A Noise-Resilient Online Learning Algorithm for Scene Classification



Abstract
:
1. Introduction
- -
- Lacking Noise-Resilient Scene Classification Algorithm: since images’ categories are often annotated by human beings, and it is natural for us to make some incorrect annotations especially when we are provided with massive images. In addition, an image may cover several semantics. For example, the images in Figure 1 can be annotated with the scene of river or forest, but, under the framework of multi-classification, only one category is assigned to each of the images. Thus, noisy labels are often inevitable in scene classification. It is necessary to devise a scene classification algorithm that is robust to noisy labels.
- -
- Lacking Online Scene Classification Algorithm: a vast majority of existing scene classification algorithms predominantly focus on the static setting and require the accessibility of the whole image data set. However, with the constant improvement of satellite and aerospace technology, a large number of images are available continuously in the streaming fashion. The requirement to have all the training data in prior to training poses a serious constraint in the application of traditional scene classification algorithms based on batch learning techniques. To this end, it is necessary and of vital importance to perform online scene classification to adapt to the streaming data accordingly.
- -
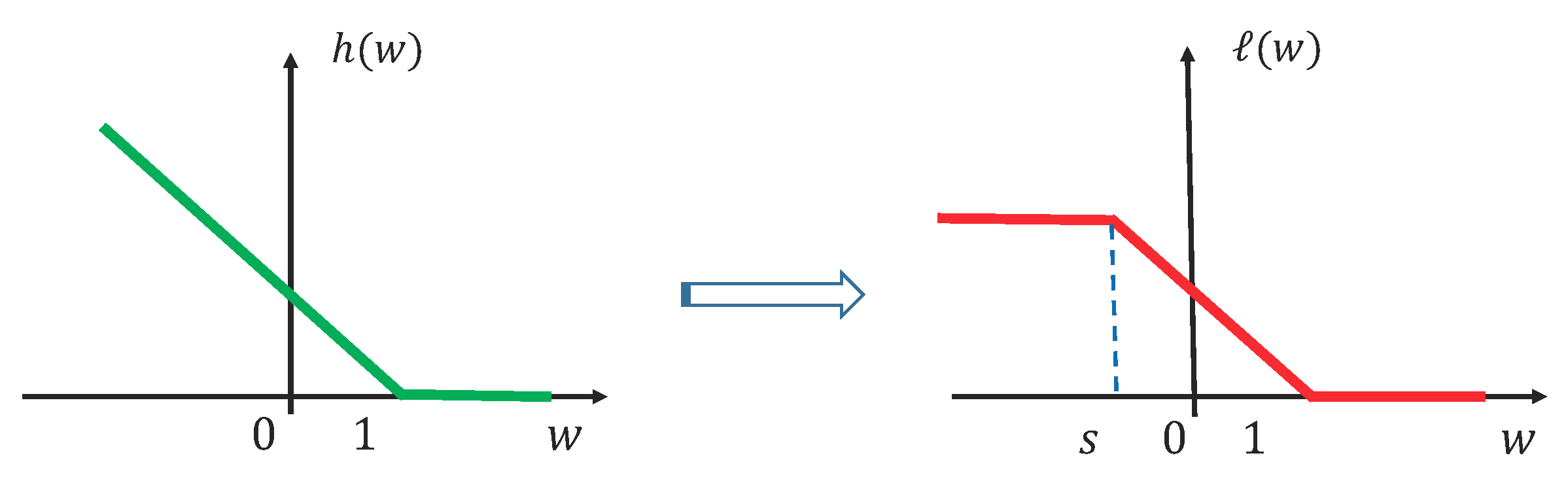
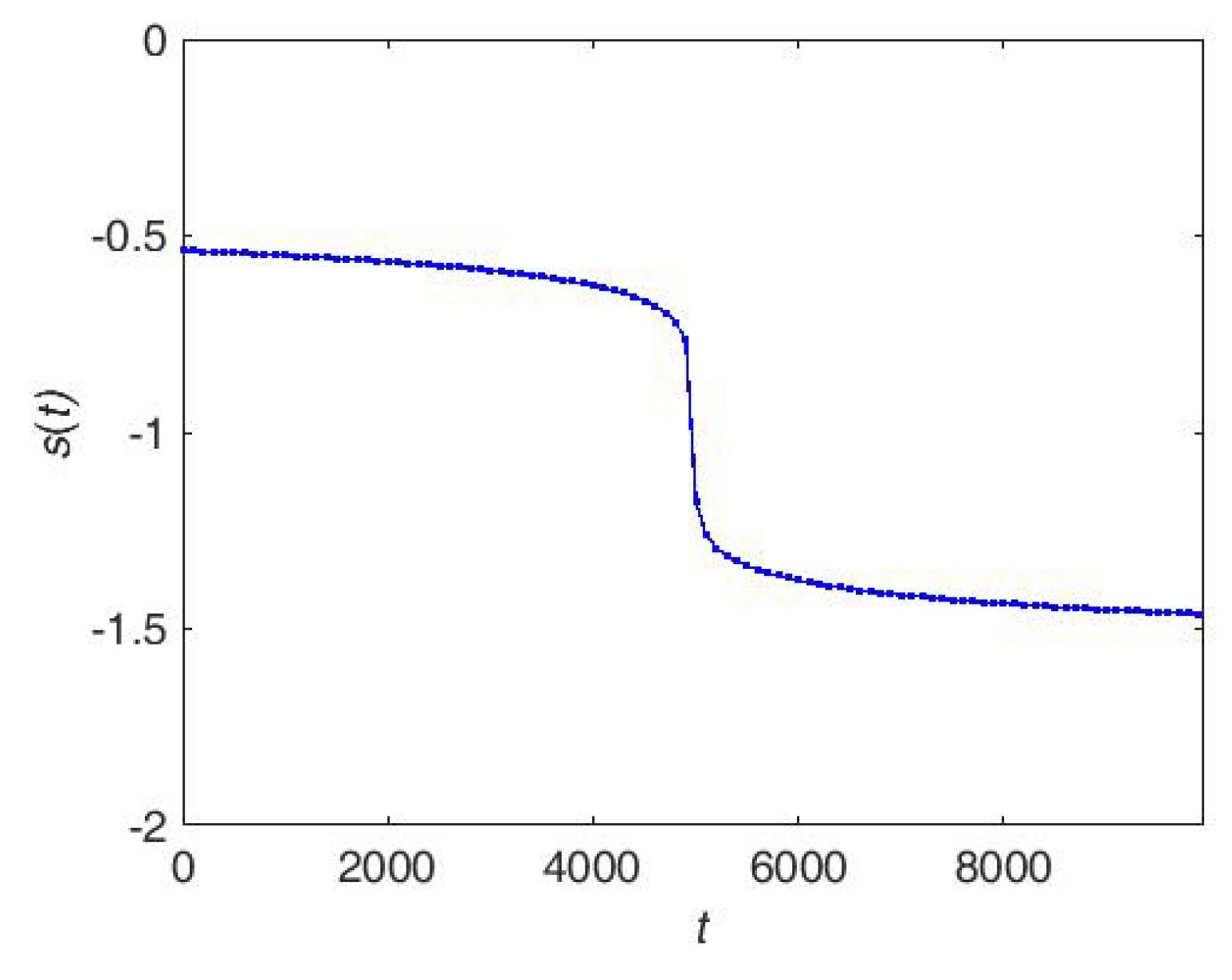
- Noise-Resilient: by the dynamical setting of threshold parameter s, the noise which would lead to a large loss (larger than the threshold parameter) would be identified and won’t be incorporated into the Support Vectors (SVs) set.
- -
- Sparsity: as can be seen from Figure 3, only a fraction of examples (with the loss between s and 1) would serve as Support Vectors (SVs). It is designed to reduce the computational cost and enjoy the perfect scalability property.
2. Related Work
3. Method
3.1. Ramp Loss
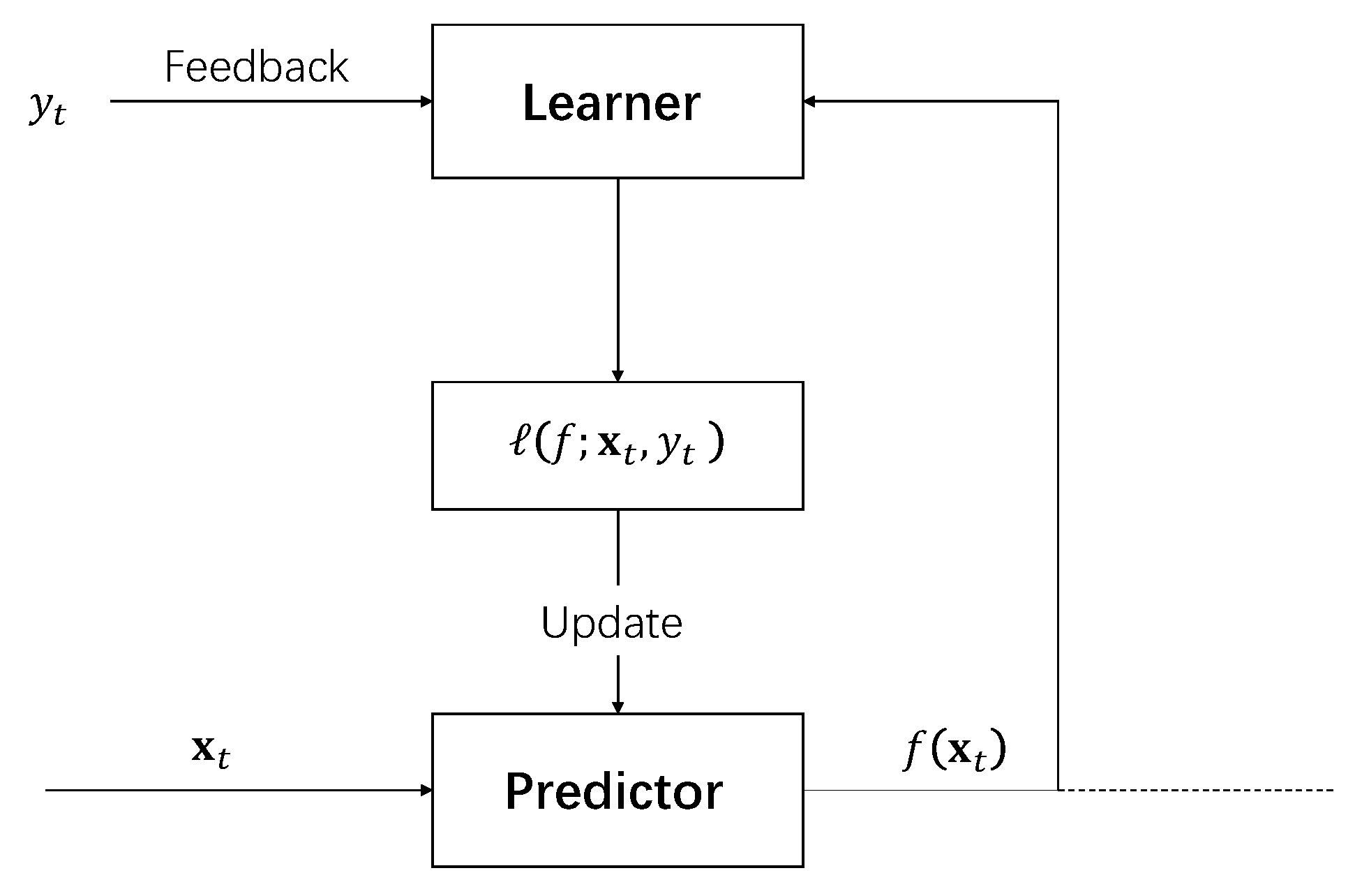
3.2. Online Learning Algorithm
3.3. Noise-Resilient Online Multi-Classification Algorithm
| Algorithm 1 Noise-Resilient Online Multi-classification Algorithm |
|
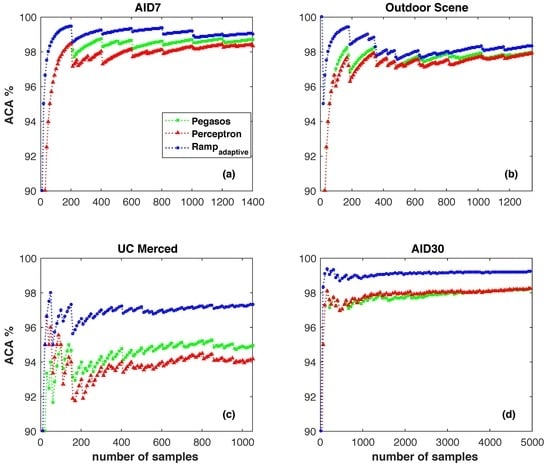
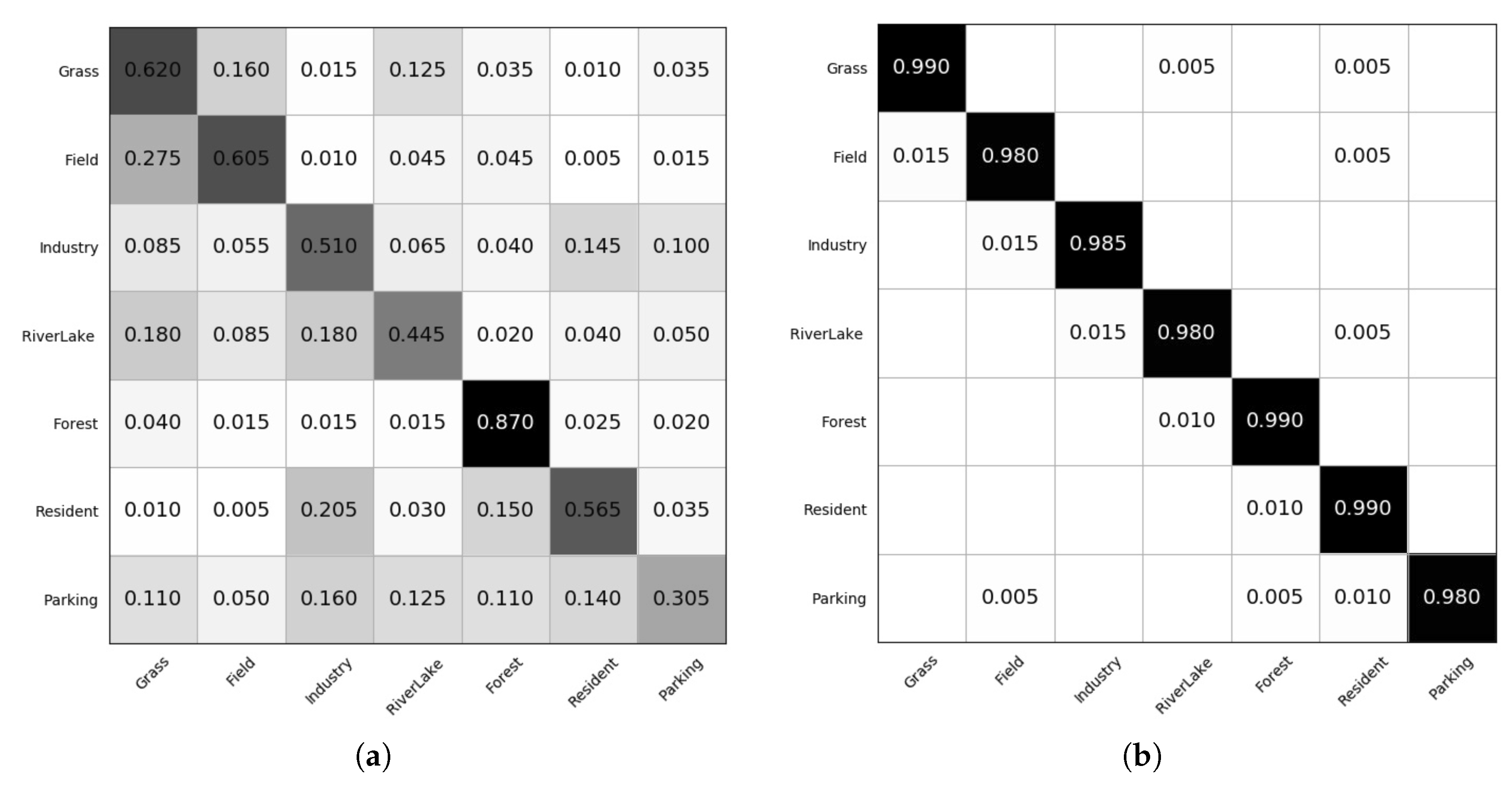
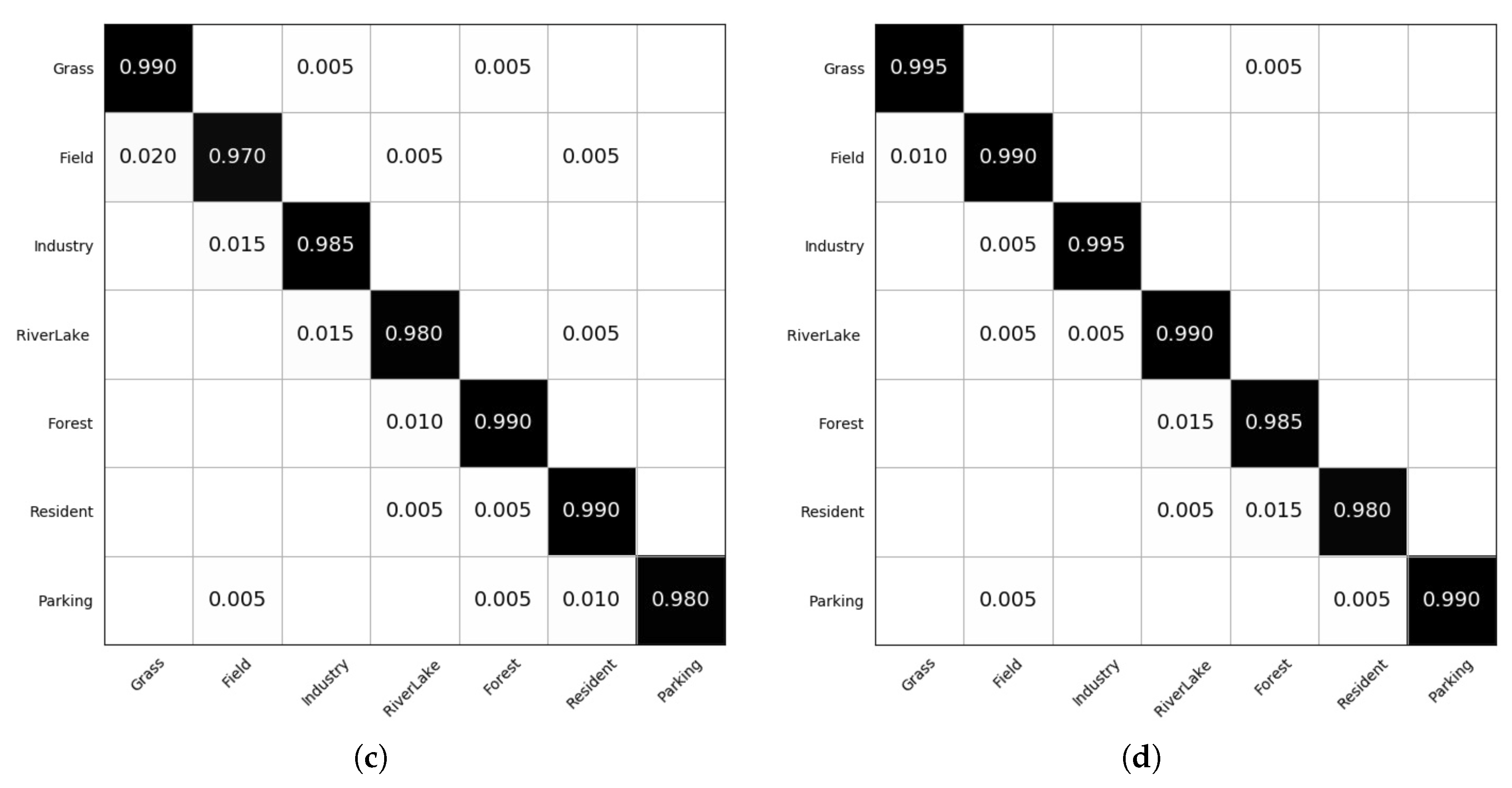
4. Experiments
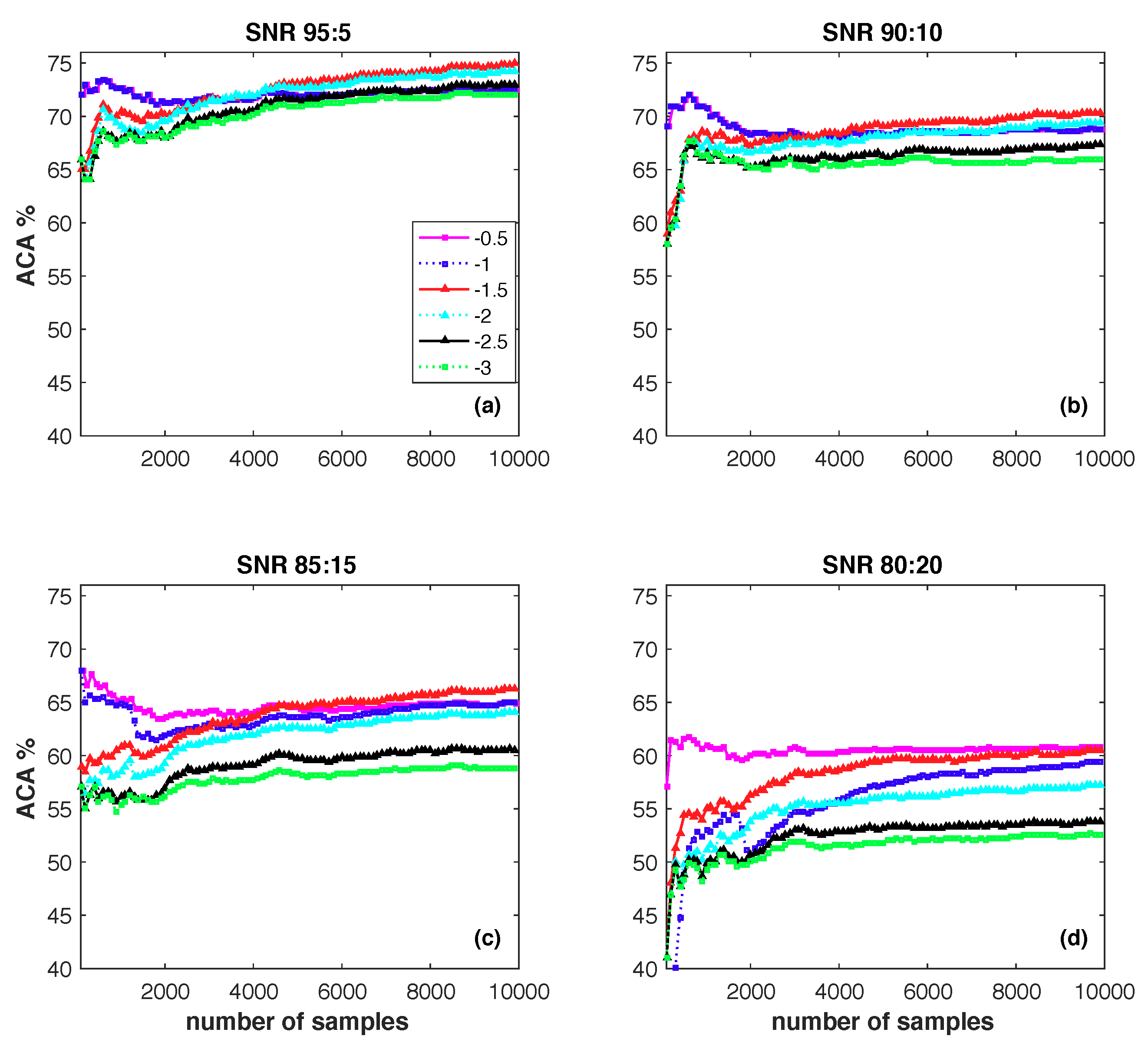
4.1. Parameter Sensitivity Study
- -
- At the beginning of the online learning process, the bigger s always outperforms small ones.
- -
- On the whole, the higher the noise level is, the worse the performance of the algorithm will be. On a fixed noise level, e.g., SNR 90:10, a smaller s will incorporate more SVs into the classifier. Among them some are useful examples and the other are noisy examples. Thus, a proper setting for s is the key problem for the proposed noise-resilient online classification algorithm.
- -
- The proposed algorithm is sensitive to ramp loss parameter s. In this study, gives the overall best performance, and is the worst one. Any fixed setting of s can not outperform others in all four of the situations.
