
A Systematic Review of Literature on Sustaining Decision-Making in Healthcare Organizations Amid Imperfect Information in the Big Data Era

 , ,
, ,  , ,
, ,  ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Phase 1: Planning
2.1.1. Definition of Research Questions
- What research studies have explored the role of imperfect information in the sustainability of decision making within health organizations (HOs)?
- What factors associated with imperfect information can impede the sustainability of decision making in HOs?
- Which theoretical models are utilized to support the sustainability of decision making in HOs?
- What specific contributions have studies made in addressing the issue of imperfect information in the context of decision making sustainability within HOs?
2.1.2. Search Strategy
2.1.3. Search Terms
2.1.4. Literature Resources and Existing Research Review
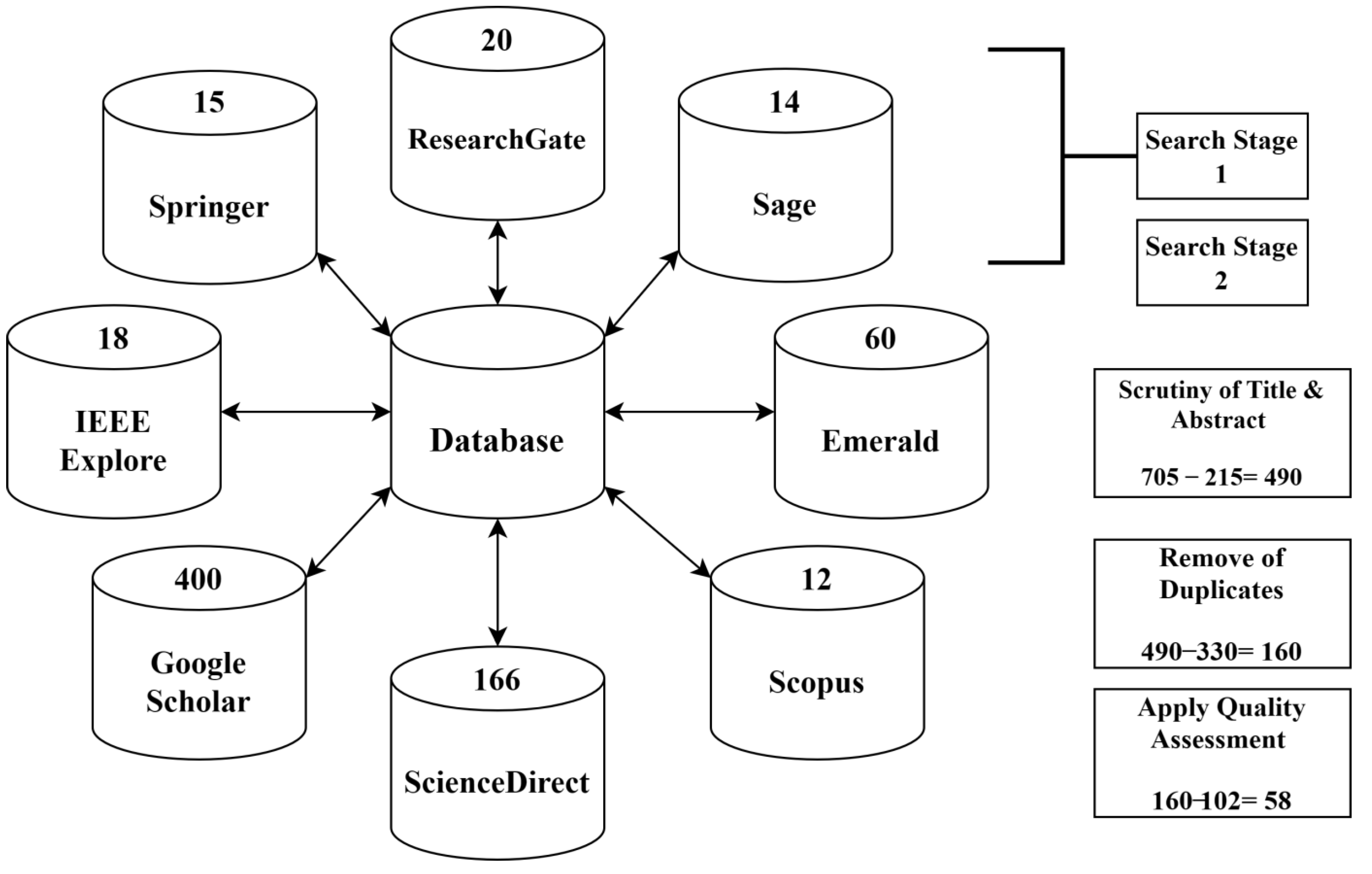
2.2. Phase 2: Selection
Scrutiny and Filtering Process
2.3. Phase 3: Extraction
Study Quality Assessment
2.4. Phase 4: Execution
Data Synthesis
3. Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Factor | Theory/Model | Definition | Source |
|---|---|---|---|---|
| P1 | Uncertainty | Belief functions theory | Imprecision, uncertainty, incompleteness, ignorance and conflict. | [36,53,72,73] |
| P2 | Imprecision | Fuzzy set logic/possibility theory | Imprecision and ambiguity. | [26,32,72,77,78,79,80,81,87] |
| P3 | Vagueness | Classification entropy/rough sets theory | Handles ambiguity between the classes and vagueness. | [28,47,75,76] |
| P4 | Incompleteness | Probability theory | Model incompleteness of data. | [26,36,38,72,74] |
| P5 | Complexity | Belief functions theory | Complication; model complicated data. | [36,53,72,73,88] |
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Whichello, C.; Bywall, K.S.; Mauer, J.; Stephen, W.; Cleemput, I.; Pinto, C.A.; van Overbeeke, E.; Huys, I.; de Bekker-Grob, E.W.; Hermann, R.; et al. An Overview of Critical Decision-Points in the Medical Product Lifecycle: Where to Include Patient Preference Information in the Decision-Making Process? Health Policy 2020, 124, 1325–1332. [Google Scholar] [CrossRef]
- Shahmoradi, L.; Safadari, R.; Jimma, W. Knowledge Management Implementation and the Tools Utilized in Healthcare for Evidence-Based Decision Making: A Systematic Review. Ethiop. J. Health Sci. 2017, 27, 541–558. [Google Scholar] [CrossRef]
- Shahid, N.; Rappon, T.; Berta, W. Applications of Artificial Neural Networks in Health Care Organizational Decision-Making: A Scoping Review. PLoS ONE 2019, 14, e0212356. [Google Scholar] [CrossRef] [PubMed]
- Damman, O.C.; Jani, A.; de Jong, B.A.; Becker, A.; Metz, M.J.; de Bruijne, M.C.; Timmermans, D.R.; Cornel, M.C.; Ubbink, D.T.; van der Steen, M. The Use of PROMs and Shared Decision-Making in Medical Encounters with Patients: An Opportunity to Deliver Value-Based Health Care to Patients. J. Eval. Clin. Pract. 2020, 26, 524–540. [Google Scholar] [CrossRef] [PubMed]
- Vis, C.; Bührmann, L.; Riper, H.; Ossebaard, H.C. Health Technology Assessment Frameworks for EHealth: A Systematic Review. Int. J. Technol. Assess. Health Care 2020, 36, 204–216. [Google Scholar] [CrossRef]
- Gupta, S.; Kamboj, S.; Bag, S. Role of Risks in the Development of Responsible Artificial Intelligence in the Digital Healthcare Domain. Inf. Syst. Front. 2021, 1–18. [Google Scholar] [CrossRef]
- Mardani, A.; Zavadskas, E.K.; Fujita, H.; Köppen, M. Big Data-Driven Large-Scale Group Decision-Making under Uncertainty (BiGDM-U). Appl. Intell. 2022, 52, 13341–13344. [Google Scholar] [CrossRef] [PubMed]
- Thokala, P.; Devlin, N.; Marsh, K.; Baltussen, R.; Boysen, M.; Kalo, Z.; Longrenn, T.; Mussen, F.; Peacock, S.; Watkins, J.; et al. Multiple Criteria Decision Analysis for Health Care Decision Making—An Introduction: Report 1 of the ISPOR MCDA Emerging Good Practices Task Force. Value Health 2016, 19, 1–13. [Google Scholar] [CrossRef]
- Galetsi, P.; Katsaliaki, K.; Kumar, S. Values, Challenges and Future Directions of Big Data Analytics in Healthcare: A Systematic Review. Soc. Sci. Med. 2019, 241, 112533. [Google Scholar] [CrossRef]
