Cascade Failure-Based Identification and Resilience of Critical Nodes in Automotive Supply Chain Networks


Abstract
:1. Introduction
2. Materials and Methods
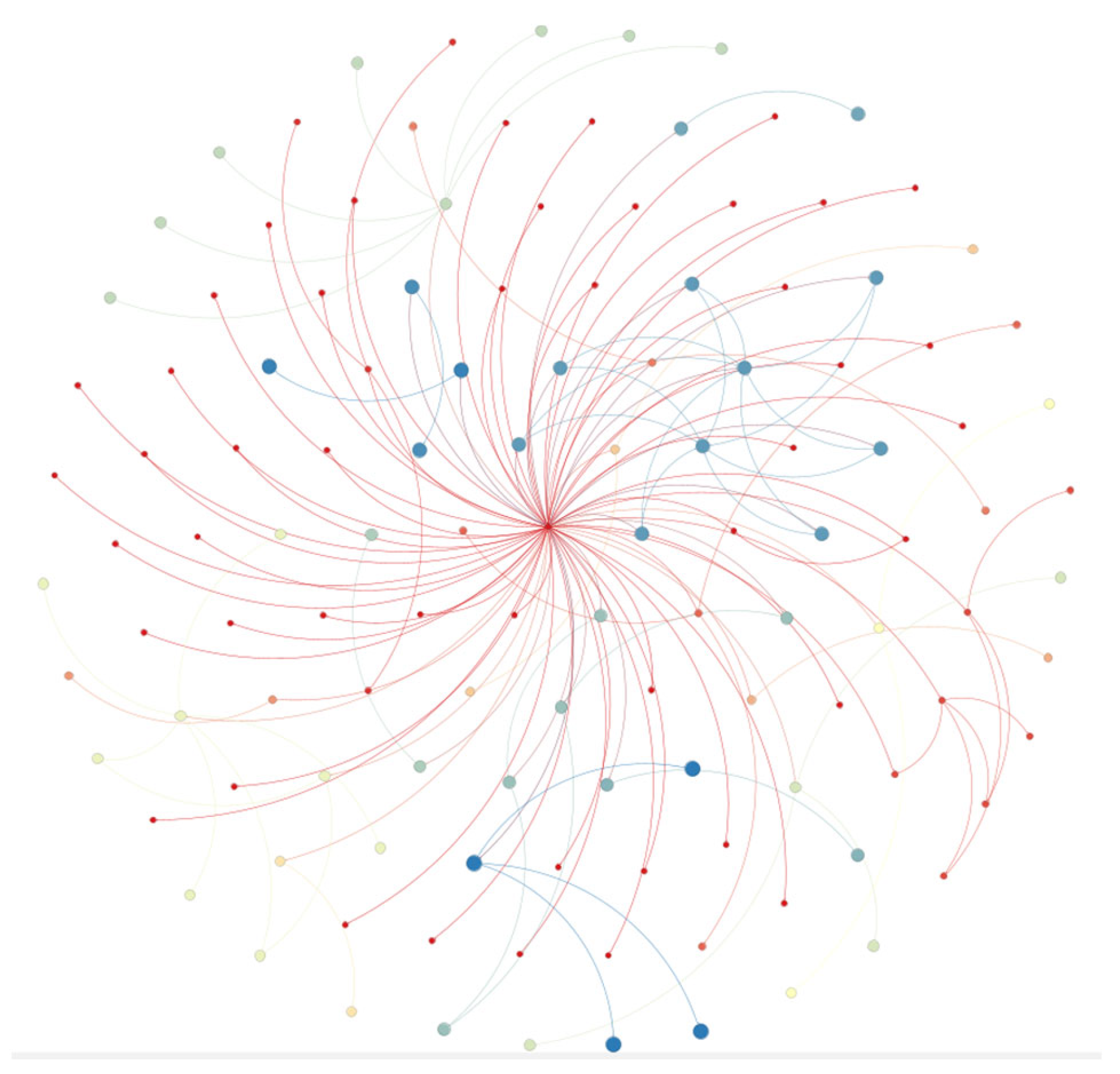
2.1. Automotive Supply Chain Network Modeling
2.2. Identification of Key Nodes in Tesla Motors’ Supply Chain Network Based on an Improved K-Shell Algorithm
- Decompose the Tesla automotive supply chain network using the K-shell method to obtain the Ks values of different categories of nodes.
