

E-Government 3.0: An AI Model to Use for Enhanced Local Democracies


Abstract
:1. Introduction
2. Literature Review
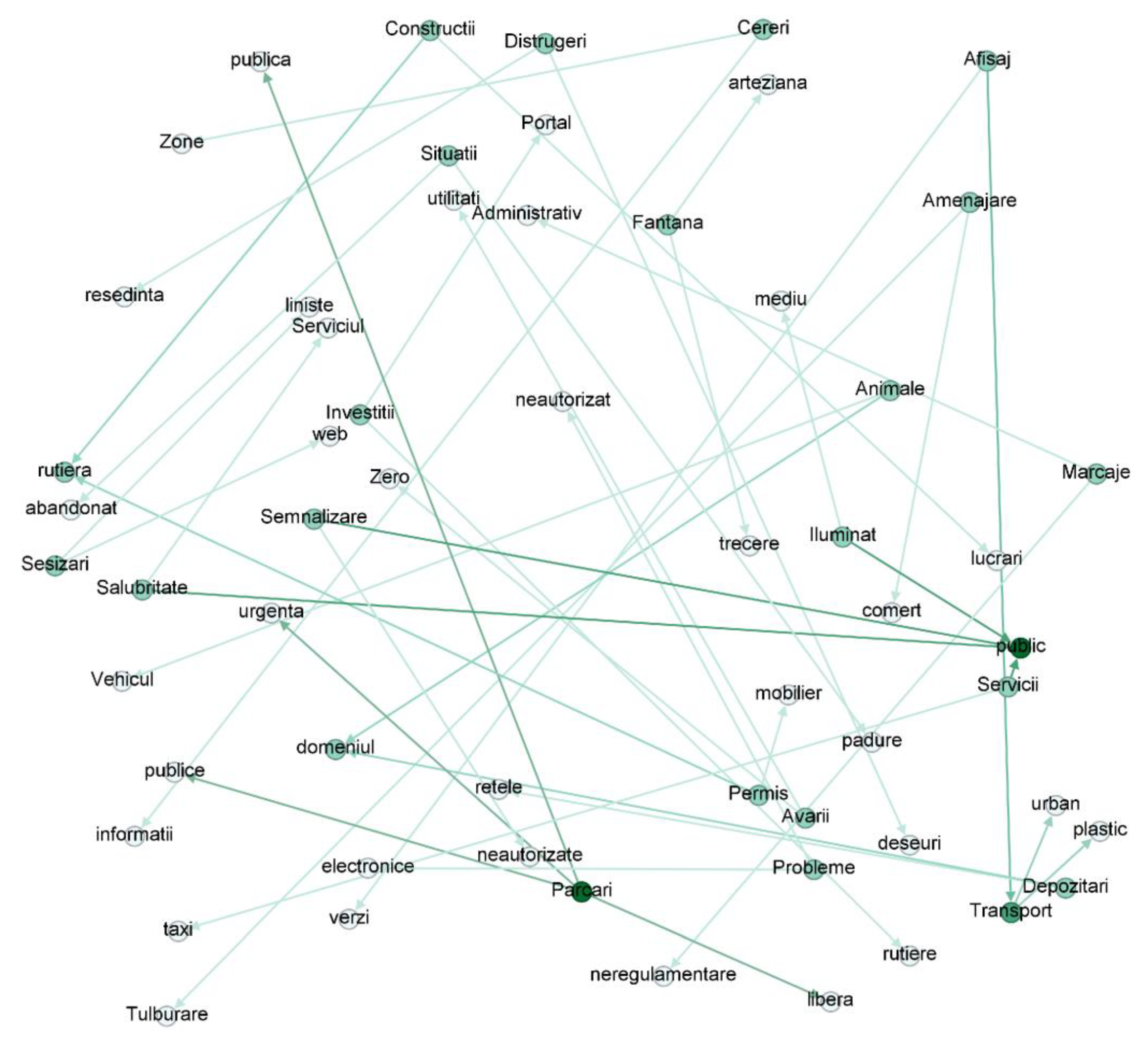
3. Materials and Methods
- Tokenization: Split text into individual words or tokens to allow for further processing;
- Removing punctuation;
- Spell correction;
- Removing URLs and HTML tags;
- Removing special characters;
- Removing emoticons;
- Removing offensive and bad words.
