Short-Term Multiple Forecasting of Electric Energy Loads for Sustainable Demand Planning in Smart Grids for Smart Homes


Abstract
:1. Introduction
Research Question and Outline
- Development of a cooperative PSA-DT model, integrating the concept of probabilistic scenario analysis and decision tree techniques for short-term load forecasting and sustainable economic planning of electricity demand in an SG.
2. Preliminaries
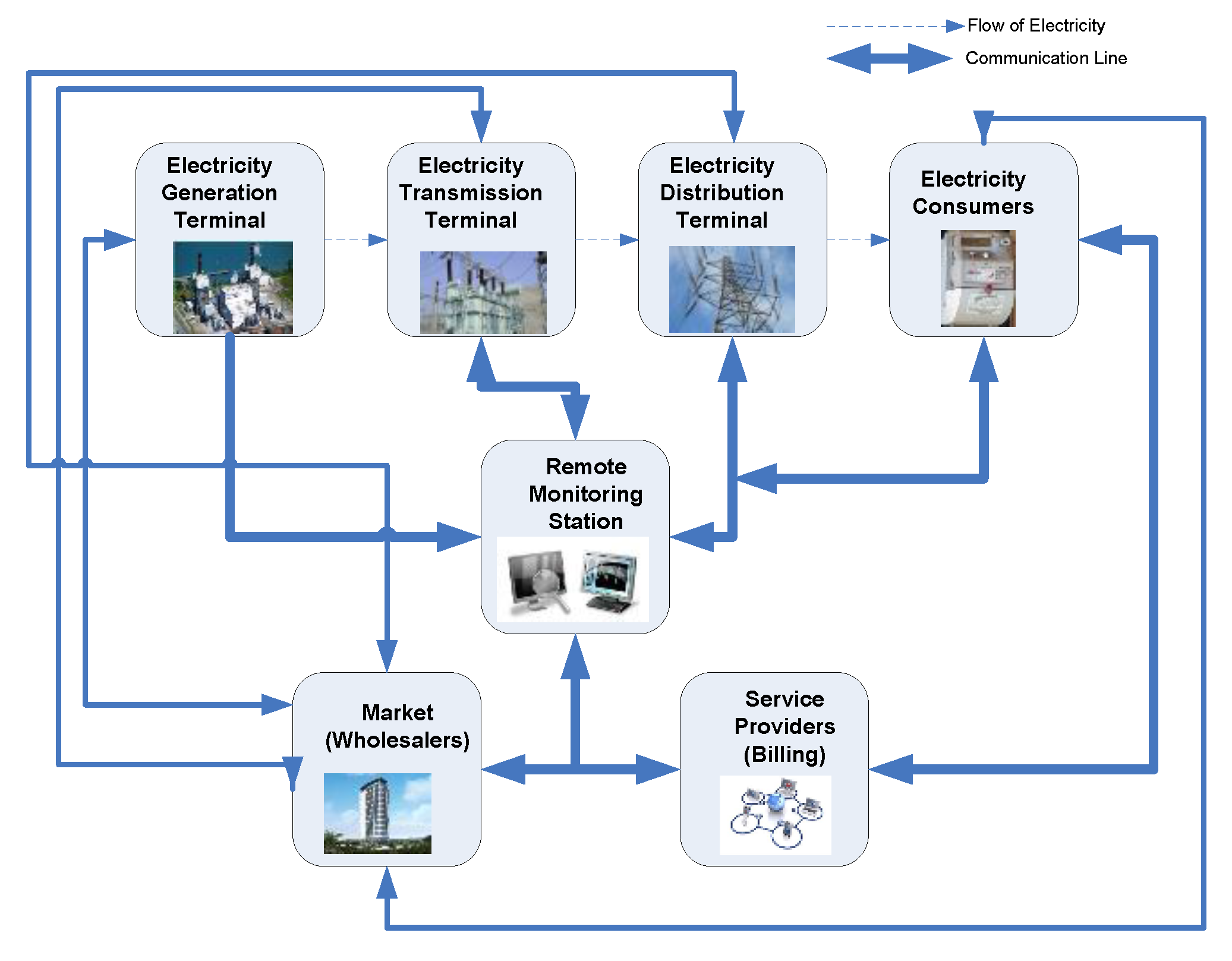
2.1. Smart-Grid Metering
2.2. Forecasting Modelling Techniques for Energy Load
2.2.1. Regression-Based Method
2.2.2. Time Series Analysis Method
2.2.3. Exponential Smoothing Method
2.2.4. Expert System Approach
2.2.5. Artificial Neural Network-Based Techniques
2.2.6. Support Vector Machine (SVM)
2.3. Theoretical Techniques
2.3.1. Probabilistic Scenario Analysis (PSA)
