



An Integrated Data-Driven Procedure for Product Specification Recommendation Optimization with LDA-LightGBM and QFD


Abstract
:1. Introduction
2. Materials and Methods
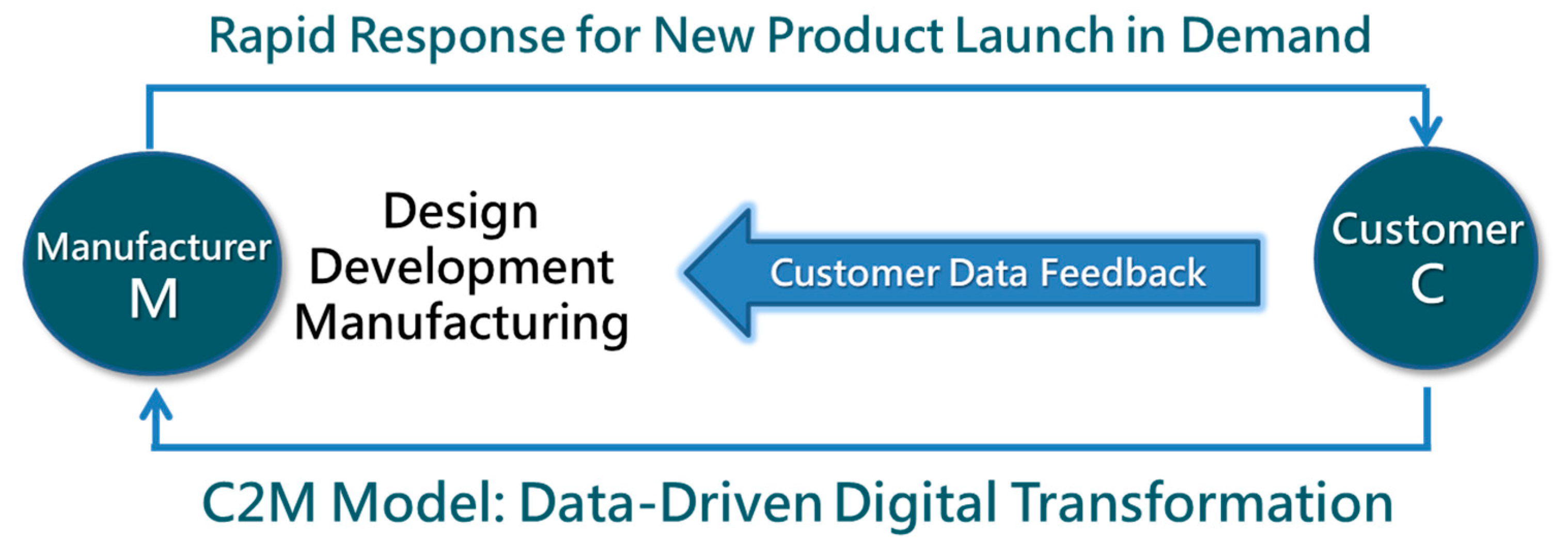
2.1. Conceptualizing the C2M Data Model
2.2. Proposed Framework
2.3. Case Study
- Terminal Market Data Acquisition Mode: The implementation of this system instigates a transformative enhancement to the existing product database. The transition from traditional internal database analysis to a holistic internal and external data model proves pivotal. By orchestrating the automatic collection of external product data and the subsequent generation of structured information via the ETL process, the system ensures expedited access to terminal customer insights. Consequently, the arduous task of market data retrieval is substantially abridged.
- Customer Need Analysis Findings: When a product manager sets out to craft innovative offerings, the system rapidly furnishes real-time insights, encompassing customer demands, product attributes, inherent product functionalities, and the most sought-after items in the current market. By categorizing a spectrum of product requirements, the system equips product managers with the ability to discern key elements and assign them relevant significance rankings. The availability of a topic analytical model expedites the intricacies of market research, thereby considerably aiding in the meticulous realm of product planning.
