
Deep-Learning-Based Anti-Collision System for Construction Equipment Operators
Abstract
:1. Introduction
2. Literature Review
2.1. PWS
2.1.1. Tag-Based PWS
2.1.2. Non-Tag-Based PWS
2.2. Object Detection Based Deep Learning
3. Deep Learning-Based Anti-Collision System
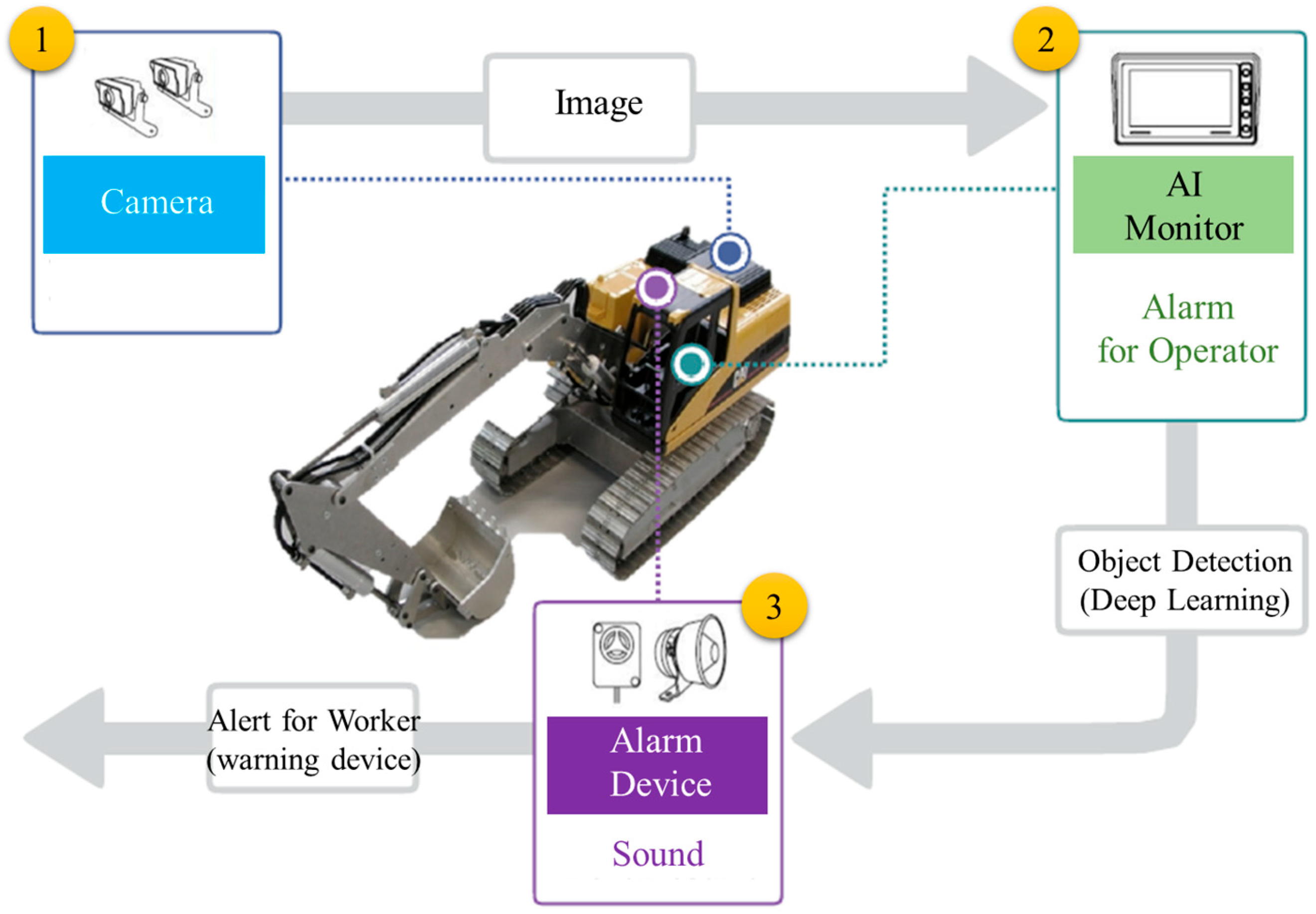
3.1. Overview of the Proposed System
3.2. Object Detection Algorithm
3.2.1. Transfer Learning
3.2.2. YOLO-v4
Bag of Freebies
Bag of Specials
3.3. Training Dataset
3.3.1. Popular Image Dataset
3.3.2. Industrial Worker Dataset-Construction (IWD-C)
3.4. Implementation of the Proposed System
3.4.1. Hardware Description
3.4.2. NVIDIA Jetson Nano for Inference
3.4.3. User Interface of the AI Monitor
4. Evaluation
4.1. Bounding-Box Merging and Extension
4.2. Performance Evaluation
5. Field Test
5.1. Static Test
5.1.1. Maximum Detection Distance Test
5.1.2. Detection Performance Test According to the Camera Angle of View and Distance
5.2. Dynamic Test
6. Conclusions
6.1. Summary
6.2. Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jo, B.W.; Lee, Y.S.; Kim, J.H.; Khan, R.M.A. Trend Analysis of Construction Industrial Accidents in Korea from 2011 to 2015. Sustainability 2017, 9, 1297. [Google Scholar] [CrossRef]
- Kim, D.; Liu, M.; Lee, S.; Kamat, V.R. Remote proximity monitoring between mobile construction resources using camera-mounted UAVs. Autom. Constr. 2019, 99, 168–182. [Google Scholar] [CrossRef]
- Park, J.; Yang, X.; Cho, Y.K.; Seo, J. Improving dynamic proximity sensing and processing for smart work-zone safety. Autom. Constr. 2017, 84, 111–120. [Google Scholar] [CrossRef]
- Teizer, J.; Allread, B.S.; Fullerton, C.E.; Hinze, J. Autonomous pro-active real-time construction worker and equipment operator proximity safety alert system. Autom. Constr. 2010, 19, 630–640. [Google Scholar] [CrossRef]
- Kim, K.; Kim, H.; Kim, H. Image-based construction hazard avoidance system using augmented reality in wearable device. Autom. Constr. 2017, 83, 390–403. [Google Scholar] [CrossRef]
- Jo, B.-W.; Lee, Y.-S.; Khan, R.M.A.; Kim, J.-H.; Kim, D.-K. Robust Construction Safety System (RCSS) for Collision Accidents Prevention on Construction Sites. Sensors 2019, 19, 932. [Google Scholar] [CrossRef] [PubMed]
- Ruff, T. Recommendations for Evaluating and Implementing Proximity Warning Systems on Surface Mining Equipment; US Department of Health and Human Services: Washington, DC, USA, 2007. Available online: https://www.cdc.gov/niosh/mining/works/coversheet202.html#print (accessed on 5 September 2023).
- Ruff, T.M.; Hession-Kunz, D. Application of radio-frequency identification systems to collision avoidance in metal/nonmetal mines. IEEE Trans. Ind. Appl. 2001, 37, 112–116. [Google Scholar] [CrossRef]
- Marks, E.D.; Teizer, J. Method for testing proximity detection and alert technology for safe construction equipment operation. Constr. Manag. Econ. 2013, 31, 636–646. [Google Scholar] [CrossRef]
- Ruff, T.M. Test Results of Collision Warning Systems for Surface Mining Dump Trucks; US Department of Health and Human Services: Washington, DC, USA, 2000.
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Cheng, T.; Venugopal, M.; Teizer, J.; Vela, P.A. Performance evaluation of ultra wideband technology for construction resource location tracking in harsh environments. Autom. Constr. 2011, 20, 1173–1184. [Google Scholar] [CrossRef]
