Change Detection in Hyperspectral Images Using Recurrent 3D Fully Convolutional Networks



Abstract
:
1. Introduction
1.1. Background of Hyperspectral Change Detection
1.2. Problem Statements
1.3. Contributions of the Paper
- (1)
- Our method is simple and effective in generating training samples. In many real cases, it is difficult to obtain training/testing samples by applying CD methods. The fusion of PCs obtained from multi-temporal images and the spectral correlation angle (SCA) [41] can produce more-representative samples that have high probabilities of either being changed or unchanged, for obtaining multivariate high accuracy. This improves the training of the network efficiency with fewer samples.
- (2)
- The method can also detect multi-class changes in an end-to-end manner. Most CD methods focus on binary CD to identify specific changes, but the proposed method can discriminate the nature changes in the sample-generation step. The proposed network can also learn the characteristics of the changed class effectively. Moreover, the Re3FCN can receive two images directly and perform the CD with no pre-treatment of the two input images.
- (3)
- The proposed method is effective in extracting spectral–spatial–temporal features of multi-temporal HSIs while maintaining spatial information using a fully convolutional structure. The 3D convolution is effective in exploiting the spectral–spatial information, and ConvLSTM can model the temporal dependency of multi-temporal images while maintaining the spatial structure. Thus, this study is a novel method which uses an FCN that includes 3D convolutional layers and an ConvLSTM for the hyperspectral CD.
2. Change Detection Methodology
- (1)
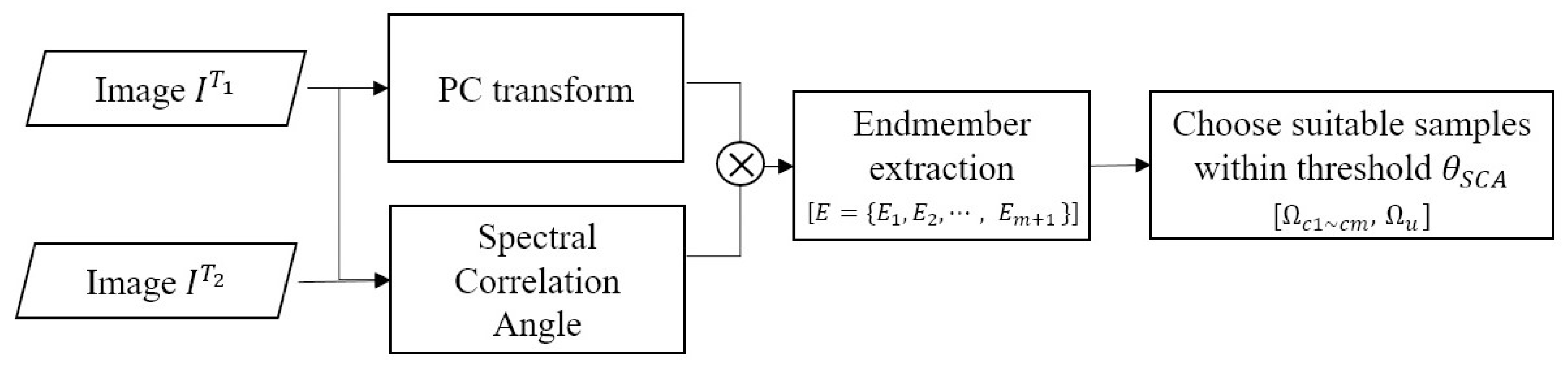
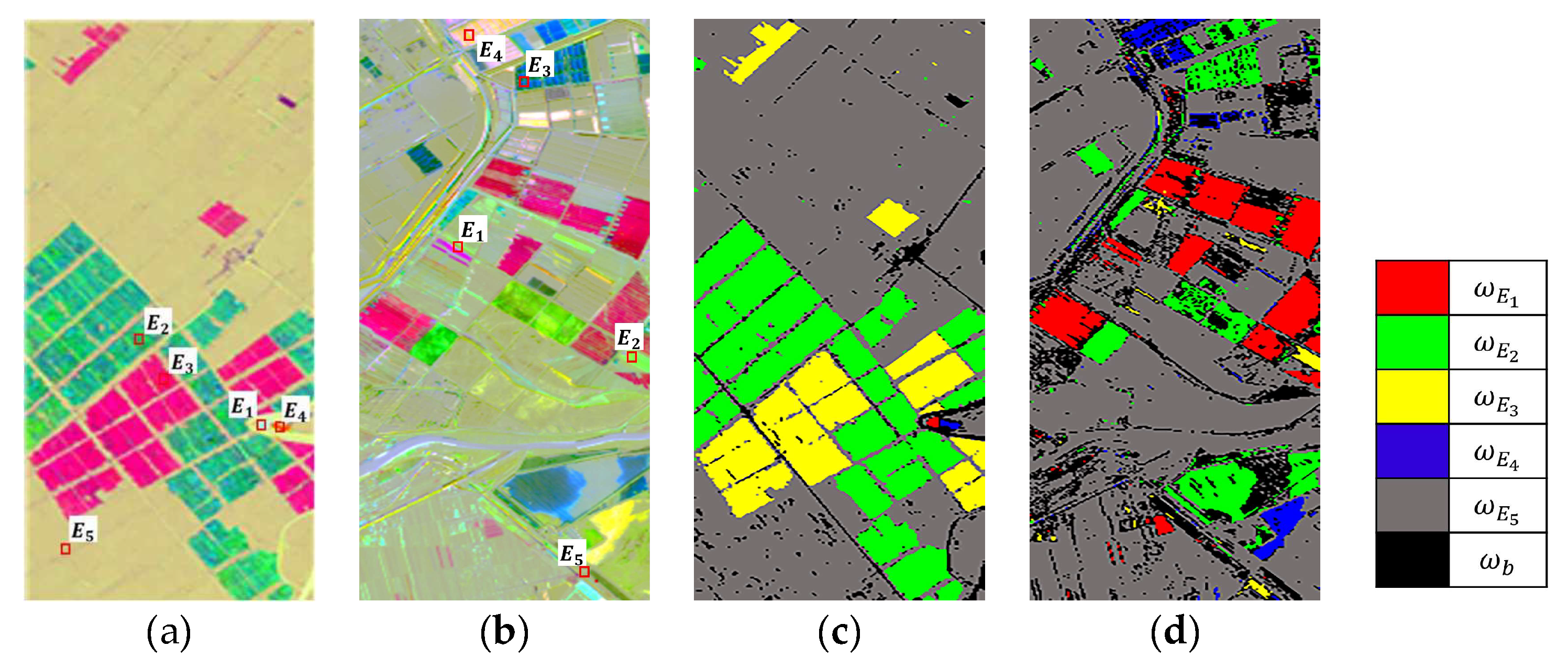
- Generating samples for network training using PCA and similarity measures. To identify multiple changes, a difference image (DI) was produced using PCA and the spectral similarity measure. The PCs and SCA were calculated using multi-temporal images and fused to form the DI. To select training samples of each class, the endmembers were extracted as a reference spectrum of each class. Finally, the pixels in which spectral angle was lower than the threshold were assigned to each endmember class. The samples were then selected randomly, and 3D image patches centered at each selected sample were fed into the Re3FCN network.
