
Research on Maize Acreage Extraction and Growth Monitoring Based on a Machine Learning Algorithm and Multi-Source Remote Sensing Data

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Data Sources
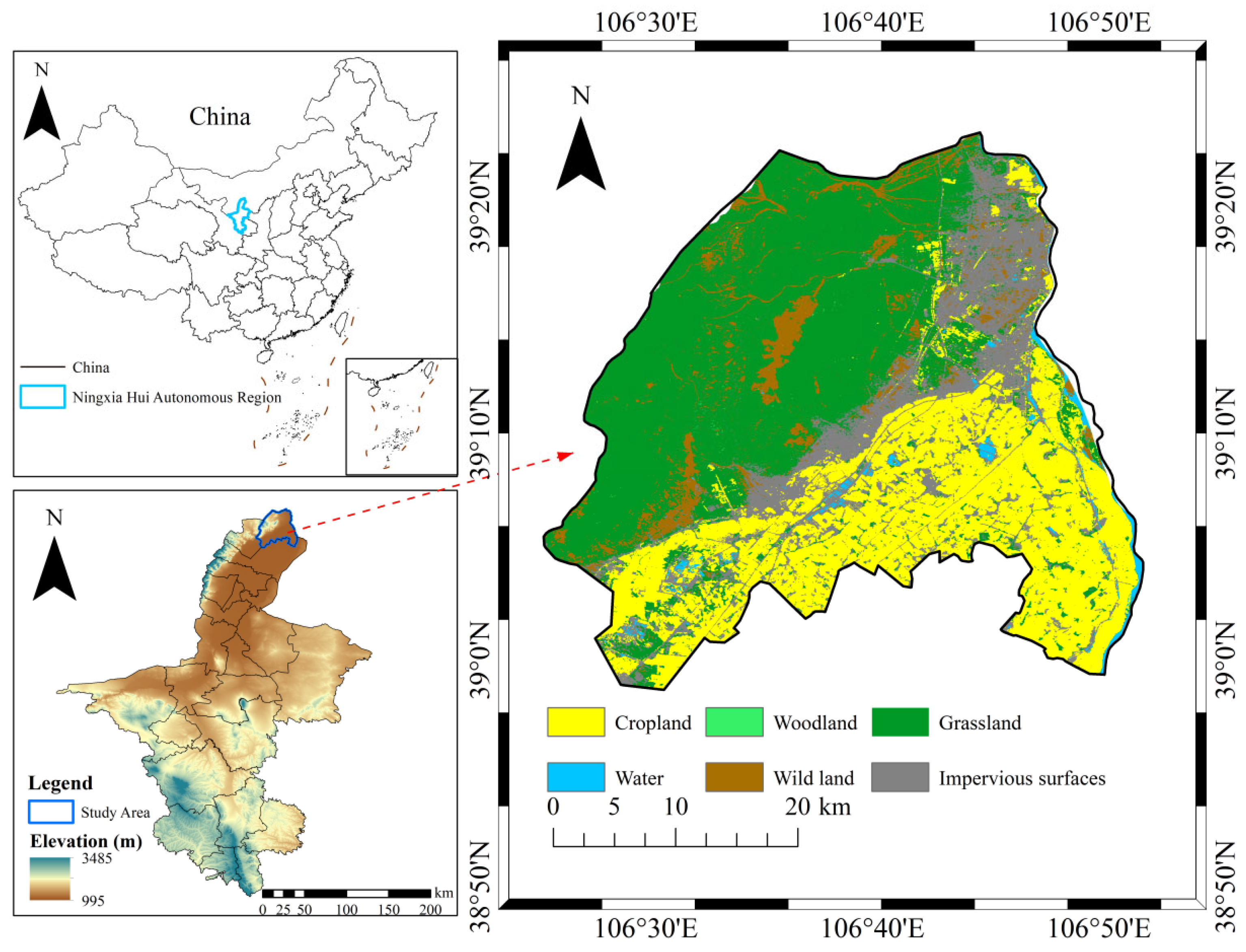
2.1.1. Overview of the Study Area
2.1.2. Overview and Pre-Processing of Remotely Sensed Image Data
2.2. Research Methodology
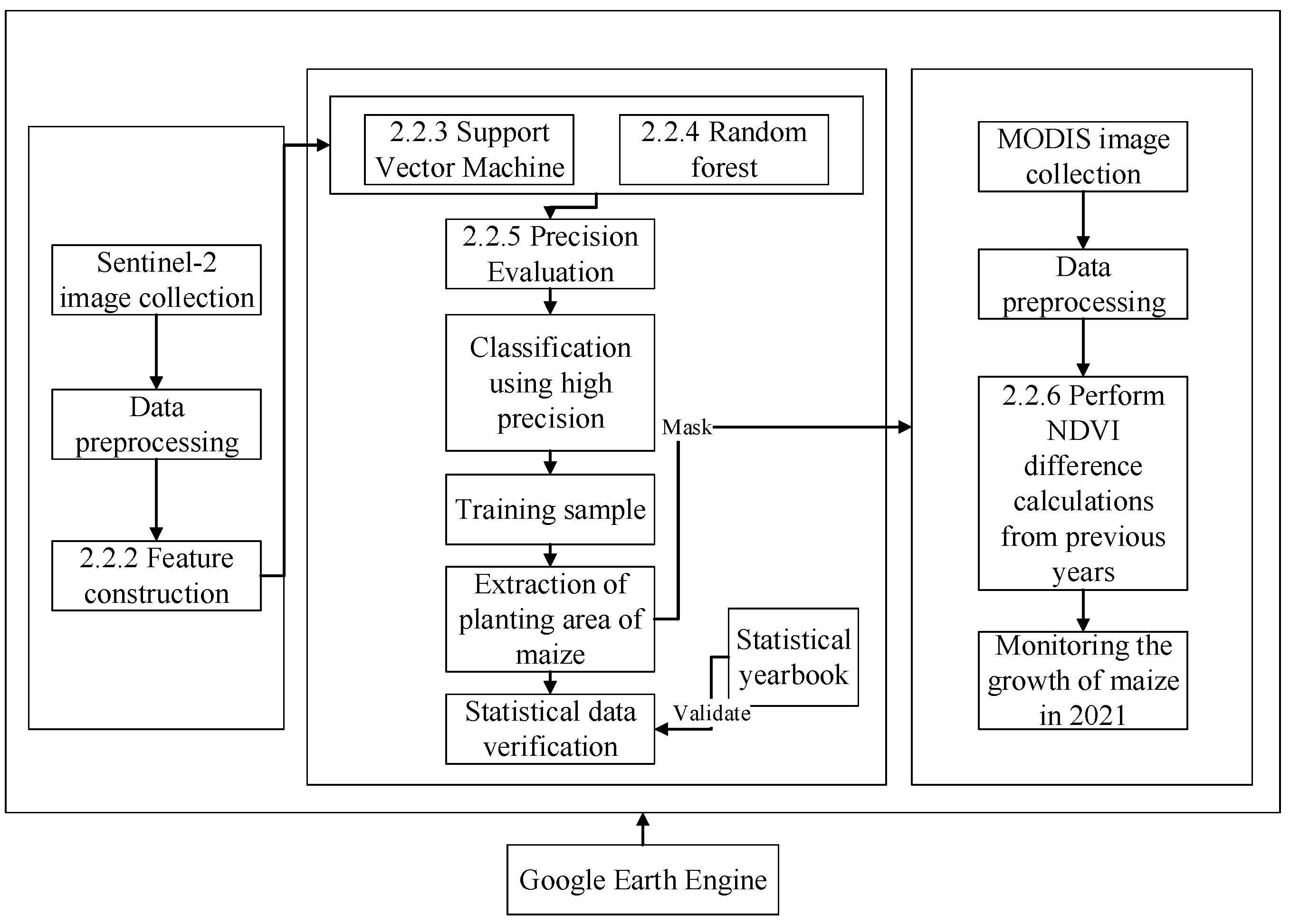
2.2.1. Technical Processes
2.2.2. Training Sample Construction
2.2.3. Support Vector Machine Classification Methods
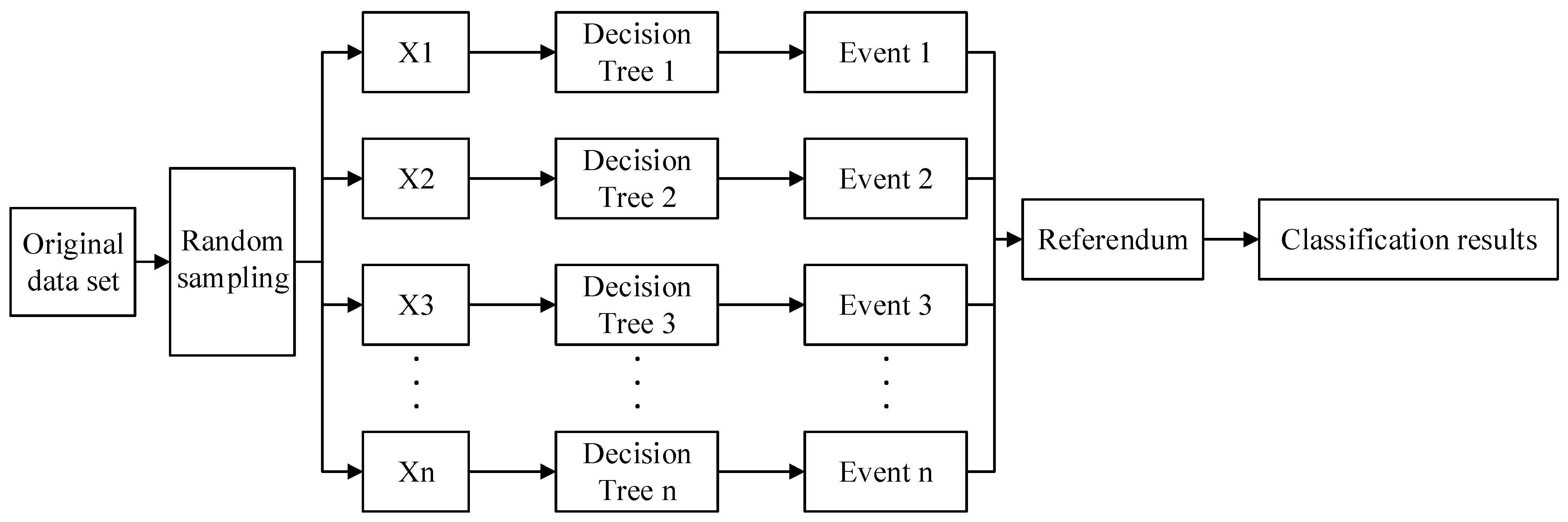
2.2.4. Random Forest Classification Methods
2.2.5. Validation Methods
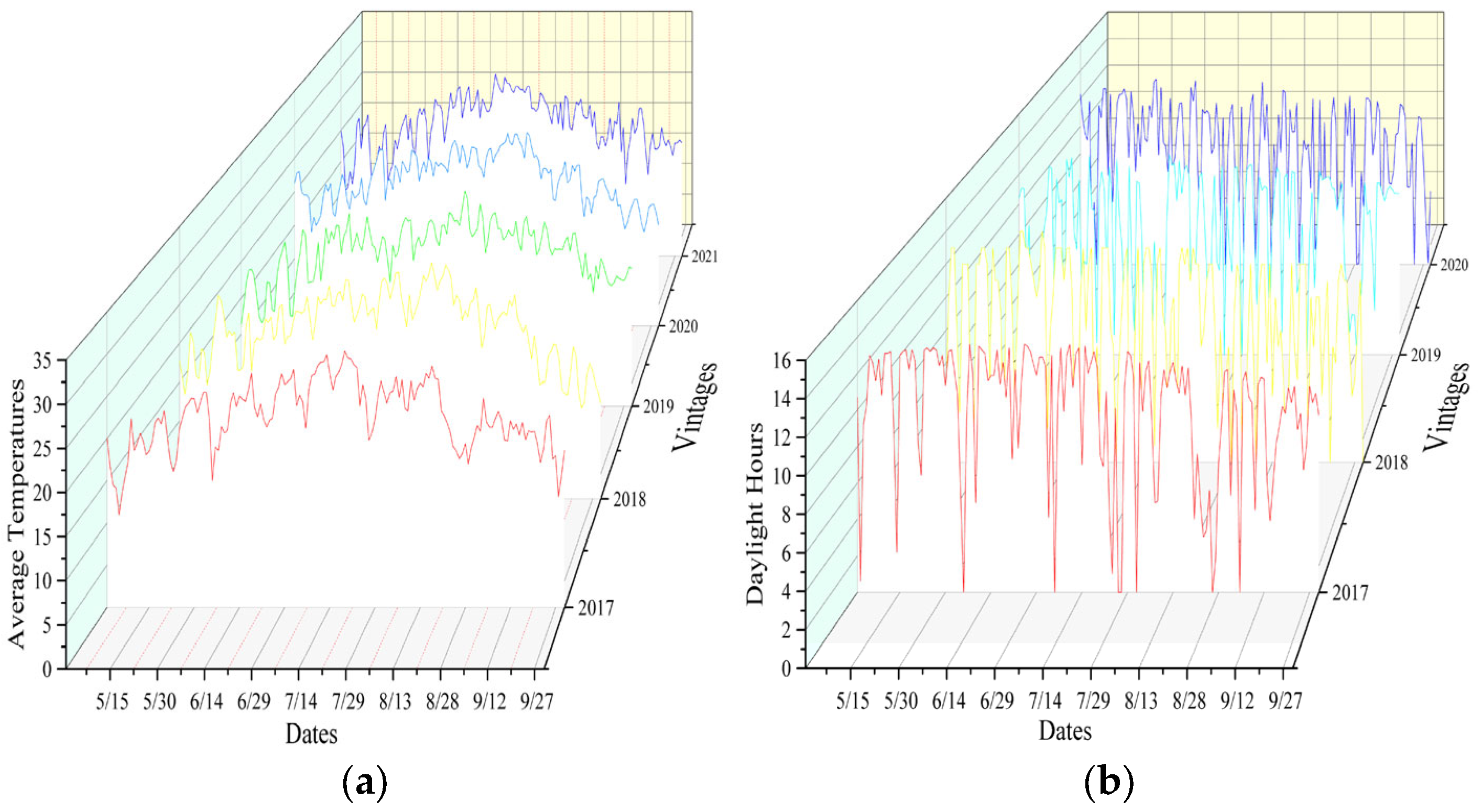
2.2.6. Maize Growth Information Extraction
3. Results and Analyses
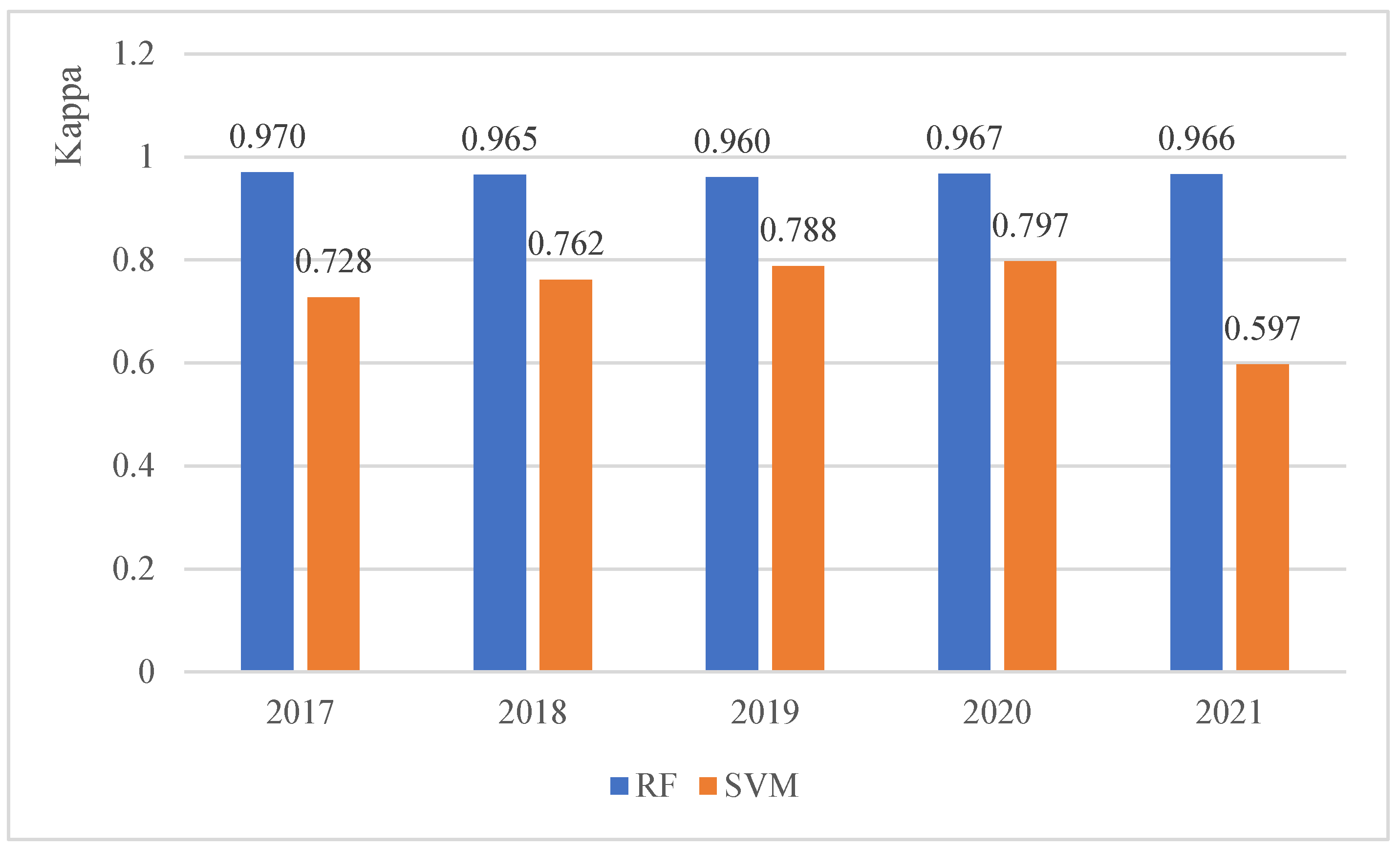
3.1. Comparison of Support Vector Machine and Random Forest Classification Accuracies
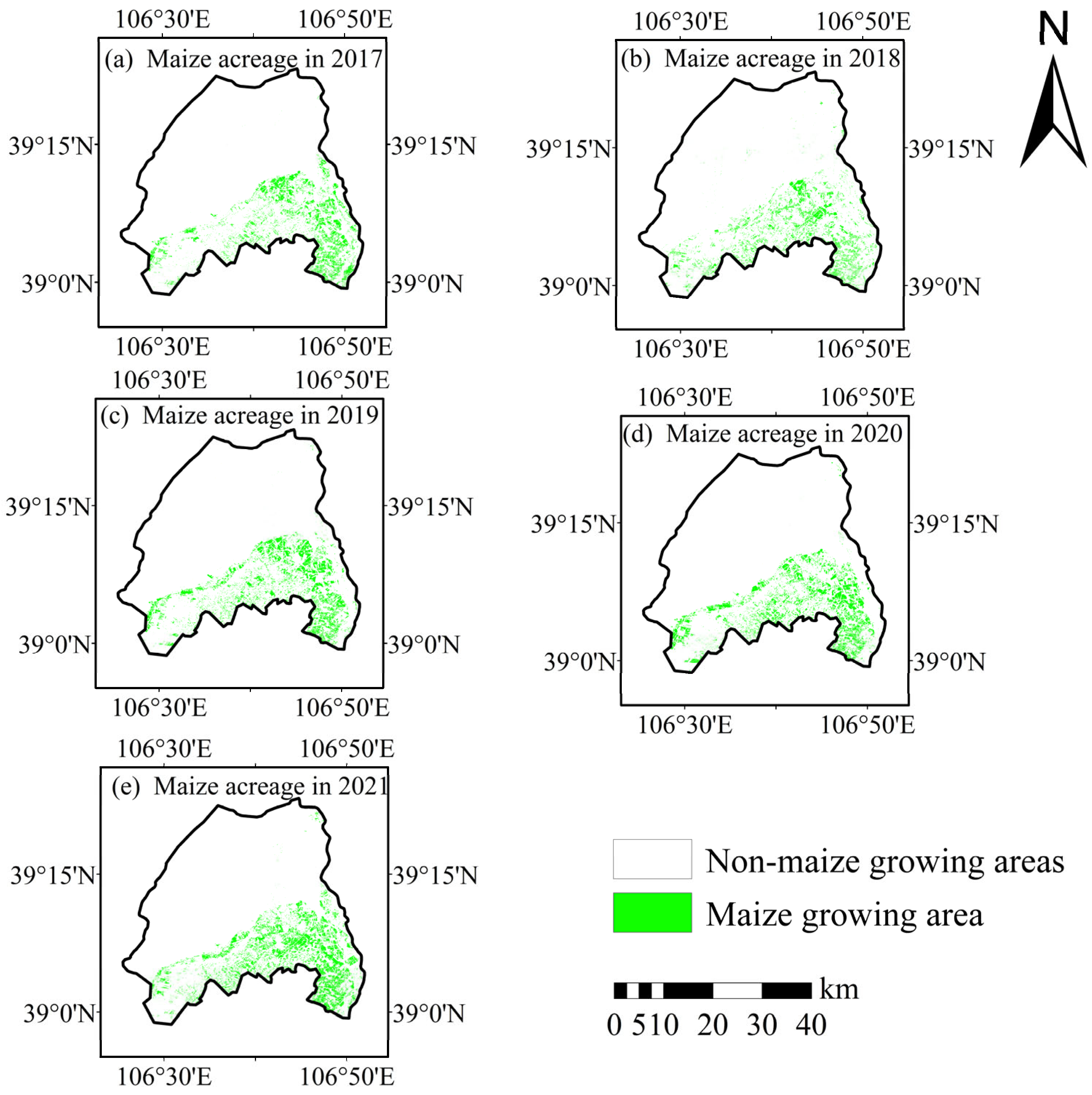
3.2. Area Monitoring Results
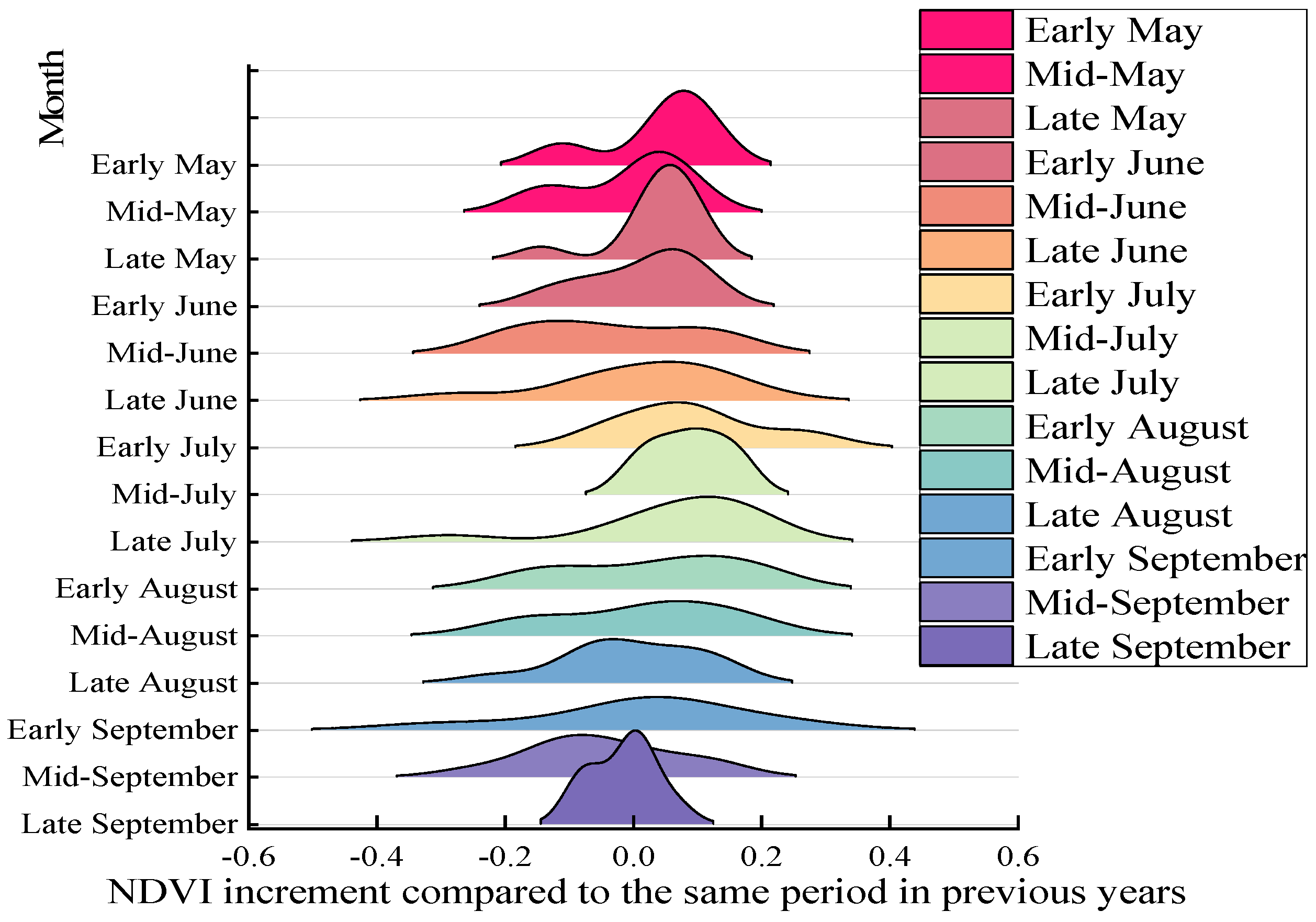
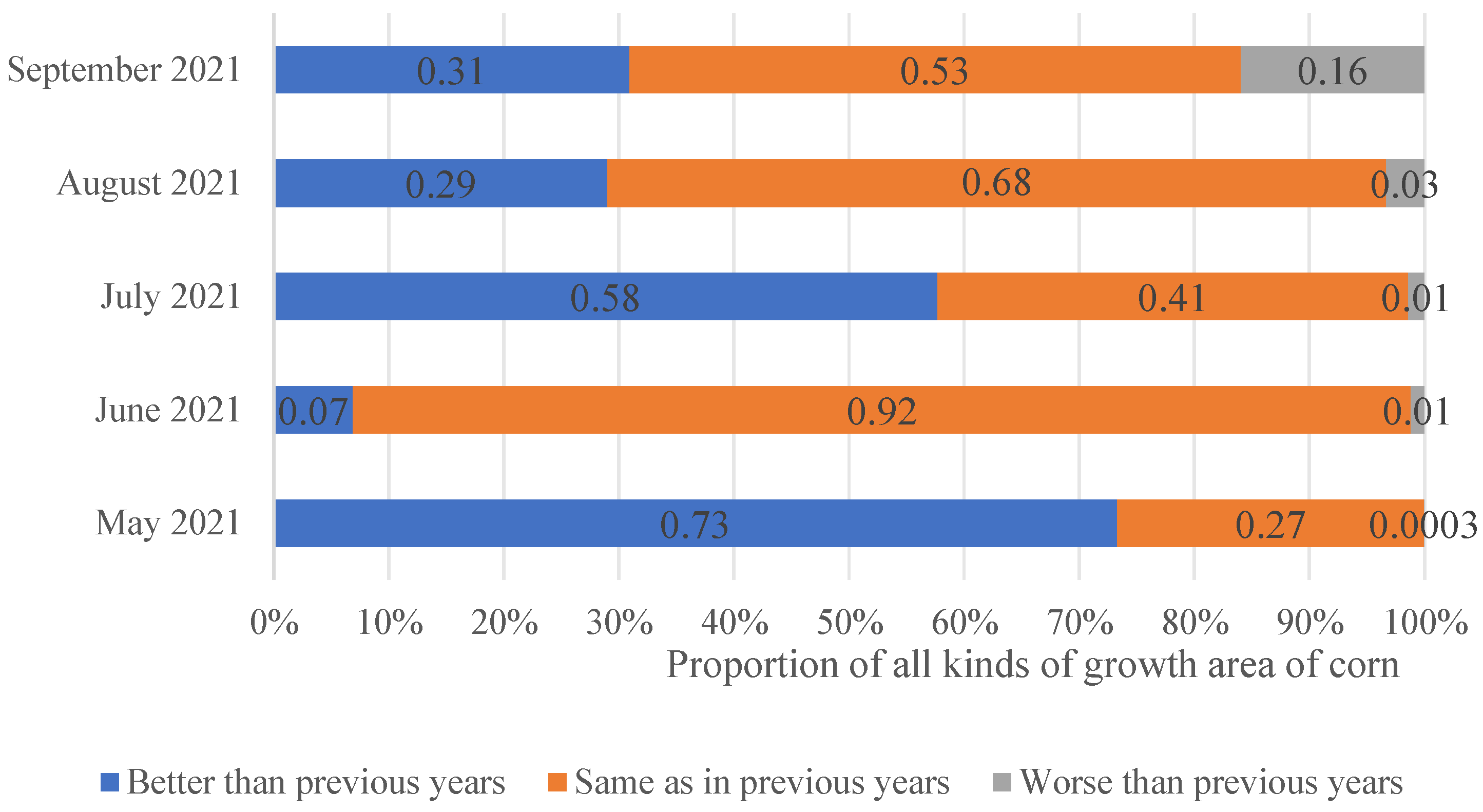
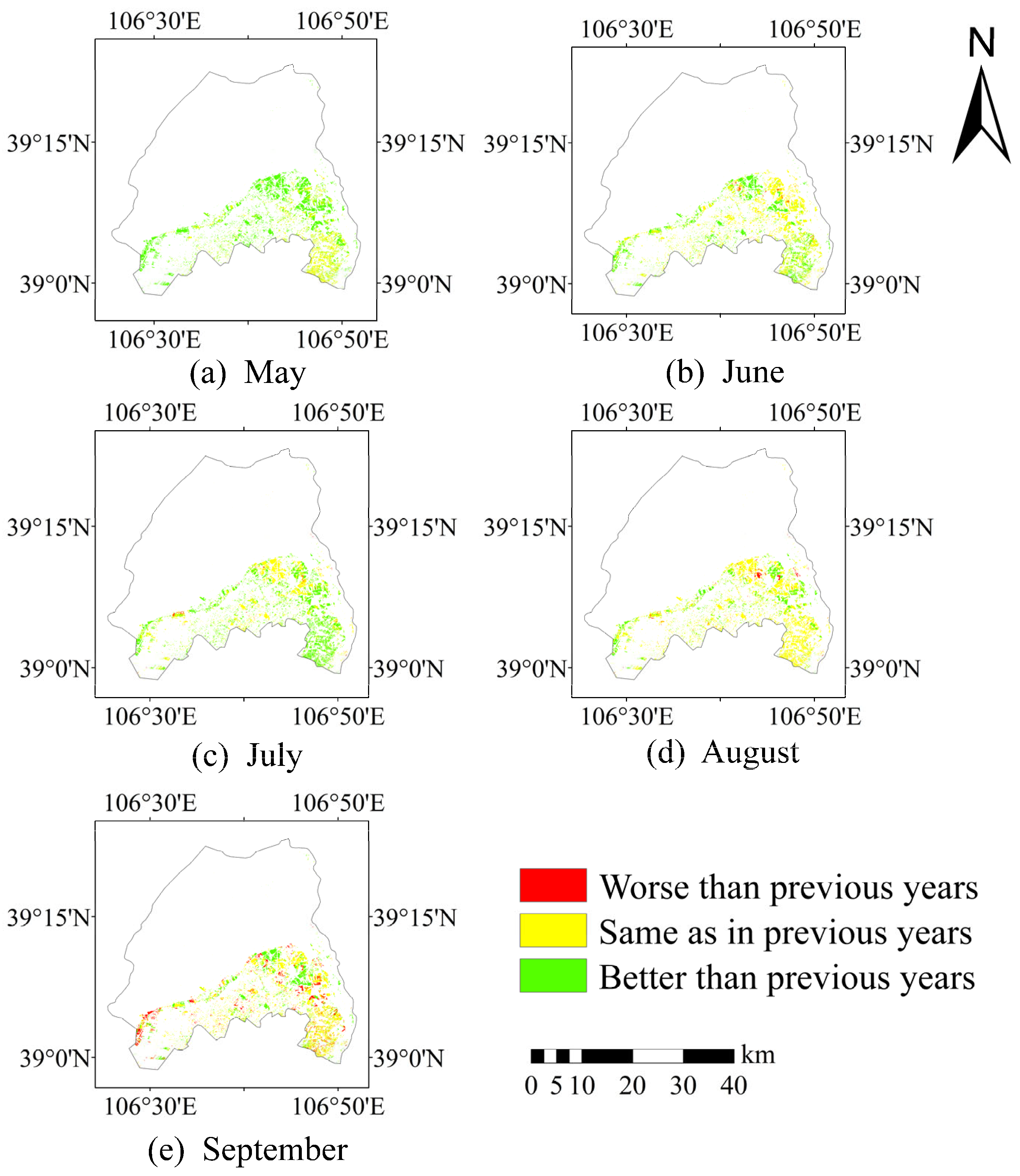
3.3. Growth Test Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fritz, S.; See, L.; McCallum, I.; You, L.; Bun, A.; Moltchanova, E.; Duerauer, M.; Albrecht, F.; Schill, C.; Perger, C.; et al. Mapping Global Cropland and Field Size. Glob. Change Biol. 2015, 21, 1980–1992. [Google Scholar] [CrossRef] [PubMed]
- Fuchs, R.; Herold, M.; Verburg, P.H.; Clevers, J.G.P.W.; Eberle, J. Gross Changes in Reconstructions of Historic Land Cover/Use for Europe between 1900 and 2010. Glob. Change Biol. 2015, 21, 299–313. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Lei, Q.; Liang, X.; Lindsey, S.; Luo, J.; Pei, W.; Du, X.; Wu, S.; An, M.; Qiu, W.; et al. Optimization of the N Footprint Model and Analysis of Nitrogen Pollution in Irrigation Areas: A Case Study of Ningxia Hui Autonomous Region, China. J. Environ. Manag. 2023, 340, 118002. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Feng, L.; Yao, F. Improved Maize Cultivated Area Estimation over a Large Scale Combining MODIS–EVI Time Series Data and Crop Phenological Information. ISPRS J. Photogramm. Remote Sens. 2014, 94, 102–113. [Google Scholar] [CrossRef]
