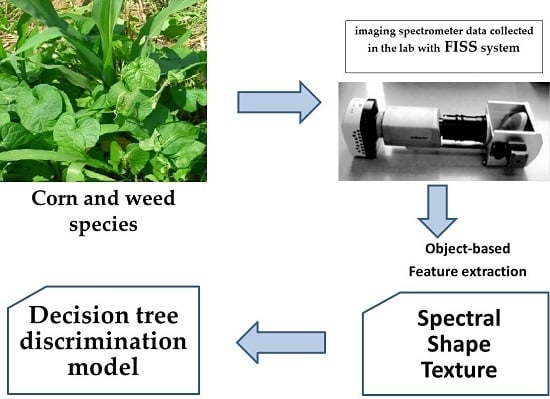
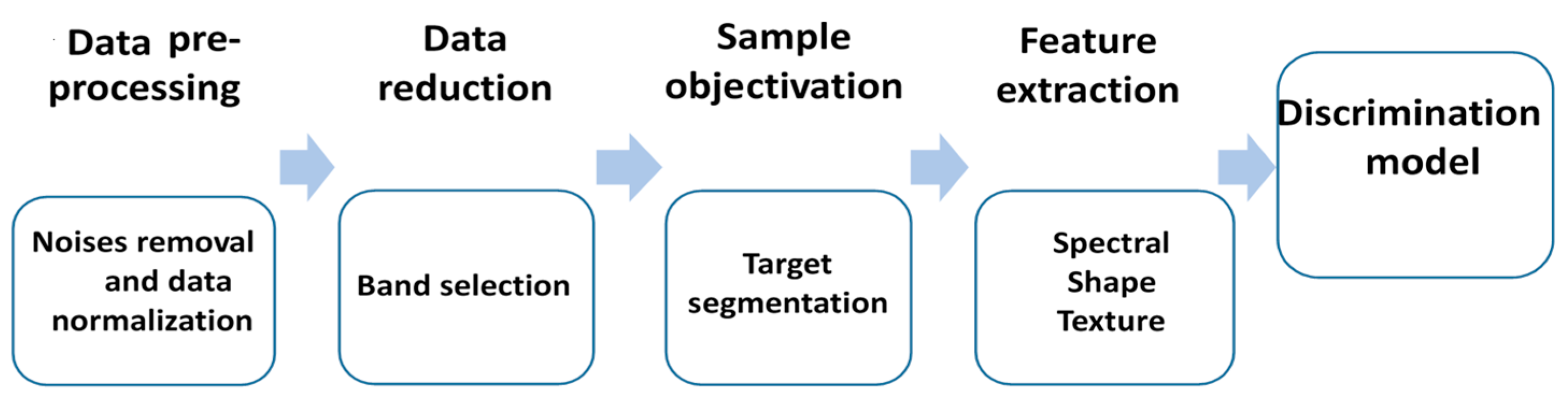
2.4.4. Spectral, Shape, and Texture Feature Extraction of Plant Objects
We measured a number of features from the raw corn/weeds images to be later used for classification purposes. A total of 11 features were considered to be most representative of the classes of interest, which correspond to spectral, shape, and textural characteristics of corn and weeds. They are described below.
