Monitoring Water Surface and Level of a Reservoir Using Different Remote Sensing Approaches and Comparison with Dam Displacements Evaluated via GNSS






Abstract
:
1. State of Art and Introduction
2. Theory and Methods
2.1. Radiometric Calibration of Remote Sensing Data
2.1.1. Pixel Aggregate on SAR Images
2.1.2. Visual Matching
2.1.3. Classification
2.2. GNSS Processing
3. Study Area
4. Materials
4.1. Optical and SAR Remote Sensing Images
4.2. GNSS Time-Series
5. Results and Discussion
5.1. Remote Sensing
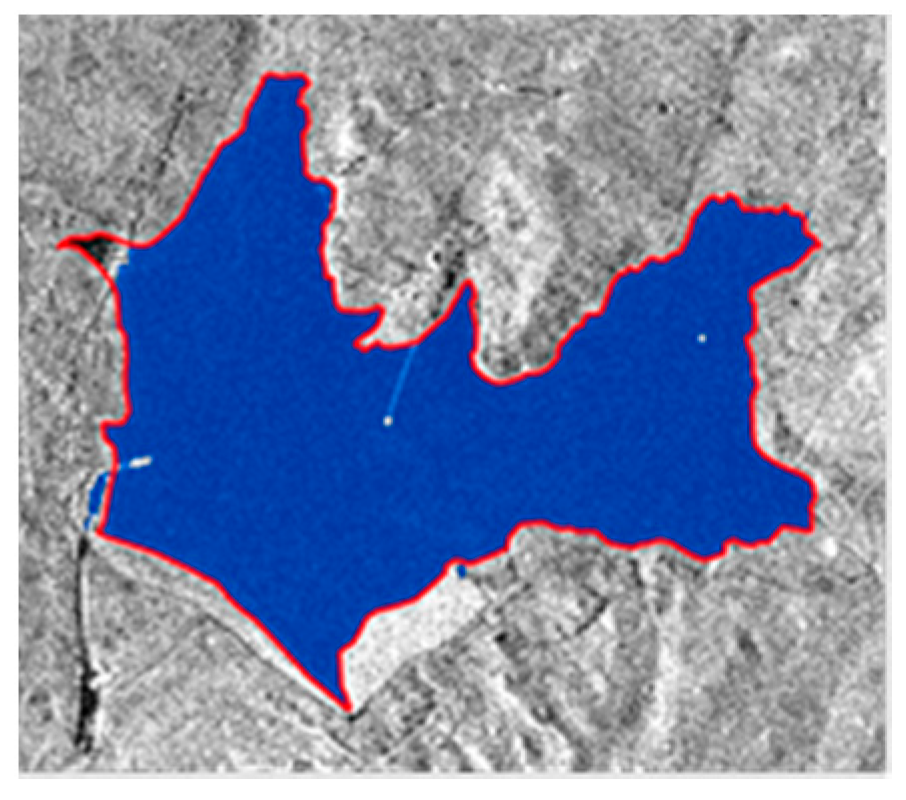
5.1.1. Pixel Aggregate of SAR and Optical Images
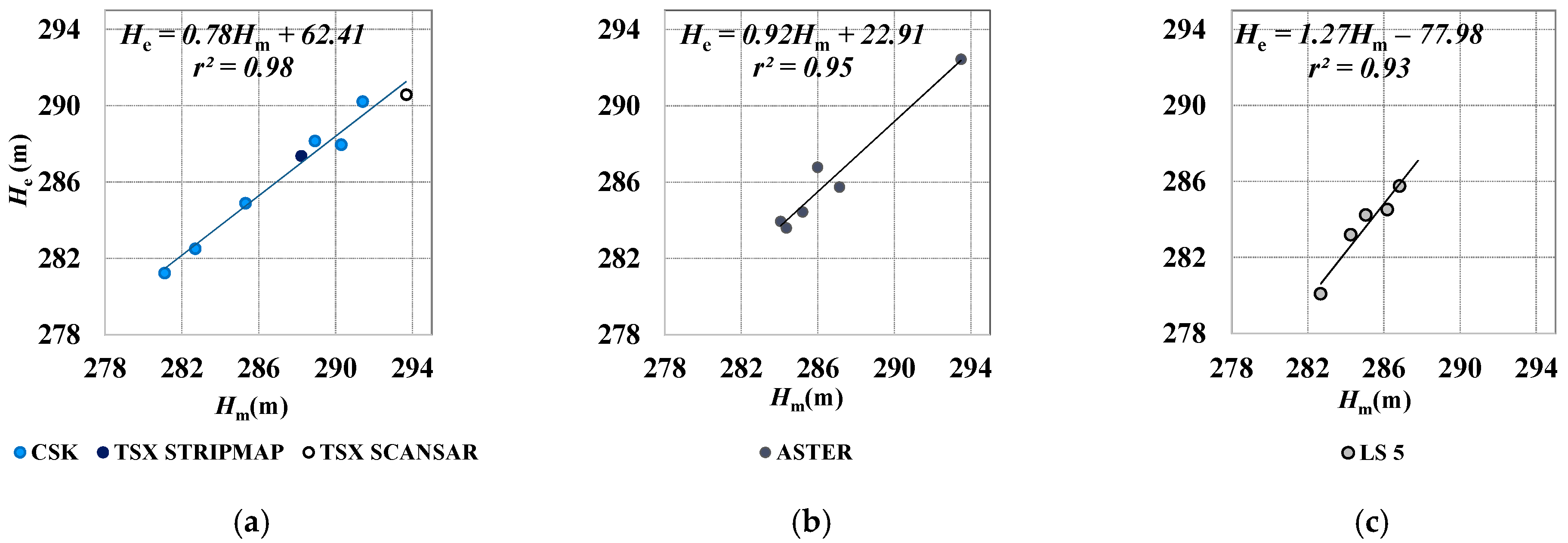
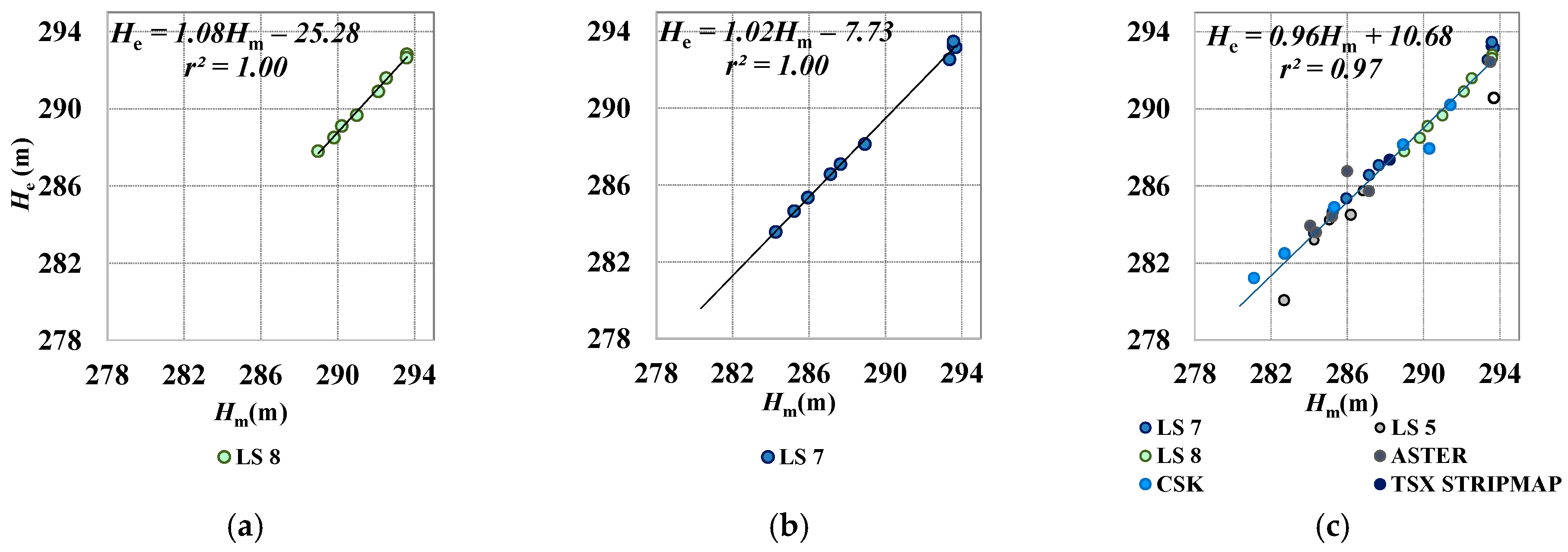
5.1.2. Visual Matching
Visual Matching at Full Spatial Resolution
Visual Matching with Improved Spatial Resolution (Resolution Merge)
5.1.3. Classification
5.2. GNSS
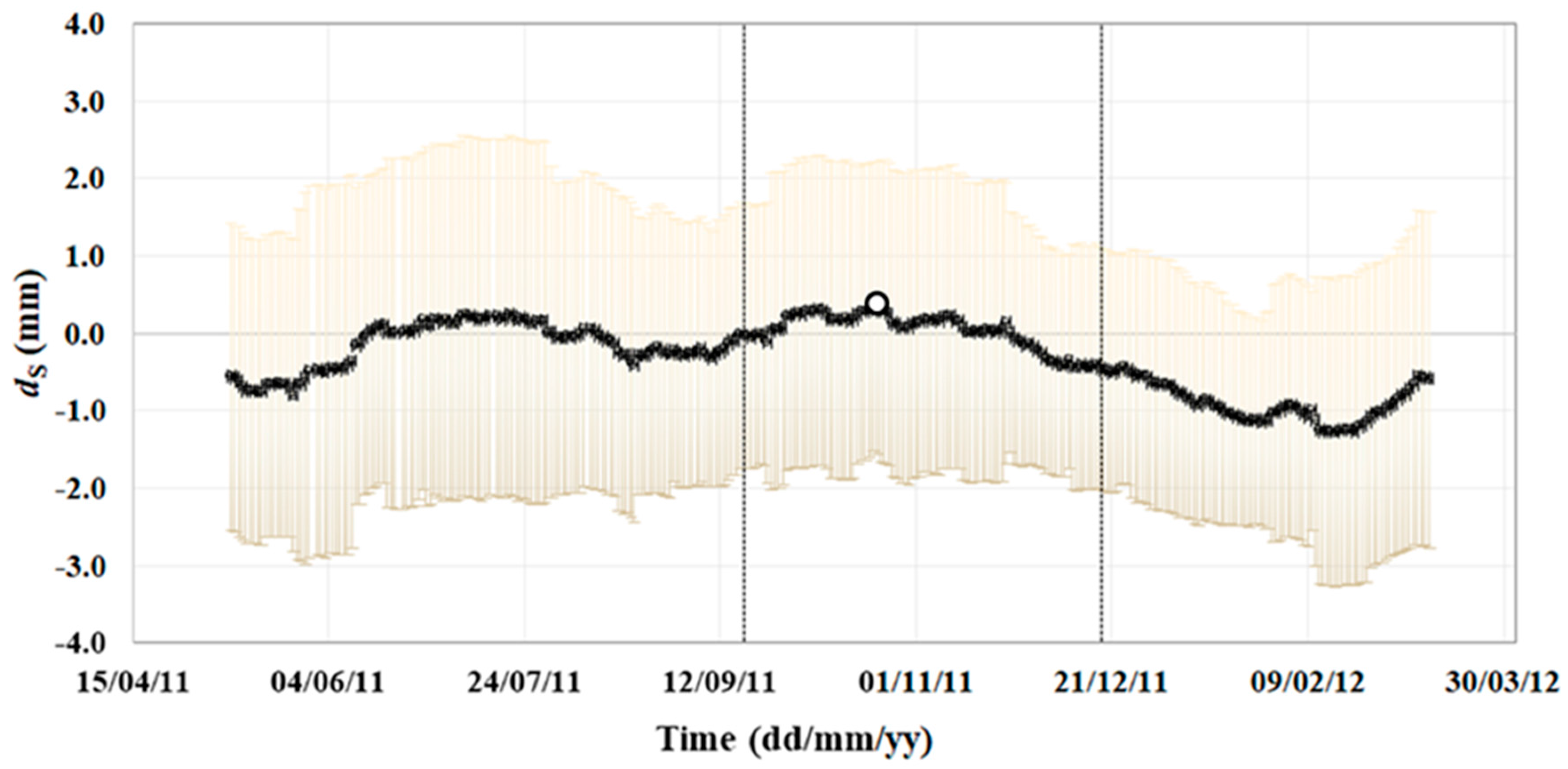
5.3. Comparison between Displacements and Water Levels
6. Conclusions and Recommendations
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Szostak-Chrzanowski, A.; Massiéra, M. Modelling of deformations during construction of a large earth dam in The La Grande Complex, Canada. Tech. Sci. 2004, 7, 109–122. [Google Scholar]
- Drummond, P. Combining Cors Networks, Automated Observations and Processing, for Network Rtk Integrity Analysis and Deformation Monitoring. In Proceedings of the 15th FIG Congress Facing the Challenges-Building the Capacity, Sydney, Australia, 11–16 April 2010. [Google Scholar]
