


Analysis of Circular Price Prediction Strategy for Used Electric Vehicles
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
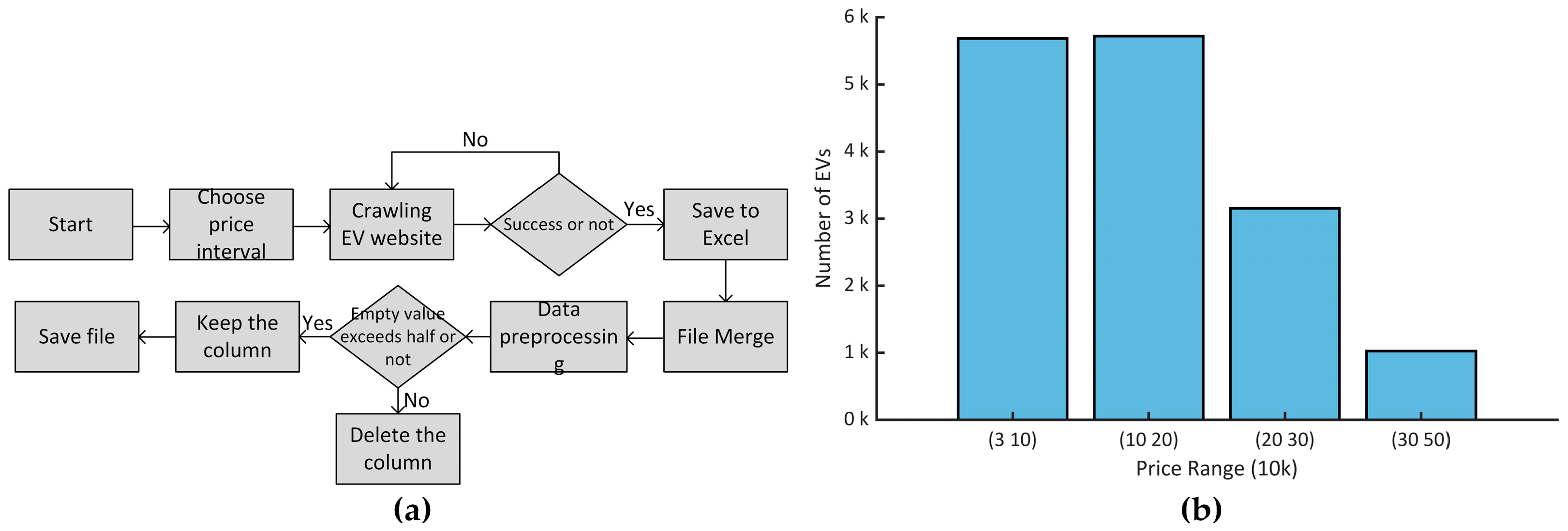
3.1. Data Collection
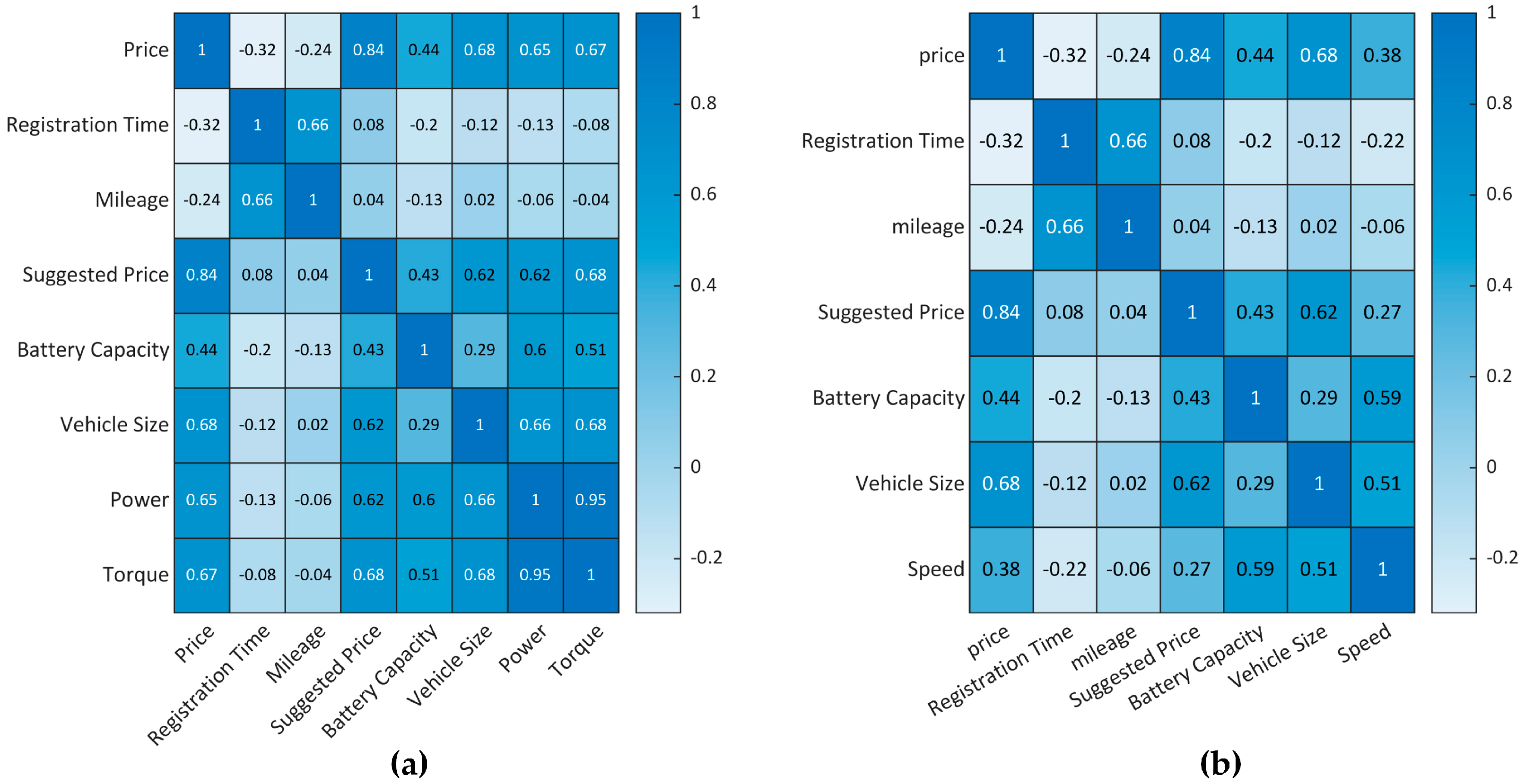
3.2. Data Processing
3.3. Regression Methods
3.3.1. Lasso Regression
3.3.2. Regression Tree
3.3.3. Support Vector Regression
3.3.4. Random Forest
3.3.5. GBRT
3.4. The Evaluation Methods
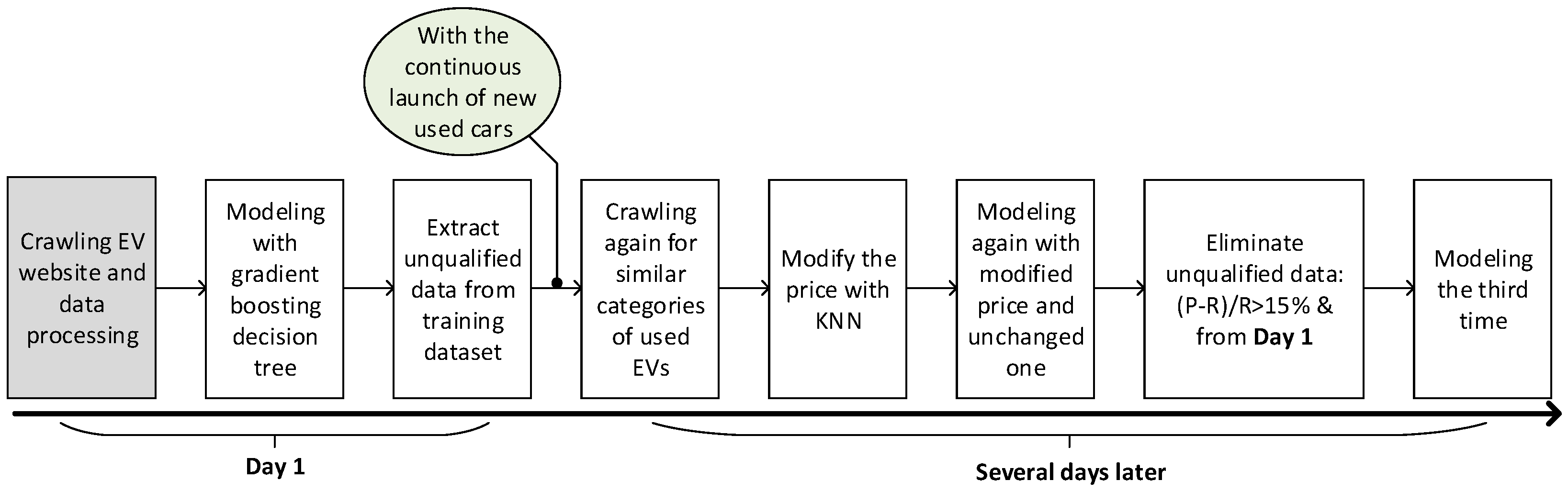
3.5. Price Updating Strategy
3.5.1. Three Round Training
3.5.2. K-Nearest Neighbor (KNN)
3.5.3. Training and Testing Set
4. Results
4.1. Comparison of Model Evaluation with Different Methods
4.2. Evaluation of Numerical Features and Texture Features
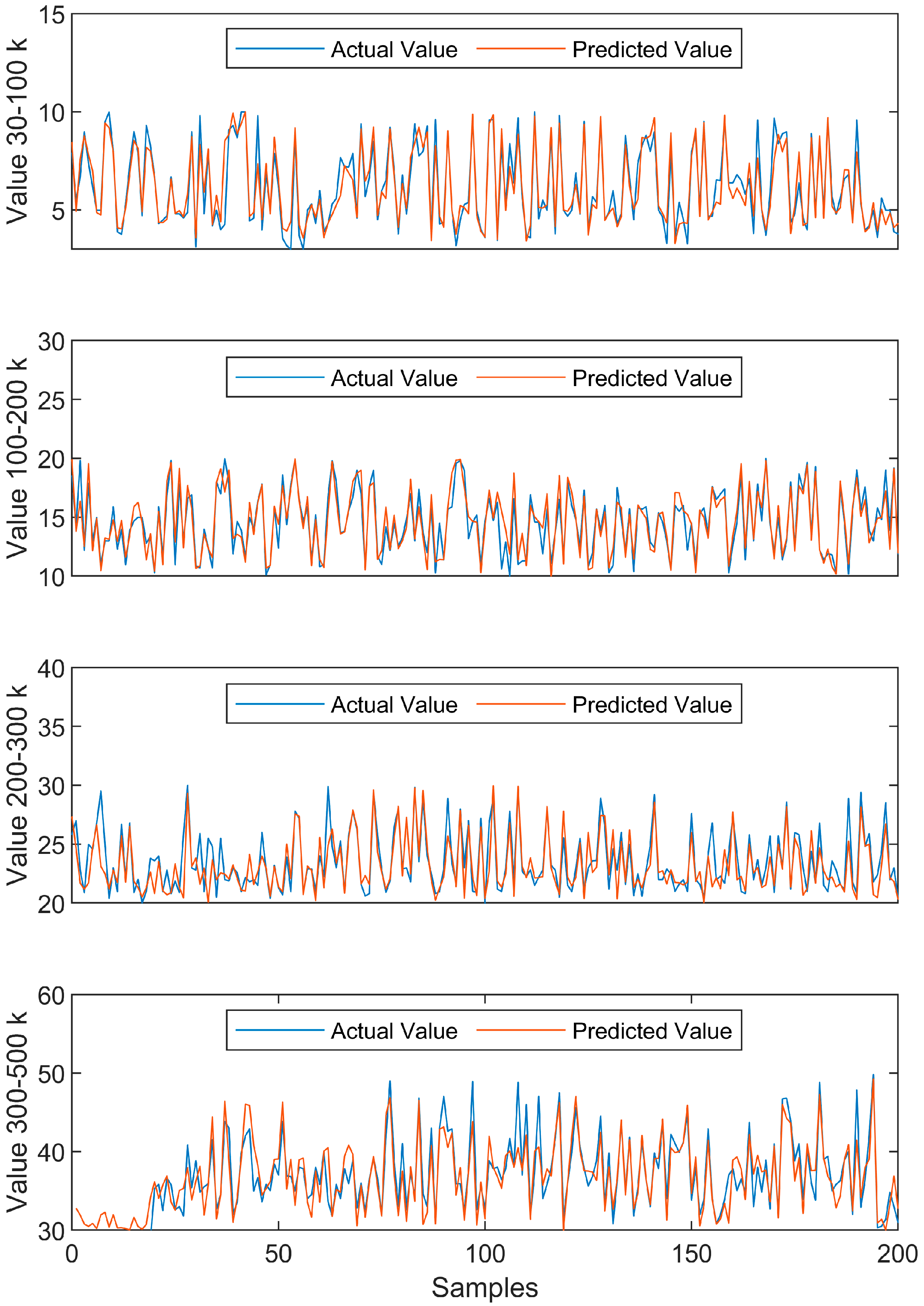
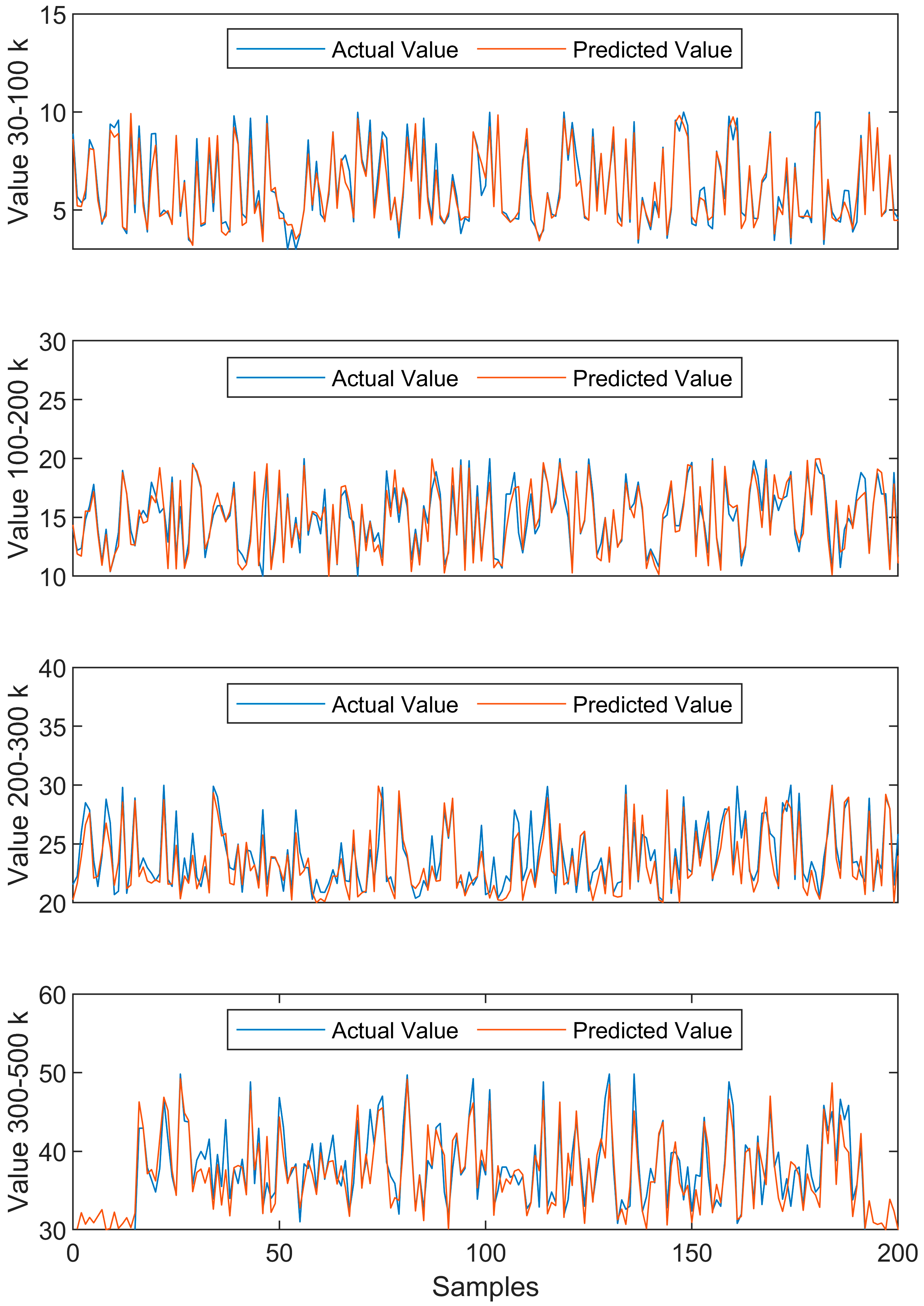
4.3. Price Updating with Extra Training
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Fang, X.; Sun, C. The alternative path for fossil oil: Electric vehicles or hydrogen fuel cell vehicles? J. Environ. Manag. 2023, 341, 118019. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Burke, P.J.; Wang, Q. Effectiveness of electric vehicle subsidies in China: A three-dimensional panel study. Resour. Energy Econ. 2024, 76, 101424. [Google Scholar] [CrossRef]
- Wang, N.; Tang, L.; Zhang, W.; Guo, J. How to face the challenges caused by the abolishment of subsidies for electric vehicles in China? Energy 2019, 166, 359–372. [Google Scholar] [CrossRef]
- Jones, B.; Nguyen-Tien, V.; Elliott, R.J.R. The electric vehicle revolution: Critical material supply chains, trade and development. World Econ. 2023, 46, 2–26. [Google Scholar] [CrossRef]
