
Machine Learning Assessment of Damage Grade for Post-Earthquake Buildings: A Three-Stage Approach Directly Handling Categorical Features

Abstract
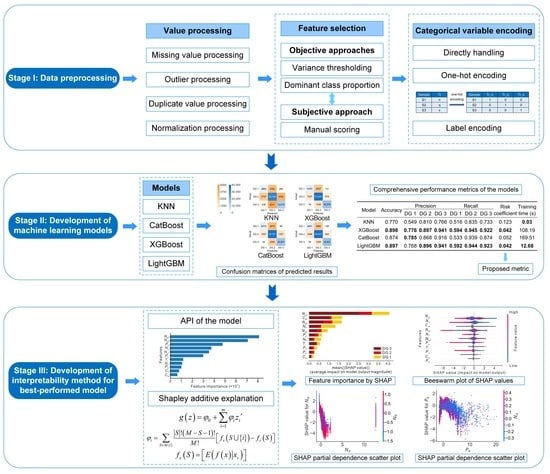
:
1. Introduction
2. Overview of Machine Learning and Interpretability Methods
2.1. Machine Learning Methods
2.1.1. K-Nearest Neighbors (KNNs)
- (1)
- Determine the distance between each training and test set of data;
- (2)
- Sort by the increasing distance;
- (3)
- Choose the K points with the shortest distance;
- (4)
- Determine the frequency of occurrence of the category in which the first K points belong;
- (5)
- Provide the data class that appears the most frequently in the first K points as the classification result of the test data.
2.1.2. Extreme Gradient Boosting (XGBoost)
2.1.3. Categorical Boosting (CatBoost)
2.1.4. Light Gradient Boosting Machine (LightGBM)
2.2. Machine Learning Evaluation Metrics
2.3. Interpretability Method: Shapely Additive Explanations
3. Modeling of Damage Grade Assessment for Buildings
3.1. Stage I: Data Preprocessing
3.1.1. Missing Value Processing
3.1.2. Outlier Processing
3.1.3. Duplicate Value Processing
3.1.4. Normalization Processing
3.1.5. Feature Selection
3.1.6. Categorical Variable Encoding
3.2. Stage II: Development of the Machine Learning Models
3.3. Stage III: Development of the Interpretability Method for the Best-Performing Model
4. Conclusions
- (1)
- An integrated data preprocessing framework combined with subjective–objective feature selection was proposed to accelerate the model training and prediction without losing an excessive amount of accuracy, providing a reference for similar problems.
- (2)
- The LightGBM and CatBoost models directly handle categorical features with training times of 12.68 s and 169.51 s, while the XGBoost model tackles features by one-hot encoding with a training time of 108.19 s. Given the guarantee of accuracy, the algorithms in LightGBM for handling categorical features can significantly accelerate training, while those in CatBoost instead increase the training time for this problem.
- (3)
- The LightGBM and XGBoost models have the highest accuracies of 0.897 and 0.898, followed by the CatBoost model with 0.874. The KNN model may be less appropriate for this problem, with an accuracy of only 0.770.
- (4)
- The risk coefficient was proposed to evaluate the safety of the model classification quantitatively, and the risk coefficients of the KNN, XGBoost, CatBoost, and LightGBM models were 0.123, 0.042, 0.052, and 0.042. The safety of the XGBoost and LightGBM models was the highest.
- (5)
- Comparing the accuracy, precision, recall, risk coefficient, and training time of the four models, the LightGBM model has the best overall performance.
