Figure 1.
The structures of (a) supervised and (b) semi-supervised spectral–spatial deep learning for HSI classification.
Figure 1.
The structures of (a) supervised and (b) semi-supervised spectral–spatial deep learning for HSI classification.
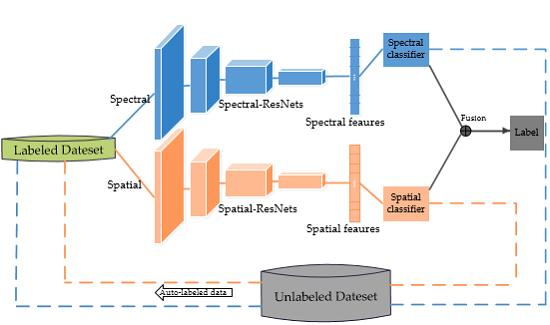
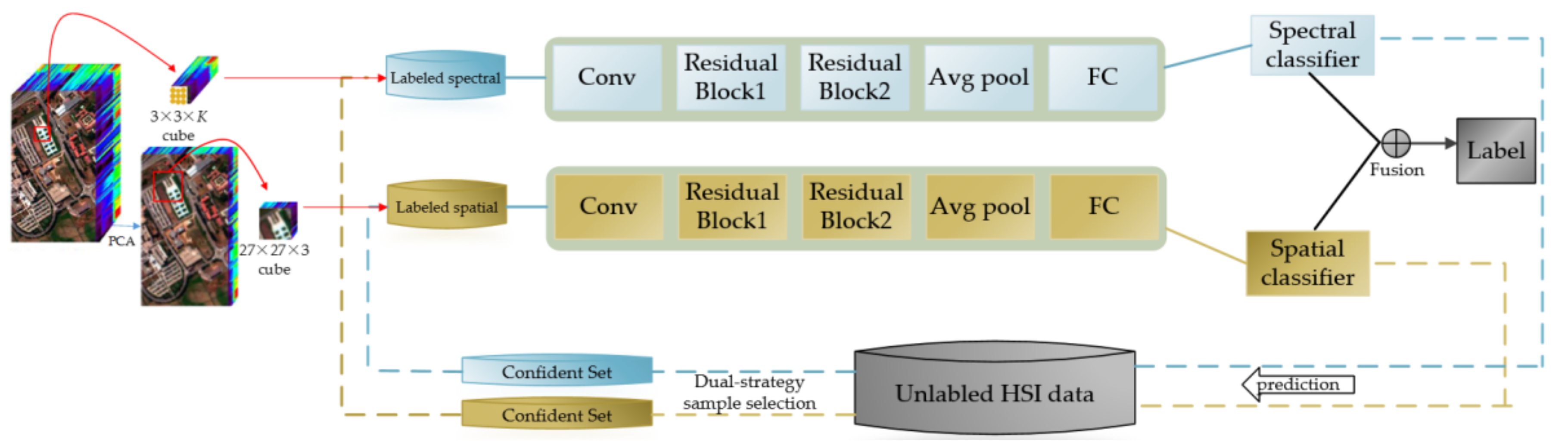
Figure 2.
Overview of semi-supervised deep learning framework for hyperspectral image (HSI) classification. The training of the framework mainly two iterative steps: (1) Training the spectral- and spatial- models over the respective data based on the labeled pool (indicated as solid lines); (2) applying each model to predict the unlabeled HSI data and use respective sample selection strategy to select the most confident samples for the other (indicated as dashed lines. See details in the text). After all iterations of co-training are completed, the classification results of the test dataset which obtained through two training networks were fused, and then the label of the test dataset was obtained (indicated as solid black lines).
Figure 2.
Overview of semi-supervised deep learning framework for hyperspectral image (HSI) classification. The training of the framework mainly two iterative steps: (1) Training the spectral- and spatial- models over the respective data based on the labeled pool (indicated as solid lines); (2) applying each model to predict the unlabeled HSI data and use respective sample selection strategy to select the most confident samples for the other (indicated as dashed lines. See details in the text). After all iterations of co-training are completed, the classification results of the test dataset which obtained through two training networks were fused, and then the label of the test dataset was obtained (indicated as solid black lines).
Figure 3.
A residual network for spatial-ResNet model, which contains two “bottleneck” building blocks, and each building block has one shortcut connection. The number on each building block is the number of output feature map. F(x) is the residual mapping and x is the identity mapping, for each residual function, we use a stack of 3 layers. The original mapping is represented as F(x) + x.
Figure 3.
A residual network for spatial-ResNet model, which contains two “bottleneck” building blocks, and each building block has one shortcut connection. The number on each building block is the number of output feature map. F(x) is the residual mapping and x is the identity mapping, for each residual function, we use a stack of 3 layers. The original mapping is represented as F(x) + x.
