To understand how crop values depend on factors that affect rice productivity, we employed seven unique two-dimensional copula models, as outlined in the previous section. These models included the Student-t, Normal, Clayton, Frank, Joe, Gumbel, Galambos, and Husler–Reiss copulas. We derived the parameters for these selected copulas using a two-stage maximum likelihood technique.
3.1. Data Analysis
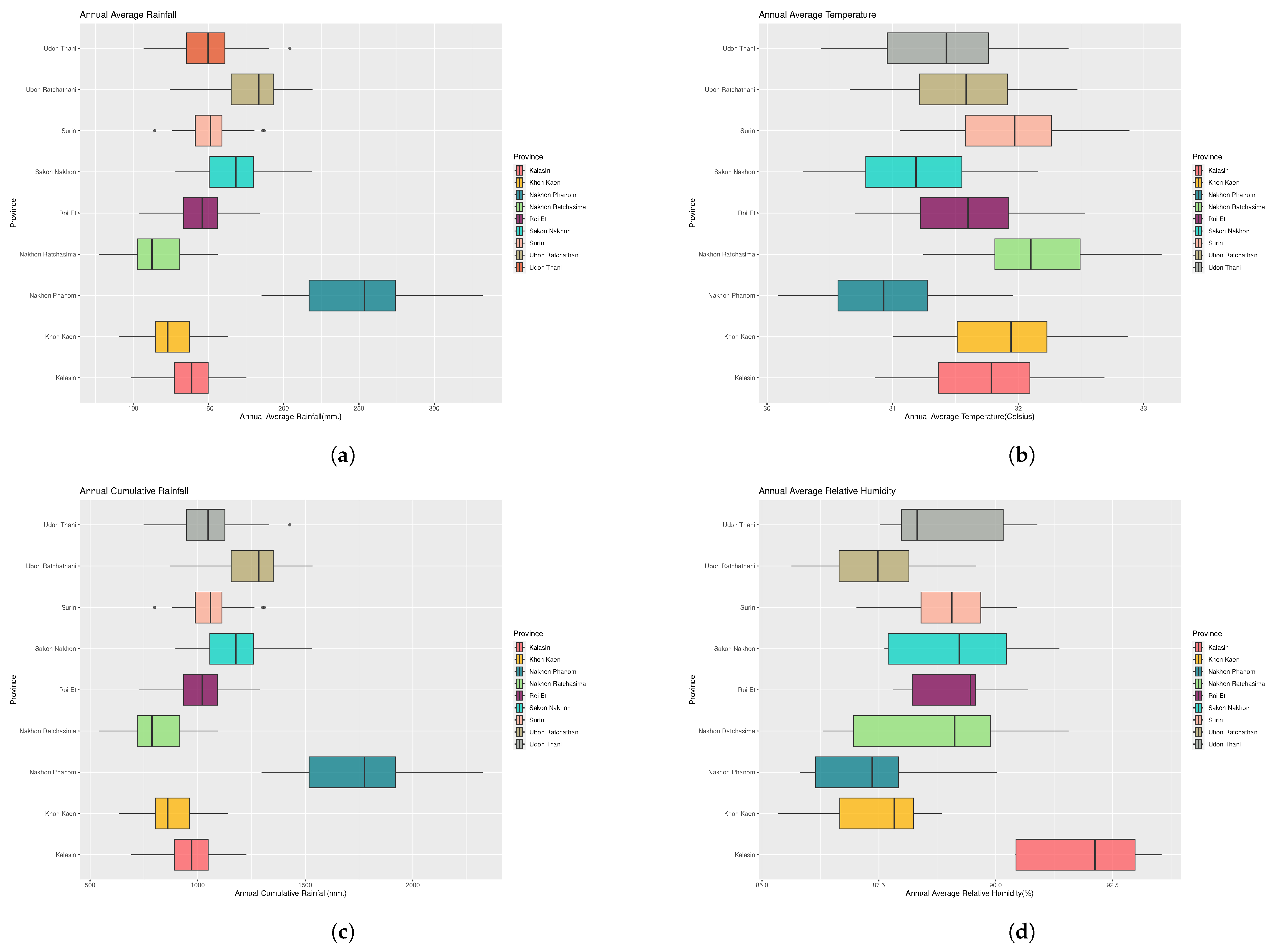
A summary of crop data from the Northeast regions between 1981–2021, including cultivated area (ha), harvested area (ha), productivities (ton), and yield (kg/ha), can be found in the
Supplementary Material (Tables S2–S4). Additionally, a comparison between rice productivity and other crop data, encompassing cultivated area (ha), harvested area (ha), and yield per ha (kg) for selected provinces from 1981–2021 is illustrated in
Figure 4,
Figure 5,
Figure 6 and
Figure 7.
Rice production and yield in select provinces saw a significant rise from 1981, starting at 13.4 million tons and reaching 38.1 million tons by 2011, marking an impressive growth over a span of 40 years (as depicted in
Figure 4,
Figure 5,
Figure 6 and
Figure 7). The initial 20 years witnessed a moderate yearly growth, which nearly doubled post the year 2000. However, post-2011, there has been an observable decline and fluctuation in production. This growth between 1981 to 2011 can be attributed to two factors:
An expansion in rice cultivation areas, growing from 7.3 million hectares to 12.0 million hectares (a jump of 64%).
A surge in yield rates, rising from 1.8 tons per hectare to 3.2 tons per hectare. This represents a 78% increase, averaging an annual growth rate of 35.9 kg per hectare.