- Wang, S.; Yu, J. Evaluating the electric vehicle popularization trend in China after 2020 and its challenges in the recycling industry. Waste Manag. Res. 2021, 39, 818–827. [Google Scholar] [CrossRef]
- Hu, S.; Wen, Z. Why does the informal sector of end-of-life vehicle treatment thrive? A case study of China and lessons for developing countries in motorization process. Resour. Conserv. Recycl. 2015, 95, 91–99. [Google Scholar] [CrossRef]
- Yechiam, E.; Abofol, T.; Pachur, T. The Seller’s Sense: Buying–Selling Perspective Affects the Sensitivity to Expected Value Differences. J. Behav. Decis. Mak. 2017, 30, 197–208. [Google Scholar] [CrossRef]
- Car Review. BMW i3 Has a Significant Price Cut, Which One Is More Attractive than the Xiaomi SU7? Available online: https://new.qq.com/rain/a/20240606A03OQD00 (accessed on 29 June 2024).
- Gabriel, P.; Helena, N. Second-hand electrical vehicles: A first look at the secondary market of modern EVs. Int. J. Electr. Hybrid Veh. 2018, 10, 236–252. [Google Scholar] [CrossRef]
- Rogoff, K.; Yang, Y. Rethinking China’s growth. Econ. Policy 2024. [Google Scholar] [CrossRef]
- Storchmann, K. On the depreciation of automobiles: An international comparison. Transportation 2004, 31, 371–408. [Google Scholar] [CrossRef]
- Cramer, J.S. The depreciation and mortality of motor-cars. J. R. Stat. Soc. Ser. A Stat. Soc. 1958, 121, 18–46. [Google Scholar] [CrossRef]
- Venkatasubbu, P.; Ganesh, M. Used cars price prediction using supervised learning techniques. Int. J. Eng. Adv. Technol. 2019, 9, 216–223. [Google Scholar] [CrossRef]
- Wu, J.D.; Hsu, C.C.; Chen, H.C. An expert system of price forecasting for used cars using adaptive neuro-fuzzy inference. Expert Syst. Appl. 2009, 36, 7809–7817. [Google Scholar] [CrossRef]