- El-Rabbany, A. Introduction to GPS: The Global Positioning System; Artech House: New York, NY, USA, 2002. [Google Scholar]
- Vega, A.N. Development of a Real-time Proximity Warning and 3-D Mapping System Based on Wireless Networks, Virtual Reality Graphics, and GPS to Improve Safety in Open-Pit Mines; Colorado School of Mines Golden: Golden, CO, USA, 2001. [Google Scholar]
- Nieto, A.; Dagdelen, K. Accuracy Testing of a Vehicle Proximity Warning System based on GPS and Wireless Networks. Int. J. Surf. Min. Reclam. Environ. 2003, 17, 156–170. [Google Scholar] [CrossRef]
- Nieto, A.; Dagdelen, K. Development and testing of a vehicle collision avoidance system based on GPS and wireless networks for open-pit mines. Appl. Comput. Oper. Res. Miner. Ind. 2003, 31, 27–34. [Google Scholar]
- Nieto, A.; Miller, S.; Miller, R. GPS proximity warning system for at-rest large mobile equipment. Int. J. Surf. Min. Reclam. Environ. 2005, 19, 75–84. [Google Scholar] [CrossRef]
- Song, J.; Haas, C.T.; Caldas, C.H. A proximity-based method for locating RFID tagged objects. Adv. Eng. Inform. 2007, 21, 367–376. [Google Scholar] [CrossRef]
- Chae, S.; Yoshida, T. Application of RFID technology to prevention of collision accident with heavy equipment. Autom. Constr. 2010, 19, 368–374. [Google Scholar] [CrossRef]
- Lee, H.-S.; Lee, K.-P.; Park, M.; Baek, Y.; Lee, S. RFID-Based Real-Time Locating System for Construction Safety Management. J. Comput. Civ. Eng. 2012, 26, 366–377. [Google Scholar] [CrossRef]
- Kelm, A.; Laußat, L.; Meins-Becker, A.; Platz, D.; Khazaee, M.J.; Costin, A.M.; Helmus, M.; Teizer, J. Mobile passive Radio Frequency Identification (RFID) portal for automated and rapid control of Personal Protective Equipment (PPE) on construction sites. Autom. Constr. 2013, 36, 38–52. [Google Scholar] [CrossRef]
- Teizer, J. Wearable, wireless identification sensing platform: Self-monitoring alert and reporting technology for hazard avoidance and training (SmartHat). J. Inf. Technol. Constr. ITcon 2015, 20, 295–312. [Google Scholar]
- Jo, B.-W.; Lee, Y.-S.; Kim, J.-H.; Kim, D.-K.; Choi, P.-H. Proximity Warning and Excavator Control System for Prevention of Collision Accidents. Sustainability 2017, 9, 1488. [Google Scholar] [CrossRef]
- Enji, S.; Nieto, A.; Zhongxue, L. GPS and Google Earth based 3D assisted driving system for trucks in surface mines. Min. Sci. Technol. China 2010, 20, 138–142. [Google Scholar]
- Ruff, T. Test Results of Collision Warning Systems on Off-Highway Dump Trucks; US Department of Health and Human Services: Washington, DC, USA, 2000.
- Ruff, T. Evaluation of a radar-based proximity warning system for off-highway dump trucks. Accid. Anal. Prev. 2006, 38, 92–98. [Google Scholar] [CrossRef]
- Choe, S.; Leite, F.; Seedah, D.; Caldas, C. Evaluation of sensing technology for the prevention of backover accidents in construction work zones. J. Inf. Technol. Constr. ITcon 2014, 19, 1–19. [Google Scholar]
- Ruff, T.M. Recommendations for Testing Radar-Based Collision Warning Systems on Heavy Equipment; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2002. Available online: https://stacks.cdc.gov/view/cdc/9496#tabs-2 (accessed on 5 September 2023).