2.3.2. Decision Tree (DT)
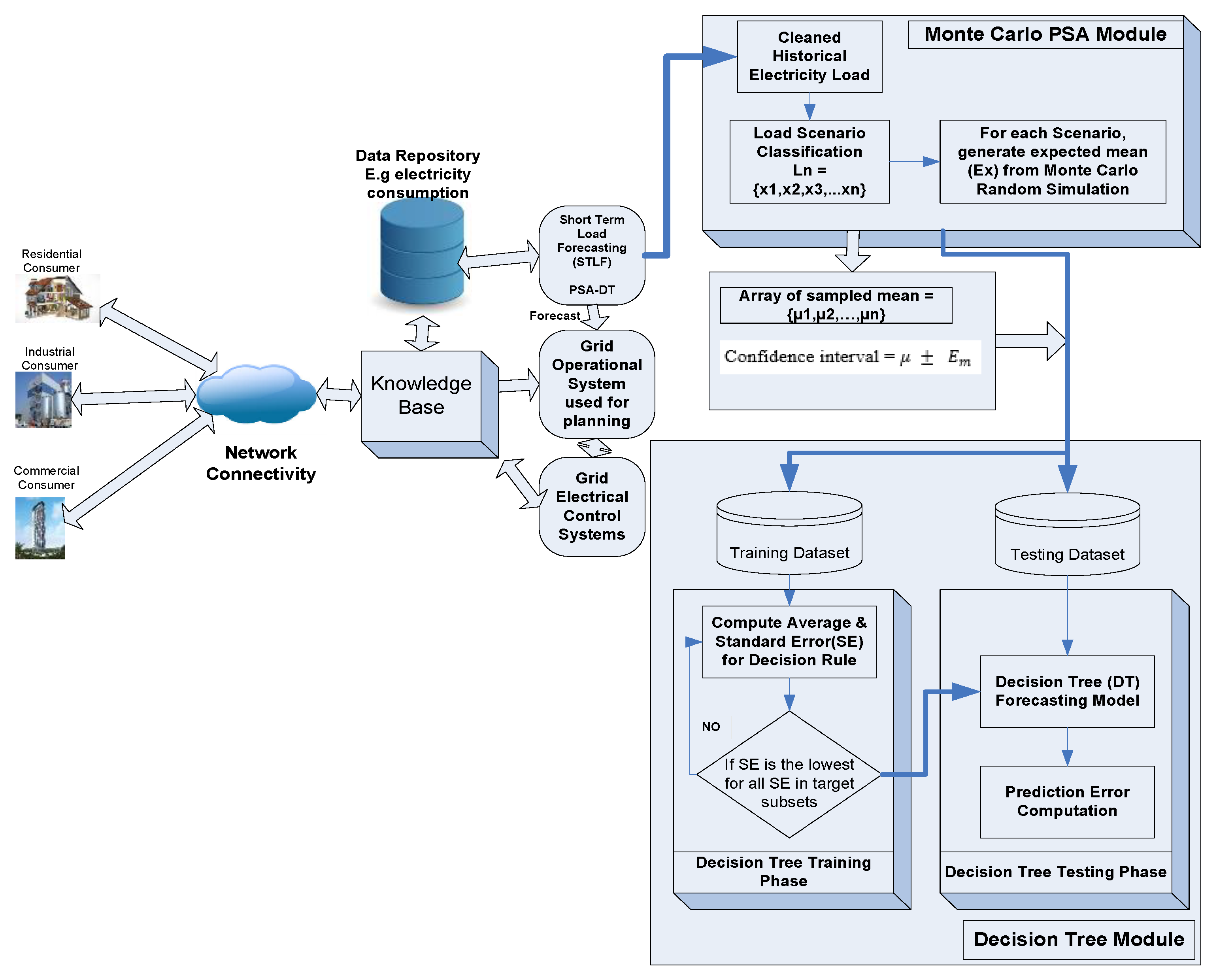
3. Development of Cooperative PSA-DT Model for Short-Term Load Forecasting
3.1. Confidence Interval and Degrees of Freedom
3.2. PSA-DT: Monte Carlo Probabilistic SA Modelling
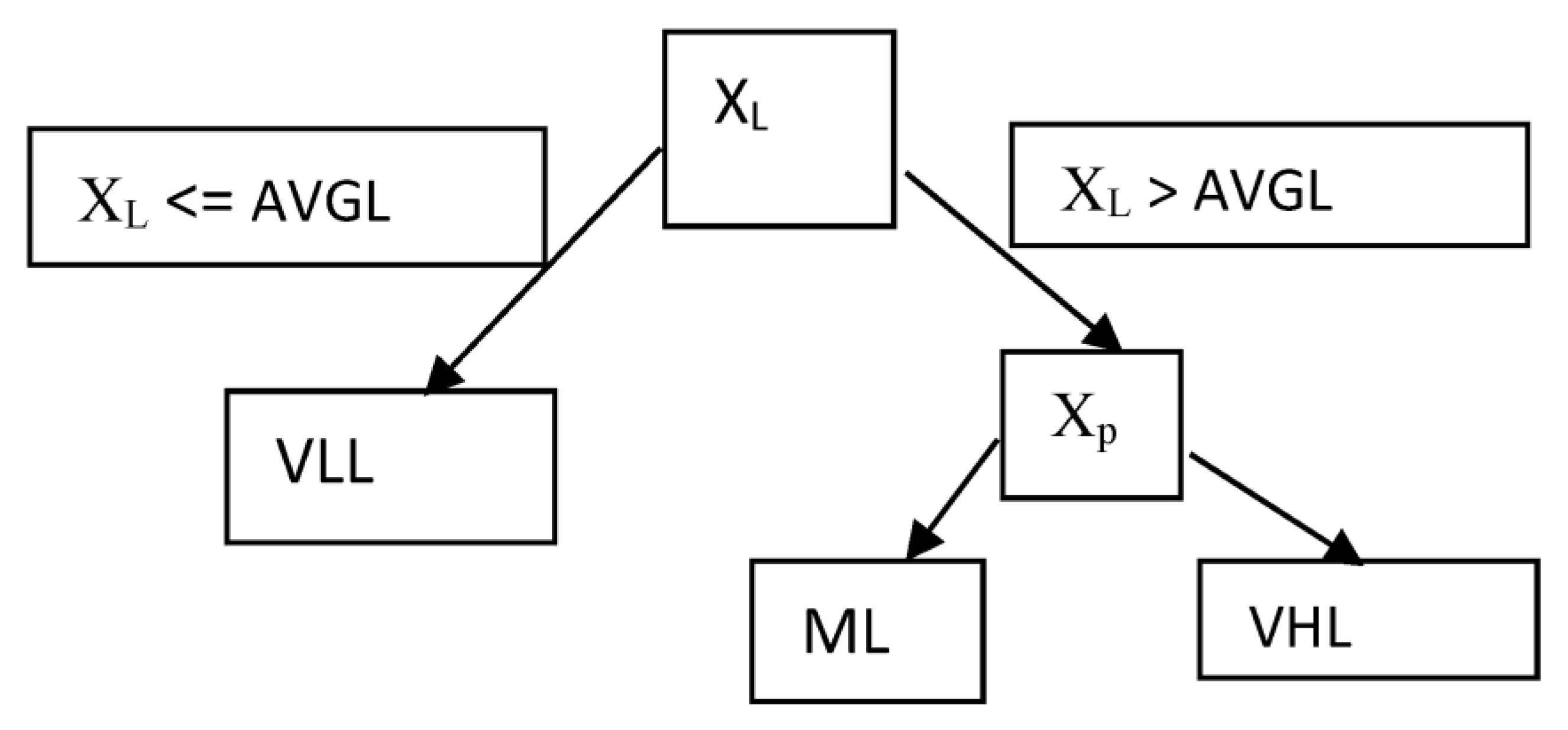
3.3. PSA-DT: Decision Tree Modelling
- If XL <= AVGL, Y = “VLL”.
- If XL ∈ Z, where Z > AVGL and Xp = “average weather”, then Y = “ML”.
- If X1 ∈ Z, where Z > AVGL and Xp = “hash weather”, then Y = ”VHL”.
3.4. PSA-DT Algorithmic and Mathematical Analysis
3.5. Scoring and Evaluation Mechanisms
3.5.1. Cross-Validation Scheme
- Model training using k-1 of the folds as training data; and
- Validating the resulting model on the remaining set of data i.e., it is used as test data to compute its accuracy, which is a performance measurement.
