
Deep Learning-Based Automatic Defect Detection Method for Sewer Pipelines
Abstract
:1. Introduction
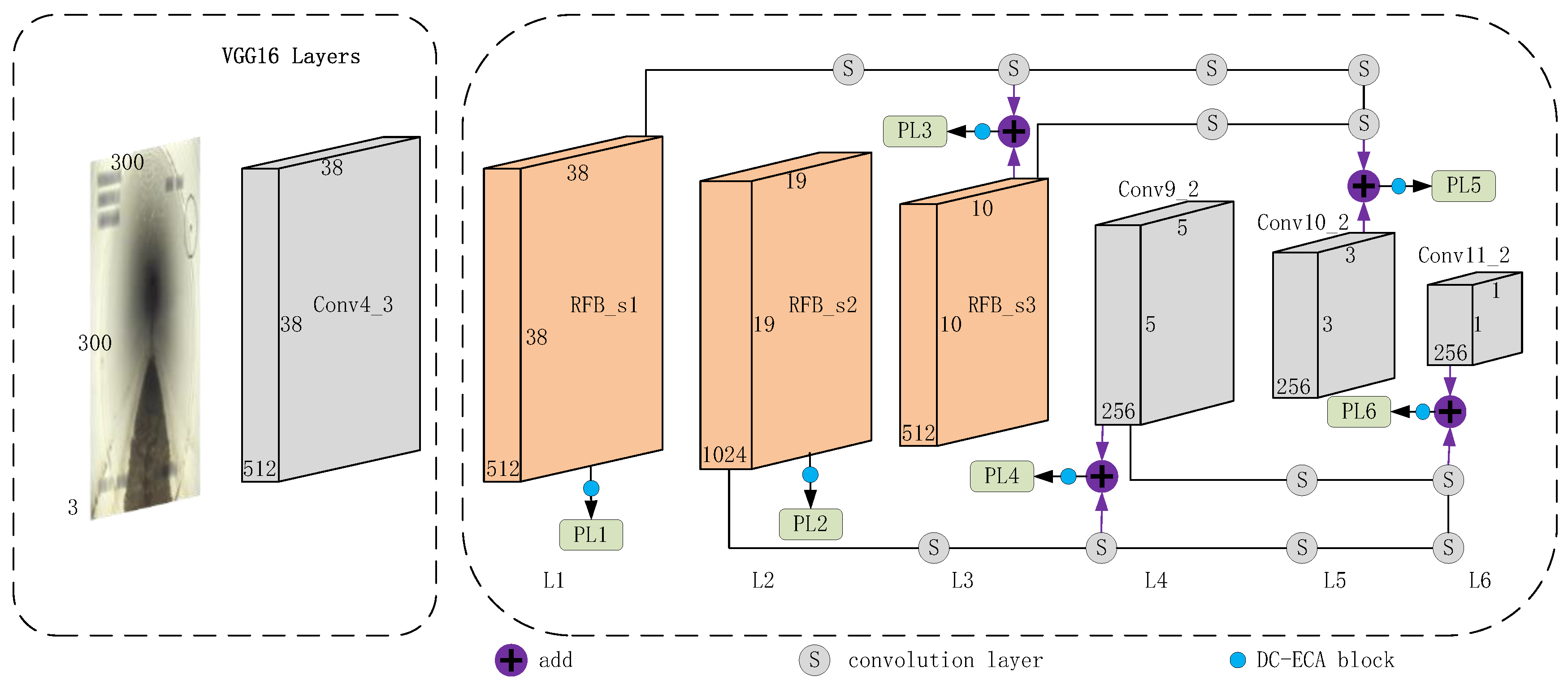
2. SSD
3. Materials and Methods
3.1. RFB Module
3.2. SDCM Module
3.3. Attentional Mechanism Module
- ①
- Perform global average pooling on the input feature map.