- Obtain the degree values of all nodes in the Tesla automotive supply chain network, using the number of connected edges of the nodes to measure the degree of centrality.
- Computation of eigenvector centrality for all nodes in the supply chain network of Tesla Motors.is the eigenvalue of the adjacency matrix . if the nodes are connected and if they are not and is normalized by:
- Extract the average eigenvector value of the first reachable point of all nodes .
- The second reachable point of each node is calculated cyclically using the BFS backtracking algorithm to obtain the neighbor matrix L’ of the second reachable node, and the average eigenvector value of the second reachable point is extracted.
- Based on the formula:the weighted importance of each node is calculated.
2.3. Cascade Failure Modeling
3. Disruptive Analysis of Automotive Supply Chain Networks
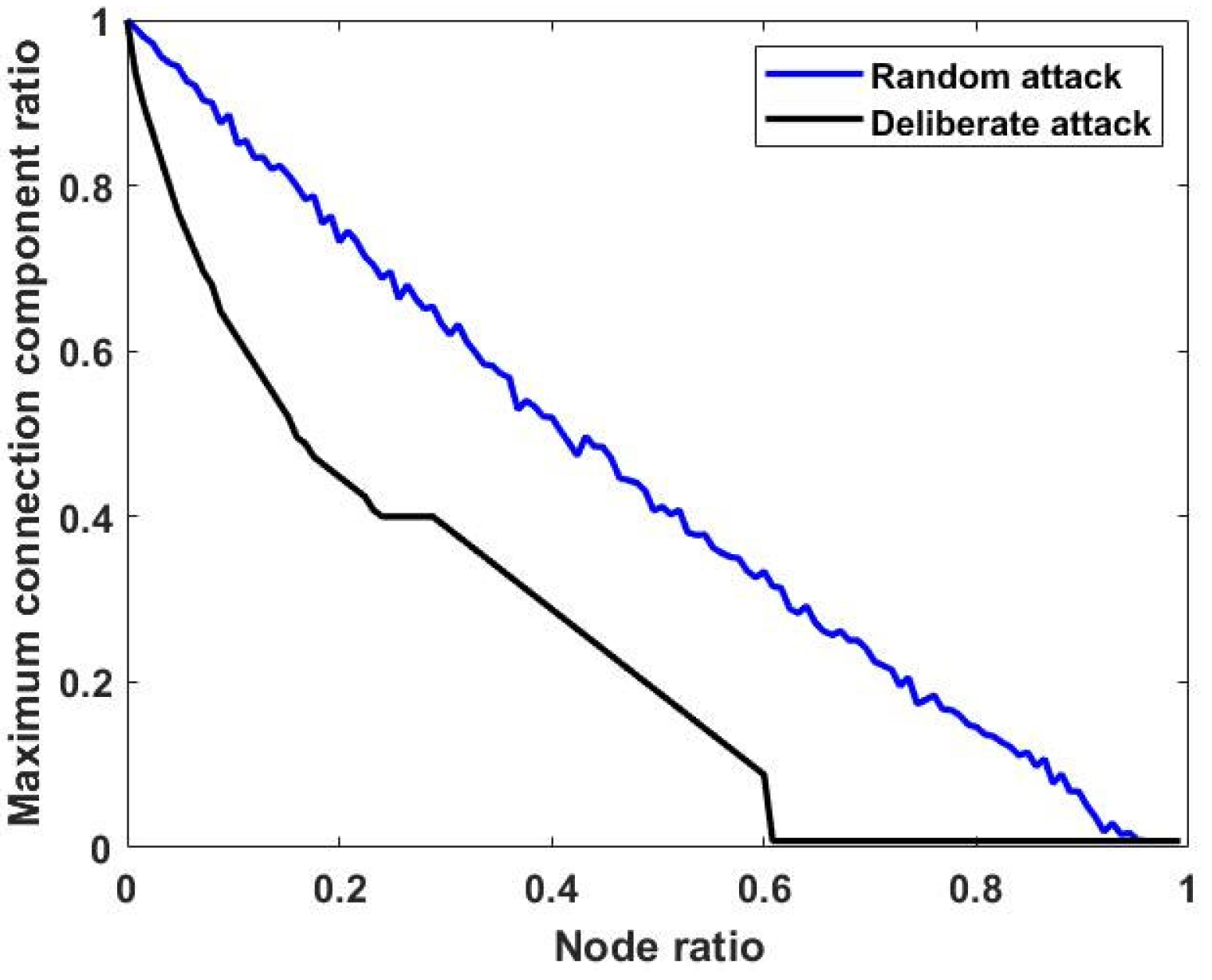
3.1. Comparing Different Attack Strategies
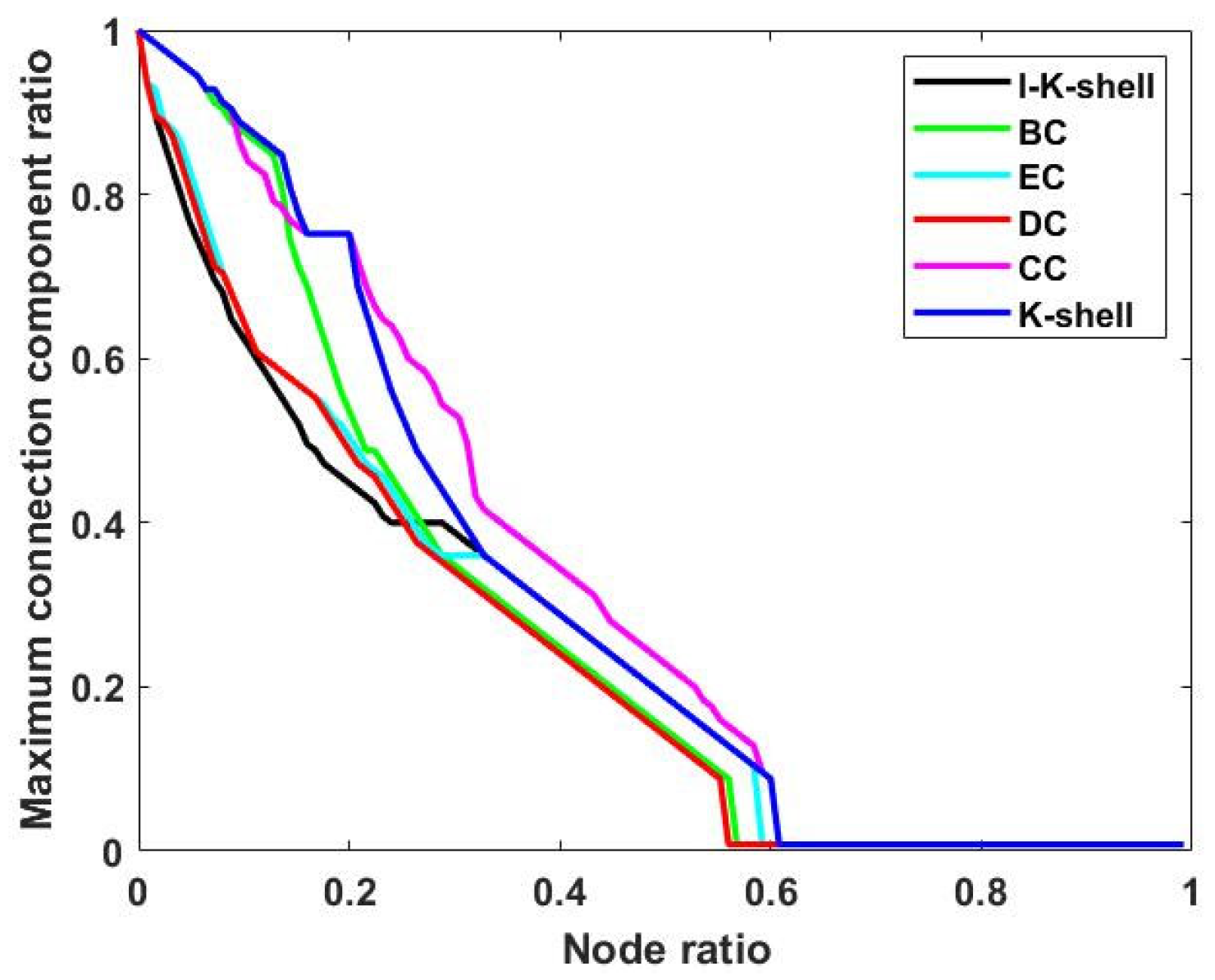
3.2. Performance Comparison of Different Methods for Identifying Nodes in Automotive Supply Chain Networks
3.3. Adjustment of Cascade Failure Model Parameters for Comparison
3.3.1. Observation of Network Effects for Different Values of α and β
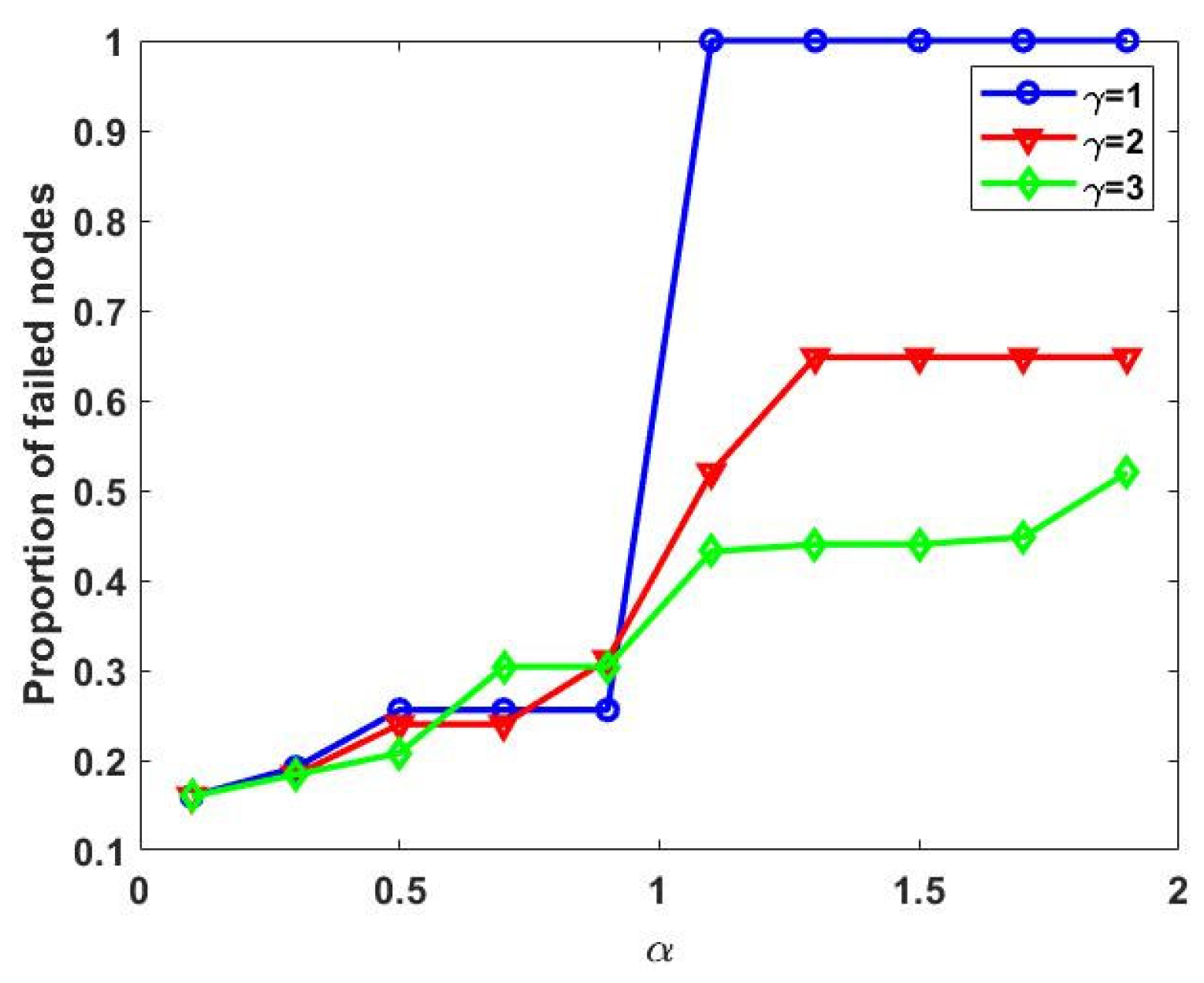
3.3.2. Observation of Network Effects for Different Values of α and γ