- Product Specification Recommendation Model: An innovative facet of this system involves the establishment of a robust foundation in terms of product specification knowledge, complemented by the framework of quality function deployment (QFD). This is further reinforced by a self-learning mechanism. The system autonomously elucidates intrinsic relationships between product functionalities and specifications. Manual adaptations seamlessly integrate into the knowledge base, subsequently fortifying the training model via the self-learning mechanism. This meticulous self-study mechanism distinctly elevates the reliability quotient within the realm of burgeoning interdisciplinary domains.
2.4. Latent Dirichlet Allocation and Customer Need Variables
2.5. Machine Learning and Deep Learning
- Long short-term memory (LSTM): LSTM is a type of recurrent neural network (RNN) specifically designed for handling sequential data, such as text. It effectively tackles the vanishing gradient problem by incorporating memory cells that can retain information over long sequences. In the context of processing review data, LSTM proves valuable in analyzing the sequential nature of reviews, capturing dependencies between words or phrases to comprehend the underlying sentiment or meaning. By learning patterns from review data, LSTM models can predict and classify reviews based on sentiment or other relevant attributes (Hochreiter, S. and Schmidhuber, J., 1997) [27].
- Convolutional neural networks (CNNs): a CNN is a deep learning architecture widely used in computer vision tasks, but it can also be adapted for text data. In the context of review data, CNN can extract pertinent features from text by applying filters or convolutions over the input. These filters can capture patterns or word combinations that are indicative of the sentiment or other characteristics of the reviews. Utilizing multiple layers of convolutions and pooling operations, CNN models can learn hierarchical representations of text data, enabling them to predict or classify reviews based on these learned features (Kim, Y., 2014) [28].
- CNN-LSTM: CNN-LSTM is a hybrid model that combines the strengths of a CNN and LSTM. It is particularly effective in handling sequential data with both spatial and temporal dependencies, as found in text data. In the context of review data, a CNN-LSTM model uses CNN layers to extract features from the text and then passes these features to LSTM layers to capture the sequential dependencies. This combination allows the model to grasp both local patterns in the text and long-term dependencies, improving its ability to understand the sentiment or other characteristics of the reviews (Onan, A., 2021) [29].
- LightGBM (light gradient-boosting machine): a LightGBM is a gradient-boosting framework that employs decision trees as base learners. It is well-regarded for its efficiency and capacity to handle large datasets. LightGBM functions by iteratively adding decision trees trained to correct mistakes made by previous trees. It utilizes gradient-based one-sided sampling to select the most informative instances for building trees, enhancing both speed and memory usage. In the context of review data, LightGBM can be utilized for regression tasks to predict numerical values, such as the number of reviews or ratings. Additionally, it can handle categorical features and is commonly employed for feature selection, classification, and regression tasks across various domains (Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., and Liu, T. Y., 2017) [30].
- After evaluating diverse deep learning sentiment models, the integration of the gradient-boosting decision tree (LightGBM) stands out due to its unique advantages. LSTM efficiently handles sequential data and dependencies, capturing nuanced sentiment in reviews. CNN employs convolutional filters for pivotal feature extraction in sentiment classification. CNN-LSTM hybrids adeptly manage spatial and temporal dependencies in sequential text data. Unlike other models that focus on the LDA context, LightGBM’s strength lies in managing data imbalances. It excels in addressing data skewness through gradient-based one-sided sampling, which is crucial when handling reviews with uneven sentiment distribution. This strengthens sentiment analysis by ensuring a balanced approach, making LightGBM an apt choice to enhance sentiment classification precision and robustness.
- Below is an introduction to the LightGBM objective function, loss function, and regularization term.
- Objective Function:
- Loss Function:
- Regularization Term:
2.6. Quality Function Deployment
2.7. Data Preprocessing
2.8. The Procedure
- Step 1: Pre-processing of current market data:
- Step 2: Analysis of consumer demands:
- Step 3: Identifying fit values of product requirement/specifications:
- Step 4: Recommending optimal product specifications:
- Step 5: Deployment in management system:
3. Results
3.1. Prediction of Product Ratings
3.2. Permutation Feature Importance
4. Discussion
4.1. Principal Findings
4.2. Practical Implications of Sustainable Business Models
- (1)
- Data-Driven Framework for Sustainable Product Service Systems
- (2)
- C2M System Framework for Sustainable Business Models
4.3. Discuss Limitations
5. Conclusions
- By integrating machine learning techniques and latent Dirichlet allocation (LDA), a two-stage product feature recommendation model is developed. This model automates the generation of comprehensive product data aligned with market preferences, considering diverse customer requirements. The LDA-lightGBM analysis successfully identifies crucial features across industries, highlighting specific product demands.
