An algorithm was written in C++ with iterations to correct for atmospheric scattering due to solar zenith angle variation and variation of the aerosol optical properties in different wavelengths. This method demonstrates a greater potential of being able to substantially reduce the number of misclassified pixels and enhance the classification accuracy. This was done by using randomly selected training sets of the vegetation classes across the scene.Atmospheric components such as scattering efficiecy, scattering coefficient, and path radiance per pixel were derived mathematicaly. The scattering efficiency was derived using Mie particle theory. We introduce a mathematical model which consists of two concepts to derive the scattering coefficient and the path radiance per pixel. This was followed by the implementation of the atlgorithm and atmospheric correction method. The methodology was divided into the following sub-sections.
2.2. Theoretical Background and Derivation of Atmospheric Correction Components
Radiative Transfer Theory is the theoretical basis for driving the equations used to develop the atmospheric correction algorithm. At a satellite detector, the received electromagnetic radiation reflected from the earth and scattered through the atmosphere (multiple scattering), is composed of the three components in the following equation:
where
Lo is the radiation that is scattered through the atmosphere and arrives at the satellite detector without being reflected by the earth’s surface. The
Lo component is independent of surface reflectance and causes a loss of contrast in the image spectral signatures. The
Ls component is the radiation that is reflected by the surface, transmitted through the atmosphere, and intercepted by the satellite detector. The
Ld component is the radiation that is scattered through the atmosphere from the neighboring pixels and transmitted to the sensor as
The scattering path radiance is defined as the sum of two components [
12], the radiation of sunlight that scattered before reaching the surface (
Lo); and the radiation that is scattered through the atmosphere by the neighboring pixels (
Ld).
To derive the atmospheric model for aerosol scattering, we have to understand the physics of scattering in a realistic medium. Consider a cylinder of a unit volume, with cross sectional area
dσ = 1, and length ds, to be embedded in the medium of the atmosphere. A pencil of monochromatic radiation with intensity
IV (Ω) traverses the cylinder and emerges with an intensity of
IV(Ω) +
dIV(Ω) after being attenuated by scattering in the medium. Two types of radiation emerge from the volume. The first one is the incident beam from direction Ω that undergoes the change of intensity -
KscaIVds on its passage, but continues in the same direction. The value of
Ksca, the scattering coefficient, is the fraction of change in intensity
IV per unit length [
13]. The second type is the radiation field emerging from the volume arising from scattering radiation and incident on the volume from all directions Ω’ except direction Ω (diffused radiation); this is called path radiance [
13].The sum of the two radiation types gives the following equation of transfer:
where
dI (Ω) is the change in intensity in the forward direction,
I* is the diffuse multiple scattered radiation, Ω is the direction of propagation, Ω’ is the direction of the diffuse radiation,
P is the phase function, Z is the altitude,
θ’ and
ϕ’ are the viewing zenith and azimuth coordinate angles, respectively [
13].
We derived the path radiance (error per pixel) that is intercepted by the field of view of the satellite’s sensor by considering two radiative transfer equations as follows:
The basic equation of radiative transfer for direct scattering along the line of sight,
The equation of radiative transfer of diffuse scattered radiation.
The necessary assumptions include the following:
A plane parallel atmosphere in which radiation is transmitted up or down
A clear atmosphere (cloud free).
Attenuation due to absorption is relatively insignificant compared with scattering
The plane parallel atmosphere is related to the path length
dS =
dZ / cos
θ (where
θ is the solar zenith angle) and to the component of path radiance that scattered in the atmosphere before reaching the surface and subsequently was transmitted to a satellite detector
Lo. The path length
dZ is related to the component of radiation that has been scattered by aerosols, from the neighboring pixels
Ld, when surface reflectance is directly reflected and transmitted to a satellite detector oriented such that it takes the observation at nadir [
1]. The basic Radiative Transfer Equation (RTE) for the two components (
Lo–
Ld) (see
Figure 1) from Equation 1 [
13] is given by the following expression:
where
dl is the change in intensity due to atmospheric scattering. Equation 4 is integrated as in the following:
The absolute intensity can be written in the following equation:
To derive the error per pixel due to scattering, we assume a fraction
µ of the scattered radiance is transmitted to the satellite field of view and is related to the path radiance and intensity in the following equation:
where
,
,
,
W is the path radiance and Z is the altitude in kilometers. Rearranging Equation 4 through Equation 8,
µ can be written in the following form:
Since
µ is also a fraction of the scattered in the forward direction from the target subtracted from the diffuse multiple scattered radiations (
L–
Ls) (see
Figure 1) from Equation 1,
W can be written in the following:
where, and
A is the pixel area, and
I* is given by Equation 3. The term
I0 is absolute intensity of pixel value (free of error) which can be represented by the following expression:
where
Wij represents the error (scattering effect) at row i and line j across the scene and
Ipixel is the pixel value. By substituting Equation 9, and Equation 11, in Equation 10, the path radiance per pixel due to the three components of the scattering
Lo,
Ls and
Ld that are transmitted to a satellite FOV is given by the following equation:
where,
Ksca is the total scattering coefficient for aerosol particles for which derivation is shown below.