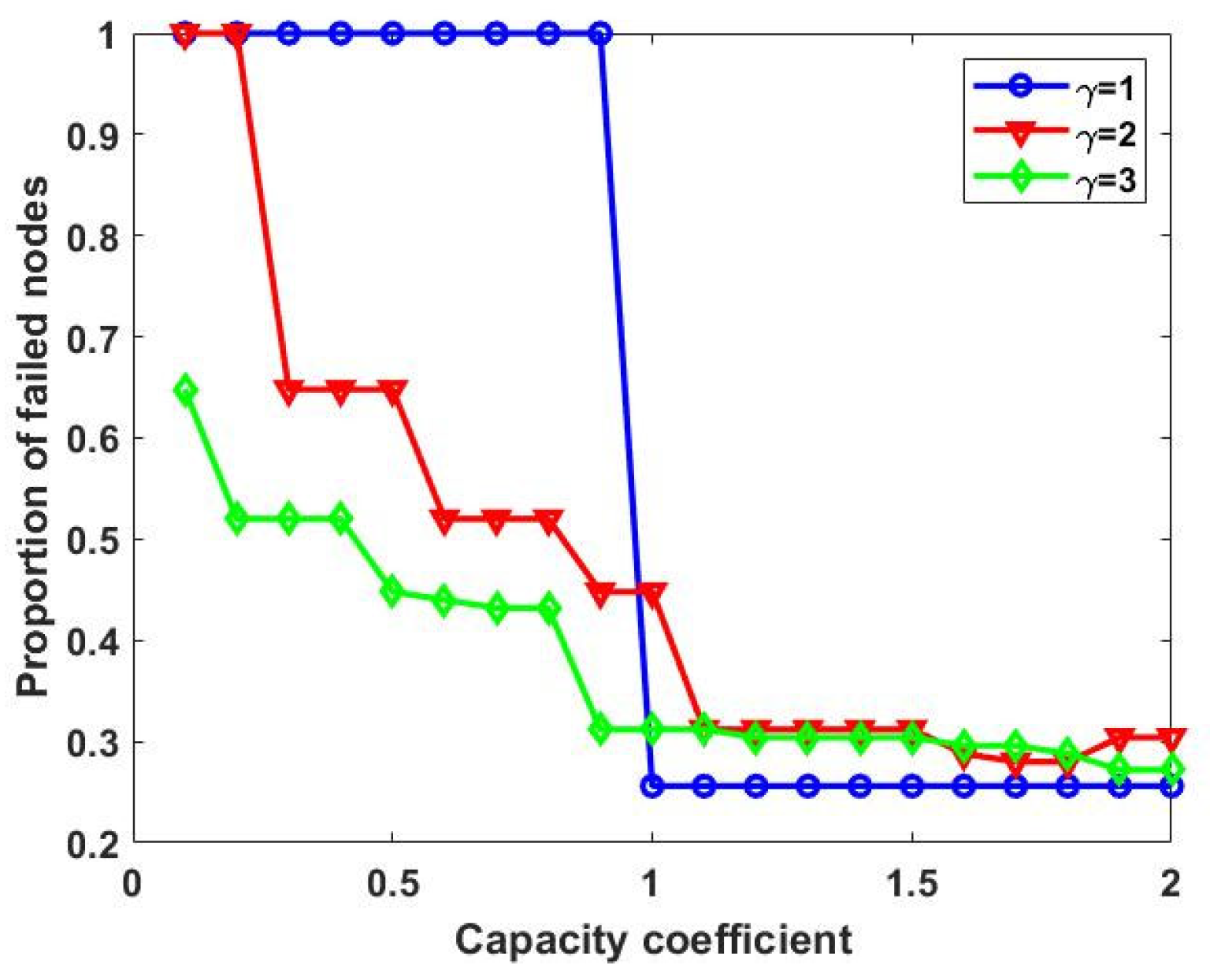
3.3.3. Observation of Network Effects for Different Values of β and γ
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, K.; Wang, J.; Zhang, J. Automotive Supply Chain Disruption Risk Management: A Visualization Analysis Based on Bibliometric. Processes 2023, 11, 710. [Google Scholar] [CrossRef]
- Belhadi, A.; Kamble, S.; Jabbour, C.J.C.; Gunasekaran, A.; Ndubisi, N.O.; Venkatesh, M. Manufacturing and service supply chain resilience to the COVID-19. Technol. Forecast. Soc. Chang. 2020, 163, 120447–120495. [Google Scholar] [CrossRef] [PubMed]
- Santos, L.P.; Proença, J.F. Developing Return Supply Chain: A Research on the Automotive Supply Chain. Sustainability 2022, 14, 6587. [Google Scholar] [CrossRef]
- Tang, L.; Jing, K.; He, J.; Stanley, H.E. Robustness of assembly supply chain networks by considering risk propagation and cascading failure. Phys. A Stat. Mech. Appl. 2016, 4520169, 129–139. [Google Scholar] [CrossRef]
- Colon, C.; Hochrainer-Stigler, S. Systemic risks in supply chains: A need for system-level governance. Supply Chain Manag. Int. J. 2023, 28, 682–694. [Google Scholar] [CrossRef]
- Zafar, S.; Hassan, S.F.U.; Mohammad, A.; Al-Ahmadi, A.A.; Ullah, N. Implementation of a Distributed Framework for Permissioned Blockchain-Based Secure Automotive Supply Chain Management. Sensors 2022, 22, 7367. [Google Scholar] [CrossRef] [PubMed]