- In our study, we compare various popular deep learning architectures for sequence processing from current literature. We investigate four distinct deep learning techniques, integrating them with LDA and conducting comprehensive tests across diverse review analysis scenarios. By carefully selecting the best-performing predictive model, our proposed ensemble model demonstrates superior predictive power and robustness compared to other baseline models. This not only contributes a novel ensemble approach to the sentiment analysis modeling field but also establishes our model as a benchmark in the literature.
- Moreover, feature importance assigns a distinct score to each feature, reflecting their influence on model performance. These scores gauge the contribution of individual features to decision making within the constructed model. The analysis framework assesses product specifications across diverse consumer requirements. The integration of product specification scores and consumer needs constitutes a data-driven C2M business model, facilitating informed decision making in profitable product development.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mak, H.Y.; Max Shen, Z.J. When triple-A supply chains meet digitalization: The case of JD. com’s C2M model. Prod. Oper. Manag. 2021, 30, 656–665. [Google Scholar] [CrossRef]
- Hinterhuber, A. Digital transformation, the Holy Grail, and the disruption of business models: An interview with Michael Nilles. Bus. Horiz. 2022, 65, 261–265. [Google Scholar] [CrossRef]
- Relich, M. A Data-Driven Approach for Improving Sustainable Product Development. Sustainability 2023, 15, 6736. [Google Scholar] [CrossRef]
- Wang, Y.; Luo, L.; Liu, H. Bridging the semantic gap between customer needs and design specifications using user-generated content. IEEE Trans. Eng. Manag. 2020, 69, 1622–1634. [Google Scholar] [CrossRef]
- Mohammad, M.N.; Kumari, C.U.; Murthy AS, D.; Jagan BO, L.; Saikumar, K. Implementation of online and offline product selection system using FCNN deep learning: Product analysis. Mater. Today Proc. 2021, 45, 2171–2178. [Google Scholar] [CrossRef]
- Patnaik, S.K.; Babu, C.N.; Bhave, M. Intelligent and adaptive web data extraction system using convolutional and long short-term memory deep learning networks. Big Data Min. Anal. 2021, 4, 279–297. [Google Scholar] [CrossRef]
- Balakrishnan, P.V.; Jacob, V.S. Genetic algorithms for product design. Manag. Sci. 1996, 42, 1105–1117. [Google Scholar] [CrossRef]
- Altiparmak, F.; Gen, M.; Lin, L.; Karaoglan, I. A steady-state genetic algorithm for multi-product supply chain network design. Comput. Ind. Eng. 2009, 56, 521–537. [Google Scholar] [CrossRef]
- Wang, S.T. Integration of a GA and PSO for discussing the impact of 3C product engineering changes on customisation degree. Int. J. Prod. Res. 2012, 50, 4224–4236. [Google Scholar] [CrossRef]
- Guo, J.; Peng, Q.; Zhang, L.; Tan, R.; Zhang, J. Estimation of product success potential using product value. Int. J. Prod. Res. 2021, 59, 5609–5625. [Google Scholar] [CrossRef]
- Yang, W.; Cao, G.; Peng, Q.; Sun, Y. Effective radical innovations using integrated QFD and TRIZ. Comput. Ind. Eng. 2021, 162, 107716. [Google Scholar] [CrossRef]
- Fan, X.; Wang, S.; Wang, J. The value of introducing customer-to-manufacturer model by the online retailer. Int. Trans. Oper. Res. 2022, 29, 2566–2585. [Google Scholar] [CrossRef]