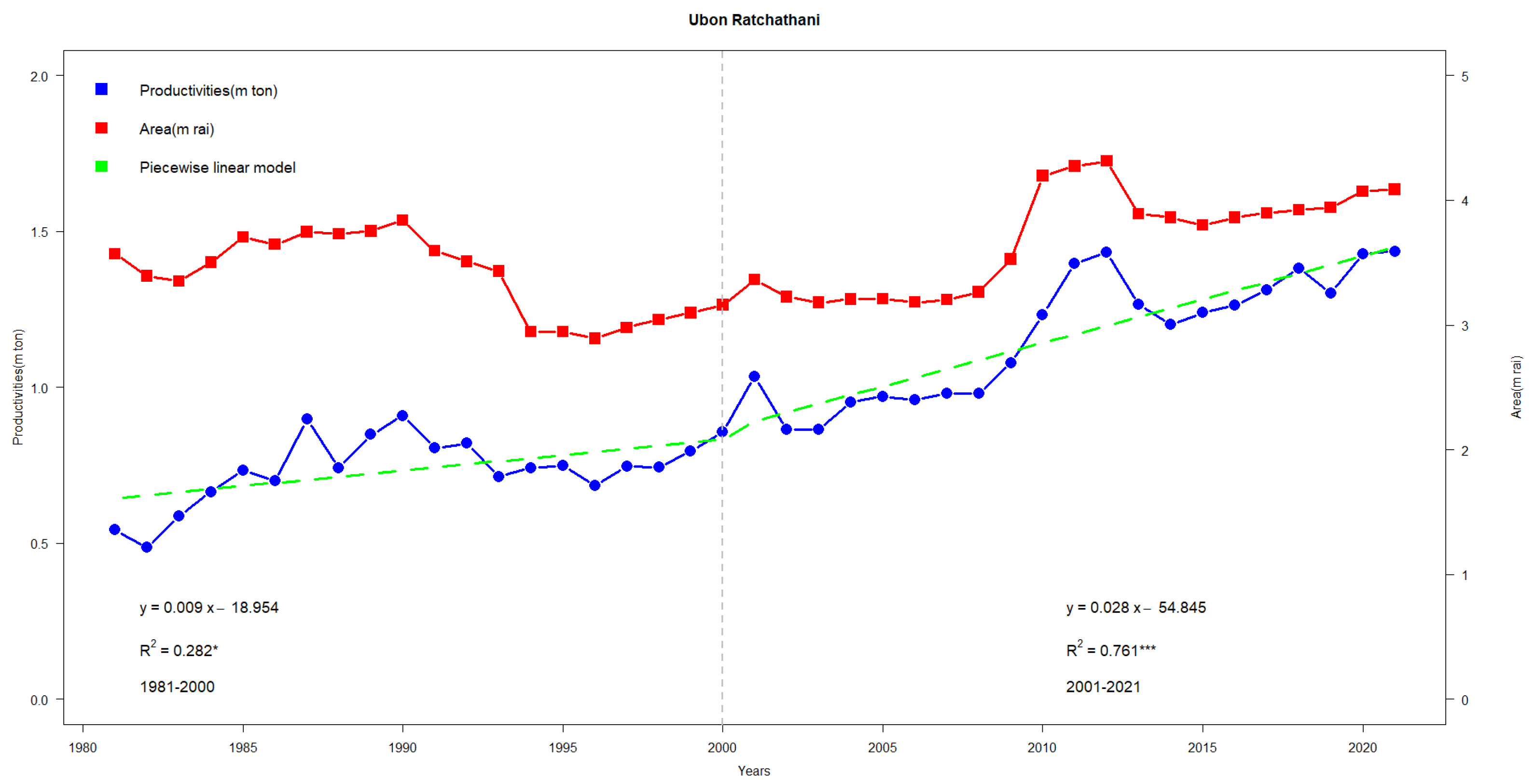
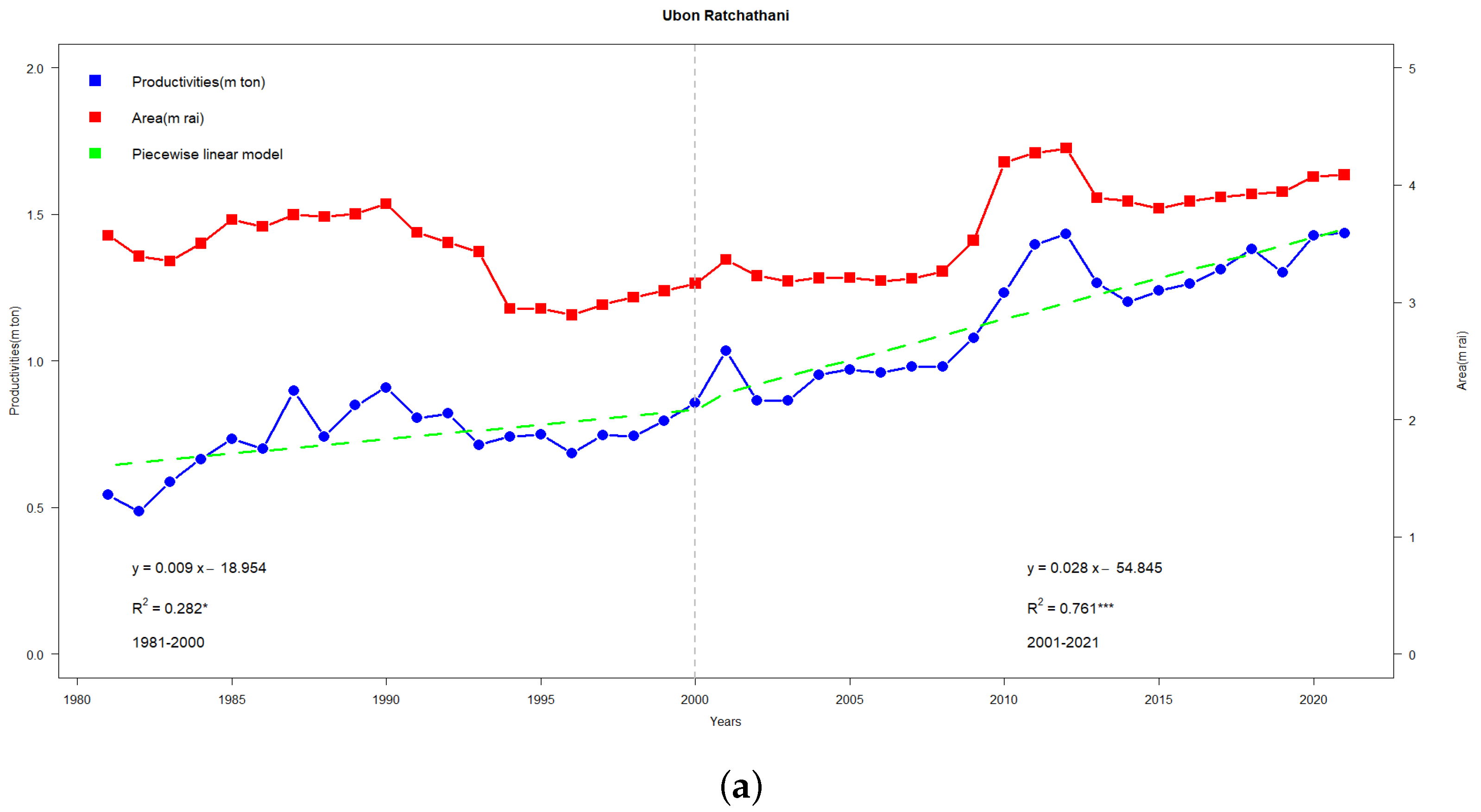
Figure 4a shows highlights on two separate slopes in the production (ton) regression line (blue line)—one from 1981–2000 and the other from 2001–2021, both of which are on an upward trend. For the area (ha), there is a declining slope from 1981–2000, which reverses into an increasing trend from 2001 onwards. These patterns correspond to two regression models:
with
and
with
, respectively. From 2000 onwards, there is a noticeable intersection of the production and area regression lines, signaling that an expansion in area is paired with an increase in production.