- Tang, K.; Zhu, W.; Zhan, P.; Ding, S. An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features. Remote Sens. 2018, 10, 193. [Google Scholar] [CrossRef]
- Atzberger, C. Advances in Remote Sensing of Agriculture: Context Description, Existing Operational Monitoring Systems and Major Information Needs. Remote Sens. 2013, 5, 949–981. [Google Scholar] [CrossRef]
- Su, W.; Jiang, F.; Zhu, D.; Zhan, J.; Ma, H.; Zhang, X. Extraction of Maize Planting Area Based on Decision Tree and Mixed-Pixel Unmixing Methods. Trans. Chin. Soc. Agric. Mach. 2015, 46, 289–295. [Google Scholar]
- Friedl, M.A.; Brodley, C.E. Decision Tree Classification of Land Cover from Remotely Sensed Data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Luo, C.; Qi, B.; Liu, H.; Guo, D.; Lu, L.; Fu, Q.; Shao, Y. Using Time Series Sentinel-1 Images for Object-Oriented Crop Classification in Google Earth Engine. Remote Sens. 2021, 13, 561. [Google Scholar] [CrossRef]
- Virnodkar, S.; Pachghare, V.K.; Patil, V.C.; Jha, S.K. Performance Evaluation of RF and SVM for Sugarcane Classification Using Sentinel-2 NDVI Time-Series. In Proceedings of the Progress in Advanced Computing and Intelligent Engineering; Panigrahi, C.R., Pati, B., Mohapatra, P., Buyya, R., Li, K.-C., Eds.; Springer: Singapore, 2021; pp. 163–174. [Google Scholar]
- Kwak, G.-H.; Park, N.-W. Impact of Texture Information on Crop Classification with Machine Learning and UAV Images. Appl. Sci. 2019, 9, 643. [Google Scholar] [CrossRef]
- Böhler, J.E.; Schaepman, M.E.; Kneubühler, M. Crop Classification in a Heterogeneous Arable Landscape Using Uncalibrated UAV Data. Remote Sens. 2018, 10, 1282. [Google Scholar] [CrossRef]