- Tao, F.; Cheng, J.; Qi, Q.; Zhang, M.; Zhang, H.; Sui, F. Digital twin-driven product design, manufacturing and service with big data. Int. J. Adv. Manuf. Technol. 2018, 94, 3563–3576. [Google Scholar] [CrossRef]
- Dodds, W.B.; Monroe, K.B.; Grewal, D. Effects of price, brand, and store information on buyers’ product evaluations. J. Mark. Res. 1991, 28, 307–319. [Google Scholar]
- Richardson, P.S.; Dick, A.S. Extrinsic and intrinsic cue effects on perceptions of store brand quality. J. Mark. 1994, 58, 28–36. [Google Scholar] [CrossRef]
- Rao, A.R.; Monroe, K.B. The Moderating Effect of Prior Knowledge on Cue Utilization in Product Evaluations. J. Consum. Res. 1988, 15, 253–264. [Google Scholar] [CrossRef]
- Lee, M.; Lou, J. Consumer response to television commercials: The impact of involvement and background music on brand attitude formation. J. Mark. Res. 1996, 33, 11–24. [Google Scholar]
- Purohit, D.; Srivastava, J. Effect of manufacturer reputation, retailer reputation, and product warranty on consumer judgments of product quality: A cue diagnosticity framework. J. Consum. Psychol. 2001, 10, 123–134. [Google Scholar] [CrossRef]
- Boulding, W.; Kirmani, A. A consumer-side experimental examination of signaling theory: Do consumers perceive warranties as signals of quality? J. Consum. Res. 1993, 20, 111–123. [Google Scholar] [CrossRef]
- Katz, M.L.; Shapiro, C. Technology adoption in the presence of network externalities. J. Political Econ. 1986, 94, 822–841. [Google Scholar] [CrossRef]
- Huang, L.; Dou, Z.; Hu, Y.; Huang, R. Online sales prediction: An analysis with dependency scor-topic sentiment model. IEEE Access 2019, 7, 79791–79797. [Google Scholar] [CrossRef]
- Huang, L.; Dou, Z.; Hu, Y.; Huang, R. Textual analysis for online reviews: A polymerization topic sentiment model. IEEE Access 2019, 7, 91940–91945. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Blei, D.M.; Lafferty, J.D. A correlated topic model of Science. Ann. Appl. Stat. 2007, 1, 17–35. [Google Scholar] [CrossRef]
- Abdelrazek, A.; Eid, Y.; Gawish, E.; Medhat, W.; Hassan, A. Topic modeling algorithms and applications: A survey. Inf. Syst. 2022, 112, 102131. [Google Scholar] [CrossRef]
- Qin, C.; Zeng, X.; Liang, S.; Zhang, K. Do Live Streaming and Online Consumer Reviews Jointly Affect Purchase Intention? Sustainability 2023, 15, 6992. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Onan, A. Sentiment analysis on product reviews based on weighted word embeddings and deep neural networks. Concurr. Comput. Pract. Exp. 2021, 33, e5909. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Dou, Z.; Sun, Y.; Zhu, J.; Zhou, Z. The Evaluation Prediction System for Urban Advanced Manufacturing Development. Systems 2023, 11, 392. [Google Scholar] [CrossRef]
- Wang, Y.H.; Lee, C.H.; Trappey, A.J. Service design blueprint approach incorporating TRIZ and service QFD for a meal ordering system: A case study. Comput. Ind. Eng. 2017, 107, 388–400. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, K.; Dong, X.; Wang, P. A Big Data-Kano and SNA-CRP Based QFD Model: Application to Product Design under Chinese New E-commerce Model. IEEE Trans. Eng. Manag. 2022, 1–15. [Google Scholar] [CrossRef]
- Ha, S.; Geum, Y. Identifying new innovative services using M&A data: An integrated approach of data-driven morphological analysis. Technol. Forecast. Soc. Chang. 2022, 174, 121197. [Google Scholar]
- Jaiswal, E.S. A case study on quality function deployment (QFD). J. Mech. Civ. Eng. 2012, 3, 27–35. [Google Scholar] [CrossRef]