- (2)
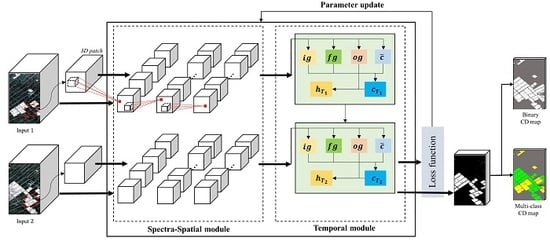
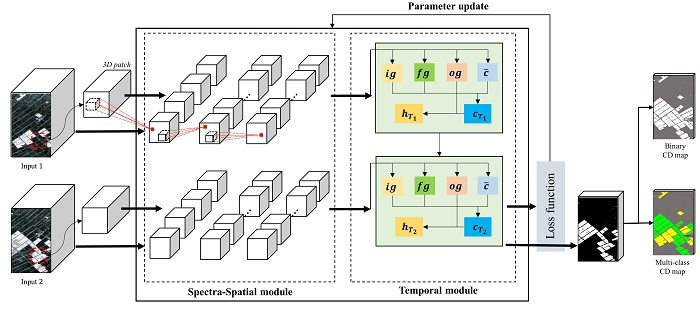
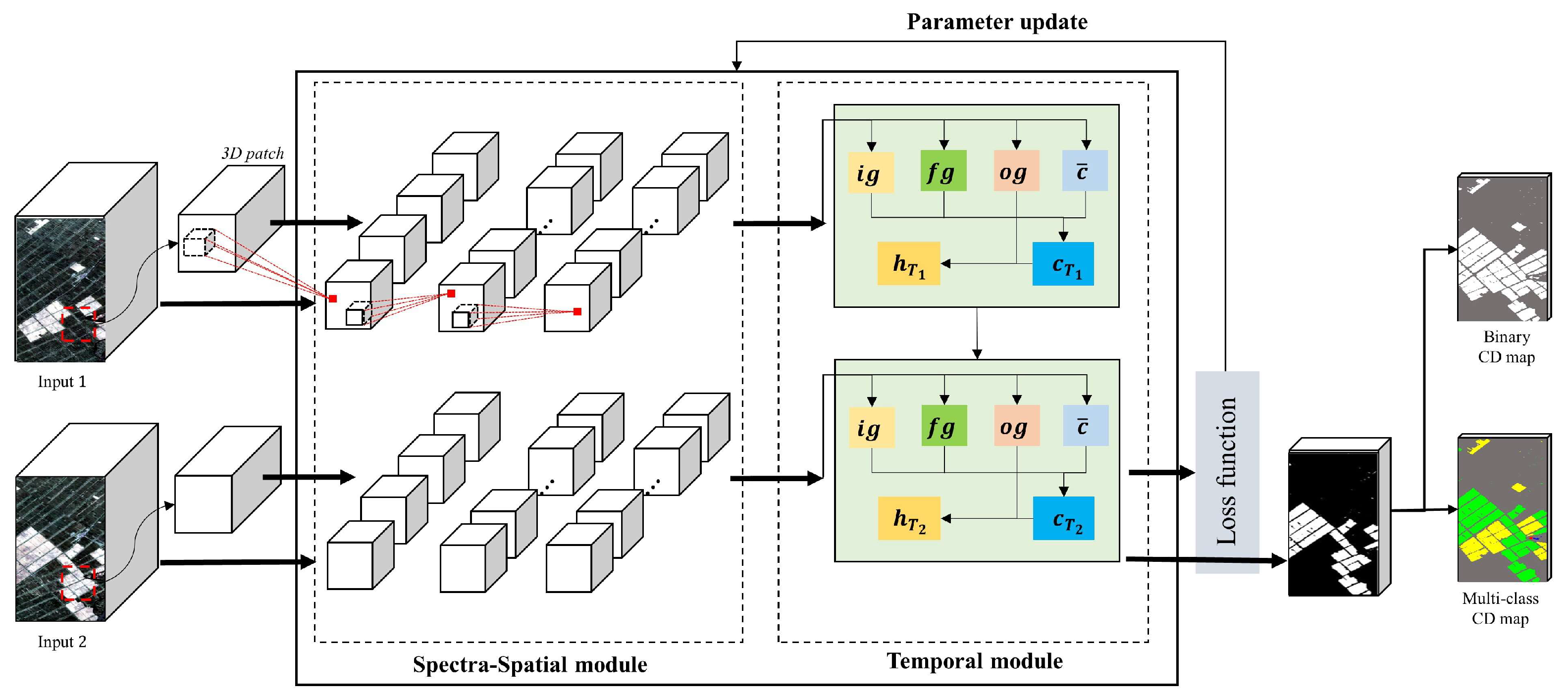
- Training the Re3FCN and producing the CD map. The 3D patches obtained from each image passed through the 3D convolutional layer to extract spectral and spatial information, whereupon the spectral–spatial feature maps were fed into the ConvLSTM layer. In this phase, the temporal information between two images was reflected. The output of the ConvLSTM layer was fed into the prediction layer to generate the score map. The number of final feature maps equaled the number of classes. Finally, the pixels were classified to the final classes according to the score map.
