1. Introduction
A scientific understanding of land use change and urban expansion is required for policy makers to strategize and facilitate sustainable urbanization development. Land use change is influenced by the interaction of many driving forces, including demographic change, socio-economic development, natural factors, human behavior and government policies [
1,
2]. In this context, urban growth simulations have made an indispensably significant contribution towards facilitating sustainable development by urban planners, decision makers, economists and ecologists. Over the past several decades, a great deal of literature has focused on realizing the interactions between land use change and its driving forces using land use models. These include statistical approaches [
3,
4], system dynamics models [
5], conceptual models [
6], Markov chain [
7,
8], agent-based models [
9], cellular automata (CA) approaches and the integration of these methods [
10,
11].
CA models simulate and predict a spatial-temporal and nonlinear dynamic system by defining simple local transition rules. The CA models have been shown to be powerful and popular land use change simulation tools [
12,
13]. The CA model was first applied to simulate and explore urban growth in Detroit (Tobler 1970) [
14]. Since then, CA models have been widely utilized in research on land use change and urban expansion simulation [
15,
16,
17,
18,
19,
20,
21,
22,
23]. However, it remains a significant challenge to specify the transition rules of CA. The objective of CA calibration is to obtain the best transition rules that allow for the most accurate simulated results [
23,
24]. Consequently, it is crucial to properly calibrate CA parameters to acquire more precise land use change results.
So far, a large number of methods has been developed to calibrate CA parameters. Some authors used the SLEUTH urban growth model developed by Clarke based on the cellular automata to simulate urban expansion [
16,
17,
25,
26]. However, the input layers of the SLEUTH model are slope, land use/land cover, excluded zones, urban areas, transportation network and hillshading, which do not consider population change and socio-economic development. Furthermore, while the five variable parameters of the SLEUTH independently range from 0–100, there are too many combinations that can influence model performance. Wu (1998) [
27], Wu and Webster (1998) [
28] defined a multi-criteria evaluation (MCE) method based on the analytic hierarchy process (AHP) to obtain transition rules. Specifically, whether a cell developed or not was determined by the comprehensive evaluation of various spatial variables. Nonetheless, CA calibration with MCE is highly affected by the subjective parameter setting. Therefore, a number of studies proposed a CA model based on logistic regression to deal with multi-factor problems [
29,
30]. However, logistic regression is more likely to overfit and has difficulty effectively determining the complex relationships among variables. Consequently, artificial intelligence, machine learning techniques (e.g., support vector machine) and global intelligent optimization algorithms were introduced into CA parameter calibration [
22,
31,
32,
33].
Li and Yeh (2002) [
18] first integrated artificial neural networks (ANNs) with CA models to simulate land use change. They demonstrated that the ANN-based CA (ANN-CA) model can be successfully applied to land use change and urban expansion simulations, due to ANNs’ strong self-adaptiveness, self-organization and ability to learn and mimic complex nonlinear problems [
2,
19,
21,
32,
34]. However, the conventional ANNs are weak in global searching and fall more easily into local optima. Hence, improving conventional ANNs or developing a new method to be coupled with the CA might offer better simulation precision.
In the past decade, deep learning has shown great success with speech recognition and image classification [
35,
36,
37]. As one of the dominant methods of deep learning, the deep belief network (DBN) has excellent feature detection abilities. When compared to the conventional ANNs, the DBN is more capable of interpreting complex mathematical models, due to a number of hidden layers for the feature detection [
38,
39,
40]. Furthermore, it is much easier to express the non-linear, complex structures of the data in deep hidden layers. There is a fast, greedy, unsupervised learning algorithm that can initialize the weights of conventional ANN. DBN and ANN both employ a machine learning approach, which is not dependent on fixed functional relationships and is able to handle complex non-linear functions without any a priori knowledge of variable relationships [
21,
41]. Thus, the DBN overcomes ANN’s local convergence problem effectively. However, so far, only a few studies have combined DBN with the CA model to simulate land use change or urban growth.
Typical studies in urban growth used remote sensing and GIS techniques [
2,
27,
41,
42] and utilized three phases during model implementation: calibration, validation and prediction. Alsharif and Pradhan used a logistic regression model in the calibration phase from 1984–2002, validation from 2002–2010 and prediction for 2020 and 2025 for Tripoli, Libya [
43]. Grekousis, Manetos and Photis integrated the ANN and fuzzy logic with GIS to calibrate, validate and predict urban growth for the Athens metropolitan area [
41]. The ANN model in conjunction with other methods was also used to simulate urban growth including both calibration and validation [
44,
45,
46]. Berberoğlu, Akın and Clarke compared urban modeling approaches, including logistic regression, regression tree, ANN and SLEUTH, to forecast the urban growth, and two calibration and prediction phases of these models were performed [
47]. Riccioli utilized CA and Markov chains to examine the land use changes from 1990–2000, and it was validated for 2006 [
48].