- Chen, Y.; Xie, W.; Zou, X. A binary differential evolution algorithm learning from explored solutions. Neurocomputing 2015, 149, 1038–1047. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Bhattacharyya, M. A combined QFD and integer programming framework to determine attribute levels for conjoint study. Int. J. Prod. Res. 2009, 47, 6633–6649. [Google Scholar] [CrossRef]
- Zhang, L.; Chu, X.; Chen, H.; Yan, B. A data-driven approach for the optimisation of product specifications. Int. J. Prod. Res. 2019, 57, 703–721. [Google Scholar] [CrossRef]
- Reim, W.; Parida, V.; Örtqvist, D. Product–Service Systems (PSS) business models and tactics–a systematic literature review. J. Clean. Prod. 2015, 97, 61–75. [Google Scholar] [CrossRef]
- Li, X.; Wang, Z.; Chen, C.H.; Zheng, P. A data-driven reversible framework for achieving Sustainable Smart product-service systems. J. Clean. Prod. 2021, 279, 123618. [Google Scholar] [CrossRef]
- Pirola, F.; Boucher, X.; Wiesner, S.; Pezzotta, G. Digital technologies in product-service systems: A literature review and a research agenda. Comput. Ind. 2020, 123, 103301. [Google Scholar] [CrossRef]
- Fichter, K.; Lüdeke-Freund, F.; Schaltegger, S.; Schillebeeckx, S.J. Sustainability impact assessment of new ventures: An emerging field of research. J. Clean. Prod. 2022, 384, 135452. [Google Scholar] [CrossRef]
- Park, J.; Hong, E.; Park, Y.N. Toward a new business model of retail industry: The role of brand experience and brand authenticity. J. Retail. Consum. Serv. 2023, 74, 103426. [Google Scholar] [CrossRef]
- Sharma, S.; Koehl, L.; Bruniaux, P.; Zeng, X.; Wang, Z. Development of an intelligent data-driven system to recommend personalized fashion design solutions. Sensors 2021, 21, 4239. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Product Attribution | Reference |
|---|---|
| Price | Dodds, W. B., Monroe, K. B., and Grewal, D. (1991) [14] |
| Brand | Richardson, P. S. and Dick, A. S. (1994) [15] |
| Durability | Rao, A. R. and Monroe, K. B. (1988) [16] |
| Quality | Lee, M. and Lou, J. (1996) [17] |
| Warranty | Purohit, D. and Srivastava, J. (2001) [18] |
| Advertising | Boulding, W. and Kirmani, A. (1993) [19] |
| Compatibility | Katz, M. L. and Shapiro, C. (1986) [20] |
| ASIN | Category | Reviews | Price |
|---|---|---|---|
| B09MV3M4GL | Cell phones and accessories | 11,899 | 51.62 |
| B07PZSXL9J | Cell phone wall chargers | 8017 | 39.99 |
| B01IUTIUEA | Cell phone wall chargers | 5660 | 39.99 |
| B00P933OJC | Cell phone wall chargers | 3765 | 30.99 |
| B07D64QLQ1 | Laptop chargers and adapters | 3754 | 25.99 |
| B097PTBB5V | Laptop chargers and adapters | 3744 | 29.99 |
| B07ZCGYP27 | Cell phone wall chargers | 2928 | 54.99 |
| B08KTG9L3H | Chargers and adapters | 2444 | 49.99 |
| B07VSMK849 | Cell phone wall chargers | 2150 | 24.53 |
| B07DFGXLY4 | Cell phone wall chargers | 2120 | 119.99 |
| B08YJLMQGD | Cell phone wall chargers | 2047 | 49.99 |
| Topic 1: Brand | Topic 2: Charging Speed | Topic 3: Price | Topic 4: Certification | Topic 5: Quality and Durability | |
|---|---|---|---|---|---|
| 1 | Anker | Charged fast | Cheap | TUV certification | Break your phone |
| 2 | Samsung | Charges fast | Expensive | IEC 62368-1 | Robust noise immunity |
| 3 | Nekteck | Charging efficiency | Pricy | USB-IF | Overcurrent protection |
| 4 | Apple | Charging speed | Affordable | UL certification | Died |
