1. Introduction
Hyperspectral imagery (HSI) has been widely used in the remote sensing community in order to take advantage of the composition of hundreds of spectral channels over a single scene. However, HSI demands robust and accurate classification techniques to extract the features from the image. The classification of HSI has been considered as a particularly challenging problem due to the complicated nature of the image scene (i.e., a large amount of data, mixed pixels and limited training samples), and therefore many attempts have been made to address this issue in the last few decades. In the early stage of HSI classification, spectral domain classifiers, such as support vector machines (SVMs) [
1,
2], random forest (RF) [
3], and multinomial logistic regression (MLR) [
4], have made great improvements in understanding the image scenes.
Recent technological development provides more promising approaches to deal with HSI classification. For example, morphological profiles (MPs) [
5,
6], Markov random fields (MRFs) [
7,
8], and sparsity signal-based methods (e.g., joint sparse models) [
9] were introduced for a better understanding of the image scenes by using the spatial and contextual properties. These methods aim to classify HSI by taking advantage of both spectral and spatial information. For instance, a joint sparse model [
9] combines the information from a few neighboring pixels of the test pixel, which is proven to be an effective way to improve the classification performance.
Very recently, deep learning is of interest to researchers in the field of computer vision. In particular, convolutional neural networks (CNNs) have attracted a lot of attention due to their superior performance in many domains, such as face recognition [
10,
11], object detection [
12] and video classification [
13]. In terms of feature extraction, CNNs can learn feature representations through several convolutional blocks. In contrast to the traditional rules-based feature extraction methods, CNNs can learn features automatically from the original images. Moreover, CNNs can be designed as an end-to-end framework that can produce classification maps directly. Therefore many CNN models have been applied to HSI classification. For example, Chen, et al. [
14] employed several convolutional layers to extract the nonlinear and invariant deep features from raw HSI, and the authors also investigated a few strategies to avoid overfitting in the model. In [
15], a deep CNN was combined with a dimension reduction method to extract the spectral-spatial features for HSI classification, and the obtained discriminative features led to a high performance on benchmark datasets. In [
16], a CNN structure was exploited to hierarchically construct high-level deep features automatically in order to conduct the HSI classification task. Similar work was also done by [
17], in which a specific deep CNN framework was presented to learn both spectral and spatial features. In [
18], various attribute profiles were extracted and stacked up on the raw HSI data as the input to a CNN model, which captured the geometric and spectral properties for HSI classification efficiently. The aforementioned state-of-the-art CNN models for HSI classification have focused on the automatic extraction of spectral and spatial features. Zhao, et al. [
19] investigated an approach to combine the deep learning features extracted at multiple spatial scales, which improved the performance for HSI classification to some extent. In [
20], a partial view selection strategy was utilized to compose a multiview input for a specific CNN architecture for land-use classification. There are some noteworthy examples where CNNs have been applied to, such as oil tank detection [
21], scene classification [
22], and road network extraction [
23].
As seen in the aforementioned examples, most CNN methods consider the HSI classification as a task of extracting robust high-level deep features. On the other hand, multiple feature learning aims to learn several types of features simultaneously in order to extract more representative features for image processing purposes. Multiple feature learning has been successfully applied to many computer vision-based fields, such as face detection [
24], pedestrian detection [
25] and multimedia search [
26]. However, there is a lack of comprehensive studies on multiple feature learning for HSI classification.