2.1. Sample Generation
2.2. Training Re3FCN and Producing CD Map
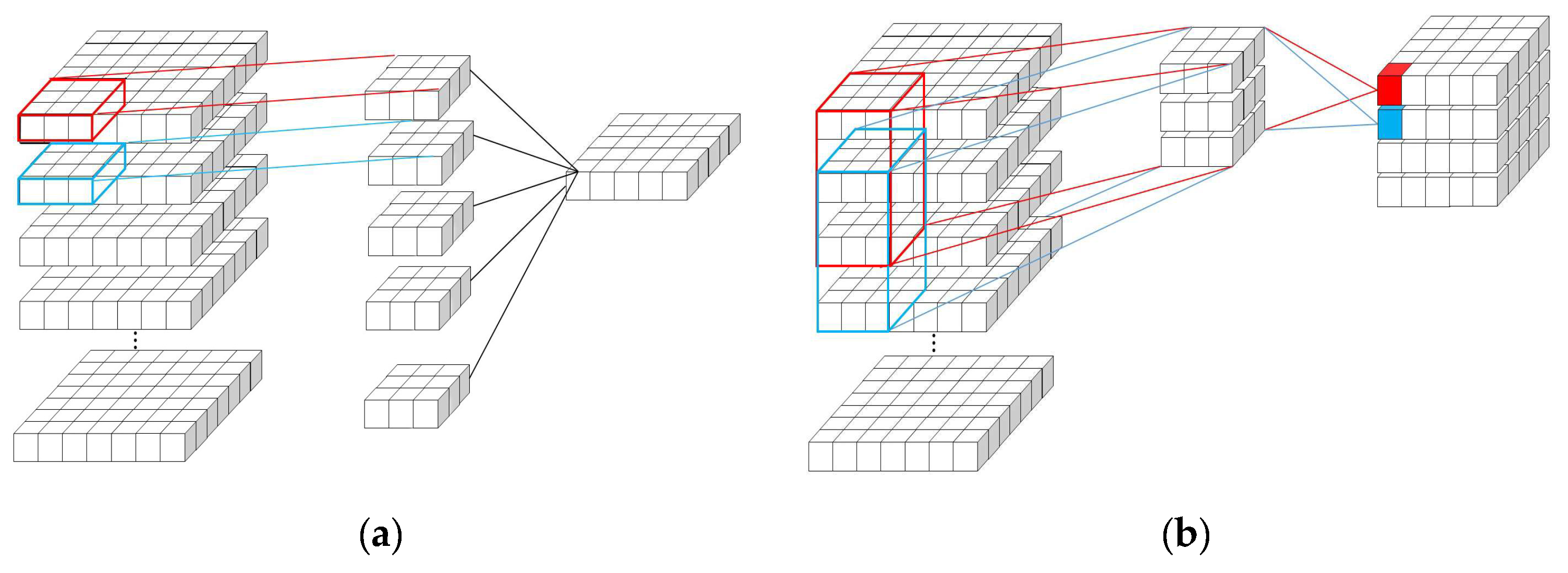
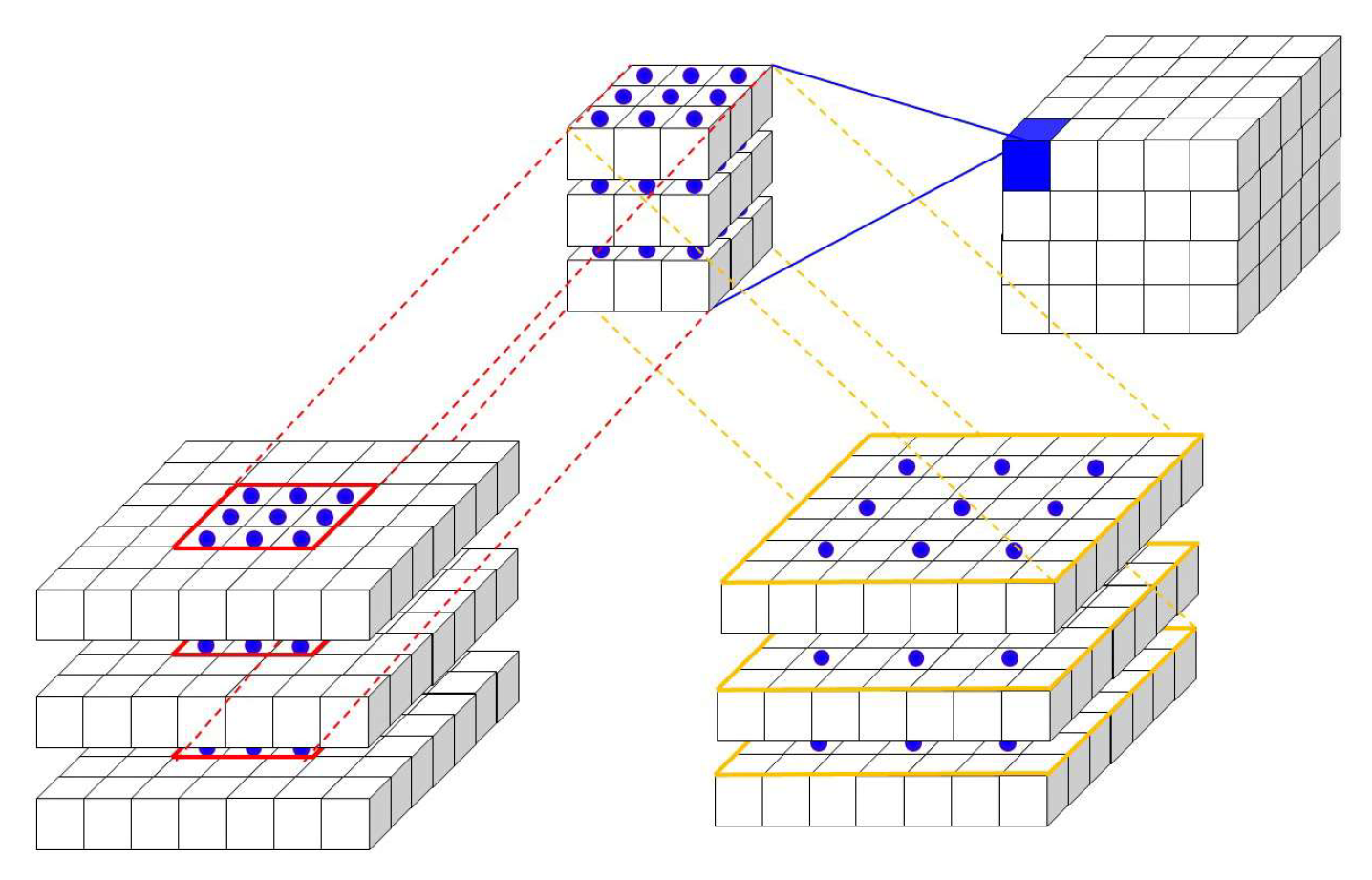
2.2.1. Spectral-Spatial Module with 3D Convolutional Layers
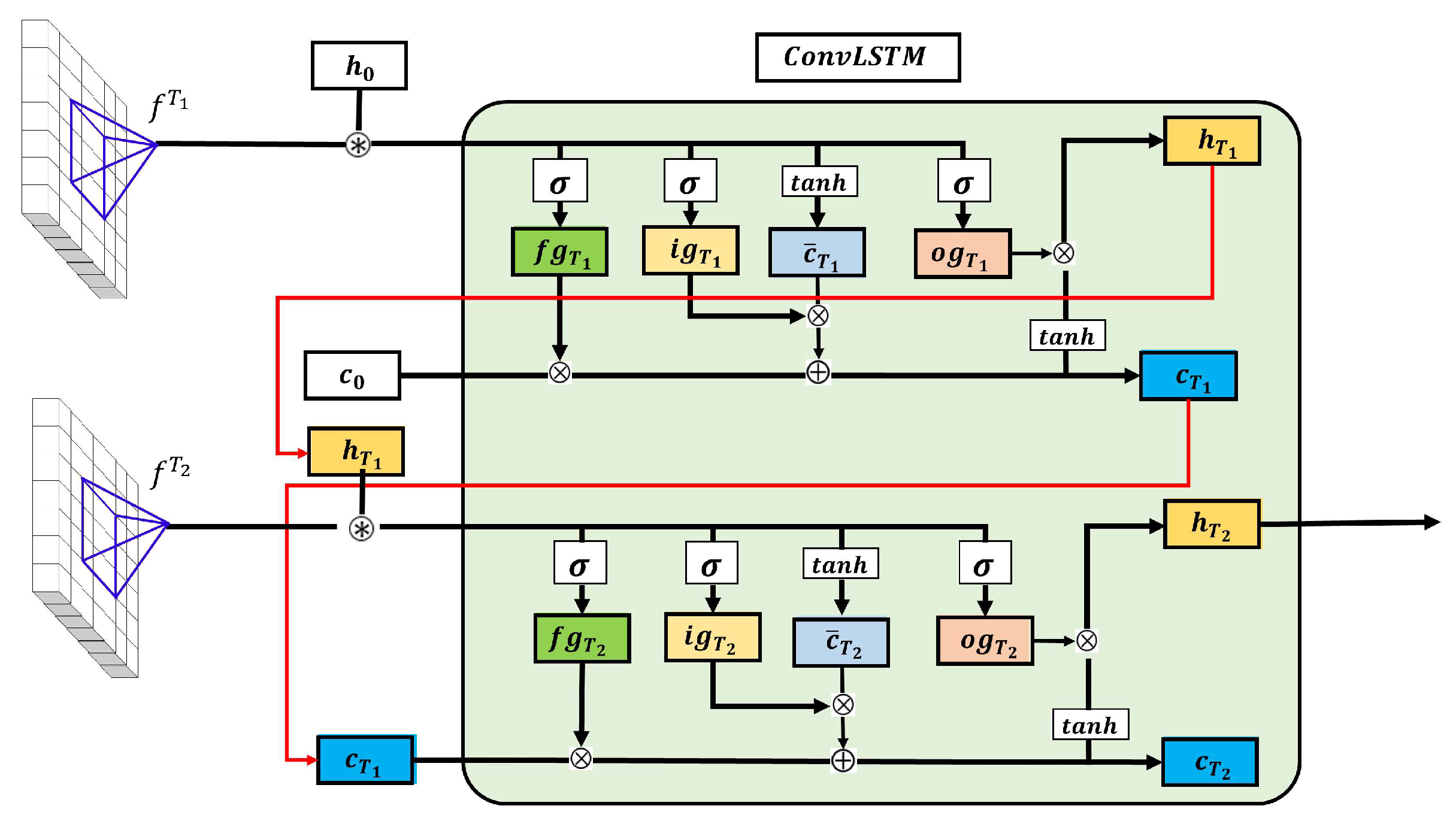
2.2.2. Temporal Module with Convolutional LSTM
2.2.3. Quality Evaluation
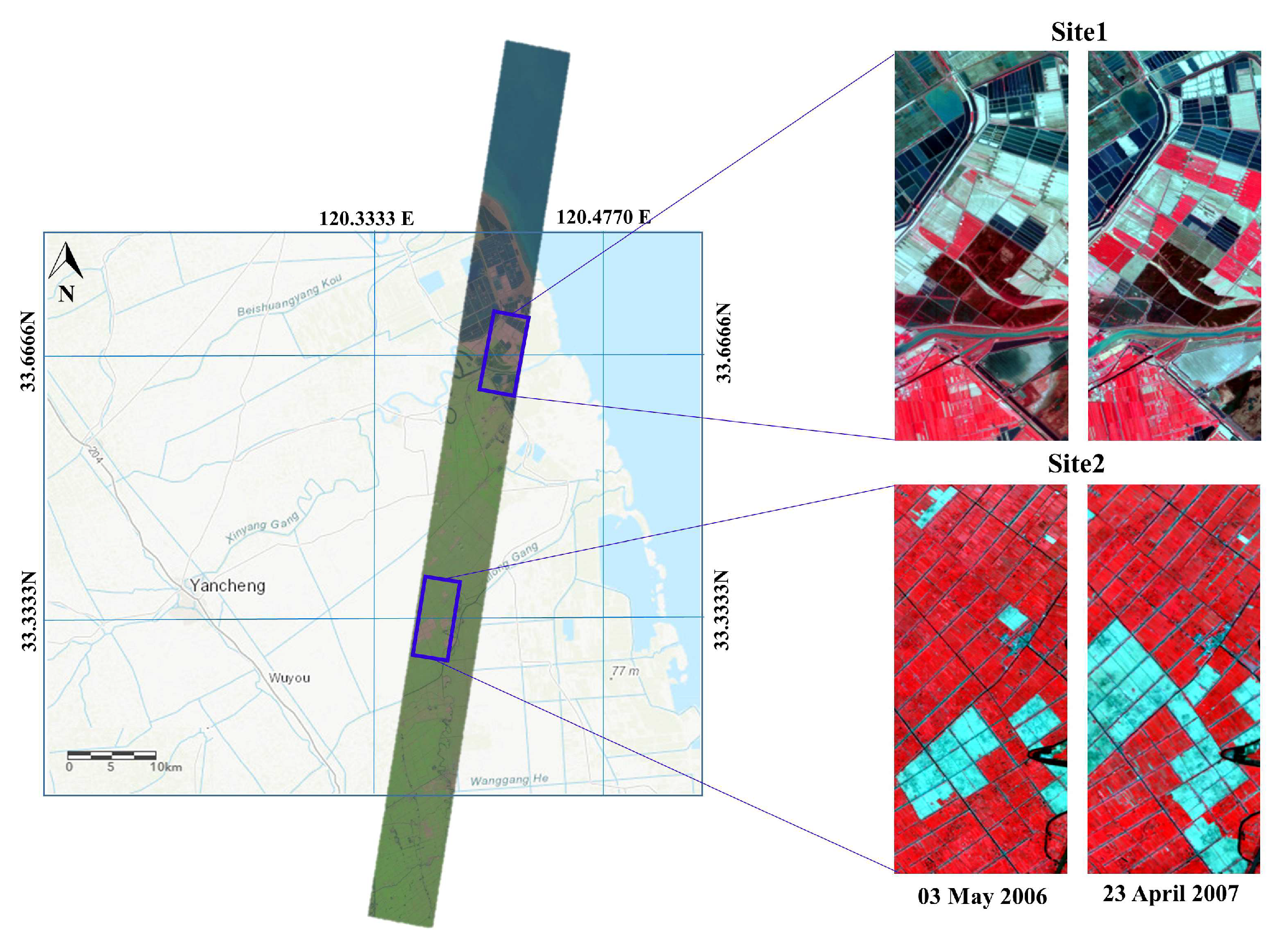
3. Dataset
4. Results
4.1. Sample Generation
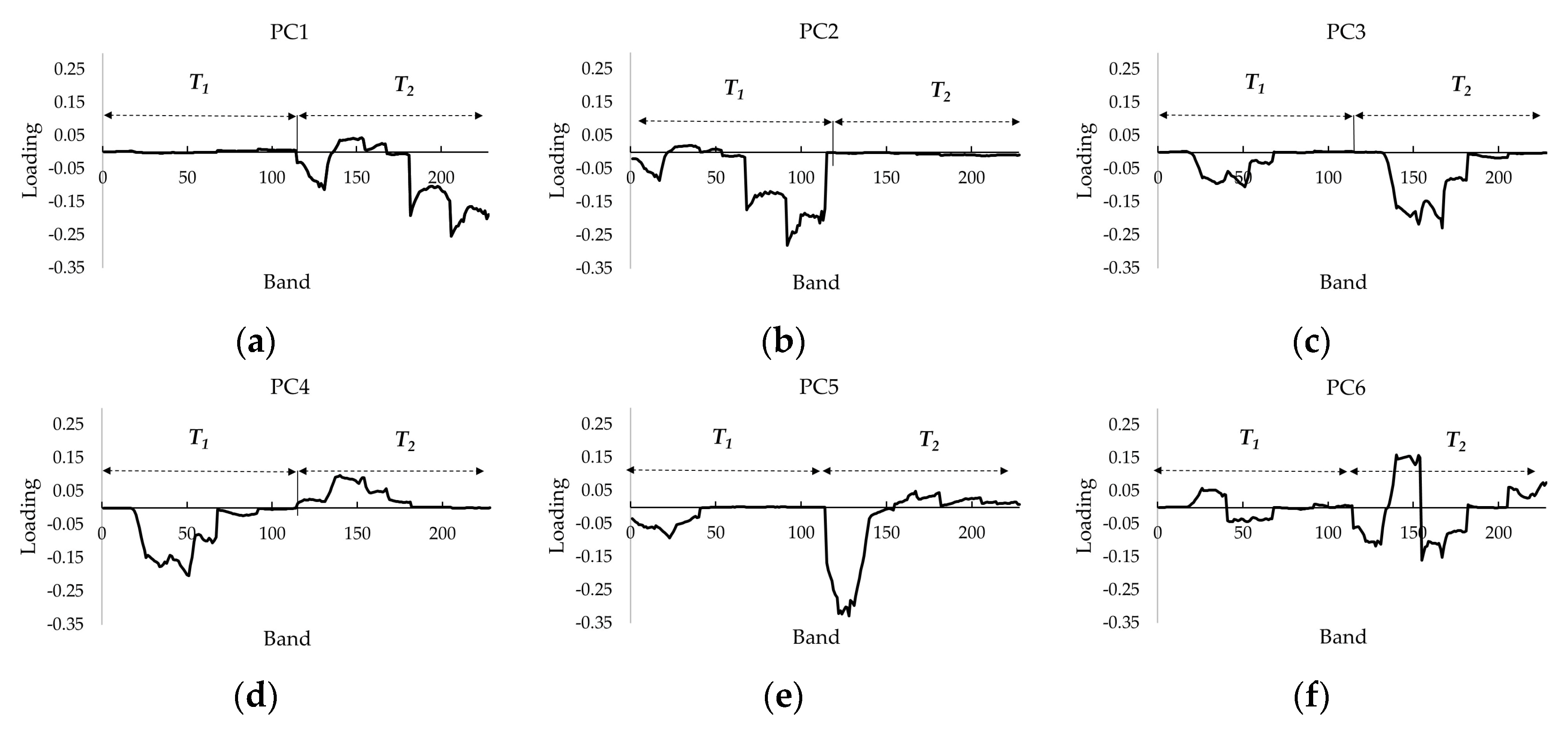
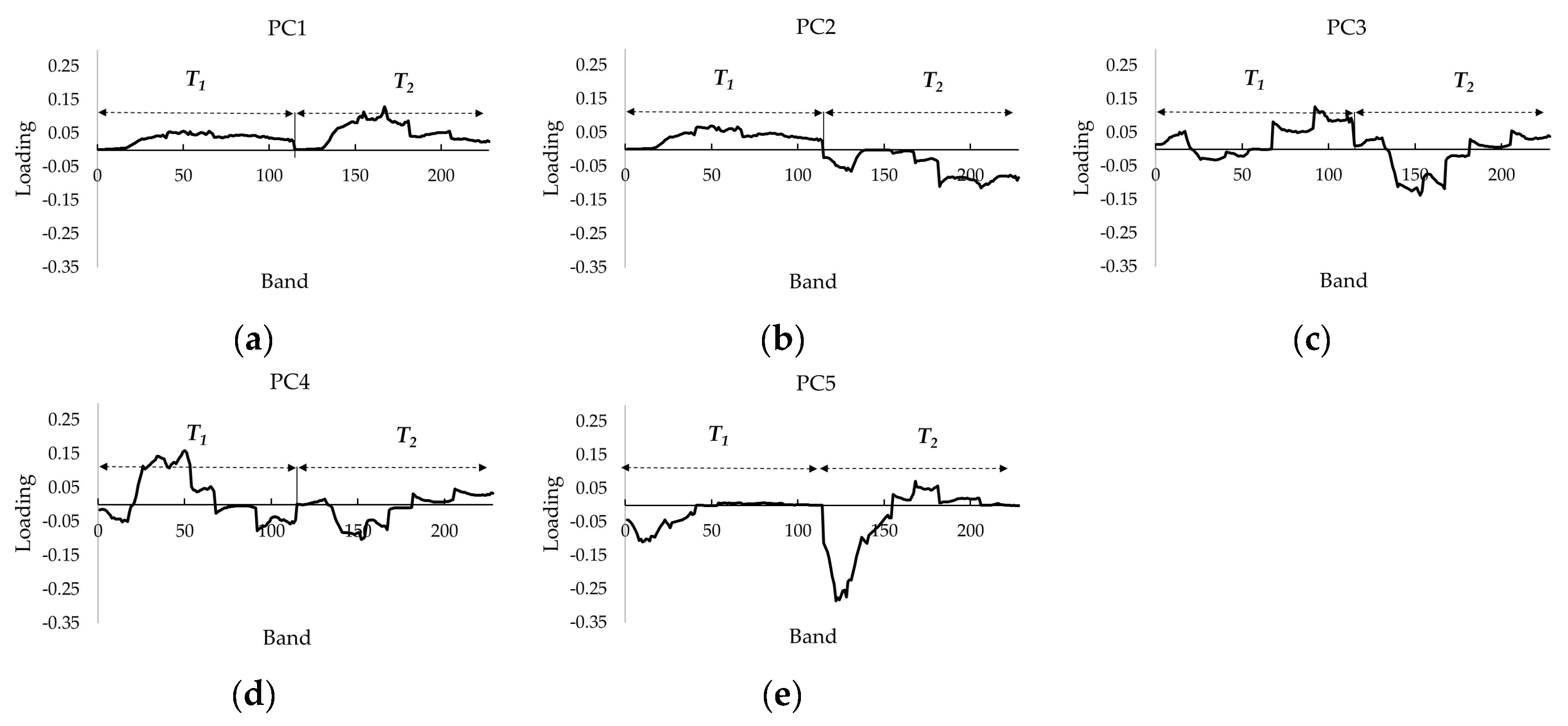
4.1.1. PCs for CD
4.1.2. Clustering Pixels by SCA with Endmembers
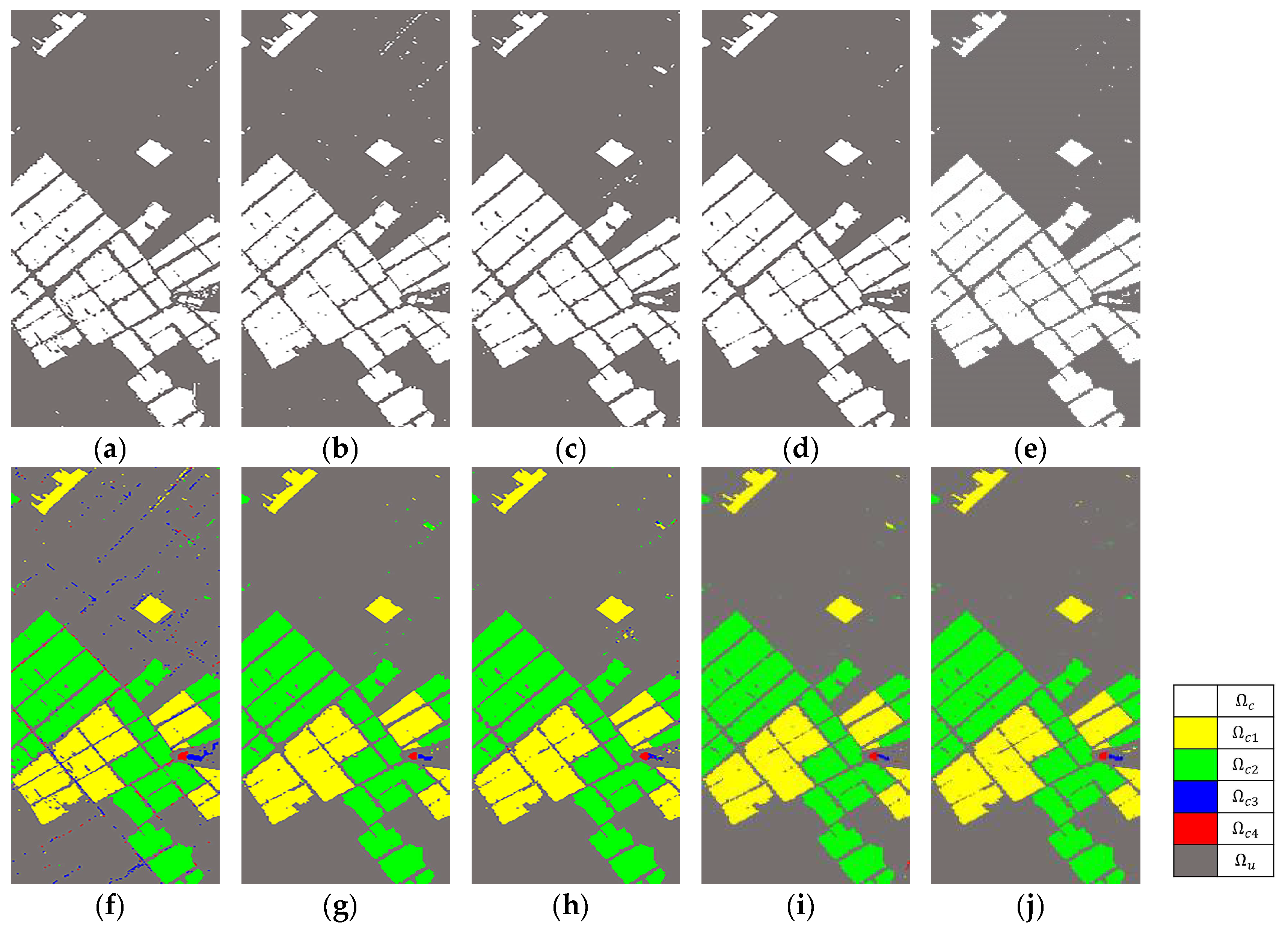
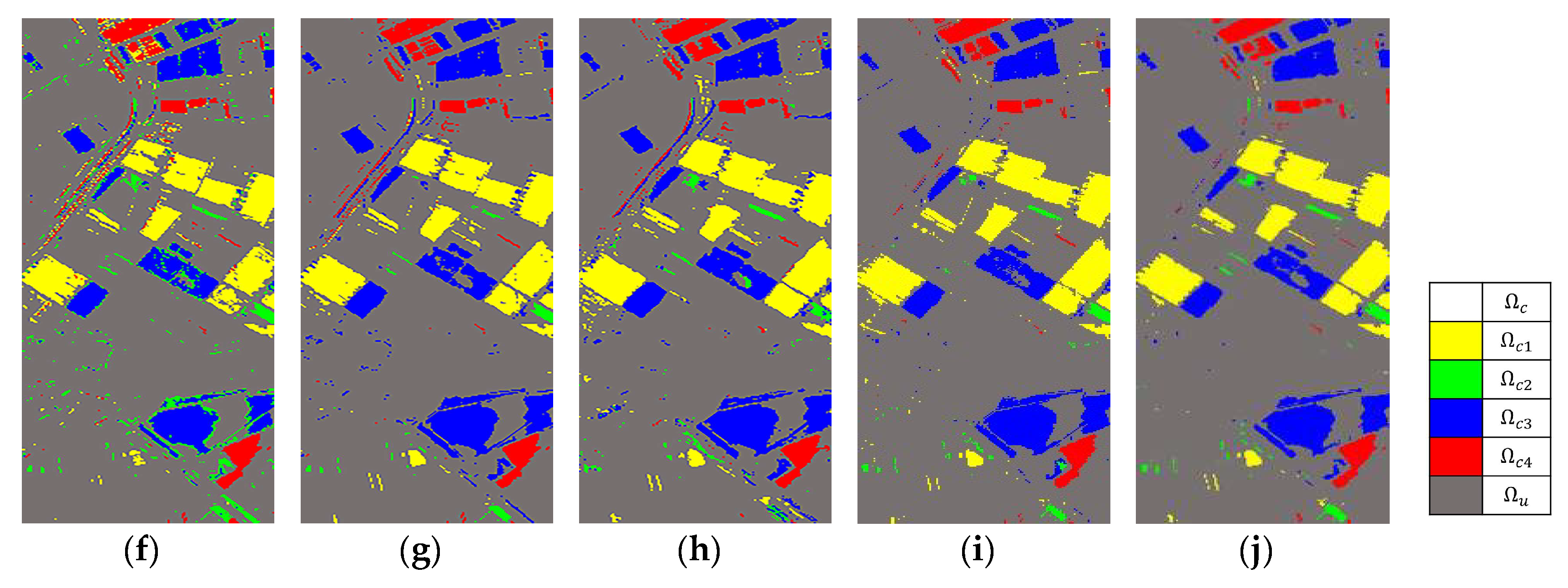
4.2. Change Detection Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Adão, T.; Hruška, J.; Pádua, L.; Bessa, J.; Peres, E.; Morais, R.; Sousa, J.J. Hyperspectral imaging: A review on UAV-based sensors, data processing and applications for agriculture and forestry. Remote Sens. 2017, 9, 1110. [Google Scholar] [CrossRef]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.K.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- Yuan, Y.; LV, H.; LU, X. Semi-supervised change detection method for multi-temporal hyperspectral images. Neurocomputing 2015, 148, 363–375. [Google Scholar] [CrossRef]
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Rumpf, T.; Mahlein, A.K.; Steiner, U.; Oerke, E.C.; Dehne, H.W.; Plümer, L. Early detection and classification of plant diseases with support vector machines based on hyperspectral reflectance. Comput. Electron. Agric. 2010, 74, 91–99. [Google Scholar] [CrossRef]
- Pu, R.; Gong, P.; Tian, Y.; Miao, X.; Carruthers, R.I.; Anderson, G.L. Invasive species change detection using artificial neural networks and CASI hyperspectral imagery. Environ. Monit. Assess. 2008, 140, 15–32. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.J.; Khan, H.S.; Yousaf, A.; Khurshid, K.; Abbas, A.A. Modern trends in hyperspectral image analysis: A Review. IEEE Access 2018, 6, 14118–14129. [Google Scholar] [CrossRef]