3.5.2. Mean Absolute Error
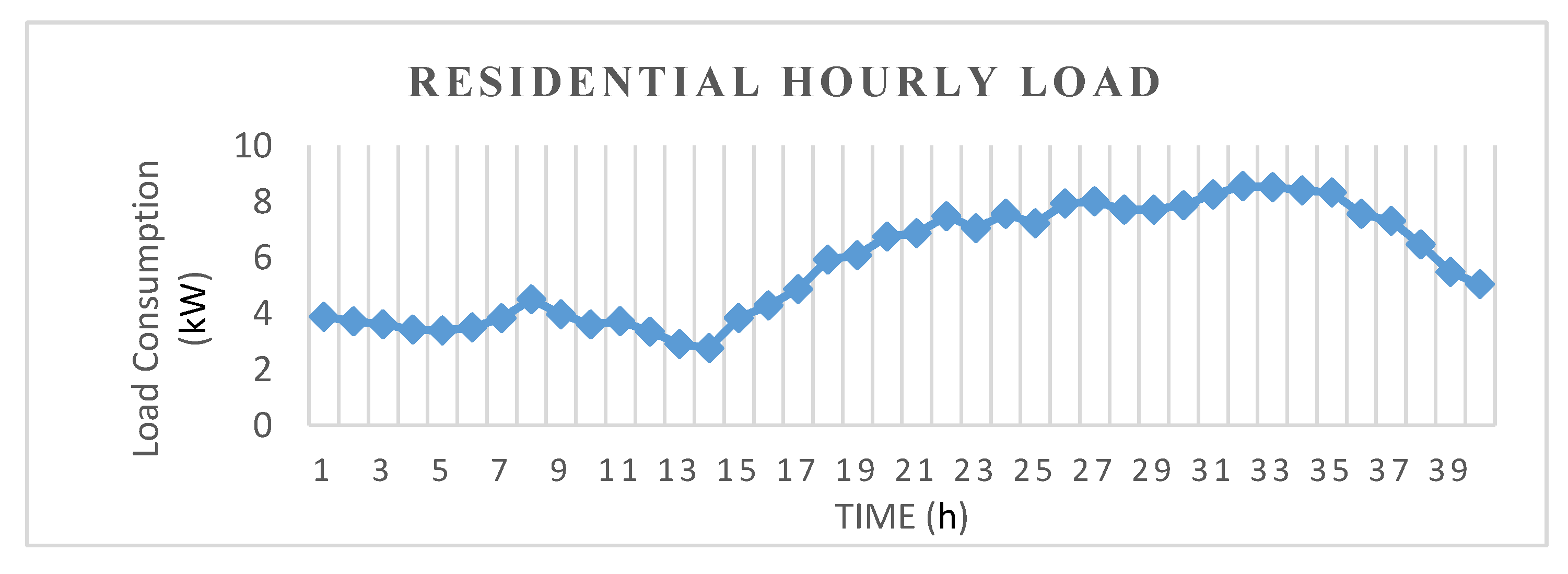
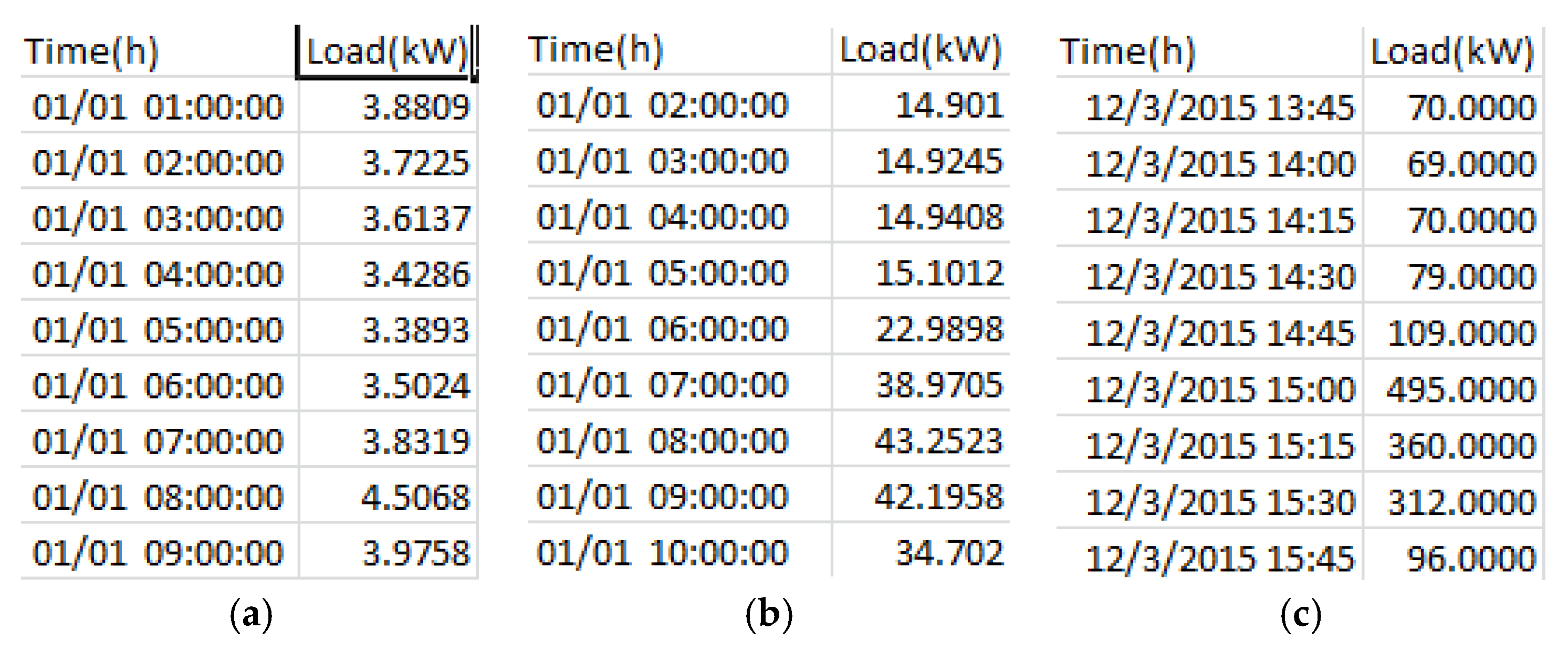
3.6. Numerical Scenario
- N = sample size = 10
- = Standard deviation = 0.1224
- = Confidence Level = 95% = 0.95.From Equation (8) DF = 10 − 1 = 9
- = Standard Error = = 0.0387.
- lower limit with 95% confidence interval = 3.7499 − 0.0875 = 3.6624; and
- upper limit with 95% confidence interval = 3.7499 + 0.0875 = 3.8375.
