
Atmospheric PM2.5 Prediction Model Based on Principal Component Analysis and SSA–SVM

 ,
,
Abstract
1. Introduction
- (1)
- Principal component analysis (PCA) is combined with SSA–SVM to reduce the redundancy of air pollution data and analyse air pollution data. Next, an SVM hyperparameter optimisation algorithm is designed based on the SSA.
- (2)
- The SVM parameter selection is solved using the SSA algorithm. For the SSA, a spread that can change the adjustable operator, ω, is added to enhance the SSA. Next, the improved sparrow search method determines the best SVM parameters. The refined SSA-SVR is better at predicting the amount of pollution in the air. How well does the guess about the gas concentration fit? The prediction results demonstrate how well the proposed model worked at predicting PM2.5 concentrations and improving SVM parameters, confirming its reliability and suitability.
2. Study Area and Data
3. Materials and Methods
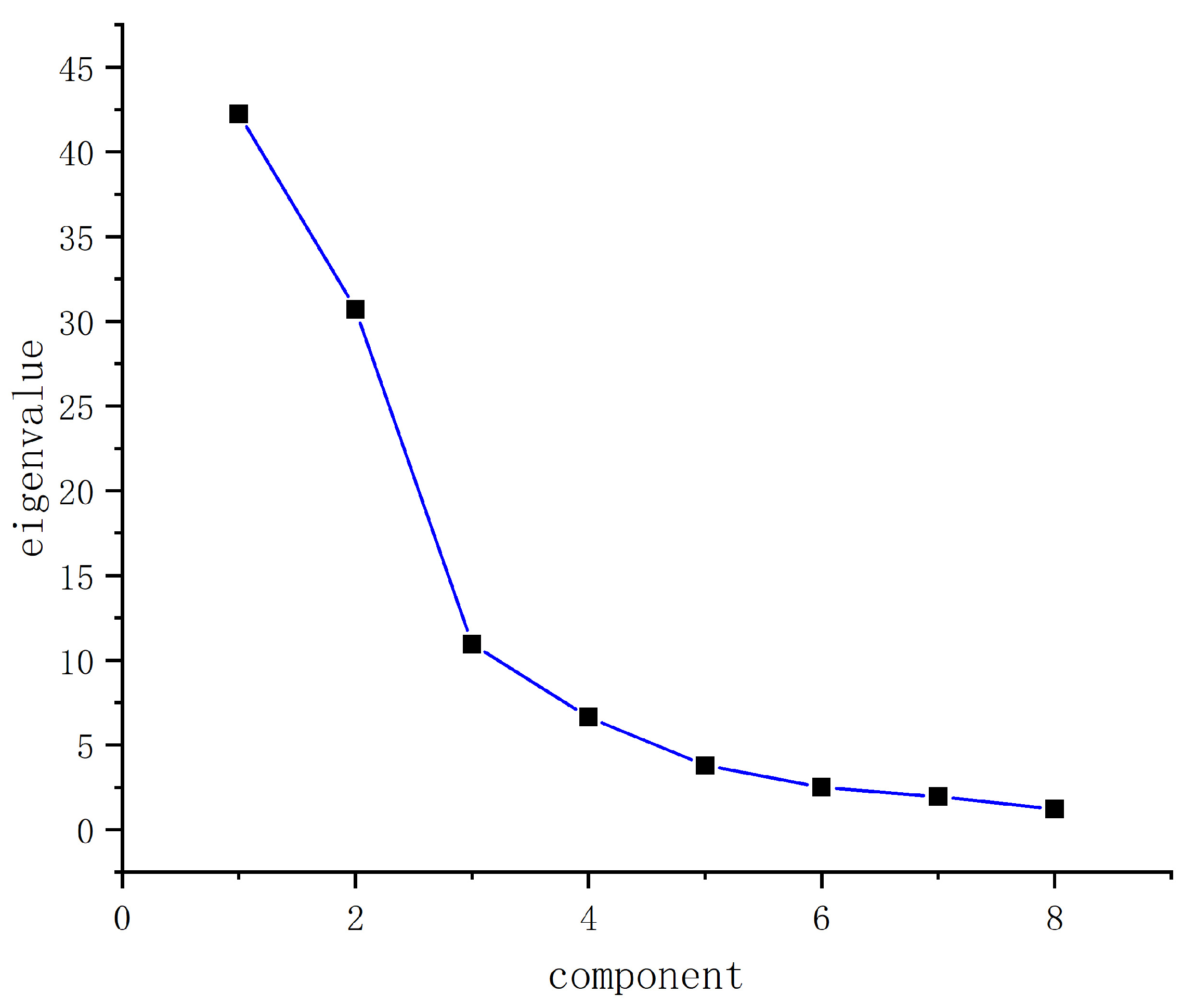
3.1. Principal Component Analysis
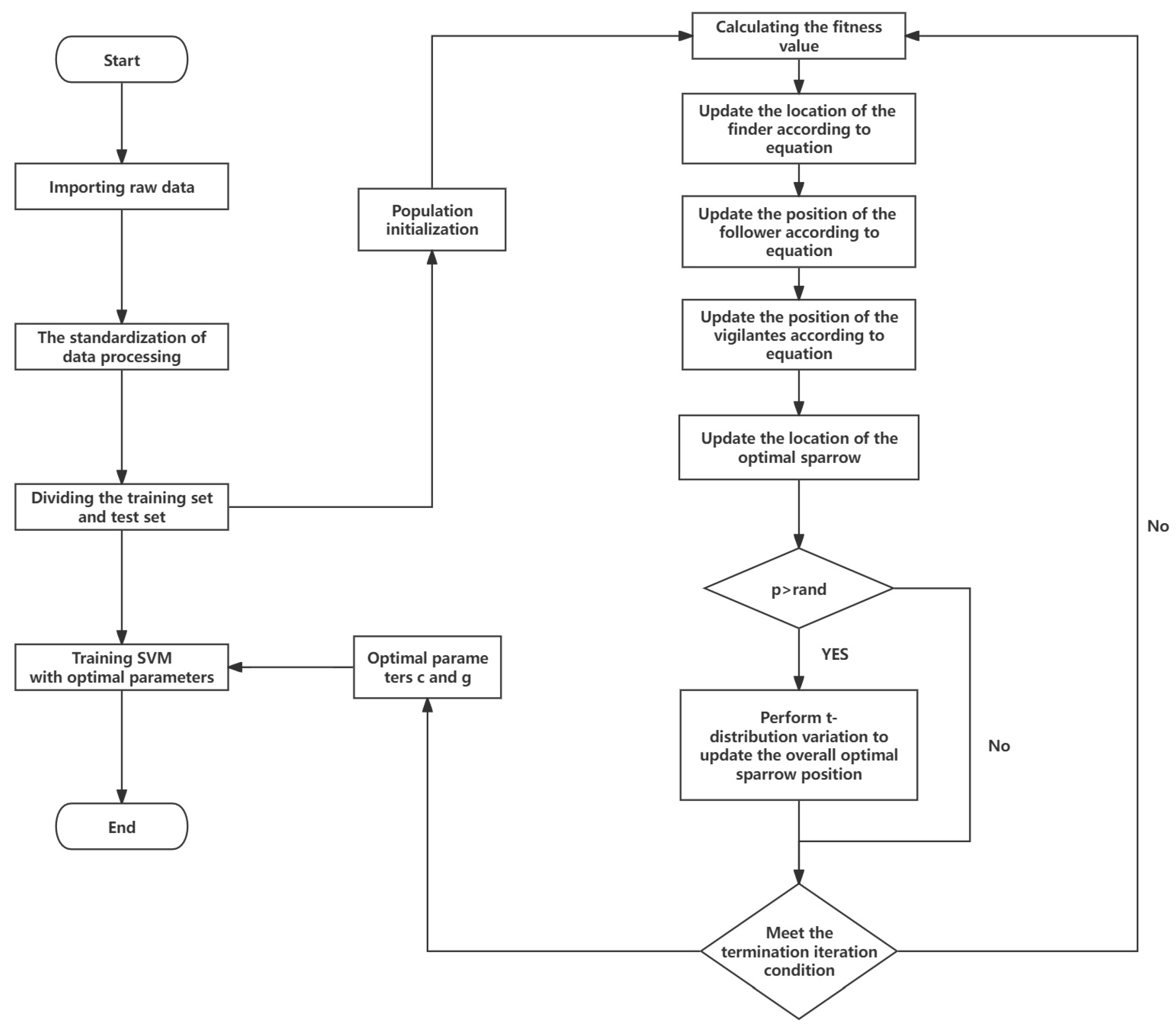
3.2. Building SSA–SVM Prediction Model
3.2.1. Sparrow Search Algorithm
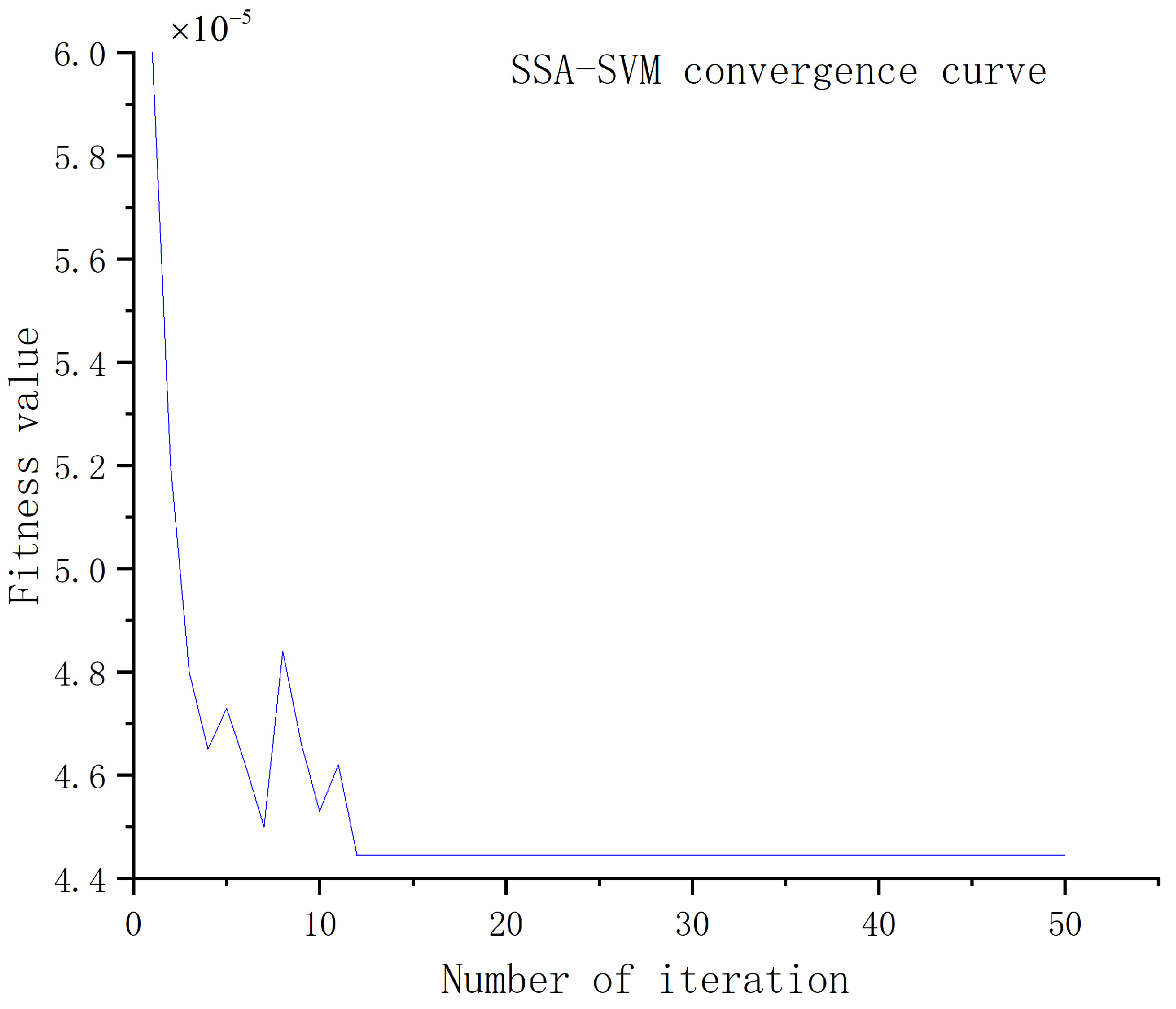
3.2.2. Improved Sparrow Search Algorithm
4. Results
4.1. Evaluation Index
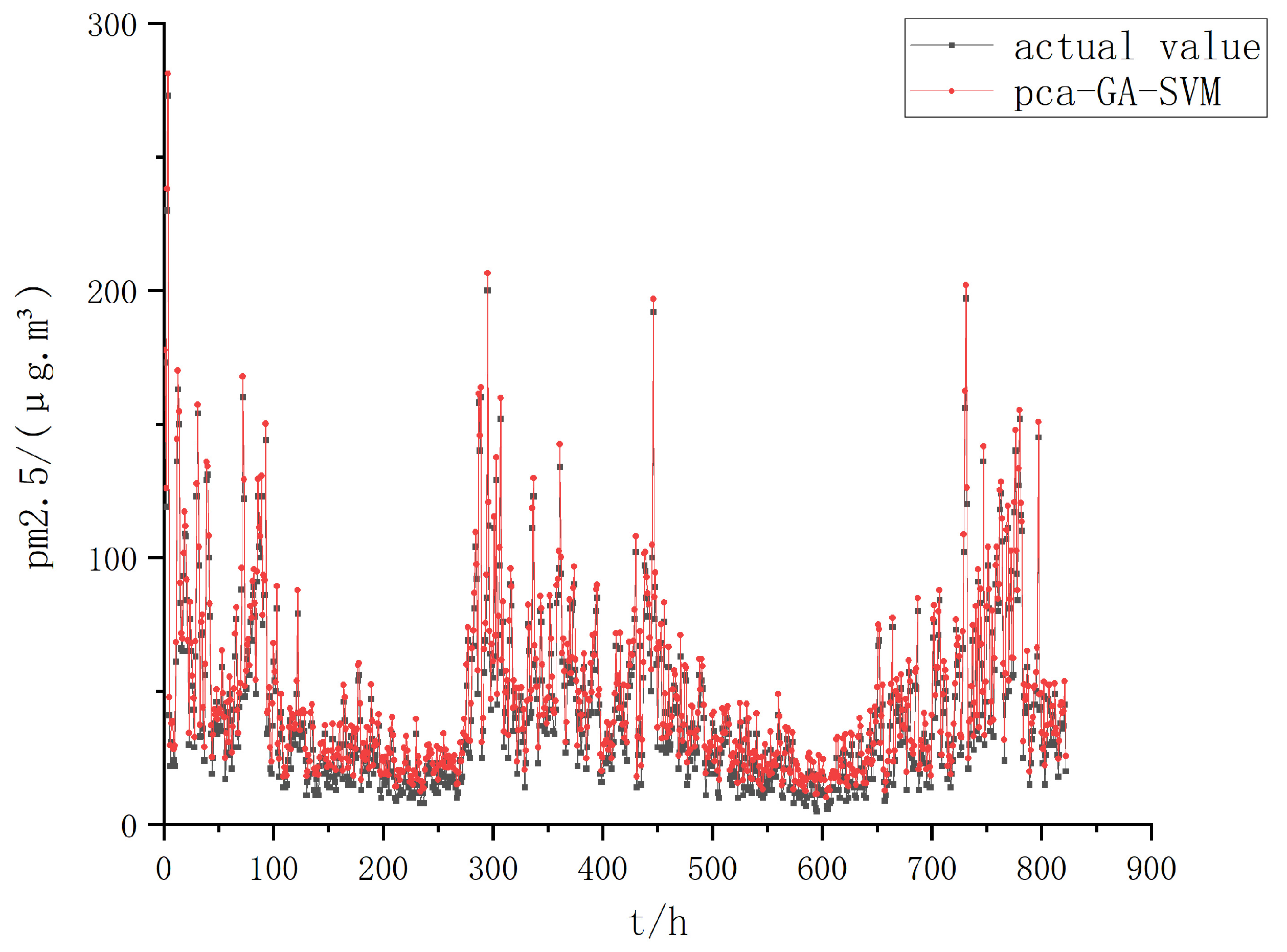
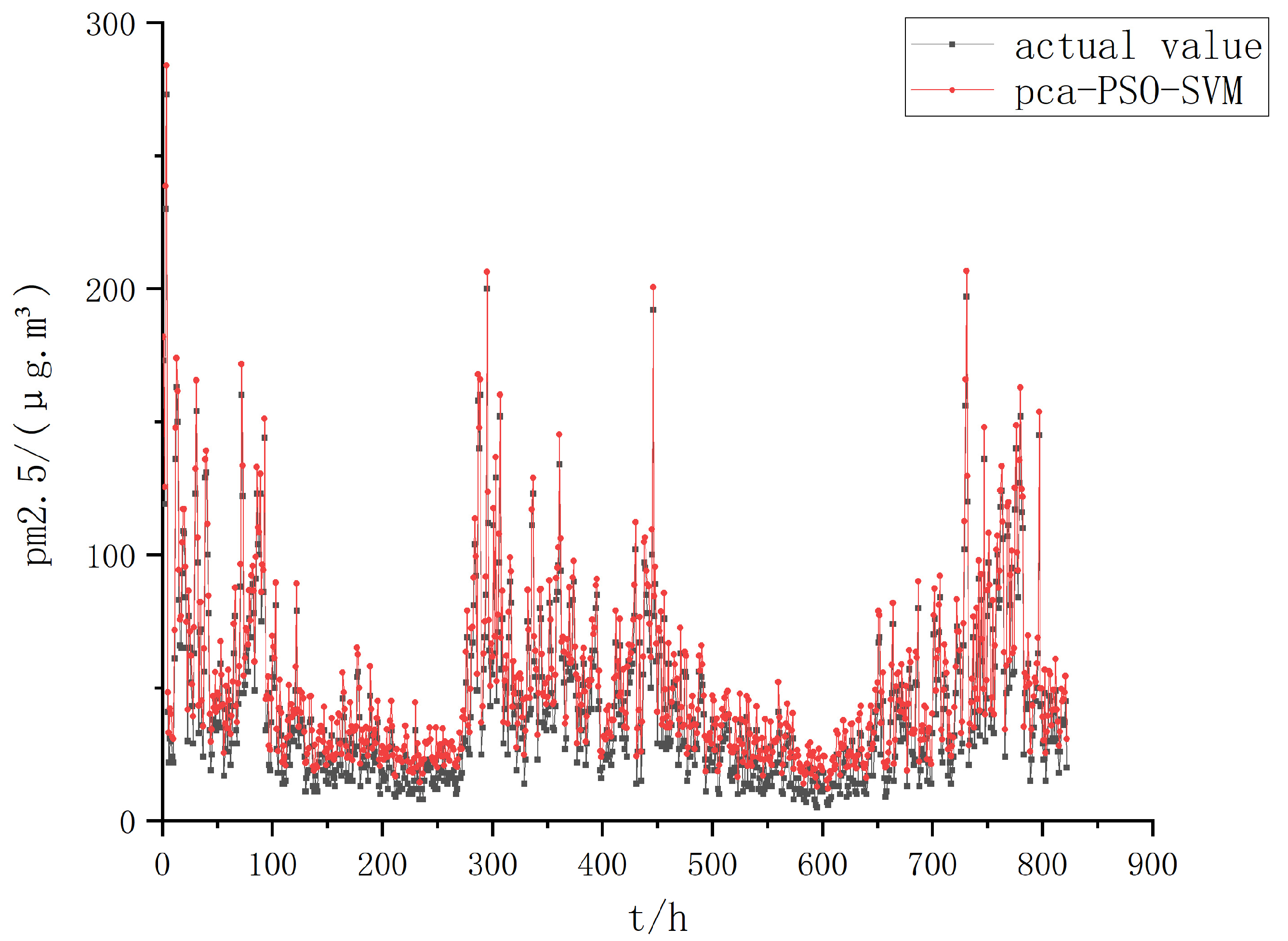
4.2. Comparison of Prediction Results
4.3. Optimised SSA–SVM Compared with Other Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stern, A.C. Air Pollution: The Effects of Air Pollution; Elsevier: Amsterdam, The Netherlands, 1977. [Google Scholar]
- Brunekreef, B.; Holgate, S.T. Air pollution and health. Lancet 2002, 360, 1233–1242. [Google Scholar] [PubMed]
- Chow, J.C. Health effects of fine particulate air pollution: Lines that connect. J. Air Waste Manag. Assoc. 2006, 56, 707–708. [Google Scholar]
