
An AI-Based Shortlisting Model for Sustainability of Human Resource Management

Abstract
:1. Introduction
2. Background
2.1. Recruitment Process
2.2. Recruitment Process with AI
2.3. Some AI-Related Research in HRM
2.4. Opportunities in AI Applications for HRM
2.4.1. Chatbots and NLP in Recruitment
2.4.2. Data Mining for AI
3. Methodology
3.1. Minimum Description Length
- The length, in bits, of the description of the theory; and
- The length, in bits, of data when encoded with the help of the theory.
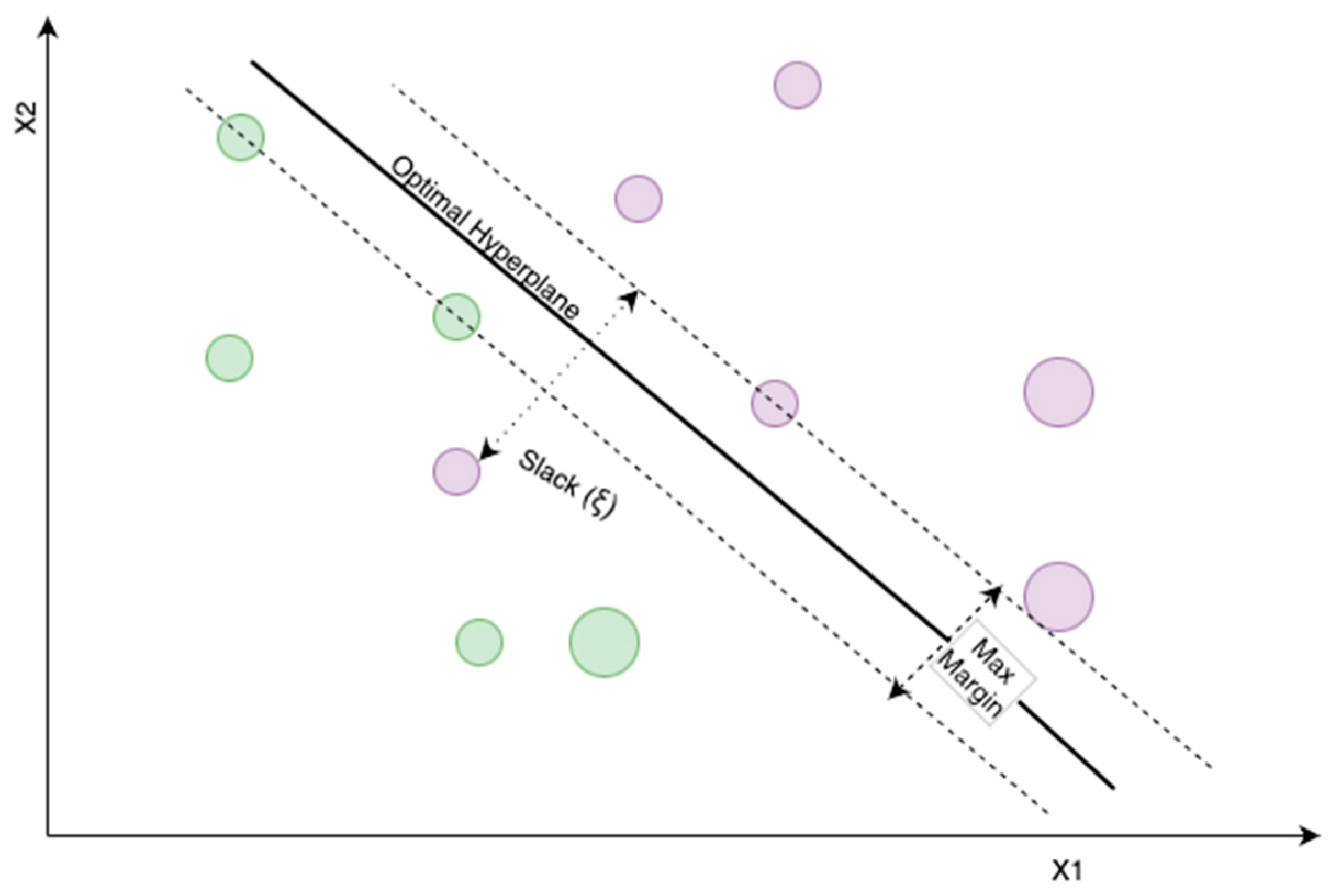
3.2. Support Vector Machine
3.3. Data
3.4. Feature Selection
- BD_10059: Indicates that they have experience with the “Analysis” position.