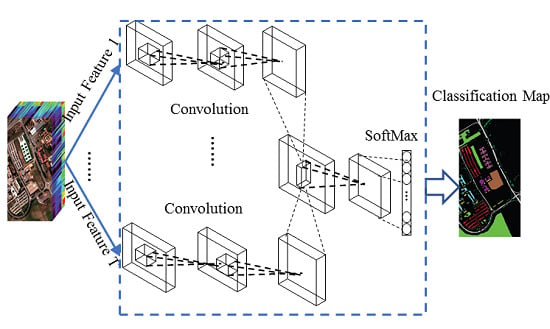
In order to extract robust and effective features from HSI classification, it is reasonable to explore CNN models which can simultaneously extract the spatial and spectral information from multiple HSI features. In this paper, an enhanced framework that combines a CNN and a multiple feature learning method is proposed. Considering that spatial information extracted by the proposed CNN is more about the neighboring information, other forms of geometrical information should be also investigated to boost the performance of HSI classification. Therefore, firstly, initial geometrical feature maps are extracted by four widely used attribute filters. The initial feature maps can reveal various spatial characteristics and local spatial correlations in the original image. Subsequently, the initial feature maps along with the original image are fed into a CNN which has different inputs corresponding to the different initial features. The representative features are extracted by several groups of subsequent layers and are used as the input to a concatenating layer to form a joint feature map which represents both spectral and contextual properties of HSI. The final labels of HSI pixels are determined by the subsequent layers with the joint feature map as input. The proposed framework does not need any post-processing step. The designed CNN consists of four key components: proper convolutional layers, a pooling layer, a concatenating layer and a rectified linear unit (ReLU) function. Since HSI has a problem with a limited number of training samples, a deeper and wider network without enough training samples may result in overfitting; hence the proposed network is a relatively shallow network but is an effective one. The pooling layer can provide spatial invariance, the concatenating layer is designed to exploit the rich information, and the ReLU function will accelerate the convergence. The main contributions of this paper include: (1) the construction of a novel CNN architecture which benefits from the multiple inputs corresponding to various image features; (2) the concurrent exploitation of both spectral and spatial contextual information; and (3) the proposed network that is robust and efficient even if a small number of training samples are available.
The remainder of this paper is organized as follows:
Section 2 introduces the overall mechanism of the designed CNN. The proposed framework is also presented in detail in this section. The experimental results and discussions are provided in
Section 3. Several impacts influential to the experimental results are also investigated in
Section 3. Finally, the conclusions are drawn in
Section 4 with some remarks.
2. The Context of the Proposed Framework
Figure 1 illustrates the structure of the proposed framework. The first step of this framework is the extraction of multiple HSI features followed by several CNN blocks. Given
sets of features, each individual CNN block will learn the corresponding representative feature map, and all the feature maps will be jointed by a concatenating layer. The weight and bias for each block are fine-tuned in this network through back propagation. The output of the network for each pixel is a vector of class membership probability with
units, corresponding to
classes defined in the hyperspectral data set. The main principles of the proposed framework are explained in detail in the following sections.
2.1. Extraction of Attribute Profiles
The characterization of spatial contextual information computed by morphological profiles (MPs) can represent the variability of the structures for images [
27]. However, features extracted by a specific MP cannot be modelled as other geometrical features. In order to model various geometrical characteristics simultaneously for the feature extraction in HSI classification, the application of attribute profiles (APs) is firstly introduced in the work of [
28]. APs showed interesting properties in HSI processing, which can be used to generate an extended AP (EAP).
APs are a generalized form of MPs, which can be obtained from an image by applying a criterion
. The construction of APs relies on the morphological attribute filters (AFs), and it can be obtained by applying a sequence of AFs to a scalar image [
28]. AFs are defined as the connected operators which process the image by merging its connected components instead of pixels. After the operators are applied to the regions, the attribute results are compared to a pre-defined reference value. The region is determined to be preserved or removed from the image depending on whether the criterion is met or not (i.e., the attribute results are preserved if the value is larger than the pre-defined reference value). The values in the removed region will be set as the closest grayscale value of the adjacent region. If the merged region is a lower (greater) gray level, then the thinning (thickening) is applied.
Subsequently, an AP can be directly constructed by using a sequence of thinning and thickening AFs which are applied to the image with a set of given criteria. By using
morphological thickening (
) and
thinning (
) operators, an AP from the image
can be constructed as:
Generally, there are some common criteria associated with the operators, such as area, volume, diagonal box, and standard deviation. According to the operators (thickening or thinning) used in the image processing, the image can be transformed to an extensive or anti-extensive one. In this paper, since our goal is to measure the effectiveness of multiple feature learning by the proposed CNN, but not to achieve absolute performance maximization, only APs based on four different criterions (i.e., area, standard deviation, the moment of inertia, and length of the diagonal) are extracted as the different feature maps for classification tasks. In addition, in this paper, the different AP features are named by the corresponding criterions. One can find the details of various APs from [
27].