- Sathyan, R.; Parthiban, P.; Dhanalakshmi, R.; Sachin, M.S. An integrated Fuzzy MCDM approach for modelling and prioritising the enablers of responsiveness in automotive supply chain using Fuzzy DEMATEL, Fuzzy AHP and Fuzzy TOPSIS. Soft Comput. 2023, 27, 257–277. [Google Scholar] [CrossRef]
- Li, Y.; Zobel, C.W. Network Characteristics and Supply Chain Resilience under Conditions of Risk. Int. J. Prod. Econ. 2020, 223, 107529–107577. [Google Scholar] [CrossRef]
- Li, Y.; Zobel, C.W. Exploring supply chain network resilience in the presence of the ripple effect. Int. J. Prod. Econ. 2020, 228, 107693–107706. [Google Scholar] [CrossRef]
- Li, F.; Wu, C.-H.; Zhou, L.; Xu, G.; Liu, Y.; Tsai, S.-B. A model integrating environmental concerns and supply risks for dynamic sustainable supplier selection and order allocation. Soft Comput. 2021, 25, 535–549. [Google Scholar] [CrossRef]
- Sheng, J.; Dai, J.; Wang, B.; Duan, G.; Long, J.; Zhang, J.; Guan, K.; Hu, S.; Chen, L.; Guan, W. Identifying influential nodes in complex networks based on global and local structure. Phys. A Stat. Mech. Appl. 2020, 541, 123262–123275. [Google Scholar] [CrossRef]