- Taşçcedil, L. Analysis of dam deformation measurements with the robust and non-robust methods. Sci. Res. Essays 2010, 5, 1770–1779. [Google Scholar]
- Duffy, M.; Hill, C.; Whitaker, C.; Chrzanowski, A.; Lutes, J.; Bastin, G. An automated and integrated monitoring program for Diamond Valley Lake in California. In Proceedings of the 10th FIG International Symposium on Deformation Measurements, Orange, CA, USA, 19–22 March 2001. [Google Scholar]
- Tarsisius Aris, S.; Kabul Basah, S.; Fakrurazzi, D.; Adin, S.; Adhi, D.; Susilo, A. Design and installation for Dam Monitoring Using Multi sensors: A Case Study at Sermo Dam, Yogyakarta Province, Indonesia. In Proceedings of the FIG Working Week 2012, Knowing to Manage the Territory, Protect the Environment, Evaluate the Cultural Heritage, Rome, Italy, 6–10 May 2012. [Google Scholar]
- Bayrak, T. Verifying Pressure of Water on Dams, a Case Study. Sensors 2008, 8, 5376–5385. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalkan, Y. Geodetic deformation monitoring of Ataturk Dam in Turkey. Arab. J. Geosci. 2014, 7, 397–405. [Google Scholar] [CrossRef]
- Yigit, C.O.; Alcay, S.; Ceylan, A. Displacement response of a concrete arch dam to seasonal temperature fluctuations and reservoir level rise during the first filling period: evidence from geodetic data. Geomat. Nat. Hazards Risk 2016, 7, 1489–1505. [Google Scholar] [CrossRef]
- Gao, H.; Birkett, C.; Lettenmaier, D.P. Global monitoring of large reservoir storage from satellite remote sensing. Water Resour. Res. 2012, 48, W09504. [Google Scholar] [CrossRef]