- Borges do Nascimento, I.J.; Marcolino, M.S.; Abdulazeem, H.M.; Weerasekara, I.; Azzopardi-Muscat, N.; Gonçalves, M.A.; Novillo-Ortiz, D. Impact of Big Data Analytics on People’s Health: Overview of Systematic Reviews and Recommendations for Future Studies. J. Med. Internet Res. 2021, 23, e27275. [Google Scholar] [CrossRef]
- Biswas, R. Outlining Big Data Analytics in Health Sector with Special Reference to COVID-19. Wirel. Pers. Commun. 2022, 124, 2097–2108. [Google Scholar] [CrossRef] [PubMed]
- Cozzoli, N.; Salvatore, F.P.; Faccilongo, N.; Milone, M. How Can Big Data Analytics Be Used for Healthcare Organization Management? Literary Framework and Future Research from a Systematic Review. BMC Health Serv. Res. 2022, 22, 809. [Google Scholar] [CrossRef] [PubMed]
- Singh, R.K.; Agrawal, S.; Sahu, A.; Kazancoglu, Y. Strategic Issues of Big Data Analytics Applications for Managing Health-Care Sector: A Systematic Literature Review and Future Research Agenda. TQM J. 2023, 35, 262–291. [Google Scholar] [CrossRef]
- Janssen, M.; Van Der Voort, H.; Wahyudi, A. Factors Influencing Big Data Decision-Making Quality. J. Bus. Res. 2017, 70, 338–345. [Google Scholar] [CrossRef]
- Ellaway, R.H.; Pusic, M.V.; Galbraith, R.M.; Cameron, T. Developing the Role of Big Data and Analytics in Health Professional Education. Med. Teach. 2014, 36, 216–222. [Google Scholar] [CrossRef]
- Garattini, C.; Raffle, J.; Aisyah, D.N.; Sartain, F.; Kozlakidis, Z. Big Data Analytics, Infectious Diseases and Associated Ethical Impacts. Philos. Technol. 2019, 32, 69–85. [Google Scholar] [CrossRef]
- Rehman, A.; Naz, S.; Razzak, I. Leveraging Big Data Analytics in Healthcare Enhancement: Trends, Challenges and Opportunities. Multimed. Syst. 2022, 28, 1339–1371. [Google Scholar] [CrossRef]
- Ancker, J.S.; Witteman, H.O.; Hafeez, B.; Provencher, T.; Van de Graaf, M.; Wei, E. “You Get Reminded You’re a Sick Person”: Personal Data Tracking and Patients with Multiple Chronic Conditions. J. Med. Internet Res. 2015, 17, e202. [Google Scholar] [CrossRef] [PubMed]
- El Samad, M.; El Nemar, S.; Sakka, G.; El-Chaarani, H. An Innovative Big Data Framework for Exploring the Impact on Decision-Making in the European Mediterranean Healthcare Sector. EuroMed J. Bus. 2022, 17, 312–332. [Google Scholar] [CrossRef]
- Baro, E.; Degoul, S.; Beuscart, R.; Chazard, E. Toward a Literature-Driven Definition of Big Data in Healthcare. BioMed Res. Int. 2015, 2015, 639021. [Google Scholar] [CrossRef]
- Wamba, S.F.; Akter, S.; Edwards, A.; Chopin, G.; Gnanzou, D. How ‘Big Data’Can Make Big Impact: Findings from a Systematic Review and a Longitudinal Case Study. Int. J. Prod. Econ. 2015, 165, 234–246. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. An Overview of Health Analytics. J. Health Med. Inform. 2013, 4, 1–43. [Google Scholar] [CrossRef]
- Ward, M.J.; Marsolo, K.A.; Froehle, C.M. Applications of Business Analytics in Healthcare. Bus. Horiz. 2014, 57, 571–582. [Google Scholar] [CrossRef] [PubMed]
- Jacofsky, D.J. The Myths of ‘Big Data’in Health Care. Bone Jt. J. 2017, 99, 1571–1576. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Kung, L.; Gupta, S.; Ozdemir, S. Leveraging Big Data Analytics to Improve Quality of Care in Healthcare Organizations: A Configurational Perspective. Br. J. Manag. 2019, 30, 362–388. [Google Scholar] [CrossRef]
- Alizadehsani, R.; Roshanzamir, M.; Hussain, S.; Khosravi, A.; Koohestani, A.; Zangooei, M.H.; Abdar, M.; Beykikhoshk, A.; Shoeibi, A.; Zare, A.; et al. Handling of Uncertainty in Medical Data Using Machine Learning and Probability Theory Techniques: A Review of 30 Years (1991–2020). Ann. Oper. Res. 2021; online ahead of print. [Google Scholar] [CrossRef]
- Andreu-Perez, J.; Poon, C.C.; Merrifield, R.D.; Wong, S.T.; Yang, G.-Z. Big Data for Health. IEEE J. Biomed. Health Inform. 2015, 19, 1193–1208. [Google Scholar] [CrossRef]
- Bania, R.K.; Halder, A. R-Ensembler: A Greedy Rough Set Based Ensemble Attribute Selection Algorithm with KNN Imputation for Classification of Medical Data. Comput. Methods Programs Biomed. 2020, 184, 105122. [Google Scholar] [CrossRef]