- Berberler, M.E. Global and local structure-based influential nodes identification in wheel-type networks. Numer. Methods Partial. Differ. Equ. 2020, 40, e22709. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, J.; Dai, J.; Sheng, J. Influential nodes identification using network local structural properties. Sci. Rep. 2022, 12, 1833–1846. [Google Scholar] [CrossRef] [PubMed]
- Maji, G.; Namtirtha, A.; Dutta, A.; Malta, M.C. Influential spreaders identification in complex networks with improved k-shell hybrid method. Expert Syst. Appl. 2019, 144, 113092–113105. [Google Scholar] [CrossRef]
- Wang, S.; Du, Y.; Deng, Y. A new measure of identifying influential nodes Efficiency centrality. Commun. Nonlinear Sci. Numer. Simul. 2017, 47, 151–163. [Google Scholar] [CrossRef]
- Ahajjam, S.; Badir, H. Identification of influential spreaders in complex networks using HybridRank algorithm. Sci. Rep. 2018, 8, 11932–11942. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.; Wang, S.; Mei, G. Efficient parallel algorithm for detecting influential nodes in large biological networks on the Graphics Processing Unit. Future Gener. Comput. Syst. 2020, 106, 1–13. [Google Scholar] [CrossRef]
- Nabaei, A.; Hamian, M.; Parsaei, M.R.; Safdari, R.; Samad-Soltani, T.; Zarrabi, H.; Ghassemi, A. Topologies and performance of intelligent algorithms: A comprehensive review. Artif. Intell. Rev. 2018, 49, 79–103. [Google Scholar] [CrossRef]
- Fu, X.; Yang, Y.; Postolache, O. Invulnerability of Clustering Wireless Sensor Networks Against Cascading Failures. IEEE Syst. J. 2019, 13, 1431–1442. [Google Scholar] [CrossRef]
