
Shanghai Transport Carbon Emission Forecasting Study Based on CEEMD-IWOA-KELM Model


Abstract

1. Introduction
2. Related Works
3. Materials and Methods
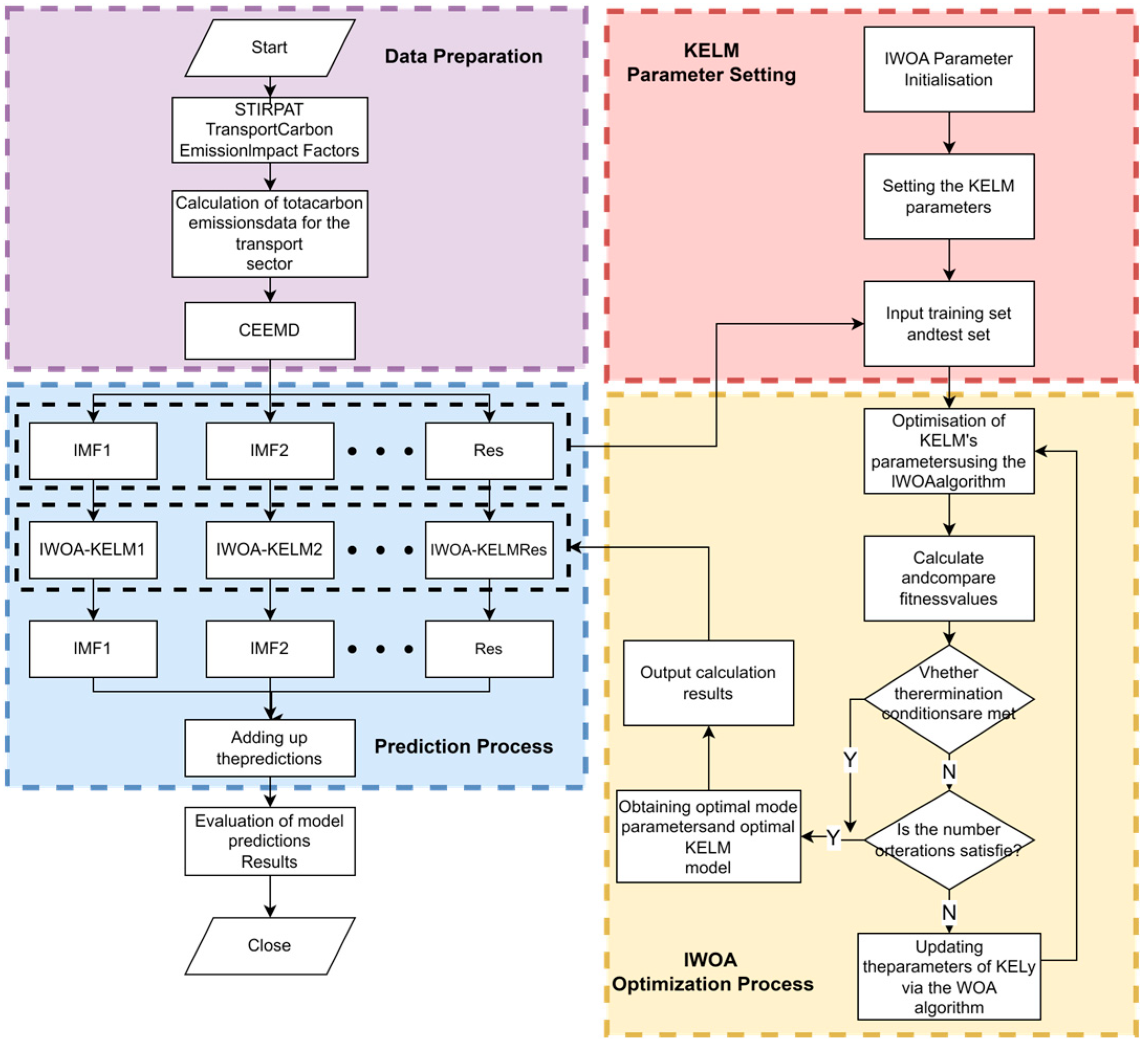
3.1. Transport Carbon Emission Measurement
3.1.1. Methodology for Measuring Carbon Emissions from Transport
3.1.2. Selection of Factors Affecting Transport Carbon Emissions
3.1.3. Data Sources
3.2. Data Preprocessing
3.3. Parameter Optimization
3.4. Machine Learning Model Selection
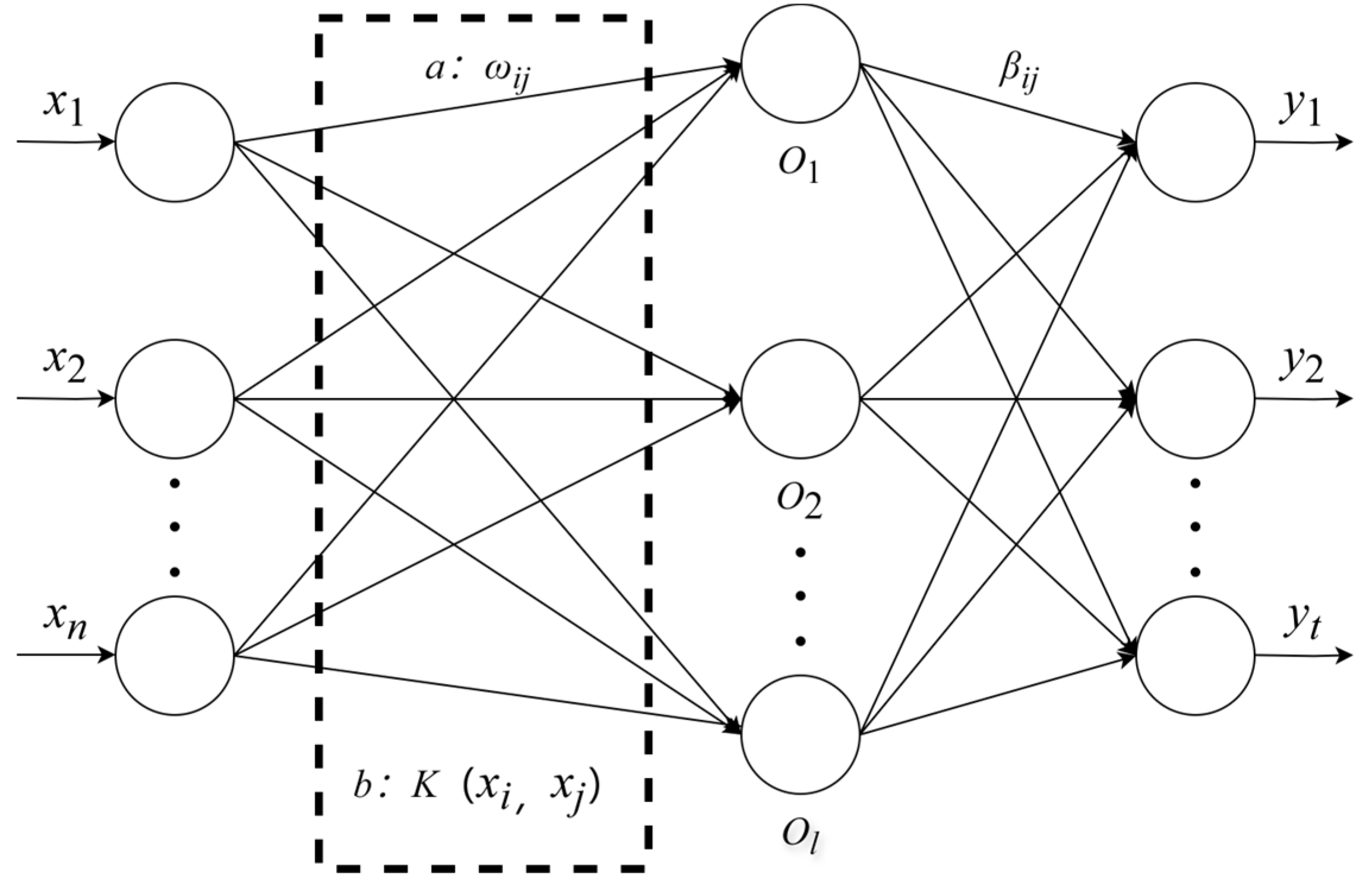
3.4.1. Kernel Extreme Learning Machine