- Zhao, Z.-Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Kim, J.; Hwang, J.; Chi, S.; Seo, J. Towards database-free vision-based monitoring on construction sites: A deep active learning approach. Autom. Constr. 2020, 120, 103376. [Google Scholar] [CrossRef]
- Bhowmick, S.; Nagarajaiah, S.; Veeraraghavan, A. Vision and Deep Learning-Based Algorithms to Detect and Quantify Cracks on Concrete Surfaces from UAV Videos. Sensors 2020, 20, 6299. [Google Scholar] [CrossRef] [PubMed]
- Shim, S.; Korea Institute of Civil Engineering and Building Technology; Chun, C.; Ryu, S.-K. Road Surface Damage Detection based on Object Recognition using Fast R-CNN. J. Korea Inst. Intell. Transp. Syst. 2019, 18, 104–113. [Google Scholar] [CrossRef]
- Spencer, B.F., Jr.; Hoskere, V.; Narazaki, Y. Advances in Computer Vision-Based Civil Infrastructure Inspection and Monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Rasul, A.; Seo, J.; Oh, K.; Khajepour, A.; Reginald, N. Predicted Safety Algorithms for Autonomous Excavators Using a 3D LiDAR Sensor. In Proceedings of the 2020 IEEE International Systems Conference (SysCon), Montreal, QC, Canada, 24 August–20 September 2020. [Google Scholar]
- Fremont, V.; Bui, M.T.; Boukerroui, D.; Letort, P. Vision-Based People Detection System for Heavy Machine Applications. Sensors 2016, 16, 128. [Google Scholar] [CrossRef] [PubMed]
- Jeelani, I.; Asadi, K.; Ramshankar, H.; Han, K.; Albert, A. Real-time vision-based worker localization & hazard detection for construction. Autom. Constr. 2020, 121, 103448. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Uijlings, J.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Wang, L. Support Vector Machines: Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005; Volume 177. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? arXiv 2019, arXiv:1906.02629. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. arXiv 2018, arXiv:1810.12890. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-iteration batch normalization. arXiv 2020, arXiv:2002.05712. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning 2015, PMLR, Lille, France, 6–11 July 2015. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xiang, Y.; Wang, H.; Su, T.; Li, R.; Brach, C.; Mao, S.S.; Geimer, M. Kit moma: A mobile machines dataset. arXiv 2020, arXiv:2007.04198. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Geiger, A.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Nath, N.D.; Behzadan, A.H. Deep Convolutional Networks for Construction Object Detection Under Different Visual Conditions. Front. Built Environ. 2020, 6, 1–22. [Google Scholar] [CrossRef]
- Neuhausen, M.; Pawlowski, D.; König, M. Comparing Classical and Modern Machine Learning Techniques for Monitoring Pedestrian Workers in Top-View Construction Site Video Sequences. Appl. Sci. 2020, 10, 8466. [Google Scholar] [CrossRef]
- Jetson Nano. Available online: https://developer.nvidia.com/embedded/jetson-nano (accessed on 27 April 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Main Item | Main Features | Related Research |
|---|---|---|
| RFID | [Advantage] Cost-efficient of RFID-tag Detection function for both daytime and night [Disadvantages] Detection area of uneven Difficulty of maintenance due to the durability of RFID-tag | [8,18,19,20,21,22,23] |