- Sun, J.Y.; Tang, J.M.; Fu, W.P.; Wu, B.Y. Hybrid modeling and empirical analysis of automobile supply chain network. Phys. A Stat. Mech. Appl. 2017, 473, 377–389. [Google Scholar] [CrossRef]
- Yang, G.; Qi, X.; Liu, L. Research on network robustness based on different deliberate attack methods. Phys. A Stat. Mech. Appl. 2020, 545, 123588–123598. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Nodes | Edge | Average Degree | Average Shortest Path | Clustering | Coefficient Graph Density |
|---|---|---|---|---|---|---|
| Numeric | 125 | 146 | 2.336 | 2.673 | 0.199 | 0.019 |
| Nodal Enterprise | BC | EC | DC | CC | K-Shell | I-K-Shell |
|---|---|---|---|---|---|---|
| Tesla (unit) | 7476.5 | 0.091743 | 79 | 0.005917 | 3 | 8.13 |
| Panasonic | 366 | 0.010376 | 4 | 0.003497 | 1 | 1.524741 |
| Sumitomo Chemical | 243.5 | 0.011917 | 5 | 0.003509 | 2 | 2.612001 |
| Sugo Corporation | 0 | 0.011305 | 2 | 0.003472 | 2 | 2.577348 |
| Nissin Chemical | 366 | 0.010376 | 4 | 0.003497 | 1 | 1.524741 |
| Mitsubishi Chemical | 245 | 0.010249 | 3 | 0.003472 | 1 | 1.517586 |
| Changying Precision | 123 | 0.010126 | 2 | 0.003448 | 1 | 1.510604 |
| Kodaly | 0 | 0.010005 | 1 | 0.003425 | 1 | 1.503787 |
| Sunrise | 123 | 0.010126 | 2 | 0.003448 | 1 | 1.510604 |