- Basha, S.M.; Srinu, N.; Surekha, C.; Sree, K.N.; Sree, R.N. Utilizing Machine Learning and Big Data in Healthcare Systems. Int. J. Comput. Intell. Control 2019, 11, 235–248. [Google Scholar]
- Bates, D.W.; Heitmueller, A.; Kakad, M.; Saria, S. Why Policymakers Should Care about “Big Data” in Healthcare. Health Policy Technol. 2018, 7, 211–216. [Google Scholar] [CrossRef]
- Costa, F.F. Big Data in Biomedicine. Drug Discov. Today 2014, 19, 433–440. [Google Scholar] [CrossRef]
- Dhand, G.; Sheoran, K.; Agarwal, P.; Biswas, S.S. Deep Enriched Salp Swarm Optimization Based Bidirectional-Long Short Term Memory Model for Healthcare Monitoring System in Big Data. Inform. Med. Unlocked 2022, 32, 101010. [Google Scholar] [CrossRef]
- Fatt, Q.K.; Ramadas, A. The Usefulness and Challenges of Big Data in Healthcare. J. Health Commun. 2018, 3, 21. [Google Scholar] [CrossRef]
- Ghorbel, F.; Hamdi, F.; Achich, N.; Metais, E. Handling Data Imperfection—False Data Inputs in Applications for Alzheimer’s Patients. Data Knowl. Eng. 2020, 130, 101864. [Google Scholar] [CrossRef]
- Gomes, M.A.S.; Kovaleski, J.L.; Pagani, R.N.; da Silva, V.L.; de Severo Pasquini, T.C. Transforming Healthcare with Big Data Analytics: Technologies, Techniques and Prospects. J. Med. Eng. Technol. 2023, 47, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.-G.; Fang, G.-C.; Liu, Y.-Y.; Guo, L.-K.; Wang, Y.-M. Disjunctive Belief Rule-Based Reasoning for Decision Making with Incomplete Information. Inf. Sci. 2023, 625, 49–64. [Google Scholar] [CrossRef]
- Han, P.K.; Klein, W.M.; Arora, N.K. Varieties of Uncertainty in Health Care: A Conceptual Taxonomy. Med. Decis. Mak. 2011, 31, 828–838. [Google Scholar] [CrossRef]
- Hariri, R.H.; Fredericks, E.M.; Bowers, K.M. Uncertainty in Big Data Analytics: Survey, Opportunities, and Challenges. J. Big Data 2019, 6, 44. [Google Scholar] [CrossRef]
- Kaur, P. Big Data Analytics in Healthcare: A Review. Int. J. Eng. Res. Technol. 2021, 10, 1–4. [Google Scholar]
- Martin-Sanchez, F.; Verspoor, K. Big Data in Medicine Is Driving Big Changes. Yearb. Med. Inform. 2014, 23, 14–20. [Google Scholar]
- Mayston, D. Health Care Reform: A Study in Imperfect Information. In Welfare and Policy; Lunt, N., Coyle, D., Eds.; Routledge: London, UK, 2013; pp. 3–20. [Google Scholar]
- Mehta, N.; Pandit, A. Concurrence of Big Data Analytics and Healthcare: A Systematic Review. Int. J. Med. Inform. 2018, 114, 57–65. [Google Scholar] [CrossRef]
- Nazir, S.; Khan, S.; Khan, H.U.; Ali, S.; Garcia-Magarino, I.; Atan, R.B.; Nawaz, M. A Comprehensive Analysis of Healthcare Big Data Management, Analytics and Scientific Programming. IEEE Access 2020, 8, 95714–95733. [Google Scholar] [CrossRef]
- Ola, O.; Sedig, K. The Challenge of Big Data in Public Health: An Opportunity for Visual Analytics. Online J. Public Health Inform. 2014, 5, 223. [Google Scholar] [PubMed]
- Palanisamy, V.; Thirunavukarasu, R. Implications of Big Data Analytics in Developing Healthcare Frameworks—A Review. J. King Saud Univ.-Comput. Inf. Sci. 2019, 31, 415–425. [Google Scholar] [CrossRef]
- Pisana, A.; Wettermark, B.; Kurdi, A.; Tubic, B.; Pontes, C.; Zara, C.; Van Ganse, E.; Petrova, G.; Mardare, I.; Fürst, J. Challenges and Opportunities with Routinely Collected Data on the Utilization of Cancer Medicines. Perspectives from Health Authority Personnel across 18 European Countries. Front. Pharmacol. 2022, 13, 873556. [Google Scholar] [CrossRef] [PubMed]
- Qian, W.; Yu, S.; Yang, J.; Wang, Y.; Zhang, J. Multi-Label Feature Selection Based on Information Entropy Fusion in Multi-Source Decision System. Evol. Intell. 2020, 13, 255–268. [Google Scholar] [CrossRef]
- Rosenfeld, A.; Benrimoh, D.; Armstrong, C.; Mirchi, N.; Langlois-Therrien, T.; Rollins, C.; Tanguay-Sela, M.; Mehltretter, J.; Fratila, R.; Israel, S. Big Data Analytics and Artificial Intelligence in Mental Healthcare. In Applications of Big Data in Healthcare; Elsevier: Amsterdam, The Netherlands, 2021; pp. 137–171. [Google Scholar]
- Sachan, S.; Almaghrabi, F.; Yang, J.-B.; Xu, D.-L. Evidential Reasoning for Preprocessing Uncertain Categorical Data for Trustworthy Decisions: An Application on Healthcare and Finance. Expert Syst. Appl. 2021, 185, 115597. [Google Scholar] [CrossRef]