- = {3.7416, 3.7398, 3.7403, 3.7401, 3.7406, 3.7415, 3.7397, 3.7398} and the mean of = 3.7404
- = {3.7408, 3.74}.
- Split 1: The DT was split where the SD is at minimum value, which is at the point where the load value is 3.7403 KW/h. This is S1 while the remaining members in the will form set S2 as described in Section 3.3. The S1 becomes the leaf node while S2 will go through recursive process of extracting the member set with minimal SE carried out in Split 2 as shown in Table 2.
- Split 2: During this split process, the SD of the remaining dataset in Table 2 will be recalculated to obtain the least SD value. The load value 3.7406 Kw/h with SD 0.0002, being the minimum value among others, is selected as the decision node for further splitting. When the split result is more than one, an average of such result was computed for the leaf node e.g., (3.7398 + 3.7401 + 3.7406)/3 = 3.7401 KW/h.
- Split 3: At this juncture, the corresponding dataset was used to calculate the SD in order to obtain its least SD value. Load values 3.7415 and 3.7398 have the same SD value (0.00085) but the average of the two loads has an approximate value of 3.7407 Kw/h, which will form the decision point to aid the final decision. The final leaf nodes in Figure 11 form the model checked against for effective testing of the model. is a new dataset that has never been used during the DT training process and this was used against the training model to obtain a MAE that indicates the predictive performance of the model.
- = {22.7436, 14.901, 14.9245, 14.9408, 15.1012, 22.9898, 38.9705, 43.2523, 42.1958, 34.702} in Kw/h.
- = Standard deviation = 1.0486
- = Standard Error = = 0.3316
- = Confidence Coefficient = (1-confidence level)/2 = (1 − 0.99)/2 = 0.005 using Equation (2)
- (0.005) = 3.250 obtained from T distribution in [35]
- = 3.250 × 0.3316 = 1.0777
- Lower limit with 95% confidence interval = 25.6743 − 1.0777 = 24.5966
- Upper limit with 95% confidence interval = 25.6743 + 1.0777 = 26.752
- = {26.5586, 26.5453, 26.5359, 26.5369, 26.5535, 26.5547, 26.5295, 26.5333} and the mean of = 26.5435, which can also be used as the initial root node.
- = {26.5418, 26.5485}
- S1 (initial) = {26.5359, 26.5369, 26.5295, 26.5333} was formed when .
- S2 (initial) = {26.5586, 26.5453, 26.5535, 26.5547} was formed when
- Considering Tree S1 (initial) with :
- Split 1: The split point through S1 was determined by the least SD with value equal to 0.0006 and the corresponding load value is 26.5333 Kw/h, as shown in Table 3. Therefore, another set of S1 and S2 was also formed.
- S1 = {26.5295} was formed when SD is at its lowest value of 0.0006 and S1 average ≤ 26.5339 Kw/h.
- S2 = {26.5359, 26.5369, 26.5333} was formed when SD was at its lowest value of 0.0006 and S1 average > 26.5339 Kw/h with new S2 average as 26.5354 Kw/h.
- Split 2: In this section, the split point is at least SD of 0.0005 with a load value of 26.5359 Kw/h and another set of S1 and S2 was formed.
- S1 = {26.533} was formed when SD is at its lowest value of 0.0005.
- S2 = {26.5359, 26.5369} was formed when SD was at its lowest value of 0.0005 with a new decision node of 26.5364 Kw/h, being an average of S2.
- Split 3: In this last recursive iteration, the average of S2 in Split 2 forms the decision node for the final split with an average of the remaining member set because they both have the same SD value of 0.0005.
