
Discrete Choice Experiment Consideration: A Framework for Mining Community Consultation with Case Studies


Abstract
:1. Introduction
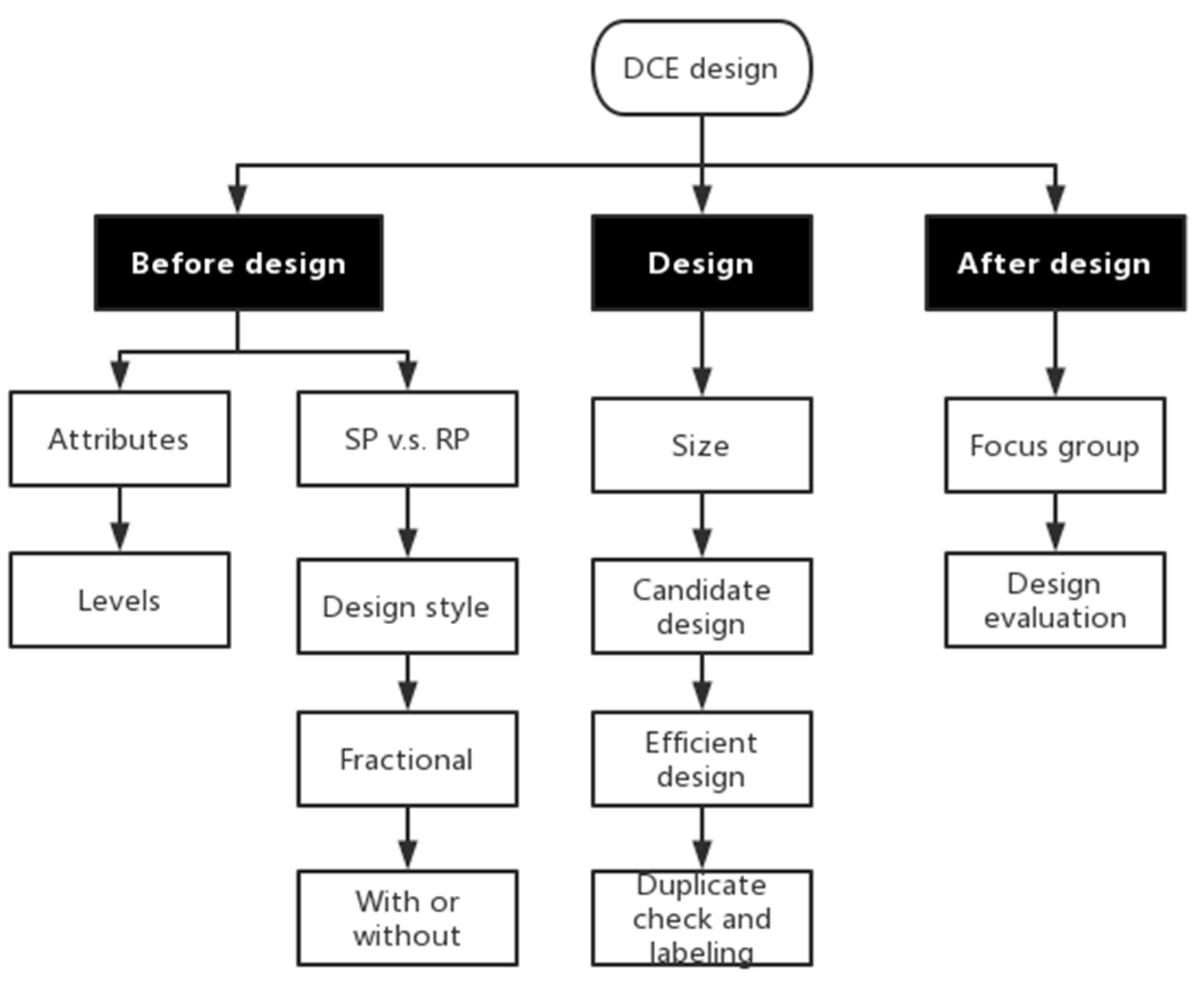
2. Materials and Methods
2.1. Attributes and Levels
2.2. Experimental Design Considerations
2.2.1. Stated Preference vs. Revealed Preference
2.2.2. Block Scheme Design
2.2.3. Fractional Factorial Design
2.2.4. Interaction vs. No Interaction
2.3. Challenges and Methods in the Developed Framework
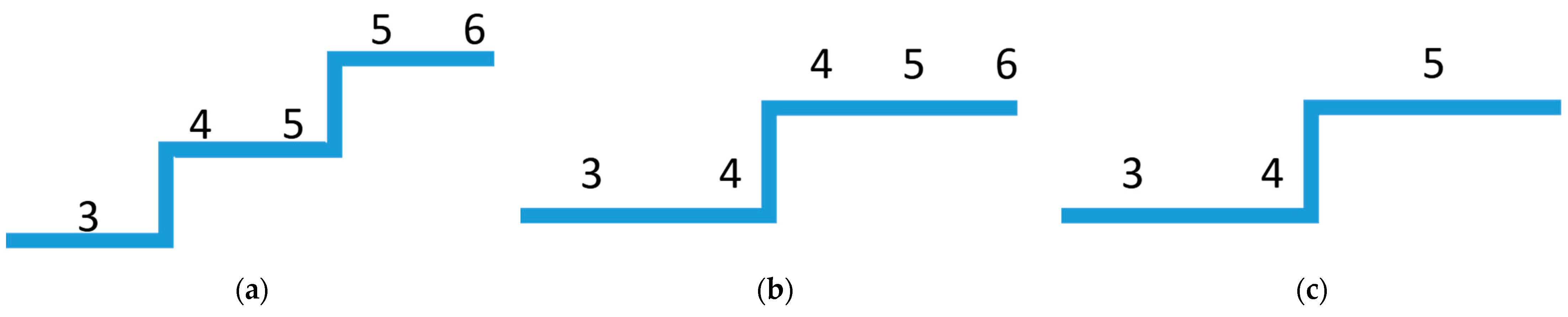
2.3.1. How to Identify the Optimum Number of Factors
2.3.2. How to Structure and Validate a DCE Design
2.4. Statistical Data Analysis and Case Study Survey
2.4.1. Kruskal–Wallis Test
2.4.2. Dunn’s Multiple Comparison Test
2.4.3. Case Study Survey
3. Results
3.1. Case Study for Challenge One
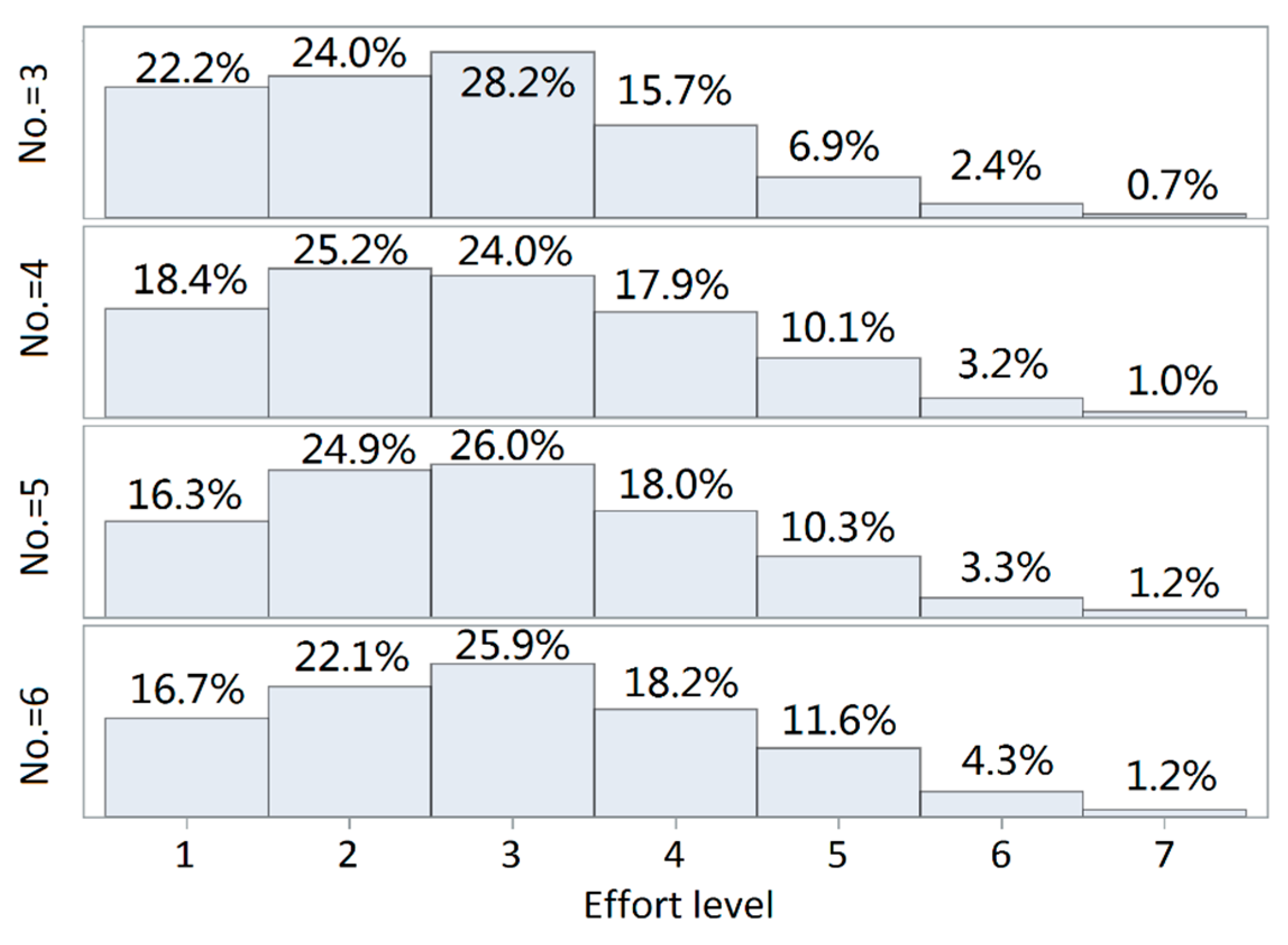
3.1.1. Effort Level Analysis
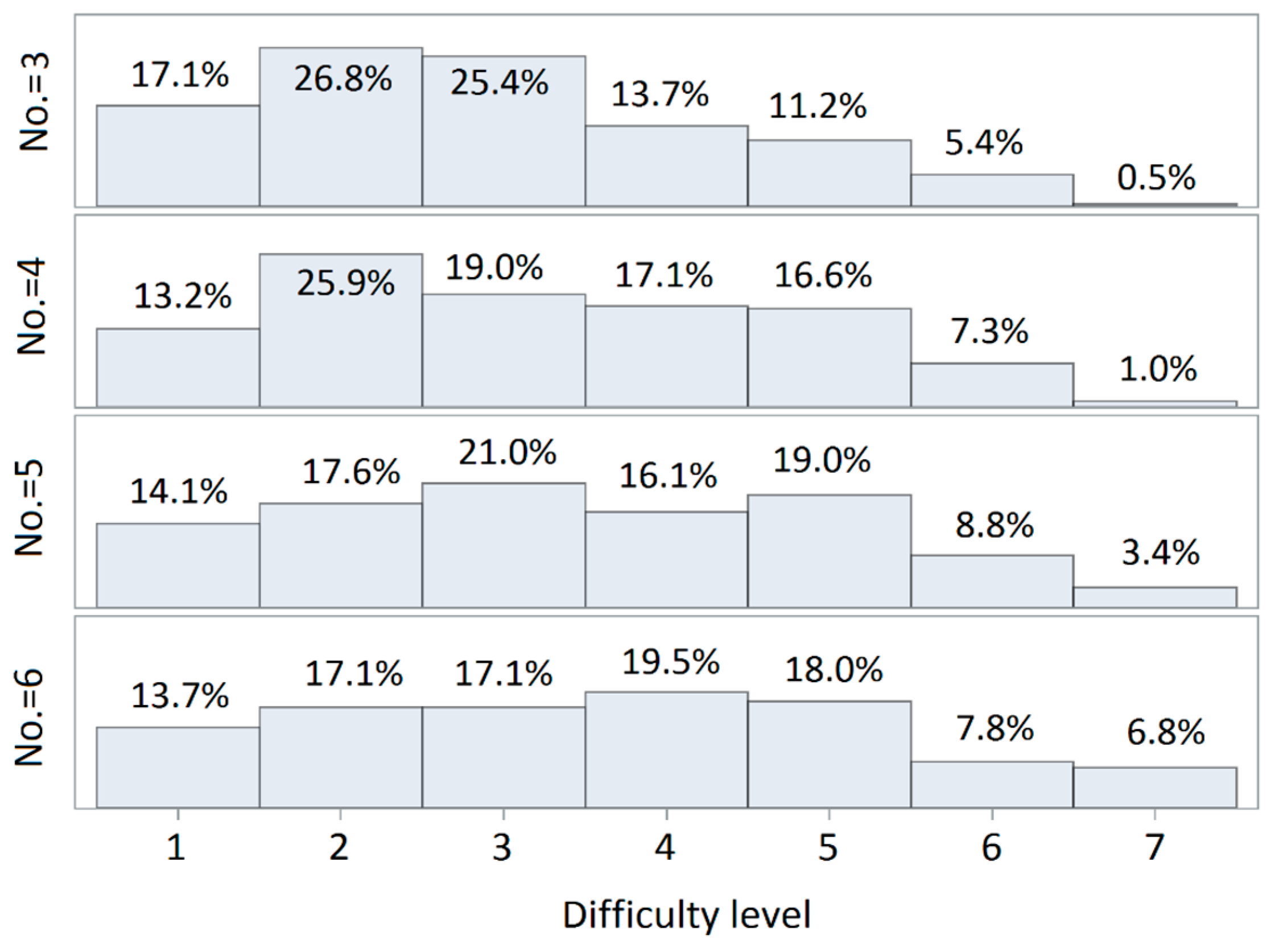
3.1.2. Difficulty Level Analysis
3.1.3. Analysis Based on Duration of the Survey
3.1.4. Comparison
3.2. Case Study for Challenge Two
3.2.1. Design Generating Experiments
- Experimental Size Determination
- Candidate design construction
- Efficient experiment design
- Duplicate check and labeling
3.2.2. Design Validation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

| Saturated = 9 | |
|---|---|
| Full Factorial = 81 | |
| Observation | Reasonable design size |
| 1 | 9 *,S |
| 2 | 18 * |
| 3 | 12 |