| 5 | Spigen | Charging time | Cost-effective | UE | Quit working |
| 6 | Innergie | Consistent power | Reasonable | FCC | Spotty |
| 7 | Syncwire | Efficiently | Costly | SGS NA listed | Stop charging |
| 8 | Nekmit | Enough power | Inexpensive | DOE Level VI | Stopped working |
| 9 | ZMI | Fast | Awesome price | CE | Well built |
| 10 | TECKNET | Fast charge | Cheaper | ETL | Temperature |
| 11 | Baseus | Have a fast charge | Reasonably priced | RoHS | Worked flawlessly |
| 12 | UGREEN | High-speed charging | Great value for money | PSE Certificate | Pitched sound |
| 13 | Hyphen-X | Lose power | Great price | PD 3.0 | Sketchy |
| 14 | AOHI | Max output | Good price | PDO | Terrific |
| 15 | Ixcv | Powerful | Pricey | PPS | Charge intermittently |
| ASIN | Category | Review | Title | Rating |
|---|---|---|---|---|
| B07D64QLQ1 | USB-C Power adapter/charger Above 60 W | Now that most brands are switching to USB-C (apple included), it’s really ridiculous that brands still charge absurd amounts of money for their own-brand charger. This will charge any 65 w device regardless of brand for a fraction of the price. Beautifully made; I plan to buy more. | Don’t buy anything else | 5 |
| B07D64QLQ1 | USB-C Power adapter/charger Above 60 W | It works with the dell xps13. What I like is the compact nature of it—the small form factor is great for travel. Excellent. However, for travel and a future where you’ll be in coffee shops doing work, a longer cord is needed. It looks to be about a three-foot cord which barely stretches from a floor outlet to your device. Wish it came with a 6- or 10-foot cord. | Good charger, short cord | 4 |
| B07D64QLQ1 | USB-C Power adapter/charger Above 60 W | Works great. I bought it as a spare charger. for my thinkpad, but it also charges my HP and several other USB-C devices. | Works great | 5 |
| Model Names | Hyperparameter Names | Hyperparameter Values |
|---|---|---|
| LDA | LDA numbers N-gram Maximum size of N-gram dictionary | {5, 2, 20,000} |
| CNN | Padding Pool size | {same, 2} |
| LSTM | Activation Dropout rate Timesteps Hidden nodes Learning rate Number of iteration | {relu,0.3,13,100,0.001,100} |
| LightGBM | Maximum number of leaf tree Maximum number of sample leaf node Learning rate Total number of trees constructed | {20,10,0.2,100} |
| Model | MAE | RMSE | RSE | RAE | Coefficient of Determination | Time * |
|---|---|---|---|---|---|---|
| LSTM | 1.10 | 1.35 | 1.00 | 0.98 | 1.03% | 5765 |
| CNN | 1.10 | 1.34 | 0.99 | 0.98 | 1.25% | 1240 |
| CNN-LSTM | 1.09 | 1.34 | 0.99 | 0.98 | 2.34% | 3482 |
| LDA-LightGBM | 1.08 | 1.33 | 0.98 | 0.98 | 3.15% | 403 |
| Training Radio% | Model | Topic 1 Brand | Topic 2 Charging Speed | Topic 3 Price | Topic 4 Certification | Topic 5 Quality and Durability |
|---|---|---|---|---|---|---|
| 70 | LSTM | 1.36 | 1.35 | 1.35 | 1.35 | 1.35 |
| CNN | 1.34 | 1.34 | 1.34 | 1.34 | 1.34 | |
| CNN-LSTM | 1.34 | 1.34 | 1.34 | 1.34 | 1.34 | |
| LDA-LightGBM | 1.34 | 1.33 | 1.33 | 1.33 | 1.33 | |
| 80 | LSTM | 1.36 | 1.35 | 1.35 | 1.35 | 1.35 |
| CNN | 1.35 | 1.34 | 1.34 | 1.34 | 1.34 | |
| CNN-LSTM | 1.35 | 1.34 | 1.34 | 1.34 | 1.34 | |
| LDA-LightGBM | 1.34 | 1.33 | 1.33 | 1.34 | 1.33 | |
| 90 | LSTM | 1.36 | 1.35 | 1.35 | 1.35 | 1.35 |
| CNN | 1.35 | 1.34 | 1.34 | 1.34 | 1.34 | |
| CNN-LSTM | 1.35 | 1.34 | 1.34 | 1.34 | 1.34 | |
| LDA-LightGBM | 1.34 | 1.33 | 1.33 | 1.34 | 1.33 |
| Ranking | Customer Needs |