- Secundo, G.; Shams, S.R.; Nucci, F. Digital Technologies and Collective Intelligence for Healthcare Ecosystem: Optimizing Internet of Things Adoption for Pandemic Management. J. Bus. Res. 2021, 131, 563–572. [Google Scholar] [CrossRef]
- Singh, P. The Impact of Imperfect Information on the Health Insurance Choice, Health Outcomes, and Medical Expenditures of the Elderly. Ph.D. Thesis, The University of North Carolina at Chapel Hill, Chapel Hill, NC, USA, 2016. [Google Scholar]
- Sohail, S.A.; Bukhsh, F.A.; van Keulen, M. Multilevel Privacy Assurance Evaluation of Healthcare Metadata. Appl. Sci. 2021, 11, 10686. [Google Scholar] [CrossRef]
- Yang, B.; Gan, D.; Tang, Y.; Lei, Y. Incomplete Information Management Using an Improved Belief Entropy in Dempster-Shafer Evidence Theory. Entropy 2020, 22, 993. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, X. How Environmental Uncertainty Moderates the Effect of Relative Advantage and Perceived Credibility on the Adoption of Mobile Health Services by Chinese Organizations in the Big Data Era. Int. J. Telemed. Appl. 2016, 2016, 3618402. [Google Scholar] [CrossRef]
- Dereli, T.; Coşkun, Y.; Kolker, E.; Güner, Ö.; Ağırbaşlı, M.; Özdemir, V. Big Data and Ethics Review for Health Systems Research in LMICs: Understanding Risk, Uncertainty and Ignorance—And Catching the Black Swans? Am. J. Bioeth. 2014, 14, 48–50. [Google Scholar] [CrossRef]
- Wouters, B.; Shaw, D.; Sun, C.; Ippel, L.; van Soest, J.; van den Berg, B.; Mussmann, O.; Koster, A.; van der Kallen, C.; van Oppen, C. Putting the GDPR into Practice: Difficulties and Uncertainties Experienced in the Conduct of Big Data Health Research. Eur. Data Prot. Law Rev. 2021, 7, 206–216. [Google Scholar] [CrossRef]
- Bag, S.; Gupta, S.; Choi, T.-M.; Kumar, A. Roles of Innovation Leadership on Using Big Data Analytics to Establish Resilient Healthcare Supply Chains to Combat the COVID-19 Pandemic: A Multimethodological Study. IEEE Trans. Eng. Manag. 2021, 1–14. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Manogaran, G.; Gamal, A.; Smarandache, F. A Group Decision Making Framework Based on Neutrosophic TOPSIS Approach for Smart Medical Device Selection. J. Med. Syst. 2019, 43, 38. [Google Scholar] [CrossRef] [PubMed]
- Pritzker, K. Biomarker Imprecision in Precision Medicine. Expert Rev. Mol. Diagn. 2018, 18, 685–687. [Google Scholar] [CrossRef]
- Lv, Z.; Qiao, L. Analysis of Healthcare Big Data. Future Gener. Comput. Syst. 2020, 109, 103–110. [Google Scholar] [CrossRef]
- Pramanik, M.I.; Lau, R.Y.; Demirkan, H.; Azad, M.A.K. Smart Health: Big Data Enabled Health Paradigm within Smart Cities. Expert Syst. Appl. 2017, 87, 370–383. [Google Scholar] [CrossRef]
- Herland, M.; Khoshgoftaar, T.M.; Wald, R. A Review of Data Mining Using Big Data in Health Informatics. J. Big Data 2014, 1, 2. [Google Scholar] [CrossRef]
- Dyczkowski, K. Intelligent Medical Decision Support System Based on Imperfect Information. In Studies in Computational Intelligence; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Dinov, I.D. Methodological Challenges and Analytic Opportunities for Modeling and Interpreting Big Healthcare Data. Gigascience 2016, 5, s13742-016. [Google Scholar] [CrossRef]
- Duggal, R.; Khatri, S.K.; Shukla, B. Improving Patient Matching: Single Patient View for Clinical Decision Support Using Big Data Analytics. In Proceedings of the 2015 4th International Conference on Reliability, Infocom Technologies and Optimization (ICRITO) (Trends and Future Directions), Noida, India, 4 September 2015; pp. 1–6. [Google Scholar]
- Hong, L.; Luo, M.; Wang, R.; Lu, P.; Lu, W.; Lu, L. Big Data in Health Care: Applications and Challenges. Data Inf. Manag. 2018, 2, 175–197. [Google Scholar] [CrossRef]
- Dhiman, G.; Juneja, S.; Mohafez, H.; El-Bayoumy, I.; Sharma, L.K.; Hadizadeh, M.; Islam, M.A.; Viriyasitavat, W.; Khandaker, M.U. Federated Learning Approach to Protect Healthcare Data over Big Data Scenario. Sustainability 2022, 14, 2500. [Google Scholar] [CrossRef]
- Juddoo, S.; George, C. A Qualitative Assessment of Machine Learning Support for Detecting Data Completeness and Accuracy Issues to Improve Data Analytics in Big Data for the Healthcare Industry. In Proceedings of the 2020 3rd International Conference on Emerging Trends in Electrical, Electronic and Communications Engineering (ELECOM), Balaclava, Mauritius, 25–27 November 2020; pp. 58–66. [Google Scholar]