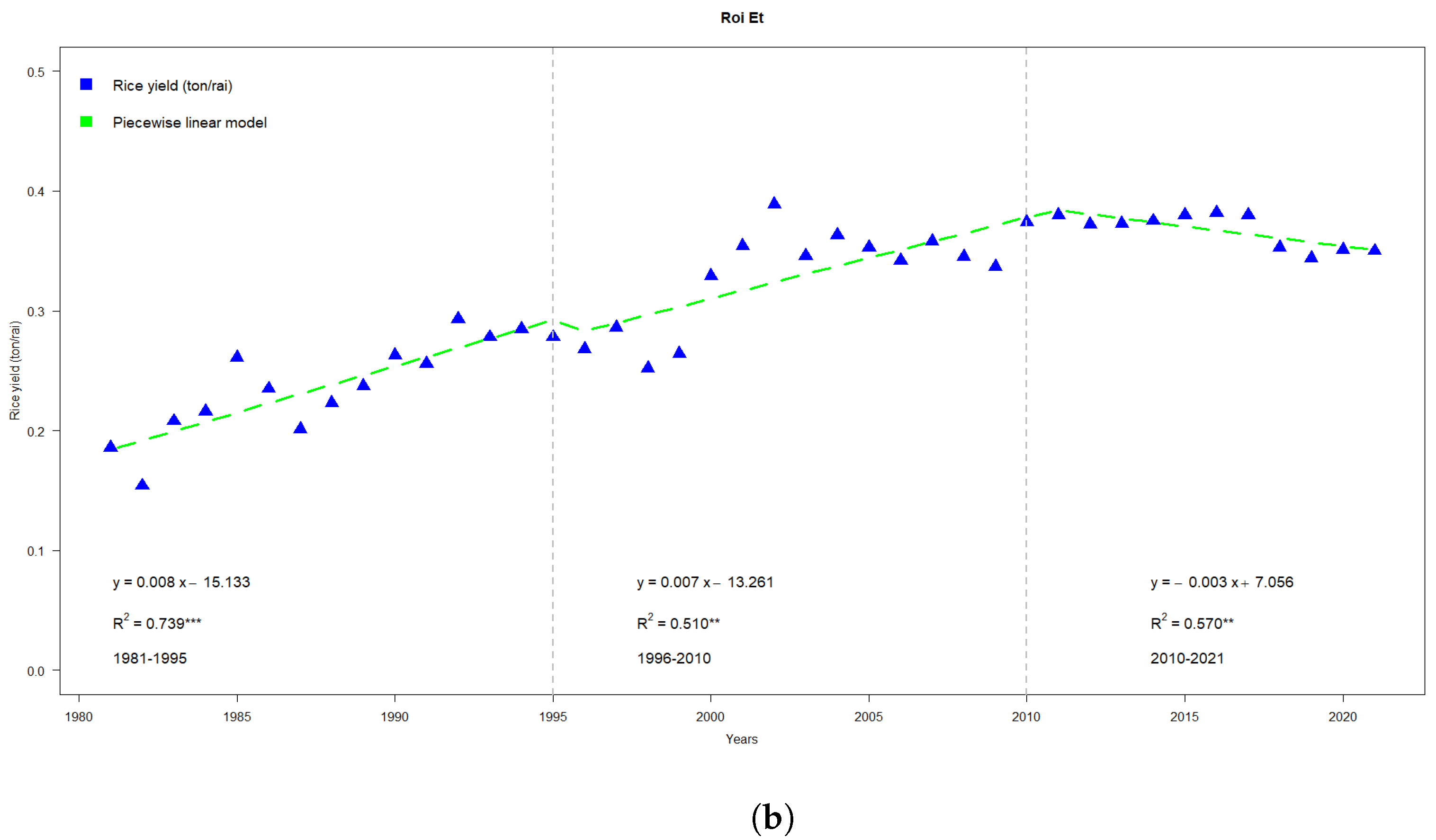
Additionally,
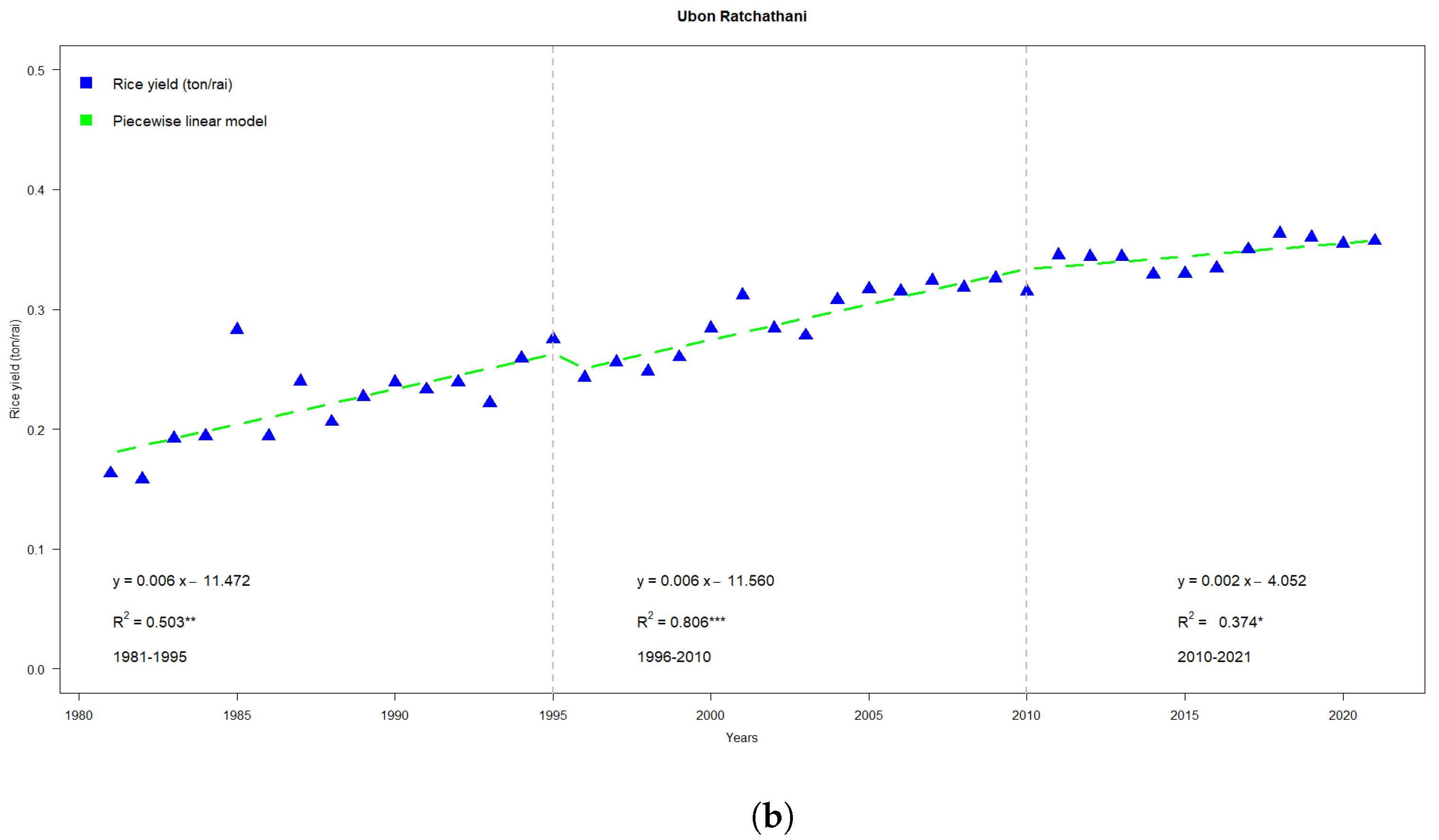
Figure 4b shows highlights for three separate slopes in the rice yield (ton/ha)—one from 1981–1995, from 1996–2010, and the other from 2010–2021, all of which are on an upward trend. These patterns correspond to three regression models:
with
,
with
and
with
, respectively.