(1) Spectral Features
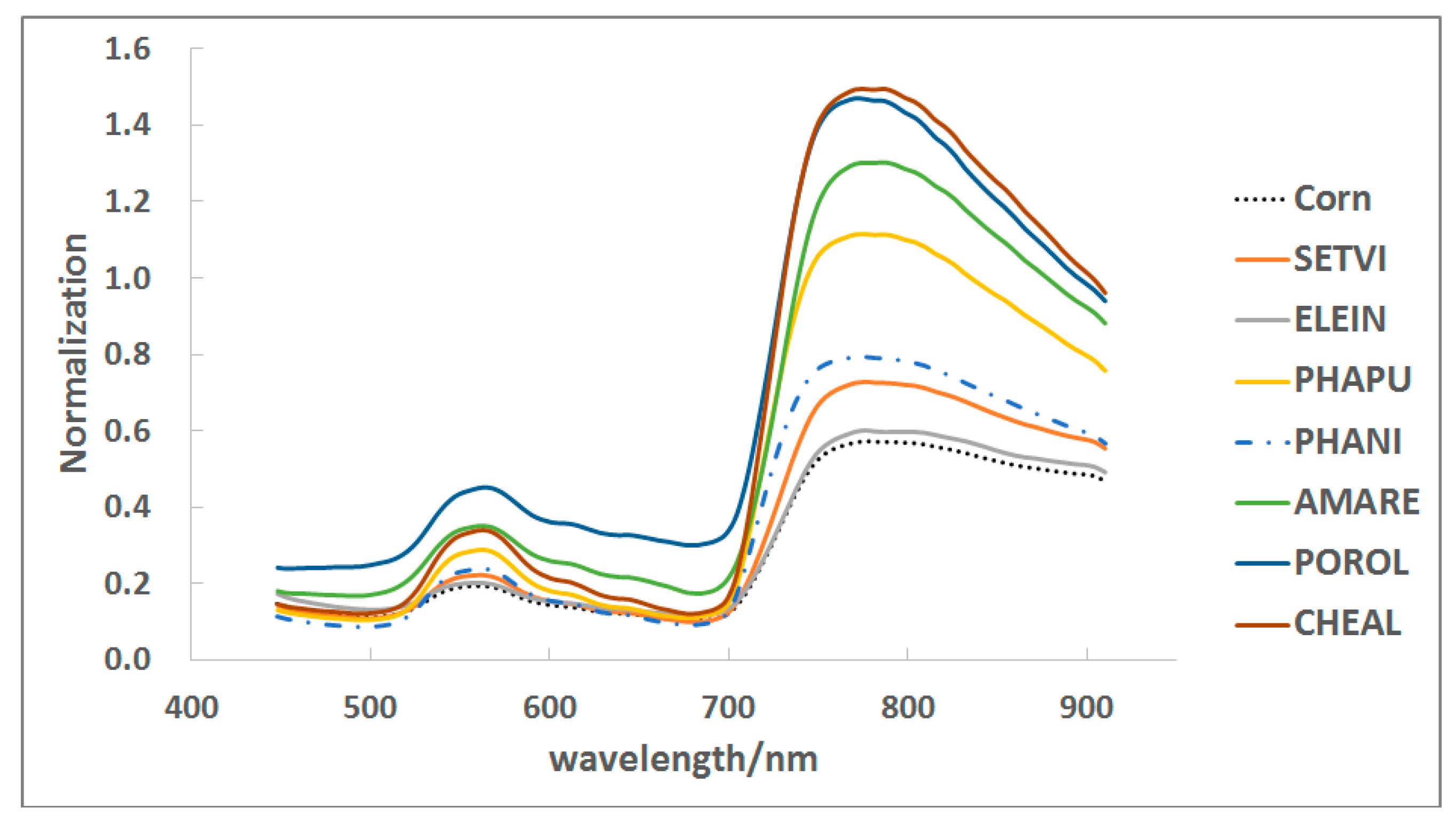
It was clear that it was useful to use certain spectral indices or ratios to distinguish between weeds and crop based on selected wavebands. In this study, four vegetation indices were selected and calculated as spectral properties of plant objects. These indexes were Ratio Vegetation Index (RVI), Red Index (RI), the Ratio of the band 677 nm and 710 nm (M1), and the normalized difference index between the band 749 nm and 710 nm (M2), separately (
Table 1).
(2) Shape Features
Shape features for object identification typically require invariance, which indicates that the values of the shape features will not be changed after the object is translated, rotated, rescaled, or repositioned [
13]. Therefore, four kinds of features were determined in the study, including area, shape index, length/width, and length. The details of these features are shown in the Reference Book of eCognition Developer 8.7 [
24].
The area describes the entire size of the object, which is the number of pixels multiplied by the size of the pixel.