- Considering Tree S2 (initial) with :
- Split 1: The split point through S1 was determined by the least SD with value equal to 0.0005 and the corresponding load value is 26.5535, as shown in Table 3. Therefore, another set of S1 and S2 was formed.
- S1 = {26.5453} was formed and S2 = {26.5586, 26.5535, 26.5547} was also formed with new S2 average as 26.5556 Kw/h forming the next decision node, as shown in Figure 12.
- Split 2: In this section, the split point is at least SD of 0.0009 with a load value of 26.5547 Kw/h and another set of S1 and S2 was formed.
- S1 = {26.5535} was formed, and S2 = {26.5586, 26.5547} was also formed with a new decision node of 26.5566 Kw/h, being an average of S2.
- Split 3: In this last recursive iteration, the previous set S2 forms the leaf node, as shown in Figure 12.
4. Evaluation of PSA-DT for Short-Term Load Forecasting towards Economic Sustainability
4.1. Experimental Setup for Smart Grids
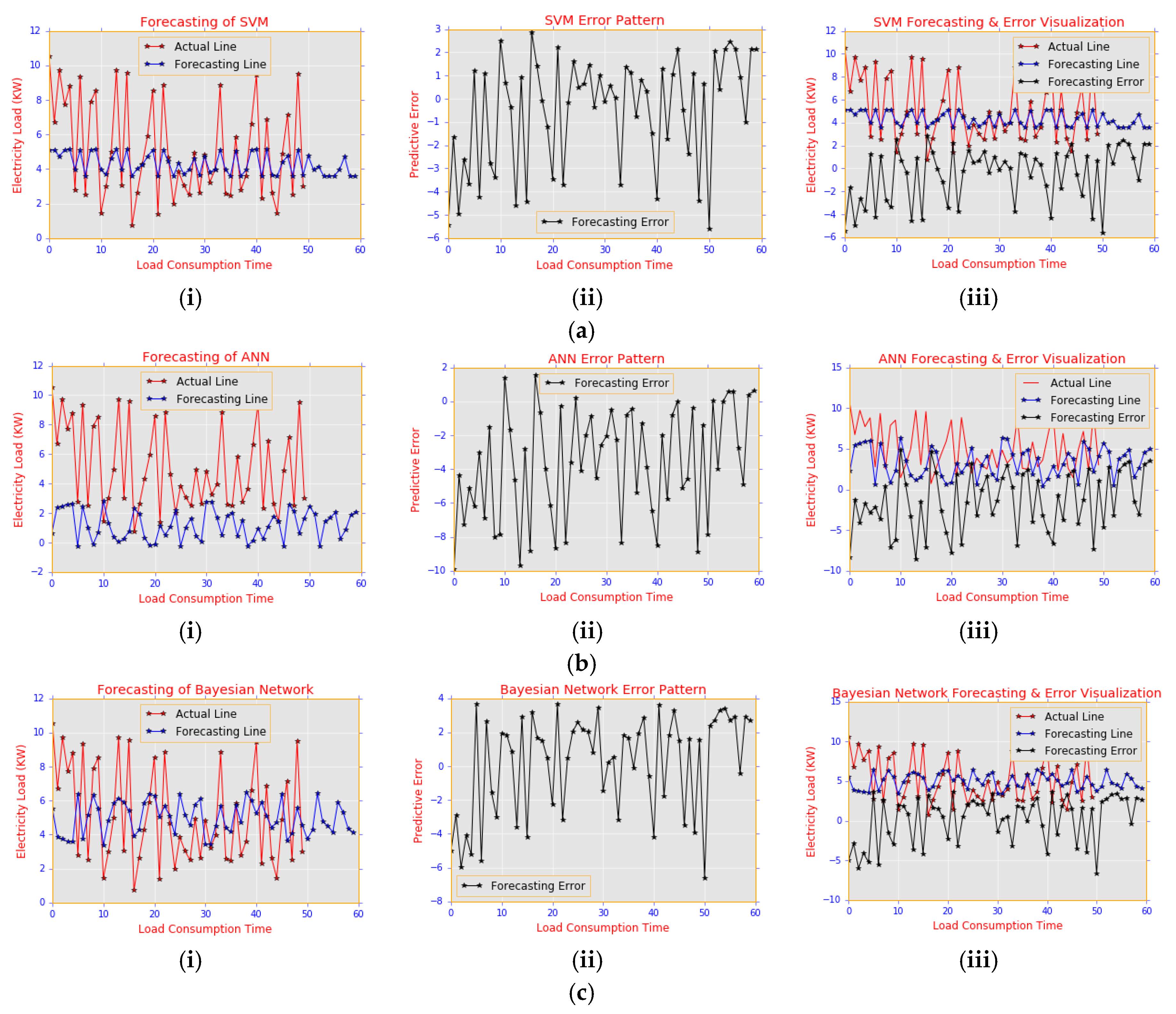
4.2. Experiment 1: Electric Load Forecasting with Classical Models on Residential Load Consumption
- Decision-making: The sampled qualitative analysis between the 51st and 60th hour for this experiment gave a corresponding answer to some of the questions asked.
- (Question) Q1: What is happening to the predictive behaviour?
- (Answer) A1: The predictive error in SVM is reduced with peak values ranging between −5.8 kw/h and 3.0 kw/h; BN predictive error is slightly higher than SVM error with a value between −6.8 kw/h and 3.8 kw/h; and predictive error from ANN is relatively higher than the results of the other classical models and ranges from −9 kw/h to 1.8 kw/h.
- Although the SVM could predict slightly better compared with the other classical models considered in terms of low predictive errors, its predictive performance can still be improved with the PSA-DT model. Although BN could predict up to 6 kw/h for an actual load of 10 kw/h, as shown in Figure 14c(i), the predictive error was still higher than the SVM predictive error. In addition, the ANN forecasting result in Figure 14b(i) could not fit the actual load for different load consumption periods. This irregularity was because large amounts of data were needed to train the ANN model for effective predictions. Therefore, these shortfalls contributed to the high predictive error generated by the ANN model in Figure 14b(ii).
- Q2: Why is it happening?
- A2: Inability of the forecasting models to predict the actual electricity load consumption accurately; this proposition can be seen clearly in Figure 14a(i), Figure 14b(i), and Figure 14c(i), meant for SVM, ANN and BN, respectively, where their forecasting lines in blue did not “fit” their corresponding actual load lines in red. Overall, there was an under-estimation.
- Q3: What can be done about it?
- A3: The forecasting error can be improved by deploying an effective cooperative model for the predictive analysis.
- Q4: What will happen next?
- A4: The SVM model tends to predict well in terms of low predictive error depicted by Figure 14a(ii), with a predictive error value of −5.8 kw/h to 3.0 kw/h when compared with the predictive error result of BN and ANN.
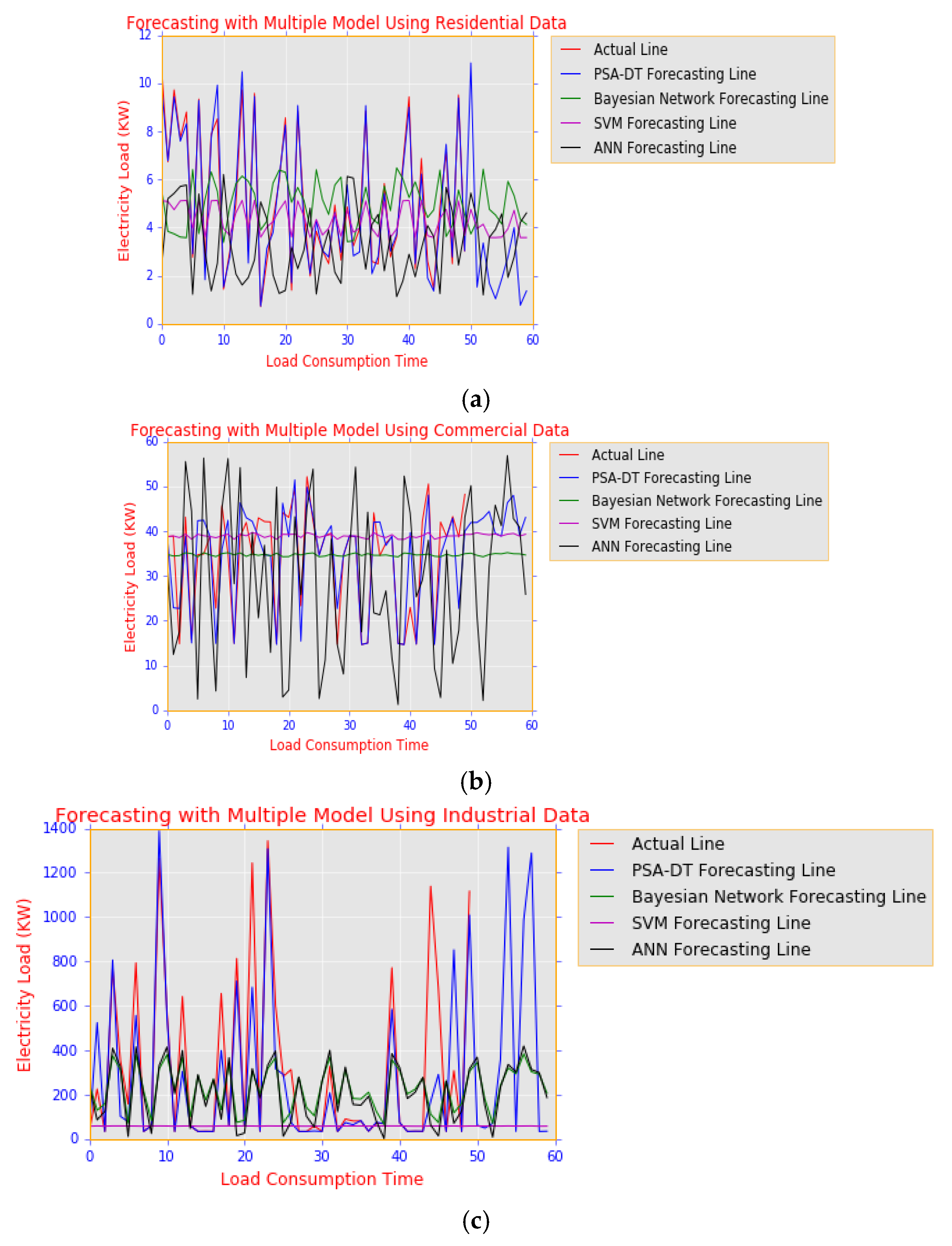
4.3. Experiment 2: Electric Load Forecasting with PSA-DT on Three Classes of Consumers in Smart Homes
- Decision-making: Sampled qualitative analysis between load consumption Hour 0 to Hour 50 and beyond.