3.4.2. Other Neutral Network Prediction Models
3.5. Construction of Carbon Emission Prediction Models for Transport
- (1)
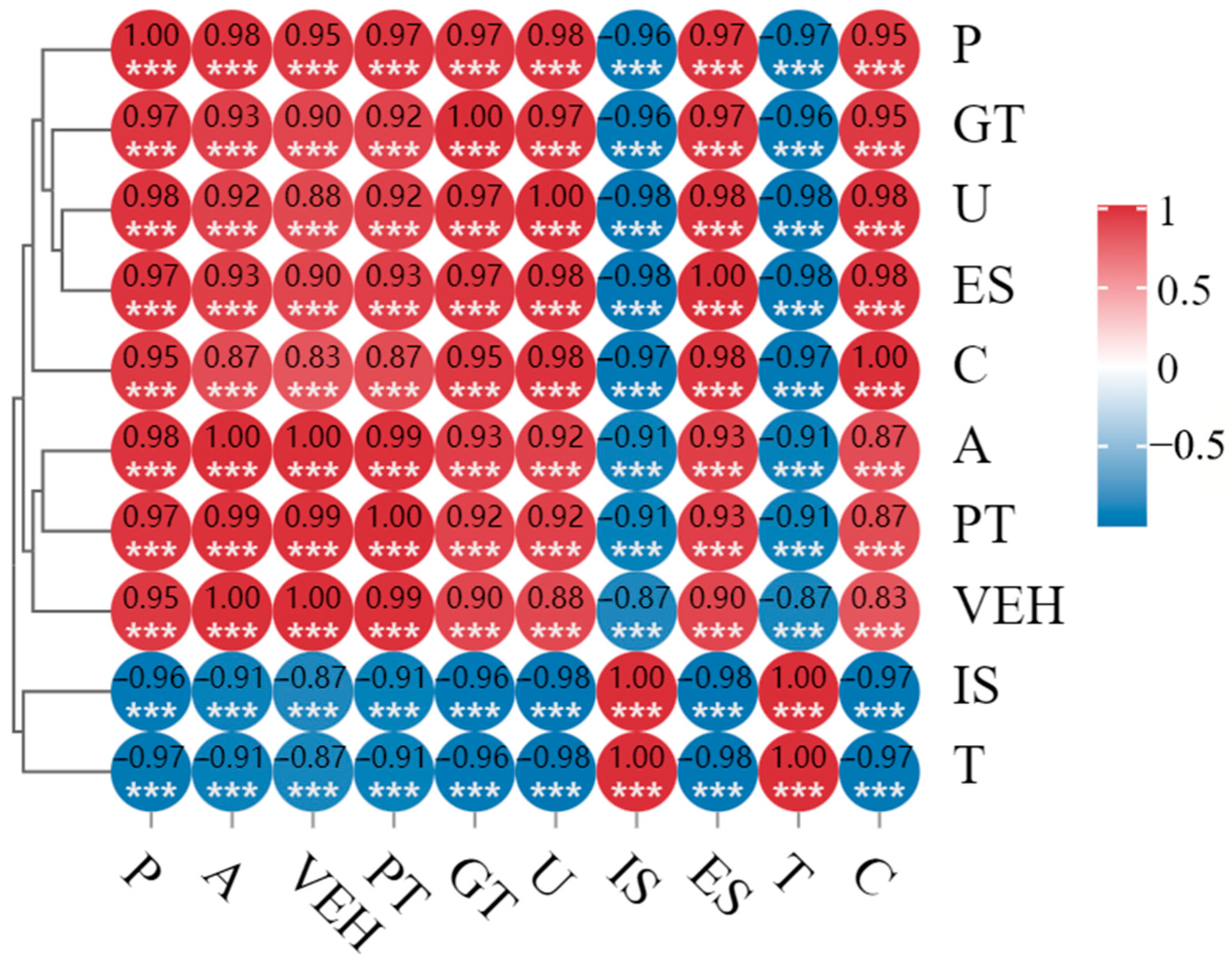
- Adopt the STIRPAT model for transport carbon emission factors, consider the influencing factors from the population factors, wealth factors, and technology level, and finally select a total of 9 types of variables as the main influencing factors, including P, U, A, VEH, PT, GT, ES, IS, and T.
- (2)
- Calculate the total carbon emissions C of Shanghai’s transport industry according to Equation (1).