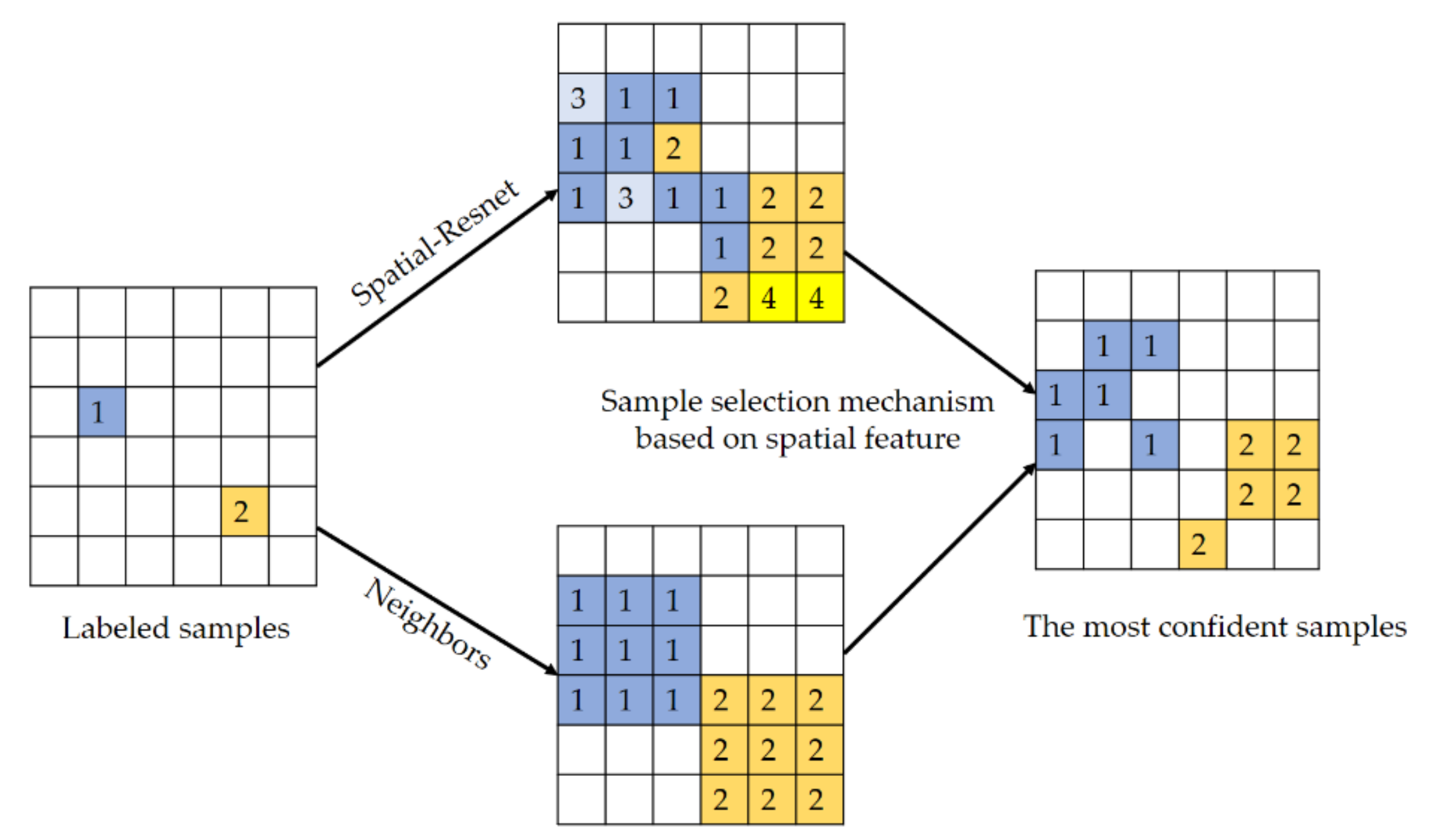
Figure 4.
The process of sample selection mechanism based on spatial feature.
Figure 4.
The process of sample selection mechanism based on spatial feature.
Figure 5.
AVIRIS Indian Pines image. (a) False-color image. (b) Reference image. Black area denotes unlabeled pixels.
Figure 5.
AVIRIS Indian Pines image. (a) False-color image. (b) Reference image. Black area denotes unlabeled pixels.