- Pandey, A.; Rastogi, V.; Singh, S. Car’s selling price prediction using random forest machine learning algorithm. In Proceedings of the 5th International Conference on Next Generation Computing Technologies (NGCT-2019), Misraspatti, India, 20–21 December 2019. [Google Scholar]
- Samruddhi, K.; Kumar, R.A. Used car price prediction using k-nearest neighbor based model. Int. J. Innov. Res. Appl. Sci. Eng. 2020, 4, 629–632. [Google Scholar]
- Gajera, P.; Gondaliya, A.; Kavathiya, J. Old car price prediction with machine learning. Int. Res. J. Mod. Eng. Technol. Sci. 2021, 3, 284–290. [Google Scholar]
- Longani, C.; Prasad Potharaju, S.; Deore, S. Price prediction for pre-owned cars using ensemble machine learning techniques. In Recent Trends in Intensive Computing; IOS Press: Amsterdam, The Netherlands, 2021; pp. 178–187. [Google Scholar]
- Gegic, E.; Isakovic, B.; Keco, D.; Masetic, Z.; Kevric, J. Car price prediction using machine learning techniques. TEM J. 2019, 8, 113. [Google Scholar]
- Cui, B.; Ye, Z.; Zhao, H.; Renqing, Z.; Meng, L.; Yang, Y. Used car price prediction based on the iterative framework of XGBoost+ LightGBM. Electronics 2022, 11, 2932. [Google Scholar] [CrossRef]
- Muti, S.; Yıldız, K. Using linear regression for used car price prediction. Int. J. Comput. Exp. Sci. Eng. 2023, 9, 11–16. [Google Scholar] [CrossRef]
- Huang, J.; Saw, S.N.; Feng, W.; Jiang, Y.; Yang, R.; Qin, Y.; Seng, L.S. A Latent Factor-Based Bayesian Neural Networks Model in Cloud Platform for Used Car Price Prediction. IEEE Trans. Eng. Manag. 2023. [Google Scholar] [CrossRef]