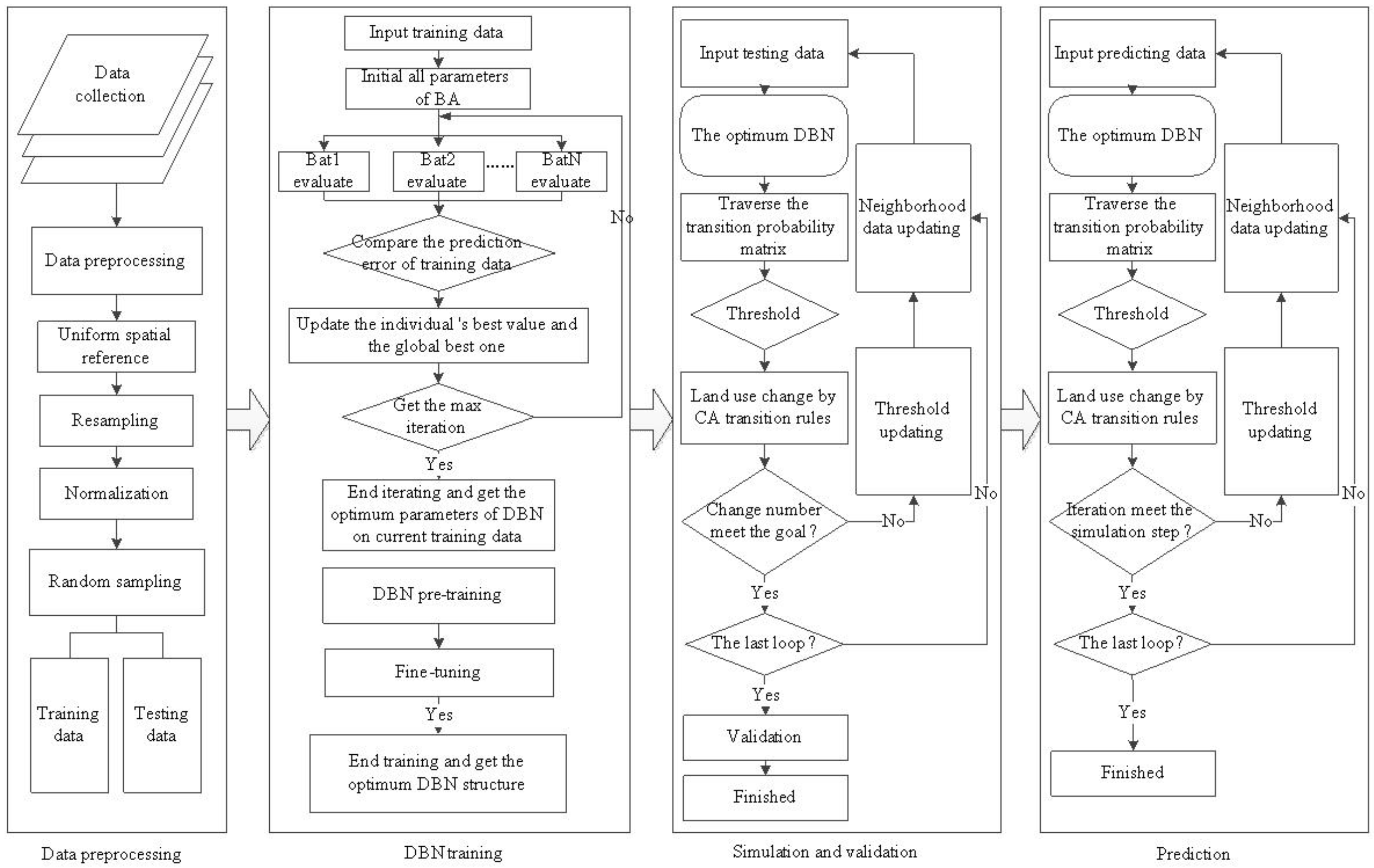
In this context, our research aims to propose a DBN-based CA (DBN-CA) model to simulate the spatial-temporal changes in non-urban land use, while the metaheuristic bat algorithm (BA) developed by Yang (2010) [
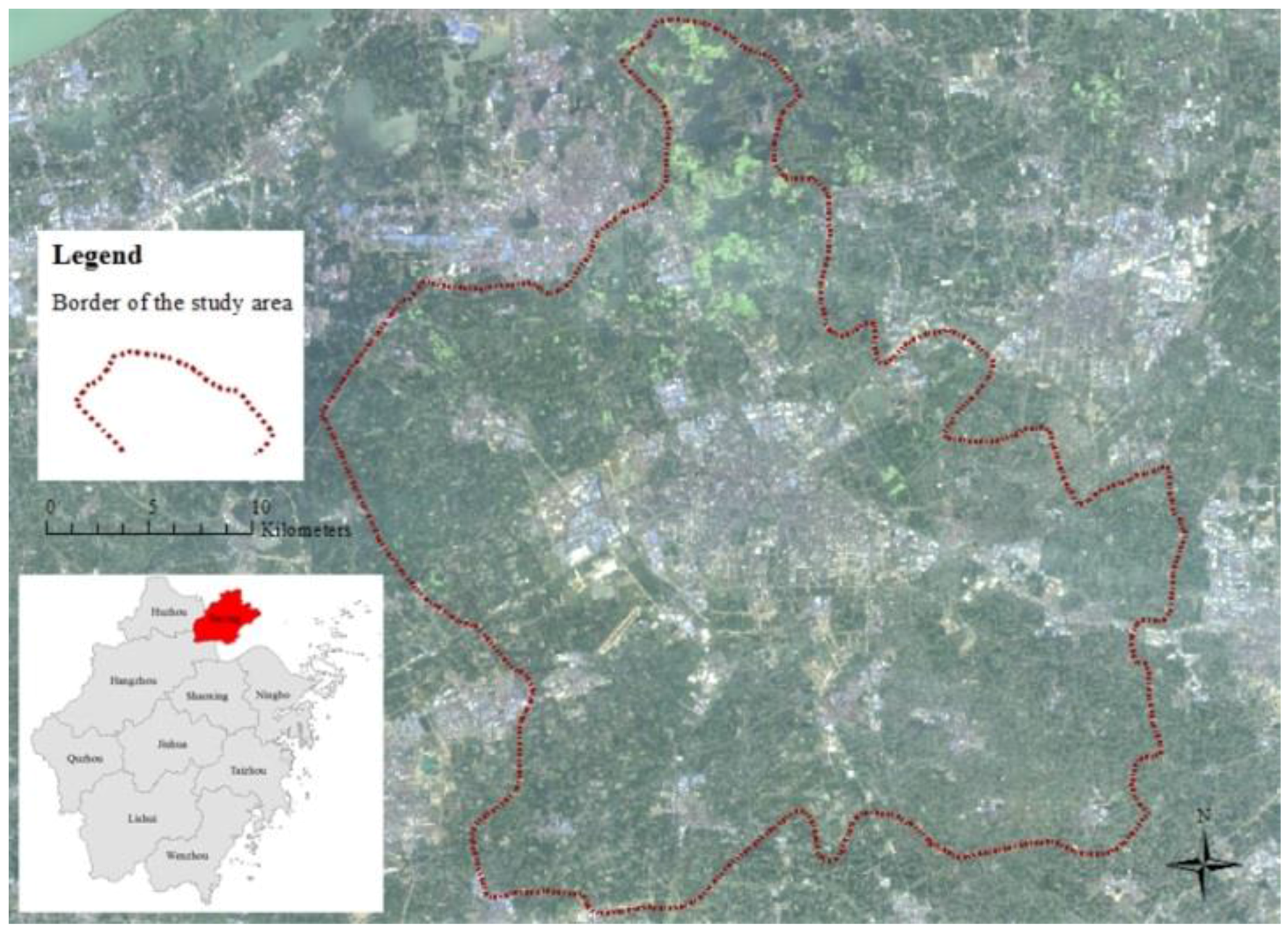
49] is proposed to obtain the best structure of the DBN, and the DBN training is used to achieve the best transition rules of non-urban change. The DBN-CA model involving data processing, DBN calibration, model validation and prediction is tested using a case study of urban growth for Jiaxing City, Zhejiang Province, China, in 2000, 2008, 2015 and 2024. We compare it to the ANN-based CA (ANN-CA) and demonstrate the effective simulation ability of the DBN-CA for the study area.
This paper is organized into five sections. The next section gives an introduction to the CA framework, the BA and DBN models and the framework of DBN-CA.
Section 3 describes the study area and data.
Section 4 describes the model implementation and discusses the results. Finally,
Section 5 gives the major conclusions.
4. Implementation, Results and Discussion
4.1. Model Implementation
The ANN-CA and DBN-CA models were developed to simulate the urban growth of Jiaxing City based on the land use data from 2000, 2008 and 2015 along with other global driving forces, including topographic, zoning suitability, distance and neighborhood data. The difference between these two models is that the DBN-CA uses the DBN model to obtain the optimized transition rules, while the ANN-CA uses the ANN model. We describe only the DBN as follows.
As shown in
Figure 7, the initial year was 2000. Five thousand cells from 2000–2008 were selected by a stratified sampling method to serve as training data, while the ratio of developed/undeveloped cells in this sample was 2–3. Spatial variables including DEM, slope, Diswater, Disrailway, Disroad, Distown, Discounty, non-urban neighborhoods, urban neighborhoods and zoning suitability data were all used in the training, validation and prediction phases. Furthermore, the 2008–2015 validation process was used as an accuracy test, in which the majority of variables were calculated from the 2008 land use map and some from 2009; while in the 2015–2024 prediction phase, the 2015 land use map was considered as the fundamental image, in which zoning data were from 2015.