- Dominici, F.; Peng, R.D.; Bell, M.L.; Pham, L.; McDermott, A.; Zeger, S.L.; Samet, J.M. Fine particulate air pollution and hospital admission for cardiovascular and respiratory diseases. JAMA 2006, 295, 1127–1134. [Google Scholar] [PubMed]
- Xing, Y.F.; Xu, Y.H.; Shi, M.H.; Lian, Y.X. The impact of PM2.5 on the human respiratory system. J. Thoracic. Dis. 2016, 8, 69. [Google Scholar]
- Brook, R.D.; Rajagopalan, S.; Pope, C.A.; Brook, J.R.; Bhatnagar, A.; Diez-Roux, A.V.; Holguin, F.; Hong, Y.; Luepker, R.V.; Mittleman, M.A.; et al. Particulate matter air pollution and cardiovascular disease: An update to the scientific statement from the american heart association. Circulation 2010, 121, 2331–2378. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A.; Burnett, R.T.; Thun, M.J.; Calle, E.E.; Krewski, D.; Ito, K.; Thurston, G.D. Lung cancer, cardiopulmonary mortality, and long-term exposure to fine particulate air pollution. JAMA 2002, 287, 1132–1141. [Google Scholar] [CrossRef]
- Li, T.; Shen, H.; Zeng, C.; Yuan, Q.; Zhang, L. Point-surface fusion of station measurements and satellite observations for mapping PM2.5 distribution in China: Methods and assessment. Atmos. Environ. 2017, 152, 477–489. [Google Scholar]
- James, D.E.; Chambers, J.A.; Kalma, J.D.; Bridgman, H.A. Air quality prediction in urban and semi-urban regions with generalised input-output analysis: The hunter region, australia. Urban Ecol. 1985, 9, 25–44. [Google Scholar]
- Bruckman, L. Overview of the enhanced geocoded emissions modeling and projection (enhanced gemap) system. In Proceeding of the Air & Waste Management Association’s Regional Photochemical Measurements and Modeling Studies Conference, San Diego, CA, USA, 8–12 November 1993. [Google Scholar]