- Kleine, I.; Rogass, C.; Medeiros, P.H.A.; Erpen, N.M.; Francke, T.; Bronstert, A.; Förster, S. Comparison of approaches for water surface area segmentation using high resolution TerraSAR-X data for reservoir monitoring in a large semi-arid catchment in north eastern Brazil. In Proceedings of the 2013 SPIE Remote Sensing, Dresden, Germany, 23–26 September 2013. [Google Scholar]
- Sima, S.; Tajrishy, M. Using satellite data to extract volume-area-elevation relationships for Urmia Lake, Iran. J. Great Lakes Res. 2013, 39, 90–99. [Google Scholar] [CrossRef]
- Crétaux, J.-F.; Bergé-Nguyen, M.; Calmant, S.; Romanovski, V.V.; Meyssignac, B.; Perosanz, F.; Tashbaeva, S.; Arsen, A.; Fund, F.; Martignago, N.; et al. Calibration of Envisat radar altimeter over Lake Issykkul. Adv. Space Res. 2013, 51, 1523–1541. [Google Scholar] [CrossRef]
- Birkett, C.M.; Beckley, B. Investigating the performance of the Jason-2/OSTM Radar Altimeter over Lakes and Reservoirs. Mar. Geodesy 2010, 33, 204–238. [Google Scholar] [CrossRef]
- Shimizu, N. Rock Displacement Monitoring using Satellite Technologies-GPS and InSAR. In Proceedings of the ISRM VietRock International Workshop, Hanoi, Vietnam, 12–13 March 2015. [Google Scholar]
- Lazecky, M.; Perissin, D.; Lei, L.; Qin, Y.; Scaioni, M. Plover Cove Dam Monitoring with Spaceborne InSAR Technique in Hong Kong. In Proceedings of the 2nd Joint International Symposium on Deformation Monitoring (JISDM), Nottingham, UK, 9–10 September 2003. [Google Scholar]