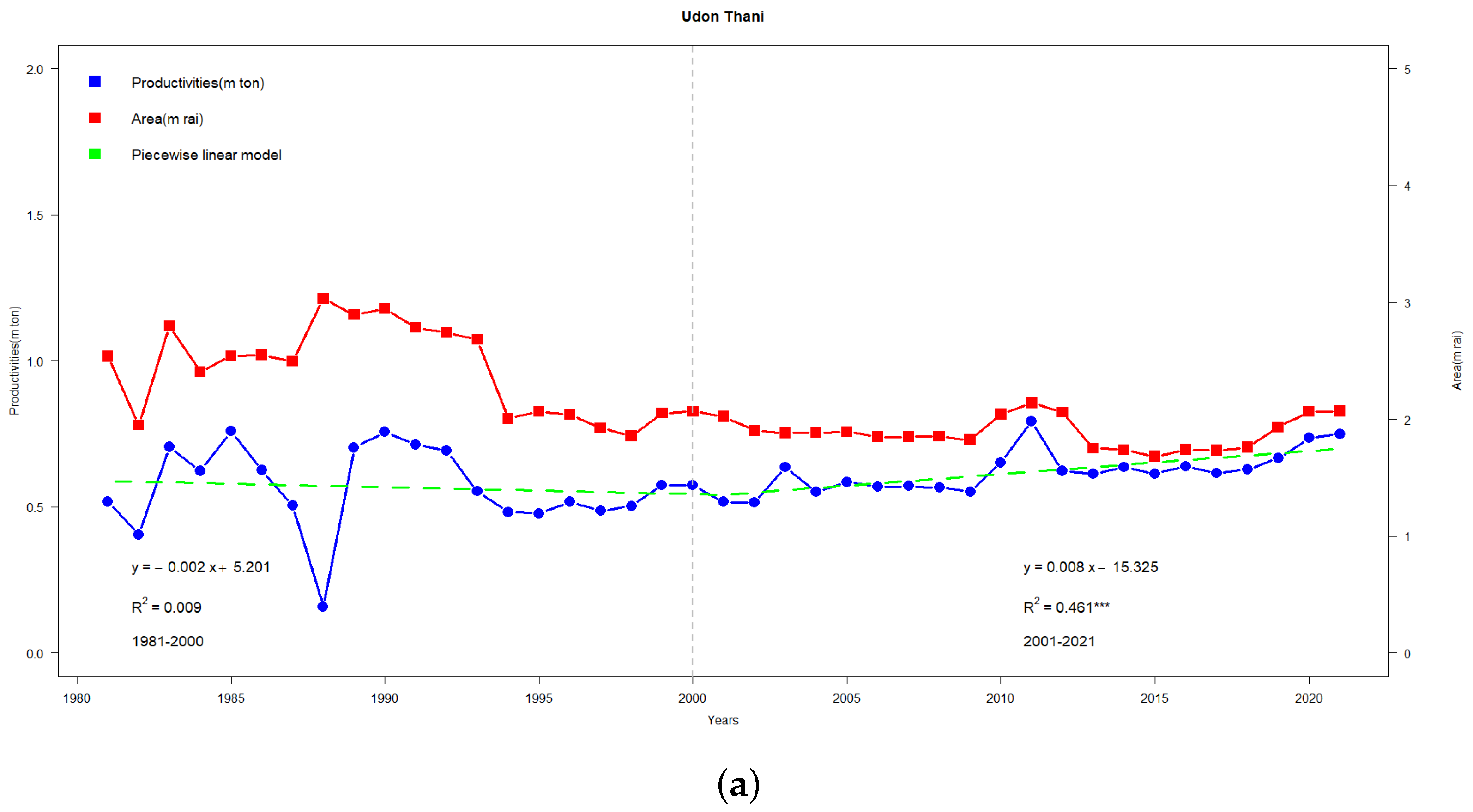
Figure 5a illustrates the production (ton) regression line (blue line) with two distinct slopes: a decreasing trend from 1981–2000 and a stable trajectory from 2001–2021. Similarly, the area (ha) showcases a downward slope from 1981–2000, transitioning to a consistent trend from 2001 and beyond. These patterns correspond to two regression models:
with
and
with
, respectively.
Additionally,
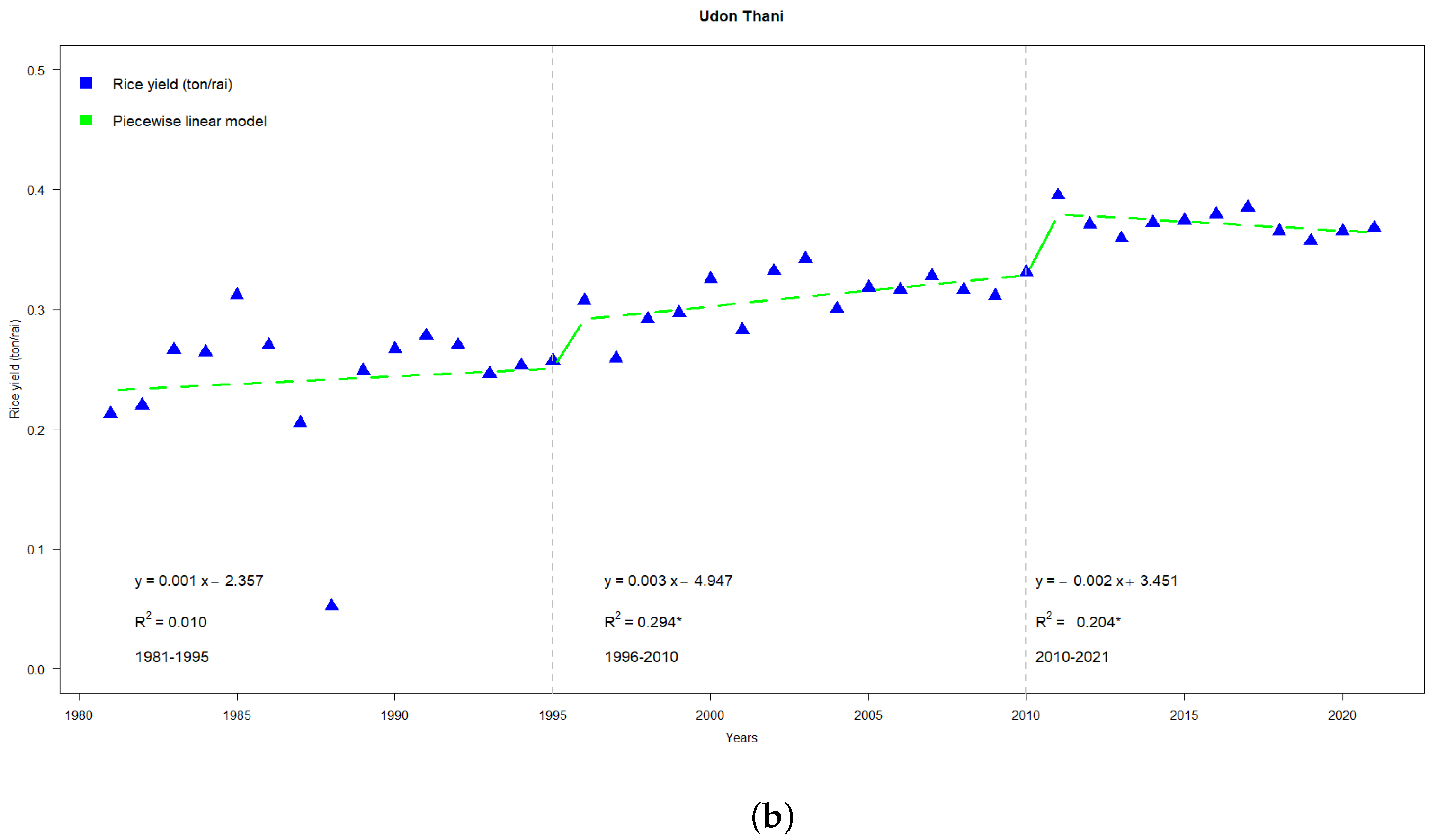
Figure 5b shows highlights for three separate slopes in the rice yield (ton/ha)—one from 1981–1995, from 1996–2010, and the other from 2010–2021, all of which are on an upward trend. These patterns correspond to three regression models:
with
,
with
and
with
, respectively.