- BY_1: Language knowledge “English” is important.
- BD_10021: They have past experience as “Software Developer”.
- BSS_26: Has the knowledge for “Analysis”.
- B_CALISMA_DURUMU: If they are working currently or not.
- BD_GECICI_TABLO_EVT__: Indicates that a candidate has an experience in any job.
3.5. Feature Extraction
- Extract the most important information from the original dataset.
- Compress the dataset keeping only this important information.
- Simplify dataset annotation.
3.6. Machine Learning Model and Experiments
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jainh, M. A Comparison of Nationalized and Private Banks’ Strategic Human Resource Management Practices. J. Contemp. Issues Bus. Gov. 2021, 27, 709–713. [Google Scholar]
- Stone, D.L.; Deadrick, D.L.; Lukaszewski, K.M.; Johnson, R. The Influence of Technology on the Future of Human Resource Management. Hum. Resour. Manag. Rev. 2015, 25, 216–231. [Google Scholar] [CrossRef]
- Marler, J.H.; Parry, E. Human resource management, strategic involvement and e-HRM technology. Int. J. Hum. Resour. Manag. 2016, 27, 2233–2253. [Google Scholar] [CrossRef]
- García-Arroyo, J.; Osca Segovia, A. Big data contributions to human resource management: A systematic review. Int. J. Hum. Resour. Manag. 2021, 32, 4337–4362. [Google Scholar] [CrossRef]
- Hong, Z. Research on human resource recommendation algorithm based on machine learning. Sci. Program. 2021, 2021, 8387277. [Google Scholar]
- Michael, H.; Kaplan, A. A Brief History of Artificial Intelligence: On the Past, Present, and Future of Artificial Intelligence. Calif. Manag. Rev. 2019, 61, 5–14. [Google Scholar]
- Tambe, P.; Cappelli, P.; Yakubovich, V. Artificial intelligence in human resources management: Challenges and a path forward. Calif. Manag. Rev. 2019, 61, 15–42. [Google Scholar] [CrossRef]
- Tekkeşin, A.İ. Artificial Intelligence in Healthcare: Past, Present and Future. Anatol. J. Cardiol. 2019, 22, 8–9. [Google Scholar]
- Buiten, M.C. Towards intelligent regulation of artificial intelligence. Eur. J. Risk Regul. 2019, 10, 41–59. [Google Scholar] [CrossRef]
- Kuzior, A. Technological Unemployment in The Perspective of Industry 4.0 Development. Virtual Econ. 2022, 5, 7–23. [Google Scholar] [CrossRef]
- Kuzior, A.; Kwilinski, A. Cognitive Technologies and Artificial Intelligence in Social Perception. Manag. Syst. Prod. Eng. 2022, 30, 109–115. [Google Scholar] [CrossRef]
- Berhil, S.; Benlahmar, H.; Labani, N. A review paper on artificial intelligence at the service of human resources management. Indones. J. Electr. Eng. Comput. Sci. 2020, 18, 32–40. [Google Scholar] [CrossRef]
- Bhardwaj, G.; Singh, S.V.; Kumar, V. An Empirical Study of Artificial Intelligence and its Impact on Human Resource Functions. In Proceedings of the 2020 International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, 9–10 January 2020; pp. 47–51. [Google Scholar]
- Ore, O.; Sposato, M. Opportunities and risks of artificial intelligence in recruitment and selection. Int. J. Organ. Anal. 2021, 30, 1771–1782. [Google Scholar] [CrossRef]
- Li, F.; Ruijs, N.; Lu, Y. Ethics & AI: A Systematic Review on Ethical Concerns and Related Strategies for Designing with AI in Healthcare. AI 2023, 4, 28–53. [Google Scholar]