| STMicroelectronics | 245 | 0.010249 | 3 | 0.003472 | 1 | 1.517586 |
| Yazaki | 0 | 0.010005 | 1 | 0.003425 | 1 | 1.503787 |
| Tradelink | 0 | 0.010005 | 1 | 0.003425 | 1 | 1.503787 |
| Tyco Electronics | 123 | 0.010126 | 2 | 0.003448 | 1 | 1.510604 |
| Gao Hua | 245 | 0.010249 | 3 | 0.003472 | 1 | 1.517586 |
| Huden | 603.5 | 0.011044 | 7 | 0.003571 | 2 | 2.562555 |
| Dongshan Precision | 117.5 | 0.010518 | 3 | 0.003472 | 2 | 2.532817 |
| Junsheng Electronics | 0 | 0.010005 | 1 | 0.003425 | 1 | 1.503787 |
| Anjie Technology | 0 | 0.01126 | 2 | 0.003448 | 2 | 2.574816 |
| Dana | 0 | 0.010005 | 1 | 0.003425 | 1 | 1.503787 |
| SANHUA Intelligent Control | 0 | 0.01126 | 2 | 0.003448 | 2 | 2.574816 |
| Rank | BC | EC | DC | CC | K-Shell | I-K-Shell |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1, 42, 49, 53, 54, 55, 56, 57, 58, 120 | 1 |
| 2 | 23 | 42 | 23, 42 | 23 | 3, 4, 15, 16, 18, 20, 21, 36, 59, 64, 70, 85, 86, 103, 104, 117 | 42 |
| 3 | 15 | 49, 53, 54, 55, 56, 57, 58 | 15120 | 15 | 2, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 17, 19, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 37, 38, 39, 40, 41, 43, 44, 45, 46, 47, 48, 50, 51, 52, 60, 61, 62, 63, 65, 66, 67, 68, 69, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 118, 119, 121, 122, 123, 124, 125 | 49, 53, 54, 55, 56, 57, 58 |
| 4 | 2, 5, 22, 68 | 3 | 3 | 42 | 120 | |