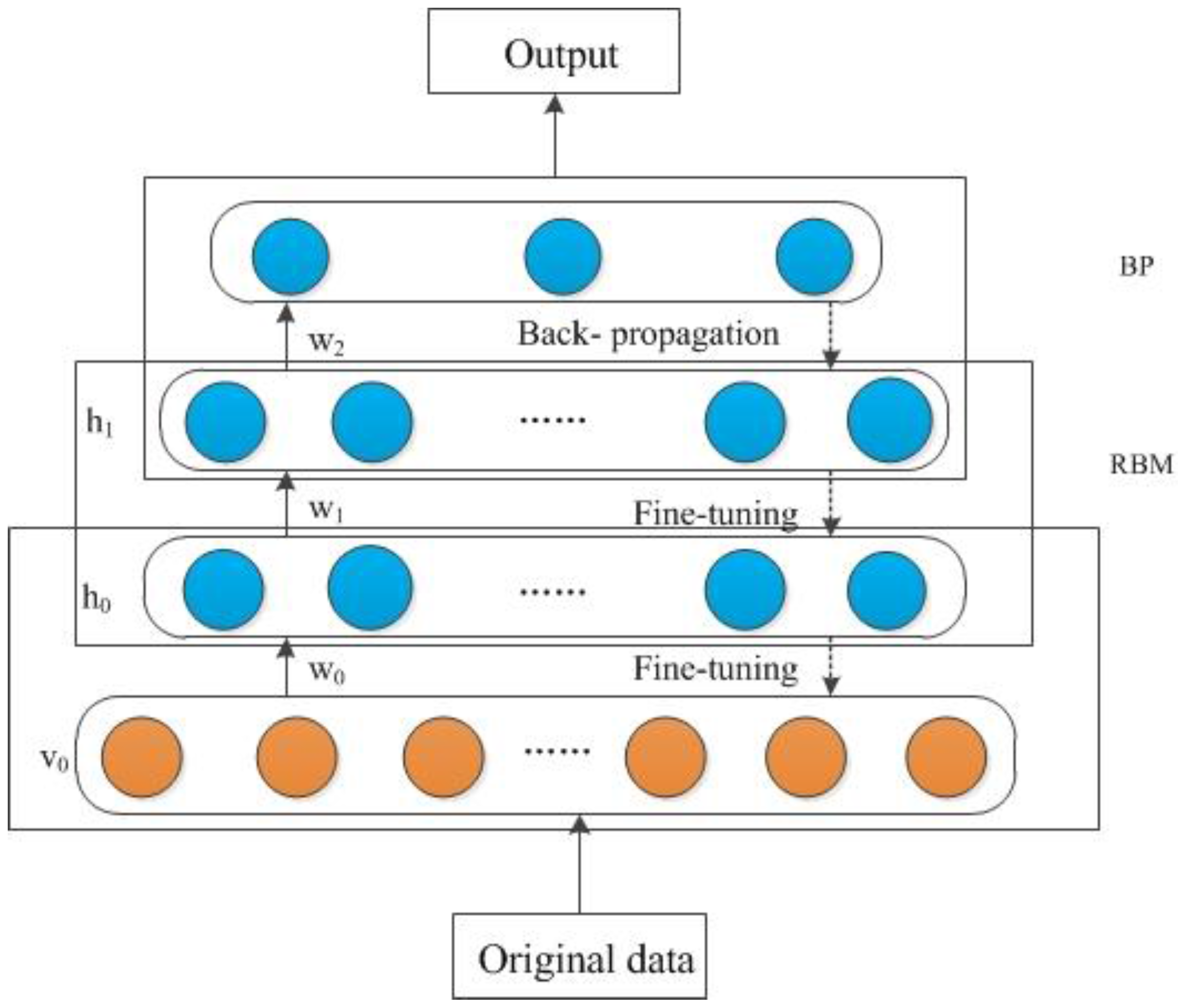
The architecture of the DBN-CA model is shown in
Figure 3. First, the experimental data were converted to the same spatial reference (WGS_84_UTM_Zone_50N coordinate) and the same resolution (30 × 30 m). We performed experiments based on the DBN-CA model using the linear (Equation (7)) and the sigmoidal (Equation (8)) normalization methods, which normalized the data into [0,1] respectively:
where
is the minimum and
is the maximum value of each variable. There were a total of 1,098,913 cells in the whole study area.
The simulation results of the experiments demonstrated that the linear normalization method is better than that of the sigmoidal normalization, since the linear normalization with a 78.366% kappa coefficient performs better than the sigmoidal one (with a 76.640% kappa coefficient). Therefore, the linear normalization method that is also commonly used in the literature [
48,
53] was adopted in this paper.