| 4 | 15 |
| 5 | 10 |
| 6 | 11 |
| 7 | 13 |
| 8 | 14 |
| 9 | 16 |
| 10 | 17 |
| Observation | x1 | x2 | x3 | x4 |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 2 | 2 |
| 3 | 1 | 2 | 1 | 3 |
| 4 | 1 | 2 | 3 | 1 |
| 5 | 1 | 3 | 2 | 3 |
| 6 | 1 | 3 | 3 | 2 |
| 7 | 2 | 1 | 1 | 3 |
| 8 | 2 | 1 | 3 | 1 |
| 9 | 2 | 2 | 2 | 2 |
| 10 | 2 | 2 | 3 | 3 |
| 11 | 2 | 3 | 1 | 2 |
| 12 | 2 | 3 | 2 | 1 |
| 13 | 3 | 1 | 2 | 3 |
| 14 | 3 | 1 | 3 | 2 |
| 15 | 3 | 2 | 1 | 2 |
| 16 | 3 | 2 | 2 | 1 |
| 17 | 3 | 3 | 1 | 1 |
| 18 | 3 | 3 | 3 | 3 |
| Design | Iteration | D-Efficiency | D-Error | Relative D-Efficiency |
|---|---|---|---|---|
| 1 | 0 | 0 | . | . |
| 1 | 5.970687 | 0.167485 | 66% | |
| 2 | 6.142330 | 0.162805 | 68% | |
| 3 | 6.500560 | 0.153833 | 72% | |
| 4 | 6.500560 | 0.153833 | 72% | |
| 2 | 0 | 1.837117 | 0.544331 | 20% |
| 1 | 5.759409 | 0.173629 | 64% | |
| 2 | 5.845501 | 0.171072 | 65% | |
| 3 | 6.167149 | 0.162149 | 69% | |
| 4 | 6.167149 | 0.162149 | 69% |
| Observation (Table A2) | Set |
|---|---|
| 4 | 1 |
| 13 | 1 |
| 8 | 2 |
| 15 | 2 |
| 9 | 3 |
| 18 | 3 |
| 16 | 4 |
| 11 | 4 |
| 12 | 5 |
| 3 | 5 |
| 5 | 6 |
| 14 | 6 |
| 17 | 7 |
| 2 | 7 |
| 1 | 8 |
| 10 | 8 |
| 6 | 9 |
| 7 | 9 |
References
- Lokuwaduge, S.D.S.C.; Heenetigala, K. Integrating Environmental, Social and Governance (ESG) Disclosure for a Sustainable Development: An Australian Study. Bus. Strategy Environ. 2017, 26, 438–450. [Google Scholar] [CrossRef]