- Dardanelli, G.; La Loggia, G.; Perfetti, N.; Capodici, F.; Puccio, L.; Maltese, A. Monitoring displacements of an earthen dam using GNSS and remote sensing. In Proceedings of the 2014 SPIE Remote Sensing, Amsterdam, The Netherlands, 22–25 September 2014. [Google Scholar]
- Dardanelli, G.; Pipitone, C. Hydraulic models and finite elements for monitoring of an earth dam, by using GNSS techniques. Period. Polytech. Civ. Eng. 2017, 61, 421–433. [Google Scholar] [CrossRef]
- Thome, K.; Markham, B.; Barker, J.; Slater, P.; Biggar, S. Radiometric calibration of Landsat. Photogramm. Eng. Remote Sens. 1997, 63, 853–858. [Google Scholar]
- Epema, G.F. Effect of moisture content on spectral reflectance in a playa area in Southern Tunisia. In Proceedings of the International Symposium Remote Sensing and Water Resources, Enschede, The Netherlands, 20–24 August 1990; pp. 301–308. [Google Scholar]
- Airbus Defence & Space. Radiometric Calibration of TerraSAR-X Data-Beta Naught and Sigma Naught Coefficient Calculation. Document: TSXX-ITD-TN-0049-radiometric_calculations_I3.00.doc. March 2014. Available online: https://spacedata.copernicus.eu/documents/12833/14537/TerraSAR-X_RadiometricCalculations (accessed on 5 January 2018).
- E-Geos. COSMO SkyMed Image Calibration. Document: COSMO-SkyMed-Image_Calibration.pdf. Available online: http://www.e-geos.it/products/pdf/COSMO-SkyMed-Image_Calibration.pdf (accessed on 3 January 2017).