2.2. Convolutional Neural Networks
CNNs aim to extract the representative features for different forms of data via multiple non-linear transformation architectures [
29]. The features learned by a CNN are usually more reliable and effective than rules-based features. In this paper, we consider HSI classification with the so-called
directed acyclic graphs (DAG) where the layers are not limited to chaining one after another. For HSI classification, a neural network can realize the function of mapping the input HSI pixels to the output pixel labels. The function is composed of a sequence of simple blocks that are called layers. The basic layers in a CNN are as follows:
Mathematically, an individual neuron is computed by taking a vector of inputs
and applying an operator to it with a weight filter
and bias
:
where
is a nonlinear function named as an activation function. For a convolutional layer, every neuron is related to a spatial location (
) with respect to the input image. The output
associated with the input can be defined as follows:
where
is the kernel function with the learned weights,
is the input or the layer, and
denotes the convolution operator. Usually at least one layer of the activation function is implemented in a network. The most frequently used activation functions are the sigmoid function and the ReLU function. The ReLU function has been considered to be more efficient than the sigmoid function in the convergence of the training procedure [
29]. The ReLU function is defined as follows:
Another important type of layers is pooling which is implemented as a down-sampling function. The most common types of pooling are the max-pooling and mean-pooling. The pooling function partitions the input feature map into a set of rectangles and outputs the max/mean value for each sub-region. Hence, the computational complexity can be reduced.
Typically, a softmax function is performed in the top layer so that a probability distribution as an output can be obtained with each unit representing a class membership probability. Based on the above principle, in this paper, different features of the raw image are fed into each corresponding CNN block, and the network is fine-tuned through the back propagation.
2.3. Architecture of Convolutional Neural Network
HSI contains several hundreds of spectral bands, and the input of a HSI classifier is usually the whole image. This is different from common classification problems. It has been acknowledged that spatial contextual information extraction is essential for HSI classification. Based on such knowledge, we choose a three dimensional structure of the HSI pixel as input to the built CNN model. Given a HSI cube , is the image size and denotes the number of spectral channels. For a test pixel (where is the index of the test pixel), a format structure of this pixel will be adopted as the input with being a fixed neighborhood size and representing the dimension of the input features. For example, for the original image cube, is equal to the number of the spectral channels . In this paper, after attribute profile features (i.e., area, standard deviation, length of diagonal, and moment of inertia) are extracted, each attribute can be expressed as , . denotes the tth attribute of , denotes the number of spectral channels of . For each pixel in , a neighborhood region patch will be chosen as the input to the corresponding model.
Each convolutional layer has a four-dimensional convolution of , where is the kernel size of the convolutional layer, is the dimension of input variable and denotes the number of kernels in each convolutional layer. For example, for a convolutional layer with an input size of , the output in the DAG will be a format of which will be the input of the next layer.
The three-dimensional format of the input in the proposed network makes the dimensionality around several hundreds (
), which may lead to an overfitting problem during the training procedure. In order to handle this situation, ReLU is applied to the proposed network. The adopted ReLU in this paper is a simple nonlinear function that produces 0 or 1 corresponding to the positive or negative input of a neuron. It has been confirmed that ReLU can boost the performance of networks in many cases [
30].
To perform the classification with the learned representative features, a softmax operator is applied to the top layer of the proposed network. Softmax is one of the probabilistic-based classification models which measure the correlation between an output value and a reference value by a probability score. It should be noted that in the CNN construction, softmax can be applied throughout the spectral channels for all spatial locations in a convolutional manner [
31]. For the given input of three dimension (
), the probability that the input belongs to class
is computed as follows:
In order to obtain the essential probability distribution using the softmax operator, the number of kernels of the last layer should be set as the same as the number of classes defined in the HSI data set. The whole training procedure of the network can be treated as the optimization of parameters, which can minimize a loss function between the network outputs and ground truth values for the training data set. Let
denote the target ground truth value corresponding to the text pixel
, and
be the output class membership distribution with
as the index of the test pixel. The multi-class hinge loss used in this paper is given by
Finally, the predication label is decided by taking the argmin value of the loss function:
3. Experimental Results and Discussion
The proposed framework was tested with three benchmark HSI data sets (The MATLAB implementation is available on request).
Section 3.1 below introduces the data sets and shows the class information.
Section 3.2 layouts the specific network architectures applied in this paper and other relevant information regarding the experimental evaluation.
Section 3.3 provides the experimental results for all the classifiers.