- Khanday, W.A.; Kumar, K. Change detection in hyper spectral images. Asian J. Technol. Manag. Res. 2016, 6, 54–60. [Google Scholar]
- Liu, S. Advanced Techniques for Automatic Change Detection in Multitemporal Hyperspectral Images. Ph.D. Thesis, University of Trento, Trento, Italy, 2015. [Google Scholar]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A general end-to-end 2-D CNN for hyperspectral image change detection. IEEE Trans. Geosci. Remote Sens. 2018, 99, 1–11. [Google Scholar] [CrossRef]
- Yu, L.; Xie, J.; Chen, S.; Zhu, L. Generating labeled samples for hyperspectral image classification using correlation of spectral bands. Front. Comput. Sci. 2016, 10, 292–301. [Google Scholar] [CrossRef]
- Xiaolu, S.; Bo, C. Change detection using change vector analysis from Landsat TM images in Wuhan. Procedia Environ. Sci. 2011, 11, 238–244. [Google Scholar] [CrossRef]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Du, P. A novel sequential spectral change vector analysis for representing and detecting multiple changes in hyperspectral images. In Proceedings of the 2014 IEEE International Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 4656–4659. [Google Scholar]
- Singh, S.; Talwar, R. A comparative study on change vector analysis based change detection techniques. Sadhana 2014, 39, 1311–1331. [Google Scholar] [CrossRef]
- Hansanlou, M.; Seydi, S.T. Hyperspectral change detection: An experimental comparative study. Int. J. Remote Sens. 2018, 1–55. [Google Scholar] [CrossRef]
- Ortiz-Rivera, V.; Vélez-Reyes, M.; Roysam, B. Change detection in hyperspectral imagery using temporal principal components. In Proceedings of the SPIE 2006 Algorithms and Technologies for Multispectral, Hyperspectral, Ultraspectral Imagery XII, Orlando, FL, USA, 8 May 2006; p. 623312. [Google Scholar]
