
A New Combined Prediction Model for Ultra-Short-Term Wind Power Based on Variational Mode Decomposition and Gradient Boosting Regression Tree



Abstract
:1. Introduction
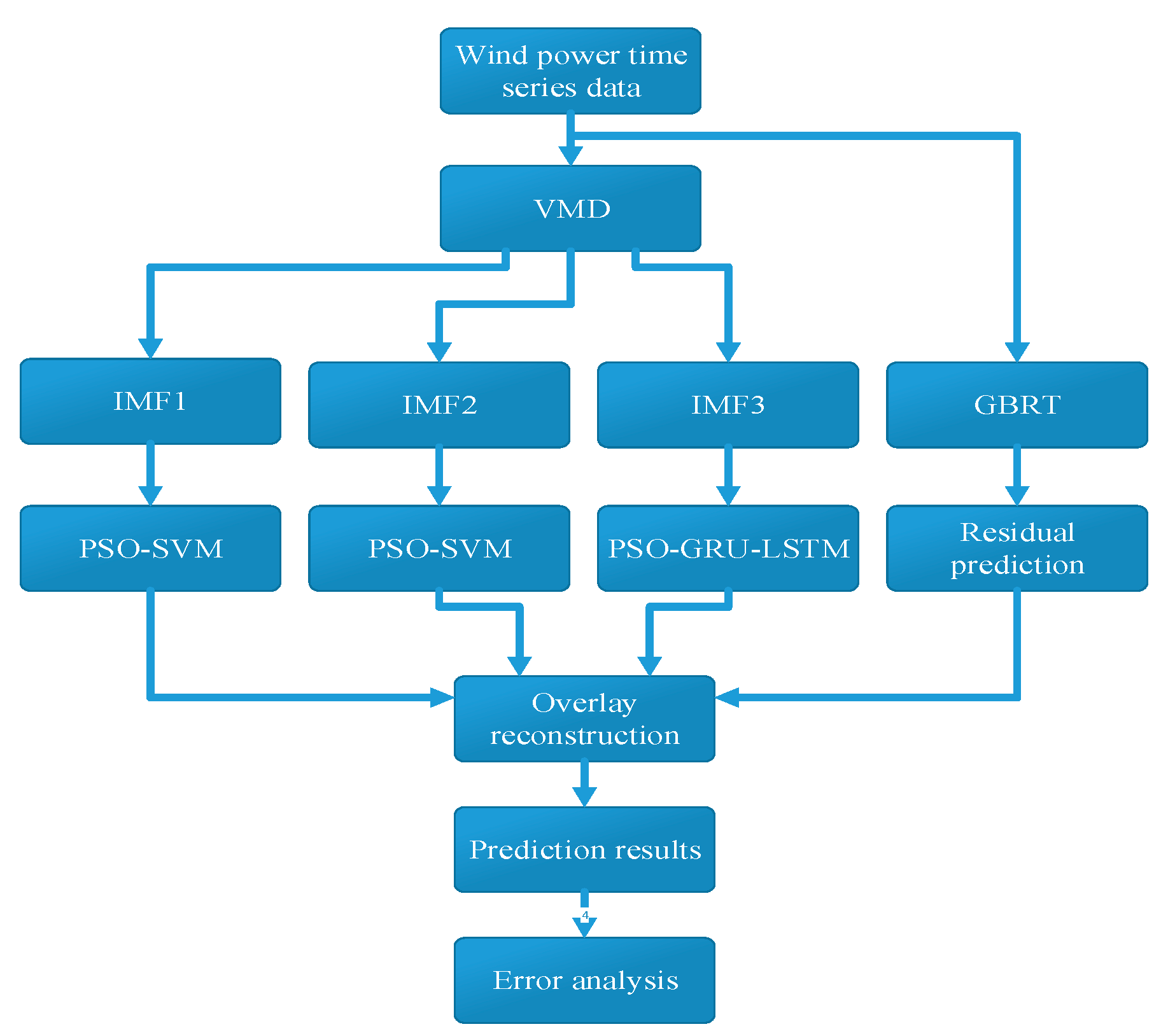
2. Overall Framework of the Prediction Model
2.1. Variational Mode Decomposition
- Initialize the Lagrange multipliers, sets of modal functions, and instantaneous frequencies as , and , where n = 0.
- Let n = n + 1 and enter the iterative loop.