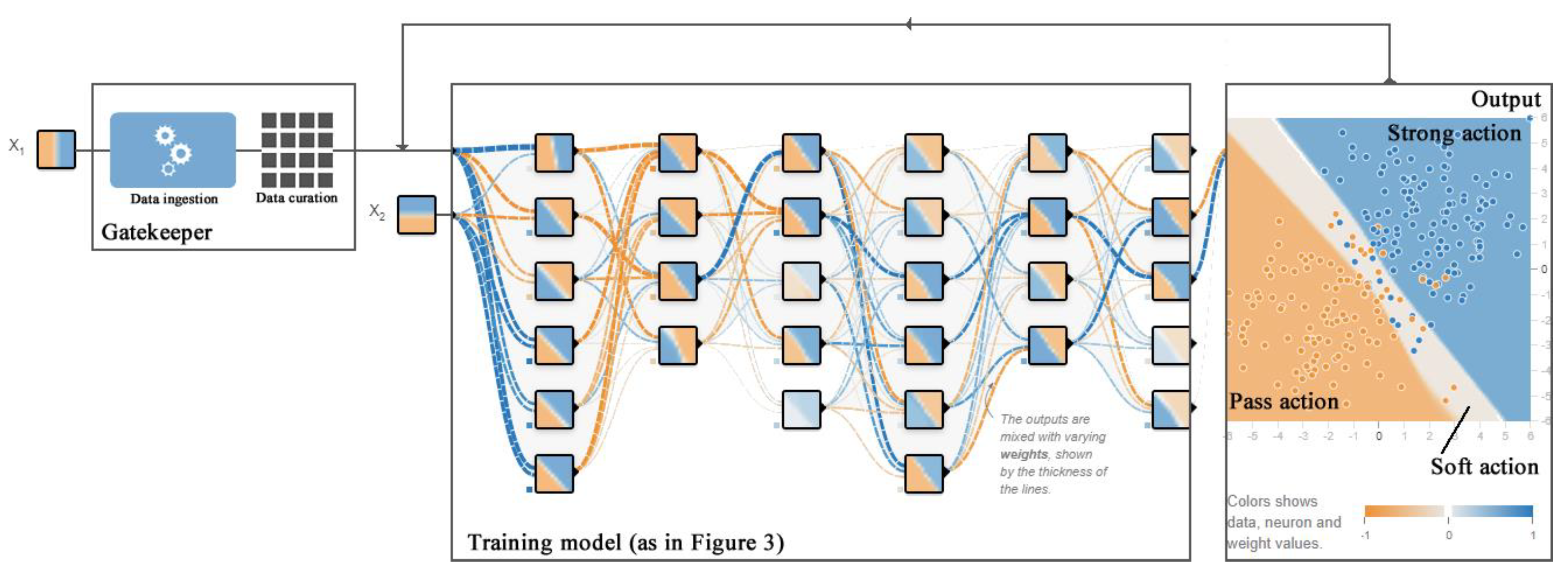
4. The AI Model Proposed
4.1. Related Works
4.2. Input Layer
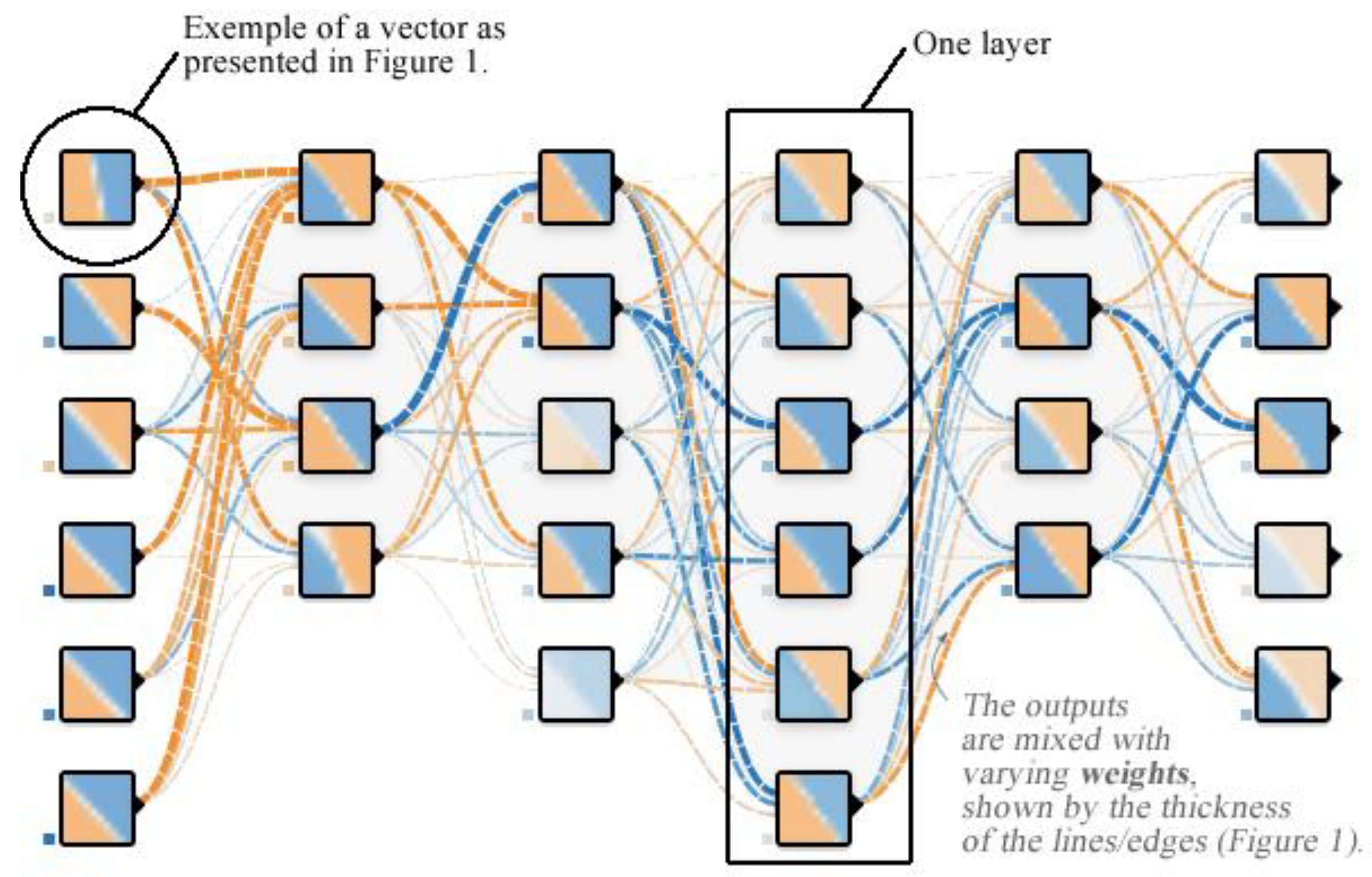
4.3. Hidden Layers
4.4. Training Model
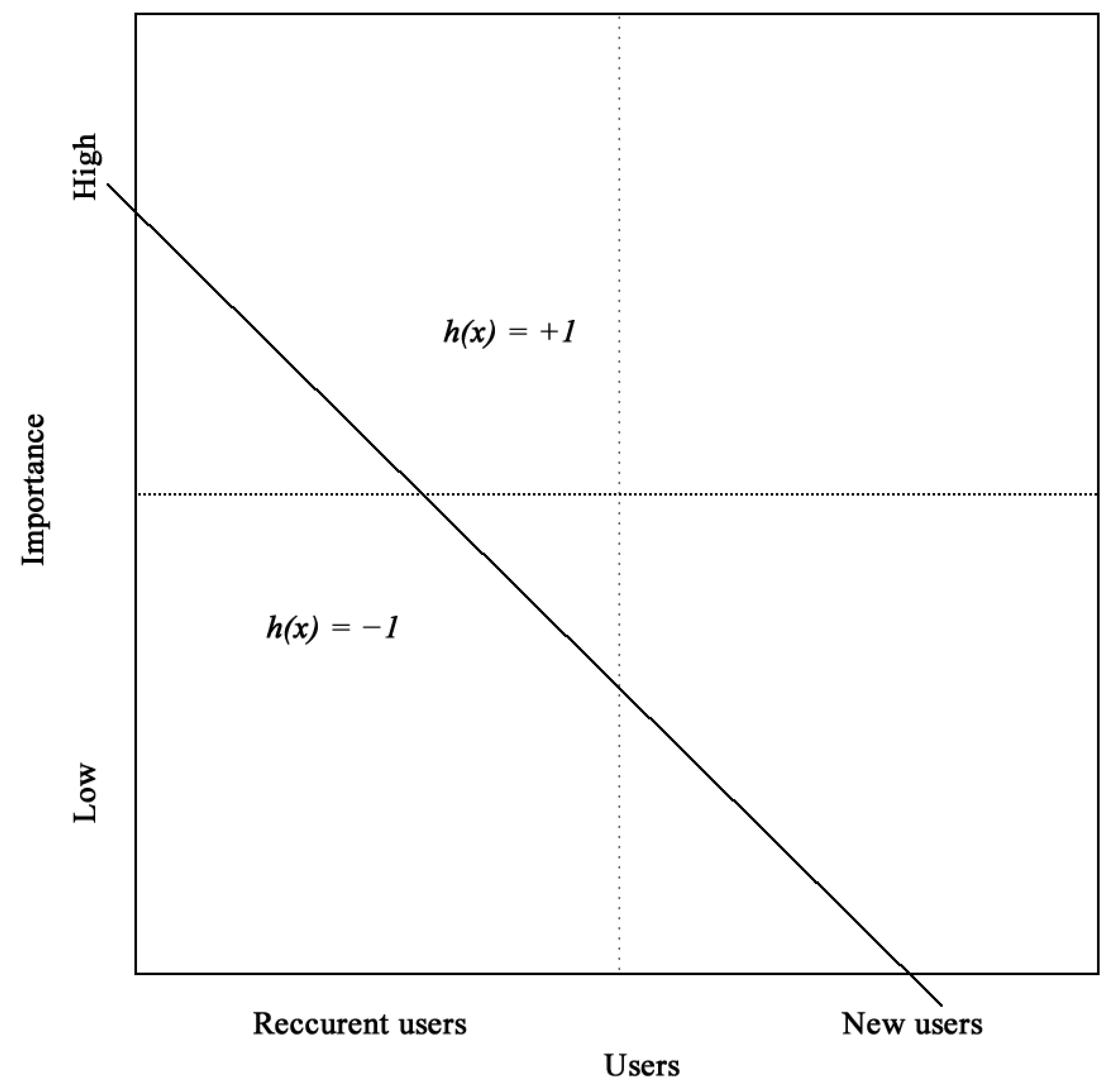
4.5. How to Increase Precision and Recall
4.6. Output Layer
- It takes a soft action–backlog, by sending the petition for human investigation while helping with extracting relevant information from the legislative framework in order to help the public servant in giving an accurate answer to the complaint;
- It takes strong action, acting on behalf of humans (independently), generating narratives, and giving all necessary information to the citizen. It could also actively engage in a dialog using more advanced NLP capabilities (such as newly released GPT-4 [73]) if necessary;
- Pass action. In this scenario, the AI system could respond in a gentle manner, using language and phrases intended to de-escalate any potential argument with a confrontational citizen.