Section 3.4 highlights some additional experiments influential to the classification results. In this paper, the original features, as well as four attribute features extracted based on four attribute filters (i.e., area, moment of inertia, length of diagonal and standard deviation) are used as inputs to the proposed network. The parameters for each AP criterion are set as default as the ones in [
28].
In order to validate the effectiveness of the proposed mechanism, the proposed work is compared with the designed CNN with original images (referred to as O-CNN), and a CNN using all features (including the original images) stacked as input (referred to as E-CNN). As shown in
Figure 2, for fair comparison, these CNNs have architectures similar to the proposed network. The attribute features extracted in this paper have the parameters set as the ones in [
27]. All the programs are executed in Matlab 2015b. The test is conducted on Intel (R) Core (TM) i7-4790 CPU 3.60 GHz and 16 GB Installed Memory. All the convolutional network models are implemented based on the publicly available matconvnet [
31] with some modifications, and the optimization algorithms used in this paper are implemented by the Statistics and Machine Learning Toolbox in Matlab.
3.1. Data Description
To verify the effectiveness of the proposed framework, three benchmark data sets [
32] are used in this paper:
Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) data set: Indian Pines. It was obtained by the AVIRIS sensor over the site in northwest Indiana, United States of America (USA). This imagery has 16 labeled classes. The data set has 220 spectral bands ranging from 0.2 to 2.4 µm wavelength, and each channel has 145 × 145 pixels with a spatial resolution of 20 m. 20 water absorption bands are removed during the experiments.
Reflective Optics System Imaging Spectrometer (ROSIS) data set: University of Pavia, Italy. This image was acquired over Pavia in north Italy. It has nine labeled ground truths with 610 × 610 pixels. Each pixel has a 1.3 m spatial resolution. With water absorption bands removed, 103 bands are used in the experiment.
AVIRIS data set: Salinas. This image was also acquired by the AVIRIS sensor over Salinas Valley, California, USA. The image is of 512 × 217 pixels, and with 224 spectral bands. The Salinas data has a 3.7 m resolution per pixel and 16 different classes. The ground truth and false color images for the data sets are illustrated in
Figure 3.
For each of the three data sets, the samples are split into two subsets, i.e., a training set and a test set. The details of the number of the subsets are listed in
Table 1,
Table 2 and
Table 3. For training the architecture of each CNN block, 90% of the training pixels are used to learn the filter parameters for each CNN block and the remaining 10% are used as the validation set. The training set is used to adjust the weights on the neural network. The validation set is used to provide an unbiased evaluation of a model fit on the training data set, which means that this data set is predominately used to describe the evaluation of models when tuning hyper parameters. The test is used only to assess the performance of a fully-trained CNN model.
3.2. Network Design and Experimental Setup
CNN blocks for different features were designed to have the same architecture. There are three convolutional layers, pooling layers, ReLU layers and concatenating layers. The details of the network structure are listed in
Table 4,
Table 5 and
Table 6. The input images are initially normalized into [−1 1]. The number of kernels in each convolutional layer is set as 200 empirically. The input neighborhood of each feature is set as 5 × 5, 7 × 7 and 9 × 9 for the Indian Pines data set, the University of Pavia data set and the Salinas data set, respectively. The learning rate for CNN models is set as 0.01; the number of epochs is set as 100 for the Indian Pines and the University of Pavia data sets, and 150 for the Salinas data set. The batch size is set as 10. To quantitatively validate the results of the proposed framework, overall accuracy (OA), average accuracy (AA) and the Kappa coefficient (
) are adopted as the performance metrics. Each result is shown as an average of ten times repeated experiments with the randomly chosen training samples.