- Wang, W.; Zhao, S.; Jiao, L.; Taylor, M.; Zhang, B.; Xu, G.; Hou, H. Estimation of PM2.5 concentrations in China using a spatial back propagation neural network. Sci. Rep. 2019, 9, 13788. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Mao, W.; Wang, W.; Jiao, L.; Zhao, S.; Liu, A. Modeling air quality prediction using a deep learning approach: Method optimisation and evaluation. Sustain. Cities Soc. 2020, 65, 102567. [Google Scholar] [CrossRef]
- Geng, G.; Zhang, Q.; Martin, R.V.; van Donkelaar, A.; Huo, H.; Che, H.; Lin, J.; He, K. Estimating long-term PM2.5 concentrations in China using satellite-based aerosol optical depth and a chemical transport model. Remote Sens. Environ. 2015, 166, 262–270. [Google Scholar] [CrossRef]
- Stern, R.; Builtjes, P.; Schaap, M.; Timmermans, R.; Vautard, R.; Hodzic, A.; Memmesheimer, M.; Feldmann, H.; Renner, E.; Wolke, R. A model inter-comparison study focussing on episodes with elevated PM10 concentrations. Atmos. Environ. 2008, 42, 4567–4588. [Google Scholar] [CrossRef]
- Wang, J.; Bai, L.; Wang, S.; Wang, C. Research and application of the hybrid forecasting model based on secondary denoising and multi-objective optimisation for air pollution early warning system. J. Clean. Prod. 2019, 234, 54–70. [Google Scholar] [CrossRef]
- Pan, L.; Sun, B.; Wang, W. City air quality forecasting and impact factors analysis based on grey model. Procedia Eng. 2011, 12, 74–79. [Google Scholar] [CrossRef]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, L. Geographically and temporally weighted neural networks for satellite-based mapping of ground-level PM2.5. ISPRS J. Photogramm. Remote Sens. 2020, 167, 178–188. [Google Scholar]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Lv, B.; Cai, J.; Xu, B.; Bai, Y. Understanding the rising phase of the PM2.5 concentration evolution in large China cities. Sci. Rep. 2017, 7, 46456. [Google Scholar] [CrossRef]