- Roski, J.; Bo-Linn, G.W.; Andrews, T.A. Creating Value in Health Care through Big Data: Opportunities and Policy Implications. Health Aff. 2014, 33, 1115–1122. [Google Scholar] [CrossRef] [PubMed]
- Viceconti, M.; Hunter, P.; Hose, R. Big Data, Big Knowledge: Big Data for Personalized Healthcare. IEEE J. Biomed. Health Inform. 2015, 19, 1209–1215. [Google Scholar] [CrossRef] [PubMed]
- Belle, A.; Thiagarajan, R.; Soroushmehr, S.M.; Navidi, F.; Beard, D.A.; Najarian, K. Big Data Analytics in Healthcare. BioMed Res. Int. 2015, 2015, 370194. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Guo, S.-L.; Han, L.-N.; Li, T.-L. Application and Exploration of Big Data Mining in Clinical Medicine. Chin. Med. J. 2016, 129, 731–738. [Google Scholar] [CrossRef]
- Peñafiel, S.; Baloian, N.; Pino, J.A.; Quinteros, J.; Riquelme, Á.; Sanson, H.; Teoh, D. Associating Risks of Getting Strokes with Data from Health Checkup Records Using Dempster-Shafer Theory. In Proceedings of the 2018 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon-si, Republic of Korea, 11–14 February 2018; pp. 239–246. [Google Scholar]
- Brown, N.; Cambruzzi, J.; Cox, P.J.; Davies, M.; Dunbar, J.; Plumbley, D.; Sellwood, M.A.; Sim, A.; Williams-Jones, B.I.; Zwierzyna, M. Big Data in Drug Discovery. Prog. Med. Chem. 2018, 57, 277–356. [Google Scholar]
- Sharma, L. Application of Rough Set Theory to Analyze Primary Parameters Causing Death in COVID-19 Patients. In Computational Intelligence for Managing Pandemics; Khamparia, A., Mondal, R.H., Podder, P., Bhushan, B., Albuquerque, V.H.C., Kumar, S., Eds.; Walter de Gruyter: Boston, MA, USA, 2021; Volume 5. [Google Scholar]
- Bikku, T. Multi-Layered Deep Learning Perceptron Approach for Health Risk Prediction. J. Big Data 2020, 7, 50. [Google Scholar] [CrossRef]
- Straszecka, E. Combining Uncertainty and Imprecision in Models of Medical Diagnosis. Inf. Sci. 2006, 176, 3026–3059. [Google Scholar] [CrossRef]
- Jindal, A.; Dua, A.; Kumar, N.; Das, A.K.; Vasilakos, A.V.; Rodrigues, J.J. Providing Healthcare-as-a-Service Using Fuzzy Rule Based Big Data Analytics in Cloud Computing. IEEE J. Biomed. Health Inform. 2018, 22, 1605–1618. [Google Scholar] [CrossRef]
- Majnarić, L.T.; Babič, F.; O’Sullivan, S.; Holzinger, A. AI and Big Data in Healthcare: Towards a More Comprehensive Research Framework for Multimorbidity. J. Clin. Med. 2021, 10, 766. [Google Scholar] [CrossRef]
- Li, W.; Chai, Y.; Khan, F.; Jan, S.R.U.; Verma, S.; Menon, V.G.; Kavita, F.; Li, X. A Comprehensive Survey on Machine Learning-Based Big Data Analytics for IoT-Enabled Smart Healthcare System. Mob. Netw. Appl. 2021, 26, 234–252. [Google Scholar] [CrossRef]
- Rizwan, A.; Zoha, A.; Zhang, R.; Ahmad, W.; Arshad, K.; Ali, N.A.; Alomainy, A.; Imran, M.A.; Abbasi, Q.H. A Review on the Role of Nano-Communication in Future Healthcare Systems: A Big Data Analytics Perspective. IEEE Access 2018, 6, 41903–41920. [Google Scholar] [CrossRef]
- Dempster, A.P. Upper and Lower Probabilities Induced by a Multivalued Mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Zadeh, L. Fuzzy Sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Peckol, J.K. Introduction to Fuzzy Logic; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Pawlak, Z. Rough Set Theory and Its Applications to Data Analysis. Cybern. Syst. 1998, 29, 661–688. [Google Scholar] [CrossRef]
- Sánchez-Gutiérrez, M.E.; González-Pérez, P.P. Multi-Class Classification of Medical Data Based on Neural Network Pruning and Information-Entropy Measures. Entropy 2022, 24, 196. [Google Scholar] [CrossRef] [PubMed]
- Mardani, A.; Hooker, R.E.; Ozkul, S.; Yifan, S.; Nilashi, M.; Sabzi, H.Z.; Fei, G.C. Application of Decision Making and Fuzzy Sets Theory to Evaluate the Healthcare and Medical Problems: A Review of Three Decades of Research with Recent Developments. Expert Syst. Appl. 2019, 137, 202–231. [Google Scholar] [CrossRef]