3.3. Experimental Results and Discussion
3.3.1. Classification Results for the Indian Pines Data Set
Table 7 shows the classification results obtained by different classifiers for the Indian Pines data set, and the resultant maps are provided in
Figure 4. One can observe that all the CNN-based models achieve a good performance, and the proposed method provides the improved results on this data set. For O-CNN, the original image is set as the input for the network. In order to verify the effectiveness of the proposed mechanism, the spatial contextual features are extracted and stacked together to be fed into the network for E-CNN. E-CNN has achieved more accurate results than O-CNN, but failed to outperform the proposed method. The best performance achieved by the proposed framework is probably due to the joint exploitation of spatial-spectral information. One can conclude that the proposed method produces less “salt-and-pepper” noise on the classification maps. In comparison with O-CNN, OA, AA and Kappa of the proposed method are improved by 8.43%, 3.69% and 9.5%. The same conclusion can be made when the proposed method is compared with E-CNN, especially the improvement is quite significant for the sets of similar class labels as can be observed from
Table 7. For example, the accuracies obtained by the proposed method for the classes Soybeans-no till, Soybeans-min till and Soybeans-clean till (class no. 10, 11, and 12) are 5.76%, 7.82% and 5.74% higher than those obtained by the E-CNN. The same conclusion can be obtained when the individual class accuracies for the similar sets of Grass-tress, Grass-pasture and Grass-pasture mowed (class no. 5, 6, and 7) are inspected. The results show that the proposed algorithm has a very competitive ability in classifying the similar and mixed pixels. In addition, the proposed method has demonstrated the best performance in terms of preserving the discontinuities which can be observed from the classification maps. Moreover, CNN methods do not need predefined parameters whereas pixel-level extraction methods require them.
3.3.2. Classification Results of the University of Pavia Data Set
The class-specific classification accuracies for the University of Pavia image and the representative classification maps are provided in
Table 8 and
Figure 5, respectively. From the results, one can see that the proposed method outperforms the other algorithms in terms of OA, AA and Kappa. The proposed method significantly improves the results with a very high accuracy when tested with the University of Pavia data set. From the illustrative results in classification maps, O-CNN and E-CNN show more noisy scattered points in the images. The proposed method can remove them and lead to smoother classification results without blurring the boundaries.
3.3.3. Classification Results of the Salinas Data Set
Table 9 shows the classification results for the Salinas data set with different classifiers, and the classification accuracies are illustrated in
Figure 6. The results are similar to the previous two data sets. Under the condition of the same training samples, the proposed method outperforms the other approaches in terms of OA, AA and Kappa. Although E-CNN improved the classification results of O-CNN by stacking different features, the improvement is limited when compared to the proposed framework. The better performance of the proposed network proves the capacity and effectiveness of the built network for multiple feature learning.
3.4. Discussion of Effects of Different Parameters
3.4.1. The Impact of the Number of Training Epochs
The number of training epochs is an important parameter for the CNN-based methods.
Figure 7 shows that the training error varies with the number of training epochs on all three data sets. In the training process for a network, the back propagation is implemented by minimizing the training error “objective” which is computed by
Here, the trend of the “error” item is computed by
where
Nt denotes the number of training samples,
pic denotes the
cth prediction probability of the training pixel
xi which belongs to the
cth class. It is helpful and useful for assessment. From
Figure 7, one can observe that it converges faster for the training process of the Indian Pines image and the University of Pavia image, slower for the Salinas image. ReLU is an important factor which is influential to the training procedure; ReLU can accelerate the convergence of the network and improve the training efficiency [
29].
3.4.2. The Impact of Training Samples
One critical factor to the training a CNN is the number of training samples. It is widely known that a CNN may not extract effective features unless abundant training samples are available. However, it is not common for HSI to have a large number of training samples, hence it is very important to build a network that is robust and efficient for the classification task.