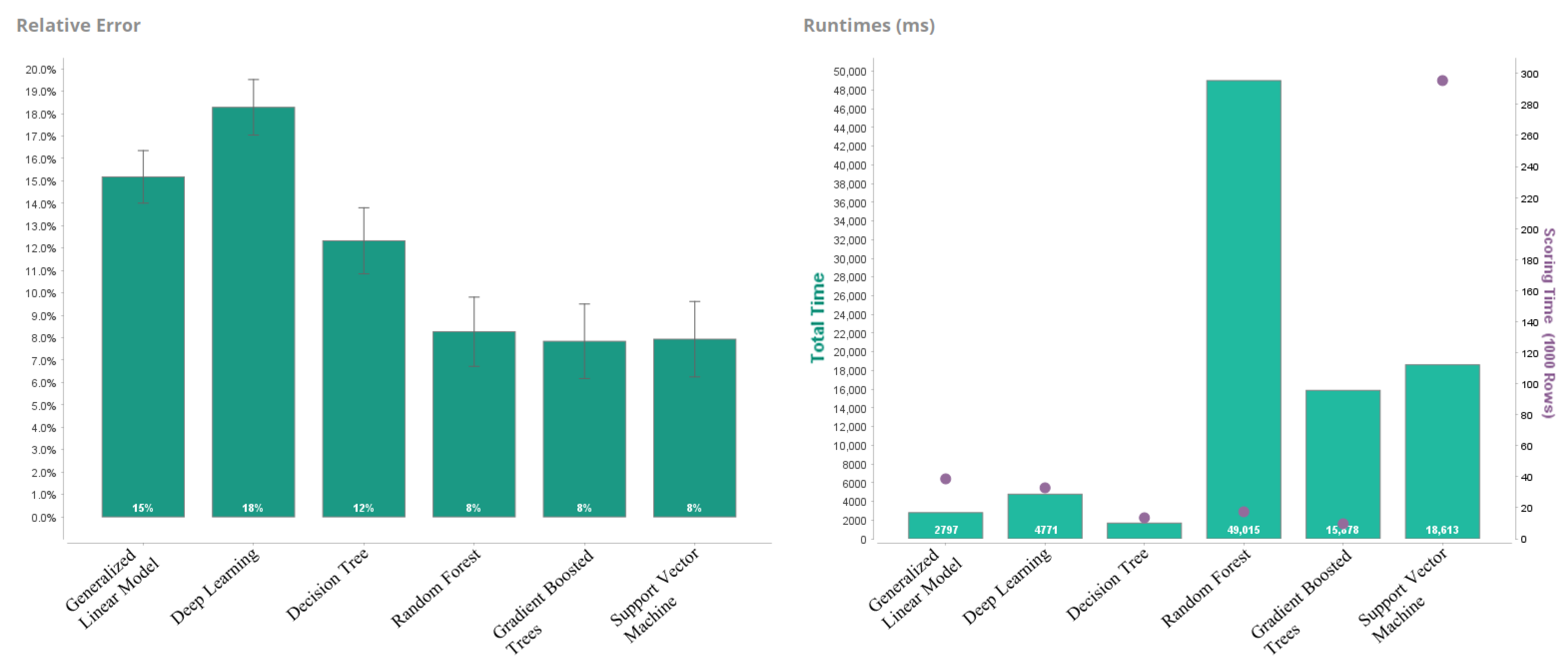
5. Results
- Is a particular word such as ‘thing’ present in the context? Detection;
- What type of thing is ‘thing’? Classification;
- How could ‘thing’ be grouped or ungrouped? Segmentation
6. Discussion
6.1. Limitation
6.2. Future Work
6.3. Theoretical, Practical, and Policy Implications
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Item | Active | Resolved | Total |
|---|---|---|---|---|
| 1 | Unauthorized display/trade | - | 34 | 34 |
| 2 | Road improvements | 244 | 1250 | 1494 |
| 3 | Animals in public domain | 2 | 58 | 60 |
| 4 | Damage to utility networks | 312 | 1653 | 1965 |
| 5 | Requests for information | 9 | 2520 | 2529 |
| 6 | Unauthorized construction/works | - | 160 | 160 |
| 7 | Waste disposal | 2 | 107 | 109 |
| 8 | Destruction of public domain | 6 | 58 | 64 |
| 9 | Fountain | - | 6 | 6 |
| 10 | Public lighting | 3 | 851 | 854 |
| 11 | Investments | 10 | 5 | 15 |
| 12 | Road markings | - | 18 | 18 |
| 13 | Illegal parking | 5 | 882 | 887 |
| 14 | Public/residential parking | 5 | 159 | 164 |
| 15 | Free passage permit | - | 16 | 16 |
| 16 | Environmental issues | - | 77 | 77 |
| 17 | Sanitation | 6 | 1443 | 1449 |
| 18 | Road signs | 2 | 970 | 972 |
| 19 | Electronic services/Web portal | 12 | 18 | 30 |
| 20 | Administrative Service Complaints | 9 | 4 | 13 |
| 21 | Emergency situations | - | 28 | 28 |
| 22 | Public transport | 43 | 142 | 185 |
| 23 | Taxi transport | - | 4 | 4 |
| 24 | Public disturbance | 2 | 356 | 358 |
| 25 | Abandoned vehicle | 1 | 318 | 319 |
| 26 | Zero plastic in green areas | - | 8 | 8 |
| 27 | Green areas/urban furniture | 12 | 1790 | 1802 |
| Total | 685 ** | 12,935 | 13,620 |
| ID | Item | Total |
|---|---|---|
| 1 | 968 | |
| 2 | Smartphone | 8074 |
| 3 | Instant message | 2 |
| 4 | Web platform | 1463 |
| 5 | Phone | 3113 |
| Total | 13,620 |
References
- Vrabie, C. Elemente de E-Guvernare [Elements of E-Government]; Pro Universitaria: Bucharest, Romania, 2016. [Google Scholar]
- Porumbescu, G.; Vrabie, C.; Ahn, J.; Im, T. Factors Influencing the Success of Participatory E-Government Applications in Romania and South Korea. Korean J. Policy Stud. 2012, 27, 2233347. [Google Scholar] [CrossRef] [Green Version]
- European Commission. eGovernment and Digital Public Services; European Commission: Brussels, Belgium, 2022; Available online: https://digital-strategy.ec.europa.eu/en/policies/egovernment (accessed on 23 April 2023).