- Gupta, P.; Christopher, S.A. Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: 2. A neural network approach. J. Geophys. Res. Atmos. 2009, 114, 1–14. [Google Scholar]
- Zhang, G.; Lu, H.; Dong, J.; Poslad, S.; Li, R.; Zhang, X.; Rui, X. A framework to predict high-resolution spatiotemporal PM2.5 distributions using a deep-learning model: A case study of Shijiazhuang, China. Remote Sens. 2020, 12, 2825. [Google Scholar]
- Fan, Z.; Zhan, Q.; Yang, C.; Liu, H.; Bilal, M. Estimating PM2.5 concentrations using spatially local Xgboost based on full-covered SARA AOD at the urban scale. Remote Sens. 2020, 12, 3368. [Google Scholar] [CrossRef]
- Shen, H.; Jiang, Y.; Li, T.; Cheng, Q.; Zeng, C.; Zhang, L. Deep learning-based air temperature mapping by fusing remote sensing, station, simulation and socioeconomic data. Remote Sens. Environ. 2020, 240, 111692. [Google Scholar] [CrossRef]
- Wan, R.; Mei, S.; Wang, J.; Liu, M.; Yang, F. Multivariate temporal convolutional network: A deep neural networks approach for multivariate time series forecasting. Electronics 2019, 8, 876. [Google Scholar] [CrossRef]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [PubMed]
- Han, L.; Zhao, J.; Gao, Y.; Gu, Z.; Xin, K.; Zhang, J. Spatial distribution characteristics of PM2.5 and PM10 in Xi’an city predicted by land use regression models. Sustain. Cities Soc. 2020, 61, 102329. [Google Scholar]
- Stadlober, E.; Hörmann, S.; Pfeiler, B. Quality and performance of a PM10 daily forecasting model. Atmos. Environ. 2008, 42, 1098–1109. [Google Scholar] [CrossRef]
- Perez, P.; Reyes, J. An integrated neural network model for PM10 forecasting. Atmos. Environ. 2006, 40, 2845–2851. [Google Scholar] [CrossRef]