- Lee, D.-H.; Kim, H.-J.; Park, J.-H. UAV, a Farm Map, and Machine Learning Technology Convergence Classification Method of a Corn Cultivation Area. Agronomy 2021, 11, 1554. [Google Scholar] [CrossRef]
- Ponganan, N.; Horanont, T.; Artlert, K.; Nuallaong, P. Land Cover Classification Using Google Earth Engine’s Object-Oriented and Machine Learning Classifier. In Proceedings of the 2021 2nd International Conference on Big Data Analytics and Practices (IBDAP), Bangkok, Thailand, 26–27 August 2021; pp. 33–37. [Google Scholar]
- Pott, L.P.; Amado, T.J.C.; Schwalbert, R.A.; Corassa, G.M.; Ciampitti, I.A. Satellite-Based Data Fusion Crop Type Classification and Mapping in Rio Grande Do Sul, Brazil. ISPRS J. Photogramm. Remote Sens. 2021, 176, 196–210. [Google Scholar] [CrossRef]
- Palchowdhuri, Y.; Valcarce-Diñeiro, R.; King, P.; Sanabria-Soto, M. Classification of Multi-Temporal Spectral Indices for Crop Type Mapping: A Case Study in Coalville, UK. J. Agric. Sci. 2018, 156, 24–36. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-Scale Geospatial Analysis for Everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, X.; Menarguez, M.A.; Zhang, G.; Qin, Y.; Thau, D.; Biradar, C.; Moore, B. Mapping Paddy Rice Planting Area in Northeastern Asia with Landsat 8 Images, Phenology-Based Algorithm and Google Earth Engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef]
- Luo, C.; Liu, H.; Fu, Q.; Guan, H.; Ye, Q.; Zhang, X.; Kong, F. Mapping the Fallowed Area of Paddy Fields on Sanjiang Plain of Northeast China to Assist Water Security Assessments. J. Integr. Agric. 2020, 19, 1885–1896. [Google Scholar] [CrossRef]
- Wang, J.; Tian, H.; Wu, M.; Wang, L.; Wang, Z. Rapid Mapping of Winter Wheat in Henan Province. J. Geo-Inf. Sci. 2017, 19, 846–853. [Google Scholar]
- Malenovský, Z.; Rott, H.; Cihlar, J.; Schaepman, M.E.; García-Santos, G.; Fernandes, R.; Berger, M. Sentinels for Science: Potential of Sentinel-1, -2, and -3 Missions for Scientific Observations of Ocean, Cryosphere, and Land. Remote Sens. Environ. 2012, 120, 91–101. [Google Scholar] [CrossRef]