- Ciraolo, G.; Cox, E.; La Loggia, G.; Maltese, A. The classification of submerged vegetation using hyperspectral MIVIS data. Ann. Geophys. 2006, 49, 287–294. [Google Scholar]
- Welch, R.; Ehlers, W. Merging Multiresolution SPOT HRV and Landsat TM Data. Photogramm. Eng. Remote Sens. 1987, 53, 301–303. [Google Scholar]
- Tou, J.T.; Gonzalez, R.C. Pattern Recognition Principles; Addison-Wesley Publishing Company: Reading, MA, USA, 1974; pp. 97–104. [Google Scholar]
- Jensen, J.R. Introductory Digital Image Processing; Prentice-Hall: Englewood Cliffs, NJ, USA, 1986; p. 379. [Google Scholar]
- Liebe, J.R.; van de Giesen, N.; Andreini, M.S.; Steenhuis, T.S.; Walter, M.T. Suitability and Limitations of ENVISAT ASAR for Monitoring Small Reservoirs in a Semiarid Area. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1536–1547. [Google Scholar] [CrossRef]
- Saastamoinen, J. Atmospheric correction for troposphere and stratosphere in radio ranging of satellites. In The Use of Artificial Satellites for Geodesy; Henriksen, S.W., Mancini, A., Chovitz, B.H., Eds.; AGU: Washington, WA, USA, 1972; Volume 15, pp. 247–252. [Google Scholar]
- Niell, A.E. Global mapping functions for the atmosphere delay at radio wavelengths. J. Geophys. Res. 1996, 101, 3227–3246. [Google Scholar] [CrossRef]
- Klobuchar, J.A. Ionospheric Effects on GPS. In Global Positioning System: Theory and Applications; American Institute of Aeronautics and Astronauitc: Reston, VA, USA, 1996; Chapter 12; Volume 1, pp. 485–515. [Google Scholar]
- Schwiderski, E.W. On charting global ocean tides. Rev. Geophys. Space Physics. 1980, 18, 243–268. [Google Scholar] [CrossRef]
- De Martino, P.; Tammaro, U.; Obrizzo, F.; Sepe, V.; Brandi, G.; D’Alessandro, A.; Pingue, M.D.E.F. The GPS network of Ischia Island: Ground deformations in an active volcanic area (1998–2010). Quad. Geofis. 2011, 95, 95. [Google Scholar] [CrossRef]
- Panza, G.F.; Peresan, A.; Magrin, A.; Vaccari, F.; Sabadini, R.; Crippa, B.; Marotta, A.M.; Splendore, R.; Barzaghi, R.; Borghi, A.; et al. The SISMA prototype system: Integrating Geophysical Modeling and Earth Observation for time-dependent seismic hazard assessment. Nat. Hazards 2013, 69, 1179–1198. [Google Scholar] [CrossRef]
- Fermi, M.; Caldera, S.; Chersich, M.; Osmo, M. Validazione del software NDA Professional per la compensazione di reti di stazioni permanenti GNSS. In Proceedings of the 14a Conferenza Nazionale ASITA, Brescia, Italy, 9–12 November 2010. [Google Scholar]
- Dardanelli, G.; Sciortino, M. Time series analysis in the UNIPA NRTK GNSS network. In Proceedings of the 5th International Conference and Exhibition, Melaha, Location Technologies and Solutions: The Next Frontier, Cairo, Egypt, 3–5 May 2010. [Google Scholar]
- Dardanelli, G.; Franco, V.; Lo Brutto, M. La rete GNSS per il posizionamento in tempo reale dell’Università di Palermo: progetto, realizzazione e primi risultati. Boll. SIFET 2008, 2, 107–124. [Google Scholar]
- Italian Space Agency. COSMO-SkyMed. Document: ASI-CSM-PMG-NT-001 COSMO-SkyMed Mission and Products Description.pdf. Available online: http://www.e-geos.it/images/documents/COSMO-SkyMed%20Mission%20and%20Products%20Description.pdf (accessed on 3 January 2017).