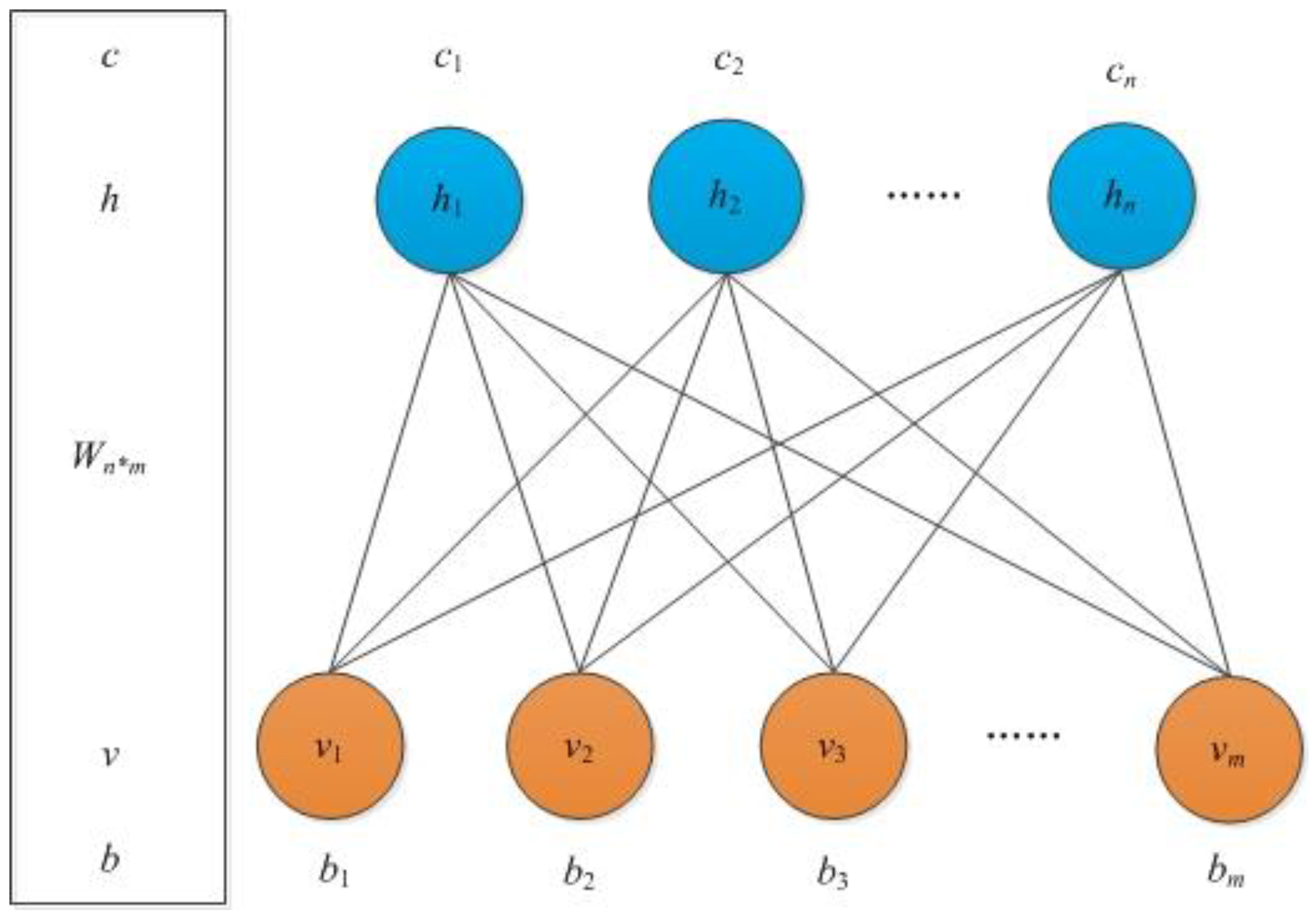
The second phase is DBN training, which aims to find the best DBN structure using the linear normalized training data. In this paper, we only discuss two RBM layers of DBN pre-training. The bat algorithm was performed to find the best architecture of DBN with training data. To implement the bat algorithm, we randomly initialized 40 bats (40 groups of RBM parameters, including the number of hidden units, learning rate, sparsity and dropout). The maximal and minimal pulse rates, loudness and frequency are 1 and 0, 2 and 1, 1.5 and 0, respectively. In addition, the fitness function (Equation (9)) can be calculated as the accumulated errors between the simulated probability and the observations of training data by DBN. The process was stopped when it reached 200 iterations.
where
is the number of training data,
is 1 if the predicted probability by DBN is larger than the threshold, otherwise it is 0.
is the observation of the current cell. Otherwise, the learning rate of the fine-tuning phase was 0.01.
According to the above model parameters, we got the best fitness value of 1035 at the 55th iteration (
Figure 8). The numbers of hidden units for the two RBM layers were 12 and 15; the learning rates were 0.016 and 0.069; and the sparsity and dropout were 0.0053 and 0.0016, respectively. Then, the DBN training module was used to obtain the optimum weights and bias of the CA parameters using RBM pre-training and BP fine-tuning. The DBN contains ten inputs (i.e., global variables and neighborhood variables mentioned before) and one output (one or zero, corresponding to non-urban developed into urban and non-urban undeveloped, respectively). The parameters of DBN were discussed in the BA module, and the number of iterations of each RBM was 50. The loop termination criterion considered both the maximum number of iterations and the accuracy of the model.