- Pierdicca, R.; Malinverni, E.S.; Piccinini, F.; Paolanti, M.; Felicetti, A.; Zingaretti, P. Deep convolutional neural network for automatic detection of damaged photovoltaic cells. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII–2, 893–900. [Google Scholar] [CrossRef]
- Boateng, E.Y.; Otoo, J.; Abaye, D.A. Basic Tenets of Classification Algorithms K-Nearest-Neighbor, Support Vector Machine, Random Forest and Neural Network: A Review. J. Data Anal. Inf. Process. 2020, 8, 341–357. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; Association for Computing Machinery: New York, NY, USA, 1992; pp. 144–152. [Google Scholar]
- Coimbra, R.; Rodriguez-Galiano, V.; Olóriz, F.; Chica-Olmo, M. Regression Trees for Modeling Geochemical Data—An Application to Late Jurassic Carbonates (Ammonitico Rosso). Comput. Geosci. 2014, 73, 198–207. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An Assessment of the Effectiveness of a Random Forest Classifier for Land-Cover Classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach Learn 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Vincenzi, S.; Zucchetta, M.; Franzoi, P.; Pellizzato, M.; Pranovi, F.; De Leo, G.A.; Torricelli, P. Application of a Random Forest Algorithm to Predict Spatial Distribution of the Potential Yield of Ruditapes Philippinarum in the Venice Lagoon, Italy. Ecol. Model. 2011, 222, 1471–1478. [Google Scholar] [CrossRef]
- Crist, E.P.; WA, M. A Temporal-Spectral Analysis Technique for Vegetation Applications of Landsat. Int. Symp. Remote Sens. Environ. 1980, 2, 1031–1040. [Google Scholar]
- Schneider, S.R.; McGinnis, D.F.; Gatlin, J.A. Use of NOAA/AVHRR Visible and near-Infrared Data for Land Remote Sensing; US Department of Commerce, National Oceanic and Atmospheric Administration: Washington, DC, USA, 1981; Volume 84. [Google Scholar]
- Tappan, G.G.; Moore, D.G.; Knausenberger, W.I. Monitoring Grasshopper and Locust Habitats in Sahelian Africa Using GIS and Remote Sensing Technology†. Int. J. Geogr. Inf. Syst. 1991, 5, 123–135. [Google Scholar] [CrossRef]