- Q1: What is happening to the predictive behaviour?
- A1: The predictive error for the PSA-DT model was reduced to a range of −0.01 to 0.01 for residential load consumption, as shown in Figure 15a(ii); error values ranged from −0.04 to 0.04 for a commercial load user category in Figure 15b(ii) and −1.5 to 0.5 for an industrial load user. The negative predictive error value occurred because under-prediction and over-prediction produce a positive predictive error value. Since this error is extremely small compared to the value generated by the classical model shown in experiment Figure 14a–c(ii), the forecasting result generated by PSA-DT model tends towards higher accuracy than the result obtained from the classical model for all classes of users being considered.
- Q2: Why is it happening?
- A2: This predictive error reduction occurred because of the cooperative nature of the PSA-DT model formed by combining the merits of both PSA and the DT model described in Section 3. Because of the uncertain nature of electricity load consumption, we obtained the expected mean load with high confidence value via the Monte Carlo experiment before passing the result into a DT for effective learning and predictions.
- Q3: What can be done about it?
- A3: To maintain the efficiency of the cooperative model, data used for such predictions can be obtained with a low time interval, less than an hourly data interval. In addition, the classical models such as ANN and SVM can be improved by acquiring more data for effective learning of the model and for better representation of the future data point in the training data.
- Q4: What will happen next?A4: Deploying this predictive model during future load planning within an SG has huge potential to yield an effective forecasting result with high confidence of low predictive error.
4.4. Performance Evaluation of Electric Load Forecasting with PSA-DT and Classical Models
5. Concluding Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xiao, L.; Wang, J.; Hou, R.; Wu, J. A combined model based on data pre-analysis and weight coefficients optimization for electrical load forecasting. Energy 2015, 82, 524–549. [Google Scholar] [CrossRef]
- Li, H.; Guo, S.; Li, C.; Sun, J. A hybrid annual power load forecasting model based on generalized regression neural network with fruit fly optimization algorithm. Knowl.-Based Syst. 2012, 37, 378–387. [Google Scholar] [CrossRef]
- Islam, B.; Baharudin, Z.; Raza, Q.; Nallagownden, P. A hybrid neural network and genetic algorithm based model for short term load forecast. Res. J. Appl. Sci. Eng. Technol. 2014, 7, 2667–2673. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, J.; Chen, Y.; Li, C. A New Strategy for Short-Term Load Forecasting; Hindawi Publishing Corporation: Cairo, Egypt, 2013. [Google Scholar]
- Ko, C.-N.; Lee, C.-M. Short-term load forecasting using SVR (support vector regression)-based radial basis function neural network with dual extended Kalman filter. Energy 2013, 49, 413–422. [Google Scholar] [CrossRef]
- Almeshaiei, E.; Soltan, H. A methodology for electric power load forecasting. Alex. Eng. J. 2011, 50, 137–144. [Google Scholar] [CrossRef]
- Australian Energy Market Operator. Forecast Accuracy Report 2016; For The National Electricity Forecasting Report; Australian Energy Market Operator: Melbourne, Australia, 2016. [Google Scholar]
- US Electricity Operating Data. U.S. ELECTRIC SYSTEM OPERATING DATA. Available online: https://www.eia.gov/beta/realtime_grid/#/data/graphs?end=20170402T00&start=20170326T00 (accessed on 24 February 2017).
- Day, P.; Fabian, M.; Noble, D.; Ruwisch, G.; Spencer, R.; Stevenson, J.; Thoppay, R. Residential power load forecasting. Procedia Comput. Sci. 2014, 28, 457–464. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- OpenEI. Commercial and Residential Hourly Profiles for all TMY3 Locations in the United State. Available online: http://en.openei.org/datasets/dataset/commercial-and-residential-hourly-load-profiles-for-all-tmy3-locations-in-the-united-states (accessed on 25 December 2016).
- Kassakian, J.G.; Schmalensee, R.; Desgroseilliers, G.; Heidel, T.D.; Afridi, K.; Farid, A.M.; Grochow, J.M.; Hogan, W.W.; Jacoby, H.D.; Kirtley, J.L.; et al. The Future of the Electric Grid: An Interdisciplinary MIT Study; Massachusetts Institute of Technology: Cambridge, MA, USA, 2011. [Google Scholar]
- OpenEI. Smart Energy Data: Terni Energy Consumption Profiles. Available online: https://data.lab.fiware.org//dataset/b6ac9ad2-7b9e-4247-a785-81a88021995c/resource/3994b4ba-788a-4def-852f-043c71a20084/download/ternienergyconsumptionprofilecustomerindustrial1.csv (accessed on 24 November 2016).