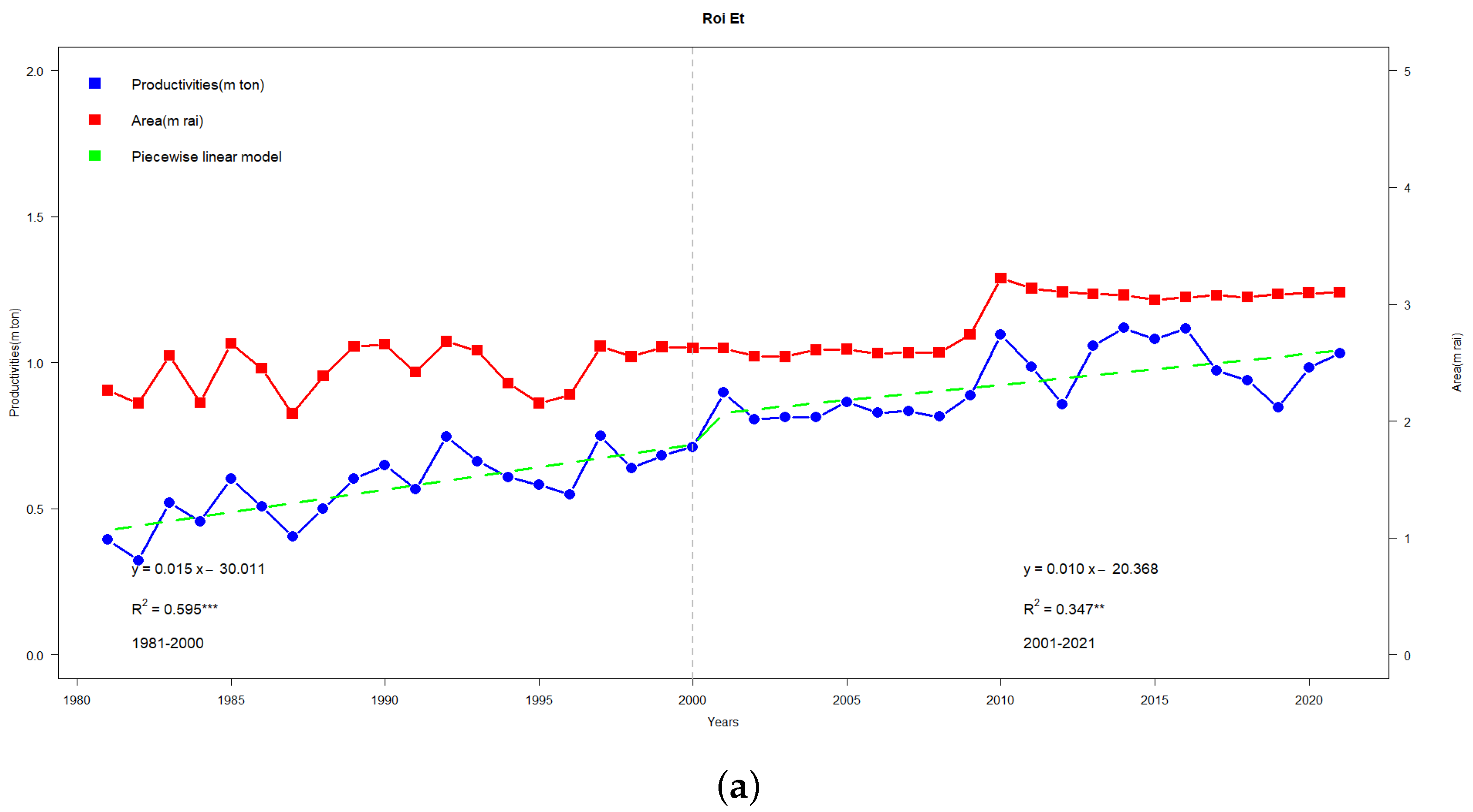
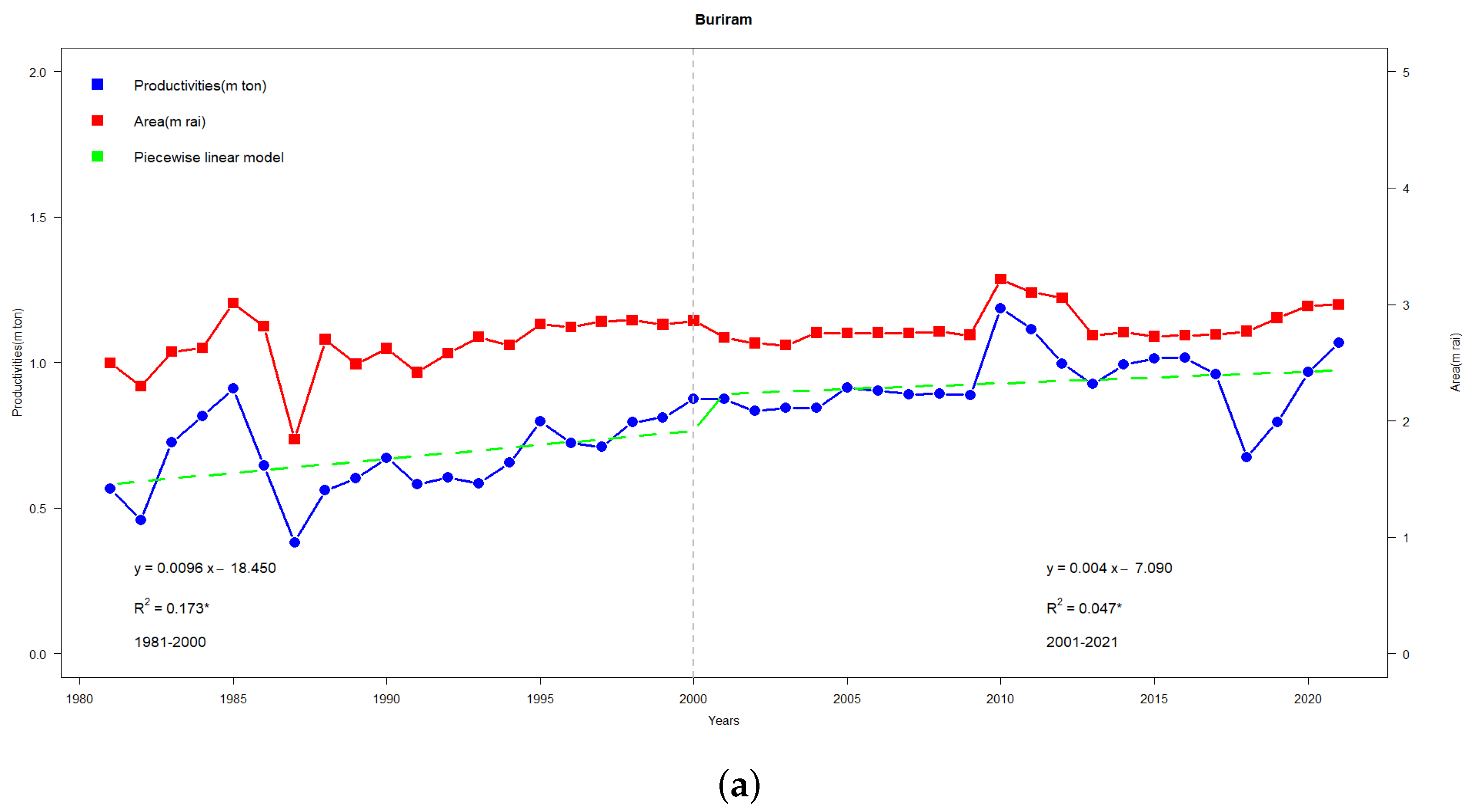
Figure 6a illustrates the production (ton) regression line (blue line) with two distinct slopes: a decreasing trend from 1981–2000 and a decreasing trend with a lower slope from 2001–2021. Similarly, the area (ha) showcases an upward slope from 1981–2000, transitioning to a decreasing trend from 2001 and beyond. These patterns correspond to two regression models:
with
and
with
, respectively.