- Ribeiro, L.A.P.A.; Garcia, A.C.B.; dos Santos, P.S.M. Temporal and Causal Relations on Evidence Theory: An Application on Adverse Drug Reactions. In Proceedings of the International FLAIRS Conference Proceedings, Clearwater Beach, FL, USA, 14–17 May 2023; Volume 34. [Google Scholar]




| QA ID | Checklist Questions | Answer |
|---|---|---|
| QA1 | Are the study’s objectives well defined? | |
| QA2 | Has the proposed theory/model/framework been clearly articulated and explained? | Y—Yes = 1/ |
| QA3 | Has the chosen methodology (research approach) been appropriately applied to the subject matter? | P—Partially = 0.5/ N—No = 0.5 |
| QA4 | Does the research information presented have value for extensive academic research or employers? |
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| The articles need to be written in English. | Any studies are written in other languages |
| All papers focus on the issues, challenges, and implications of dealing with imperfect information within the context of utilizing BDA in Hos. | Papers that had no connection to the study’s questions |
| Related articles released between 2013 and 2023 | Unfinished studies include grey ones that do not apply to the research’s goals. |
| Articles that may provide insight into at least one research question. | Duplicate papers |
| Only empirical studies that examined factors and theories associated with imperfect information in HOs were included. | This only suggests that it is impossible to confirm the validity of articles for which search engines or authors did not make the text available. |
| Articles (≥3 pages) | Short articles (<3 pages) |
| No. | Authors | Selected Studies | Location(s) |
|---|---|---|---|
| 1 | Alizadehsani [26] | Handling of uncertainty in medical data using machine learning and probability theory techniques: A review of 30 years (1991–2020). | Australia |
| 2 | Andreu-Perez [27] | Big data for health. | UK, USA, China |
| 3 | Bania & Halder [28] | R-Ensemble: A greedy rough set-based ensemble attribute selection algorithm with kNN imputation for classification of medical data. | India |
| 4 | Basha [29] | Utilizing machine learning and big data in healthcare systems. | India |
| 5 | Bates [30] | Why policymakers should care about “big data” in healthcare. | USA |
| 6 | Costa [31] | Big data in biomedicine. | USA, Brazil |
| 7 | Dhand [32] | Deep enriched salp swarm optimization based bidirectional long short-term memory model for healthcare monitoring system in big data. | India |
| 8 | Fatt & Ramadas [33] | The usefulness and challenges of big data in healthcare. | Malaysia |
| 9 | Ghorbel [34] | Handling data imperfection—False data inputs in applications for Alzheimer’s patients. | France, Tunisia |
| 10 | Gomes [35] | Transforming healthcare with big data analytics: Technologies, techniques and prospects. | Brazil |
| 11 | Fu [36] | Disjunctive belief rule-based reasoning for decision making with incomplete information. | China |
| 12 | Han [37] | Varieties of uncertainty in health care: a conceptual taxonomy. | USA |
| 13 | Hariri [38] | Uncertainty in big data analytics: Survey, opportunities, and challenges. | USA |
| 14 | Kaur [39] | Big data analytics in healthcare: A review. | India |
| 15 | Martin-Sanchez & Verspoor [40] | Big data in medicine is driving big changes. | Australia |
| 16 | Mayston [41] | Health care reform: A study in imperfect information. | UK |
| 17 | Mehta & Pandit [42] | Concurrence of big data analytics and healthcare: A systematic review. | India |
| 18 | Nascimento [10] | Impact of big data analytics on people’s health: Overview of systematic reviews and recommendations for future studies. | Brazil, USA |
| 19 | Nazir [43] | A comprehensive analysis of healthcare big data management, analytics and scientific programming. | Pakistan |
| 20 | Ola & Sedig [44] | The challenge of big data in public health: An opportunity for visual analytics. | USA |
| 21 | Palanisamy & Thirunavukarasu [45] | Implications of big data analytics in developing healthcare frameworks—A review. | India |
| 22 | Pisana [46] | Challenges and opportunities with routinely collected data on the utilization of cancer medicines: Perspectives from health authority personnel across 18 European countries. | Sweden |