- Nessa, W. Sustainable community development: Integrating social and environmental sustainability for sustainable housing and communities. Sustain. Dev. 2021, 30, 191–202. [Google Scholar]
- Del-Aguila-Arcentales, S.; Álvarez-Risco, A.; Jaramillo-Arévalo, M.; De-la-Cruz-Diaz, M.; Anderson-Seminario, M.d.l.M. Influence of Social, Environmental and Economic Sustainable Development Goals (SDGs) over Continuation of Entrepreneurship and Competitiveness. J. OpenInnov. Technol. Mark. Complex. 2022, 8, 73. [Google Scholar] [CrossRef]
- Allauddin, K.; Nawaz, A.K. The impacts of economic and environmental factors on sustainable mega project development: Role of community satisfaction and social media. Environ. Sci. Pollut. Res. Int. 2021, 28, 2753–2764. [Google Scholar]
- Silvius, G.; Schipper, R. Planning Project Stakeholder Engagement from a Sustainable Development Perspective. Adm. Sci. 2019, 9, 46. [Google Scholar] [CrossRef]
- ICMM. Mining’s Contribution to Sustainable Development—An Overview Mining’s Contribution to Sustainable Development; ICMM: London, UK, 2012. [Google Scholar]
- van Rijnsoever, F.J.; van Mossel, A.; Broecks, K.P.F. Public acceptance of energy technologies: The effects of labeling, time, and heterogeneity in a discrete choice experiment. Renew. Sustain. Energy Rev. 2015, 45, 817–829. [Google Scholar] [CrossRef]