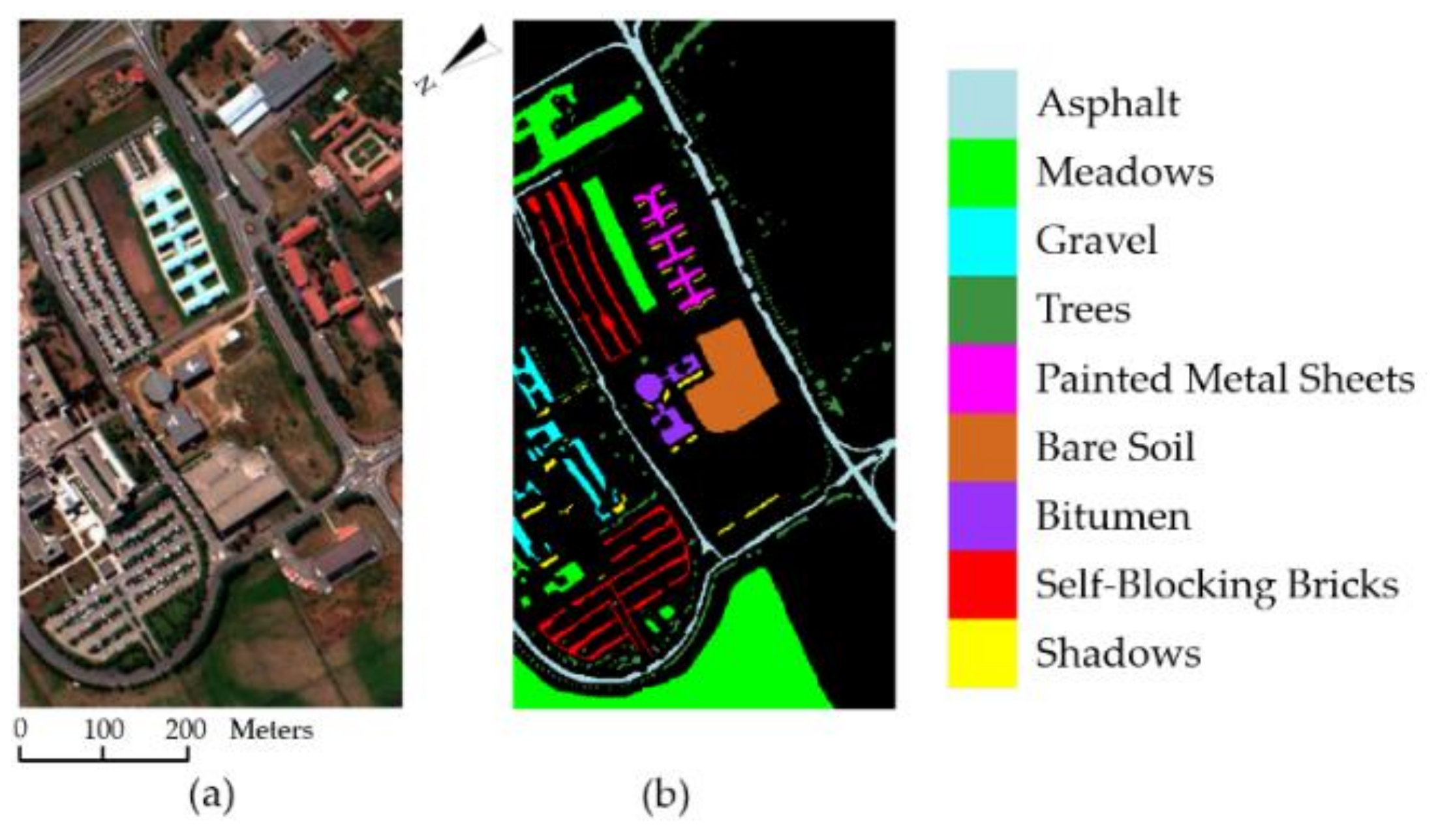
Figure 6.
ROSIS-03 University of Pavia image. (a) True color image. (b) Reference image. Black area denotes unlabeled pixels.
Figure 6.
ROSIS-03 University of Pavia image. (a) True color image. (b) Reference image. Black area denotes unlabeled pixels.
Figure 7.
AVIRIS Salinas Valley image. (a) True color image. (b) Reference image. Black area denotes unlabeled pixels.
Figure 7.
AVIRIS Salinas Valley image. (a) True color image. (b) Reference image. Black area denotes unlabeled pixels.