- Vlahovic, N.; Vracic, T. An Overview of E-Government 3.0 Implementation; IGI Global: Hershey, PA, USA, 2015. [Google Scholar]
- Jun, C.N.; Chung, C.J. Big data analysis of local government 3.0: Focusing on Gyeongsangbuk-do in Korea. Technol. Forecast. Soc. Chang. 2016, 110, 3–12. [Google Scholar] [CrossRef]
- Terzi, S.; Votis, K.; Tzovaras, D.; Stamelos, I.; Cooper, K. Blockchain 3.0 Smart Contracts in E-Government 3.0 Applications. arXiv 2019, arXiv:1910.06092. [Google Scholar]
- European Commission. Public Administration and Governance in the EU; European Commission: Brussels, Belgium, 2023; Available online: https://reform-support.ec.europa.eu/system/files/2023-01/DG%20REFORM%20Newsletter02_january2023.pdf (accessed on 23 April 2023).
- Twizeyimana, J.D.; Andersson, A. The public value of E-Government—A literature review. Gov. Inf. Q. 2019, 36, 167–178. [Google Scholar] [CrossRef]
- Vrabie, C. Digital Governance (in Romanian Municipalities). A Longitudinal Assessment of Municipal Web Sites in Romania. Eur. Integr. Realities Perspect. 2011, 906–926. [Google Scholar] [CrossRef]
- Invest Brasov. Brașov–Best Smart City Project Award, Invest Brasov. Available online: https://investbrasov.org/2022/04/24/cum-influenteaza-schimbarea-mediului-de-lucru-productivitatea%EF%BF%BC/ (accessed on 21 March 2023).
- SCIA. Campionii Industriei Smart City, Romanian Association for Smart Cities, 1 April 2022. Available online: https://scia.ro/campionii-industriei-smart-city-editia-6/ (accessed on 21 March 2023).
- Vrabie, C. Artificial Intelligence Promises to Public Organizations and Smart Cities. In Digital Transformation; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 3–14. [Google Scholar]
- Vrabie, C. Digital Governance (in Romanian Municipalities) and Its Relation with the IT Education–A Longitudinal Assessment of Municipal Web Sites in Romania. In Public Administration in Times of Crisis; NISPAcee PRESS: City Warsaw, Poland, 2011; pp. 237–269. [Google Scholar]
- Hashem, I.; Usmani, R.; Almutairi, M.; Ibrahim, A.; Zakari, A.; Alotaibi, F.; Alhashmi, S.; Chiroma, H. Urban Computing for Sustainable Smart Cities: Recent Advances, Taxonomy, and Open Research Challenges. Sustainability 2023, 15, 3916. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, Y.; Iftikhar, H.; Ullah, A.; Mao, J.; Wang, T. Dynamic Influence of Digital and Technological Advancement on Sustainable Economic Growth in Belt and Road Initiative (BRI) Countries. Sustainability 2022, 14, 15782. [Google Scholar] [CrossRef]
- Bonnell, C. In Business We Trust. In People Trust Businesses More Than Governments, Nonprofits, Media: Survey; Associated Press: New York City, NY, USA, 2023; Available online: https://eu.usatoday.com/story/money/2023/01/16/trust-business-more-than-government-nonprofits-media-survey/11062453002/ (accessed on 23 April 2023).
- Vangelov, N. Ambient Advertising in Metaverse Smart Cities. SCRD J. 2023, 7, 43–55. [Google Scholar]
- Iancu, D.C.; Ungureanu, M. Depoliticizing the Civil Service: A critical review of the public administration reform in Romania. Res. Soc. Chang. 2010, 2, 63–106. [Google Scholar]
- Vrabie, C. Informing citizens, building trust and promoting discussion. Glob. J. Sociol. 2016, 6, 34–43. [Google Scholar] [CrossRef]
- Iancu, D.C. European compliance and politicization of public administration in Romania. Innov. Issues Approaches Soc. Sci. 2013, 6, 103–117. [Google Scholar]
- Hamrouni, B.; Bourouis, A.; Korichi, A.; Brahmi, M. Explainable Ontology-Based Intelligent Decision Support System for Business Model Design and Sustainability. Sustainability 2021, 13, 9819. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Ahn, M.; Wang, Y.-F. Artificial Intelligence and Public Values: Value Impacts and Governance in the Public Sector. Sustainability 2023, 15, 4796. [Google Scholar] [CrossRef]
- Noordt, C.V.; Misuraca, G. Artificial intelligence for the public sector: Results of landscaping the use of AI in government across the European Union. Gov. Inf. Q. 2022, 39, 101714. [Google Scholar] [CrossRef]
- Reis, J.; Santo, P.E.; Melão, N. Artificial Intelligence in Government Services: A systematic literature review. Springer Nat. 2019, 1, 241–252. [Google Scholar]
- Thakhathi, V.G.; Langa, R.D. The role of smart cities to promote smart governance in municipalities. SCRD J. 2022, 6, 9–22. [Google Scholar]
- KPMG. Manage the Effects of Robotic Process Automation to Enable a Future-Proof Workforce; KPMG Advisory: Amstelveen, The Netherlands, 2019. [Google Scholar]
- Sánchez, J.; Rodríguez, J.; Espitia, H. Review of Artificial Intelligence Applied in Decision-Making Processes in Agricultural Public Policy. Processes 2020, 8, 1374. [Google Scholar] [CrossRef]
- Schachtner, C. Smart government in local adoption—Authorities in strategic change through AI. SCRD J. 2021, 5, 53–62. [Google Scholar]
- Etscheid, J. Artificial Intelligence in Public Administration. In Electronic Government. EGOV 2019. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Kolkman, D. The usefulness of algorithmic models in policy making. Gov. Inf. Q. 2020, 37, 101488. [Google Scholar] [CrossRef]
- Ibtissem, M.; Mohsen, B.; Jaleleddine, B. Quantitative relationship between corruption and development of the Tunisian stock market. Public Munic. Financ. 2018, 7, 39–47. [Google Scholar]
- Munshi, A.; Mehra, A.; Choudhury, A. LexRank Algorithm: Application in Emails and Comparative Analysis. Int. J. New Technol. Res. (IJNTR) 2021, 7, 34–38. [Google Scholar] [CrossRef]
- Zalwert, M. LexRank Algorithm Explained: A Step-by-Step Tutorial with Examples, 5 May 2021. Available online: https://maciejzalwert.medium.com/lexrank-algorithm-explained-a-step-by-step-tutorial-with-examples-3d3aa0297c57 (accessed on 25 March 2023).