- (6)
- To visualize the mechanism of the LightGBM model by its API and SHAP, the six most essential features are Ng2, Ng1, Ng3, Na, Pa, and Css. The impact of Ng1, Ng2, and Ng3 variations on the model output are all compound, while that of other features is related to the specific damage grade, presenting a monotonic or compound influence.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cariolet, J.-M.; Vuillet, M.; Diab, Y. Mapping Urban Resilience to Disasters—A Review. Sustain. Cities Soc. 2019, 51, 101746. [Google Scholar] [CrossRef]
- Han, L.; Ma, Q.; Zhang, F.; Zhang, Y.; Zhang, J.; Bao, Y.; Zhao, J. Risk Assessment of An Earthquake-Collapse-Landslide Disaster Chain by Bayesian Network and Newmark Models. Int. J. Environ. Res. Public. Health 2019, 16, 3330. [Google Scholar] [CrossRef] [PubMed]
- Qiang, Y.; Huang, Q.; Xu, J. Observing Community Resilience from Space: Using Nighttime Lights to Model Economic Disturbance and Recovery Pattern in Natural Disaster. Sustain. Cities Soc. 2020, 57, 102115. [Google Scholar] [CrossRef]
- DesRoches, R.; Comerio, M.; Eberhard, M.; Mooney, W.; Rix, G.J. Overview of the 2010 Haiti Earthquake. Earthq. Spectra 2011, 27, 1–21. [Google Scholar] [CrossRef]
- Chaulagain, H.; Gautam, D.; Rodrigues, H. Chapter 1—Revisiting Major Historical Earthquakes in Nepal: Overview of 1833, 1934, 1980, 1988, 2011, and 2015 Seismic Events. In Impacts and Insights of the Gorkha Earthquake; Gautam, D., Rodrigues, H., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; pp. 1–17. ISBN 978-0-12-812808-4. [Google Scholar]
- Chen, W.; Rao, G.; Kang, D.; Wan, Z.; Wang, D. Early Report of the Source Characteristics, Ground Motions, and Casualty Estimates of the 2023 Mw 7.8 and 7.5 Turkey Earthquakes. J. Earth Sci. 2023, 34, 297–303. [Google Scholar] [CrossRef]
- Omer, S. 2023 Turkey and Syria Earthquake: Facts, FAQs, and How to Help. Available online: https://www.worldvision.org/disaster-relief-news-stories/2023-turkey-and-syria-earthquake-faqs (accessed on 6 June 2023).
- Ningthoujam, M.C.; Nanda, R.P. A GIS System Integrated with Earthquake Vulnerability Assessment of RC Building. Structures 2018, 15, 329–340. [Google Scholar] [CrossRef]
- Khan, S.U.; Qureshi, M.I.; Rana, I.A.; Maqsoom, A. Seismic Vulnerability Assessment of Building Stock of Malakand (Pakistan) Using FEMA P-154 Method. SN Appl. Sci. 2019, 1, 1625. [Google Scholar] [CrossRef]
- Diana, L.; Lestuzzi, P.; Podestà, S.; Luchini, C. Improved Urban Seismic Vulnerability Assessment Using Typological Curves and Accurate Displacement Demand Prediction. J. Earthq. Eng. 2021, 25, 1709–1731. [Google Scholar] [CrossRef]
- Ozer, E.; Özcebe, A.G.; Negulescu, C.; Kharazian, A.; Borzi, B.; Bozzoni, F.; Molina, S.; Peloso, S.; Tubaldi, E. Vibration-Based and Near Real-Time Seismic Damage Assessment Adaptive to Building Knowledge Level. Buildings 2022, 12, 416. [Google Scholar] [CrossRef]
- Martínez-Cuevas, S.; Morillo Balsera, M.C.; Benito, B.; Torres, Y.; Gaspar-Escribano, J.; Staller, A.; García-Aranda, C. Assessing Building Habitability after an Earthquake Using Building Typology and Damage Grade. Application in Lorca, Spain. J. Earthq. Eng. 2022, 26, 3417–3439. [Google Scholar] [CrossRef]
- Chaurasia, K.; Kanse, S.; Yewale, A.; Singh, V.K.; Sharma, B.; Dattu, B.R. Predicting Damage to Buildings Caused by Earthquakes Using Machine Learning Techniques. In Proceedings of the 2019 IEEE 9th International Conference on Advanced Computing (IACC 2019), Tiruchirappalli, India, 13–14 December 2019; IEEE: New York, NY, USA, 2019; pp. 81–86. [Google Scholar]
- Chen, W.; Zhang, L. Predicting Building Damages in Mega-Disasters under Uncertainty: An Improved Bayesian Network Learning Approach. Sustain. Cities Soc. 2021, 66, 102689. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, L. Building Vulnerability Assessment in Seismic Areas Using Ensemble Learning: A Nepal Case Study. J. Clean. Prod. 2022, 350, 131418. [Google Scholar] [CrossRef]