- Update the yk, ωk and λ according to Equations (3)–(5).
- Set a threshold ε and evaluate the condition given by Equation (6). If the computed result is smaller than ε, satisfying the condition in Equation (6), stop the iteration. Otherwise, continue the iteration.
2.2. PSO Module
2.3. PSO-SVM Module
2.4. PSO-GRU-LSTM Module
2.5. GBRT Module
- Initialization of regression trees:
- Calculating the negative gradient of the loss function:
- 3
- Calculating the step size for the gradient descent:
- 4
- Updating the regression tree:
3. Experimental Results Analysis
3.1. Basic Data
3.2. VMD Result Analysis
3.3. Comparative Analysis of Various Models Based on VMD
3.4. Experimental Results and Analysis
4. Conclusions
- The models utilizing VMD consistently outperform the models without it. For example, Model 2 exhibits a lower MSE by 0.0115, a lower MAE by 0.0029, and a higher R2 by 0.0084 compared to PSO-GRU-LSTM. This demonstrates that VMD improves the predictive performance of the models.
- PSO-GRU-LSTM outperforms PSO-LSTM, with a lower MSE by 0.0093, a lower MAE by 0.0251, and a higher R2 by 0.0068. This indicates that the combination of GRU-LSTM performs better in prediction accuracy than LSTM alone.
- The combination in Model 3 outperforms the combination in Model 2, with a lower MSE by 0.0345, a lower MAE by 0.0726, and a higher R2 by 0.0252. Compared to Model 1, Model 3 exhibits a lower MSE by 0.0038, a lower MAE by 0.0152, and a higher R2 by 0.0028. This is because SVM exhibits a good fitting capability for the long-term and short-term components, while the GRU-LSTM combination effectively captures the stochastic component.
- Model 4 shows an improvement over Model 3, with a lower MSE by 0.0042, a lower MAE by 0.022, and a higher R2 by 0.003. This demonstrates that predicting the overall residuals using GBRT further enhances the prediction accuracy.
- Although the proposed ultra-short-term wind power prediction model in this study improves the accuracy of wind power forecasting, there are still areas for further improvement. For example, the occasional occurrence of PSO algorithm being trapped in local optima and the slightly lower prediction accuracy of a large-scale wind power plant compared to that of a small-scale wind power plant.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| Abbreviations | |
| ADMM | Alternate direction method of multipliers |
| ARIMA | Autoregressive integrated moving average model |
| BCD | Bayesian dynamic clustering |
| BP | Back propagation |
| CNN | Convolutional neural network |
| DLSTM | Deep long-term memory |
| EMD | Empirical mode decomposition |
| EMEMA | Enhanced multi-objective exchange market algorithm |
| GBRT | Gradient boosting regression tree |
| GRU | Gated recurrent unit |
| IMFs | Intrinsic mode functions |
| ISSO | Improved simplified swarm optimization |
| LSSVM | Least square support vector machine |
| LSTM | Long short-term memory |
| MAE | Mean absolute error |
| MLP | Multi-layer perceptron |
| MSE | Mean squared error |
| NN | Neural network |
| PSO | Particle swarm optimization |
| RBF | Radial basis function |
| S-G | Savitzky–Golay |
| SVM | Support vector machine |
| SVR | Support vector regression |
| VMD | Variational mode decomposition |
| Symbols | |
| R2 | The coefficient of determination |
| n | Number of iterations |
| ε | Threshold |
| γ | A tunable parameter in the Gaussian kernel function |
| C | Penalty coefficient |
| Yi | The actual values |
| Ŷi | The predicted values |
| The mean of the observed values | |
| m | The number of trees |
| xi | The input samples |
| yi | The expected value |
| N | The sample sizes |
| Li | Lagrange multiplier of the i-th sample |
| vid | The particle velocity |
| xid | The particle positions |
| d | The spatial dimension |
| i | The population sizes |
| u | inertia weight |
| c1, c2 | The acceleration factors that enable particles to have self-awareness and learn from other individuals |
| r1, r2 | Random numbers between 0 and 1 |
| , | The individual and global best values |