- Clemente-Colón, P.; Yan, X.H. Low-Backscatter Ocean Features in Synthetic Aperture Radar Imagery. Johns Hopkins APL Tech. Dig. 2000, 21, 116–121. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reservoir | Date (dd/mm/yyyy) | Reference Surface Si (km2) | Sensor |
|---|---|---|---|
| Guadalami | 01/05/2015 | 0.10 | GeoEye-1 |
| Castello | 25/08/2001 | 0.58 | Ikonos-2 |
| Lentini | 16/09/2011 | 9.29 | WorldView2 |
| Cosmo-SkyMed | |||||
|---|---|---|---|---|---|
| Date (dd/mm/yyyy) | Acquisition Time (UTC) | Look Direction (°CW from N) | Orbit Direction | Far Incidence Angle (°) | Near Incidence Angle (°) |
| 08/09/2011 | 17:15 | ≈11.17 | Descending | ≈28.28 | ≈24.90 |
| 08/02/2012 | 04:54 | ≈169.36 | Ascending | ≈33.85 | ≈30.78 |
| 15/02/2012 | 17:13 | ≈11.17 | Descending | ≈28.29 | ≈24.91 |
| 23/06/2012 | 04:53 | ≈169.52 | Ascending | ≈35.45 | ≈32.43 |
| 10/09/2012 | 17:11 | ≈11.18 | Descending | ≈28.28 | ≈24.90 |
| 13/10/2012 | 04:52 | ≈169.51 | Ascending | ≈35.45 | ≈32.44 |
| TerraSAR-X | ||||||
|---|---|---|---|---|---|---|
| Date (dd/mm/yyyy) | Acquisition Time (UTC) | Look Direction (°CW from N) | Orbit Direction | Far Incidence Angle (°) | Near Incidence Angle (°) | Acquisition Mode |
| 22/01/2011 | 16:57 | ≈ (169.78–169.54) | Ascending | ≈34.56 | ≈31.76 | Stripmap |