The shape index describes the smoothness of an image object border. The smoother the border of an image object is, the lower the shape index. It is calculated from the border length feature of the image object divided by four times the square root of its area.
where α is the shape index; e is the perimeter;
A is the area.
Length/width is the length-to-width ratio of an image object. The covariance matrix of the coordinates of the boundary pixels is the foundation for calculating length/width. The form of the covariance matrix is
where
X is the vector composed of the
x coordinates of the boundary pixel;
Y is the vector composed of the
y coordinated of the boundary pixel; both
X and
Y use the same order.
Var(
X) and
Var(
Y) are the variances of
X and
Y, and
Cov (
XY) is the covariance of
X and
Y.
After the covariance matrix is obtained, length/width can be represented by Equation (3).
where
eig1(
S) is the maximum eigenvalue of the matrix
S;
eig2(
S) is the minimum eigenvalue of the matrix
S.
The length of a 2D image object is calculated using the length-to-width ratio.
where l is the length;
γ is the length-to-width ratio;
A is the area of the object.
(3) Texture Features
The texture is an important image feature that shows the regularity of the gray or color distribution for the image. In the macro scale, we can see different crop and weed cluster textures when the leaf shows different texture traits in the micro level. For example, the vein texture of the monocotyledonous plants is parallel or curved; that of the dicotyledonous plants is reticular. Therefore, the texture information of the plant leaf is useful to identify corn/weeds.
Gray level co-occurrence matrix (GLCM) is a statistical technique for texture analysis, which was presented by Haralick et al. [
25]. The eCognition software generates the gray level co-occurrence matrix (GLCM) algorithm, which is a tabulation of how often different combinations of pixel gray levels occur in a scene. A different co-occurrence matrix exists for each spatial relationship. Calculation of textures is dependent upon the direction of the analysis and the distance. The gray co-occurrence can be specified in a matrix of relative frequencies
P (
i, j, s, β) with which two neighboring resolution cells separated by distances occur on the image, one with gray tone
i and the other with gray tone y. The direction
β includes four directions, Direction 0°, Direction 45°, Direction 90°, Direction 135°. Such matrices of spatial gray tone dependence frequencies are symmetric and a function of the angular relationship between the neighboring resolution cells as well as a function of the distance between them. Texture features are based on the GLCM matrix and algorithm of a particular feature, such as GLCM homogeneity being locally homogeneous in the image, GLCM contrast being the opposite of the homogeneity and a measure of the amount of local variation in the image, GLCM dissimilarity similar to contrast but increasing linearly, GLCM entropy representing equal distribution of the elements of GLCM.
It will be time-consuming and generate redundant information if the GLCM algorithm is performed on the imaging data of each waveband. Through testing, it was determined that three textural features of GLCM contrast, entropy, and homogeneity, based on three sensitive wavelengths of 516 nm, 677 nm, and 843 nm as well as the 90° direction, would be used (
Table 2).