- Suárez Sánchez, A.; García Nieto, P.J.; Riesgo Fernández, P.; Del Coz Díaz, J.J.; Iglesias-Rodríguez, F.J. Application of an SVM-based regression model to the air quality study at local scale in the Avilés urban area (Spain). Math. Comput. Model. 2011, 54, 1453–1466. [Google Scholar]
- Gariazzo, C.; Carlino, G.; Silibello, C.; Renzi, M.; Finardi, S.; Pepe, N.; Radice, P.; Forastiere, F.; Michelozzi, P.; Viegi, G.; et al. A multi-city air pollution population exposure study: Combined use of chemical-transport and random-forest models with dynamic population data. Sci. Total Environ. 2020, 724, 138102. [Google Scholar]
- Danesh Yazdi, M.; Kuang, Z.; Dimakopoulou, K.; Barratt, B.; Suel, E.; Amini, H.; Lyapustin, A.; Katsouyanni, K.; Schwartz, J. Predicting fine particulate matter (PM2.5) in the greater London area: An ensemble approach using machine learning methods. Remote Sens. 2020, 12, 914. [Google Scholar] [CrossRef]
- Schneider, R.; Vicedo-Cabrera, A.M.; Sera, F.; Masselot, P.; Stafoggia, M.; de Hoogh, K.; Kloog, I.; Reis, S.; Vieno, M.; Gasparrini, A. A satellite-based spatio-temporal machine learning model to reconstruct daily PM2.5 concentrations across Great Britain. Remote Sens. 2020, 12, 3803. [Google Scholar]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM2.5 forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef] [PubMed]
- Chang-Hoi, H.; Park, I.; Oh, H.; Gim, H.; Hur, S.; Kim, J.; Choi, D. Development of a PM2.5 prediction model using a recurrent neural network algorithm for the Seoul metropolitan area, Republic of Korea. Atmos. Environ. 2021, 245, 118021. [Google Scholar]
- Wu, S.; Feng, Q.; Du, Y.; Li, X.D. Artificial neural network models for daily PM10 air pollution index prediction in the urban area of Wuhan, China. Environ. Eng. Sci. 2011, 28, 357–363. [Google Scholar] [CrossRef]