- Dimitropoulos, A.; Kontoleon, A. Assessing the determinants of local acceptability of wind-farm investment: A choice experiment in the Greek Aegean Islands. Energy Policy 2009, 37, 1842–1854. [Google Scholar] [CrossRef]
- Vlachokostas, C.; Achillas, C.; Diamantis, V.; Michailidou, A.V.; Baginetas, K.; Aidonis, D. Supporting decision making to achieve circularity via a biodegradable waste-to-bioenergy and compost facility. J. Environ. Manag. 2021, 285, 112215. [Google Scholar] [CrossRef]
- Su, W.; Liu, M.; Zeng, S.; Streimikiene, D.; Balezentis, T.; Alisauskaite-Seskiene, I. Valuating renewable microgeneration technologies in lithuanian households: A study on willingness to pay. J. Clean. Prod. 2018, 191, 318–329. [Google Scholar] [CrossRef]
- Ivanova, G.; Rolfe, J.; Lockie, S.; Timmer, V. Assessing social and economic impacts associated with changes in the coal mining industry in the Bowen Basin, Queensland, Australia. Manag. Environ. Qual. Int. J. 2007, 18, 211–228. [Google Scholar] [CrossRef]
- Ivanova, G.; Rolfe, J. Assessing development options in mining communities using stated preference techniques. Resour. Policy 2011, 36, 255–264. [Google Scholar] [CrossRef]
- Grasshoff, U.; Grossmann, H.; Holling, H.; Schwabe, R. Optimal design for probit choice models with dependent utilities. Stat. A J. Theor. Appl. Stat. 2021, 55, 173–194. [Google Scholar] [CrossRef]
- Traets, F.; Vandebroek, M. Generating optimal designs for discrete choice experiments in r: The idefix package frits traets. J. Stat. Softw. 2020, 96, 1–41. [Google Scholar] [CrossRef]