The basic equation of the scattering coefficient is in the following:
where, r is particle size,
n(
r) is the size distribution, and
Qsca is the scattering efficiency per single particle. The scattering efficiency per single particle
Qsca was derived by using expansions of Bessel’s function and Legendre Polynomial for the scattered field surrounding the spherical particle. The scattered field is represented by an infinite series of vector spherical harmonics [
12]. The vector spherical harmonics are the electrical and magnetic modes of the scattered field surrounding the single particle. The coefficients of the expansions are given by the following:
where:
ψ and
ψ’ are the wave functions;
ξ and
ξ’ are Bessel’s functions and
x is the parameter size (
), m is the complex index of refraction. According to Mie Particle Theory, coefficients of expansions are accurate to
x6 [
12]. The coefficients are expanded and shown by the following equations:
From Equation 15 through 18, the scattering efficiency per particle is shown in the following:
The complex indices of refractions m and particles’ sizes are arbitrary as mentioned previously (0.1–0.5
µm for band 1; 0.1–0.6
µm for band 2; 0.1–0.7
µm for band 3) [
12].
The scattering coefficient
Ksca is also given in terms of the size distribution
n(
r) [
14] as in the following equation:
where
r is particle size,
rmim = 0.1
µm,
r = 10
µm, and C is constant representing the highest concentration of particles in a unit volume [
14]. Since the particles are distributed along the path length and our assumption included plane parallel atmosphere, the path length that is derived from particle sizes
dr in a unit volume is given in terms of the solar zenith angle by the following [
13]:
where
θ is the solar zenith angle,
drm is the path length in the vertical direction. The scattering coefficient decreases exponentially with respect to the altitude Z up to three kilometers [
15,
16,
17], and from Equations (13), (20), (21), and (22) we have the following equation:
From Equations (19), (21) and (22) we have the following equation:
where H is the scale height which equal 0.8 in a clear sky condition [
6]. Equation 24 represents the derived scattering coefficient in terms of the particle efficiencies and solar zenith angle which is substituted in Equation 15 which represents the error in pixel value
Wij due to the scattering effect and is converted to radiance units using the conversion formula.
2.3. Training Set Data Development and Testing
The overall objective of the training set selection process is to assemble a set of statistics that describes the spectral response pattern for each land cover type. The actual classification of multispectral image data is a highly automated process which uses the training data for classification [
18]. We obtained samples of the necessary training sets within the image by using the training set signature editor in ENVI 4.4 (commercial software) where a reference cursor on the screen was used to manually delineate training area polygons in the displayed image. The pixel values within the polygons were used in the software to develop a statistical description file for each training area. The training set development incorporates GPS ground truth reference data since it requires substantial reference data and a thorough knowledge of the geographical area [
19]. Neural network is an automated classifier in ENVI 4.4 which uses the statistical description file and the ground truth reference data file for the classification process [
19].
A set of GPS ground truth reference data were collected from the study area of Nicolet forestland vegetations in northern Wisconsin (wetland for shrub swamp, sedge meadow and upland opening shrub) using GPS single point positioning technique. The single point positioning technique utilizes pseudo-range measurements to determine positions of vegetation classes in UTM coordinates accurately. The UTM coordinates file of different vegetation types was converted to POLYGRID file format, then to ERDAS GIS file. The GIS file of the ground truth reference data was imported to ERDAS IMAGINE as an image file. This file was used in the processes of the training set development, classification, and accuracy assessment (contains 100% accurate positions of vegetations) [
20].