- Pillai, A.S. A Deep Learning Approach for Used Car Price Prediction. J. Sci. Technol. 2022, 3, 31–50. [Google Scholar]
- Liu, E.; Li, J.; Zheng, A.; Liu, H.; Jiang, T. Research on the Prediction Model of the Used Car Price in View of the PSO-GRA-BP Neural Network. Sustainability 2022, 14, 8993. [Google Scholar] [CrossRef]
- Jin, C. Price Prediction of Used Cars Using Machine Learning. In Proceedings of the 2021 IEEE International Conference on Emergency Science and Information Technology (ICESIT), Chongqing, China, 22–24 November 2021; pp. 223–230. [Google Scholar]
- Bukvić, L.; Pašagić Škrinjar, J.; Fratrović, T.; Abramović, B.J.S. Price prediction and classification of used-vehicles using supervised machine learning. Sustainability 2022, 14, 17034. [Google Scholar] [CrossRef]
- Wang, Z.; Ching, T.W.; Huang, S.; Wang, H.; Xu, T. Challenges faced by electric vehicle motors and their solutions. IEEE Access 2020, 9, 5228–5249. [Google Scholar] [CrossRef]
- Yang, L.; Wu, H.; Jin, X.; Zheng, P.; Hu, S.; Xu, X.; Yu, W.; Yan, J. Study of cardiovascular disease prediction model based on random forest in eastern China. Sci. Rep. 2020, 10, 5245. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; Volume 26. [Google Scholar]
- Awad, M.; Khanna, R.; Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar]
- Zhu, G.; Li, Q.; Zhao, W.; Lv, X.; Qian, C.; Qian, Q. Tropical Cyclones Intensity Prediction in the Western North Pacific Using Gradient Boosted Regression Tree Model. Front. Earth Sci. 2022, 10, 929115. [Google Scholar] [CrossRef]
- Financial Aid Backs Equipment Renewal. 2024. Available online: http://en.people.cn/n3/2024/0412/c90000-20156152.html (accessed on 29 June 2024).