- (3)
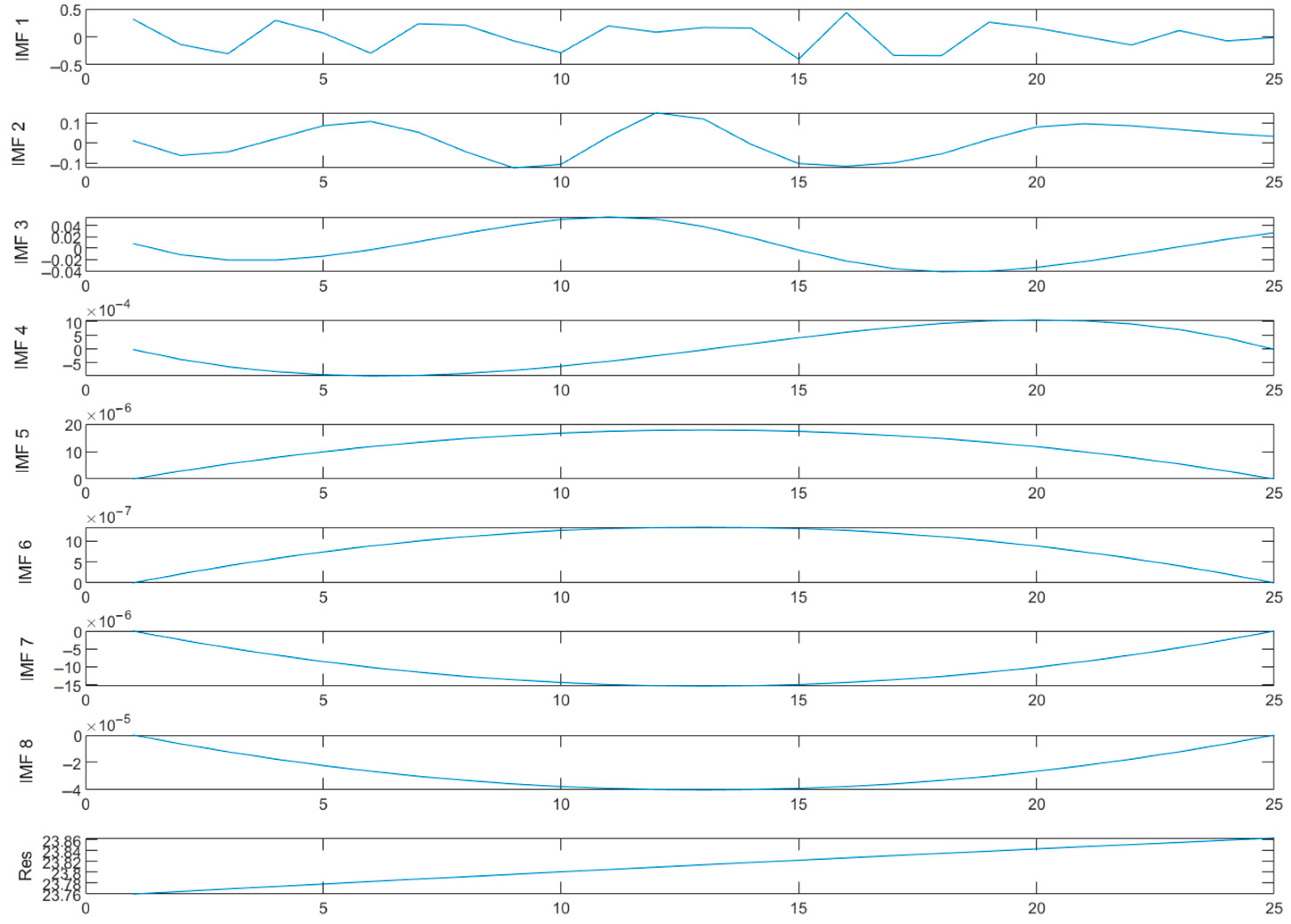
- Decompose the original transport carbon emission data by the CEEMD method, and separate out the internal modal component and the residual part Res.
- (4)
- Adjust the initial parameters of the IWOA algorithm and the KELM model, and update the position of the whale population in the search space by means of Equations (6)~(11); meanwhile, establish the KELM prediction model by means of Equations (12)~(15).
- (5)
- For each decomposed and Res, establish an IWOA-KELM prediction model, and obtain the predicted output value of each decomposed sequence through optimal selection of parameters.
- (6)
- Combine the forecasts of all the decomposed sequences to obtain the forecast value of total carbon emissions from the Shanghai transport industry.
- (7)
- Compare the obtained prediction values with the actual measured data, quantify the prediction errors by calculating the error indicators, and analyze them in depth to assess the validity and reliability of the model.
4. Results
4.1. Data Preprocessing
4.2. Evaluation Indicators
4.3. Decomposition of Data
4.4. Comparison and Analysis of Forecast Results
- (1)
- The analysis of the results presented in Table 5 reveals that the CEEMD-IWOA-KELM prediction model exhibits the highest precision. The analysis of the CEEMD-IWOA-KELM, IWOA-KELM, WOA-KELM, ELM, BP, LSTM, and GRNN models yields the average values of relative errors 0.11%, 0.21%, −0.90%, 0.67%, 3.52%, 4.30%, and 1.26%, and the average relative error of the CEEMD-IWOA-KELM model is 2.44%. The relative error is 2.44%, significantly due to the other models tested.