- Sajan, K.C.; Bhusal, A.; Gautam, D.; Rupakhety, R. Earthquake Damage and Rehabilitation Intervention Prediction Using Machine Learning. Eng. Fail. Anal. 2023, 144, 106949. [Google Scholar] [CrossRef]
- Zio, E. Prognostics and Health Management (PHM): Where Are We and Where Do We (Need to) Go in Theory and Practice. Reliab. Eng. Syst. Saf. 2022, 218, 108119. [Google Scholar] [CrossRef]
- Wei, P.; Lu, Z.; Song, J. Variable Importance Analysis: A Comprehensive Review. Reliab. Eng. Syst. Saf. 2015, 142, 399–432. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Apley, D.W.; Zhu, J. Visualizing the Effects of Predictor Variables in Black Box Supervised Learning Models. arXiv 2019, arXiv:1612.08468. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Lundberg, S.M.; Erion, G.G.; Lee, S.-I. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv 2019, arXiv:1802.03888. [Google Scholar]
- Bangyal, W.H.; Qasim, R.; Rehman, N.U.; Ahmad, Z.; Dar, H.; Rukhsar, L.; Aman, Z.; Ahmad, J. Detection of Fake News Text Classification on COVID-19 Using Deep Learning Approaches. Comput. Math. Methods Med. 2021, 2021, 5514220. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Cheng, D. Learning k for KNN Classification. ACM Trans. Intell. Syst. Technol. 2017, 8, 1–19. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Wang, R. Efficient KNN Classification With Different Numbers of Nearest Neighbors. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1774–1785. [Google Scholar] [CrossRef] [PubMed]
- Salvador–Meneses, J.; Ruiz–Chavez, Z.; Garcia–Rodriguez, J. Compressed KNN: K-Nearest Neighbors with Data Compression. Entropy 2019, 21, 234. [Google Scholar] [CrossRef] [PubMed]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN Model-Based Approach in Classification. In Proceedings of the On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE, Sicily, Italy, 3–7 November 2003; Meersman, R., Tari, Z., Schmidt, D.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Elith, J.; Leathwick, J.R.; Hastie, T. A Working Guide to Boosted Regression Trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Fatahi, R.; Nasiri, H.; Homafar, A.; Khosravi, R.; Siavoshi, H.; Chelgani, S. Modeling Operational Cement Rotary Kiln Variables with Explainable Artificial Intelligence Methods—A “Conscious Lab” Development. Part. Sci. Technol. 2022, 41, 715–724. [Google Scholar] [CrossRef]
- Le, T.-T.-H.; Oktian, Y.; Kim, H. XGBoost for Imbalanced Multiclass Classification-Based Industrial Internet of Things Intrusion Detection Systems. Sustainability 2022, 14, 8707. [Google Scholar] [CrossRef]
- Nasiri, H.; Alavi, S.A. A Novel Framework Based on Deep Learning and ANOVA Feature Selection Method for Diagnosis of COVID-19 Cases from Chest X-Ray Images. Comput. Intell. Neurosci. 2022, 2022, e4694567. [Google Scholar] [CrossRef]
- Fatahi, R.; Nasiri, H.; Dadfar, E.; Chelgani, S. Modeling of Energy Consumption Factors for an Industrial Cement Vertical Roller Mill by SHAP-XGBoost: A “Conscious Lab” Approach. Sci. Rep. 2022, 12, 7543. [Google Scholar] [CrossRef]
- Alajmi, M.S.; Almeshal, A.M. Predicting the Tool Wear of a Drilling Process Using Novel Machine Learning XGBoost-SDA. Materials 2020, 13, 4952. [Google Scholar] [CrossRef]
- Wan, Z.; Xu, Y.; Šavija, B. On the Use of Machine Learning Models for Prediction of Compressive Strength of Concrete: Influence of Dimensionality Reduction on the Model Performance. Materials 2021, 14, 713. [Google Scholar] [CrossRef]
- Xu, B.; Tan, Y.; Sun, W.; Ma, T.; Liu, H.; Wang, D. Study on the Prediction of the Uniaxial Compressive Strength of Rock Based on the SSA-XGBoost Model. Sustainability 2023, 15, 5201. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 31. [Google Scholar]
- Zhang, M.; Chen, W.; Yin, J.; Feng, T. Health Factor Extraction of Lithium-Ion Batteries Based on Discrete Wavelet Transform and SOH Prediction Based on CatBoost. Energies 2022, 15, 5331. [Google Scholar] [CrossRef]
- Nasiri, H.; Tohry, A.; Heidari, H. Modeling Industrial Hydrocyclone Operational Variables by SHAP-CatBoost—A “Conscious Lab” Approach. Powder Technol. 2023, 420, 118416. [Google Scholar] [CrossRef]