- Wei, G.; Zhao, J.; Yu, Z.; Feng, Y.; Li, G.; Sun, X. An effective gas sensor array optimisation method based on random forest. In Proceedings of the 2018 IEEE Sensors, New Delhi, India, 28–31 October 2018; pp. 1–4. [Google Scholar]
- Xu, Y.; Zhao, X.; Chen, Y.; Zhao, W. Research on a mixed gas recognition and concentration detection algorithm based on a metal oxide semiconductor olfactory system sensor array. Sensors 2018, 18, 3264. [Google Scholar] [PubMed]
- Boateng, E.Y.; Otoo, J.; Abaye, D.A. Basic tenets of classification algorithms K-nearest-neighbor, support vector machine, random forest and neural network: A review. J. Data Anal. Inf. Process. 2020, 8, 341–357. [Google Scholar]
- Sánchez, V.D.A. Advanced support vector machines and kernel methods. Neurocomputing 2003, 55, 5–20. [Google Scholar] [CrossRef]
- Zhao, X.; Li, P.; Xiao, K.; Meng, X.; Han, L.; Yu, C. Sensor Drift Compensation Based on the Improved LSTM and SVM Multi-Class Ensemble Learning Models. Sensors 2019, 19, 3844. [Google Scholar]
- Tao, Z.; Huiling, L.; Wenwen, W.; Xia, Y. GA–SVM-based feature selection and parameter optimisation in hospitalisation expense modeling. Appl. Soft Comput. 2019, 75, 323–332. [Google Scholar] [CrossRef]
- Huang, S.; Zheng, X.; Ma, L.; Wang, H.; Huang, Q.; Leng, G.; Meng, E.; Guo, Y. Quantitative contribution of climate change and human activities to vegetation cover variations based on GA–SVM model. J. Hydrol. 2020, 584, 124687. [Google Scholar] [CrossRef]
- Cuong-Le, T.; Nghia-Nguyen, T.; Khatir, S.; Trong-Nguyen, P.; Mirjalili, S.; Nguyen, K.D. An efficient approach for damage identification based on improved machine learning using PSO–SVM. Eng. Comput. 2022, 38, 3069–3084. [Google Scholar]
- Zhang, L.; Shi, B.; Zhu, H.; Yu, X.B.; Han, H.; Fan, X. PSO–SVM-based deep displacement prediction of Majiagou landslide considering the deformation hysteresis effect. Landslides 2021, 18, 179–193. [Google Scholar] [CrossRef]
