1. Introduction
The number of vehicles running on fossil fuels is globally increasing with increasing living standards and urbanization rates [
1]. The emission rates (ERs) of such vehicles are also progressively increasing, raising global concerns about the environmental impact of the transportation sector, especially in mega and metropolitan cities [
2]. The ERs of vehicles, including that of carbon monoxide (CO), carbon dioxide (CO
2), and nitrogen oxides (NOx), depend on many factors (e.g., factors related to vehicle design and age). In contrast, others are related to driving conditions, such as driving mode (e.g., idling, acceleration, deceleration, and cruise), ambient conditions, road grade/architecture, traffic conditions, and behavior of the drivers [
3,
4]. Different codes and standards have been proposed or put in action, mostly in the United States (US) and the European Union (EU), to limit the environmental impact of the transportation sector on public health in urban areas. However, any measure to be taken in this regard requires precise measurements and accurate tools for quantifying the on-road ERs to enable certifications and other legislative actions [
5].
Due to the complexity, costs, and skilled labor required for such measurements, predictive models are becoming increasingly popular among researchers and stakeholders, especially in the era of artificial intelligence and the internet-of-things. Smit et al. [
6] classified the models used for predicting vehicular emissions based on the model type, accuracy level, and the set of inputs required for making estimates. They showed that by far, the ‘modal’ and the simple average speed models are the most popular for practical purposes nowadays. However, these models suffer from low accuracy, especially for short-term predictions [
7]. Furthermore, most of the models developed in the literature are primarily used for predicting CO
2 release rates, with less attention paid to other emissions, such as CO, hydrocarbons (HC), and NOx, which arguably have a higher impact on public health [
8]. Part of the reason behind this is the weaker correlations between the rates of these emissions and the commonly used engine parameters, such as engine torque and speed, compared to CO
2 [
5].
Although empirically developed models are limited in terms of accuracy, analytical models excel in this regard. However, analytical models are more complex to develop and use since they require multiple specific inputs that depend on the vehicle under study. Their accuracy comes from the fact that they comprise sub-models of fluid flow, heat transfer, energy balances, and combustion reactions, making them computationally intensive and too specific for general use of on-road and real-time prediction purposes, which are the applications targeted in this study [
5,
9]. However, data-driven machine learning models are expected to solve such problems with non-linear correlations between the model input and output, especially when trained using comprehensive and sufficiently sized datasets.
Various studies have been reported in the literature for predicting vehicular ERs, yet most of those studies were dedicated to estimating the emissions of certain combinations of engine and fuel types. Most of those studies were also carried out on engine test beds, rather than real-world conditions. Molkdaragh et al. [
10] used wavelet neural networks and a stochastic gradient algorithm to correlate the engine power, consumed fuel, emission production, and the concentration of nanoparticles at different speeds for a compression ignition engine working with a nanoparticle diesel fuel. The superiority of the selected algorithm over the back-propagation network and the non-linear autoregressive network with exogenous input (NARX) was demonstrated. The multi-layered perceptron neural network was adopted in another study by Saraee et al. [
11] for correlating engine power and ERs with concentrations of cerium oxide nanoparticles in diesel fuel. Domínguez-Sáez et al. [
12] adopted artificial neural networks and symbolic regression techniques for predicting the CO
2 and NOx emissions of a 2.0 Euro 4 engine working with pure diesel and animal fat fuels and running on a dynamometer test with the NEDC cycle.
Table 1 shows a summary and comparison of the popular algorithms used in the literature for estimating vehicles’ FC and ERs.
Prediction of real-time exhaust emissions under different traffic conditions started to grab the attention of researchers only recently due to the undeniable deviations between synthetic driving cycles of dynamometer tests and real-world driving [
22]. For instance, Ramos et al. [
23] compared the real-world driving NOx emissions of light-duty diesel fuel with the emissions of the same vehicle when running on the new European driving cycle, and revealed a significant difference between the two sets of results. However, available studies that tried to take advantage of the capability of data-driven algorithms in simulating highly stochastic, high-dimensional, real-world vehicles’ data are rare. Wang et al. [
9] developed a vehicle-specific power (VSP)-based neural network model for estimating the emissions of different types of buses operating with different fuels in Zhenjiang, China. Jaikumar et al. [
24] developed another neural network-based model for estimating the emissions of passenger cars running on urban roads in India. On-board measurements were used to train the model based on the inputs of the vehicle’s speed, revolutions per minute, and specific power. Antanasijević et al. [
25] developed a general regression neural network for estimating the emissions of vehicles based on acquired data from 26 European countries. All estimations were found in good agreement with measured data, except for NOx and non-methane volatile organic compounds. Azeez et al. [
26] developed a hybrid model of correlation-based feature selection, support vector machines (SVM), and geographical information system (GIS) data to predict on-road vehicles’ emissions at specific times and locations in Kuala Lumpur. Moradi and Miranda-Moreno [
27] found that the category-specific long short-term memory (LSTM) model outperforms classic approaches in the literature for forecasting the fuel consumption (FC) and ERs of 35 vehicles in three cities in Canada, Iran, and Colombia. As stated in
Table 1, random forest (RF) ensembles are known to be equally precise and stable in similar problems [
28]. They have been used in scarce studies, as demonstrated in
Table 2. It should be noted that the studies summarized in this table have several significant differences other than what is stated in the table, such as the approach and frequency of collecting the data, and the techniques for model development and construction.
Based on this survey of the public literature, it can be stated that:
There is an apparent lack of studies on data-driven models of on-road vehicle emissions rather than emissions of engines running on testbeds due to the immense costs of required measurements, especially in urban areas of developing countries.
For Egypt, such studies are completely lacking, where classic models are used instead, which deviate significantly from real-world driving conditions [
3].
The limited available models of on-road ERs are typically developed based on measurements carried out for specific vehicles or a limited fleet of vehicles, such as in [
20], which limits their extrapolation potential to other vehicles in use in the same area.