| 15/03/2012 | 16:57 | “ ” | Ascending | ≈40.40 | ≈31.76 | Scansar |
| RG (m) | ΔHL (m) | ΔHR (m) |
|---|---|---|
| 1.25 | 0.11 | 0.20 |
| 2.50 | 0.23 | 0.41 |
| 5.00 | 0.45 | 0.81 |
| 8.25 | 0.75 | 1.34 |
| 15.00 | 1.36 | 2.44 |
| 30.00 | 2.73 | 4.88 |
| 60.00 | 5.45 | 9.77 |
| SAR | ASTER | LS8 | LS5 | LS7 | ||
|---|---|---|---|---|---|---|
| RG | Stripmap 5.00 | Scansar 8.25 | 15.00 | 30.00 | 30.00 | 30.00 |
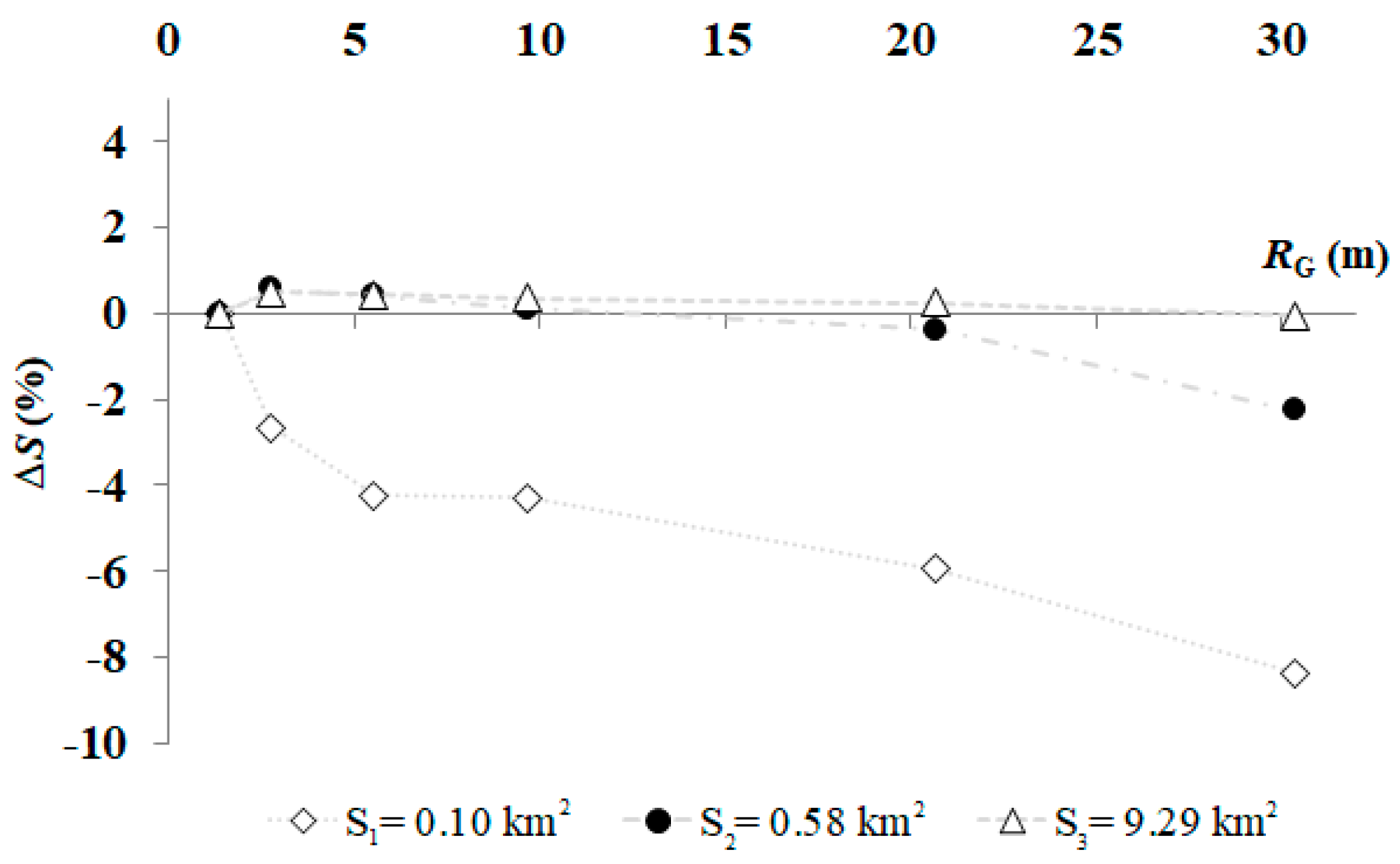
| Segmentation | −36.2 ± 16.9 | −2.5 | −2.9 ± 1.9 | −1.1 ± 1.5 | −0.5 ± 0.8 | −0.2 ± 0.3 |
| Clump | 4.8 ± 4.8 | 0.8 | ||||
| SAR | ASTER | LS8 | LS5 | LS7 | All Data | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M | C | M | C | M | C | M | C | M | C | M | C | |
| (8) | (8) | (8) | (6) | (9) | (8) | (6) | (5) | (21) | (10) | (52) | (37) | |
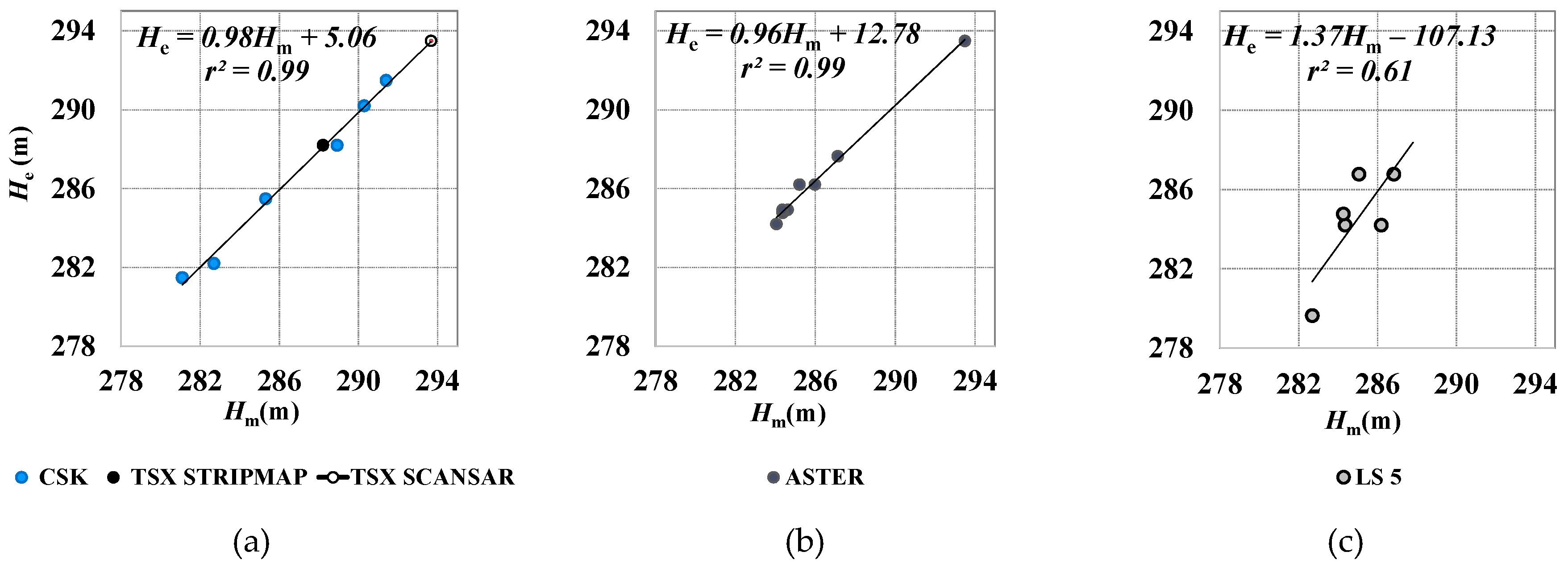
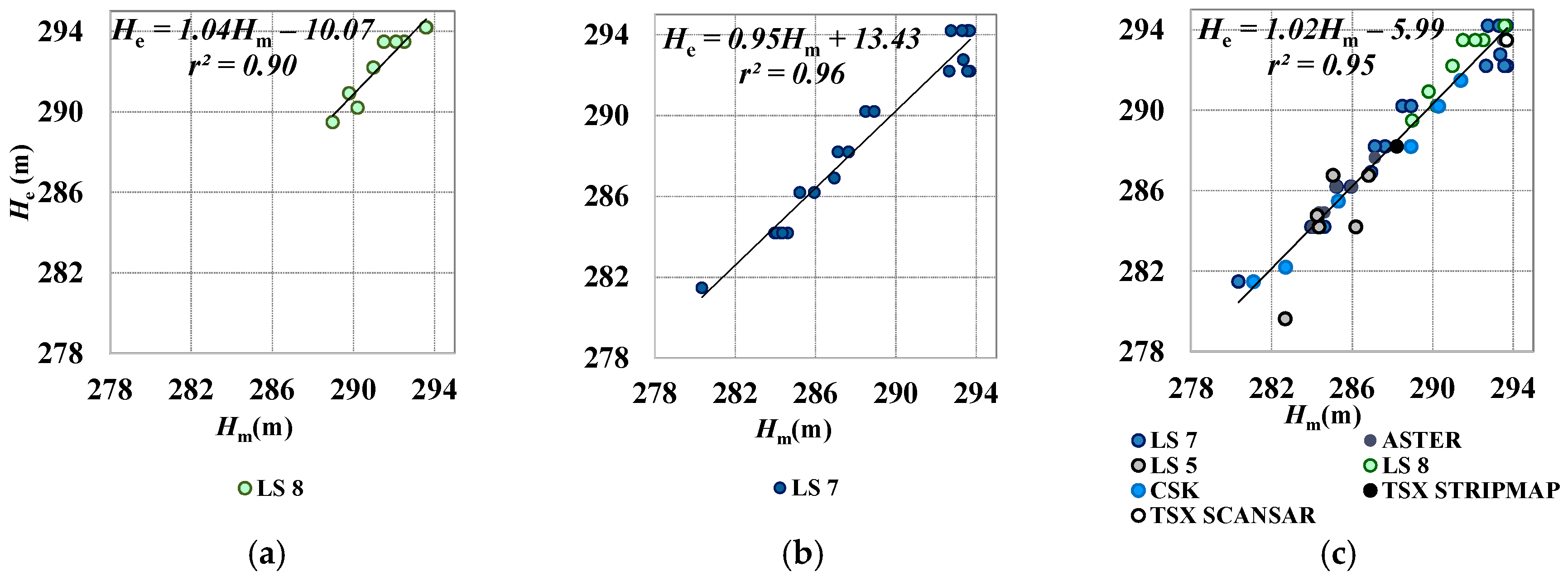
| m (−) | 0.98 | 0.78 | 0. 96 | 0.92 | 1.04 | 1.08 | 1.37 | 1.27 | 0.95 | 1.02 | 1.02 | 0.96 |
| q (m) | 5.06 | 62.41 | 12.78 | 22.91 | −10.07 | −25.28 | −107.13 | −77.98 | 13.43 | −7.73 | −5.99 | 10.68 |
| r (−) | 1.00 | 0.99 | 1.00 | 0.98 | 0.95 | 1.00 | 0.78 | 0.96 | 0.98 | 1.00 | 0.98 | 0.98 |