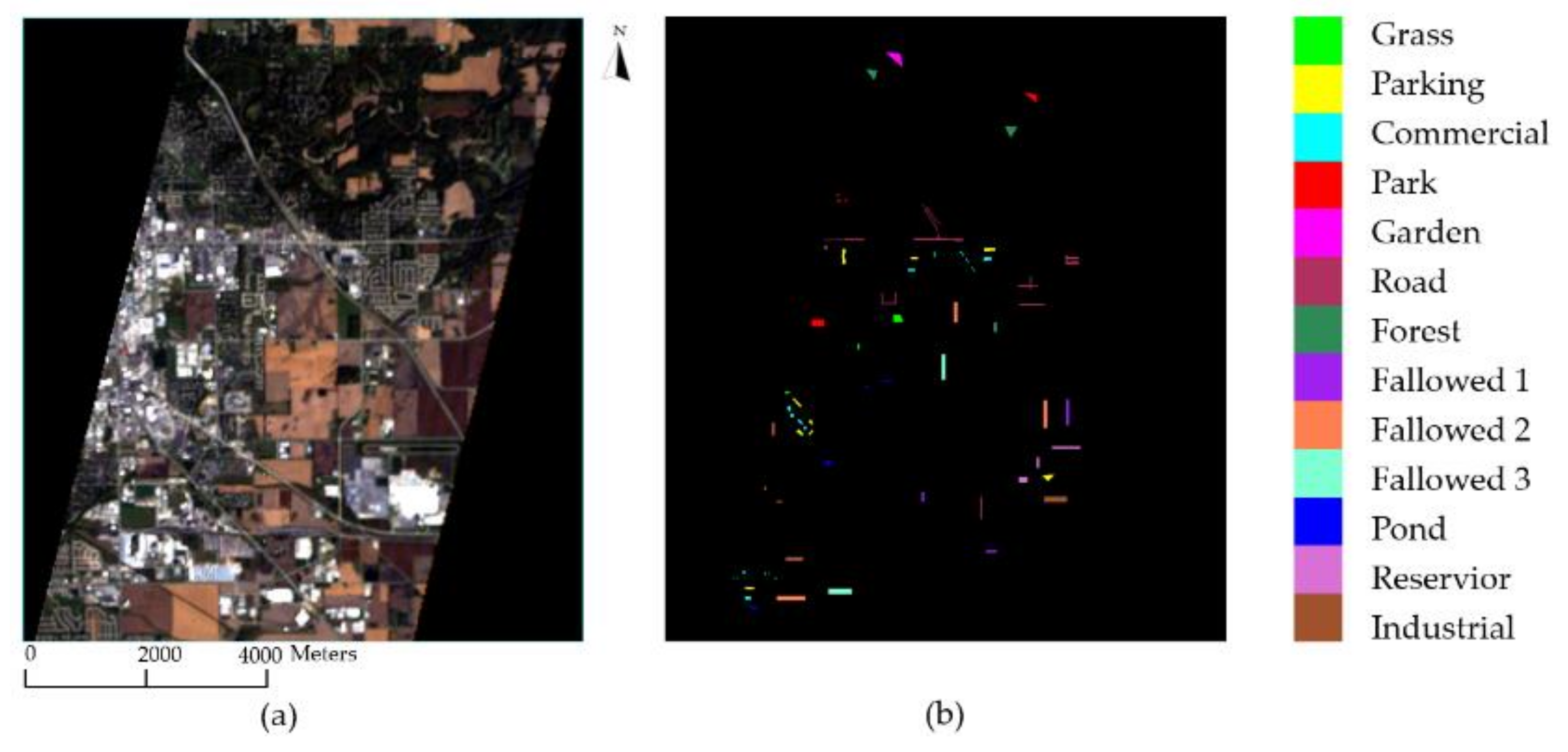
Figure 8.
Hyperion image. (a) True color image. (b) Reference image. Black area denotes unlabeled pixels.
Figure 8.
Hyperion image. (a) True color image. (b) Reference image. Black area denotes unlabeled pixels.
Figure 9.
Classification results of AVIRIS Indian Pines. (a) False-color image. (b) Reference image (c) Label = 5, OA = 92.35%. (d) Label = 10, OA = 96.34%. (e) Label = 15, OA = 98.38%. (f) Label = 20, OA = 98.2%.
Figure 9.
Classification results of AVIRIS Indian Pines. (a) False-color image. (b) Reference image (c) Label = 5, OA = 92.35%. (d) Label = 10, OA = 96.34%. (e) Label = 15, OA = 98.38%. (f) Label = 20, OA = 98.2%.
Figure 10.
Classification results of ROSIS Pavia University data. (a) True color image. (b) Reference image (c) Label = 5, OA = 89.7%. (d) Label = 10, OA = 97.13%. (e) Label = 15, OA = 98.9%. (f) Label = 20, OA = 99.40%.
Figure 10.
Classification results of ROSIS Pavia University data. (a) True color image. (b) Reference image (c) Label = 5, OA = 89.7%. (d) Label = 10, OA = 97.13%. (e) Label = 15, OA = 98.9%. (f) Label = 20, OA = 99.40%.
Figure 11.
Classification results of AVIRIS Salinas Valley. (a) True color image. (b) Reference image (c) Label = 5, OA = 95.69%. (d) Label = 10, OA = 98.09%. (e) Label = 15, OA = 98.59%. (f) Label = 20, OA = 99.08%.