- Scholl, H.J. Manuel Pedro Rodríguez Bolívar, Regulation as both enabler of technology use and global competitive tool: The Gibraltar case. Gov. Inf. Q. 2019, 36, 601–613. [Google Scholar] [CrossRef]
- Vrabie, C.; Dumitrascu, E. Smart Cities: De la Idee la Implementare, Sau, Despre cum Tehnologia Poate da Strălucire Mediului Urban; Universul Academic: Bucharest, Romania, 2018. [Google Scholar]
- Timan, T.; Veenstra, A.F.V.; Bodea, G. ArtificiaI Intelligence and Public Services; European Parliament: Strasbourg, France, 2021. [Google Scholar]
- Wu, H.; Wang, Z.; Qing, F.; Li, S. Reinforced Transformer with Cross-Lingual Distillation for Cross-Lingual Aspect Sentiment Classification. Electronics 2021, 10, 270. [Google Scholar] [CrossRef]
- Mehr, H. Artificial Intelligence for Citizen Services and Government; Harvard Ash Center: Cambridge, MA, USA, 2017; Available online: https://ash.harvard.edu/files/ash/files/artificial_intelligence_for_citizen_services.pdf (accessed on 18 March 2023).
- Reshi, A.; Rustam, F.; Aljedaani, W.; Shafi, S.; Alhossan, A.; Alrabiah, Z.; Ahmad, A.; Alsuwailem, H.; Almangour, T.; Alshammari, M.; et al. COVID-19 Vaccination-Related Sentiments Analysis: A Case Study Using Worldwide Twitter Dataset. Healthcare 2022, 10, 411. [Google Scholar] [CrossRef]
- Alabrah, A.; Alawadh, H.; Okon, O.; Meraj, T.; Rauf, H. Gulf Countries’ Citizens’ Acceptance of COVID-19 Vaccines—A Machine Learning Approach. Mathematics 2022, 10, 467. [Google Scholar] [CrossRef]
- Zschirnt, S. Justice for All in the Americas? A Quantitative Analysis of Admissibility Decisions in the Inter-American Human Rights System. Laws 2021, 10, 56. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative Sources in a Hyperlinked Environment. J. ACM 1999, 46, 604–632. [Google Scholar] [CrossRef] [Green Version]
- Hreňo, J.; Bednár, P.; Furdík, K.; Sabol, T. Integration of Government Services using Semantic Technologies. J. Theor. Appl. Electron. Commer. Res. 2011, 6, 143–154. [Google Scholar] [CrossRef] [Green Version]
- Piaggesi, D. Hyper Connectivity as a Tool for the Development of the Majority. Int. J. Hyperconnect. Internet Things 2021, 5, 63–77. [Google Scholar] [CrossRef]
- Verma, S. Sentiment analysis of public services for smart society: Literature review and future research directions. Gov. Inf. Q. 2022, 39, 101708. [Google Scholar] [CrossRef]
- Chui, M.; Harrysson, M.; Manyika, J.; Roberts, R.; Chung, R.; Nel, P.; Heteren, A.V. Applying Artificial Intelligence for Social Good; McKinsey Global Institute: New York City, NY, USA, 2018; Available online: https://www.mckinsey.com/featured-insights/artificial-intelligence/applying-artificial-intelligence-for-social-good (accessed on 9 April 2023).
- Rohit Madan, M.A. AI adoption and diffusion in public administration: A systematic literature review and future research agenda. Gov. Inf. Q. 2023, 40, 101774. [Google Scholar] [CrossRef]
- Ahn, M.J.; Chen, Y.-C. Digital transformation toward AI-augmented public administration: The perception of government employees and the willingness to use AI in government. Gov. Inf. Q. 2022, 39, 101664. [Google Scholar] [CrossRef]
- Kumari, S.; Agarwal, B.; Mittal, M. A Deep Neural Network Model for Cross-Domain Sentiment Analysis. Int. J. Inf. Syst. Model. Des. 2021, 12, 1–16. [Google Scholar] [CrossRef]
- Lu, Z.; Hu, X.; Xue, Y. Dual-Word Embedding Model Considering Syntactic Information for Cross-Domain Sentiment Classification. Mathematics 2022, 10, 4704. [Google Scholar] [CrossRef]
- Yu, H.; Lu, G.; Cai, Q.; Xue, Y. A KGE Based Knowledge Enhancing Method for Aspect-Level Sentiment Classification. Mathematics 2022, 10, 3908. [Google Scholar] [CrossRef]
- Eom, S.J.; Lee, J. Digital government transformation in turbulent times: Responses, challenges, and future direction. Gov. Inf. Q. 2022, 39, 101690. [Google Scholar] [CrossRef]
- Zankova, B. Smart societies, gender and the 2030 spotlight—Are we prepared. SCRD J. 2021, 5, 63–76. [Google Scholar]
- Chui, M.; Roberts, R.; Yee, L. Generative AI is Here: How Tools Like ChatGPT Could Change Your Business; McKinsey & Company: Atlanta, GA, USA, 2022; Available online: https://www.mckinsey.com/capabilities/quantumblack/our-insights/generative-ai-is-here-how-tools-like-chatgpt-could-change-your-business (accessed on 9 April 2023).