- Zhang, X.; Bai, X. Incentive policies from 2006 to 2016 and new energy vehicle adoption in 2010–2020 in China. Renew. Sustain. Energy Rev. 2017, 70, 24–43. [Google Scholar] [CrossRef]
- Ji, W.; Zhao, K.; Zhao, B. The trend of natural ventilation potential in 74 Chinese cities from 2014 to 2019: Impact of air pollution and climate change. Build. Environ. 2022, 218, 109146. [Google Scholar] [CrossRef]
- Qiu, Y.Q.; Zhou, P.; Sun, H.C. Assessing the effectiveness of city-level electric vehicle policies in China. Energy Policy 2019, 130, 22–31. [Google Scholar] [CrossRef]
- Qian, L.; Grisolía, J.M.; Soopramanien, D. The impact of service and government-policy attributes on consumer preferences for electric vehicles in China. Transp. Res. Part A Policy Pract. 2019, 122, 70–84. [Google Scholar] [CrossRef]
- Yang, Z. The development of new energy vehicles will enter a period of deep adjustment. China Energy News, 8 January 2024. [Google Scholar]
- Yearender: China’s New Energy Vehicle Industry in Growth Fast Lane. Available online: https://english.news.cn/20221229/82c05e5ef538408b87fb77ba71b854e9/c.html (accessed on 29 June 2024).
- Jia, J.; Shi, B.; Che, F.; Zhang, H. Predicting the Regional Adoption of Electric Vehicle (EV) With Comprehensive Models. IEEE Access 2020, 8, 147275–147285. [Google Scholar] [CrossRef]
- Li, W.; Long, R.; Chen, H.; Geng, J. A review of factors influencing consumer intentions to adopt battery electric vehicles. Renew. Sustain. Energy Rev. 2017, 78, 318–328. [Google Scholar] [CrossRef]
- Cecere, G.; Corrocher, N.; Guerzoni, M. Price or performance? A probabilistic choice analysis of the intention to buy electric vehicles in European countries. Energy Policy 2018, 118, 19–32. [Google Scholar] [CrossRef]
- Mwasilu, F.; Justo, J.J.; Kim, E.-K.; Do, T.D.; Jung, J.-W. Electric vehicles and smart grid interaction: A review on vehicle to grid and renewable energy sources integration. Renew. Sustain. Energy Rev. 2014, 34, 501–516. [Google Scholar] [CrossRef]
- Liu, L.; Kong, F.; Liu, X.; Peng, Y.; Wang, Q. A review on electric vehicles interacting with renewable energy in smart grid. Renew. Sustain. Energy Rev. 2015, 51, 648–661. [Google Scholar] [CrossRef]
- Chandak, A.; Ganorkar, P.; Sharma, S.; Bagmar, A.; Tiwari, S. Car price prediction using machine learning. Int. J. Comput. Sci. Eng. 2019, 7, 444–450. [Google Scholar] [CrossRef]
- Ouyang, D.; Zhang, Q.; Ou, X. Review of Market Surveys on Consumer Behavior of Purchasing and Using Electric Vehicle in China. Energy Procedia 2018, 152, 612–617. [Google Scholar] [CrossRef]
- Baars, J.; Domenech, T.; Bleischwitz, R.; Melin, H.E.; Heidrich, O. Circular economy strategies for electric vehicle batteries reduce reliance on raw materials. Nat. Sustain. 2021, 4, 71–79. [Google Scholar] [CrossRef]
- Xiao, G.; Xiao, Y.; Shu, Y.; Ni, A.; Jiang, Z. Technical and economic analysis of battery electric buses with different charging rates. Transp. Res. Part D Transp. Environ. 2024, 132, 104254. [Google Scholar] [CrossRef]
- Li, S.; Tong, L.; Xing, J.; Zhou, Y. The Market for Electric Vehicles: Indirect Network Effects and Policy Design. SSRN Electron. J. 2014. [Google Scholar] [CrossRef]
- Yu, Z.; Li, S.; Tong, L. Market dynamics and indirect network effects in electric vehicle diffusion. Transp. Res. Part D Transp. Environ. 2016, 47, 336–356. [Google Scholar] [CrossRef]