- (2)
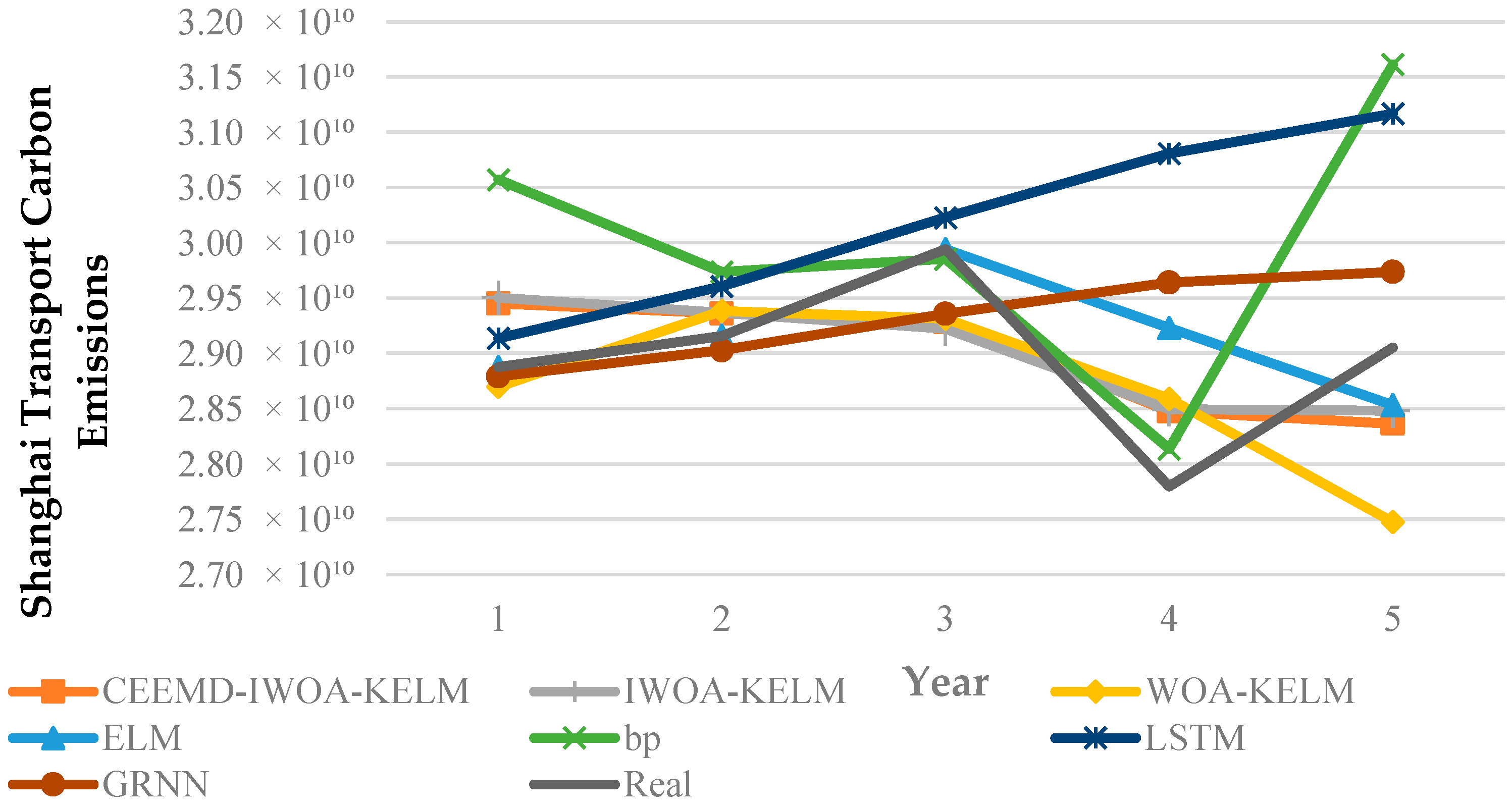
- Figure 7 shows the predicted and actual values of Shanghai’s transport carbon emissions by model. Compared with the other transport carbon emission prediction models in the test, the CEEMD-IWOA-KELM model shows the best data fitting performance with the highest prediction accuracy, and its predicted trend direction is in high agreement with the dynamic changes in transport carbon emissions in the actual situation.
- (3)
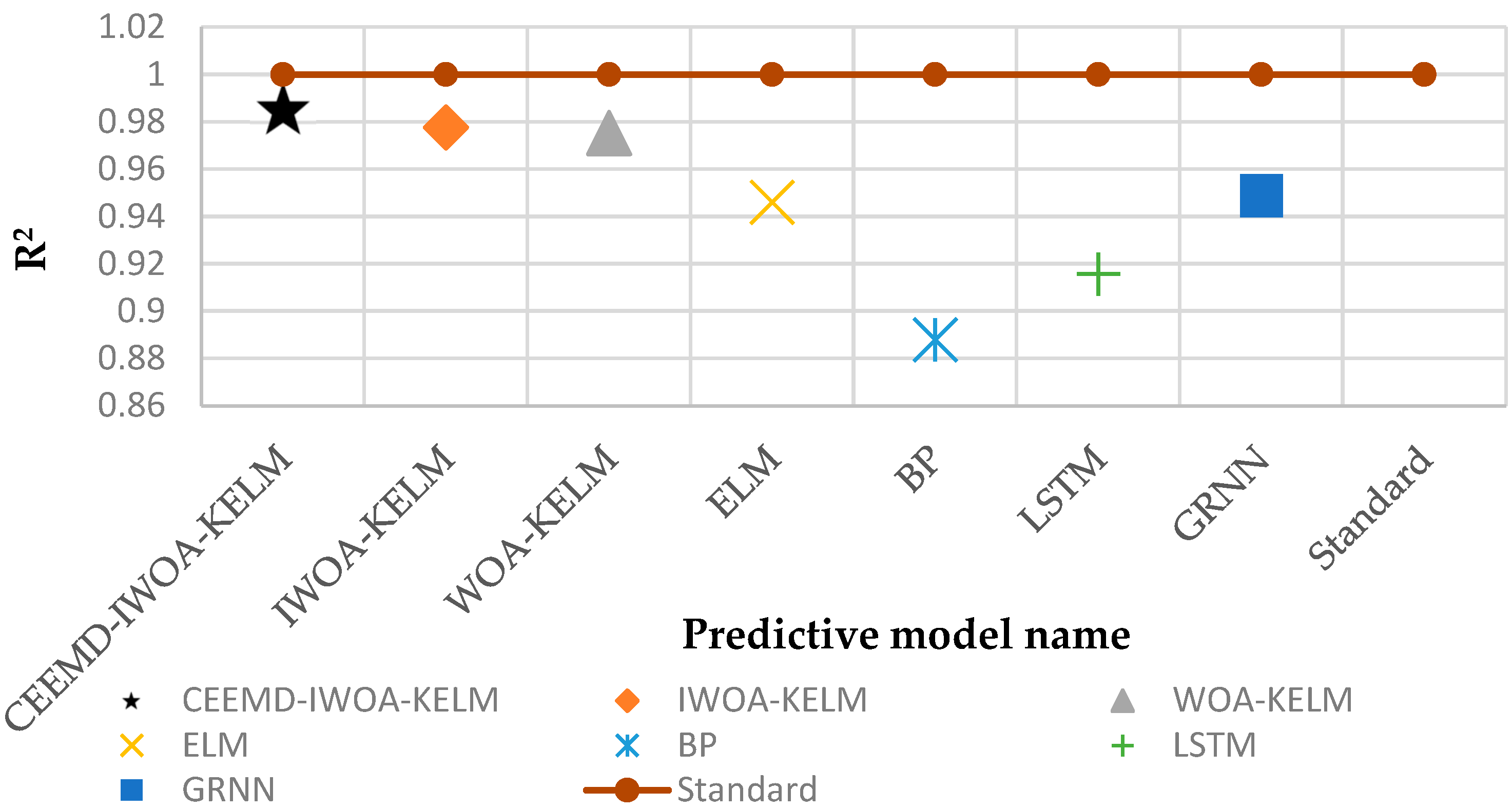
- Table 6 provides detailed error data. The model proposed in this paper has the highest performance under all four evaluation metrics: RMSE = 0.0324, MAE = 0.0215, MAPE = 0.09%, and R2 = 0.9857. Figure 8 combines the MAE and RMSE in a single histogram. It can be clearly seen that the CEEMD-IWOA-KELM model proposed in this paper has the lowest values, indicating the highest model accuracy. Figure 9 displays the R2 values of the models. The model closest to the standard line of 1 indicates higher accuracy. It can be observed that the R2 value of the CEEMD-IWOA-KELM model is closest to 1.