The accuracy improvements are the result of iterative parameterizations of the atmospheric correction using the classification accuracy as the goal. In the pre-processing stage, a portion of the training data were randomly selected and used in the iterative process to simulate the aerosol size distribution constant; to compute the scattering efficiencies, and the scattering coefficients; and to correct for the atmospheric scattering throughout the image. In the post-processing stage, another portion of the training data (independent training sets) was employed to compare the class accuracy between corrected and uncorrected images through sequence of classifications and accuracy assessments.
In both stages, the accuracies of classifications were assessed using the error/covariance matrices (classification results). This is done by comparing the accuracy criteria of the error/covariance matrices of the corrected image with the original image (image prior to correction) and incorporating GPS reference points. The accuracy criteria include the overall accuracy,
(Kappa/KHAT statistics), and Z-Score. The overall accuracy is computed by dividing the total number of correctly classified pixels (i.e., the sum of the elements along the major diagonal of the error matrix) by the total number of reference pixels. The
statistics is a measure of the difference between the actual agreement between reference data and automated classifier, and the chance agreement between the reference data and an automated classifier [
1] as in the following:
This statistic serves as an indicator of the extent to which the percentage of correct values in an error matrix is due to true agreement versus chance agreement. The value for
varies between 0 (poor classification) and 1 (ideal classification). A higher
indicates that the data are more separable. Z-score is the statistical test, which follows a Gaussian distribution and is used to determine whether the accuracy of the two classifications is significantly different. If the Z-score exceeds 1.96, then the difference between accuracies of the two classifications of the corrected and the original image is considered significant [
21].
2.4. Algorithm and Atmospheric Correction Method
In our approach, we used a large image from the Northern Hemisphere. This is based on the fact that the solar zenith angle in the Northern Hemisphere remains larger than about 60° throughout the year [
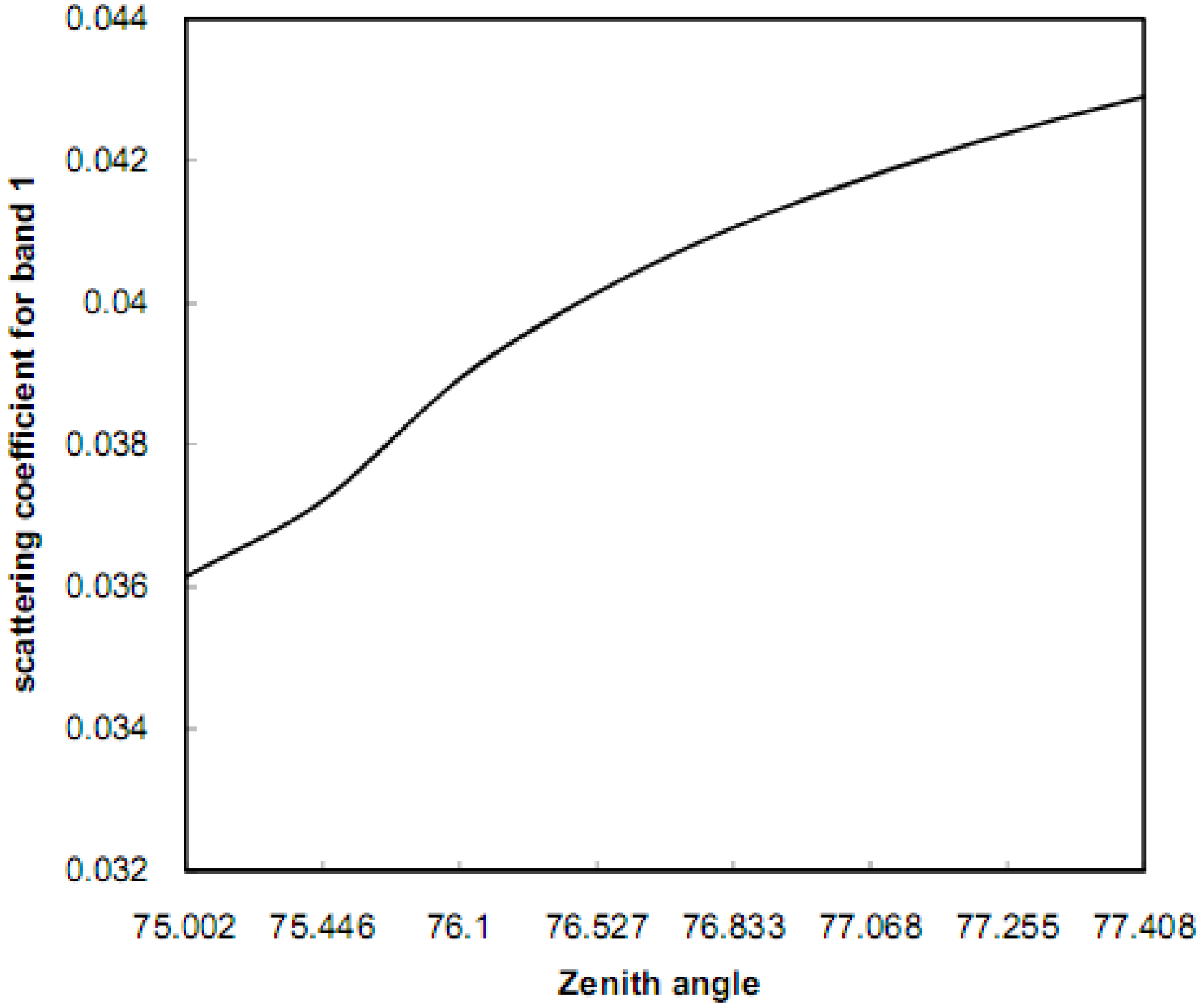
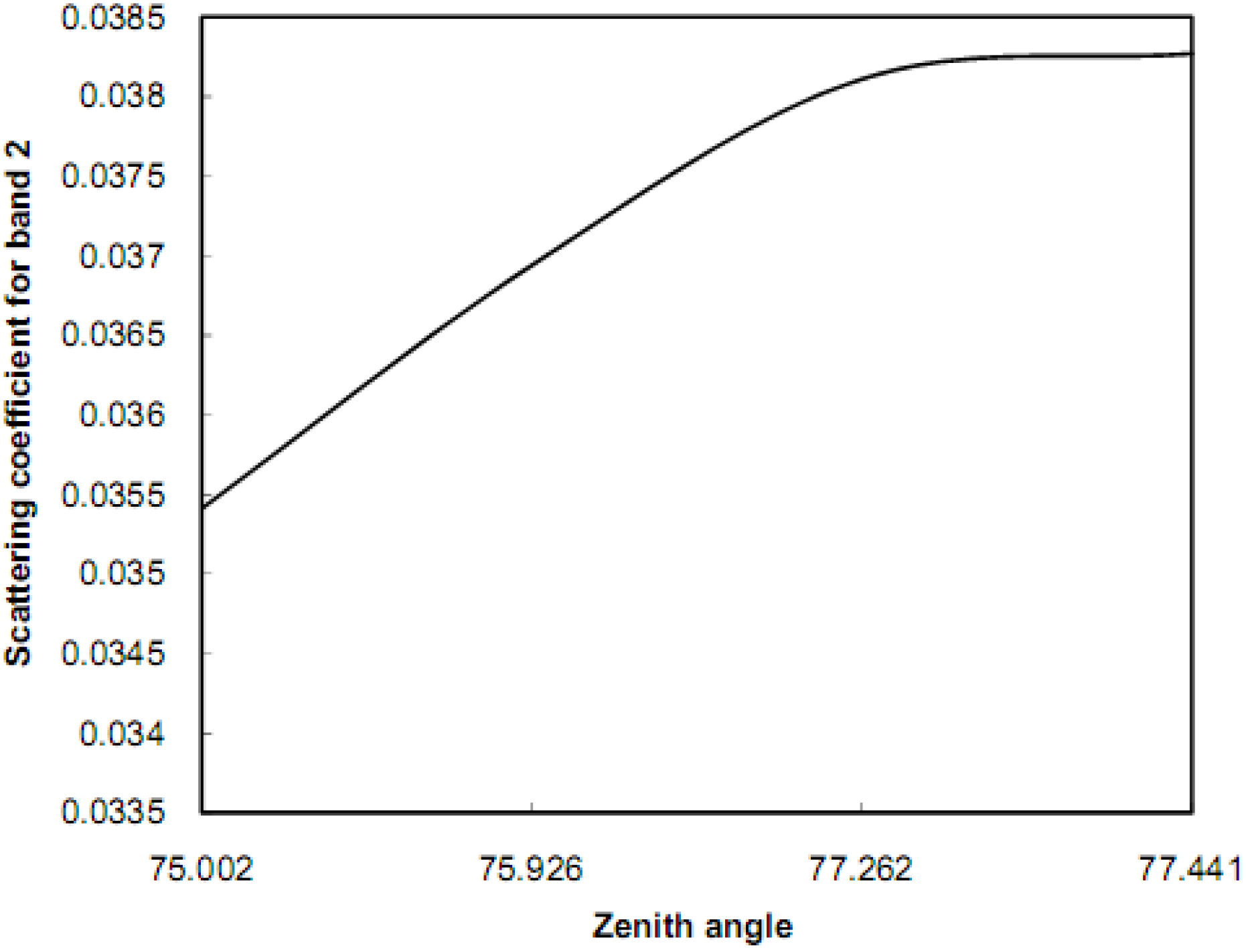
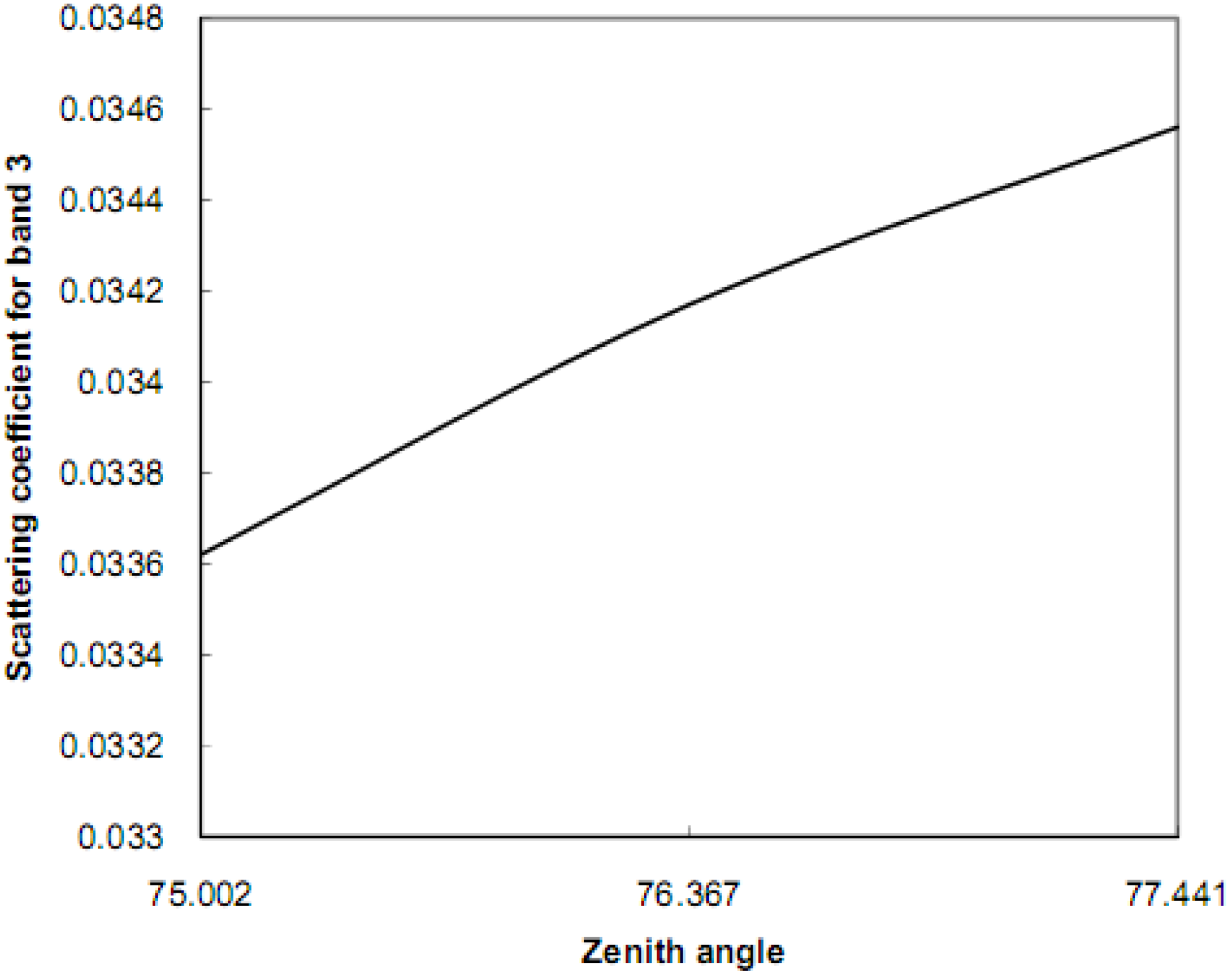
10]. Significant scattering can exist for the solar zenith angle larger than 60° (between 75° and 77° for this aerosol model) [
11]. Since the size of the solar zenith angle depends on the latitude, the variation in the solar zenith angle occurs when the scene is large with respect to the latitude direction. Equations 11, 12, 16-21, and 24 were used in the algorithm (in