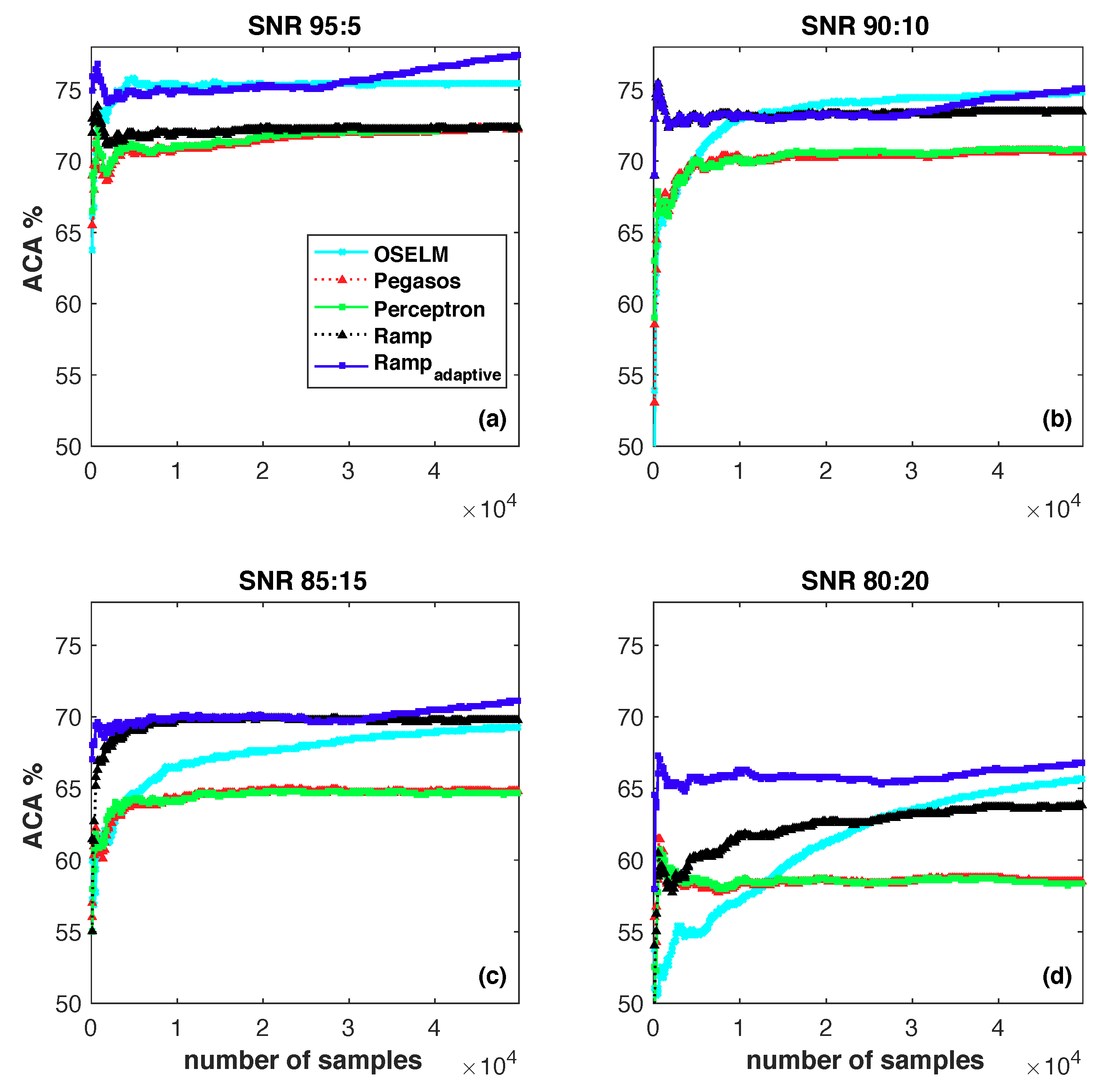
4.2. Synthesis Data Sets
- -
- Sparsity: How sparse is the proposed online classification algorithm for streaming data?
- -
- Noise-Resilient: How effective is the proposed online classification algorithm for data with noisy labels?
4.3. Benchmark Data Sets
- -
- AID7 data set: AID is a large-scale aerial image data set, by collecting sample images from Google Earth imagery. AID7 is made up of the following seven aerial scene types: grass, field, industry, river lake, forest, resident, and parking. The AID7 data set has a number of 2800 images within seven classes and each class contains 400 samples of size 600×600 pixels.
- -
- Outdoor Scene categories data set: this data set contains eight outdoor scene categories, i.e., coast, mountain, forest, open country, street, inside city, tall buildings and highways. There are 2600 color images of 256×256 pixels. All of the objects and regions in this data set have been fully labeled. There are more than 29,000 objects.
- -
- UC Merced Landuse data set: the images in the UC Merced Landuse data set were manually extracted from large images from the USGS (United States Geological Survey) National Map Urban Area Imagery collection for various urban areas around the country. The pixel resolution of this public domain imagery is one foot. The UC Merced data set contains 2100 images in total and each image measures 256×256 pixels. There are 100 images for each of the following 21 classes: agricultural, airplane, baseball diamond, beach, buildings, chaparral, dense residential, forest, freeway, golf course, harbor, intersection, medium residential, mobile home park, overpass, parking lot, river, runway, sparse residential, storage tanks, and tennis court. Some sample images from this data set are shown in Figure 8.