- (4)
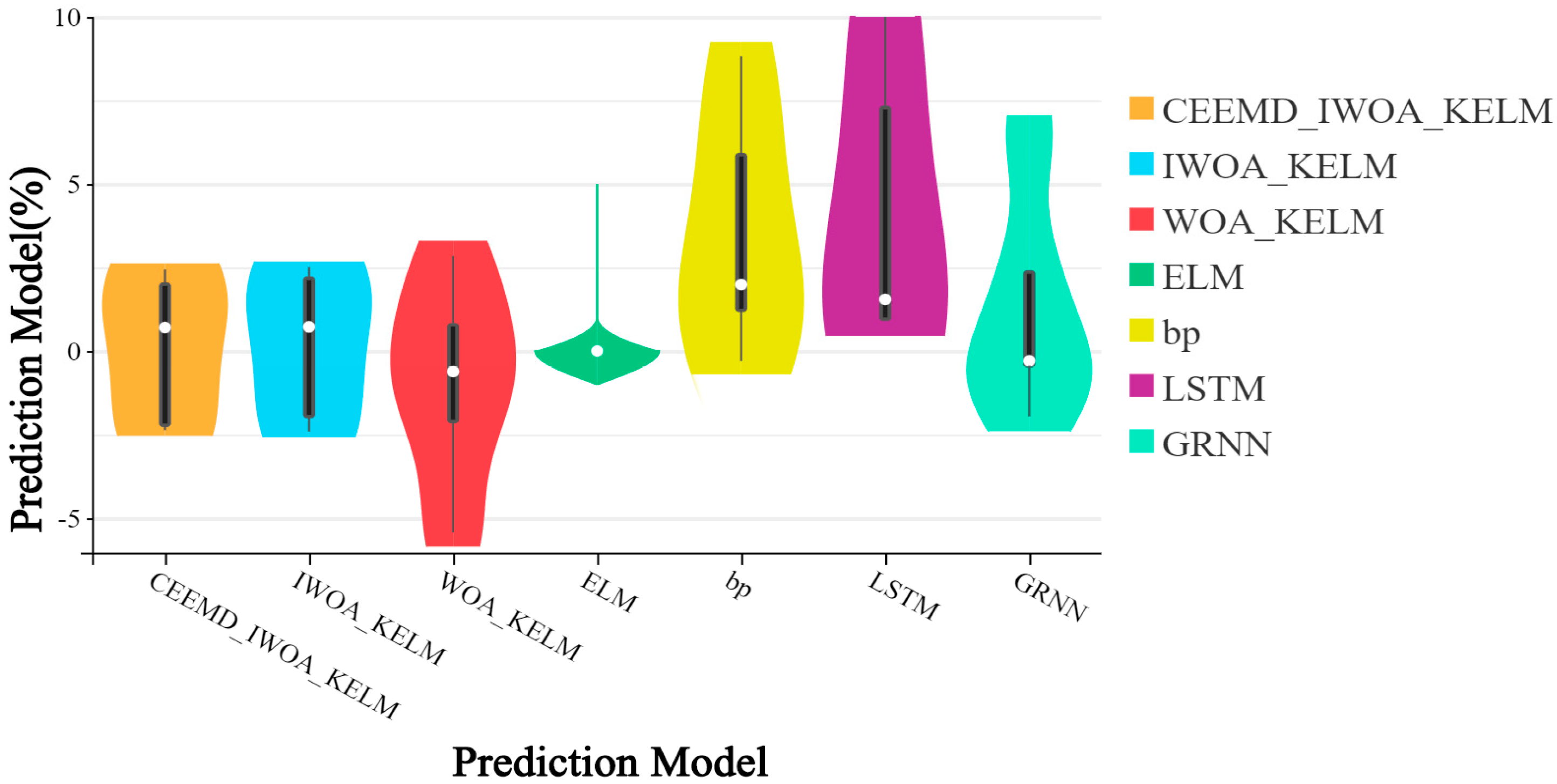
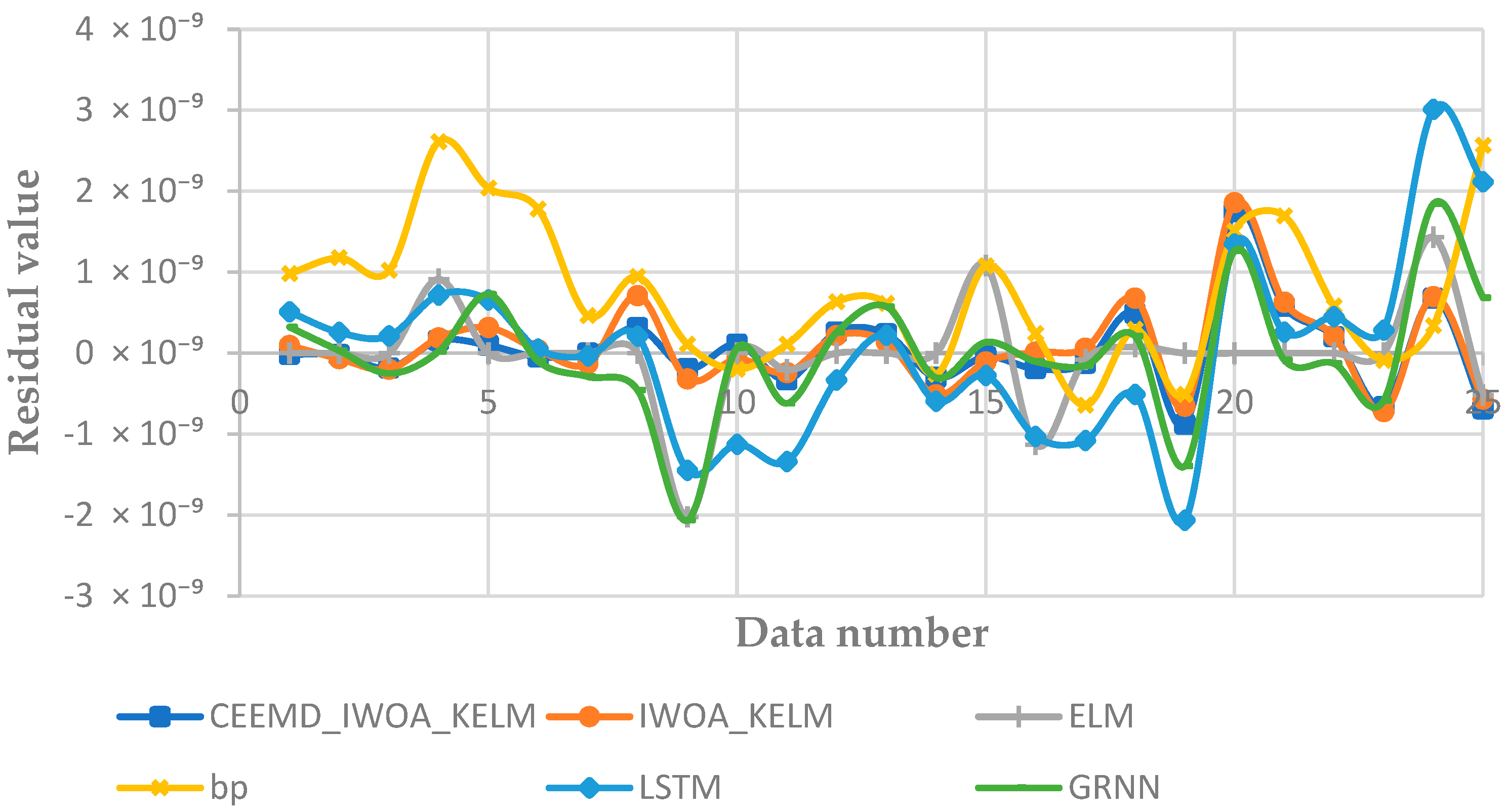
- Figure 10 shows the residual values for all predictions made by each model. It can be observed that the CEEMD-IWOA-KELM model and the IWOA-KELM model exhibit a relatively stable performance. In comparison, the BP model shows the poorest stability. The ELM model has some predictions match the actual values closely, but its overall prediction performance is less stable, leading to significant discrepancies. Therefore, using swarm intelligence optimization algorithms to optimize machine learning models is highly necessary.
5. Conclusions and Future Work
5.1. Conclusions
- (1)
- Effectiveness of data decomposition: The CEEMD technique successfully transformed the transport carbon emission data into a series of low-complexity, smooth components, and this preprocessing step significantly alleviated the nonlinearity and volatility of the original data, and the smooth data can be better used for prediction studies. Compared with the IWOA-KELM model without CEEMD, the average absolute error of the CEEMD-IWOA-KELM model proposed in this paper is reduced by 22.61%, which shows that data decomposition has a significant role in improving prediction accuracy.
- (2)
- Performance improvement of optimization algorithm: The IWOA algorithm not only maintains the original powerful global search capability of the whale optimization algorithm, but also further improves the prediction accuracy through the quasi-backward learning strategy, the introduction of nonlinear convergence factors, the adaptive weighting strategy, and the stochastic difference variance strategy. The data show that the RMSE value of the IWOA-KELM model is reduced by 19.47% compared with the base WOA-KELM model, and a substantial reduction of 50.26% is achieved compared with the standard ELM model, which clearly proves that the global optimization and generalization ability of the model is significantly enhanced after the optimization of the IWOA and the combination of the kernel function.
5.2. Future Work
- (1)
- Although the constructed CEEMD-IWOA-KELM model demonstrates significant performance in terms of prediction accuracy, it still faces several challenges. For instance, the factors influencing carbon emissions in the transportation sector are multifaceted, and future research should incorporate more variables to better reflect the actual situation comprehensively. Additionally, the market share of new energy vehicles is increasing year by year, and future studies need to consider the carbon footprint left by new energy vehicles.
- (2)
- This study primarily focused on the novelty of the model, without delving deeper into predictive analysis. Future work will integrate scenario forecasting to provide a more thorough prediction of carbon emissions in Shanghai’s transportation sector and offer corresponding policies and recommendations. Additionally, the generalizability of the research findings needs attention, considering the extension of the experience in predicting traffic carbon emissions in the Shanghai region to other major cities in China. This would contribute to China’s goal of peaking carbon emissions before 2030 and achieving carbon neutrality before 2060.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mou, Y.T.; Ke, Z.K. Exploring the scientific consensus on global warming and the misunderstanding of the American public. SIND 2022, 38, 64–70. [Google Scholar]
- Lin, B.; Xie, C. Reduction potential of CO2 emissions in Chinas transport industry. Renew. Sustain. Energy Rev. 2014, 33, 689–700. [Google Scholar] [CrossRef]
- Xi, W.X. Research and analysis of carbon emission influencing factors in Shanghai transportation industry. LEM 2023, 45, 97–100+119. [Google Scholar]