Additionally,
Figure 6b shows highlights for three separate slopes in the rice yield (ton/ha)—one from 1981–1995, from 1996–2010, and the other from 2010–2021, two of which are on an upward trend, and the last one is one downward trend. These patterns correspond to three regression models:
with
,
with
and
with
, respectively.
Figure 7a illustrates the production (ton) regression line (blue line) with two distinct slopes: a decreasing trend from 1981–2000 and a decreasing trend with a lower slope from 2001–2021. Similarly, the area (ha) showcases an upward slope from 1981–2000, transitioning to a decreasing trend from 2001 and beyond. These patterns correspond to two regression models:
with
and
with
, respectively.
Additionally,
Figure 7b shows highlights for three separate slopes in the rice yield (ton/ha)—one from 1981–1995, one from 1996–2010, and the other from 2010–2021, two of which are on an upward trend and the last one is on a downward trend. These patterns correspond to three regression models:
with
,
with
, and
with
, respectively.
In addition, we note that the 1980s were marked by an expansion in rice cultivation areas. This trend plateaued during the 1990s through the early 2000s but then picked up pace rapidly between 2005 and 2011. Unfortunately, post-2011, the cultivated area saw some fluctuations, eventually dipping to 8.7 million hectares by 2016. In terms of yield, the initial decade starting from 1981 experienced a slower growth rate of 20.3 kg per hectare annually, culminating at 1.95 tons per hectare in 1990 (as shown in
Figure 4b,
Figure 5b,
Figure 6b and
Figure 7b). The following 21 years up to 2011 marked a rate of increase of 53.5 kg per hectare annually, which translates to a 1.7% yearly surge. However, the subsequent seven years leading up to 2021 did not witness any further rise in yield. The causes behind these shifts in production will be explored in subsequent sections.
3.2. Dependence Analysis
To investigate the interplay between rice production and yield in designated provinces, we utilized seven distinct two-dimensional copula models, as previously described.
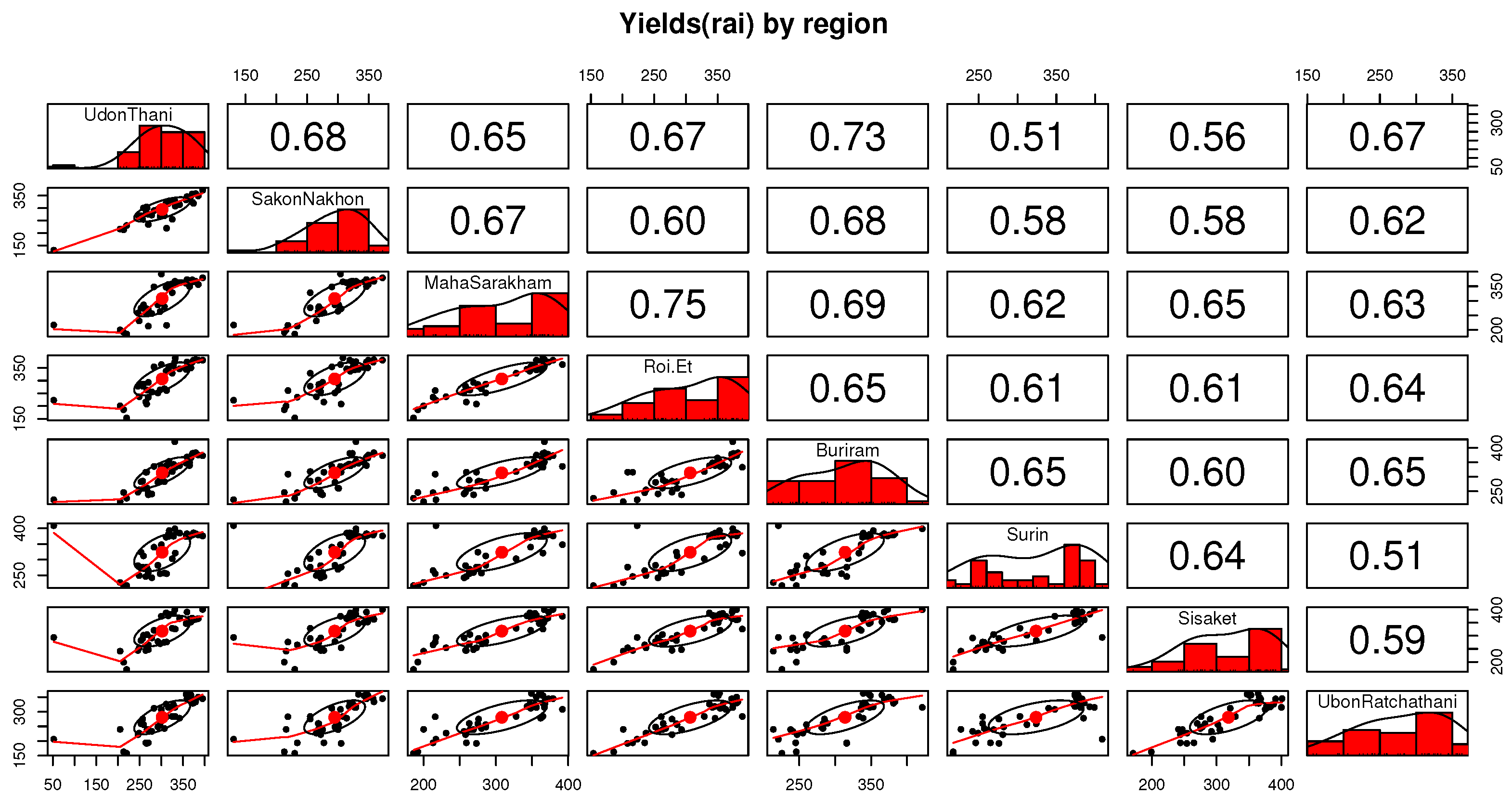
Figure 8 displays the connection between yields and the selected provinces. In contrast,
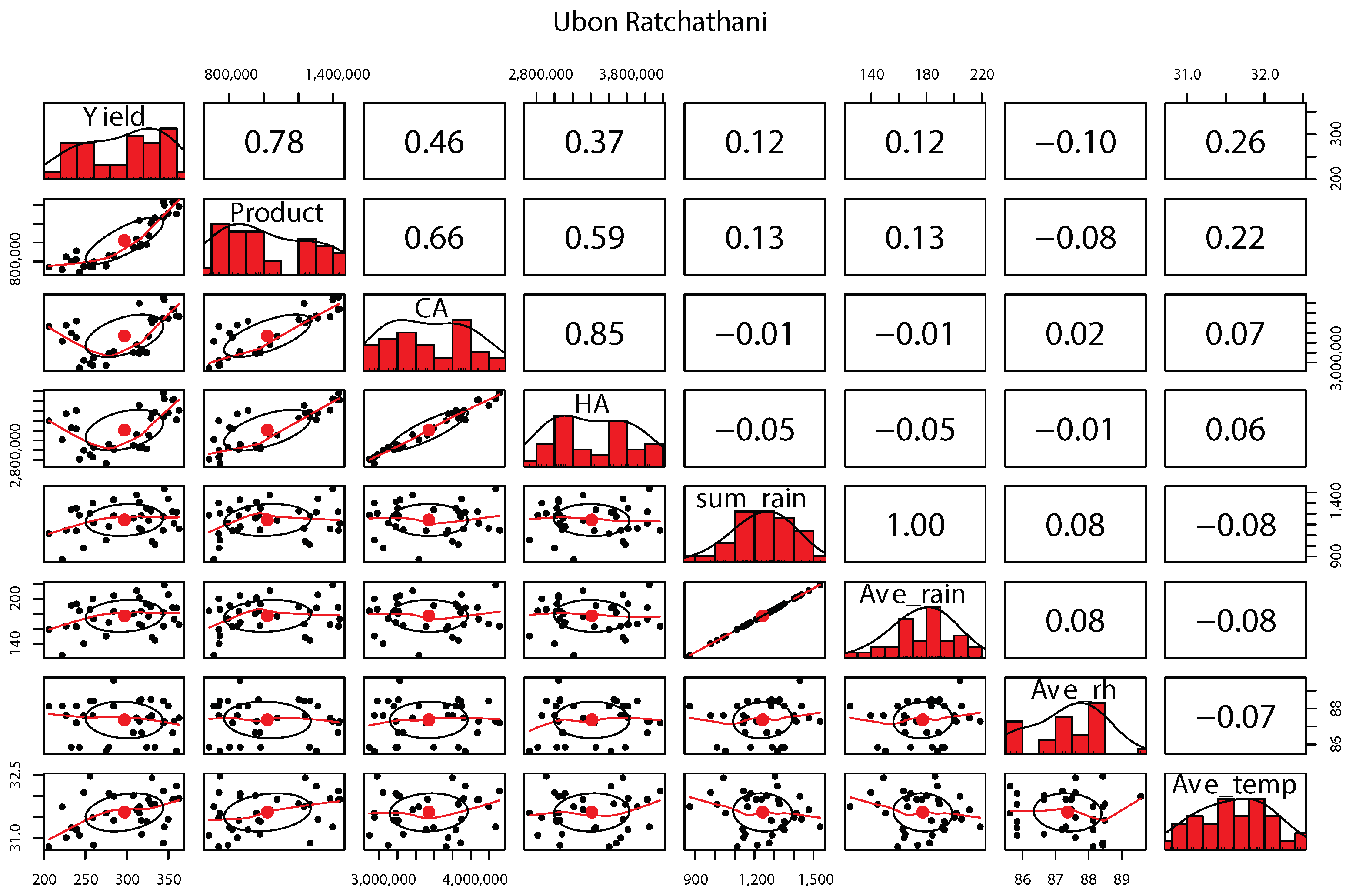
Figure 9 emphasizes the linkage between crop variables and key meteorological elements.
Figure 8 reveals a strong correlation within agricultural planning for neighboring areas, influenced by water management practices within each watershed. Concurrently,
Figure 9 demonstrates the impact or risk assessment of critical meteorological variables, such as cumulative rainfall (mm) and average temperature (°C), on yield (kg) and production (ton).