- -
- AID30 data set: similar to the AID7 data set, this data set is made up of the following 30 aerial scene types: airport, bareland, baseballfield, beach, bridge, center, church, commercial, dense residential, desert, farmland, forest, industrial, meadow, medium residential, mountain, park, parking, playground, pond, port, railway station, resort, river, school, sparse residential, square, stadium, storage tanks and viaduct. In total, the AID30 data set has a number of 10,000 images within 30 classes and each class contains about 200 to 400 samples of size 600×600 pixels.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. Dense connectivity based two-stream deep feature fusion framework for aerial scene classification. Remote Sens. 2018, 10, 1158. [Google Scholar] [CrossRef]
- Faisal, A.; Kafy, A.; Roy, S. Integration of remote sensing and GIS techniques for flood monitoring and damage assessment: A case study of naogaon district. Egypt. J. Remote Sens. Space Sci. 2018, 7, 2. [Google Scholar] [CrossRef]
- Bi, S.; Lin, X.; Wu, Z.; Yang, S. Development technology of principle prototype of high-resolution quantum remote sensing imaging. In Quantum Sensing and Nano Electronics and Photonics XV; International Society for Optics and Photonics: Bellingham, WA, USA, 2018. [Google Scholar]
- Weng, Q.; Quattrochi, D.; Gamba, P.E. Urban Remote Sensing; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Mukherjee, A.B.; Krishna, A.P.; Patel, N. Application of remote sensing technology, GIS and AHP-TOPSIS model to quantify urban landscape vulnerability to land use transformation. In Information and Communication Technology for Sustainable Development; Springer: Singapore, 2018. [Google Scholar]
- Li, P.; Ren, P.; Zhang, X. Region-wise deep feature representation for remote sensing images. Remote Sens. 2018, 10, 871. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Aptoula, E. Remote sensing image retrieval with global morphological texture descriptors. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3023–3034. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Trans. Geosci. Remote Sens. 2013, 52, 818–832. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Li, Y.; Zhang, Y.; Tao, C. Content-based high-resolution remote sensing image retrieval via unsupervised feature learning and collaborative affinity metric fusion. Remote Sens. 2016, 8, 709. [Google Scholar] [CrossRef]
- Yu, Y.; Gong, Z.; Wang, C. An unsupervised convolutional feature fusion network for deep representation of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 23–27. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Ma, X.; Liu, W.; Li, S.; Tao, D.; Zhou, Y. Hypergraph-Laplacian regularization for remotely sensed image recognition. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Wang, Q.; He, X.; Li, X. Locality and structure regularized low rank representation for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised deep feature extraction for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef]
- Li, F.F.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental Bayesian approach tested on 101 object categories. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; Volume 106, p. 178. [Google Scholar]
- Jian, L.; Shen, S.Q.; Li, J.D.; Liang, X.J.; Li, L. Budget online learning algorithm for least squares SVM. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2076–2087. [Google Scholar] [CrossRef] [PubMed]
- Song, X.X.; Jian, L.; Song, Y.Q. A chunk updating LS-SVMs based on block Gaussian elimination method. Appl. Soft Comput. 2017, 51, 96–104. [Google Scholar] [CrossRef]
- Hu, J.; Sun, Z.; Li, B. Online user modeling for interactive streaming image classification. In Proceedings of the Conference on Multimedia Modeling, Reykjavik, Iceland, 4–6 January 2017; pp. 293–305. [Google Scholar]
- Meng, J.E.; Venkatesan, R.; Ning, W. An online universal classifier for binary, multi-class and multi-label classification. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Budapest, Hungary, 9–12 October 2017; pp. 3701–3706. [Google Scholar]
- Zhao, P.; Hoi, S.C.H. Cost-sensitive online active learning with application to malicious URL detection. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 919–927. [Google Scholar]
- Jian, L.; Ma, X.; Song, Y.; Luo, S. Laplace error penalty-based M-type model detection for a class of high dimensional semiparametric models. J. Comput. Appl. Math. 2019, 347, 210–221. [Google Scholar] [CrossRef]
- Mason, L.; Bartlett, P.L.; Baxter, J. Improved generalization through explicit optimization of margins. Mach. Learn. 2000, 38, 243–255. [Google Scholar] [CrossRef]
- Shen, X.T.; Tseng. On ψ-learning. J. Am. Stat. Assoc. 2003, 98, 724–734. [Google Scholar] [CrossRef]