| S.E.(m) | 0.38 | 0.58 | 0.30 | 0.81 | 0.61 | 0.14 | 1.83 | 0.65 | 0.86 | 0.21 | 0.92 | 0.70 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pipitone, C.; Maltese, A.; Dardanelli, G.; Lo Brutto, M.; La Loggia, G. Monitoring Water Surface and Level of a Reservoir Using Different Remote Sensing Approaches and Comparison with Dam Displacements Evaluated via GNSS. Remote Sens. 2018, 10, 71. https://doi.org/10.3390/rs10010071
Pipitone C, Maltese A, Dardanelli G, Lo Brutto M, La Loggia G. Monitoring Water Surface and Level of a Reservoir Using Different Remote Sensing Approaches and Comparison with Dam Displacements Evaluated via GNSS. Remote Sensing. 2018; 10(1):71. https://doi.org/10.3390/rs10010071
Chicago/Turabian StylePipitone, Claudia, Antonino Maltese, Gino Dardanelli, Mauro Lo Brutto, and Goffredo La Loggia. 2018. "Monitoring Water Surface and Level of a Reservoir Using Different Remote Sensing Approaches and Comparison with Dam Displacements Evaluated via GNSS" Remote Sensing 10, no. 1: 71. https://doi.org/10.3390/rs10010071
APA StylePipitone, C., Maltese, A., Dardanelli, G., Lo Brutto, M., & La Loggia, G. (2018). Monitoring Water Surface and Level of a Reservoir Using Different Remote Sensing Approaches and Comparison with Dam Displacements Evaluated via GNSS. Remote Sensing, 10(1), 71. https://doi.org/10.3390/rs10010071