- Pan, M.; Li, C.; Gao, R.; Huang, Y.; You, H.; Gu, T.; Qin, F. Photovoltaic power forecasting based on a support vector machine with improved ant colony optimisation. J. Clean. Prod. 2020, 277, 123948. [Google Scholar] [CrossRef]
- Lewis, M. A The whale optimisation algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar]
- Xue, J.K.; Shen, B. A novel swarm intelligence optimisation approach: Sparrow search algorithm. Syst. Sci. Control. Eng. 2020, 8, 22–34. [Google Scholar]
- Ye, Y.B.; Li, R.C.; Xie, M.; Wang, Z.; Ba, Q. A state evaluation method for a relay protection device based on SSA–SVM. Power Syst. Prot. Control. 2022, 50, 171–178. (In Chinese) [Google Scholar]
- Yu, S.; Hu, D.; Tang, C.; Zhang, C.; Tang, W. MSSA-SVM Transformer Fault Diagnosis Method Based on TLR-ADASYN Balanced Data Set. High Volt. Eng. 2021, 47, 3845–3853. (In Chinese) [Google Scholar]
- Song, J.; Cong, Q.M.; Yang, S.S.; Yang, J. Improved sparrow search algorithm for water quality prediction in RBF neural networks. Comput. Syst. 2023, 4, 255–261. [Google Scholar]
- Li, N.; Xue, J.K.; Shu, H.S. UA V trajectory planning based on adaptive t-distribution variational sparrow search algorithm. J. Donghua Univ. (Nat. Sci. Ed.) 2022, 48, 69–74. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Number | Eigenvalue | Contribution Rate | Accumulated Contribution Rate |
|---|---|---|---|---|
| PM2.5 | 1 | 42.236 | 42.236 | 42.236 |
| PM10 | 2 | 30.720 | 30.720 | 72.956 |
| SO2 | 3 | 10.945 | 10.945 | 83.901 |
| NO2 | 4 | 6.633 | 6.632 | 90.533 |
| NO | 5 | 3.797 | 3.798 | 94.331 |
| O3 | 6 | 2.502 | 2.501 | 96.832 |
| Temperature | 7 | 1.947 | 1.947 | 98.779 |
| Relative humidity | 8 | 1.221 | 1.221 | 100.000 |
| Variable | X1 | X2 | X3 | X4 |
|---|---|---|---|---|
| PM2.5 | 0.876 | 0.294 | 0.059 | −0.135 |