Figure 11.
Classification results of AVIRIS Salinas Valley. (a) True color image. (b) Reference image (c) Label = 5, OA = 95.69%. (d) Label = 10, OA = 98.09%. (e) Label = 15, OA = 98.59%. (f) Label = 20, OA = 99.08%.
Figure 12.
Classification results of Hyperion data with 5, 10 and 15 initial labeled samples per class. (a) True color image. (b) Label = 5, OA = 82.56%. (c) Label = 10, OA = 91.89%. (d) Label = 15, OA = 93.97%.
Figure 12.
Classification results of Hyperion data with 5, 10 and 15 initial labeled samples per class. (a) True color image. (b) Label = 5, OA = 82.56%. (c) Label = 10, OA = 91.89%. (d) Label = 15, OA = 93.97%.
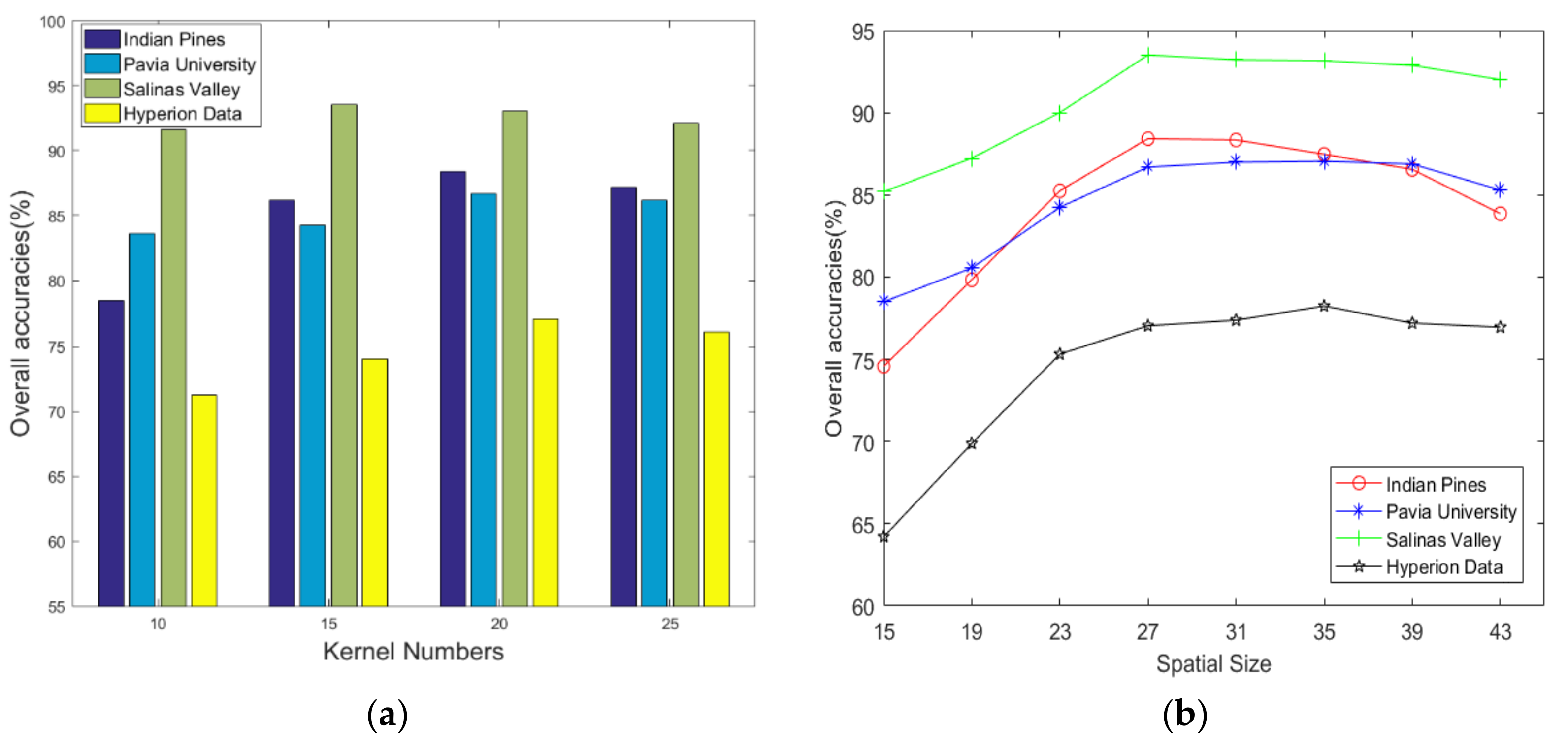
Figure 13.
Influence of network hyper-parameters. (a) Overall accuracies of different kernel numbers. (b) Overall accuracies of different spatial size.