| 23 | Qian [47] | Multi-label feature selection based on information entropy fusion in multi-source decision system. | China |
| 24 | Rosenfeld [48] | Big data analytics and artificial intelligence in mental healthcare. | Israel |
| 25 | Sachan [49] | Evidential reasoning for preprocessing uncertain categorical data for trustworthy decisions: An application on healthcare and finance. | UK |
| 26 | Secundo [50] | Digital technologies and collective intelligence for healthcare ecosystem: Optimizing Internet of things adoption for pandemic management. | UK |
| 27 | Singh [51] | The impact of imperfect information on the health insurance choice, health outcomes, and medical expenditures of the elderly. | USA |
| 28 | Sohail [52] | Multilevel privacy assurance evaluation of healthcare metadata. | The Netherlands |
| 29 | Yang [53] | Incomplete information management using an improved belief entropy in Dempster–Shafer evidence theory. | China |
| 30 | Chen & Zhang [54] | Explores how relative advantage and perceived credibility impact uptake of mobile health services by an organization and how environmental unpredictability alters these relationships. | China |
| 31 | Dereli [55] | Understanding risk, uncertainty, and ignorance in big data and ethics reviews for health systems research in low-income countries. | Turkey |
| 32 | Wouters [56] | Recognizing the challenges and uncertainties faced when conducting big data health research. | The Netherlands |
| 33 | Bag [57] | Investigate the influence of innovation leadership on big data analytics (BDA) on healthcare supply chain (HSC) innovation, responsiveness, and resilience in the context of the COVID-19 pandemic. | Taiwan |
| 34 | Abdel-Basset [58] | Estimating the selection of smart medical devices (SMDs) in a group decision-making (GDM) setting in a hazy decision-making setting. | Egypt |
| 35 | Pritzker [59] | The objective of precision medicine is to give patients more effective treatments that are informed by more accurate diagnoses. | Canada |
| 36 | Lv & Qiao [60] | Examine how China’s healthcare system is developing as well as the privacy and security risks associated with medical data against the backdrop of big data. | China |
| 37 | Pramanik [61] | A systematic assessment of various big data and smart system technologies, a critique of cutting-edge advanced healthcare systems, and a description of the three-dimensional paradigm shift. | Hong Kong |
| 38 | Herland [62] | Cite current studies that analyze health informatics data collected at many levels, including the molecular, tissue, patient, and population levels, utilizing big data tools and methodologies. | USA |
| 39 | Dyczkowski [63] | Describe and discuss the theoretical underpinnings of the system that the author and his colleagues developed, OvaExpert. | Poland |
| 40 | Dinov [64] | Give examples of how to use distributed cloud services, automated and semi-automatic classification methods, and open science protocols to analyze heterogeneous datasets. | USA |
| 41 | Duggal [65] | Use of big data analytic methods like fuzzy matching algorithms and MapReduce is suggested as a solution to the issue of matching patient records from different systems. | India |
| 42 | Hong [66] | The purpose of the review was to enumerate the characteristics, uses, methods of analysis, and difficulties of big data in health care. | China |
| 43 | Dhiman [67] | The use of anonymity technology and differential privacy in data collecting can help avoid attacks based on background information derived through data integration and fusion. | India |
| 44 | Juddoo & George [68] | Examine the prospects for employing machine learning in the process of identifying data incompleteness and inaccuracy, since these two data quality dimensions were considered to be the most significant by the authors’ prior research study. | Mauritius |
| 45 | Roski [69] | Investigates these issues as well as the prospects for integrating big data into the healthcare system. | USA |
| 46 | Viceconti [70] | Big data analytics and VPH technology may be effectively coupled to provide reliable and efficient in silico medical solutions. | Italy |