- Jepsen, D.M.; Grob, S. Sustainability in recruitment and selection: Building a framework of practices. J. Educ. Sustain. Dev. 2015, 9, 160–178. [Google Scholar] [CrossRef]
- Bauer, T.N.; Erdogan, B.; Taylor, S. Creating and Maintaining Environmentally Sustainable Organizations: Recruitment and Onboarding; Jossey-Bass/Wiley: New York, NY, USA, 2012. [Google Scholar]
- Saad, M.F.M.; Nugro, A.W.L.; Thinakaran, R.; Baijed, M. A Review of Artificial Intelligence Based Platformin Human Resource Recruitment Process. In Proceedings of the 6th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Kedah, Malaysia, 1–3 December 2021. [Google Scholar]
- Furtmuellera, E.; Wilderom, C.; Tate, M. Managing recruitment and selection in the digital age: E-HRM and resumes. Hum. Syst. Manag. 2021, 30, 243–259. [Google Scholar] [CrossRef]
- Wilfred, D. AI in recruitment. NHRD Netw. J. 2018, 11, 15–18. [Google Scholar] [CrossRef]
- Arbab, A.M.; Mahdi, M.O.S. Human resources management practices and organizational excellence in public orgnizations. Pol. J. Manag. Stud. 2018, 18, 9–21. [Google Scholar] [CrossRef]
- Strohmeier, S.; Piazza, F. Artificial intelligence techniques in human resource management—A conceptual exploration. In Intelligent Techniques in Engineering Management; Springer: Cham, Switzerland, 2015; pp. 149–172. [Google Scholar]
- Da Silva, L.B.P.; Soltovski, R.; Pontes, J.; Treinta, F.T.; Leitão, P.; Mosconi, E.; Yoshino, R.T. Human resources management 4.0: Literature review and trends. Comput. Ind. Eng. 2022, 168, 108111. [Google Scholar] [CrossRef]
- Merlin, R.P.; Jayam, R. Artificial Intelligence in Human Resource Management. Int. J. Pure Appl. Math. 2018, 119, 1891–1896. [Google Scholar]
- Alavuo, N.H. Modern Recruitment Process as a Competitive Advantage in Talent Acquisition: A Recruiter’s Playbook. Master’s Thesis, Haaga-Helia University of Applied Sciences, Helsinki, Finland, 2020. [Google Scholar]
- Hoang, L. From Customer Journey to Candidate Journey: Applying Marketing Principles to Build a Winning Hiring Culture. Master’s Thesis, Metropolia University of Applied Sciences, Helsinki, Finland, 2018. [Google Scholar]
- Al-Alawi, A.I.; Naureen, M.; AlAlawi, E.I.; Al-Hadad, A.A.N. The Role of Artificial Intelligence in Recruitment Process Decision-Making. In Proceedings of the 2021 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 7–8 December 2021; pp. 197–203. [Google Scholar]
- Utami, E.; Luthfi, E.T. Profiling Analysis Based on Social Media for Prospective Employees Recruitment Using SVM and Chi-Square. J. Phys. Conf. Ser. 2018, 1140, 012043. [Google Scholar]
- Wang, Q.L.; Li, B.; Hu, J. Feature selection for human resource selection based on affinity propagation and SVM sensitivity analysis. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009. [Google Scholar]
- Li, Y.-M.; Lai, C.-Y.; Kao, C.-P. Building a qualitative recruitment system via SVM with MCDM approach. Appl. Intell. 2011, 35, 75–88. [Google Scholar] [CrossRef]
- Mnasri, M. Recent advances in conversational NLP: Towards the standardization of Chatbot building. arXiv 2019, arXiv:1903.09025. [Google Scholar]
- Chowdhury, G.G. Natural language processing. In Fundamentals of Artificial Intelligence; Springer: New Delhi, India, 2020; pp. 603–649. [Google Scholar]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]