- Dalezios, N.R.; Domenikiotis, C.; Loukas, A.; Tzortzios, S.T.; Kalaitzidis, C. Cotton Yield Estimation Based on NOAA/AVHRR Produced NDVI. Phys. Chem. Earth Part B: Hydrol. Ocean. Atmos. 2001, 26, 247–251. [Google Scholar] [CrossRef]
- Hill, M.J.; Donald, G.E. Estimating Spatio-Temporal Patterns of Agricultural Productivity in Fragmented Landscapes Using AVHRR NDVI Time Series. Remote Sens. Environ. 2003, 84, 367–384. [Google Scholar] [CrossRef]
- Sakamoto, T.; Gitelson, A.A.; Arkebauer, T.J. MODIS-Based Corn Grain Yield Estimation Model Incorporating Crop Phenology Information. Remote Sens. Environ. 2013, 131, 215–231. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Z.; Kang, X.; Lin, J.; Yin, C.; Ma, L.; Huang, C. Cotton Planting Area Extraction and Yield Prediction Based on Sentinel-2A. Trans. Chin. Soc. Agric. Eng. 2022, 38, 205–214. [Google Scholar]
- Chai, N.; Zhou, W.; Wan, B. Research on Performance Evaluation and Obstacle Diagnosis for Urban Water Ecological Civilization Construction Based on GFAHP-Cloud-FSE Model: The Case of Shizuishan, China. Stoch Env. Res Risk Assess 2022, 36, 3439–3465. [Google Scholar] [CrossRef]
- Drusch, M.; Bello, U.D.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Y.; Yang, Y.; Ma, C. Qualitative Analysis of Molten Steel Based on Support Vector Machine by LIBS. Laser Optoelectron. Prog. 2015, 52, 215–220. [Google Scholar]
- Mao, Z.; Chen, Q. Recognition and Tracking of AGV Multi-Branch Path Based on PCA-LDA and SVM. Laser Optoelectron. Prog. 2018, 55, 148–155. [Google Scholar]
- Francisco, J.; Marcos, O.; Carlos, M.; Christian, A.; Doris, S.; Pablo, E. On-Line Estimation of the Aerobic Phase Length for Partial Nitrification Processes in SBR Based on Features Extraction and SVM Classification. Chem. Eng. J. 2018, 331, 114–123. [Google Scholar]