- Wang, Q.R.; Wang, J.J.; Zhu, C.F.; Hao, F. Research on carbon emission prediction of transportation industry by integrating VMD and SSA-LSSVM. Environ. Eng. 2023, 41, 124–132. [Google Scholar]
- Yang, H.; O’Connell, J.F. Short-term carbon emissions forecast for aviation industry in Shanghai. J. Clean. Prod. 2020, 275, 122734. [Google Scholar] [CrossRef]
- Huang, X.Y.; Wu, J.Y.; Lin, W.H.; Wu, Q.X. Carbon emission prediction of Jiangsu Province based on GM (1,1) model. Heilongjiang Sci. 2022, 13, 26–28+32. [Google Scholar]
- Yang, W.L.; Yan, Z.A. Evaluation of CO2 emission from agricultural soils based on RBF neural network algorithm. Softw. Guide 2022, 21, 7–11. [Google Scholar]
- Tursun, B.; Ding, W.M.; Xie, J.H. Neural network-based carbon emission prediction and analysis of influencing factors. Environ. Eng. 2017, 35, 156–160. [Google Scholar]
- Zhang, D.; Wang, T.T.; Zhi, J.H. Carbon emission prediction and eco-economic analysis of Shandong Province based on IPSO-BP neural network model. Ecol. Sci. 2022, 41, 149–158. [Google Scholar]
- Lian, Y.; Su, D.; Shi, S. Carbon Peak Prediction in Fujian Province Based on STIRPAT and CNN-LSTM Combination Model. Environ. Sci. 2024. Available online: https://www.chndoi.org/Resolution/Handler?doi=10.13227/j.hjkx.202401065 (accessed on 5 August 2024). [CrossRef]
- Huang, G.B. An Insight into Extreme Learning Machines: Random Neurons, Random Features and Kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Zhang, X.S.; Wei, Z.Z.; Chen, Z.Z.; Han, Y.W. Research on industrial carbon emission prediction method based on LASSO-GWO-KELM. Environ. Eng. 2023, 41, 141–149. [Google Scholar]
- Xu, T. Research on Prediction and Classification Based on Swarm Intelligence Algorithm and Machine Learning. Ph.D. Thesis, North China University, Beijing, China, 2021. [Google Scholar]
- Wang, K.; Niu, D.; Zhen, H.; Sun, L.; Xu, X.M. Research on Carbon Emission Prediction in China Based on WOA-ELM Model. Ecol. Econ. 2020, 36, 20–27. [Google Scholar]
- Chi, X.; Xu, Z.; Jia, X.; Zhang, W.J. Carbon Emission Prediction of Power Plants Based on WPD-ISSA-CA-CNN Model. Control. Eng. 2022, 1–8. Available online: https://www.chndoi.org/Resolution/Handler?doi=10.14107/j.cnki.kzgc.20220983 (accessed on 5 August 2024). [CrossRef]
- Long, D. Research on Scenario Prediction of Carbon Emissions in Guangdong Province Based on CSO-FLN. Ph.D. Thesis, North China Electric Power University, Beijing, China, 2022. [Google Scholar]
- Mao, H.S. Carbon emission right price prediction based on CS-BP neural network model. IT&I 2023, 9, 52–55. [Google Scholar]
- Jiao, J.J.; Liu, T.Y. Short-term load forecasting based on ICEEMDAN-IWOA-BiLSTM hybrid algorithm model. Electr. Autom. 2024, 46, 36–39. [Google Scholar]
- Wu, Z.Q.; Mou, Y.M. An improved whale optimization algorithm. Appl. Res. Comput. 2020, 37, 3618–3621. [Google Scholar]
- Bokde, N.D.; Tranberg, B.; Andresen, G.B. Short-term CO2 emissions forecasting based on decomposition approaches and its impact on electricity market scheduling. Appl. Energ. 2021, 281, 116061. [Google Scholar] [CrossRef]
- Zhang, X.S.; Ren, M.Y.; Chen, Z.Z. Research on carbon emission prediction of construction industry based on CEEMD-SSA-ELM method. Ecol. Econ. 2023, 39, 33–39+88. [Google Scholar]
- Cai, B.F.; Zhu, S.L.; Yu, S.M.; Dong, H.M.; Zhang, C.Y.; Wang, C.K.; Zhu, J.H.; Gao, Q.X.; Fang, S.X.; Pan, X.B.; et al. Interpretation of the 2019 Revision of the IPCC 2006 Guidelines for National Greenhouse Gas Inventories. Environ. Eng. 2019, 37, 1–11. [Google Scholar]
- York, R.; Rosa, E.A.; Dietz, T. STIRPAT, IPAT and ImPACT: Analytic tools for unpacking the driving forces of environmental impacts. Ecol. Econ. 2003, 3, 46. [Google Scholar] [CrossRef]
- Liu, J.C. Energy saving potential and carbon emission prediction in China’s transportation sector. Resour. Sci. 2011, 33, 640–646. [Google Scholar]