Third, the simulation and validation module was designed to obtain the transition probability matrix by predicting the testing data using the trained DBN, which was given in the DBN training module. In this research, we set the initial threshold at 0.8. The CA transition rules were defined as follows. First, the transition probability matrix was traversed to estimate if the transition probability is bigger than and if the land use type changed from non-urban to urban in current cell ij. If it did not, it remained non-urban. Second, the neighborhood data were updated after each iteration, and the threshold was decreased by 0.002 if the total number of cells in the urban growth number was less than 100. The loop was repeated until the number of simulated urban units was almost identical to the observed data. Finally, a cell-by-cell comparison method was used to obtain the confusion matrix and kappa coefficient between the simulated map and the observed map, which was built to evaluate the result. In this paper, while calculating the kappa coefficient and confusion matrix, water was incorporated into the non-urban category.
The prediction phase was repeated as the third phase. It stopped once it reached the maximum iteration gained in the previous stage, and there was no validation.
The ANN and DBN training module and all the models’ simulation and validation were implemented using MATLAB software.
4.2. Analysis of the Observed Data
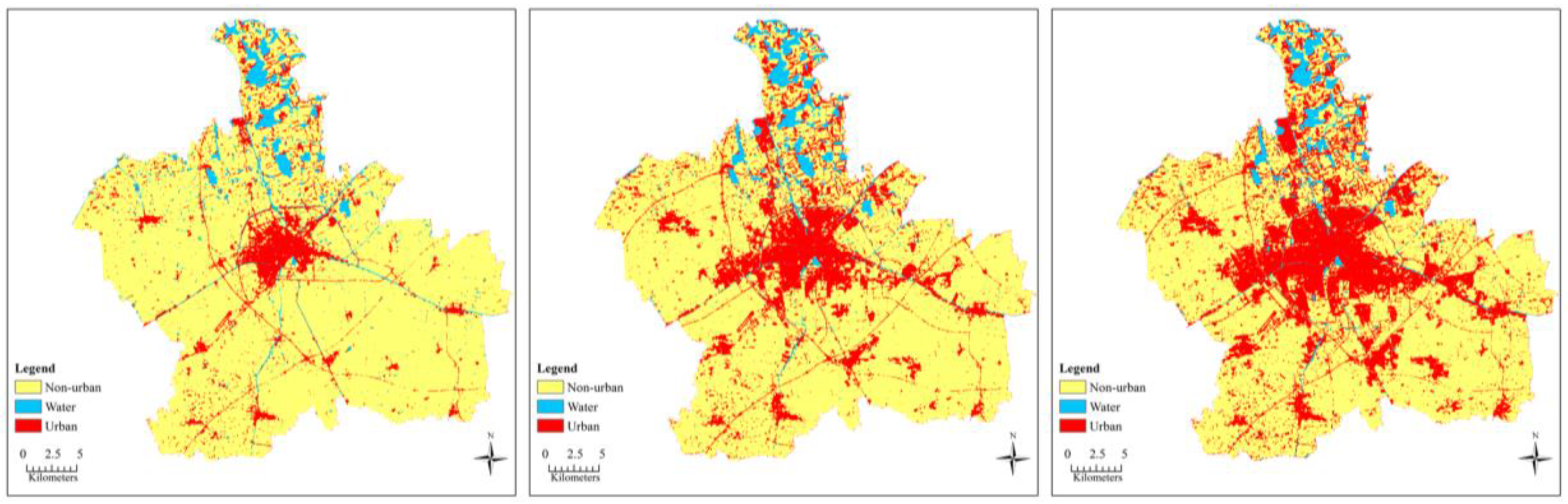
Tremendous non-urban areas were converted into urban areas between 2000 and 2015. Concurrently, water was relatively stable.
Table 2 summarizes the land use type cells, percentages, gains and losses for the three time periods in Jiaxing City: 2000–2008, 2008–2015 and 2000–2015. In the period from 2000–2008, 106,014 non-urban cells (equivalent to 9541.26 ha, 9.647% of the total number of cells) and 1668 cells (equivalent to 150.12 hectares, 0.151% of the total number of cells) of water were transformed to urban use. Urban land increased by 8.845% (8747.73 hectares) from 2008 –2015. Jiaxing City rapidly developed between 2000 and 2015, as the urban land increased by 18.643% of the total number of cells, and almost all of them (17,975.61 hectares) were derived from non-urban cells.