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate alteration detection (MAD) and MAF postprocessing in multispectral, bitemporal image data: New approaches to change detection studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef]
- Nielsen, A.A. The regularized iteratively reweighted MAD method for change detection in multi-and hyperspectral data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed]
- Danielsson, P.E. Euclidean distance mapping. Comput. Gr. Image Process. 1980, 14, 227–248. [Google Scholar] [CrossRef] [Green Version]
- Kruse, F.A.; Lefkoff, A.B.; Boardman, J.W.; Heidebrecht, K.B.; Shaprio, A.T.; Barloon, P.J.; Goetz, A.F.H. The spectral image processing system (SIPS)—Interactive visualization and analysis of imaging spectrometer data. Remote Sens. Environ. 1993, 44, 145–163. [Google Scholar] [CrossRef]
- De Carvalho, O.A.; Meneses, P.R. Spectral correlation mapper (SCM): An improvement on the spectral angle mapper (SAM). In Proceedings of the 9th Airborne Earth Science Workshop, Pasadena, CA, US, 23–25 February 2000. [Google Scholar]
- Chang, C.I. Spectral information divergence for hyperspectral image analysis. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS 1999), Hamburg, Germany, 28 June–2 July 1999; pp. 509–511. [Google Scholar]
- Wu, C.; Du, B.; Zhang, L. A subspace-based change detection method for hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 815–830. [Google Scholar] [CrossRef]
- Shi, A.; Gao, G.; Shen, S. Change detection of bitemporal multispectral images based on FCM and D-S theory. EURASIP J. Adv. Signal Process. 2016, 2016, 96. [Google Scholar] [CrossRef]
- Du, Q. A new method for change analysis of multi-temporal hyperspectral images. In Proceedings of the Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Shanghai, China, 4–7 June 2012; pp. 1–4. [Google Scholar]