- ②
- Perform two fully-connected layers, with fewer neurons in the first layer and the same number of neurons as the input feature map in the second layer.
- ③
- After completing the two fully-connected layers, obtain the weights of each channel in the feature map through the sigmoid function.
- ④
- Multiply the obtained weight values with the original input feature map.
3.4. Focal Loss
4. Experiment and Results Analysis
4.1. Dataset Processing and Evaluation Metrics
4.2. Optimal Weight Coefficients
4.3. Comparative Experiment of Mainstream Detection Networks
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SSD | Single Shot MultiBox Detector |
| EFE-SSD | Enhanced Feature Extraction SSD |
| RFB | Receptive Field Block |
| ECA | Efficient Channel Attention |
| DC-ECA | Dual-Channel Efficient Channel Attention |
| CCTV | Closed-Circuit Television |
| Sewer-ML | A Multi-Label Sewer Defect Classification Dataset |
| YOLO | You Only Look Once |
| SDCM | A Dense Skip-Connected Module |
| AF | Settled Deposits |
| FS | Displaced Joint |
| DE | Deformation |
| RO | Roots |
| AP | Average Precision |
References
- Xiao, Q.; Wang, J.; Chen, H.; Ye, S.; Xiang, L. The detection and evaluation by CCTV and rehabilitation analysis of sewer pipeline in an area of Shenzhen City. Water Wastewater Eng. 2019, 45, 109–114. [Google Scholar]
- Gao, Y.; Wang, H.; Zhang, S.; Ma, L. Current research progress in combined sewer sediments and their models. China Water Wastewater 2010, 26, 15–27. [Google Scholar]
- Tan, H.; Lei, J.; Chen, Y.; Hao, J.; Liu, J.; Zhang, A.; Zhang, Y. Investigation and rectification strategy of drainage pipe network in a development zone. Cities Towns Constr. Guangxi 2009, 46, 71–73. [Google Scholar]
- Zhang, C. Strengthen the planning and construction management of urban drainage pipe networks and ensure their efficient and safe operation. Water Wastewater Eng. 2016, 52, 1–3. [Google Scholar]
- Kumar, S.S.; Abraham, D.M.; Jahanshahi, M.R.; Iseley, T.; Starr, J. Automated defect classification in sewer closed circuit television inspections using deep convolutional neural networks. Autom. Constr. 2018, 91, 273–283. [Google Scholar] [CrossRef]
- Li, S.A.; Li, T.; Wen, H.F.; Tao, H.Z. Analysis of CCTV detection results of drainage pipes in a city in South China. Urban Geotech. Investig. Surv. 2022, 5, 169–172+180. [Google Scholar]
- Cao, J.; Li, Y.; Sun, H.; Xie, J.; Huang, K.; Pang, Y. A survey on deep learning based visual object detection. J. Image Graph. 2022, 27, 1697–1722. [Google Scholar]
- Lü, B.; Liu, Y.; Ye, S.; Yan, Z. Convolutional-neural-network-based sewer defect detection in videos captured by CCTV. Bull. Surv. Mapp. 2019, 11, 103–108. [Google Scholar]
- Haurum, J.B.; Moeslund, T.B. Sewer-ML: A multi-label sewer defect classification dataset and benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13456–13467. [Google Scholar]
- Yin, X.; Chen, Y.; Bouferguene, A.; Zaman, H.; Al-Hussein, M.; Kurach, L. A deep learning-based framework for an automated defect detection system for sewer pipes. Autom. Constr. 2020, 109, 102967. [Google Scholar] [CrossRef]