| w | The weight vectors |
| ϕ(x) | The non-linear function |
| b | The bias |
| ξi, | The slack variables that are used to measure the degree of sample deviation error |
| σ | The width factor of the kernel function |
| The loss functions | |
| {yk} | The sets of all modes |
| {ωk} | The center frequencies |
| Fourier transforms of each variable | |
References
- Ajagekar, A.; You, F.Q. Deep reinforcement learning based unit commitment scheduling under load and wind power uncertainty. IEEE Trans. Sustain. Energy 2023, 14, 803–812. [Google Scholar] [CrossRef]
- Xu, T.; Du, Y.; Li, Y.; Zhu, M.; He, Z. Interval prediction method for wind power based on VMD-ELM/ARIMA-ADKDE. IEEE Access 2022, 10, 72590–72602. [Google Scholar] [CrossRef]
- An, J.Q.; Yin, F.; Wu, M.; She, J.H.; Chen, X. Multisource wind speed fusion method for short-term wind power prediction. IEEE Trans. Ind. Inform. 2021, 17, 5927–5937. [Google Scholar] [CrossRef]
- Wang, H.Z.; Wang, G.B.; Li, G.Q.; Peng, J.C.; Liu, Y.T. Deep belief network based deterministic and probabilistic wind speed forecasting approach. Appl. Energy 2016, 182, 80–93. [Google Scholar] [CrossRef]
- Blachnik, M.; Walkowiak, S.; Kula, A. Large scale, mid term wind farms power generation prediction. Energies 2023, 16, 2359. [Google Scholar] [CrossRef]
- Zhang, F.M.; Que, L.Y.; Zhang, X.X.; Wang, F.M.; Wang, B. Rolling-horizon robust economic dispatch under high penetration wind power. In Proceedings of the 2022 4th International Conference on Power and Energy Technology (ICPET), Beijing, China, 28–31 July 2022; pp. 665–670. [Google Scholar]
- Zhang, H.F.; Yue, D.; Dou, C.X.; Li, K.; Hancke, G.P. Two-step wind power prediction approach with improved complementary ensemble empirical mode decomposition and reinforcement learning. IEEE Syst. J. 2022, 16, 2545–2555. [Google Scholar] [CrossRef]
- El-Fouly, T.H.M.; El-Saadany, E.F.; Salama, M.M.A. Grey predictor for wind energy conversion systems output power prediction. IEEE Trans. Power Syst. 2006, 21, 1450–1452. [Google Scholar] [CrossRef]
- Barbounis, T.G.; Theocharis, J.B. Locally recurrent neural networks for wind speed prediction using spatial correlation. Inform. Sci. 2007, 177, 5775–5797. [Google Scholar] [CrossRef]
- Mohandes, M.A.; Halawani, T.O.; Rehman, S.; Hussain, A.A. Support vector machines for wind speed prediction. Renew. Energy 2004, 29, 939–947. [Google Scholar] [CrossRef]
- Fan, S.; Liao, J.R.; Yokoyama, R.; Chen, L.; Lee, W.J. Forecasting the wind generation using a two-Stage network based on meteorological information. IEEE Trans. Energy Convers. 2009, 24, 474–482. [Google Scholar] [CrossRef]
- Yuan, X.H.; Tan, Q.X.; Lei, X.H.; Yuan, Y.B.; Wu, X.T. Wind power prediction using hybrid autoregressive fractionally integrated moving average and least square support vector machine. Energy 2017, 129, 122–137. [Google Scholar] [CrossRef]
- Yeh, W.C.; Yeh, Y.M.; Chang, P.C.; Ke, Y.C.; Chung, V. Forecasting wind power in the Mai Liao wind farm based on the multilayer perceptron artificial neural network model with improved simplified swarm optimization. Int. J. Electr. Power Syst. 2014, 55, 741–748. [Google Scholar] [CrossRef]
- Zhang, H.T.; Zhao, L.X.; Du, Z.P. Wind power prediction based on CNN-LSTM. In Proceedings of the 2021 IEEE 5th Conference on Energy Internet and Energy System Integration (EI2), Taiyuan, China, 22–25 October 2021; pp. 3097–3102. [Google Scholar]
- Nourianfar, H.; Abdi, H. A new technique for investigating wind power prediction error in the multi-objective environmental economics problem. IEEE Trans. Power Syst. 2023, 38, 1379–1387. [Google Scholar] [CrossRef]
- Sun, Q.; Cai, H.F. Short-Term Power Load Prediction Based on VMD-SG-LSTM. IEEE Access 2022, 10, 102396–102405. [Google Scholar] [CrossRef]
- Zhang, Y.G.; Zhao, Y.; Gao, S. A novel hybrid model for wind speed prediction based on VMD and neural network considering atmospheric uncertainties. IEEE Access 2019, 7, 60322–60332. [Google Scholar] [CrossRef]