Furthermore, these studies are mostly adopting ANN-based models for this purpose, which are known to be prone to overfitting and lack accuracy when carelessly developed.
The RF technique has been employed in [
20] for one vehicle, but its potential in handling large datasets for a diverse fleet of vehicles is still to be addressed.
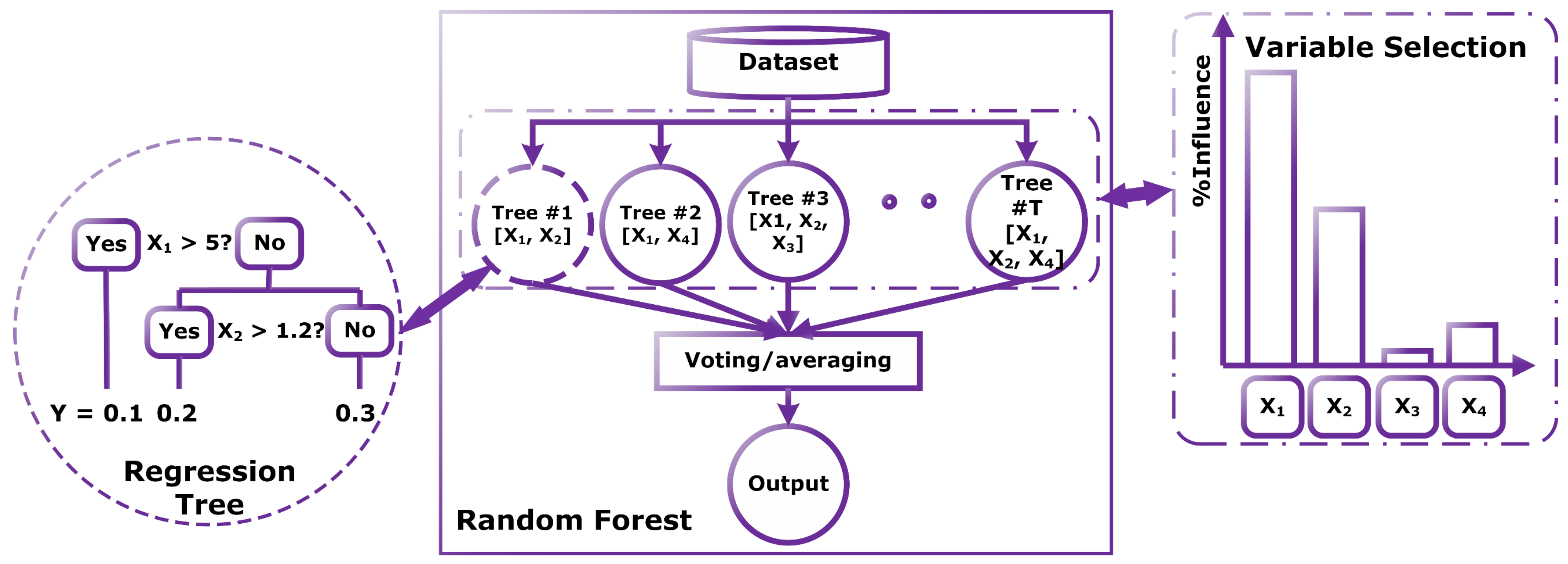
Vehicle category-based models seem to be a good compromise between vehicle-specific models and region-specific models in terms of accuracy and ability to generalize. RF excels in accepting both numerical and categorical inputs while having unbiased estimates. Yet, this has not been explored in the context of the present study to the best of the authors’ knowledge.