- Zhang, S.; Xie, F.; Wei, D. Multi-Temporal Remote Sensing Lmages Based on Support Vector Machines for Winter Wheat Planting Area Extraction. Territ. Nat. Resour. Study 2018, 2, 76–77. [Google Scholar] [CrossRef]
- Geng, R.; Fu, B.; Cai, J.; Chen, X.; Lan, F.; Yu, H.; Li, Q. Object-Based Karst Wetland Vegetation Classification Method UsingUnmanned Aerial Vehicle Images and Random Forest Algorithm. J. Geo-Inf. Sci. 2019, 21, 1295–1306. [Google Scholar]
- Zheng, L.; Xu, J.; Wang, X. Application of Random Forests Algorithm in Researches on Wetlands. Wetl. Sci. 2019, 17, 16–24. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, P.; Zhang, Y.; Song, C.; Zhang, D.; Ma, X. Research on Extraction of Winter Wheat Planting Area in Weifang City Based on Sentinel-2A Remote Sensing Image. J. Chin. Agric. Mech. 2022, 43, 98–105. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Trees vs Neurons: Comparison between Random Forest and ANN for High-Resolution Prediction of Building Energy Consumption. Energy Build. 2017, 147, 77–89. [Google Scholar] [CrossRef]
- Charlotte, P.; Silvia, V.; Jordi, I.; Nicolas, C.; Gérard, D. Assessing the Robustness of Random Forests to Map Land Cover with High Resolution Satellite Image Time Series over Large Areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Muhammad, S. Feature Selection of Time Series MODIS Data for Early Crop Classification Using Random Forest: A Case Study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef]
- Hossain, E.; Hossain, M.F.; Rahaman, M.A. A Color and Texture Based Approach for the Detection and Classification of Plant Leaf Disease Using KNN Classifier. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Ok, A.O.; Akar, O.; Gungor, O. Evaluation of Random Forest Method for Agricultural Crop Classification. Eur. J. Remote Sens. 2012, 45, 421–432. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop classification on single date sentinel-2 imagery using random forest and suppor vector Machine. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII–5, 683–688. [Google Scholar] [CrossRef]