- Thai, T.T.H.; Bliemer, M.; Chen, G.; Spinks, J.; De New, S.; Lancsar, E. A comparison of full and partial choice set designs in a labelled discrete choice experiment. Patient 2021, 32, 1284–1304. [Google Scholar]
- Mamine, F.; Fares, M.; Minviel, J.J. Contract design for adoption of agrienvironmental practices: A meta-analysis of discrete choice experiments. Ecol. Econ. 2020, 176, 106721. [Google Scholar] [CrossRef]
- Hoyos, D. The State of the Art of Environmental Valuation with Discrete Choice Experiments. Ecol. Econ. 2010, 69, 1595–1603. [Google Scholar] [CrossRef]
- Caussade, S.; Ortúzar, J.D.D.; Rizzi, L.I.; Hensher, D.A. Assessing the influence of design dimensions on stated choice experiment estimates. Transp. Res. Part B Methodol. 2005, 39, 621–640. [Google Scholar] [CrossRef]
- Que, S.; Awuah-Offei, K.; Wang, L.; Samaranayake, V.A.; Weidner, N.; Yuan, S. Individual preferences for mineral resource development: Perspectives from an urban population in the United States. J. Clean. Prod. 2018, 189, 30–39. [Google Scholar] [CrossRef]
- Que, S.; Offei, K.A. Framework for mining community consultation based on discrete choice theory. Int. J. Min. Miner. Eng. 2014, 5, 59–74. [Google Scholar] [CrossRef]