- Han, Y.; Chang, A.; Choi, S.; Park, H.; Choi, J. An Unsupervised algorithm for change detection in hyperspectral remote sensing data using synthetically fused images and derivative spectral profiles. J. Sens. 2017, 2017, 1–14. [Google Scholar] [CrossRef]
- Gao, F.; Liu, X.; Dong, J.; Zhong, G.; Jian, M. Change detection in SAR images based on deep Semi-NMF and SVD networks. Remote Sens. 2017, 9, 435. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Atkinson, P.P.; Tantnall, A.R.L. Introduction neural networks in remote sensing. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a transferable change rule from a recurrent neural network for land cover change detection. Remote Sens. 2016, 8, 506. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. arXiv, 2018; arXiv:1803.02642. [Google Scholar]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Liu, S.; Du, Q.; Tong, X.; Samat, A.; Pan, H.; Ma, X. Band selection-based dimensionality reduction for change detection in multi-temporal Hyperspectral Images. Remote Sens. 2017, 9, 1008. [Google Scholar] [CrossRef]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 153–160. [Google Scholar]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 1, 802–810. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Valipour, S.; Siam, M.; Jafersand, M.; Ray, N. Recurrent fully convolutional networks for video segmentation. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 29–36. [Google Scholar]
- Lu, N.; Wu, Y.; Feng, L.; Song, J. Deep Learning for Fall Detection: 3D-CNN Combined with LSTM on Video Kinematic Data. IEEE J. Biomed. Health Inform. 2018, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhu, G.; Shen, P.; Song, J. Learning spatiotemporal features using 3dcnn and convolutional LSTM for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 3120–3128. [Google Scholar]