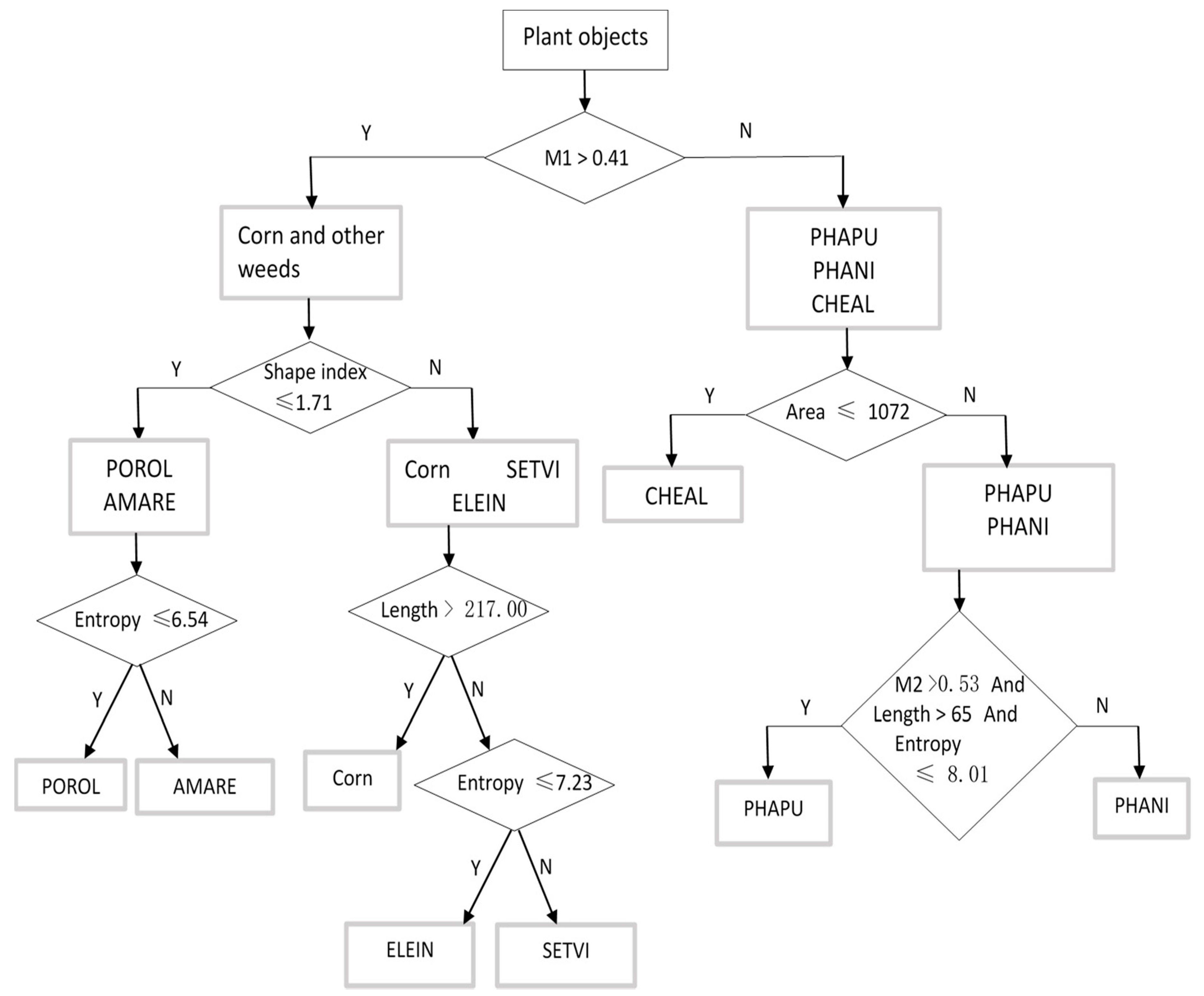
2.4.5. Classifier and Validation
Identification of corn and weed species was done with a C 5.0 algorithm based on plant leaf objects. C 5.0 is an extension of the C 4.5 algorithm, and it is more efficient and uses less memory [
26]. C 5.0 constructs the classification trees from discrete values based on the “information gain” calculated by the entropy. The C 5.0 model can split samples on the basis of the biggest information gain field. The sample subset that is obtained from the former split is split afterwards. The process continues until the sample subset cannot be split and is usually according to another field. Finally, on examining the lowest level split, those sample subsets that do not have a remarkable contribution to the model are rejected [
27]. The decision tree method automatically discovers classification rules by using machine learning techniques. It uses the “information gain ratio” to determine the splits at each internal node of the decision tree [
28]. In the study decision tree classifier construction options included 10 trials of boosting and global pruning.
All plant object samples were randomly split into two parts, 70% of which was training dataset and the other was testing dataset. The training set was useful to build the discrimination model, whereas the testing set was used for validating the classification. The classification quality was quantitatively assessed through the Global accuracy, Kappa coefficients, user’s accuracy, and producer’s accuracy, were all extracted from the confusion matrix.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}