- Que, S.; Awuah-Offei, K.; Samaranayake, V.A. Classifying critical factors that influence community acceptance of mining projects for discrete choice experiments in the united states. J. Clean. Prod. 2015, 87, 489–500. [Google Scholar] [CrossRef]
- Helveston, P.J.; Feit, M.E.; Michalek, J.J. Pooling stated and revealed preference data in the presence of RP endogeneity. Transp. Res. Part B 2018, 109, 70–89. [Google Scholar] [CrossRef]
- Louviere, J.J.; Hensher, D.A.; Swait, J.D. Stated Choice Methods Analysis and Applications; Cambridge University Press: Cambridge, UK, 2003; pp. 1–418. [Google Scholar]
- Hensher, D.; Rose, J.; Greene, W. Applied Choice Analysis: A Primer; Cambridge University: Cambridge, UK, 2005; pp. 1–742. [Google Scholar]
- Ryan, M.; Gerard, K. Using discrete choice experiments to value health care: Current practice and future prospects. Appl. Health Econ. Policy Anal. 2003, 2, 55–64. [Google Scholar]
- Scott, A. Identifying and analysing dominant preferences in discrete choice experiments: An application in health care. J. Econ. Psychol. 2002, 23, 383–398. [Google Scholar] [CrossRef]
- Witt, J.; Scott, A.; Osborne, R.H. Designing Choice Experiments with Many Attributes: An Application to Setting Priorities for Orthopaedic Waiting Lists; Melbourne Institute of Applied Economic and Social Research, The University of Melbourne: Victoria, Australia, 2006. [Google Scholar]
- SAS. The % MktRuns Macro. 2007. Available online: https://support.sas.com/en/support-home.html (accessed on 20 April 2023).