| 47 | Belle [71] | Focus on three new and promising fields of medical research, address some of the significant challenges: analytics using image, signal, and genomics. | USA |
| 48 | Zhang [72] | Examines big data mining ideas, methods, and their use in clinical practice. | China |
| 49 | Peñafiel [73] | Compare the Dempster–Shafer method’s outcomes to those of other machine learning techniques. | Chile |
| 50 | Brown [74] | Showcase some of the amazing public domain materials and projects that are currently available for examination to explain big data in the context of biology, chemistry, and clinical trials. | UK |
| 51 | Sharma [75] | In intelligent information systems, large data analysis is essential. | India |
| 52 | Bikku [76] | Focuses on using deep learning to predict sickness using historical medical data. | India |
| 53 | Mardani [7] | Analyzes conventional and fuzzy decision-making approaches used in healthcare and medical concerns in a comprehensive manner. | USA |
| 54 | Straszecka [77] | Proposes a unified fuzzy-probabilistic framework for modeling medical diagnostic procedures. | Poland |
| 55 | Jindal [78] | To deliver Healthcare-as-a-Service. The suggested approach is based on the development of initial clusters, retrieval, and processing of massive data in a cloud environment. | UK |
| 56 | Majnarić [79] | Integration and deployment of effective AI technologies, notably deep learning, into clinical routines directly into medical practitioners’ workflows. | Croatia |
| 57 | Li [80] | Give healthcare practitioners and government organizations with insight into the current developments in ML-based big data analytics for smart healthcare. | Vietnam |
| 58 | Rizwan [81] | Delivers a first-of-its-kind assessment of the open literature on the relevance of big data created by nano-sensors and nano-communication networks for future healthcare and biological applications. |
| Code | Factor | Description | Source |
|---|---|---|---|
| P1 | Uncertainty | The data are ambiguous when they are not well characterized. A doubt over the integrity of the information is also reflected in uncertainty. | [31,33,37,54,55,56,57,58] |
| P2 | Imprecision | Imprecision is related to the data’s inherent potential for ambiguity. Additionally, it alludes to the challenge of clearly and exactly expressing knowledge. | [34,52,58,59] |
| P3 | Vagueness | Data that is ambiguous is related to vagueness. | [58,60,61,62] |
| P4 | Incompleteness | The absence of data is referred to as incompleteness. It also has to do with incomplete or lacking knowledge. | [61,63,65,66,67,68] |
| P5 | Complexity | Simple definitions of complexity include difficulty, a state of being unclear, or intricate. | [36,42,52,61,69,70,71] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orlu, G.U.; Abdullah, R.B.; Zaremohzzabieh, Z.; Jusoh, Y.Y.; Asadi, S.; Qasem, Y.A.M.; Nor, R.N.H.; Mohd Nasir, W.M.H.b. A Systematic Review of Literature on Sustaining Decision-Making in Healthcare Organizations Amid Imperfect Information in the Big Data Era. Sustainability 2023, 15, 15476. https://doi.org/10.3390/su152115476
Orlu GU, Abdullah RB, Zaremohzzabieh Z, Jusoh YY, Asadi S, Qasem YAM, Nor RNH, Mohd Nasir WMHb. A Systematic Review of Literature on Sustaining Decision-Making in Healthcare Organizations Amid Imperfect Information in the Big Data Era. Sustainability. 2023; 15(21):15476. https://doi.org/10.3390/su152115476
Chicago/Turabian StyleOrlu, Glory Urekwere, Rusli Bin Abdullah, Zeinab Zaremohzzabieh, Yusmadi Yah Jusoh, Shahla Asadi, Yousef A. M. Qasem, Rozi Nor Haizan Nor, and Wan Mohd Haffiz bin Mohd Nasir. 2023. "A Systematic Review of Literature on Sustaining Decision-Making in Healthcare Organizations Amid Imperfect Information in the Big Data Era" Sustainability 15, no. 21: 15476. https://doi.org/10.3390/su152115476
APA StyleOrlu, G. U., Abdullah, R. B., Zaremohzzabieh, Z., Jusoh, Y. Y., Asadi, S., Qasem, Y. A. M., Nor, R. N. H., & Mohd Nasir, W. M. H. b. (2023). A Systematic Review of Literature on Sustaining Decision-Making in Healthcare Organizations Amid Imperfect Information in the Big Data Era. Sustainability, 15(21), 15476. https://doi.org/10.3390/su152115476