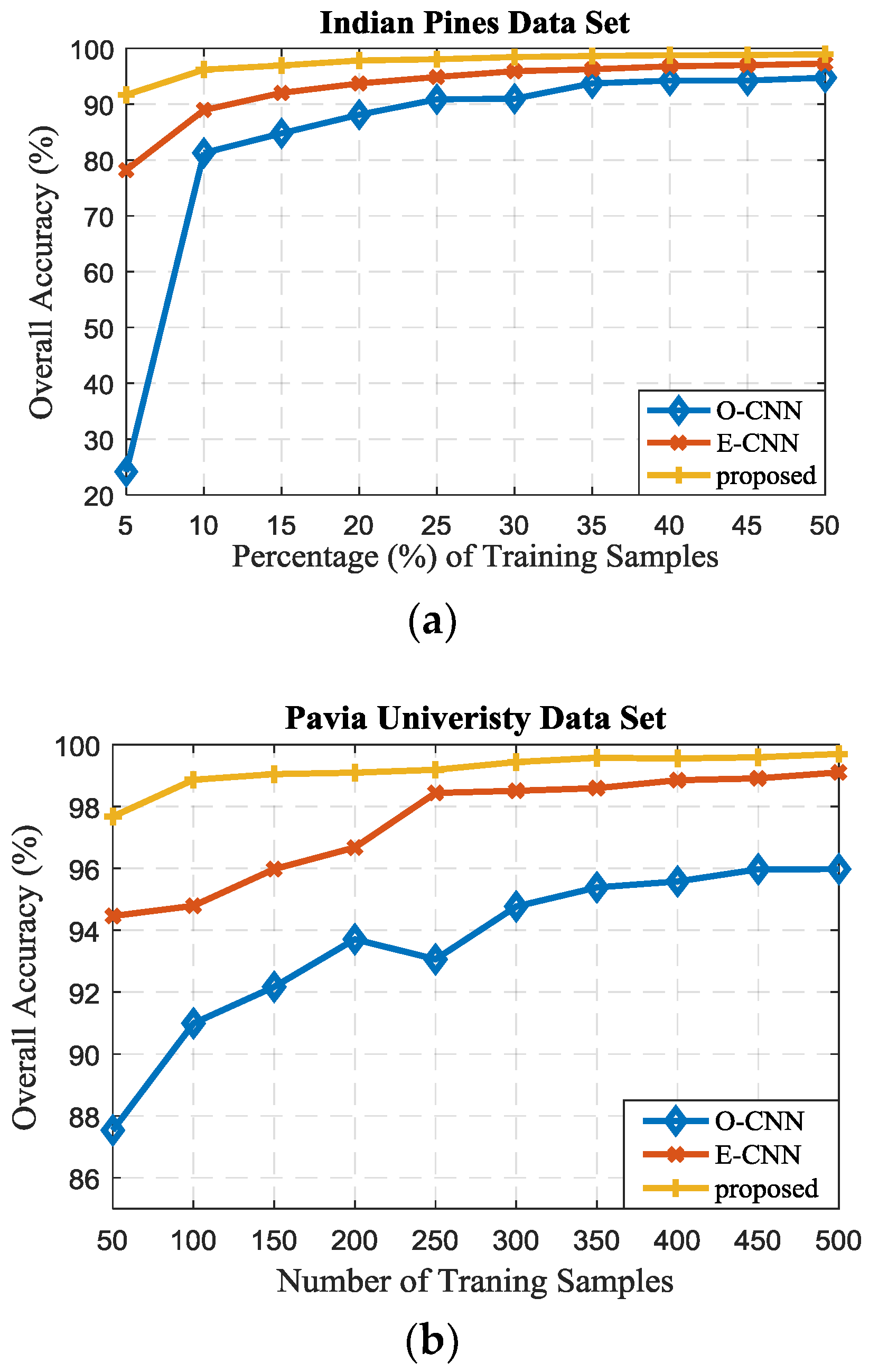
In this paper, the impacts of the number of training samples on the accuracies of three data sets are also tested. For the Indian Pines scene, 5 to 50% of the samples are randomly selected as training pixels and the remaining pixels are used as the test set. For both the University of Pavia and the Salinas images, 50 to 500 pixels per class are chosen randomly as the training samples with the remaining as the test set.
Figure 8 illustrates the OA for various methods with different numbers of training pixels. From
Figure 8, one can see that all the methods perform better if the number of training samples increases for the Indian Pines data set, and the proposed method performs the best. Especially, the proposed method obtains an accuracy of higher than 95% with less than 10% training samples. The accuracies tend to become stabilized for these three methods if the number of training samples further increases. For the University of Pavia data set, the classification accuracies for these CNN-based methods show approximately 100% as the number of training samples further increases, especially for the proposed method which has the accuracy more than 96% with 50 samples per class. For the Salinas data set, the performances for all approaches fluctuate in a range, and the proposed method performs the best in most cases. It should be noted that for the whole three data sets, the CNN-based classifiers are more sensitive to the number of training samples and the accuracy increases as the number of training samples increases. In addition, the CNN-based approaches can achieve a competitive performance with a large number of training samples, and the proposed method shows more robustness with a variety of the number of training samples.
3.4.3. The Impact of Input Neighborhood Size
The neighborhood size
of the input image is another important factor related to the classification results.