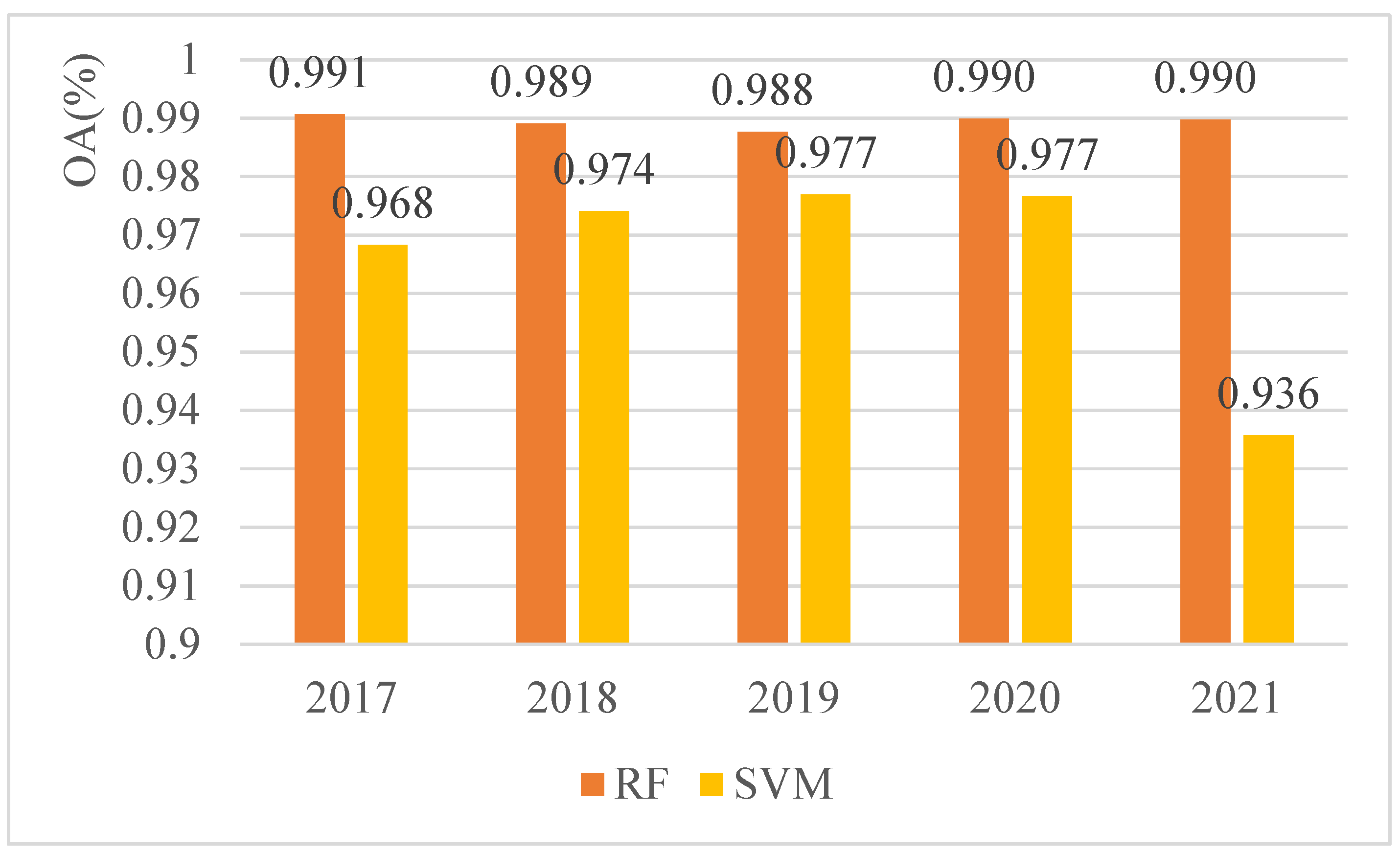

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentinel-2 Bands | Sentinel-2A | Sentinel-2B | Spatial Resolution(m) | ||
|---|---|---|---|---|---|
| Central Wavelength (nm) | Band Width (nm) | Central Wavelength (nm) | Band Width (nm) | ||
| Band 1-Coastal aerosol | 442.7 | 21 | 442.2 | 21 | 60 |
| Band 2-Blue | 492.4 | 66 | 492.1 | 66 | 10 |
| Band 3-Green | 559.8 | 36 | 559 | 36 | 10 |
| Band 4-Red | 664.5 | 31 | 664.9 | 31 | 10 |
| Band 5-Vegetation red edge | 704.1 | 15 | 703.8 | 16 | 20 |
| Band 6-Vegetation red edge | 740.5 | 15 | 739.1 | 15 | 20 |
| Band 7-Vegetation red edge | 782.8 | 20 | 779.7 | 20 | 20 |
| Band 8-NIR | 832.8 | 106 | 832.9 | 106 | 10 |
| Band 8A-Narrow NIR | 864.7 | 21 | 864 | 22 | 20 |
| Band 9-Water Vapor | 945.1 | 20 | 943.2 | 21 | 60 |
| Band 10-SWIR–Cirrus | 1373.5 | 31 | 1376.9 | 30 | 60 |
| Band 11-SWIR | 1613.7 | 91 | 1610.4 | 94 | 20 |
| Band 12-SWIR | 2202.4 | 175 | 2185.7 | 185 | 20 |
| Date | Maize Fertility Cycle |
|---|---|
| Early May to mid-June | Seedling stage |
| Mid-June to mid-July | Early nodulation stage |
| Mid-July to mid-August | Stalking and silking stage |
| Mid-August to late-August | Silking–irrigation stage |
| Late August to late September | Mature stage |
| Sample Point Type | Training Sample | Description |
|---|---|---|
| Urban Area |  | The built-up area of the study area consists mainly of town buildings. |
| Water |  | The water bodies in the study area consist mainly of lakes and rivers (Yellow River) with cyan and dark blue texture and yellow color in the Yellow River. |
| Bare Ground |  | There are no buildings above the bare ground in the study area and the surface is not covered with vegetation, which is highly reflective and homogeneous in texture. |
| Road |  | Roads in the study area include citywide arterial and highway roads, residential roads, excluding all types of plaza and car park sites and internal roads in neighborhoods. The primary textural feature is represented by elongated patches of mixed white and green. |