Figure 13.
Influence of network hyper-parameters. (a) Overall accuracies of different kernel numbers. (b) Overall accuracies of different spatial size.
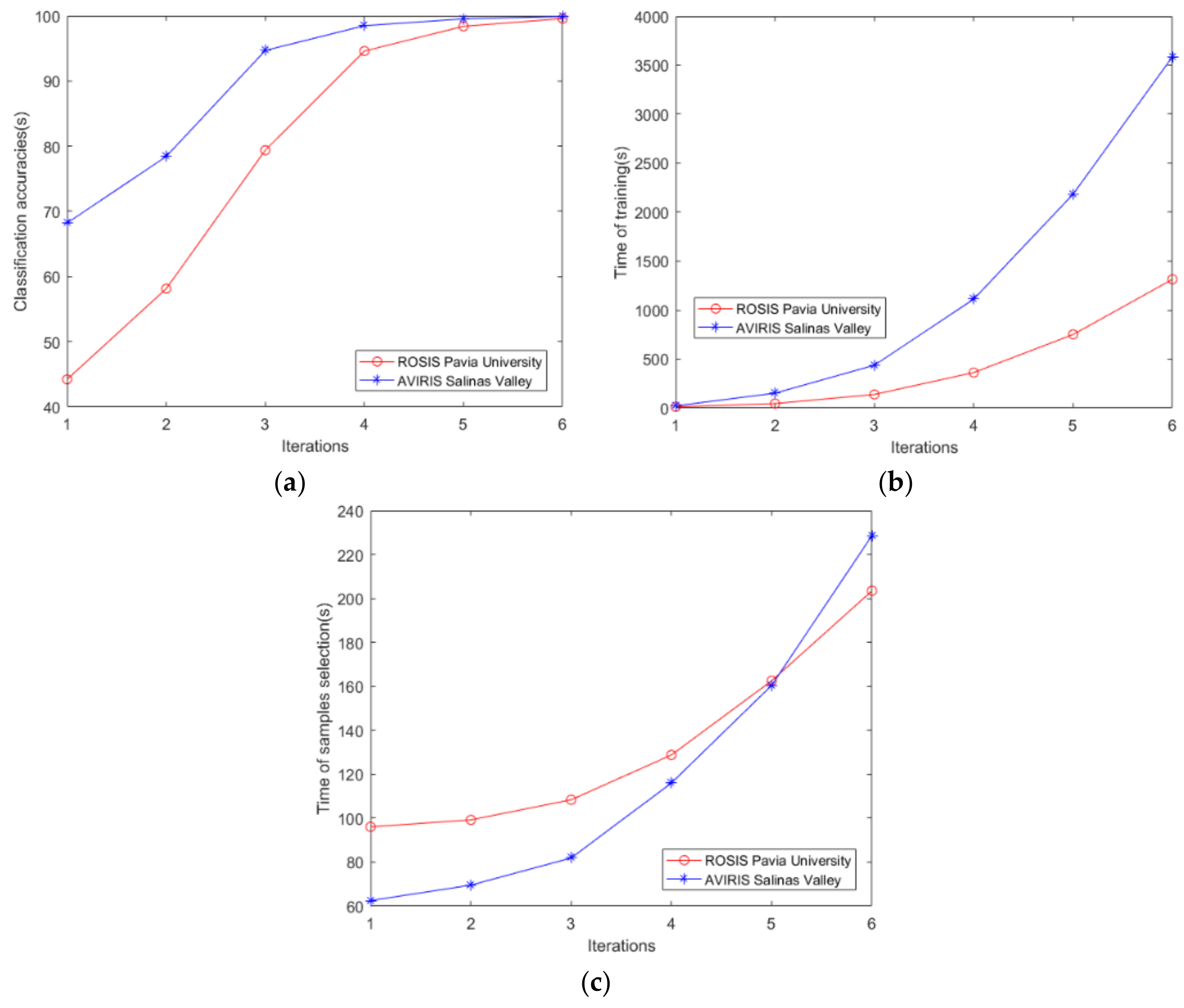
Figure 14.
Performance analysis of effect of the number of iterations of co-training. (a) Classification accuracies of different iterations. (b) Time cost of the network training progress of different iterations of co-training. (c) Time cost of the sample selection progress of different iterations of co-training.
Figure 14.
Performance analysis of effect of the number of iterations of co-training. (a) Classification accuracies of different iterations. (b) Time cost of the network training progress of different iterations of co-training. (c) Time cost of the sample selection progress of different iterations of co-training.
Table 1.
Classification accuracy (%) of the proposed algorithm for AVIRIS Indian Pines with 5, 10, 15 and 20 initial training samples per class and iterations of co-training.
