are mostly incompatible. After this comparison, the daily generation data are manipulated for the next 12 months (365 days) using both trained prediction models. It is evident in
Figure 15 that Bi-LSTM (bidirectional long short-term memory) shows a decrease initially and then achieves a continuous pattern up to 160 days. After the 60th day, ARIMA’s prediction is observed to be constantly increasing.
Figure 16 displays the “radiance (MJ/
)” parameter’s range from 0 to 30 on the
y-axis, with the number of days on the
x-axis. The comparison of predicted data using ARIMA (auto-regressive integrated moving average) and Bi-LSTM (bidirectional long short-term memory) and the remaining actual 60-day test data shows that Bi-LSTM’s prediction is almost synchronized with the test results, but ARIMA’s results are incompatible. After this comparison, the radiance data are manipulated for the next 12 months (365 days) using both trained prediction models. Bi-LSTM (bidirectional long short-term memory) exhibits a decrease initially up to the 80th day and then achieves a continuous pattern up to the 220th day. Afterward, an up-and-down pattern is observed. In contrast, the ARIMA (auto-regressive integrated moving average) model remained continuous from start to end.



 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}