| PM10 | 0.908 | −0.121 | 0.103 | –0.003 |
| SO2 | 0.121 | 0.848 | 0.037 | 0.871 |
| NO2 | 0.600 | 0.560 | −0.435 | −0.053 |
| NO | 0.634 | 0.146 | −0.042 | −0.025 |
| O3 | 0.499 | −0.547 | 0.763 | 0.342 |
| Temperature | 0.534 | −0.749 | −0.128 | −0.150 |
| Relative humidity | 0.074 | 0.665 | 0.611 | 0.382 |
| Modelling Methods | MAE | RMSE | R² | Time/s |
|---|---|---|---|---|
| Full-PLS | 6.25 | 8.14 | 0.9306 | 6.1321 |
| PCA–PLS | 1.86 | 3.76 | 0.9598 | 5.7554 |
| Full-SVM | 0.843 | 1.054 | 0.9286 | 4.2311 |
| PCA–SVM | 0.339 | 0.401 | 0.9571 | 3.9871 |
| Full–GA–SVM | 2.65 | 2.97 | 0.9621 | 16.3269 |
| PCA–GA–SVM | 2.028 | 1.53 | 0.9798 | 13.1432 |
| Full–PSO–SVM | 7.48 | 8.84 | 0.9369 | 13.2411 |
| PCA–PSO–SVM | 2.221 | 3.16 | 0.9649 | 10.2311 |
| Full–SSA–SVM | 0.59 | 0.92 | 0.9889 | 6.0569 |
| PCA–SSA–SVM | 0.084 | 0.11 | 0.9996 | 4.1121 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, H.; Guo, J.; Mu, Y.; Guo, Y.; Hu, T.; Li, S.; Luo, T.; Sun, Y. Atmospheric PM2.5 Prediction Model Based on Principal Component Analysis and SSA–SVM. Sustainability 2024, 16, 832. https://doi.org/10.3390/su16020832
Gong H, Guo J, Mu Y, Guo Y, Hu T, Li S, Luo T, Sun Y. Atmospheric PM2.5 Prediction Model Based on Principal Component Analysis and SSA–SVM. Sustainability. 2024; 16(2):832. https://doi.org/10.3390/su16020832
Chicago/Turabian StyleGong, He, Jie Guo, Ye Mu, Ying Guo, Tianli Hu, Shijun Li, Tianye Luo, and Yu Sun. 2024. "Atmospheric PM2.5 Prediction Model Based on Principal Component Analysis and SSA–SVM" Sustainability 16, no. 2: 832. https://doi.org/10.3390/su16020832
APA StyleGong, H., Guo, J., Mu, Y., Guo, Y., Hu, T., Li, S., Luo, T., & Sun, Y. (2024). Atmospheric PM2.5 Prediction Model Based on Principal Component Analysis and SSA–SVM. Sustainability, 16(2), 832. https://doi.org/10.3390/su16020832