4.3. A Comparison of the Simulation Results between DBN-CA and ANN-CA
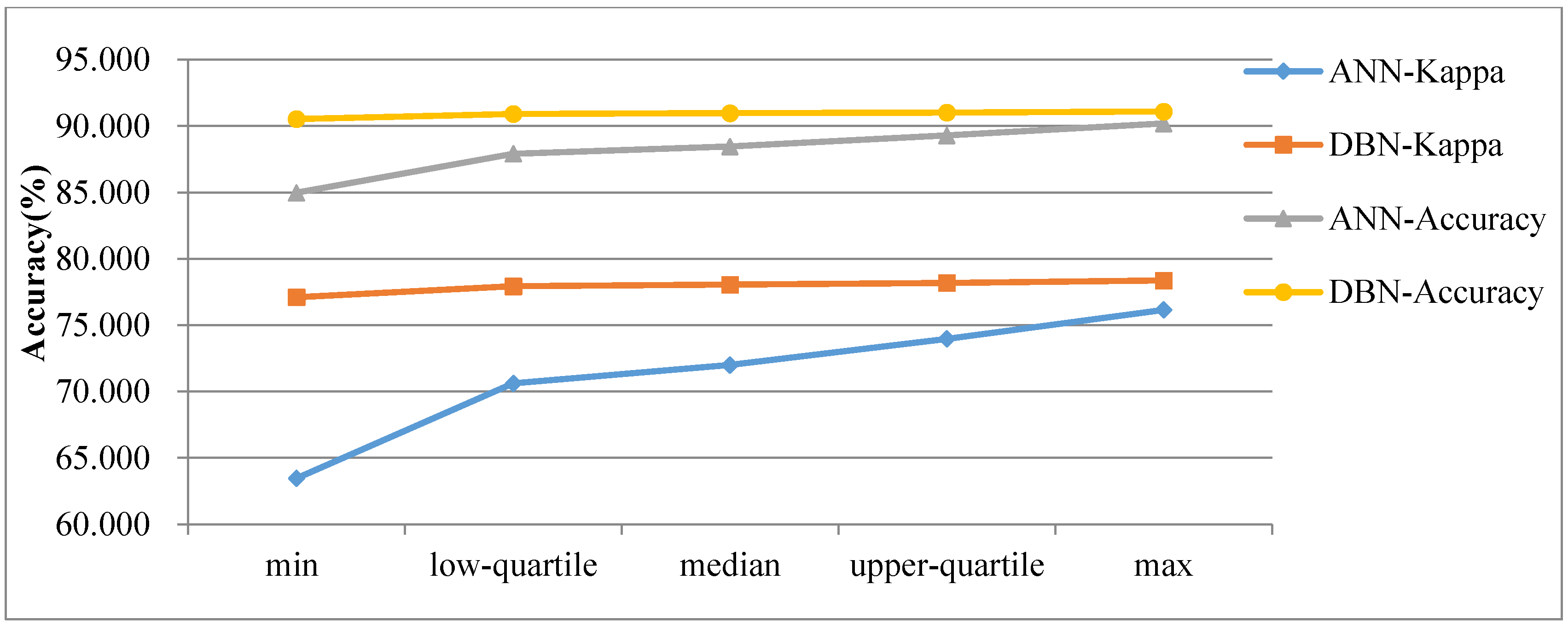
To reduce the error caused by random initialization in the weights and biases of ANN, we repeated the process 200 times to test the ANN-CA. Additionally, after obtaining the optimum structure of DBN using BA, we conducted 200 tests on the DBN-CA. Exploratory data analysis methods were used to explore the five-number summary of the ANN-CA and DBN-CA simulation results, including the minimum, maximum, median, upper quartile and lower quartile values of the kappa coefficient and overall accuracy of these two models over the 200 experiments (
Figure 9). The minimum kappa coefficient of the DBN-CA and ANN-CA was 63.460% and 77.109%, respectively, while the maximum of the DBN-CA was 78.366%, almost 2.215% larger than the value for the ANN-CA. The lower-quartile, median and upper-quartile kappa coefficient of the proposed model and compared model were 77.931%, 78.050% and 78.187% and 70.610%, 72.001% and 73.966%, respectively. The overall accuracy values from the five-number summary of the DBN-CA and ANN-CA were 90.533%, 90.916%, 90.971%, 91.019% and 91.100% and 84.971%, 87.913%, 88.457%, 89.294% and 90.191%, respectively.
From the data summarized in
Figure 9, we see that the simulation results of the proposed model are much more stable than those obtained using the ANN-CA model, since the difference between the minimum and maximum values of overall accuracy and kappa coefficient were 0.567% and 1.257%, while the ANN-CA’s values were 5.220% and 12.691%, respectively. Furthermore, the DBN-CA model has, on average, a higher accuracy and kappa coefficient than the ANN-CA.
We have performed a general analysis of the 200 tests’ simulation results for the DBN-CA and ANN-CA models using the five-number summary approach above. Next, we chose the best results of these two models to compare and analyze.