C++) to correct for atmospheric scattering. The variable parameters across the scene are the solar zenith angle and the scattering coefficient. The path length of the solar radiation relies on the scattering coefficients. The scattering coefficient can be computed by using the particles’ efficiencies and size distribution [
22]. While the optical properties of single particles such as shape, size, and complex index of refraction are arbitrary according to Mie Particle Theory, the particles’ efficiencies can be computed using sequences of iterations. The size distribution of aerosol particles can be determined by using particles sizes that are less or comparable to the image wavelengths (Mie Particle Theory) and by determining the constant of the size distribution (see Equation 21). The constant of the size distribution of aerosols particles can be determined by starting at an initial value and applying sequences of iterations throughout the correction process. The optimum correction can potentially enhance the classification accuracy of training data substantially resulting in a reduction in the number of misclassified pixels. The steps of the algorithm are outlined as follows:
Step 1 Computation of Atmospheric Input Parameters
Arbitraryinitial values for the index of refractions and the full range of aerosol particle sizes between 0.1microns and the sensor’s bandwidths (0.5–0.7 microns) were used as input values to compute the scattering efficiencies (Equation 20).
Using latitude at the upper left corner of the image, the solar zenith angles were computed for the entire image using the hour angle and the declination of sun.
Step 2 Input Measurements
GPS ground truth data were imported as an image file using ERDAS IMAGINE 8.7 and overlaid on the TM image.
Two categories of training sets were used: the first category was a group of randomly selected training sets for the pre-processing stage and the second category was a group of independent training sets for the post-processing stage. The randomly selected training sets in the pre-processing stage were used for the iterative parameterization of the correction throughout the image. The independent training sets in the post-processing stage were used for the sequences of classifications and accuracy assessments.
Step 3 Pre-processing Stage of Iterations and Simulation
The pixel values throughout the image were converted to radiances prior to the correction process.
The size distribution was computed (Equation 21) using initial value for the size distribution constant.
The scattering coefficient was computed for each pixel throughout the image (Equation 24) using scattering efficiencies (Equation 20), size distribution (Equation 21), and solar zenith angle.
The aerosol scattering effect for each pixel (error per pixel) was computed for each pixel (Equation 12).
The atmospheric errors were subtracted from all pixels throughout the image.