| UWB | [Advantage] Easy installation and data collection More accurate detection of activity object [Disadvantages] Relatively high cost due to object-tag Periodic battery charging of object-tag | [4,6,9,12] |
| GPS | [Advantage] Minimal required device Suitable for long-range detection [Disadvantages] Not available indoors An expensive system is required for precise positioning | [14,15,16,17,24] |
| Main Item | Main Features | Related Research |
|---|---|---|
| Radar | [Advantage] Detection function for both daytime and night Unaffected by weather conditions [Disadvantages] Not able to distinguish a person from other objects Susceptibility to false alarms or nuisance alarms | [10,25,26,27,28] |
| LiDAR | [Advantage] High-resolution object information collection possible The system can identify a ground worker from other objects [Disadvantages] Relatively high-cost sensor High data processing effort | [34] |
| Video Camera | [Advantage] Minimal required device Provides visual object information [Disadvantages] Not available night Highly influenced by weather conditions | [5,35,36] |
| Categories | |||
|---|---|---|---|
| Backbone | BoF | Data augmentation [56] | CutMix [57] Mosaic [55] |
| Data imbalance [58] | Class label smoothing [59] | ||
| Regularization | DropBlock [60] | ||
| BoS | Activation function | Mish [61] | |
| Skip-connection | Cross-stage partial connections (CSP) [62] Multi-input weighted residual connections (MiWRC) | ||
| Detector | BoF | Data augmentation | Mosaic [55] Self-Adversarial Training [55] |
| Regularization | DropBlock [60] | ||
| Objective function | CIoU-loss [63] | ||
| Batch Normalization | CmBN [64] | ||
| Others | Optimal hyperparameters [55] Cosine annealing scheduler [65] Eliminate grid sensitivity [55] Using multiple anchors for a single ground truth [55] Random training shapes [55] | ||
| BoS | Activation function | Mish [61] | |
| Receptive field enhancement | SPP [47,66] | ||
| Attention module | Modified-SAM [67] | ||
| Feature integration | Modified-PAN(Path aggregation network) [68] | ||
| Post-processing | DIoU-NMS [63] | ||
| Construction Site—A (6 May 2021–30 July 2021) | |||
|---|---|---|---|
| Equipment | Excavator 1 | Excavator 2 | Excavator 3 |
| Image |  |  |  |
| Number of videos | 153,205 | 139,461 | 131,498 |
| Construction Site—B (6 May 2021–30 July 2021) | |||
| Equipment | Excavator 1 | Excavator 2 | Excavator 3 |
| Image |  |  |  |
| Number of videos | 67,048 | 73,903 | 115,162 |
| Equipment | Excavator 4 | Excavator 5 | |
| Image |  |  | |
| Number of videos | 81,673 | 64,086 | |
| Construction Site—C (4 June 2021–30 July 2021) | |||
| Equipment | Excavator 1 | Excavator 2 | Excavator 3 |
| Image |  |  |  |
| Number of videos | 41,629 | 69,793 | 40,114 |
| Equipment | Excavator 4 | Excavator 5 | Excavator 6 |
| Image |  |  |  |
| Number of videos | 10,864 | 43,796 | 70,419 |
| Equipment | Excavator 7 | ||
| Image |  | ||
| Number of videos | 53,883 | ||
| Summary | |||
| Number of ① video/② image/③ object | ① 1,156,634 ② 42,620 ③ 57,228 | ||
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
| Classification | Image | Features |