- Ng, A. AI is the New Electricity; O’Reilly Media: Sebastopol, CA, USA, 2018. [Google Scholar]
- Google. Google Colaboratory. Available online: https://colab.research.google.com/#scrollTo=-gE-Ez1qtyIA (accessed on 25 February 2023).
- Google Research. BERT. 2020. Available online: https://github.com/google-research/bert, (accessed on 25 February 2023).
- Silipo, R.; Melcher, K. Text Encoding: A Review; Towards Data Science: Toronto, ON, Canada, 2019; Available online: https://towardsdatascience.com/text-encoding-a-review-7c929514cccf#:~:text=Index%2DBased%20Encoding,that%20maps%20words%20to%20indexes (accessed on 8 April 2023).
- Kameni, J.; Flambeau, F.; Tsopze, N.; Tchuente, M. Explainable Deep Neural Network for Skills Prediction from Resumes, December 2021. Available online: https://www.researchgate.net/publication/357375852_Explainable_Deep_Neural_Network_for_Skills_Prediction_from_Resumes?channel=doi&linkId=61cb04a1b8305f7c4b074a9b&showFulltext=true (accessed on 8 April 2023).
- DreamQuark. TabNet: Attentive Interpretable Tabular Learning. arXiv 2019, arXiv:1908.07442. [Google Scholar]
- Tensor Flow, Deep Playground, Tensor Flow. Available online: https://github.com/tensorflow/playground (accessed on 19 March 2023).
- Brynjolfsson, E.; McAfee, A. The business of artificial intelligence. Harv. Bus. Rev. 2017, 95, 53–62. [Google Scholar]
- Davenport, T.H.; Ronanki, R. Artificial intelligence for the real world. Harv. Bus. Rev. 2018, 96, 108–116. [Google Scholar]
- Schrage, M. The key to winning with AI: Improve your workflow—Not your algorithm. MIT Sloan Manag. Rev. 2018, 59, 1–9. [Google Scholar]
- Vrabie, C. Smart-EDU Hub. In Proceedings of the ‘Accelerating innovation’ Smart Cities International Conference (SCIC), 10th ed. Bucharest, Romania, 8–9 December 2022; Smart Cities and Regional Development (SCRD) Open Access: Bucharest, Romania, 2022. Available online: https://www.smart-edu-hub.eu/about-scic10/conference-program10 (accessed on 18 March 2023).
- OpenAI. Introducing ChatGPT.; OpenAI: San Francisco, CA, USA, 2022; Available online: https://openai.com/blog/chatgpt (accessed on 18 March 2023).
- Sutskever, I. Fireside Chat with Ilya Sutskever and Jensen Huang: AI Today and Vision of the Future; Stanford University: San Francisco, CA, USA, 2023. [Google Scholar]
- Akyürek, E.; Schuurmans, D.; Andreas, J.; Ma, T.; Zhou, D. What learning algorithm is in-context learning? Investigations with linear models. arXiv 2022, arXiv:2211.15661. [Google Scholar]
- Flender, S. Deploying Your Machine Learning Model Is Just the Beginning; Towards Data Science: Toronto, ON, Canada, 2022; Available online: https://towardsdatascience.com/deploying-your-machine-learning-model-is-just-the-beginning-b4851e665b11 (accessed on 19 March 2023).
- Alcott, B. Jevons’ paradox. Ecol. Econ. 2005, 54, 9–21. [Google Scholar] [CrossRef]
- Sorrell, S. Jevons’ Paradox revisited: The evidence for backfire from improved energy efficiency. Energy Policy 2009, 37, 1456–1469. [Google Scholar] [CrossRef]
- Fich, L.; Viola, S.; Bentsen, N. Jevons Paradox: Sustainable Development Goals and Energy Rebound in Complex Economic Systems. Energies 2022, 15, 5821. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Is OpenAI’s Most Advanced System, Producing Safer and More Useful Responses; OpenAI: San Francisco, CA, USA, 2023; Available online: https://openai.com/product/gpt-4 (accessed on 23 April 2023).
- Barnhart, B. The Importance of Social Media Sentiment Analysis (and How to Conduct It); Sprout Social: Chicago, IL, USA, 2019; Available online: https://sproutsocial.com/insights/social-media-sentiment-analysis/ (accessed on 6 May 2022).
- Dabhade, V. Conducting Social Media Sentiment Analysis: A Working Example; Express Analytics: Irvine, CA, USA, 2021; Available online: https://www.expressanalytics.com/blog/social-media-sentiment-analysis/ (accessed on 6 May 2022).
- LeaveBoard. Zile Lucrătoare 2022, LeaveBoard. Available online: https://leaveboard.com/ro/zile-lucratoare-2022/ (accessed on 22 March 2023).
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial Examples Are Not Bugs, They Are Features. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Neagu, D.; Rus, A.; Grec, M.; Boroianu, M.; Bogdan, N.; Gal, A. Towards Sentiment Analysis for Romanian Twitter Content. Algorithms 2022, 15, 357. [Google Scholar] [CrossRef]
- Cioban, Ș. Cross-Domain Sentiment Analysis of the Natural Romanian Language. In Digital Economy. Emerging Technologies and Business Innovation; Springer Link: Berlin/Heidelberg, Germany, 2021; pp. 172–180. [Google Scholar]
- Keras. ResNet and ResNetV2, Keras. Available online: https://keras.io/api/applications/resnet/#resnet50-function (accessed on 8 April 2023).