Table 1.
Classification accuracy (%) of the proposed algorithm for AVIRIS Indian Pines with 5, 10, 15 and 20 initial training samples per class and iterations of co-training.
| Class | Labeled Samples Per Class |
|---|
| No. | Number of Samples | 5 | 10 | 15 | 20 |
|---|
| 1 | 46 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 2 | 1428 | 82.99 ± 6.41 | 94.56 ± 2.12 | 97.27 ± 1.07 | 97.74 ± 0.52 |
| 3 | 830 | 86.16 ± 8.97 | 94.07 ± 0.99 | 97.57 ± 1.39 | 96.69 ± 1.14 |
| 4 | 237 | 99.57 ± 0.67 | 98.40 ± 2.57 | 99.48 ± 0.72 | 95.08 ± 3.34 |
| 5 | 483 | 95.68 ± 1.85 | 98.87 ± 1.17 | 99.22 ± 0.66 | 99.35 ± 0.41 |
| 6 | 730 | 98.83 ± 0.95 | 99.64 ± 0.76 | 99.86 ± 0.22 | 99.74 ± 0.27 |
| 7 | 28 | 97.83 ± 3.64 | 99.31 ± 1.97 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 8 | 478 | 99.83 ± 0.25 | 99.97 ± 0.07 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 9 | 20 | 95.56 ± 5.44 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 10 | 972 | 87.94 ± 3.53 | 96.09 ± 2.11 | 98.38 ± 0.92 | 98.67 ± 1.34 |
| 11 | 2455 | 76.40 ± 11.03 | 92.07 ± 2.17 | 96.26 ± 1.64 | 97.26 ± 0.46 |
| 12 | 593 | 93.31 ± 4.47 | 95.22 ± 2.36 | 98.82 ± 0.70 | 98.14 ± 1.52 |
| 13 | 205 | 99.42 ± 0.80 | 84.93 ± 13.47 | 92.98 ± 6.97 | 96.04 ± 3.24 |
| 14 | 1265 | 96.93 ± 3.67 | 95.45 ± 2.03 | 97.41 ± 0.74 | 97.20 ± 0.69 |
| 15 | 386 | 96.33 ± 2.25 | 96.44 ± 2.54 | 97.71 ± 1.53 | 93.03 ± 6.84 |
| 16 | 93 | 98.86 ± 1.44 | 99.55 ± 0.90 | 97.44 ± 3.89 | 99.32 ± 1.15 |
| OA | 88.42 ± 3.07 | 95.07 ± 1.02 | 97.66 ± 0.63 | 97.66 ± 0.85 |
| AA | 94.11 ± 1.12 | 96.54 ± 0.88 | 98.28 ± 0.71 | 98.39 ± 0.49 |
| 86.90 ± 3.44 | 94.39 ± 1.16 | 97.34 ± 0.72 | 97.36 ± 0.40 |
| F1-measure | 90.09 ± 0.01 | 95.66 ± 0.01 | 97.87 ± 0.01 | 97.27 ± 0.01 |
Table 2.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on AVIRIS Indian Pines with 5, 10, 15 and 20 initial training samples per class.
Table 2.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on AVIRIS Indian Pines with 5, 10, 15 and 20 initial training samples per class.
| Algorithm | | Labeled Samples Per Class |
|---|
| 5 | 10 | 15 | 20 |
|---|
| CNN | OA | 47.33 ± 4.19 | 64.09 ± 2.76 | 68.90 ± 1.73 | 79.62 ± 1.06 |
| AA | 57.71 ± 2.74 | 78.5 ± 2.61 | 83.38 ± 1.25 | 88.73 ± 0.89 |
| 41.95 ± 4.45 | 59.77 ± 2.74 | 65.15 ± 1.26 | 79.93 ± 0.93 |
| CDL-MD-L | OA | 74.85 | 86.46 ± 1.78 | 90.22 | 91.54 |
| AA | 72.98 | 79.30 ± 1.66 | 85.12 | 88.02 |
| 74.13 | 84.63 ± 2.00 | 88.94 | 91.06 |
| Co-DC-CNN | OA | 85.81 ± 3.33 | 92.31 ± 1.23 | 95.13 ± 0.79 | 94.89 ± 1.02 |
| AA | 91.58 ± 1.32 | 93.53 ± 1.09 | 95.37 ± 0.87 | 95.40 ± 0.79 |
| 84.64 ± 3.39 | 91.40 ± 1.54 | 94.88 ± 0.95 | 94.01 ± 0.74 |
| Proposed | OA | 88.42 ± 3.07 | 95.07 ± 1.02 | 97.66 ± 0.63 | 97.66 ± 0.85 |
| AA | 94.11 ± 1.12 | 96.54 ± 0.88 | 98.28 ± 0.71 | 98.39 ± 0.49 |
| 86.90 ± 3.44 | 94.39 ± 1.16 | 97.34 ± 0.72 | 97.36 ± 0.40 |
Table 3.