Motivated by the aforementioned research gap, the potential of the RF ensemble technique in estimating FC and on-road emissions of different categories of passenger vehicles is investigated in this study. The novelty and contributions of the study can be summarized as follows:
Five ensemble models are developed and validated carefully to estimate FC and emission rates (CO, CO2, NOx, and HC) for lightweight gasoline passenger cars in the metropolitan region of Greater Cairo, Egypt.
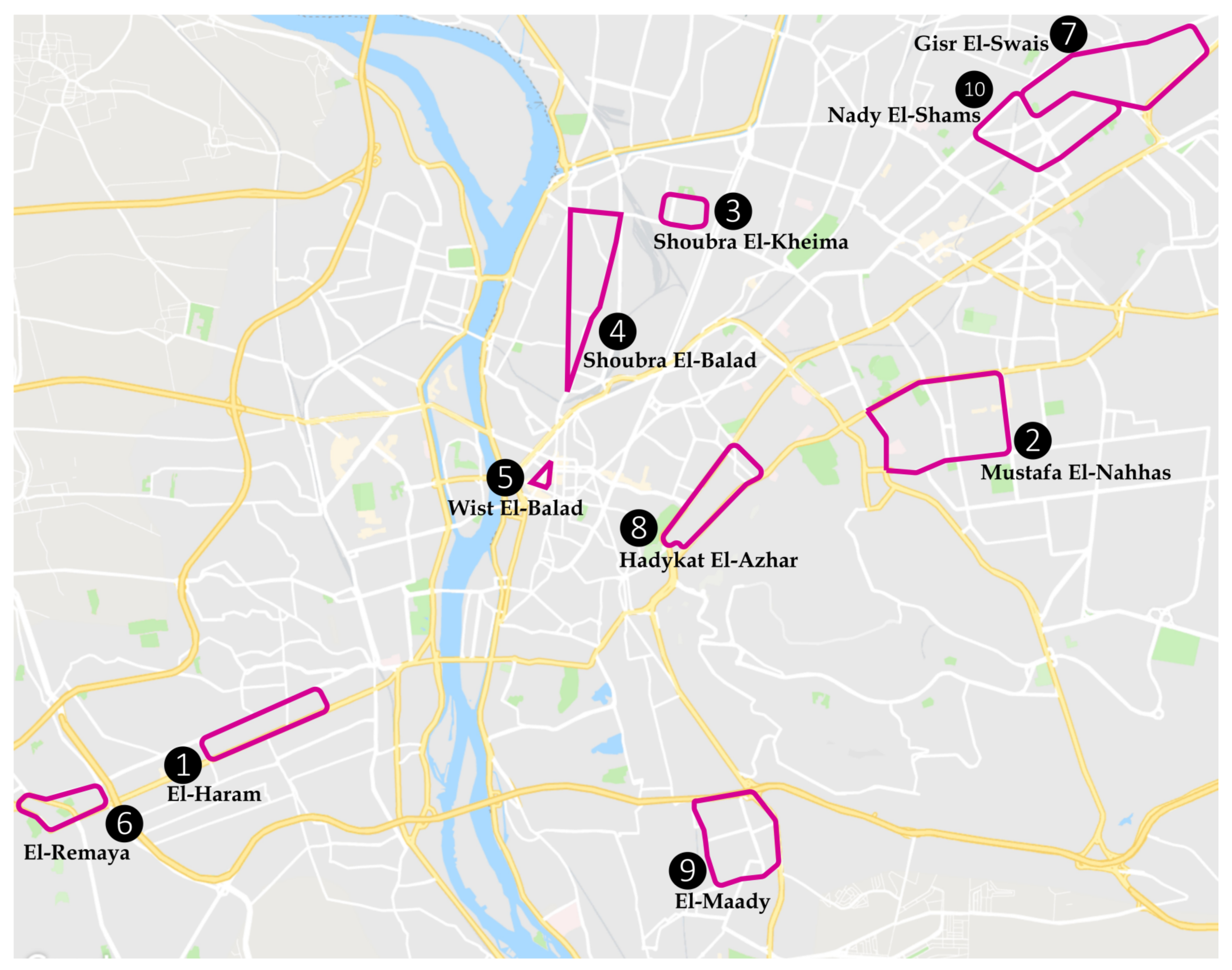
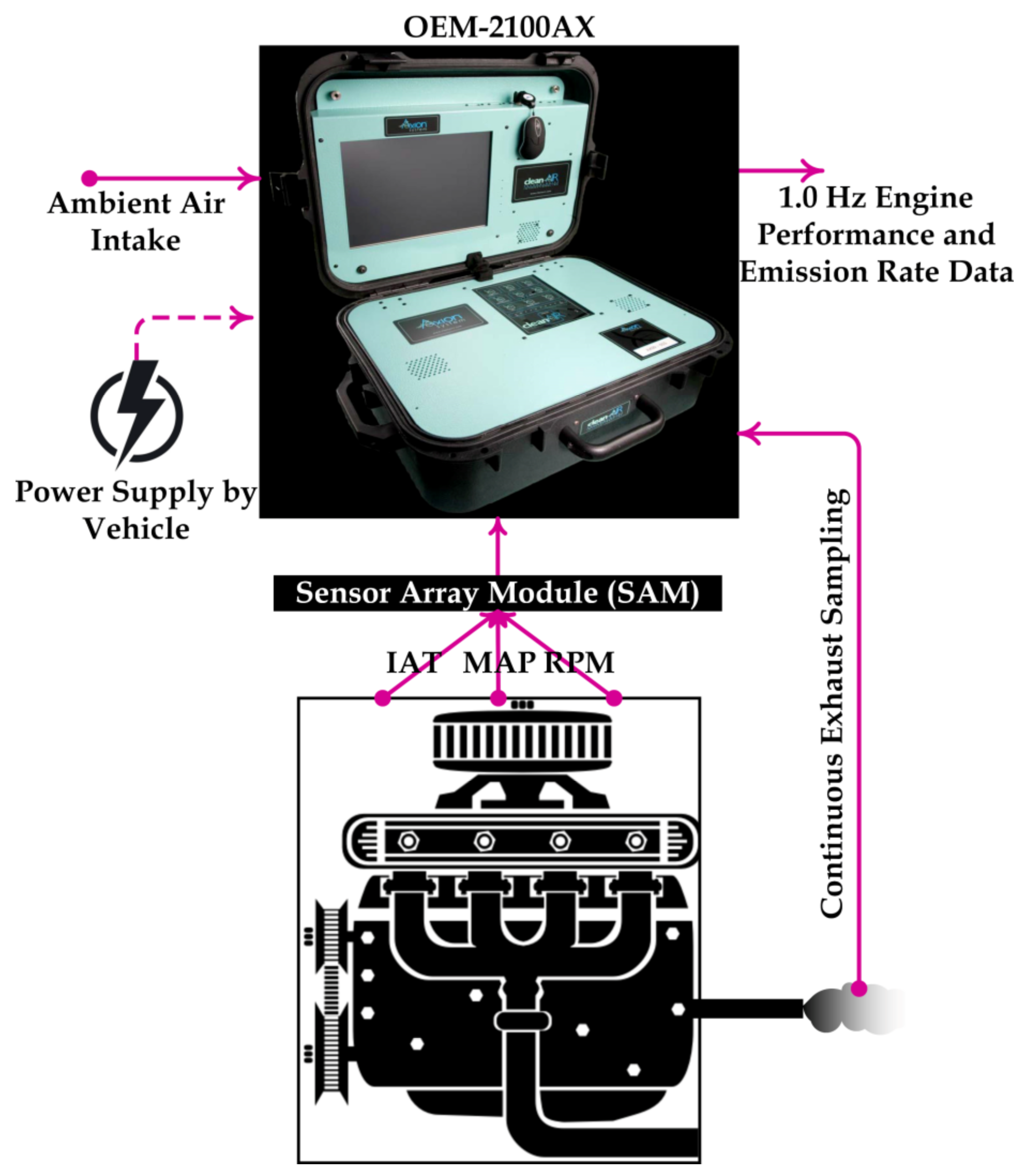
The models are developed based on extensive and precise onboard measurements from 87 vehicles driven over 10 different types of routes in the region.
The proposed models accept both numerical and categorical inputs, and the relative impact of each input variable is demonstrated to examine the potential of simplifying the models or testing their performance in case of incomplete data.