- Li, X.; Ma, J.; Zhou, X.; Yuan, R. Research on Consumer Trust Mechanism in China’s B2C E-Commerce Platform for Second-Hand Cars. Sustainability 2023, 15, 4244. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training and Testing (1st) | Training and Testing (2nd) | Training and Testing (3rd) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Price Range | Training Dataset | Testing Dataset | Total | Training Dataset | Testing Dataset | Total | Training Dataset | Testing Dataset | Total |
| 3–10 | 4548 | 1138 | 5686 | 6757 | 1690 | 8447 | 6314 | 1579 | 7893 |
| 10–20 | 4575 | 1144 | 5719 | 6188 | 1548 | 7736 | 5979 | 1495 | 7474 |
| 20–30 | 2521 | 631 | 3152 | 3724 | 931 | 4655 | 3660 | 916 | 4576 |
| 30–50 | 820 | 206 | 1026 | 1100 | 276 | 1376 | 1089 | 273 | 1362 |
| 3–50 | 12,464 | 3119 | 15,583 | 17,769 | 4445 | 22,214 | 17,042 | 4263 | 21,305 |
| Price Range (Num.) | Method | Lasso Regression | Regression Tree | Support Vector Regression | Random Forest | GBRT |
|---|---|---|---|---|---|---|
| 3–10 10 k (5686) | MSE | 5.646 ± 1.490 | 1.113 ± 0.596 | 26.122 ± 4.283 | 0.803 ± 0.428 | 0.837 ± 0.373 |
| RMSE | 2.356 ± 0.306 | 1.023 ± 0.257 | 5.094 ± 0.418 | 0.870 ± 0.216 | 0.896 ± 0.187 | |
| MAE | 1.507 ± 0.236 | 0.676 ± 0.149 | 4.618 ± 0.419 | 0.579 ± 0.137 | 0.623 ± 0.125 | |
| R2 | −0.249 ± 0.322 | 0.755 ± 0.129 | −4.774 ± 0.896 | 0.823 ± 0.092 | 0.816 ± 0.080 | |
| 10–20 10 k (5719) | MSE | 6.088 ± 2.862 | 3.027 ± 1.428 | 24.609 ± 5.932 | 1.966 ± 1.128 | 1.944 ± 1.200 |
| RMSE | 2.401 ± 0.567 | 1.695 ± 0.394 | 4.924 ± 0.601 | 1.352 ± 0.372 | 1.337 ± 0.396 | |
| MAE | 1.736 ± 0.434 | 1.163 ± 0.227 | 4.423 ± 0.556 | 0.942 ± 0.217 | 0.950 ± 0.238 | |
| R2 | 0.264 ± 0.383 | 0.636 ± 0.189 | −1.938 ± 0.911 | 0.764 ± 0.144 | 0.766 ± 0.152 | |
| 20–30 10 k (3152) | MSE | 7.811 ± 3.432 | 5.206 ± 2.016 | 10.709 ± 4.278 | 3.482 ± 1.502 | 3.467 ± 1.423 |
| RMSE | 2.725 ± 0.621 | 2.245 ± 0.409 | 3.208 ± 0.648 | 1.831 ± 0.360 | 1.829 ± 0.349 | |
| MAE | 1.959 ± 0.456 | 1.538 ± 0.274 | 2.596 ± 0.560 | 1.263 ± 0.227 | 1.282 ± 0.213 | |
| R2 | −0.114 ± 0.351 | 0.222 ± 0.254 | −0.547 ± 0.432 | 0.472 ± 0.209 | 0.470 ± 0.210 | |
| 30–50 10 k (1026) | MSE | 47.990 ± 9.399 | 13.678 ± 3.853 | 29.499 ± 3.054 | 9.812 ± 3.372 | 8.522 ± 2.886 |
| RMSE | 6.896 ± 0.655 | 3.661 ± 0.522 | 5.424 ± 0.287 | 3.089 ± 0.518 | 2.882 ± 0.465 | |
| MAE | 5.285 ± 0.417 | 2.541 ± 0.274 | 4.564 ± 0.271 | 2.121 ± 0.290 | 2.012 ± 0.278 | |
| R2 | −0.979 ± 0.203 | 0.444 ± 0.094 | −0.238 ± 0.192 | 0.603 ± 0.088 | 0.653 ± 0.080 | |
| 3–50 10 k (15,583) | MSE | 9.034 ± 2.828 | 3.471 ± 1.364 | 22.672 ± 4.635 | 2.365 ± 1.080 | 2.281 ± 1.044 |
| RMSE | 2.971 ± 0.453 | 1.830 ± 0.348 | 4.737 ± 0.485 | 1.504 ± 0.322 | 1.477 ± 0.316 | |
| MAE | 1.931 ± 0.348 | 1.152 ± 0.205 | 4.134 ± 0.466 | 0.952 ± 0.192 | 0.968 ± 0.191 | |
| R2 | 0.892 ± 0.032 | 0.959 ± 0.015 | 0.729 ± 0.049 | 0.972 ± 0.012 | 0.973 ± 0.012 |
| Price Range (Num.) | Acc. Within | Lasso Regression | Regression Tree | Support Vector Regression | Random Forest | GBRT |
|---|---|---|---|---|---|---|
| 3–10 10 k (1142) | 5% | 0.152 ± 0.030 | 0.353 ± 0.053 | 0.017 ± 0.005 | 0.401 ± 0.063 | 0.346 ± 0.048 |
| 10% | 0.305 ± 0.056 | 0.605 ± 0.073 | 0.038 ± 0.013 | 0.667 ± 0.085 | 0.628 ± 0.067 | |
| 10–20 10 k (1147) | 5% | 0.333 ± 0.069 | 0.475 ± 0.042 | 0.049 ± 0.016 | 0.550 ± 0.056 | 0.542 ± 0.065 |