- Kim, B.; Lee, D.-E.; Hu, G.; Natarajan, Y.; Preethaa, S.; Rathinakumar, A.P. Ensemble Machine Learning-Based Approach for Predicting of FRP–Concrete Interfacial Bonding. Mathematics 2022, 10, 231. [Google Scholar] [CrossRef]
- Yin, J.; Zhao, J.; Song, F.; Xu, X.; Lan, Y. Processing Optimization of Shear Thickening Fluid Assisted Micro-Ultrasonic Machining Method for Hemispherical Mold Based on Integrated CatBoost-GA Model. Materials 2023, 16, 2683. [Google Scholar] [CrossRef] [PubMed]
- Asad, R.; Altaf, S.; Ahmad, S.; Shah Noor Mohamed, A.; Huda, S.; Iqbal, S. Achieving Personalized Precision Education Using the Catboost Model during the COVID-19 Lockdown Period in Pakistan. Sustainability 2023, 15, 2714. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Liang, W.; Luo, S.; Zhao, G.; Wu, H. Predicting Hard Rock Pillar Stability Using GBDT, XGBoost, and LightGBM Algorithms. Mathematics 2020, 8, 765. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, H.; Sun, J.; Tang, Y. Digital Inclusive Finance and Family Wealth: Evidence from LightGBM Approach. Sustainability 2022, 14, 15363. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, Q.; Ma, Q.; Yu, B. LightGBM-PPI: Predicting Protein-Protein Interactions through LightGBM with Multi-Information Fusion. Chemom. Intell. Lab. Syst. 2019, 191, 54–64. [Google Scholar] [CrossRef]
- Daoud, E.A. Comparison between XGBoost, LightGBM and CatBoost Using a Home Credit Dataset. Int. J. Comput. Inf. Eng. 2019, 13, 6–10. [Google Scholar]
- Hu, Y.; Sun, Z.; Han, Y.; Li, W.; Pei, L. Evaluate Pavement Skid Resistance Performance Based on Bayesian-LightGBM Using 3D Surface Macrotexture Data. Materials 2022, 15, 5275. [Google Scholar] [CrossRef] [PubMed]
- Mangalathu, S.; Hwang, S.-H.; Jeon, J.-S. Failure Mode and Effects Analysis of RC Members Based on Machine-Learning-Based SHapley Additive ExPlanations (SHAP) Approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Rafferty, J.P. Nepal Earthquake of 2015. Available online: https://www.britannica.com/topic/Nepal-earthquake-of-2015 (accessed on 12 July 2023).
- Bull, P.; Slavitt, I.; Lipstein, G. Harnessing the Power of the Crowd to Increase Capacity for Data Science in the Social Sector. arXiv 2016, arXiv:1606.07781. [Google Scholar]
- Li, Y.; Qin, Y.; Wang, H.; Xu, S.; Li, S. Study of Texture Indicators Applied to Pavement Wear Analysis Based on 3D Image Technology. Sensors 2022, 22, 4955. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- DrivenData Richter’s Predictor: Modeling Earthquake Damage. Available online: https://www.drivendata.org/competitions/57/nepal-earthquake/page/136/ (accessed on 11 July 2023).
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; van der Walt, S., Millman, J., Eds.; 2010; pp. 56–61. [Google Scholar]
- Waskom, M.L. Seaborn: Statistical Data Visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Nguyen, H.D.; LaFave, J.M.; Lee, Y.-J.; Shin, M. Rapid Seismic Damage-State Assessment of Steel Moment Frames Using Machine Learning. Eng. Struct. 2022, 252, 113737. [Google Scholar] [CrossRef]
- Ghimire, S.; Gueguen, P.; Giffard-Roisin, S.; Schorlemmer, D. Testing Machine Learning Models for Seismic Damage Prediction at a Regional Scale Using Building-Damage Dataset Compiled after the 2015 Gorkha Nepal Earthquake. Earthq. Spectra 2022, 38, 2970–2993. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Identifier | Type | Description | Possible Values |
|---|---|---|---|---|
| geo_level_1_id | Ng1 | int | from broadest (level 1) to narrowest (level 3) in terms of the building’s geographical location | 0–30 |
| geo_level_2_id | Ng2 | 0–1427 | ||
| geo_level_3_id | Ng3 | 0–12,567 | ||
| count_floors_pre_eq | Nfl | post-earthquake number of floors of the building | no exact value range | |
| age | Na | number of years the building has been in existence | no exact value range | |
| count_families | Nfa | number of family members residing in the building | 0–9 | |