- Robila, S.A. An analysis of spectral metrics for hyperspectral image processing. In Proceedings of the 2004 IGARSS Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; pp. 3233–3236. [Google Scholar]
- Deng, J.S.; Wang, K.; Deng, Y.H.; Qi, G.J. PCA-based land-use change detection and analysis using multitemporal and multisensor satellite data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Fung, T.; Ledrew, E. Application of principal components analysis to change detection. Photogramm. Eng. Remote Sens. 1987, 53, 1649–1658. [Google Scholar]
- Carvalho Júnior, O.A.; Guimarães, R.F.; Gillespie, A.R.; Silva, N.C.; Gomes, R.A. A new approach to change vector analysis using distance and similarity measures. Remote Sens. 2011, 3, 2473–2493. [Google Scholar] [CrossRef]
- Neville, R.A.; Staenz, K.; Szeredi, T.; Lefebvre, J. Automatic endmember extraction from hyperspectral data for mineral exploration. In Proceedings of the 21st Canadian Symposium on remote Sensing, Ottawa, ON, Canada, 21–24 July 1999; pp. 891–897. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? (no, it is not about internal covariate shift). arXiv, 2018; arXiv:1805.11604. [Google Scholar]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [PubMed]
- Jiao, L.; Liang, M.; Chen, H.; Yang, S.; Liu, H.; Cao, X. Deep fully convolutional network-based spatial distribution prediction for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5585–5599. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Chen, L.C.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the 2016 International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing—Explorations in the Microstructure of Cognition; Rumelhart, D.E., McClelland, J.L., Eds.; The MIT Press: Cambridge, MA, USA, 1986; pp. 318–362. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- ArcGIS Webmap. Available online: https://www.arcgis.com/home/webmap/viewer.html (accessed on 11 October 2018).