| 5 | 6, 10, 14 | 36, 59 | 2, 5, 21, 22, 68 | 3 | 3 | |
| 6 | 3 | 4 | 6, 10, 14, 16, 36, 49, 53, 54, 55, 56, 57, 58, 59 | 2, 5, 21, 22, 68 | 36, 59 | |
| 7 | 21 | 18, 20 | 4, 7, 9, 13, 18, 20, 24, 39, 40, 60, 62, 64, 70, 85, 86, 103, 104, 117 | 4, 6, 10, 14, 16 | 4 | |
| 8 | 7, 9, 13, 24, 39, 40, 60, 62 | 64, 70 | 8, 11, 12, 17, 19, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 37, 38, 41, 43, 44, 45, 46, 47, 48, 50, 51, 52, 61, 63, 65, 66, 67, 69, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 118, 119, 121, 122, 123, 124, 125 | 36, 49, 53, 54, 55, 56, 57, 58, 59 | 18, 20 | |
| 9 | 16 | 15 | 7, 9, 13, 18, 20, 24, 39, 40, 60, 62 | 64, 70 | ||
| 10 | 36, 59 | 23 | 64, 70 | 15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ou, C.; Pan, F.; Lin, S. Cascade Failure-Based Identification and Resilience of Critical Nodes in Automotive Supply Chain Networks. Sustainability 2024, 16, 5514. https://doi.org/10.3390/su16135514
Ou C, Pan F, Lin S. Cascade Failure-Based Identification and Resilience of Critical Nodes in Automotive Supply Chain Networks. Sustainability. 2024; 16(13):5514. https://doi.org/10.3390/su16135514
Chicago/Turabian StyleOu, Chengyang, Fubin Pan, and Shuangjiao Lin. 2024. "Cascade Failure-Based Identification and Resilience of Critical Nodes in Automotive Supply Chain Networks" Sustainability 16, no. 13: 5514. https://doi.org/10.3390/su16135514