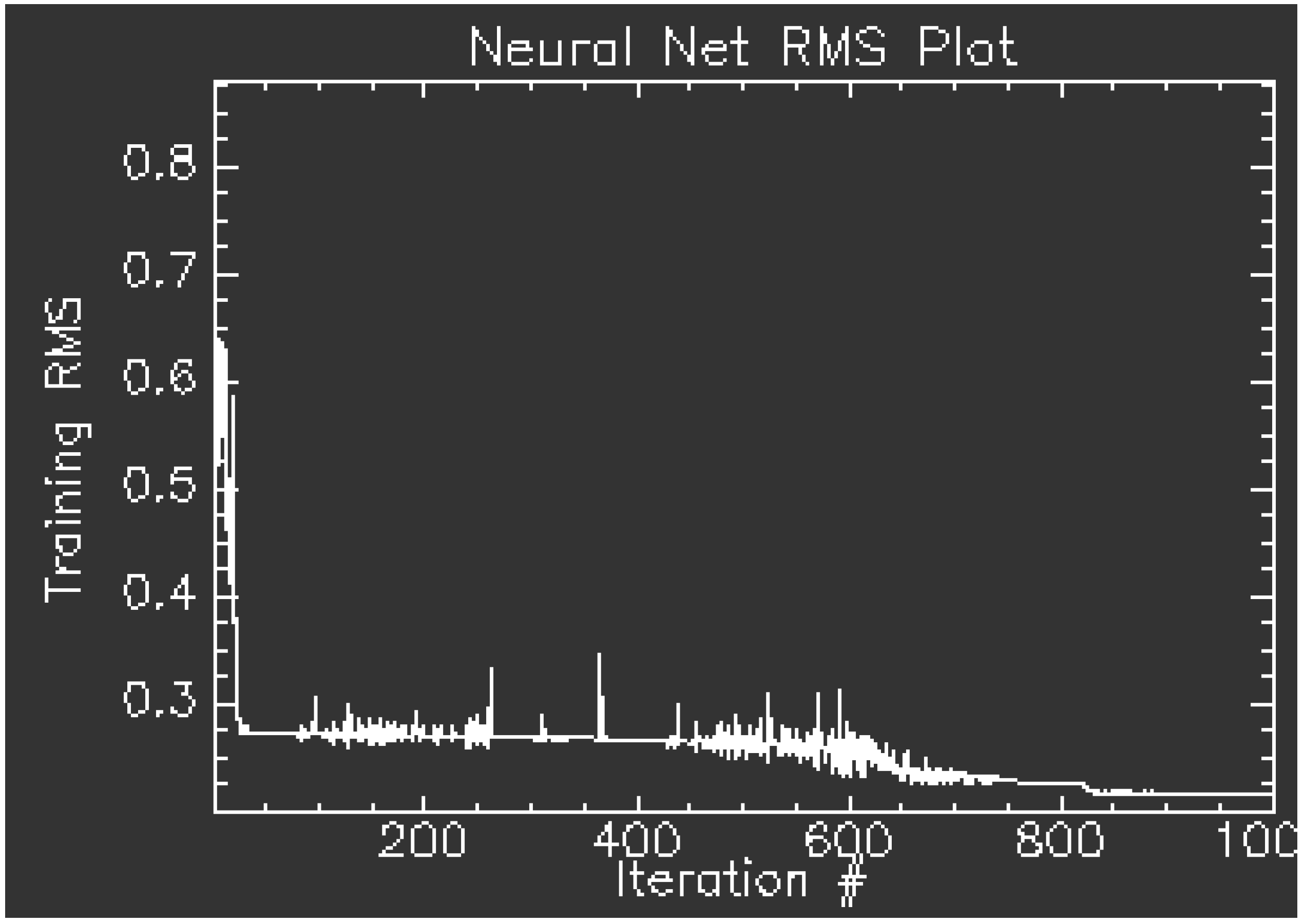
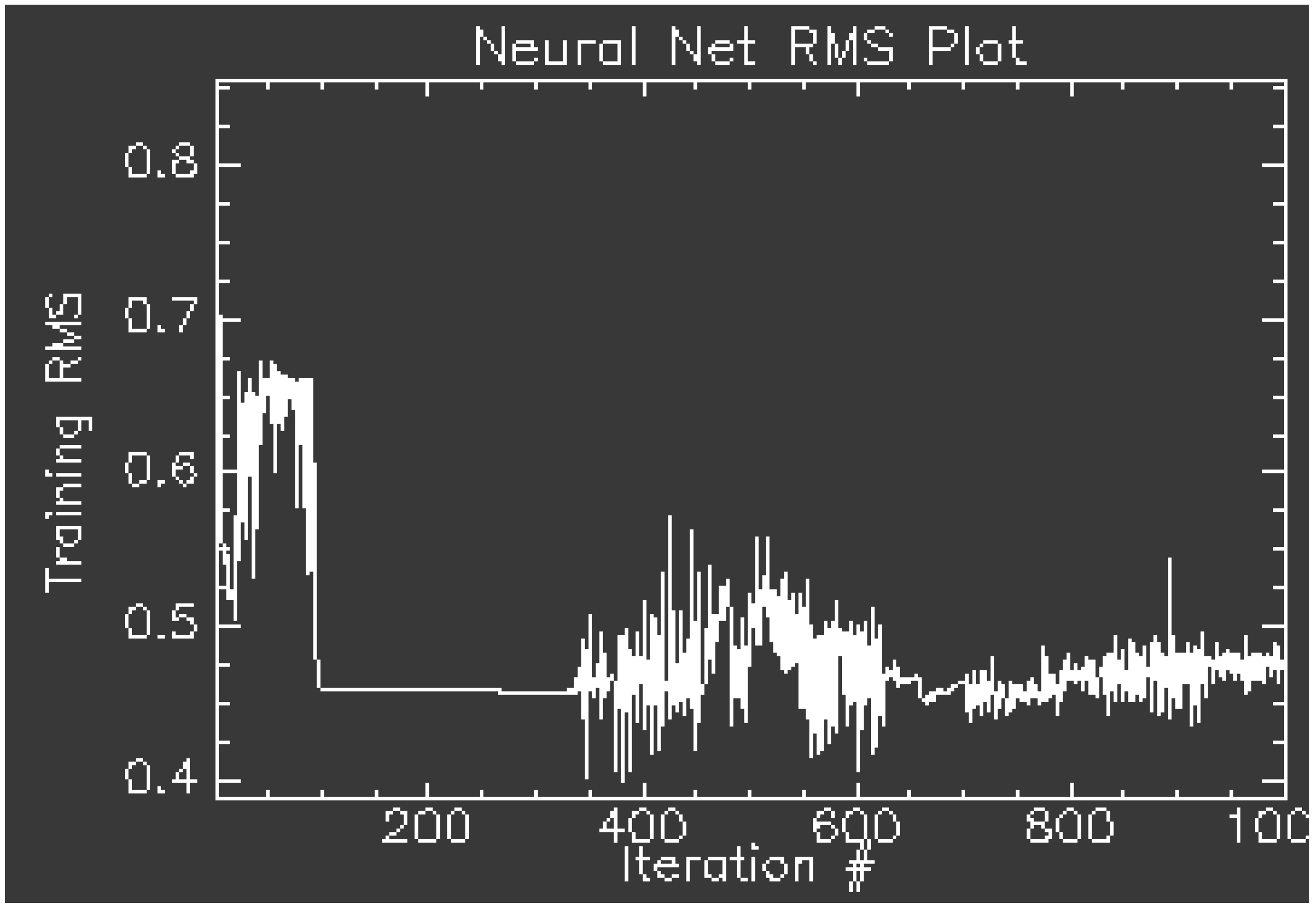
By using the randomly selected training set, the imaged was classified using neural network classifier at each iteration stage.
The classification accuracy of the corrected image was compared with the classification accuracy of the original image (prior to correction) using the error /covariance matrices incorporating the ground truth reference points.
If the accuracy was not improved, the algorithm would be repeated.
The iterations continued until reaching the optimum accuracy relative to the aerosol model.
The histogram and scatter plot of the image were checked at each iteration stage to avoid image distortion.
Step 4 Post-processing stage
The learning algorithm in FORTRAN (Spherical Particle) was used to compute the scattering efficiencies using the arbitrary initial values for the particle sizes (between 0.1 microns and the image bandwidth (0.5-0.7 microns), Mie Particle Theory and the complex indices of refractions [
22]. Sequences of iterations were used to simulate the size distribution constant C. The C++ algorithm uses the output values of the scattering efficiencies as input values to compute the scattering coefficients and the scattering effect
Wij (error per pixel, see Appendix A). We employed training samples of the vegetation classes (Nicolet vegetation cover) within the image to be classified at each iteration stage using a neural network classifier. The iterations and the process of subtraction of
Wij from each pixel continued until the number of misclassified off-diagonal pixels of the error matrices (classification results) were reduced and optimized relative to the aerosol model. This process is based on comparing the criteria of the classification accuracies of the two images (corrected and original-uncorrected) and incorporating GPS reference points. In the post-processing step, sequences of classifications and accuracy assessments were implemented using independent training samples (different from those that were used for the iteration steps). Throughout the iterations, extreme correction and subtraction of the error from each pixel value (in radiance unit) can be avoided so that the image distortion would not occur [
23,
24,
25]. This is done by checking the histogram and scatter plot of the image at each iteration stage. The iterations should stop at the optimum correction that leads to substantial enhancement in classification accuracy. If the enhancement of classification accuracy was achieved, the training data would be more separable in the error/covariance matrices. A higher
indicates that the data are more separable.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}