- SAS. The % MktEx Macro. 2007. Available online: https://support.sas.com/en/support-home.html (accessed on 20 April 2023).
- SAS. The % ChoicEff Macro. 2007. Available online: https://support.sas.com/en/support-home.html (accessed on 20 April 2023).
- SAS. The % MktDups Macro. 2007. Available online: https://support.sas.com/en/support-home.html (accessed on 20 April 2023).
- SAS. The % MktLab Macro. 2007. Available online: https://support.sas.com/en/support-home.html (accessed on 20 April 2023).
- Mark, T.L.; Swait, J. Using stated preference and revealed preference modeling to evaluate prescribing decisions. Health Econ. 2004, 13, 563–573. [Google Scholar] [CrossRef]
- Schlotzhauer, S.D. Elementary Statistics Using SAS; SAS Institute: Cary, NC, USA, 2009. [Google Scholar]
- SAS. The NPAR1WAY Procedure Example 52.2: The Exact Wilcoxon Two-Sample Test. 2007. Available online: https://support.sas.com/en/support-home.html (accessed on 20 April 2023).
- Dinno, A. Nonparametric Pairwise Multiple Comparisons in Independent Groups using Dunn’s Test. Stata J. 2015, 15, 292–300. [Google Scholar] [CrossRef]
- Kuhfeld, W. Marketing Research Methods in SAS. Graphical Techniques; SAS-Institute TS-722 (SAS 9.2., pp. 1–1309); SAS Institute Inc.: Cary, NC, USA, 2010. [Google Scholar]
- Meyer, R.K.; Nachtsheim, C.J. The Coordinate-Exchange Algorithm for Constructing Exact Optimal Experimental Designs. Technometrics 1995, 37, 60–69. [Google Scholar] [CrossRef]
- Sever, I.; Verbič, M. Providing information to respondents in complex choice studies: A survey on recreational trail preferences in an urban nature park. Landsc. Urban Plan. 2018, 169, 160–177. [Google Scholar] [CrossRef]
- Dudinskaya, C.E.; Naspetti, S.; Zanoli, R. Using eye-tracking as an aid to design on-screen choice experiments. J. Choice Model. 2020, 36, 100232. [Google Scholar] [CrossRef]
- Louviere, J.J.; Pihlens, D.; Carson, R. Design of discrete choice experiments: A discussion of issues that matter in future applied research. J. Choice Model. 2011, 4, 1–8. [Google Scholar] [CrossRef]
- Scott, W. Multiple discrete choice and quantity with order statistic marginal utilities. J. Choice Model. 2023, 46, 100395. [Google Scholar]
- Jean, S.; Duncan, M. Lost in the crowd? Using eye-tracking to investigate the effect of complexity on attribute non-attendance in discrete choice experiments. BMC Med. Inform. Decis. Mak. 2016, 16, 14. [Google Scholar]
- Heidenreich, S.; Beyer, A.; Flamion, B.; Ross, M.; Seo, J.; Marsh, K. Benefit-Risk or Risk-Benefit Trade-Offs? Another Look at Attribute Ordering Effects in a Pilot Choice Experiment. Patient 2020, 14, 65–74. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

| Step | SAS Macro | Function |
|---|---|---|
| 1. Experimental size determination | %MktRuns [28] | Suggests sizes for balanced fractional factorial experiment designs |
| 2. Candidate design construction | %MktEx [29] | Creates efficient factorial designs with the selected size |
| 3. Efficient experiment design | %ChoicEff [30] | Finds optimal experimental designs for evaluating choice designs and choice experiments |