Results detailing the estimated parameters of the probability distribution for production and yield across various provinces are provided in
Table 4 and
Table 5, categorized based on the main rivers (Khong, Chi, and Mun).
Table 6 displays the estimated probability distribution parameters for crop and meteorological variables specific to Ubon Ratchathani province. Each table highlights the fitting distribution and pertinent statistics. In this study, pseudodata based on rank variables are estimated using a copula function, so the estimation of an appropriate peripheral probability distribution is important. Probability distributions such as Weibull distribution, Normal distribution, Log-normal distribution, Gamma distribution, Logistic distribution, and Exponential distribution were considered. The KS test can be used to assess how well each chosen probability distribution fits the data for each province.
Table 4 displays the appropriate distribution of the product for each province, categorized by their respective watersheds: Khong, Chi, and Mun, located in the Northeast. Six distributions, namely Log-normal, Logistic, Gamma, Weibull, and Normal, are identified as suitable for various provinces within the Northeast region. Furthermore,
Table 5 presents the fitting distribution of yields for selected provinces. Across all regions, the Logistic and Weibull distributions were found to be the most fitting.
Table 6 displays the suitable distribution for both crop and meteorological data specific to the Ubon Ratchathani province.
The subsequent step in our analysis was to validate if the relationships illustrated by the estimated copulas were an accurate reflection of real-world data and whether they were apt for empirical modeling. To evaluate how well the estimated copulas match the empirical data related to rice production and yield, we implemented the described methodology.
One way to gauge the accuracy of copula parameter estimation is to compare the coefficients inferred from the chosen copula with the empirical Kendall coefficients, denoted as
. We obtained estimates of the Kendall coefficient (
) for all copulas via a simulation method. These results can be found in
Table 7,
Table 8 and
Table 9.
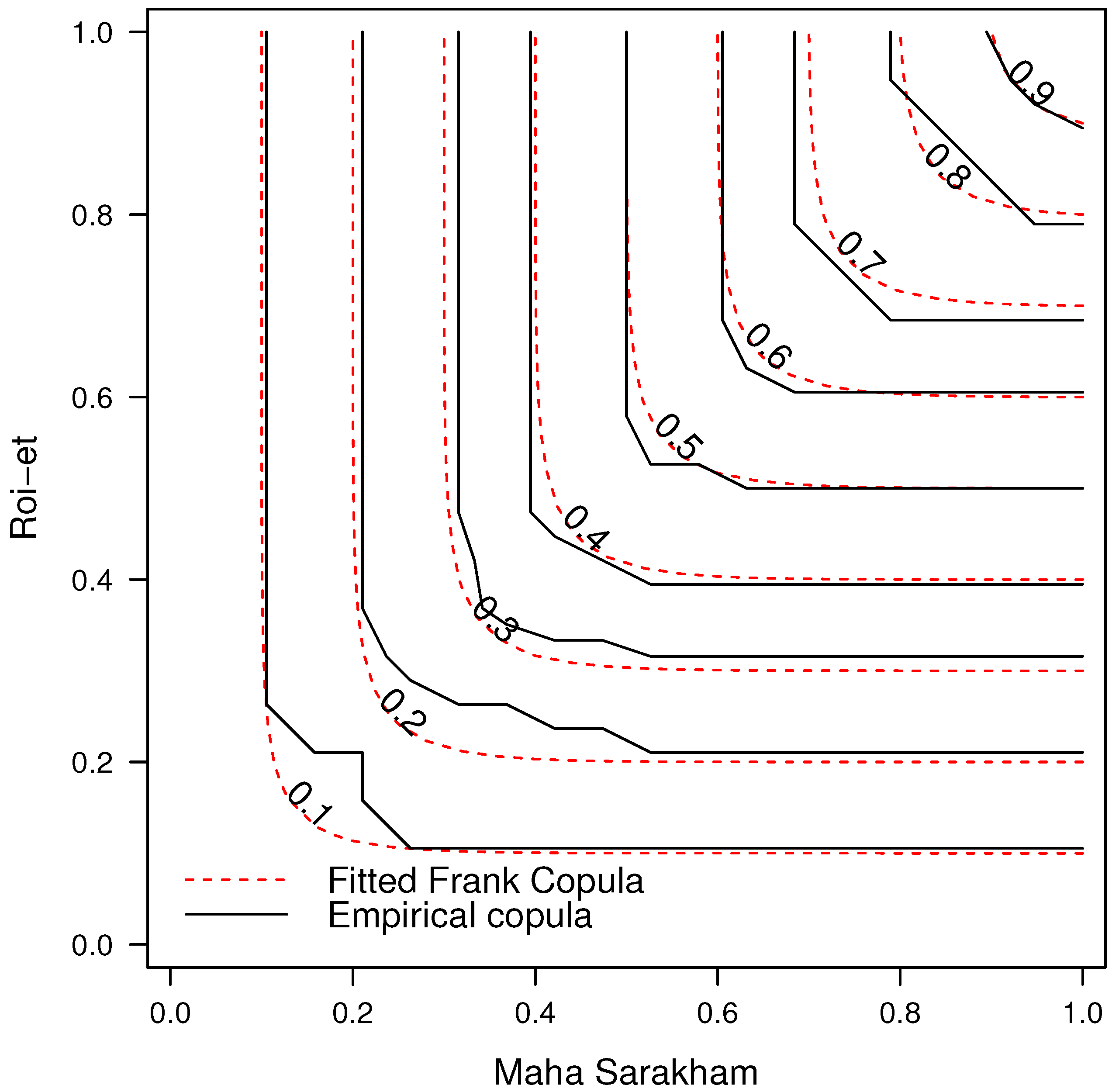
Table 7 presents the outcomes derived from the copula function that examines the product relationship between the Maha Sarakham and Roi-Et provinces. A pronounced correlation is evident, with the Frank copula emerging as the most fitting, having an estimated parameter value of 15.12 and a standard error of 3.36. For enhanced clarity,
Figure 10 visually compares the empirical copulas with the fitted copula specific to the Maha Sarakham and Roi-Et provinces, which indicates minimal variance between the empirical and theoretical copula functions.