- Zhu, C.Z.; Yang, S.; Liu, P.B.; Wang, M. Prediction of carbon peaking time in China’s transportation sector. JOTSEIT 2022, 22, 291–299. [Google Scholar]
- Liu, C.; Qu, J.S.; Ge, Y.J.; Tang, J.X.; Gao, X.Y.; Liu, L.N. Carbon emission prediction of China’s transportation industry based on LSTM model. China Environ. Sci. 2023, 43, 2574–2582. [Google Scholar]
- Wang, Y.; Hayashi, Y.; Kato, H.; Liu, C. Decomposition analysis of CO2 emissions increase from the passenger transport sector in Shanghai, China. Int. J. Urban Sci. 2011, 15, 121–136. [Google Scholar] [CrossRef]
- Hu, M.F.; Zheng, Y.B.; Li, Y.H. Prediction of peak carbon emissions from transportation in Hubei Province under multiple scenarios. CST 2022, 42, 464–472. [Google Scholar]
- Loo, B.P.Y.; Li, L. Carbon dioxide emissions from passenger transport in China since 1949: Implications for developing sustainable transport. Energy Policy 2012, 50, 464–476. [Google Scholar] [CrossRef]
- Timilsina, G.R.; Shrestha, A. Transport sector CO2 emissions growth in Asia: Underlying factors and policy options. Energy Policy 2009, 37, 4523–4539. [Google Scholar] [CrossRef]
- Zhang, H.; Kong, X.; Ren, C.X. Influencing factors and forecast of carbon emissions from transportation-taking Shandong province as an example. EES 2019, 300, 032063. [Google Scholar] [CrossRef]
- Yang, S.H.; Zhang, Y.Q.; Geng, Y. Analysis of transportation carbon emission changes in the Yangtze River Economic Belt based on LMDI. China Environ. Sci. 2022, 42, 4817–4826. [Google Scholar]
- Zhou, Y.X. Research on the decoupling and coupling relationship between transportation carbon emissions and industry economic growth—Based on Tapio decoupling model and cointegration theory. Inq. Into Econ. Issues 2016, 407, 41–48. [Google Scholar]
- Fan, Y.J.; Qu, J.S.; Zhang, H.F.; Xu, L.; Bai, J.; Wu, J.J. Research on the current situation and influencing factors of transportation carbon emissions in five provinces and regions in Northwest China. Ecol. Econ. 2019, 35, 32–37+67. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and nonstationary time series analysis. Proc. R. Soc. A-Math. Phys. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.H.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Yeh, J.R.; Shieh, J.S.; Huang, N.E. Complementary ensemble empirical mode decomposition: A novel noise enhanced data analysis method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Chen, L.; Hao, Y.C.; Li, Q.R.; Ding, J.X. Improved BP neural network traffic prediction model for SSA optimization. JHIT 2024, 56, 1–10. [Google Scholar]
- Chen, H.W.; Xing, W.W.; Zhao, C.L.; Cao, B.H.; Liu, J.H.; Zhao, X.H.; Yang, L.W. Prediction of N2O emission from wastewater treatment plant based on CEEMDAN-LSTM model. Water Wastewater Eng. 2024, 60, 166–172. [Google Scholar]
- Zhou, J.G.; Zhang, M. Combined NOx emission prediction for thermal power industry based on improved gray and generalized neural network. Environ. Eng. 2014, 32, 120–125. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Reference | Algorithm Features |
|---|---|---|
| ARIMA | Yang et al. [5] | While the model demonstrates a good fit for time series data, it lacks the capability to integrate other influencing factors. |
| GM (1, 1) | Huang et al. [6] | The model lacks the ability to accurately capture the relationship between the dependent and independent variables. |
| RBF | Yang Wenli and Yan Zhengang [7] | The algorithm presents challenges in parameter selection and exhibits high computational complexity. |
| GRNN | Turson-Buyouti et al. [8] | The algorithm has a high computational complexity and poor interpretability. |
| BP | Di Zhang [9] | Slow to learn and prone to fall into local minima |
| LSTM | Lian Yanqiong et al. [10] | Very suitable for handling time series prediction, but with a long training time and difficult debugging |