- Zhou, Z.Y.; Sun, S.W.; Gao, Y. Short-term wind power prediction based on EMD-LSTM. In Proceedings of the 2023 IEEE 3rd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 29–31 January 2023; pp. 802–807. [Google Scholar]
- Zhou, B.B.; Sun, B.; Gong, X.; Liu, C. Ultra-short-term prediction of wind power based on EMD and DLSTM. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 1909–1913. [Google Scholar]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Lv, L.L.; Wu, Z.Y.; Zhang, J.H.; Zhang, L.; Tan, Z.Y.; Tian, Z.H. A VMD and LSTM based hybrid model of load forecasting for power grid security. IEEE Trans. Ind. Inform. 2022, 18, 6474–6482. [Google Scholar] [CrossRef]
- Gu, D.H.; Chen, Z. Wind power prediction based on VMD-neural network. In Proceedings of the 2019 12th International Conference on Intelligent Computation Technology and Automation (ICICTA), Xiangtan, China, 26–27 October 2019; pp. 162–165. [Google Scholar]
- Sun, Z.X.; Zhao, M. Short-term wind power forecasting based on VMD decomposition, convLSTM networks and error analysis. IEEE Access 2020, 8, 134422–134434. [Google Scholar] [CrossRef]
- Huang, S.L.; Sun, H.Y.; Wang, S.; Qu, K.F.; Zhao, W.; Peng, L.S. SSWT and VMD linked mode identification and time-of-flight extraction of denoised SH guided waves. IEEE Sens. J. 2021, 21, 14709–14717. [Google Scholar] [CrossRef]
- Li, Y.Z.; Wang, S.Y.; Wei, Y.J.; Zhu, Q. A new hybrid VMD-ICSS-BiGRU approach for gold futures price forecasting and algorithmic trading. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1357–1368. [Google Scholar] [CrossRef]
- Qiu, Z.B.; Wang, X.Z. A feature set for structural characterization of sphere gaps and the breakdown voltage prediction by PSO-optimized support vector classifier. IEEE Access 2019, 7, 90964–90972. [Google Scholar] [CrossRef]
- Ren, Z.G.; Zhang, A.M.; Wen, C.Y.; Feng, Z.R. A scatter learning particle swarm optimization algorithm for multimodal problems. IEEE Trans. Cybern. 2014, 44, 1127–1140. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Chen, Z.Q.; Yuan, Z.Z. New chaotic PSO-based neural network predictive control for nonlinear process. IEEE Trans. Neural Netw. 2007, 18, 595–600. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.H.; Liu, L.; Xing, Z.Y.; Cong, G.T. The forecasting model of wheelset size based on PSO-SVM. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 2609–2613. [Google Scholar]
- Sun, X.C.; Li, Y.Q.; Wang, N.; Li, Z.G.; Liu, M.; Gui, G. Toward self-adaptive selection of kernel functions for support vector regression in IoT-based marine data prediction. IEEE Internet Things J. 2020, 7, 9943–9952. [Google Scholar] [CrossRef]
- Zeng, C.; Ma, C.X.; Wang, K.; Cui, Z.H. Parking occupancy prediction method based on multi factors and stacked GRU-LSTM. IEEE Access 2022, 10, 47361–47370. [Google Scholar] [CrossRef]
- Sulistio, B.; Warnars, H.L.H.S.; Gaol, F.L.; Soewito, B. Energy sector stock price prediction using the CNN, GRU & LSTM hybrid algorithm. In Proceedings of the 2023 International Conference on Computer Science, Information Technology and Engineering (ICCoSITE), Jakarta, Indonesia, 16 February 2023; pp. 178–182. [Google Scholar]
- Li, D.; Cohen, J.B.; Qin, K.; Xue, Y.; Rao, L. Absorbing aerosol optical depth from OMI/TROPOMI based on the GBRT algorithm and AERONET data in Asia. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4100210. [Google Scholar] [CrossRef]
- Sheng, T.; Shi, S.Z.; Zhu, Y.Y.; Chen, D.B.; Liu, S. Analysis of protein and fat in milk using multiwavelength gradient-boosted regression tree. IEEE Trans. Instrum. Meas. 2022, 71, 2507810. [Google Scholar] [CrossRef]
- 16 MW Wind Power Data. Available online: https://download.csdn.net/download/glpghz/11998604?ops_request_misc=&request_id=5543c7511a6046fd99579a4685888159&biz_id=&utm_medium=distribute.pc_search_result.none-task-download-2~all~koosearch_insert~default-2-11998604-null-null.142^v88^insert_down28v1,239^v2^insert_chatgpt&utm_term=%E9%A3%8E%E5%8A%9F%E7%8E%87%E6%95%B0%E6%8D%AE&spm=1018.2226.3001.4187.3 (accessed on 23 January 2023).