|---|---|---|
| AI monitor |  |
|
| Cameras |  |
|
| Device connector |  |
|
| Splitter cable |  |
|
| Alarm device (Default) |  |
|
| Classification | Specification |
|---|---|
| GPU | NVIDIA Maxwell architecture with 128 NVIDIA CUDA® cores |
| CPU | Quad-core ARM Cortex-A57 MPCore processor |
| Memory | 4 GB 64-bit LPDDR4, 1600 MHz 25.6 GB/s |
| Storage | 16 GB eMMC 5.1 |
| Classification | Image | Features |
|---|---|---|
| Main screen |  |
|
| Object detection |  |
|
| Alert |  |
| CPU | AMD 3700X |
| OS | Ubuntu 18.04 |
| GPU | RTX 2080 Ti |
| RAM | 32 GB |
| Pre-trained Model | YOLO-v4 |
| Batch size | 64 |
| Epoch | 10 |
| Learning rate | 0.001 |
| Framework | Darknet |
| IWD-C | CrowdHuman | Total | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ① | ② | ③ | ④ | ① | ② | ③ | ④ | ① | ② | ③ | ④ |
| 42,620 | 42,726 | 58,089 | 57,228 | 59,736 | 48,154 | 38,802 | 72,318 | 102,356 | 90,880 | 96,891 | 129,546 |
| Model | ① | ② | ③ | ④ | ⑤ | ⑥ | ⑦ | ⑧ |
|---|---|---|---|---|---|---|---|---|
| YOLO-v4 | 80.8% | 91.3% | 88.7% | 86.9% | 0.78 | 0.73 | 0.84 | 34 |
| Position | Test Image | Detection Rate | Position | Test Image | Detection Rate |
|---|---|---|---|---|---|
| 1 m |  | 100 | 7 m |  | 100 |
| 2 m |  | 100 | 8 m |  | 100 |
| 3 m |  | 100 | 9 m |  | 100 |
| 4 m |  | 100 | 10 m |  | 100 |
| 5 m |  | 100 | 11 m |  | 100 |
| 6 m |  | 100 | 12 m |  | 83.2 |
| Position | (%) | (%) | (%) | (%) | (%) |
|---|---|---|---|---|---|
| 1 m |  |  |  |  |  |
| 98.7 | 100 | 100 | 100 | 100 | |
| 2 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 3 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 4 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 5 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 6 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 7 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 8 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 9 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 | |
| 10 m |  |  |  |  |  |
| 100 | 100 | 100 | 100 | 100 |
| Type | Starting Point | Ending Point | Average Speed | Test Image | Detection Rate |
|---|---|---|---|---|---|
| Back and Forth | Horizontal Angle -1 m | Horizontal Angle -10 m | about 4 km/h |    | 98.2% |
| Type | Starting Point | Ending Point | Average Speed | Test Image | Detection Rate |
|---|---|---|---|---|---|
| Left and Right | Horizontal Angle -10 m | Horizontal Angle 15-10 m | about 4 km/h |    | 99.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.-S.; Kim, D.-K.; Kim, J.-H. Deep-Learning-Based Anti-Collision System for Construction Equipment Operators. Sustainability 2023, 15, 16163. https://doi.org/10.3390/su152316163
Lee Y-S, Kim D-K, Kim J-H. Deep-Learning-Based Anti-Collision System for Construction Equipment Operators. Sustainability. 2023; 15(23):16163. https://doi.org/10.3390/su152316163
Chicago/Turabian StyleLee, Yun-Sung, Do-Keun Kim, and Jung-Hoon Kim. 2023. "Deep-Learning-Based Anti-Collision System for Construction Equipment Operators" Sustainability 15, no. 23: 16163. https://doi.org/10.3390/su152316163
APA StyleLee, Y.-S., Kim, D.-K., & Kim, J.-H. (2023). Deep-Learning-Based Anti-Collision System for Construction Equipment Operators. Sustainability, 15(23), 16163. https://doi.org/10.3390/su152316163