At the same time,
Table 8 presents the Kendall correlation coefficient values,
, extracted from the sampled data. Every estimated correlation in this table is positive and statistically significant. Among pairs of agricultural products, the combination of Maha Sarakham and Roi-Et provinces displays the most robust correlation with the highest xv-CIC linked to the Frank copula, featuring an estimated parameter of 12.95 and a standard error of 3.10. Conversely, the pair of Srisaket and Ubon Ratchathani exhibits the least substantial correlation associated with the Clayton copula.
Subsequently,
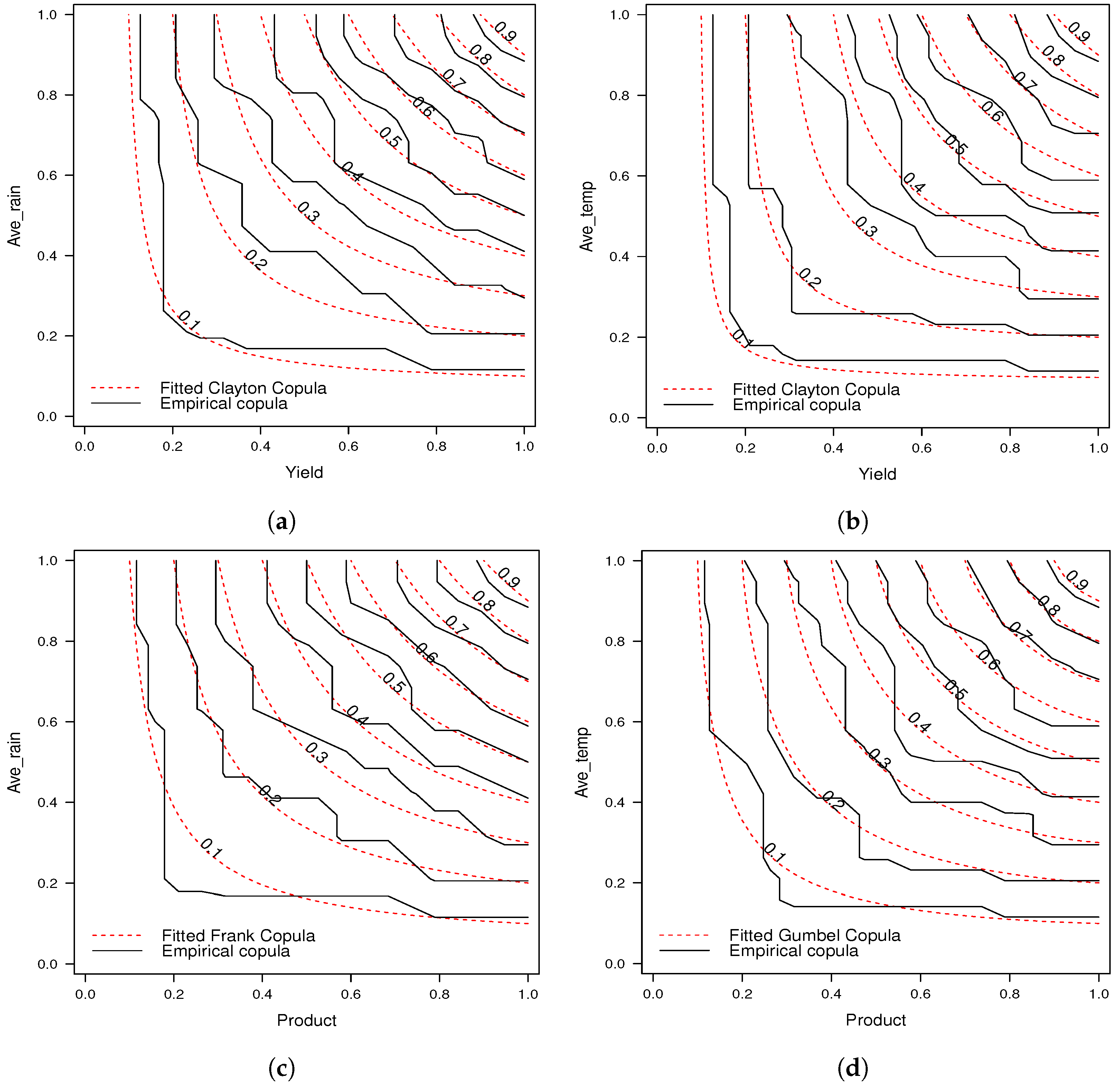
Table 9 outlines the results of the copula function relating variables in the Ubon Ratchathani province. The most fitting copula between yield and average rainfall, as well as average temperature, is the Clayton copula. For the correlation between product and average rainfall, the Frank copula is most apt, whereas the Gumbel copula best describes the relationship between product and average temperature.
The findings in
Table 8 and
Table 9 and
Figure 11 corroborate the assessment of how well the copulas fit using the Kendall coefficient
and xv-CIC value. For the observation pairs Maha Sarakham and Roi-Et, Burirum and Surin, as well as Sisaket and Ubon Ratchathani, the Frank copula offers the most optimal fit. Conversely, the Clayton copula appears to be the best match for pairs such as Surin and Srisaket and Sisaket and Ubon Ratchathani, while the Gumbel copula is best suited for the Udonthani and Sakon Nakorn pair.
In the case of Ubon Ratchathani province, when examining the relationship between correlated variables, the Clayton copula best represents the link between yield and average rainfall, the Frank copula aptly captures the connection between production and average rainfall, and the Gumbel copula is most fitting for the relationship between production and average temperature.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}