| KELM | Zhang Xinsheng [12] | More flexible in adapting to different types of data and problems |
| Impact Factors | Impact Indicators | Meaning in This Study | References |
|---|---|---|---|
| Demographic Factors | Population Size (P) | Total household population in Shanghai at the end of the year | [4,24,25,26,27,28,29,30,31,32] |
| Urbanization Level (U) | Ratio of urban population to total population | [4,26,33,34] | |
| Wealth Factors | GDP per capita (A) | Ratio of Shanghai’s GDP to the total registered population in Shanghai at the end of the year | [4,24,26,27,28,29,30,31,32,33,34] |
| Motor Vehicle Ownership (VEH) | Vehicle ownership for civilian use in Shanghai | [4,27,32,33] | |
| Passenger Turnover (PT) | Passenger traffic volume in Shanghai | [4,25,31,32,34] | |
| Cargo Turnover (GT) | Cargo turnover in Shanghai | [4,24,31,33,34] | |
| Technology Level | Energy Structure (ES) | Ratio of raw clean energy consumption to all energy consumption in Shanghai region | [28,29,30,31] |
| Energy Intensity (IS) | Ratio of Shanghai’s raw energy consumption to Shanghai’s GDP | [4,25,26,27,31,34] | |
| Carbon Emission Intensity (T) | Ratio of total carbon emissions from the transport sector in the Shanghai region to Shanghai’s GDP | [4,26,27,28,30,32] |
| Energy | Carbon Content (kg/GJ) | Lower Heating Value (kJ/kg) | Standard Coal Conversion Factor (kgce/kg) | Carbon Oxidation Rate (%) |
|---|---|---|---|---|
| Crude coal | 29.2 | 20,934 | 0.7143 | 98 |
| Crude oil | 20.0 | 41,868 | 1.4286 | 99 |
| Petrol | 18.9 | 43,124 | 1.4714 | 99 |
| Paraffin | 19.6 | 43,124 | 1.4714 | 99 |
| Diesel oil | 20.2 | 42,705 | 1.4571 | 99 |
| Fuel oil | 21.1 | 41,868 | 1.4286 | 99 |
| Year | Carbon Emissions/10 kt | Year | Carbon Emissions/10 kt |
|---|---|---|---|
| 1995 | 2277.48 | 2008 | 2599.63 |
| 1996 | 2438.67 | 2009 | 2608.21 |
| 1997 | 2418.16 | 2010 | 2829.28 |
| 1998 | 2457.87 | 2011 | 2880.87 |
| 1999 | 2599.63 | 2012 | 2865.03 |
| 2000 | 2608.21 | 2013 | 3037.40 |
| 2001 | 2829.28 | 2014 | 2749.53 |
| 2002 | 2880.87 | 2015 | 2887.64 |
| 2003 | 2865.03 | 2016 | 2915.67 |
| 2004 | 2277.48 | 2017 | 2994.37 |
| 2005 | 2438.67 | 2018 | 2779.69 |
| 2006 | 2418.16 | 2019 | 2905.12 |
| 2007 | 2457.87 |
| Year | CEEMD-IWOA-KELM | IWOA-KELM | WOA-KELM | ELM | BP | LSTM | GRNN |
|---|---|---|---|---|---|---|---|
| 2015 | 2.00% | 2.17% | −0.62% | 0.00% | 5.87% | 0.90% | −0.29% |
| 2016 | 0.70% | 0.72% | 0.78% | 0.00% | 1.99% | 1.54% | −0.44% |
| 2017 | −2.22% | −2.41% | −2.11% | 0.00% | −0.30% | 0.95% | −1.96% |
| 2018 | 2.44% | 2.51% | 2.85% | 5.15% | 1.22% | 10.83% | 6.63% |
| 2019 | −2.37% | −1.96% | −5.43% | −1.78% | 8.82% | 7.29% | 2.36% |
| Model | RMSE | MAPE | MAE | R2 |
|---|---|---|---|---|
| CEEMD-IWOA-KELM | 0.0324 | 0.0900% | 0.0215 | 0.9857 |
| IWOA-KELM | 0.0341 | 0.1161% | 0.0278 | 0.9820 |
| WOA-KELM | 0.0424 | 0.1243% | 0.0297 | 0.9794 |
| ELM | 0.0687 | 0.2503% | 0.0596 | 0.9302 |
| BP | 0.0483 | 0.1935% | 0.0456 | 0.9386 |
| LSTM | 0.0509 | 0.1900% | 0.0449 | 0.9316 |
| GRNN | 0.0687 | 0.2102% | 0.0499 | 0.8756 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, Y.; Li, C. Shanghai Transport Carbon Emission Forecasting Study Based on CEEMD-IWOA-KELM Model. Sustainability 2024, 16, 8140. https://doi.org/10.3390/su16188140
Gu Y, Li C. Shanghai Transport Carbon Emission Forecasting Study Based on CEEMD-IWOA-KELM Model. Sustainability. 2024; 16(18):8140. https://doi.org/10.3390/su16188140
Chicago/Turabian StyleGu, Yueyang, and Cheng Li. 2024. "Shanghai Transport Carbon Emission Forecasting Study Based on CEEMD-IWOA-KELM Model" Sustainability 16, no. 18: 8140. https://doi.org/10.3390/su16188140
APA StyleGu, Y., & Li, C. (2024). Shanghai Transport Carbon Emission Forecasting Study Based on CEEMD-IWOA-KELM Model. Sustainability, 16(18), 8140. https://doi.org/10.3390/su16188140