Table 3 summarizes the simulated data on land use types obtained using the DBN-CA and ANN-CA models for the research area in 2015. Compared with the observed datasets, the simulation errors compared with the observed values for the non-urban, water and urban areas using the DBN-CA model were 0.564%, 7.663% and 0.209%, respectively, while the errors of the ANN-CA model simulation results were 0.523%, 7.663% and 0.115%, respectively. For the whole study area, we obtained the average error of 2.812% in the DBN-CA and 2.767% in the ANN-CA model respectively, which were acceptable. However, we need further analysis since the high precision of the whole area might not lead to the high simulation accuracy of the models due to contingencies.
Figure 10 provides the best simulation maps and error maps of the DBN-CA and ANN-CA over 200 trails. The two models’ simulation results showed a consistent trend of expansion from the city center to outlying areas. The dense population at the city center and its convenient transportation directly led to the rapid expansion of the downtown area from 2000–2015.
Furthermore, the confusion matrix tables between the simulated results and the observed data permit us to evaluate the precision of the DBN-CA and ANN-CA models (
Table 4 and
Table 5). In the DBN-CA model, the correct simulated number of non-urban areas (including water) reaches 731,808 cells, while the urban land area reaches 269,292 cells.
Table 4 shows that the correct simulated numbers of non-urban (including water) and urban areas are 726,966 cells and 264,151 cells, respectively, which were observed in the ANN-CA model. In addition, the simulation results were good for the ANN-CA and DBN-CA since the kappa coefficients for these two models were greater than 75% and the overall accuracies were higher than 90%. However, the DBN-CA with a 78.366% kappa coefficient performed much better on the urban expansion simulation than the ANN-CA with a 76.151% kappa coefficient since the kappa coefficient was 2.215% higher.
Rapid urban expansion has brought a series of ecological and resource problems to the study area, so an effective approach to simulate urban growth can provide strong support for ecological protection and urban planning. Although the DBN-CA cannot perfectly reproduce the real world, it has been shown that DBN is more capable and stable in mining the transition rules than the ANN in Jiaxing City during 2000–2015.
4.4. Prediction
After simulation and validation, in order to estimate the non-urban loss during urbanization in the next decade, we predicted urban expansion for the year 2024. As we demonstrated that the DBN-CA model was more stable and had better performance than the ANN-CA model in 2015, it was used to simulate urban expansion based on the 2015 land use map and other global or constraint variables, as well as the 7 × 7 window Moore neighborhoods.
Figure 11 shows the potential non-urban areas that were more likely to be converted into urban land in 2024. According to the statistics, there will be almost 8946.36 hectares (13.513%) of non-urban land that may be lost over the next ten years, and these are located along the border of each town. The results also showed the outward expansion trend of Jiaxing City.
5. Conclusions
This paper made a brief quantitative analysis of non-urban land conversion of Jiaxing City in Zhejiang Province from 2000–2015. The historical data showed that 18.175% of the non-urban land was converted to urban areas, and the urban areas had increased from 10.282%–28.925%. Furthermore, an integrated model by associating the bat algorithm, the deep belief network, cellular automata and GIS was developed to model non-urban land use changes and understand the processes of urban growth. The DBN-CA model framework was proposed, which included spatial data processing, DBN training, urban growth simulation, validation and effective prediction. The DBN-CA model framework with high simulation precision and strong self-adaptive ability was built for the public.
This paper obtained the urban growth transition rules from 2000–2008 in Jiaxing City based on the bat algorithm, unsupervised learning (pre-training) and the supervised learning (BP fine-tuning) of DBN. Land use from 2008–2015 was used to simulate and validate the optimum DBN structure. To reduce the random error of the models, 200 iterations of the DBN-CA and ANN-CA model simulations were conducted. The five-number summary of the simulation overall accuracy and kappa coefficient showed that the DBN-CA model was much more stable than the ANN-CA model. Analyzing the best results of these two models, the kappa coefficients are all greater than 75%, but the one for the DBN-CA model is 2.215% higher than that for the ANN-CA model. This demonstrates that DBN-CA and ANN-CA are both able to simulate complex and nonlinear urban growth. This also demonstrated that the DBN-CA is a new promising approach to simulate urban growth due to its higher simulation accuracy and stability. Finally, according to the prediction of urban growth of Jiaxing City for 2024, it will still present an expansion trend for towns. The predicted land use map indicated that 8946.36 hectares of non-urban areas will be converted to urban areas in 2015.
The proposed model used to simulate the urban growth in the example of Jiaxing City led to a new and effective land use change and urban expansion simulation approach. The DBN-CA model can be considered as a useful tool for urban planning and its related personnel, ecologists and resource managers who are committed to sustainable development. However, the bat algorithm requires more than 10 hours to optimize the DBN for 40 bats and 200 iterations on a personal computer with a 3.60-GHz CPU and 8 GB RAM. Therefore, a future study direction may be to investigate methods of improving the calculation speed. Moreover, as the “non-urban” category in this paper is very widely defined, a more refined classification would enable us to understand which type of land is more suitable to develop into urban land.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}