- Sazzed, S.; Jayarathna, S. SSentiA: A Self-supervised Sentiment Analyzer for classification from unlabeled data. Mach. Learn. Appl. 2021, 4, 100026. [Google Scholar] [CrossRef]






| ID | Item | Value | Observations/Details |
|---|---|---|---|
| I1 | Gender * | 0/1/2 | 0—not known/1—man/2—women |
| I2 | Age group ** | 0 to 6 | 0—not known/6 > 70 |
| I3 | If it is on behalf of a company/firm | 0/1 | 0—ns/1—no/2—yes |
| I41 | Geographical 1 *** | 0 to 88 | divided in 8 major subgroups, each redivided into another 8 subgroups (0 for undisclosed) |
| I42 | Geographical 2 | 0/1/2 | 0—ns/1—the sender is living in a block of apartments/ 2—in a house (with land/garden) |
| I5 | Type of petition | 0/1/2/3/4/5 | 0—ns/1—demand/2—complain/ 3—referral/4—audience/5—proposal |
| I6 | Attachment | 0/1 | no/yes |
| I7 | Subject of petition | 0 to 9 | based on the words written in the Subject field (different from I3); 0 for ns |
| I81 | Active **** | 0/1/2 | 0—first/1—second/2—multiple |
| I82 | Active on official social media page | 0/1/2 | 0—first/1—second/2—multiple |
| I91 | Content 1 | 0/1 | if it refers to a neighbor/s (as a specific person/s) |
| I92 | 0/1 | if it refers to the neighborhood | |
| I101 | Content 2 | 0/1/2 | 0—no/1—if is regarding parking (in connection with I81)/2—if it regards parking (in connection with I82) |
| I102 | 0/1 | if it regards public utilities (in connection with the I82) | |
| I11 | Content 3 | 0/1 | 0—no/1—the content refers to the sender’s own facilities (in connection with I32) |
| I12 | […] ***** | […] | […] |
| I1 | I2 | I3 | I4 * | I5 | I6 | I7 | I8 * | I9 * | I10 * | I11 | I12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I1 | 1.0000 | −0.0955 | 0.0354 | 0.0838 | −0.0127 | 0.1109 | 0.0129 | −0.0492 | 0.4208 | 0.3429 | 0.4265 | […] |
| I2 | −0.0955 | 1.0000 | 0.0697 | −0.3778 | −0.2118 | −0.0464 | −0.0506 | 0.0533 | −0.0357 | −0.1504 | −0.0788 | […] |
| I3 | 0.0354 | 0.0697 | 1.0000 | −0.0231 | −0.0205 | −0.0147 | −0.0167 | −0.0876 | 0.0235 | 0.0896 | 0.0111 | […] |
| I4 * | 0.0838 | −0.3778 | −0.0231 | 1.0000 | 0.1147 | 0.0146 | 0.0097 | 0.0130 | 0.0466 | 0.0844 | −0.0051 | […] |
| I5 | −0.0127 | −0.2118 | −0.0205 | 0.1147 | 1.0000 | −0.0443 | 0.0345 | −0.0245 | −0.0287 | 0.0512 | 0.0208 | […] |
| I6 | 0.1109 | −0.0464 | −0.0147 | 0.0146 | −0.0443 | 1.0000 | −0.0062 | −0.0025 | 0.1103 | 0.1226 | 0.1061 | […] |
| I7 | 0.0129 | −0.0506 | −0.0167 | 0.0097 | 0.0345 | −0.0062 | 1.0000 | −0.0803 | 0.0919 | −0.0316 | 0.0499 | […] |
| I8 * | −0.0492 | 0.0533 | −0.0876 | 0.0130 | −0.0245 | −0.0025 | −0.0803 | 1.0000 | −0.0220 | −0.0073 | −0.0710 | […] |
| I9 * | 0.4208 | −0.0357 | 0.0235 | 0.0466 | −0.0287 | 0.1103 | 0.0919 | −0.0220 | 1.0000 | 0.2737 | 0.4082 | […] |
| I10 * | 0.3429 | −0.1504 | 0.0896 | 0.0844 | 0.0512 | 0.1226 | −0.0316 | −0.0073 | 0.2737 | 1.0000 | 0.2322 | […] |
| I11 | 0.4265 | −0.0788 | 0.0111 | −0.0051 | 0.0208 | 0.1061 | 0.0499 | −0.0710 | 0.4082 | 0.2322 | 1.0000 | […] |
| I12 | […] | […] | […] | […] | […] | […] | […] | […] | […] | […] | […] | 1.0000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vrabie, C. E-Government 3.0: An AI Model to Use for Enhanced Local Democracies. Sustainability 2023, 15, 9572. https://doi.org/10.3390/su15129572
Vrabie C. E-Government 3.0: An AI Model to Use for Enhanced Local Democracies. Sustainability. 2023; 15(12):9572. https://doi.org/10.3390/su15129572
Chicago/Turabian StyleVrabie, Catalin. 2023. "E-Government 3.0: An AI Model to Use for Enhanced Local Democracies" Sustainability 15, no. 12: 9572. https://doi.org/10.3390/su15129572
APA StyleVrabie, C. (2023). E-Government 3.0: An AI Model to Use for Enhanced Local Democracies. Sustainability, 15(12), 9572. https://doi.org/10.3390/su15129572