- Earth Science Data Archives of U.S. Geological Survey (USGS). Available online: http://earthexplorer.usgs.gov/ (accessed on 11 October 2018).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | |
|---|---|---|---|---|---|---|
| Eigenvalue | 0.571 | 0.257 | 0.151 | 0.011 | 0.007 | 0.002 |
| Cumulative % variance | 56.35% | 81.89% | 96.79% | 97.88% | 98.58% | 98.82% |
| PC1 | PC2 | PC3 | PC4 | PC5 | |
|---|---|---|---|---|---|
| Eigenvalue | 2.244 | 0.340 | 0.301 | 0.087 | 0.019 |
| Cumulative % variance | 73.17% | 85.88% | 95.69% | 98.51% | 99.12% |
| Dataset | Type of CD | Ground Truth | Training Samples | Testing Samples | ||
|---|---|---|---|---|---|---|
| Site 1 | Binary CD | 37,606 | 25,530 | 10,942 | ||
| 20,394 | 13,341 | 5717 | ||||
| 2470 | ||||||
| Multi-class CD | 37,606 | 25,530 | 10,942 | |||
| 6863 | 4924 | 2110 | ||||
| 13,435 | 8370 | 3587 | ||||
| 56 | 24 | 10 | ||||
| 51 | 23 | 10 | ||||
| 2470 | ||||||
| Site2 | Binary CD | 44,798 | 25,307 | 10,846 | ||
| 13,202 | 7137 | 3059 | ||||
| 11,651 | ||||||
| Multi-class CD | 44,798 | 25,307 | 10,846 | |||
| 5158 | 3100 | 1328 | ||||
| 473 | 224 | 96 | ||||
| 5655 | 2978 | 1275 | ||||
| 1889 | 838 | 359 | ||||
| 11,651 | ||||||
| PA | ||||||
|---|---|---|---|---|---|---|
| Corresponding class | Site 1 Site 2 | |||||
| Site 1 Site 2 | 0.963 | 0.998 | 0.941 | 1.000 | 1.000 | |
| 0.971 | 0.941 | 0.930 | 0.924 | 0.971 | ||
| Site 1 | Site 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OA | Kappa | PA | OA | Kappa | PA | |||||
| CVA | 0.965 | 0.922 | 0.989 | 0.919 | 0.835 | 0.899 | 0.714 | 0.926 | 0.804 | 0.786 |
| IRMAD | 0.971 | 0.937 | 0.981 | 0.952 | 0.882 | 0.872 | 0.657 | 0.883 | 0.830 | 0.696 |
| FCN | 0.974 | 0.942 | 0.990 | 0.942 | 0.877 | 0.938 | 0.822 | 0.951 | 0.889 | 0.818 |
| 2DCNN-LSTM | 0.977 | 0.949 | 0.991 | 0.950 | 0.917 | 0.951 | 0.852 | 0.982 | 0.839 | 0.856 |
| Re3FCN | 0.981 | 0.958 | 0.994 | 0.958 | 0.928 | 0.969 | 0.911 | 0.982 | 0.925 | 0.917 |
| Methods | OA | Kappa | PA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Site 1 | PCA-SCA | 0.958 | 0.919 | 0.972 | 0.918 | 0.942 | 0.977 | 0.826 | 0.809 |
| SVM | 0.973 | 0.951 | 0.991 | 0.946 | 0.940 | 0.600 | 0.558 | 0.884 | |
| FCN | 0.972 | 0.945 | 0.990 | 0.942 | 0.940 | 0.605 | 0.739 | 0.844 | |
| 2DCNN-LSTM | 0.973 | 0.950 | 0.964 | 0.935 | 0.951 | 0.488 | 0.739 | 0.878 | |
| Re3FCN | 0.976 | 0.953 | 0.993 | 0.951 | 0.942 | 0.837 | 0.783 | 0.905 | |
| Site 2 | PCA-SCA | 0.916 | 0.775 | 0.957 | 0.771 | 0.714 | 0.746 | 0.849 | 0.756 |
| SVM | 0.945 | 0.872 | 0.973 | 0.894 | 0.546 | 0.875 | 0.862 | 0.852 | |
| FCN | 0.942 | 0.846 | 0.958 | 0.923 | 0.633 | 0.871 | 0.873 | 0.811 | |
| 2DCNN-LSTM | 0.951 | 0.880 | 0.976 | 0.901 | 0.606 | 0.868 | 0.863 | 0.861 | |
| Re3FCN | 0.962 | 0.895 | 0.985 | 0.937 | 0.731 | 0.842 | 0.866 | 0.899 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, A.; Choi, J.; Han, Y.; Kim, Y. Change Detection in Hyperspectral Images Using Recurrent 3D Fully Convolutional Networks. Remote Sens. 2018, 10, 1827. https://doi.org/10.3390/rs10111827
Song A, Choi J, Han Y, Kim Y. Change Detection in Hyperspectral Images Using Recurrent 3D Fully Convolutional Networks. Remote Sensing. 2018; 10(11):1827. https://doi.org/10.3390/rs10111827
Chicago/Turabian StyleSong, Ahram, Jaewan Choi, Youkyung Han, and Yongil Kim. 2018. "Change Detection in Hyperspectral Images Using Recurrent 3D Fully Convolutional Networks" Remote Sensing 10, no. 11: 1827. https://doi.org/10.3390/rs10111827
APA StyleSong, A., Choi, J., Han, Y., & Kim, Y. (2018). Change Detection in Hyperspectral Images Using Recurrent 3D Fully Convolutional Networks. Remote Sensing, 10(11), 1827. https://doi.org/10.3390/rs10111827