- Hu, Q.H.; Su, P.Y.; Yu, D.R.; Liu, J.F. Pattern-based wind speed prediction based on generalized principal component analysis. IEEE Trans. Sustain. Energy 2014, 5, 866–874. [Google Scholar] [CrossRef]
- Mogos, A.S.; Salauddin, M.; Liang, X.D.; Chung, C.Y. An effective very short-term wind speed prediction approach using multiple regression models. IEEE Can. J. Electr. Comput. Eng. 2022, 45, 242–253. [Google Scholar] [CrossRef]
- 4 MW Wind Power Data. Available online: https://www.elia.be/en/grid-data/power-generation/wind-power-generation (accessed on 1 July 2023).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Methods | Application |
|---|---|---|
| [11] | BCD, SVR | Forecasting wind generation |
| [12] | ARFIMA, LSSVM | Wind power prediction |
| [13] | ISSO, MLP | Forecasting wind power |
| [14] | CNN, LSTM | Wind power prediction |
| [15] | EMEMA | Wind power prediction error in the multi-objective environmental economics problem |
| [16] | VMD, SG, LSTM | Short-term power load prediction |
| [17] | VMD, NN | Wind speed prediction |
| [18] | EMD, LSTM | Short-term wind power prediction |
| [19] | EMD, DLSTM | Ultra-short-term prediction of wind power |
| [21] | VMD, LSTM | Load forecasting |
| [22] | VMD, RBF | Wind power prediction |
| Training Parameters | Parameter Settings |
|---|---|
| Number of GRU layers | Adaptive optimization |
| Dropout ratio | Adaptive optimization |
| Batch size | Adaptive optimization |
| Number of LSTM neurons in the first layer | 256 |
| Number of LSTM neurons in the second layer | 128 |
| Number of LSTM neurons in the third layer | 32 |
| Activation function solver | Relu |
| Solver | Adam |
| Model | MSE | MAE | R2 |
|---|---|---|---|
| BP | 0.2041 | 0.4287 | 0.8509 |
| LSTM | 0.1218 | 0.2929 | 0.9110 |
| PSO-LSTM | 0.0839 | 0.2411 | 0.9387 |
| PSO-GRU-LSTM | 0.0746 | 0.2160 | 0.9455 |
| Model I | 0.0324 | 0.1557 | 0.9763 |
| Model II | 0.0631 | 0.2131 | 0.9539 |
| Model III | 0.0286 | 0.1405 | 0.9791 |
| Model IV | 0.0244 | 0.1185 | 0.9821 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, F.; Song, X.; Wang, Y.; Qin, C. A New Combined Prediction Model for Ultra-Short-Term Wind Power Based on Variational Mode Decomposition and Gradient Boosting Regression Tree. Sustainability 2023, 15, 11026. https://doi.org/10.3390/su151411026
Xing F, Song X, Wang Y, Qin C. A New Combined Prediction Model for Ultra-Short-Term Wind Power Based on Variational Mode Decomposition and Gradient Boosting Regression Tree. Sustainability. 2023; 15(14):11026. https://doi.org/10.3390/su151411026
Chicago/Turabian StyleXing, Feng, Xiaoyu Song, Yubo Wang, and Caiyan Qin. 2023. "A New Combined Prediction Model for Ultra-Short-Term Wind Power Based on Variational Mode Decomposition and Gradient Boosting Regression Tree" Sustainability 15, no. 14: 11026. https://doi.org/10.3390/su151411026
APA StyleXing, F., Song, X., Wang, Y., & Qin, C. (2023). A New Combined Prediction Model for Ultra-Short-Term Wind Power Based on Variational Mode Decomposition and Gradient Boosting Regression Tree. Sustainability, 15(14), 11026. https://doi.org/10.3390/su151411026