| 4. Duplicate check | %MktDups [31] | Alternatives within the generic choice set and detects duplicate choice sets |
| 5. Labeling | %MktLab [32] | Labels factors and their levels for each block |
| Income Increase | Population Increase | Mine Life | Air Pollution | I Would Choose | |
|---|---|---|---|---|---|
| Option 1 | +$300 per month | Continued population growth (average rate 4%) | 20 years | A slight increase in pollution |  |
| Option 2 | +$100 per month | Continued population growth (average rate 4%) | 30 years | No increase in pollution | |
| Option 3 | +$500 per month | A reduced rate of population growth (only 2%) | 20 years | A moderate increase in pollution | |
| Option 4 | Too complex to decide | | |||
| Comparison Group = Number of Factors | |||||
|---|---|---|---|---|---|
| Compare | Diff | SE | QAB | Q(0.05) | Conclude |
| 6 vs. 3 | 459.81 | 68.08 | 6.75 | 2.638 | Reject |
| 6 vs. 4 | 197.71 | 68.08 | 2.90 | 2.638 | Reject |
| 6 vs. 5 | 104.80 | 68.08 | 1.54 | 2.638 | Do not reject |
| 5 vs. 3 | 355.01 | 68.08 | 5.21 | 2.638 | Reject |
| 5 vs. 4 | 92.91 | 68.08 | 1.36 | 2.638 | Do not reject |
| 4 vs. 3 | 262.10 | 68.08 | 3.85 | 2.638 | Reject |
| Comparison Group = Number of Factors | |||||
|---|---|---|---|---|---|
| Compare | Diff | SE | QAB | Q(0.05) | Conclude |
| 6 vs. 3 | 92.87 | 23.02 | 4.03 | 2.638 | Reject |
| 6 vs. 4 | 48.40 | 23.02 | 2.10 | 2.638 | Do not reject |
| 6 vs. 5 | Do not reject (within non-sig. comparison) | ||||
| 5 vs. 3 | 77.25 | 23.02 | 3.36 | 2.638 | Reject |
| 5 vs. 4 | Do not reject (within non-sig. comparison) | ||||
| 4 vs. 3 | 44.47 | 23.02 | 1.93 | 2.638 | Do not reject |
| Comparison Group = Number of Factors | |||||
|---|---|---|---|---|---|
| Compare | Diff | SE | QAB | Q(0.05) | Conclude |
| 5 vs. 3 | 87.27 | 23.22 | 3.76 | 2.638 | Reject |
| 5 vs. 4 | 111.33 | 23.22 | 4.79 | 2.638 | Reject |
| 4 vs. 3 | 24.06 | 23.22 | 1.04 | 2.638 | Do not reject |
| Confusing Level | Difficulty Level | |
|---|---|---|
| Block 1 | (2, 4) | (2, 4) |
| Block 2 | (2, 3) | (2, 3) |
| Block 3 | (2, 3) | (2, 3) |
| Block 4 | (2, 3) | (2, 3) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Que, S.; Huang, Y.; Awuah-Offei, K.; Wang, L.; Liu, S. Discrete Choice Experiment Consideration: A Framework for Mining Community Consultation with Case Studies. Sustainability 2023, 15, 13070. https://doi.org/10.3390/su151713070
Que S, Huang Y, Awuah-Offei K, Wang L, Liu S. Discrete Choice Experiment Consideration: A Framework for Mining Community Consultation with Case Studies. Sustainability. 2023; 15(17):13070. https://doi.org/10.3390/su151713070
Chicago/Turabian StyleQue, Sisi, Yu Huang, Kwame Awuah-Offei, Liang Wang, and Songlin Liu. 2023. "Discrete Choice Experiment Consideration: A Framework for Mining Community Consultation with Case Studies" Sustainability 15, no. 17: 13070. https://doi.org/10.3390/su151713070
APA StyleQue, S., Huang, Y., Awuah-Offei, K., Wang, L., & Liu, S. (2023). Discrete Choice Experiment Consideration: A Framework for Mining Community Consultation with Case Studies. Sustainability, 15(17), 13070. https://doi.org/10.3390/su151713070