- Soliman, S.A.; Persaud, S.; El-Nagar, K.; El-Hawary, M.E. Application of least absolute value parameter estimation based on linear programming to short-term load forecasting. Int. J. Electr. Power Energy Syst. 1997, 19, 209–216. [Google Scholar] [CrossRef]
- Badar, E.; Islam, U. Comparison of conventional and modern load forecasting techniques based on artificial intelligence and expert systems. Int. J. Comput. Sci. Issues 2011, 8, 504–513. [Google Scholar]
- Soliman, S.A.; Al-Kandari, A.M. Electrical Load Forecasting; Elsevier: Amsterdam, The Netherlands, 2010. [Google Scholar]
- Ismail, M.M.; Hassan, M.M. Artificial neural network based approach compared with stochastic modelling for electrical load forecasting. In Proceedings of the 2013 5th International Conference on Modelling, Identification and Control (ICMIC), Cairo, Egypt, 31 August–2 September 2013; pp. 112–118. [Google Scholar]
- Hahn, H.; Meyer-Nieberg, S.; Pickl, S. Electric load forecasting methods: Tools for decision making. Eur. J. Oper. Res. 2009, 199, 902–907. [Google Scholar] [CrossRef]
- Chen, B.-J.; Chang, M.-W.; Lin, C.-J. Load forecasting using support vector Machines: A study on EUNITE competition 2001. IEEE Trans. Power Syst. 2004, 19, 1821–1830. [Google Scholar] [CrossRef]
- Tepedino, C.; Guarnaccia, C.; Iliev, S.; Popova, S.; Quartieri, J. A forecasting model based on time series analysis applied to electrical energy consumption. Int. J. Math. Model. Methods Appl. Sci. 2015, 9, 432–445. [Google Scholar]
- Feinberg, E.A.; Genethliou, D. Load forecasting. In Applied Mathematics for Restructured Electric Power Systems; Springer: Berlin, Germany, 2006; pp. 269–285. [Google Scholar]
- Koo, B.G.; Lee, S.W.; Kim, W.; Park, J.H. Comparative study of short-term electric load forecasting. In Proceedings of the 2014 5th International Conference on Intelligent Systems, Modelling and Simulation, Langkawi, Malaysia, 27–29 January 2014; pp. 463–467. [Google Scholar]
- Cheepati, K.R.; Prasad, T.N. Performance comparison of short term load forecasting techniques. Int. J. Grid Distrib. Comput. 2016, 9, 287–302. [Google Scholar] [CrossRef]
- Atmaca, H. The comparison of fuzzy inference systems and neural network approaches with ANFIS method for fuel consumption data. In Proceedings of the Second International Conference on Electrical and Electronics Engineering Papers ELECO, Bursa, Turkey, 7–11 November 2001; Volume 6, pp. 1–4. [Google Scholar]
- Ismail, Z.; Mansor, R. Fuzzy logic approach for forecasting half-hourly Malaysia electricity. In Proceedings of the 31st International Symposium On Forecasting, Prague, Czech Republic, 26–29 June 2011. [Google Scholar]
- Wu, L.; Shahidehpour, M. A hybrid model for integrated day-ahead electricity price and load forecasting in smart grid. IET Gener. Transm. Distrib. 2014, 8, 1937–1950. [Google Scholar] [CrossRef]
- Yoe, C. Probabilistic scenario analysis. Princ. Risk Anal. 2011, 399–420. [Google Scholar]
- Bessa, R.J.; Trindade, A.; Silva, C.S.; Miranda, V. Probabilistic solar power forecasting in smart grids using distributed information. Int. J. Electr. Power Energy Syst. 2015, 72, 16–23. [Google Scholar] [CrossRef]
- Bood, R.P.; Postma, T.J.B.M. Scenario Analysis as a Strategic Management Tool; University of Groningen: Groningen, The Netherlands, 1998; pp. 1–38. [Google Scholar]
- Alemohammad, S.H.; Ardakanian, R.; Karimi, A. A framework for modelling probabilistic uncertainty in rainfall scenario analysis. arXiv preprint 1995, arXiv:1304.4302, 1–8. [Google Scholar]
- Analysis, S. Chapter 6 Probabilistic Approaches: Scenario Analysis, Financial Times. 1–61.
- Ben-Naim, A. Entropy, Shannon’s measure of information and Boltzmann’s H-theorem. Entropy 2017, 19, 48. [Google Scholar] [CrossRef]
- Sreerama, K.M. Automatic construction of decision trees from data: A multi-disciplinary survey. Data Min. Knowl. Discov. 1998, 2, 345–389. [Google Scholar]
- We, X. Methods for Statistical Data Analysis with Decision Trees; Sobolev Institute of Mathematics: Novosibirsk, Russia, 2003. [Google Scholar]
- UF Department of Statistics. Statistical Tables; UF Department of Statistics: Gainesville, FL, USA, 2002; Volume II, pp. 1–26. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Energy Load Forecasting Techniques | Specific Model Used | Strength | Weakness | Error Rate with Respect to the Data Used |
|---|---|---|---|---|
| Regression [19,20] | Linear Regression and Multiple Linear Regression | Very useful in non-real time forecasting. Functional relationship between previous, forecast load and other factors such as weather, time of the day. | Not accurate for real time load and unable to handle nonlinear load consumption. Adding parameters make it unstable. | 4.665% 21.87% |
| Time-series Analysis [20,21,22] | Auto Regressive Moving Average, Auto Regressive Integrated Moving Average, Deterministic decomposition. | They possess abilities to accommodate seasonal component effects. | They suffer numerical instability | 1.48–1.99% |
| Artificial Neural Network [23,24] | Multilayer Perceptrons, Back Propagation Algorithm, Steepest descent Error Back Propagation. | Ability to handle nonlinear relationships in load consumption by adjusting its weight during the training process. | Large amounts of data are needed to train the model and complexity in the training of such data. | 2.9% 6.609% |