Figure 9 illustrates the network architectures with inputs of different neighborhood sizes. The only difference for the three data sets is the number of kernels in the last layer, which is 16 for the Indian Pines and the Salinas data sets, and 9 for the University of Pavia data set. It should be noted that, in order to obtain the probability scores corresponding to different classes, the number of kernels in the last layer should be the number of labeled classes for each data set. In
Figure 9, we take the University of Pavia data set as an example. As shown in
Table 10,
Table 11 and
Table 12, the performances decrease with the neighborhoods up to 7 × 7, 9 × 9 and 11 × 11 for three data sets, respectively. The performance degradation may be caused by the “over-smoothing” effect across the boundaries as the neighborhood size increases. Hence, 5 × 5, 7 × 7 and 9 × 9 are the optimal neighborhood sizes for the three data sets in the proposed network.
3.4.4. The Analysis of Multiple Feature Learning
To verify the effectiveness of the multiple feature learning, the experimental results for the designed CNN (
Figure 2a) with individual features (i.e., area, moment of inertia, length of diagonal and standard deviation) are also shown in
Table 13,
Table 14 and
Table 15 for the validation. From these tables, one can see that the designed CNN with features of length of diagonal performs better than other networks. Compared with the results in
Table 7,
Table 8 and
Table 9, it is obvious that E-CNN compromises the accuracy for the classification. This may be due to the data augmentation caused by the initial concatenation which is not proper for the spatial filter. The higher accuracy obtained by the proposed method benefits from the joint exploitation in the processing stage where the dimension has been cut off by the spatial filter. In addition, the concatenation of the various features at first step of E-CNN may lose the discriminative information during the training process. The various features possess different properties, learnt through the individual convolutional layers can help extract the better feature representations for the classification which leads to a superior performance. The proposed joint structure-based multi-feature learning can adaptively learning the heterogeneity of each feature, and eventually result in a better performance. It can be concluded that the comparison results with individual features reveal the effectiveness of the multiple feature learning technique of the proposed method.
3.4.5. Training Time
The training and test time averaged over ten repeated experiments for the three data sets are given in
Table 16. The training procedure for a CNN is time-consuming; however, another advantage of CNN algorithms is that they are fast for testing. In addition, the training time would take just a few seconds with GPU processing.
4. Conclusions
In order to prove the potential of CNNs for HSI classification, we presented a framework consisting of a novel CNN model. The framework was designed to have several individual CNN blocks with comprehensive features as input. To enhance the learning efficiency as well as to leverage both the spatial contextual and spectral information of the HSI, the output feature maps of each block are then concatenated and fed into subsequent convolutional layers to derive the pixel label vectors. By using the proper architecture, the built network is a shallow but efficient one, and it can concurrently exploit the interactions of different spectral and spatial contextual information by using the concatenating layer. In comparison with the CNN-based single feature learning method, the classification results are improved significantly with multiple features involved. Moreover, in contrast to the traditional rule-based classifiers, the CNN-based framework can extract the deep features automatically and in a more efficient way.
Moreover, the experiments suggest that a three-layer CNN is optimal for HSI classification, and the neighborhood size between 2 × 2 to 6 × 6 can balance the efficiency and complexity of the network. The pooling layer with a size of 2 × 2 and 200 kernels in each layer can provide an enough capacity for the network. Since the training samples are very limited in HSI classification, the multiple input feature maps and ReLU in the proposed network can help alleviate the overfitting phenomenon and accelerate convergence. The tests with three benchmark data sets showed superior performances of the proposed framework. As CNNs are gaining attention due to the strong ability in extracting the relevant features for image classification, the proposed method is expected to provide various improvements for the better feature representation purpose.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Alfalfa
Alfalfa Corn-no till
Corn-no till Corn-min till
Corn-min till Corn
Corn Grass/trees
Grass/trees Grass/pasture
Grass/pasture Grass/pasture-mowed
Grass/pasture-mowed Hay-windrowed
Hay-windrowed Oats
Oats Soybeans-no till
Soybeans-no till Soybeans-min till
Soybeans-min till Soybeans-clean till
Soybeans-clean till Wheat
Wheat Woods
Woods Buildings-grass-trees
Buildings-grass-trees Stone-steel towers
Stone-steel towers Gravel
Gravel Trees
Trees Bare soil
Bare soil Bricks
Bricks Shadows
Shadows Stubble
Stubble Lettuce 5 week
Lettuce 5 week Lettuce 6 week
Lettuce 6 week Lettuce 7 week
Lettuce 7 week Vineyard untrained
Vineyard untrained