- Soutar, K. How Chatbots Can Be Used to Re-Engage with Applicants during Recruitment. Master’s Thesis, Aalto University, Espoo, Finland, 2019. [Google Scholar]
- Majumder, S.; Mondal, A. Are chatbots really useful for human resource management? Int. J. Speech Technol. 2021, 24, 969–977. [Google Scholar] [CrossRef]
- Nawaz, N.; Gomes, A.M. Artificial intelligence chatbots are new recruiters. (IJACSA) Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef]
- Anitha, K.; Shanthi, V. A Study on Intervention of Chatbots in Recruitment. In Innovations in Information and Communication Technologies (IICT-2020); Springer: Cham, Switzerland, 2021; pp. 67–74. [Google Scholar]
- Koivunen, S.; Ala-Luopa, S.; Olsson, T.; Haapakorpi, A. The March of Chatbots into Recruitment: Recruiters’ Experiences, Expectations, and Design Opportunities. Comput. Support. Coop. Work. (CSCW) 2022, 31, 1–30. [Google Scholar] [CrossRef]
- Shehu, M.A.; Saeed, F. An adaptive personnel selection model for recruitment using domain-driven data mining. J. Theor. Appl. Inf. Technol. 2016, 91, 117–130. [Google Scholar]
- Singh, S.; Kumar, V. Performance Analysis of Engineering Students for Recruitment Using Classification Data Mining Techniques. Int. J. Sci. Eng. Comput. Technol. 2013, 3, 31–37. [Google Scholar]
- Hmoud, B.; Laszlo, V. Will artificial intelligence take over human resources recruitment and selection. Netw. Intell. Stud. 2019, 7, 21–30. [Google Scholar]
- Pah, C.E.A.; Utama, D.N. Decision Support Model for Employee Recruitment Using Data Mining Classification. Int. J. Emerg. Trends Eng. Res. 2020, 8, 1511–1516. [Google Scholar]
- Joshi, A.P.; Panchal, R.K. Data mining for staff recruitment in education system using WEKA. Int. J. Res. Comput. Sci. Manag. 2014, 2, 1–4. [Google Scholar]
- Willemink, M.J.; Koszek, W.A.; Hardell, C.; Wu, J.; Fleischmann, D.; Harvey, H.; Folio, L.R.; Summers, R.M.; Rubin, D.L.; Lungren, M.P. Preparing medical imaging data for machine learning. Radiology 2020, 295, 4–15. [Google Scholar] [CrossRef] [PubMed]
- Soibelman, L.; Kim, H. Generating construction knowledge with knowledge discovery in databases. In Proceedings of the Eighth International Conference on Computing in Civil and Building Engineering (ICCCBE-VIII), Stanford, CA, USA, 14–16 August 2000; pp. 906–913. [Google Scholar]
- Kumar, V.; Minz, S. Feature Selection: A literature Review. SmartCR 2014, 4, 211–229. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Grünwald, P.D. The Minimum Description Length Principle; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Grünwald, P. A Tutorial Introduction to the Minimum Description Length Principle. In Advances in Minimum Description Length: Theory and Applications; MIT Press: Cambridge, MA, USA; London, UK, 2005; Volume 5, pp. 1–80. [Google Scholar]
- Grünwald, P.; Roos, T. Minimum description length revisited. Int. J. Math. Ind. 2019, 11, 1930001. [Google Scholar] [CrossRef]
- Li, M.; Vitányi, P.M. Computational machine learning in theory and praxis. In Computer Science Today; Springer: Berlin/Heidelberg, Germany, 1995; pp. 518–535. [Google Scholar]
- Quinlan, J.R. MDL and categorical theories (continued). In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 464–470. [Google Scholar]
- Vishwanathan, S.V.M.; Murty, M.N. SSVM: A Simple SVM Algorithm. In Proceedings of the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, 12–17 May 2002; Volume 3, pp. 2393–2398. [Google Scholar]