| 10% | 0.579 ± 0.103 | 0.744 ± 0.063 | 0.112 ± 0.031 | 0.816 ± 0.065 | 0.813 ± 0.073 | |
| 20–30 10 k (632) | 5% | 0.427 ± 0.087 | 0.554 ± 0.050 | 0.290 ± 0.075 | 0.625 ± 0.049 | 0.617 ± 0.045 |
| 10% | 0.727 ± 0.090 | 0.803 ± 0.053 | 0.523 ± 0.094 | 0.861 ± 0.044 | 0.862 ± 0.048 | |
| 30–50 10 k (206) | 5% | 0.230 ± 0.064 | 0.511 ± 0.040 | 0.181 ± 0.016 | 0.606 ± 0.048 | 0.607 ± 0.051 |
| 10% | 0.457 ± 0.033 | 0.782 ± 0.036 | 0.416 ± 0.059 | 0.847 ± 0.039 | 0.858 ± 0.038 | |
| 3–50 10 k (3127) | 5% | 0.279 ± 0.049 | 0.449 ± 0.046 | 0.095 ± 0.021 | 0.515 ± 0.054 | 0.490 ± 0.051 |
| 10% | 0.501 ± 0.074 | 0.708 ± 0.060 | 0.188 ± 0.031 | 0.773 ± 0.064 | 0.759 ± 0.061 |
| Price Range (Num.) | Method | Numerical and Texture Features | Numerical Features | Texture Features | |||
|---|---|---|---|---|---|---|---|
| Random Forest | GBRT | Random Forest | GBRT | Random Forest | GBRT | ||
| 3–10 10 k (5686) | MSE | 0.803 ± 0.428 | 0.837 ± 0.373 | 0.896 ± 0.528 | 0.821 ± 0.417 | 1.235 ± 0.543 | 1.519 ± 0.649 |
| RMSE | 0.870 ± 0.216 | 0.896 ± 0.187 | 0.914 ± 0.248 | 0.883 ± 0.205 | 1.088 ± 0.227 | 1.209 ± 0.241 | |
| MAE | 0.579 ± 0.137 | 0.623 ± 0.125 | 0.596 ± 0.146 | 0.595 ± 0.127 | 0.762 ± 0.152 | 0.885 ± 0.155 | |
| R2 | 0.823 ± 0.092 | 0.816 ± 0.080 | 0.803 ± 0.114 | 0.819 ± 0.090 | 0.728 ± 0.118 | 0.665 ± 0.140 | |
| 10–20 10 k (5719) | MSE | 1.966 ± 1.128 | 1.944 ± 1.200 | 2.362 ± 1.241 | 2.240 ± 1.189 | 3.246 ± 1.396 | 3.162 ± 1.358 |
| RMSE | 1.352 ± 0.372 | 1.337 ± 0.396 | 1.491 ± 0.373 | 1.450 ± 0.373 | 1.764 ± 0.365 | 1.741 ± 0.363 | |
| MAE | 0.942 ± 0.217 | 0.950 ± 0.238 | 1.045 ± 0.216 | 1.012 ± 0.215 | 1.265 ± 0.234 | 1.273 ± 0.243 | |
| R2 | 0.764 ± 0.144 | 0.766 ± 0.152 | 0.717 ± 0.160 | 0.731 ± 0.154 | 0.613 ± 0.184 | 0.622 ± 0.180 | |
| 20–30 10 k (3152) | MSE | 3.482 ± 1.502 | 3.467 ± 1.423 | 3.819 ± 1.260 | 3.627 ± 1.294 | 6.713 ± 2.440 | 6.379 ± 2.545 |
| RMSE | 1.831 ± 0.360 | 1.829 ± 0.349 | 1.931 ± 0.300 | 1.879 ± 0.313 | 2.554 ± 0.434 | 2.483 ± 0.462 | |
| MAE | 1.263 ± 0.227 | 1.282 ± 0.213 | 1.353 ± 0.203 | 1.328 ± 0.208 | 1.818 ± 0.287 | 1.775 ± 0.313 | |
| R2 | 0.472 ± 0.209 | 0.470 ± 0.210 | 0.418 ± 0.190 | 0.450 ± 0.183 | 0.039 ± 0.302 | 0.087 ± 0.320 | |
| 30–50 10 k (1026) | MSE | 9.812 ± 3.372 | 8.522 ± 2.886 | 10.992 ± 3.453 | 9.531 ± 2.625 | 19.256 ± 8.214 | 17.735 ± 5.635 |
| RMSE | 3.089 ± 0.518 | 2.882 ± 0.465 | 3.278 ± 0.498 | 3.058 ± 0.426 | 4.305 ± 0.852 | 4.164 ± 0.630 | |
| MAE | 2.121 ± 0.290 | 2.012 ± 0.278 | 2.251 ± 0.238 | 2.134 ± 0.284 | 3.005 ± 0.426 | 2.940 ± 0.313 | |
| R2 | 0.603 ± 0.088 | 0.653 ± 0.080 | 0.554 ± 0.086 | 0.611 ± 0.070 | 0.210 ± 0.238 | 0.267 ± 0.142 | |
| 3–50 10 k (15,583) | MSE | 2.365 ± 1.080 | 2.281 ± 1.044 | 2.690 ± 1.112 | 2.483 ± 0.998 | 4.362 ± 1.768 | 4.258 ± 1.635 |
| RMSE | 1.504 ± 0.322 | 1.477 ± 0.316 | 1.610 ± 0.313 | 1.548 ± 0.295 | 2.052 ± 0.390 | 2.030 ± 0.368 | |
| MAE | 0.952 ± 0.192 | 0.968 ± 0.191 | 1.023 ± 0.183 | 0.998 ± 0.178 | 1.320 ± 0.225 | 1.354 ± 0.227 | |
| R2 | 0.972 ± 0.012 | 0.973 ± 0.012 | 0.968 ± 0.013 | 0.970 ± 0.011 | 0.949 ± 0.020 | 0.950 ± 0.018 | |
| Price Range | Acc. Within | Numerical and Texture Features | Numerical Features | Texture Features | |||
|---|---|---|---|---|---|---|---|
| Random Forest | GBRT | Random Forest | GBRT | Random Forest | GBRT | ||