- Collobert, R.; Sinz, F.; Weston, J.; Bottou, L. Trading convexity for scalability. In Proceedings of the ACM International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 201–208. [Google Scholar]
- Wu, Y.; Liu, Y. Robust truncated hinge loss support vector machines. Publ. Am. Stat. Assoc. 2007, 102, 974–983. [Google Scholar] [CrossRef]
- Steinwart, I. Sparseness of support vector machines. J. Mach. Learn. Res. 2008, 4, 1071–1105. [Google Scholar]
- Aggarwal, C.C. Data Mining: The Textbook; Springer: Berlin, Germany, 2015. [Google Scholar]
- Dekel, O.; Shalev-Shwartz, S.; Singer, Y. The Forgetron: A kernel-based Perceptron on a budget. SIAM J. Comput. 2008, 37, 1342–1372. [Google Scholar] [CrossRef]
- Crammer, K.; Dekel, O.; Keshet, J. Online passive-aggressive algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar]
- Francesco, O.; Joseph, K.; Barbara, C. The projectron: A bounded kernel-based Perceptron. In Proceedings of the International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 720–727. [Google Scholar]
- Zhao, P.; Wang, J.; Wu, P. Fast bounded online gradient descent algorithms for scalable kernel-based online learning. In Proceedings of the International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 169–176. [Google Scholar]
- Jian, L.; Li, J.D.; Liu, H. Toward online node classification on streaming networks. Data Min. Knowl. Discov. 2018, 32, 231–257. [Google Scholar] [CrossRef]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Cheung, W.; Hamarneh, G. n-SIFT: n-dimensional scale invariant feature transform. IEEE Trans. Image Process. 2009, 18, 2012–2021. [Google Scholar] [CrossRef] [PubMed]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, UK, 2002. [Google Scholar]
- Yuille, A.L.; Anand, R. The concave-convex procedure. Neural Comput. 2003, 15, 915–936. [Google Scholar] [CrossRef] [PubMed]
- Shalev-Shwartz, S. Online learning and online convex optimization. Found. Trends Mach. Learn. 2012, 4, 107–194. [Google Scholar] [CrossRef]
- Crammer, K.; Singer, Y. On the algorithmic implementation of multiclass kernel-based vector machines. J. Mach. Learn. Res. 2002, 2, 265–292. [Google Scholar]
- Shalev-Shwartz, S.; Singer, Y.; Srebro, N.; Cotter, A. Pegasos: Primal estimated sub-gradient solver for SVM. Math. Program. 2011, 127, 3–30. [Google Scholar] [CrossRef]
- Huang, G.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Liang, N.; Huang, G.; Saratchandran, P.; Sundararajan, N. A fast and accurate online sequential learning algorithm for feedforward networks. IEEE Trans. Neural Netw. 2006, 17, 1411–1423. [Google Scholar] [CrossRef] [PubMed]
- Crammer, K.; Singer, Y. Ultraconservative online algorithms for multiclass problems. J. Mach. Learn. Res. 2003, 3, 951–991. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR | Pegasos | Perceptron | Ramp | |||||
|---|---|---|---|---|---|---|---|---|
| #SVs | Time (s) | #SVs | Time (s) | #SVs | Time (s) | #SVs | Time (s) | |
| 95:5 | 13097 | 232.44 | 13210 | 280.59 | 6264 | 169.91 | 4970 | 65.78 |
| 90:10 | 15651 | 331.68 | 15761 | 351.32 | 6047 | 157.93 | 4853 | 61.54 |
| 85:15 | 17795 | 354.82 | 17759 | 397.43 | 5611 | 129.35 | 4692 | 56.52 |
| 80:20 | 19980 | 387.33 | 19849 | 447.82 | 5492 | 117.69 | 3934 | 53.76 |
| Data Sets | Algorithms | Overall Accuracy (%) | Average Accuracy (%) | Kappa | Time (s) |
|---|---|---|---|---|---|
| AID7 | OSELM | 56.00 | 56.00 | 0.4867 | 3.05 |
| Pegasos | 98.50 | 98.50 | 0.9825 | 5.01 | |
| Perceptron | 98.36 | 98.36 | 0.9808 | 6.55 | |
| 98.93 | 98.93 | 0.9875 | 8.29 | ||
| Outdoor Scene | OSELM | 78.94 | 79.25 | 0.7588 | 2.92 |
| Pegasos | 98.07 | 98.04 | 0.9778 | 3.83 | |
| Perceptron | 98.14 | 98.08 | 0.9787 | 4.91 | |
| 98.59 | 98.50 | 0.9838 | 6.11 | ||
| UC Merced | OSELM | 47.14 | 47.14 | 0.4450 | 2.40 |
| Pegasos | 94.57 | 94.57 | 0.9430 | 3.72 | |
| Perceptron | 94.38 | 94.38 | 0.9410 | 4.59 | |
| 97.33 | 97.33 | 0.9720 | 6.17 | ||
| AID30 | OSELM | 35.44 | 35.32 | 0.3307 | 11.21 |
| Pegasos | 98.14 | 98.11 | 0.9807 | 90.82 | |
| Perceptron | 98.08 | 98.05 | 0.9801 | 101.23 | |
| 99.16 | 99.12 | 0.9913 | 103.96 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jian, L.; Gao, F.; Ren, P.; Song, Y.; Luo, S. A Noise-Resilient Online Learning Algorithm for Scene Classification. Remote Sens. 2018, 10, 1836. https://doi.org/10.3390/rs10111836
Jian L, Gao F, Ren P, Song Y, Luo S. A Noise-Resilient Online Learning Algorithm for Scene Classification. Remote Sensing. 2018; 10(11):1836. https://doi.org/10.3390/rs10111836
Chicago/Turabian StyleJian, Ling, Fuhao Gao, Peng Ren, Yunquan Song, and Shihua Luo. 2018. "A Noise-Resilient Online Learning Algorithm for Scene Classification" Remote Sensing 10, no. 11: 1836. https://doi.org/10.3390/rs10111836
APA StyleJian, L., Gao, F., Ren, P., Song, Y., & Luo, S. (2018). A Noise-Resilient Online Learning Algorithm for Scene Classification. Remote Sensing, 10(11), 1836. https://doi.org/10.3390/rs10111836