- Mahesh, B. Machine learning algorithms—A review. Int. J. Sci. Res. (IJSR) 2020, 9, 381–386. [Google Scholar]
- Orrù, P.F.; Zoccheddu, A.; Sassu, L.; Mattia, C.; Cozza, R.; Arena, S. Machine Learning Approach Using MLP and SVM Algorithms for the Fault Prediction of a Centrifugal Pump in the Oil and Gas Industry. Sustainability 2020, 12, 4776. [Google Scholar] [CrossRef]
- Byvatov, E.; Fechner, U.; Sadowski, J.; Schneider, G. Comparison of support vector machine and artificial neural network systems for drug/nondrug classification. J. Chem. Inf. Comput. Sci. 2003, 43, 1882–1889. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Support vector machines: Theory and applications. In Advanced Course on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 1999; pp. 249–257. [Google Scholar]
- Zebari, R.Z.; Abdulazeez, A.M.; Zeebaree, D.Q.; Saeed, J.N.; Zebari, D.A. A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J. Appl. Sci. Technol. Trends 2020, 1, 56–70. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Hira, Z.M.; Gillies, D.F. A review of feature selection and feature extraction methods applied on microarray data. Adv. Bioinform. 2015, 2015, 198363. [Google Scholar] [CrossRef] [PubMed]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Park, S.H.; Goo, J.M.; Jo, C.-H. Receiver operating characteristic (ROC) curve: Practical review for radiologists. Korean J. Radiol. 2004, 5, 11–18. [Google Scholar] [CrossRef] [PubMed]
- Hoo, Z.H.; Candlish, J.; Teare, D. What is an ROC curve? Emerg. Med. J. 2017, 34, 357–359. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Setting | Value |
|---|---|---|
| No Feature Selection | Value of complexity factor | 10 |
| No Feature Selection | Number of Iteration | 30 |
| No Feature Selection | SVM Solver | SVMS_SOLVER_IPM |
| No Feature Selection | Convergence Tolerance | 0.0001 |
| No Feature Selection | Kernel | SVMS_LINEAR |
| No Feature Selection | Number of Features | 82 |
| Model | Setting | Value |
|---|---|---|
| No Feature Selection | Value of complexity factor | 10 |
| No Feature Selection | Number of Iteration | 30 |
| No Feature Selection | SVM Solver | SVMS_SOLVER_IPM |
| No Feature Selection | Convergence Tolerance | 0.0001 |
| No Feature Selection | Kernel | SVMS_LINEAR |
| No Feature Selection | Number of Features | 6 |
| Model | Setting | Value |
|---|---|---|
| No Feature Selection | SVM Solver | SVMS_SOLVER_IPM |
| No Feature Selection | Number of Iteration | 11 |
| No Feature Selection | Value of Standard Deviation | 1.7320 |
| No Feature Selection | Convergence Tolerance | 0.001 |
| No Feature Selection | Kernel | Gaussian |
| No Feature Selection | Number of Features | 6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aydın, E.; Turan, M. An AI-Based Shortlisting Model for Sustainability of Human Resource Management. Sustainability 2023, 15, 2737. https://doi.org/10.3390/su15032737
Aydın E, Turan M. An AI-Based Shortlisting Model for Sustainability of Human Resource Management. Sustainability. 2023; 15(3):2737. https://doi.org/10.3390/su15032737
Chicago/Turabian StyleAydın, Erdinç, and Metin Turan. 2023. "An AI-Based Shortlisting Model for Sustainability of Human Resource Management" Sustainability 15, no. 3: 2737. https://doi.org/10.3390/su15032737