| Maize Growing Area |  | The maize growing areas in the study area have a structural character bounded by ridges, most of which are regular-rectangular in shape and dark green or black in texture color. |
| Form of a Mountain |  | The mountains in the study area are long, narrow, north–south extending mountains with rugged terrain and vegetation with sunny and shady slopes and east–west slopes. |
| Year | Extraction Area (hm2) | Statistical Area (hm2) | Absolute Error (hm2) | Relative Error (%) |
|---|---|---|---|---|
| 2017 | 8452 | 8426 | 26 | 0.3 |
| 2018 | 8689 | 8989 | 300 | 3.3 |
| 2019 | 9209 | 9331 | 122 | 1.3 |
| 2020 | 9801 | 9573 | 484 | 2.4 |
| 2021 | 11,574 | 11,253 | 321 | 2.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luan, W.; Shen, X.; Fu, Y.; Li, W.; Liu, Q.; Wang, T.; Ma, D. Research on Maize Acreage Extraction and Growth Monitoring Based on a Machine Learning Algorithm and Multi-Source Remote Sensing Data. Sustainability 2023, 15, 16343. https://doi.org/10.3390/su152316343
Luan W, Shen X, Fu Y, Li W, Liu Q, Wang T, Ma D. Research on Maize Acreage Extraction and Growth Monitoring Based on a Machine Learning Algorithm and Multi-Source Remote Sensing Data. Sustainability. 2023; 15(23):16343. https://doi.org/10.3390/su152316343
Chicago/Turabian StyleLuan, Wenjie, Xiaojing Shen, Yinghao Fu, Wangcheng Li, Qiaoling Liu, Tuo Wang, and Dongxiang Ma. 2023. "Research on Maize Acreage Extraction and Growth Monitoring Based on a Machine Learning Algorithm and Multi-Source Remote Sensing Data" Sustainability 15, no. 23: 16343. https://doi.org/10.3390/su152316343
APA StyleLuan, W., Shen, X., Fu, Y., Li, W., Liu, Q., Wang, T., & Ma, D. (2023). Research on Maize Acreage Extraction and Growth Monitoring Based on a Machine Learning Algorithm and Multi-Source Remote Sensing Data. Sustainability, 15(23), 16343. https://doi.org/10.3390/su152316343