| 3–10 10 k (1142) | 5% | 0.401 ± 0.063 | 0.346 ± 0.048 | 0.396 ± 0.059 | 0.388 ± 0.049 | 0.294 ± 0.046 | 0.239 ± 0.039 |
| 10% | 0.667 ± 0.085 | 0.628 ± 0.067 | 0.663 ± 0.084 | 0.661 ± 0.078 | 0.531 ± 0.086 | 0.443 ± 0.066 | |
| 10–20 10 k (1147) | 5% | 0.550 ± 0.056 | 0.542 ± 0.065 | 0.506 ± 0.048 | 0.526 ± 0.054 | 0.416 ± 0.046 | 0.405 ± 0.044 |
| 10% | 0.816 ± 0.065 | 0.813 ± 0.073 | 0.784 ± 0.059 | 0.790 ± 0.064 | 0.695 ± 0.056 | 0.697 ± 0.071 | |
| 20–30 10 k (632) | 5% | 0.625 ± 0.049 | 0.617 ± 0.045 | 0.591 ± 0.038 | 0.595 ± 0.045 | 0.475 ± 0.043 | 0.471 ± 0.049 |
| 10% | 0.861 ± 0.044 | 0.862 ± 0.048 | 0.839 ± 0.042 | 0.852 ± 0.049 | 0.748 ± 0.045 | 0.755 ± 0.051 | |
| 30–50 10 k (206) | 5% | 0.606 ± 0.048 | 0.607 ± 0.051 | 0.567 ± 0.051 | 0.578 ± 0.049 | 0.442 ± 0.027 | 0.443 ± 0.026 |
| 10% | 0.847 ± 0.039 | 0.858 ± 0.038 | 0.820 ± 0.035 | 0.842 ± 0.034 | 0.738 ± 0.052 | 0.744 ± 0.032 | |
| 3–50 10 k (3127) | 5% | 0.515 ± 0.054 | 0.490 ± 0.051 | 0.487 ± 0.044 | 0.493 ± 0.044 | 0.386 ± 0.040 | 0.362 ± 0.038 |
| 10% | 0.773 ± 0.064 | 0.759 ± 0.061 | 0.753 ± 0.060 | 0.759 ± 0.060 | 0.650 ± 0.061 | 0.621 ± 0.059 | |
| Price Range | Method | Training and Testing (1st) | Training and Testing (2nd) | Training and Testing (3rd) |
|---|---|---|---|---|
| 30–100 k | MSE | 0.615 | 0.581 | 0.540 |
| RMSE | 0.784 | 0.762 | 0.735 | |
| MAE | 0.571 | 0.550 | 0.502 | |
| R2 | 0.864 | 0.866 | 0.866 | |
| 100–200 k | MSE | 1.650 | 1.281 | 1.321 |
| RMSE | 1.284 | 1.132 | 1.149 | |
| MAE | 0.916 | 0.807 | 0.825 | |
| R2 | 0.811 | 0.847 | 0.839 | |
| 200–300 k | MSE | 2.566 | 3.076 | 2.545 |
| RMSE | 1.602 | 1.754 | 1.595 | |
| MAE | 1.093 | 1.281 | 1.163 | |
| R2 | 0.649 | 0.588 | 0.663 | |
| 300–500 | MSE | 7.484 | 6.805 | 6.881 |
| RMSE | 2.736 | 2.609 | 2.623 | |
| MAE | 1.827 | 1.833 | 1.928 | |
| R2 | 0.683 | 0.694 | 0.693 | |
| 30–500 k | MSE | 1.843 | 1.733 | 1.651 |
| RMSE | 1.358 | 1.317 | 1.285 | |
| MAE | 0.886 | 0.873 | 0.849 | |
| R2 | 0.978 | 0.979 | 0.980 |
| Price Range | Acc. Within | Training and Testing (1st) | Training and Testing (2nd) | Training and Testing (3rd) |
|---|---|---|---|---|
| 30–100 k | 5% | 0.364 | 0.401 | 0.442 |
| 10% | 0.652 | 0.677 | 0.745 | |
| 100–200 k | 5% | 0.545 | 0.589 | 0.563 |
| 10% | 0.816 | 0.863 | 0.864 | |
| 200–300 k | 5% | 0.688 | 0.605 | 0.621 |
| 10% | 0.899 | 0.871 | 0.897 | |
| 300–500 k | 5% | 0.655 | 0.623 | 0.612 |
| 10% | 0.879 | 0.880 | 0.872 | |
| 30–500 k | 5% | 0.515 | 0.521 | 0.534 |
| 10% | 0.777 | 0.795 | 0.828 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Zhu, Y.; Huang, J.; Zhang, E.; Xu, T. Analysis of Circular Price Prediction Strategy for Used Electric Vehicles. Sustainability 2024, 16, 5761. https://doi.org/10.3390/su16135761
Huang S, Zhu Y, Huang J, Zhang E, Xu T. Analysis of Circular Price Prediction Strategy for Used Electric Vehicles. Sustainability. 2024; 16(13):5761. https://doi.org/10.3390/su16135761
Chicago/Turabian StyleHuang, Shaojia, Yisen Zhu, Jingde Huang, Enguang Zhang, and Tao Xu. 2024. "Analysis of Circular Price Prediction Strategy for Used Electric Vehicles" Sustainability 16, no. 13: 5761. https://doi.org/10.3390/su16135761
APA StyleHuang, S., Zhu, Y., Huang, J., Zhang, E., & Xu, T. (2024). Analysis of Circular Price Prediction Strategy for Used Electric Vehicles. Sustainability, 16(13), 5761. https://doi.org/10.3390/su16135761