| Fuzzy Inference System [19,25] | Defuzzification Method using Centre of Area, Middle of Maxima, Last of Maxima and Centre of gravity | Faster and more accurate in performance including simplicity in rule formation. | Selection of membership function to form its rule is based on trial and error. | 2.58%, 5.831% and 1.794%, 9.53% |
| Support Vector Machine [15,26] | Support Vector Regression using Incremental Learning Algorithm Support Vector Regression | It enhances higher feature space dimensionality by using ε-insensitive loss for linear regression computation and reduction in model complexity. | Choosing of suitable kernel and difficulties in its interpretation are major concerns | 4.2306% 1.57–4.28% 1.95–3.48 |
| at Split 1 | SD at Split 1 | at Split 2 | SD at Split 2 | at Split 3 | SD at Split 3 |
|---|---|---|---|---|---|
| 3.7416 | 0.0012 | 3.7416 | 0.0012 | 3.7416 | 0.00095 |
| 3.7398 | 0.0006 | 3.7398 | 0.0006 | 3.7415 | 0.00085 |
| 3.7403 | 0.0001 | 3.7401 | 0.0003 | 3.7397 | 0.00095 |
| 3.7401 | 0.0003 | 3.7406 | 0.0002 | 3.7398 | 0.00085 |
| 3.7406 | 0.0002 | 3.7415 | 0.0011 | ||
| 3.7415 | 0.0011 | 3.7397 | 0.0007 | ||
| 3.7397 | 0.0007 | 3.7398 | 0.0006 | ||
| 3.7398 | 0.0006 |
| at Split 1 | SD at Split 1 | at Split 2 | SD at Split 2 | at Split 3 | SD at Split 3 |
|---|---|---|---|---|---|
| S1 (initial) | |||||
| 26.5359 | 0.0020 | 26.5359 | 0.0005 | 26.5359 | 0.0005 |
| 26.5369 | 0.0030 | 26.5369 | 0.0015 | 26.5369 | 0.0005 |
| 26.5295 | 0.0044 | 26.5333 | 0.0021 | ||
| 26.5333 | 0.0006 | ||||
| S2 (initial) | |||||
| 26.5586 | 0.0056 | 26.5586 | 0.0030 | 26.5586 | 0.0025 |
| 26.5453 | 0.0077 | 26.5535 | 0.0021 | 26.5535 | 0.0026 |
| 26.5535 | 0.0005 | 26.5547 | 0.0009 | ||
| 26.5547 | 0.0017 |
| (a) | ||||||
| Predictive Model | Smart-Grid Data (User Category) | Hourly Load Data Size | Training Size (%) | Test Size (%) | Predictive Error (MAE) for PSA-DT | Predictive Error (MAE) for SVM |
| PSA-DT and SVM | Residential | 100 | 60 | 40 | 0.0018 | 0.0105 |
| 80 | 20 | 0.002 | 0.0100 | |||
| 200 | 60 | 40 | 0.0028 | 0.007 | ||
| 80 | 20 | 0.002 | 0.02 | |||
| 500 | 60 | 40 | 0.0032 | 0.0463 | ||
| 80 | 20 | 0.0038 | 0.0336 | |||
| Commercial | 100 | 60 | 40 | 0.0093 | 0.05 | |
| 80 | 20 | 0.0095 | 0.078 | |||
| 200 | 60 | 40 | 0.0093 | 0.0544 | ||
| 80 | 20 | 0.0093 | 0.0715 | |||
| 500 | 60 | 40 | 0.0150 | 0.1059 | ||
| 80 | 20 | 0.0129 | 0.08 | |||
| Industrial | 100 | 60 | 40 | 0.2375 | 1.2713 | |
| 80 | 20 | 0.2345 | 1.9485 | |||
| 200 | 60 | 40 | 0.20438 | 1.3151 | ||
| 80 | 20 | 0.2185 | 1.6672 | |||
| 500 | 60 | 40 | 0.4369 | 1.8399 | ||
| 80 | 20 | 0.4252 | 4.062 | |||
| (b) | ||||||
| Predictive Model | Smart-Grid Data (User Category) | Hourly Load Data Size | Training Size (%) | Test Size (%) | Predictive Error (MAE) for PSA-DT | Predictive Error (MAE) for BN |
| PSA-DT and BN | Residential | 100 | 60 | 40 | 0.0018 | 0.0028 |
| 80 | 20 | 0.002 | 0.0045 | |||
| 200 | 60 | 40 | 0.0028 | 0.0075 | ||
| 80 | 20 | 0.002 | 0.00475 | |||
| 500 | 60 | 40 | 0.0032 | 0.0053 | ||
| 80 | 20 | 0.0038 | 0.0109 | |||
| Commercial | 100 | 60 | 40 | 0.00925 | 0.011 | |
| 80 | 20 | 0.0095 | 0.0145 | |||
| 200 | 60 | 40 | 0.0093 | 0.0178 | ||
| 80 | 20 | 0.0093 | 0.0193 | |||
| 500 | 60 | 40 | 0.0150 | 0.0315 | ||
| 80 | 20 | 0.0129 | 0.0323 | |||
| Industrial | 100 | 60 | 40 | 0.2375 | 1.3978 | |
| 80 | 20 | 0.2345 | 1.996 | |||
| 200 | 60 | 40 | 0.204375 | 0.653875 | ||
| 80 | 20 | 0.2185 | 0.7785 | |||
| 500 | 60 | 40 | 0.4369 | 1.1663 | ||
| 80 | 20 | 0.4252 | 1.7514 | |||
| (c) | ||||||
| Predictive Model | Smart-Grid Data (User Category) | Hourly Load Data Size | Training Size (%) | Test Size (%) | Predictive Error (MAE) for PSA-DT | Predictive Error (MAE) for ANN |
| PSA-DT and ANN | Residential | 100 | 60 | 40 | 0.0018 | 0.0118 |
| 80 | 20 | 0.002 | 0.013 | |||
| 200 | 60 | 40 | 0.0028 | 0.0124 | ||
| 80 | 20 | 0.002 | 0.0235 | |||
| 500 | 60 | 40 | 0.0032 | 0.0569 | ||
| 80 | 20 | 0.0038 | 0.0466 | |||
| Commercial | 100 | 60 | 40 | 0.00925 | 0.0643 | |
| 80 | 20 | 0.0095 | 0.086 | |||
| 200 | 60 | 40 | 0.0093 | 0.0575 | ||
| 80 | 20 | 0.0093 | 0.078 | |||
| 500 | 60 | 40 | 0.0150 | 0.1283 | ||
| 80 | 20 | 0.0129 | 0.0904 | |||
| Industrial | 100 | 60 | 40 | 0.2375 | 2.3153 | |
| 80 | 20 | 0.2345 | 2.0225 | |||
| 200 | 60 | 40 | 0.204375 | 1.558 | ||
| 80 | 20 | 0.2185 | 1.6768 | |||
| 500 | 60 | 40 | 0.4369 | 2.2818 | ||
| 80 | 20 | 0.4252 | 4.0605 | |||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alani, A.Y.; Osunmakinde, I.O. Short-Term Multiple Forecasting of Electric Energy Loads for Sustainable Demand Planning in Smart Grids for Smart Homes. Sustainability 2017, 9, 1972. https://doi.org/10.3390/su9111972
Alani AY, Osunmakinde IO. Short-Term Multiple Forecasting of Electric Energy Loads for Sustainable Demand Planning in Smart Grids for Smart Homes. Sustainability. 2017; 9(11):1972. https://doi.org/10.3390/su9111972
Chicago/Turabian StyleAlani, Adeshina Y., and Isaac O. Osunmakinde. 2017. "Short-Term Multiple Forecasting of Electric Energy Loads for Sustainable Demand Planning in Smart Grids for Smart Homes" Sustainability 9, no. 11: 1972. https://doi.org/10.3390/su9111972
APA StyleAlani, A. Y., & Osunmakinde, I. O. (2017). Short-Term Multiple Forecasting of Electric Energy Loads for Sustainable Demand Planning in Smart Grids for Smart Homes. Sustainability, 9(11), 1972. https://doi.org/10.3390/su9111972