| area_percentage | Pa | normalized area of the building footprint | no exact value range | |
| height_percentage | Ph | normalized height of the building footprint | no exact value range | |
| land_surface_condition | Cls | categorical | the surface condition of the land for the location of the building | n, o, t. |
| foundation_type | Tf | foundation type of the building | h, i, r, u, w. | |
| roof_type | Tr | roof type of the building | n, q, x. | |
| ground_floor_type | Tg | ground floor type of the building | f, m, v, x, z. | |
| other_floor_type | To | type of constructions utilized for stories above ground level (other than the roof) | j, q, s, x. | |
| position | Pb | position of the building | j, o, s, t. | |
| plan_configuration | Cp | building plan configuration | a, c, d, f, m, n, o, q, s, u. | |
| has_superstructure | Css | the material of the superstructure | am, b, cmb, cms, mmb, mms, o, rce, rcne, sf, t | |
| legal_ownership_status | Clos | legal ownership status of the land for the location of the building | a, r, v, w. | |
| has_secondary_use | Csu | whether the building is being used secondarily and what its specific purpose is | a, go, h, hp, ind, ins, no, o, r, s, up |
| Feature | Ng1 | Ng2 | Ng3 | Nfl | Na | Pa | Ph | Nfa |
|---|---|---|---|---|---|---|---|---|
| Min | 0 | 0 | 0 | 1 | 0 | 1 | 2 | 0 |
| Max | 30 | 1427 | 12,567 | 9 | 995 | 100 | 32 | 9 |
| Standard deviation | 8.07 | 413.05 | 3661.10 | 0.73 | 75.65 | 4.52 | 1.95 | 0.42 |
| Variance | 65.08 | 170,606.27 | 13,403,651.08 | 0.54 | 5723.67 | 20.47 | 3.82 | 0.18 |
| Feature | Cls | Tf | Tr | Tg | To | Pb | Cp | Css | Clos | Csu |
|---|---|---|---|---|---|---|---|---|---|---|
| Proportion | 0.83 | 0.83 | 0.69 | 0.80 | 0.63 | 0.77 | 0.96 | 0.72 | 0.96 | 0.89 |
| Feature | Ng1 | Ng2 | Ng3 | Nfl | Na | Pa | Ph | Nfa | Cls |
| Score | 1 | 1 | 1 | 0.8 | 0.8 | 0.7 | 0.7 | 0.3 | 0.8 |
| Feature | Tf | Tr | Tg | To | Pb | Cp | Css | Clos | Csu |
| Score | 0.7 | 0.5 | 0.7 | 0.4 | 0.6 | 0.6 | 0.7 | 0.4 | 0.3 |
| Model | Accuracy | Detailed Optimal Hyperparameters | |||
|---|---|---|---|---|---|
| Default Hyperparameters | Optimal Hyperparameters | ||||
| Training Set | Test Set | Training Set | Test Set | ||
| KNN | 0.841 | 0.770 | 0.876 | 0.770 | n_neighbors = 3 |
| XGBoost | 0.877 | 0.861 | 0.969 | 0.898 | learning_rate = 0.1, n_estimators = 1200, min_child_weight = 1, gamma = 0, max_depth = 8 |
| CatBoost | 0.858 | 0.849 | 0.908 | 0.874 | depth = 8, learning_rate = 0.15, iterations = 1200 |
| LightGBM | 0.840 | 0.835 | 0.975 | 0.897 | learning_rate = 0.1, n_estimators = 1200, num_leaves = 100, max_depth = 8, colsample_bytree = 0.8, subsample = 0.8 |
| Model | Accuracy | Precision | Recall | Risk Coefficient | Training Time (s) | ||||
|---|---|---|---|---|---|---|---|---|---|
| DG 1 | DG 2 | DG 3 | DG 1 | DG 2 | DG 3 | ||||
| KNN | 0.770 | 0.549 | 0.810 | 0.766 | 0.516 | 0.835 | 0.733 | 0.123 | 0.03 |
| XGBoost | 0.898 | 0.776 | 0.897 | 0.941 | 0.594 | 0.945 | 0.922 | 0.042 | 108.19 |
| CatBoost | 0.874 | 0.785 | 0.868 | 0.916 | 0.533 | 0.939 | 0.874 | 0.052 | 169.51 |
| LightGBM | 0.897 | 0.768 | 0.896 | 0.941 | 0.592 | 0.944 | 0.923 | 0.042 | 12.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Jia, C.; Chen, H.; Su, H.; Chen, J.; Wang, D. Machine Learning Assessment of Damage Grade for Post-Earthquake Buildings: A Three-Stage Approach Directly Handling Categorical Features. Sustainability 2023, 15, 13847. https://doi.org/10.3390/su151813847
Li Y, Jia C, Chen H, Su H, Chen J, Wang D. Machine Learning Assessment of Damage Grade for Post-Earthquake Buildings: A Three-Stage Approach Directly Handling Categorical Features. Sustainability. 2023; 15(18):13847. https://doi.org/10.3390/su151813847
Chicago/Turabian StyleLi, Yutao, Chuanguo Jia, Hong Chen, Hongchen Su, Jiahao Chen, and Duoduo Wang. 2023. "Machine Learning Assessment of Damage Grade for Post-Earthquake Buildings: A Three-Stage Approach Directly Handling Categorical Features" Sustainability 15, no. 18: 13847. https://doi.org/10.3390/su151813847