The models are also tested to evaluate their performances in terms of the dataset size (e.g., in the case of limited collected data) and the number of sub-decision trees (to evaluate the model robustness).
Finally, category-specific models were customized to check the possibility of increasing prediction accuracy when focusing on specific vehicle weight, age, and engine type combinations.
Therefore, the developed models can be viewed as sort of general models (in terms of vehicle specifications), customized for the specific characteristics of the study location, or other locations with similar traffic conditions, rather than for specific vehicles. The proposed algorithm is relatively simple and intuitive compared with other data-driven algorithms (such as ANNs), and can be adopted by interested researchers and engineers without deep expertise in machine learning. Such models not only would serve as a valuable tool in estimating the consumed energy and emitted pollutants in the transportation sector but can also help policymakers in planning a more sustainable urban transportation sector.
4. Conclusions
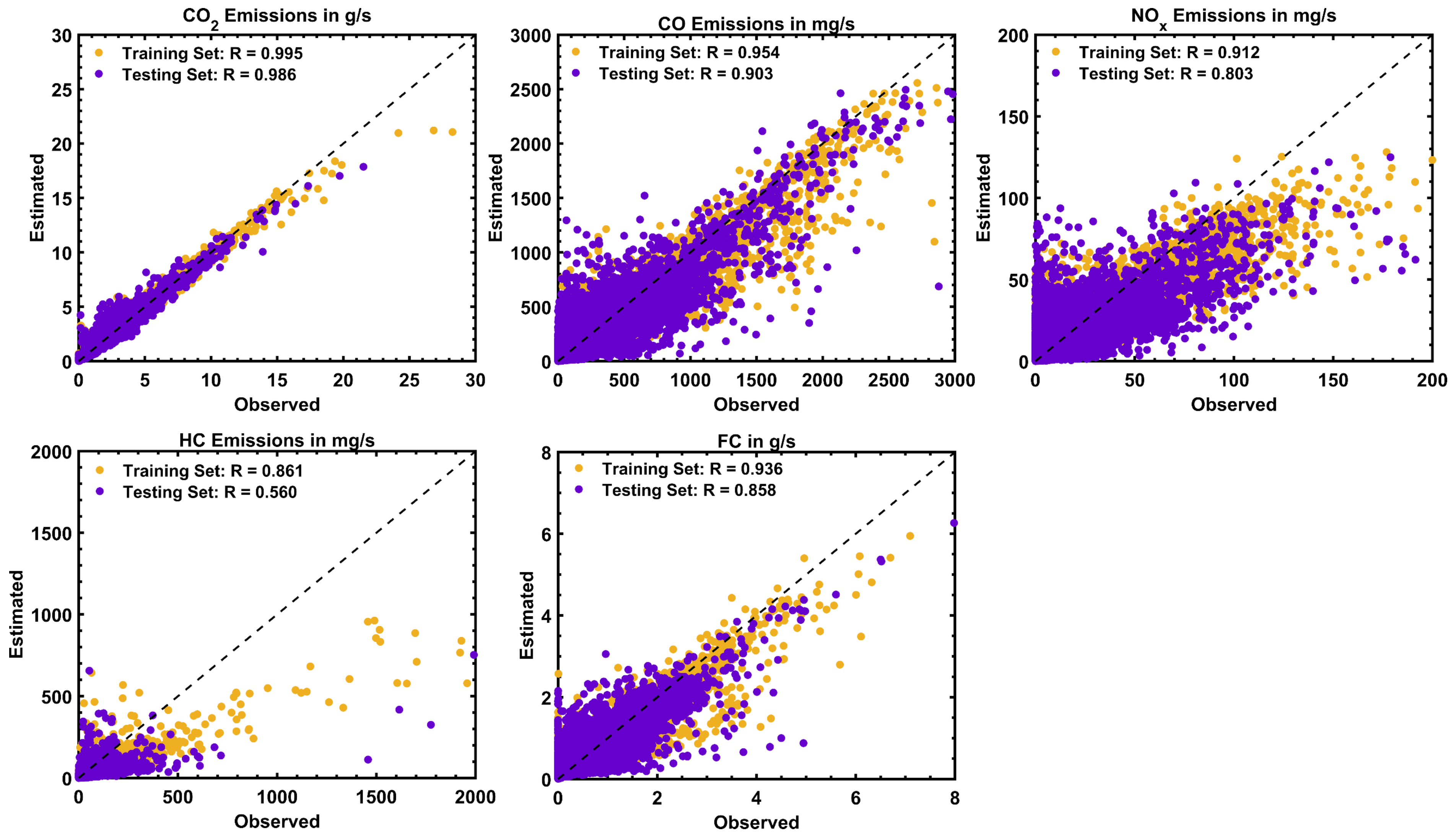
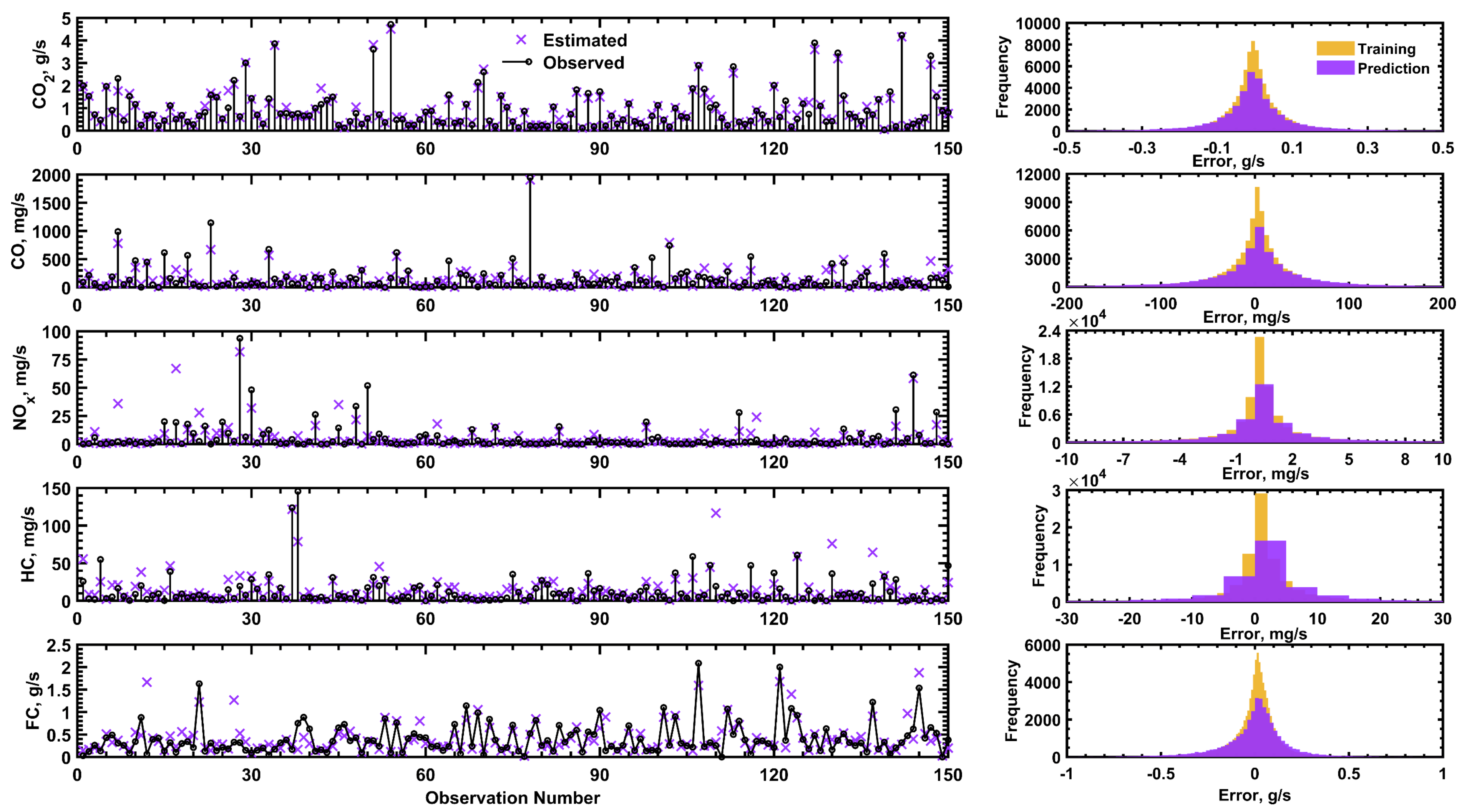
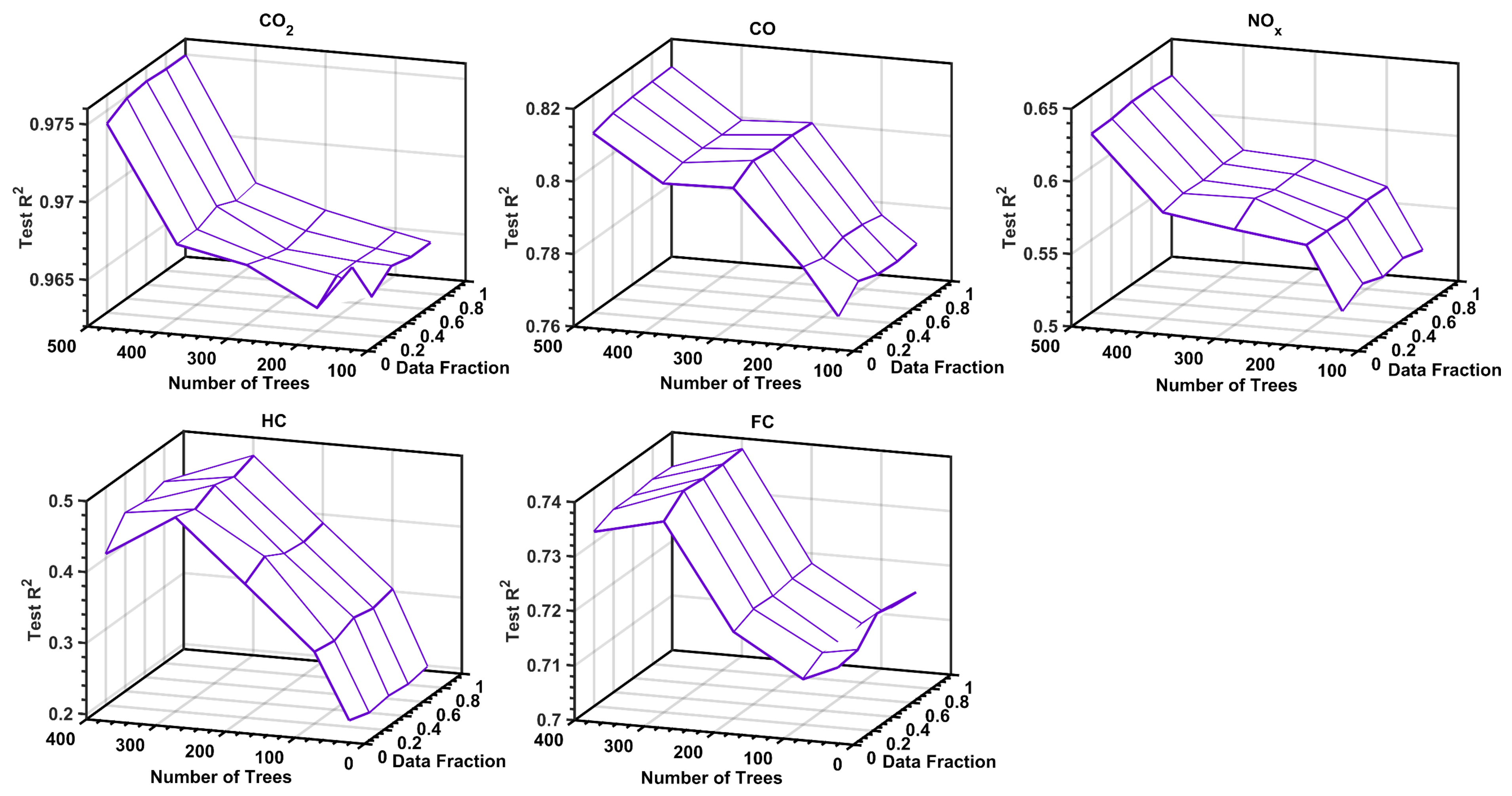
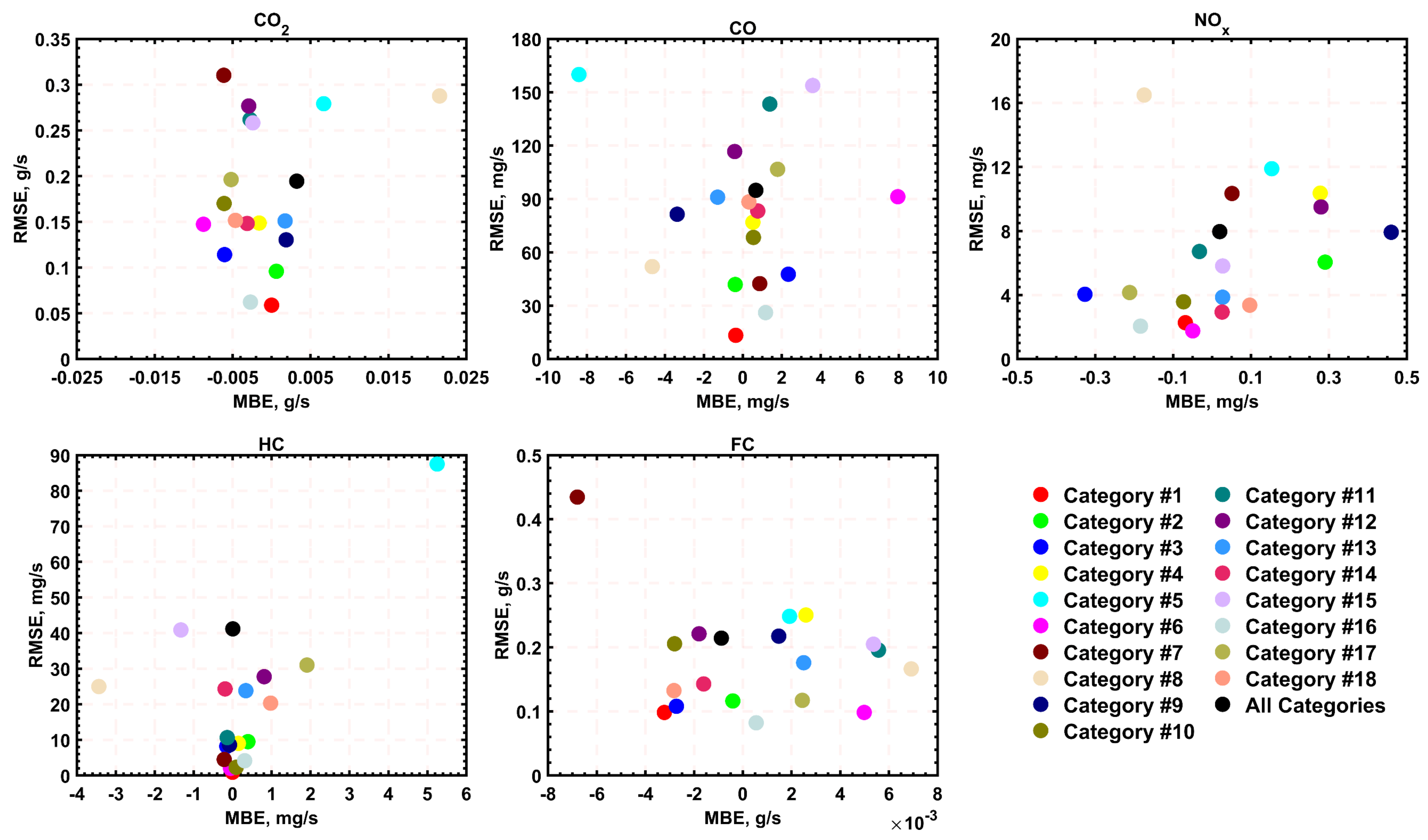
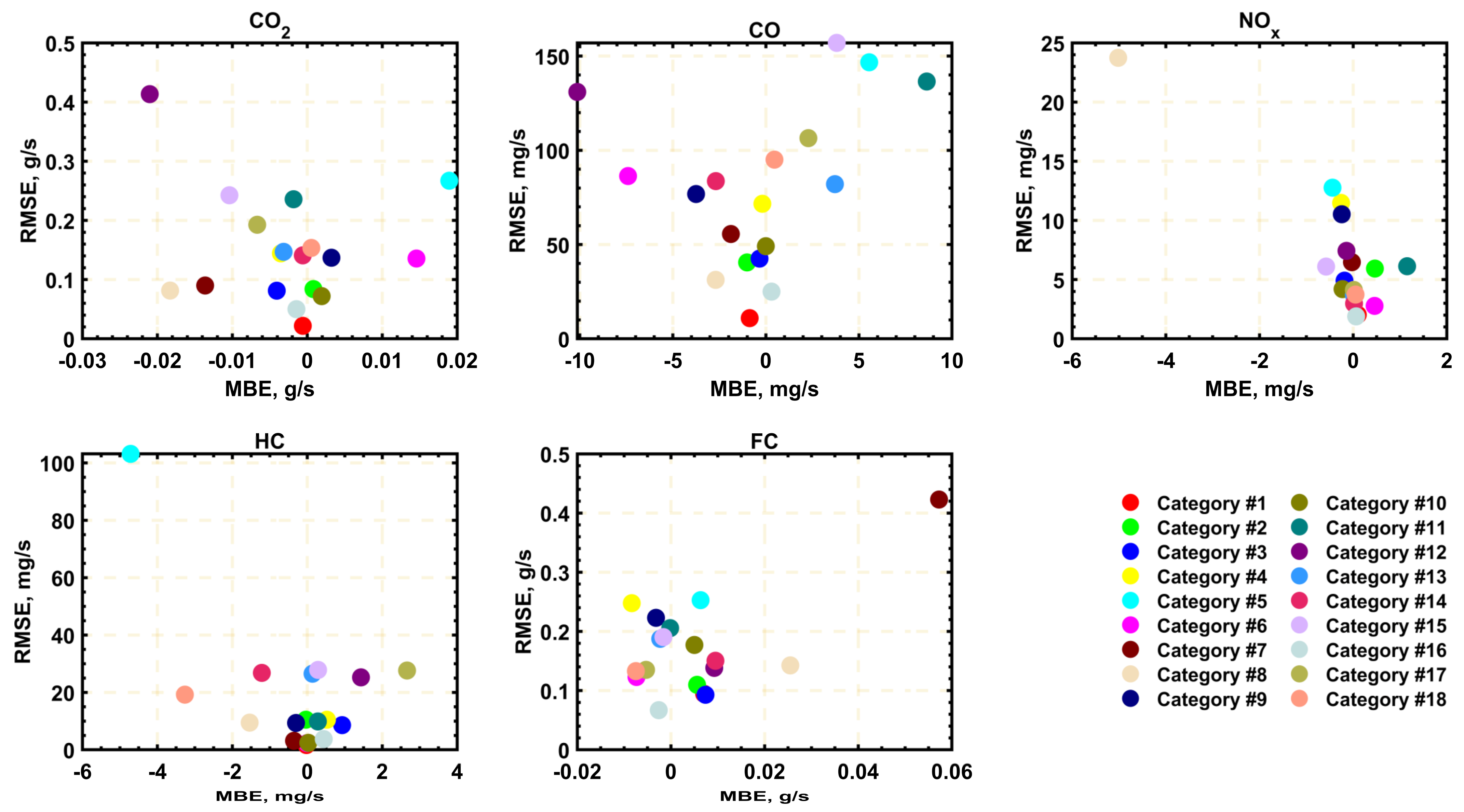
Models for predicting fuel consumption and onboard emission factors of conventional vehicles under real driving and traffic conditions are essential tools for various research and regulatory applications. The objective