- Ye, S.; Teng, Y.; Wang, Z. Research on Defect Detection of Drainage Pipeline Based on Gaussian YOLOv4. Software 2021, 42, 4. [Google Scholar]
- Li, D.; Xie, Q.; Yu, Z.; Wu, Q.; Zhou, J.; Wang, J. Sewer pipe defect detection via deep learning with local and global feature fusion. Autom. Constr. 2021, 129, 103823. [Google Scholar] [CrossRef]
- Wang, J.L.; Deng, Y.L.; Li, Y.; Zhang, X. A Review on Detection and Defect Identification of Drainage Pipeline. Sci. Technol. Eng. 2020, 33, 13520–13528. [Google Scholar]
- Cheng, J.C.; Wang, M. Automated detection of sewer pipe defects in closed-circuit television images using deep learning techniques. Autom. Constr. 2018, 95, 155–171. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Zhang, T.; Cheng, Y.; Al-Nabhan, N. Deep Learning for Object Detection: A Survey. Comput. Syst. Sci. Eng. 2021, 38, 165–182. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Zheng, P.; Bai, H.Y.; Li, W.; Guo, H.W. Small target detection algorithm in complex background. J. Zhejiang Univ. 2020, 54, 1–8. [Google Scholar]
- Cui, L.; Jiang, X.; Xu, M.; Li, W.; Lv, P.; Zhou, B. SDDNet: A fast and accurate network for surface defect detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Supplementary material for ‘ECA-Net: Efficient channel attention for deep convolutional neural networks’. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13–19. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| γ | mAP/% |
|---|---|
| 1 | 90.32 |
| 2 | 91.95 |
| 3 | 92.20 |
| 4 | 91.75 |
| 5 | 90.37 |
| Methods | Backbone | Input Size | AP/% | mAP/% | |||
|---|---|---|---|---|---|---|---|
| AF | DE | FS | RO | ||||
| Faster RCNN | Resnet50 | 600 × 600 | 94.66 | 82.07 | 85.32 | 85.94 | 87 |
| RetinaNet | Resnet50 | 600 × 600 | 97.33 | 85.42 | 89.67 | 85.81 | 89.56 |
| YOLO3 [28] | DarkNet | 416 × 416 | 90.64 | 54.11 | 81.07 | 72.19 | 74.5 |
| YOLO5X | CSPdarknet | 640 × 640 | 97.20 | 82.58 | 87.42 | 94.23 | 90.36 |
| CenterNet [29] | resnet50 | 512 × 512 | 90.75 | 42.64 | 60.02 | 74.58 | 67 |
| SSD | VGG16 | 300 × 300 | 95.65 | 85.07 | 92.10 | 86.96 | 89.94 |
| Gaussian YOLOv4 [11] | CSPdarknet | 416 × 416 | 93.24 | 57.47 | 80.94 | 77.56 | 77.3 |
| Qian Xie [12] | VGG16 | 300 × 300 | 96.47 | 82.11 | 88.09 | 74.54 | 85.3 |
| RFB Net | VGG16 | 300 × 300 | 98.41 | 87.37 | 91.40 | 86.78 | 90.1 |
| EFE-SSD | VGG16 | 300 × 300 | 96.00 | 89.43 | 84.87 | 88.46 | 92.2 |
| mAP/% | RFB_s | SDCM | Focal Loss |
|---|---|---|---|
| 89.94 | |||
| 90.74 | √ | ||
| 91.11 | √ | √ | |
| 92.20 | √ | √ | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, D.; Liu, X.; Shang, Y.; Tang, X. Deep Learning-Based Automatic Defect Detection Method for Sewer Pipelines. Sustainability 2023, 15, 9164. https://doi.org/10.3390/su15129164
Shen D, Liu X, Shang Y, Tang X. Deep Learning-Based Automatic Defect Detection Method for Sewer Pipelines. Sustainability. 2023; 15(12):9164. https://doi.org/10.3390/su15129164
Chicago/Turabian StyleShen, Dongming, Xiang Liu, Yanfeng Shang, and Xian Tang. 2023. "Deep Learning-Based Automatic Defect Detection Method for Sewer Pipelines" Sustainability 15, no. 12: 9164. https://doi.org/10.3390/su15129164