|---|---|
| 1 | Price |
| 2 | Charging speed |
| 3 | Certification |
| 4 | Quality and durability |
| 5 | Brand |
| Ranking | Product attributes |
| 1 | Wattage |
| 2 | Size |
| 3 | USB ports |
| 4 | Weight |
| 5 | Compatible devices |
| 6 | GaN |
| Topic | GaN | Wattage | Compatible Devices | Size | USB- Ports | Weight |
|---|---|---|---|---|---|---|
| Brand | 0.63% | 0.15% | 0.12% | 1.41% | 0.55% | 0.52% |
| Charging speed | 1.03% | 0.01% | 0.02% | 0.02% | 0.69% | 0.65% |
| Price | 0% | 0% | 0% | 0.01% | 0.01% | 0% |
| Certification | 1.11% | 0.11% | 0.11% | 0.86% | 0.75% | 0.06% |
| Quality and durability | 1.14% | 0.03% | 0.03% | 0.25% | 0.59% | 0.06% |
| Product Attributes | Product Specification | Product Utility |
|---|---|---|
| GaN | GaN I | 133 |
| GaN II | 66 | |
| GaN III | 25 | |
| Wattage | A1 Max 20 W | 485 |
| A2 Max 20 W | 485 | |
| A3 Max 20 W | 485 | |
| C3 Max 18 W | 284 | |
| A2 Max 12 W | 283 | |
| Compatible devices | PD3.0 | 257 |
| QC4.0 | 111 | |
| PowerIQ 3.0 | 120 | |
| PPS | 178 | |
| SCP | 69 | |
| Size | 4.19 × 3.37 × 1.34 inches | 886 |
| 3.5 × 4.5 × 1.3 inches | 501 | |
| 3.54 × 3.41 × 0.79 inches | 488 | |
| 2.09 × 1.6 × 1.17 inches | 370 | |
| 2.56 × 2.56 × 1.3 inches | 304 | |
| 2.95 × 1.42 × 1.26 inches | 264 | |
| USB ports | 1C | 203 |
| 1C1A | 57 | |
| 2C | 135 | |
| 2C1A | 250 | |
| 3C1A | 289 | |
| 1C3A | 488 | |
| 2C2A | 264 | |
| 4C | 25 | |
| Weight | 2.99 ounces | 164 |
| 4.6 ounces | 154 | |
| 13.4 ounces | 153 | |
| 2.88 ounces | 148 | |
| 2.1 ounces | 148 |
| Sales Volume of This Product Specification /Mainstream Market Specification | This Specification Represents the Mainstream Standard in the Target Market | This Specification Does Not Align with the Mainstream Standards in the Target Market |
|---|---|---|
| This product specification leads to higher sales volume in the target market | Continuously optimize the product specifications, while exercising caution to avoid entering oversaturated and highly competitive markets. | Conduct a cost assessment to determine its feasibility for investment in research and development. The product specification may potentially target blue ocean markets. |
| This product specification results in a lower sales volume in the target market | Conduct a cost assessment of the technical specification to evaluate its feasibility for investment in research and development. | Monitor and gather feedback from both buyers and sellers of the products. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.-C.; Guo, R.-S.; Chen, C. An Integrated Data-Driven Procedure for Product Specification Recommendation Optimization with LDA-LightGBM and QFD. Sustainability 2023, 15, 13642. https://doi.org/10.3390/su151813642
Wang T-C, Guo R-S, Chen C. An Integrated Data-Driven Procedure for Product Specification Recommendation Optimization with LDA-LightGBM and QFD. Sustainability. 2023; 15(18):13642. https://doi.org/10.3390/su151813642
Chicago/Turabian StyleWang, Tzu-Chien, Ruey-Shan Guo, and Chialin Chen. 2023. "An Integrated Data-Driven Procedure for Product Specification Recommendation Optimization with LDA-LightGBM and QFD" Sustainability 15, no. 18: 13642. https://doi.org/10.3390/su151813642
APA StyleWang, T.-C., Guo, R.-S., & Chen, C. (2023). An Integrated Data-Driven Procedure for Product Specification Recommendation Optimization with LDA-LightGBM and QFD. Sustainability, 15(18), 13642. https://doi.org/10.3390/su151813642