of this work was to develop the first set of such models for Greater Cairo, Egypt, based on extensive measurements using representative gasoline passenger vehicles and driving routes in the city. Five random forest regressor-based ensemble models were developed to be used for the various models of vehicles in the city. The results showed that RF models are most successful in predicting CO2 emission rates, where they explained more than 97% of the variance in the testing dataset. This was followed by the CO, fuel consumption, and NOx models, all providing satisfactory prediction accuracies. However, the HC model was the least reliable due to the diversity of considered vehicle models and the smaller correlation with input engine variables. It was also found that the prediction performance of those models is less sensitive to the size of the dataset, provided that it is sufficiently large, but considerably dependent on the RF ensemble size (up to 500 regression trees).
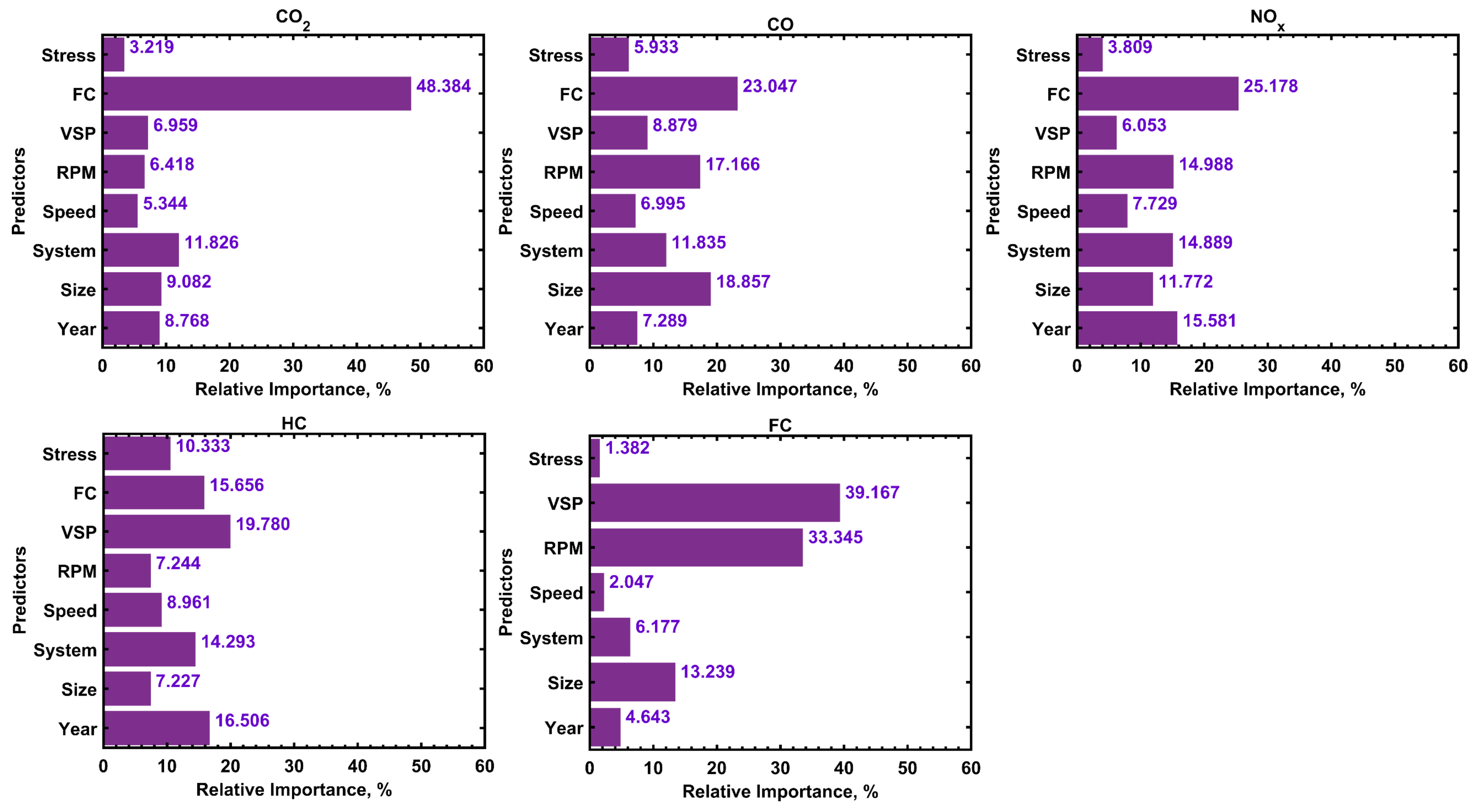
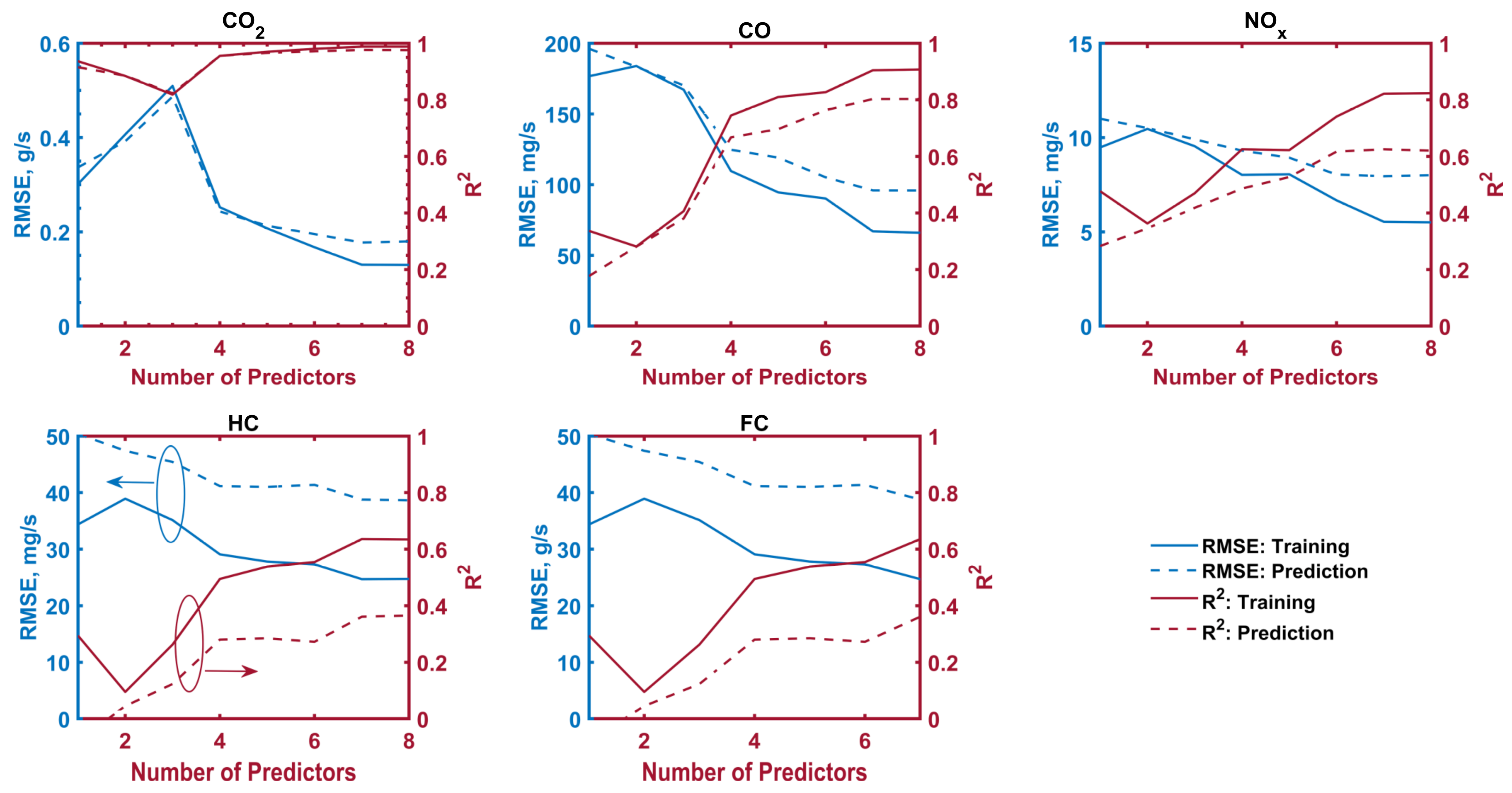
The relative importance of different model inputs has been highlighted for future studies on similar models, where it has been shown that fuel consumption is the most influential input (relative importance of >23%) for CO2, CO, and NOx predictions, followed by the engine speed and the vehicle category. The least influential input was the engine stress (<6%), which can be eliminated while having the same accuracy level. Finally, it has been shown that the accuracy levels of the different models can be boosted by limiting the dataset to specific vehicle categories, where the RMSEs can be reduced by up to 69.7, 85.9, 77.9, 97.8, and 61.6%, compared to the initially developed models of all vehicles.
For future works, specific engine/fuel-based models will be investigated using more complex techniques and additional explanatory variables to enhance the prediction accuracy of emission models. The RF models will be hybridized with optimization algorithms to ensure better stability. Finally, the performance of the models will be analyzed as a function of the traffic conditions, making it possible to develop hyper ensembles comprising sub-models for distinctive traffic conditions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