Classification accuracy (%) of semi-supervised classifiers algorithms on AVIRIS Indian Pines with 5, 10, 15 and 20 initial training samples per class.
Table 3.
Classification accuracy (%) of semi-supervised classifiers algorithms on AVIRIS Indian Pines with 5, 10, 15 and 20 initial training samples per class.
| Algorithm | | Labeled Samples Per Class |
|---|
| 5 | 10 | 15 | 20 |
|---|
| PNGrow | OA | 82.11 ± 2.69 | 89.18 ± 1.54 | 91.80 ± 2.07 | 93.22 ± 1.10 |
| AA | 88.60 ± 1.2 | 92.58 ± 1.1 | 94.26 ± 1.1 | 94.96 ± 0.7 |
| 79.74 ± 3.0 | 87.70 ± 1.7 | 90.66 ± 2.3 | 92.27 ± 1.2 |
| TT_AL_MSH_MKE | OA | 71.05 ± 7.76 | 79.36 ± 6.95 | 83.44 ± 5.45 | n/d |
| AA | 80.48 ± 5.86 | 86.45 ± 4.93 | 89.38 ± 3.55 | n/d |
| 67.88 ± 8.17 | 77.02 ± 7.46 | 81.45 ± 5.91 | n/d |
| S2CoTraC | OA | 69.15 ± 2.25 | 79.18 ± 0.56 | 90.40 ± 1.65 | 93.53 ± 0.69 |
| AA | 82.96 ± 2.64 | 88.93 ± 1.38 | 94.83 ± 0.94 | 94.20 ± 0.41 |
| 65.97 ± 2.30 | 76.69 ± 0.53 | 89.10 ± 1.85 | 92.61 ± 0.78 |
| Proposed | OA | 88.42 ± 3.07 | 95.07 ± 1.02 | 97.66 ± 0.63 | 97.66 ± 0.85 |
| AA | 94.11 ± 1.12 | 96.54 ± 0.88 | 98.28 ± 0.71 | 98.39 ± 0.49 |
| 86.90 ± 3.44 | 94.39 ± 1.16 | 97.34 ± 0.72 | 97.36 ± 0.40 |
Table 4.
Classification accuracy (%) of the proposed algorithm for ROSIS Pavia University data with 5, 10, 15 and 20 initial training samples per class and iterations of co-training.
Table 4.
Classification accuracy (%) of the proposed algorithm for ROSIS Pavia University data with 5, 10, 15 and 20 initial training samples per class and iterations of co-training.
| Class | Labeled Samples Per Class |
|---|
| No. | Number of Samples | 5 | 10 | 15 | 20 |
|---|
| 1 | 6631 | 78.96 ± 9.94 | 93.40 ± 3.26 | 97.31 ± 0.66 | 98.51 ± 0.72 |
| 2 | 18,649 | 83.10 ± 5.93 | 96.40 ± 2.28 | 98.88 ± 0.55 | 99.28 ± 0.53 |
| 3 | 2099 | 89.14 ± 3.76 | 97.57 ± 1.52 | 98.55 ± 0.66 | 99.18 ± 0.49 |
| 4 | 3064 | 97.49 ± 0.35 | 97.54 ± 0.75 | 98.03 ± 0.75 | 98.71 ± 0.42 |
| 5 | 1345 | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.97 ± 0.06 | 99.99 ± 0.03 |
| 6 | 5029 | 90.17 ± 5.20 | 97.58 ± 1.34 | 99.74 ± 0.28 | 99.96 ± 0.04 |
| 7 | 1330 | 98.68 ± 0.97 | 98.35 ± 0.68 | 99.93 ± 0.09 | 99.90 ± 0.11 |
| 8 | 3682 | 91.33 ± 2.27 | 93.15 ± 4.35 | 97.65 ± 0.69 | 98.27 ± 0.74 |
| 9 | 947 | 99.05 ± 0.66 | 99.08 ± 1.02 | 99.95 ± 0.08 | 99.87 ± 0.25 |
| OA | 86.69 ± 2.94 | 96.16 ± 1.05 | 98.64 ± 0.21 | 99.16 ± 0.24 |
| AA | 91.99 ± 1.04 | 97.01 ± 0.66 | 98.89 ± 0.12 | 99.30 ± 0.14 |
| 82.94 ± 3.57 | 94.95 ± 1.36 | 98.21 ± 0.27 | 98.89 ± 0.32 |
| F1-measure | 86.19 ± 0.01 | 96.23 ± 0.01 | 97.76 ± 0.01 | 98.60 ± 0.00 |
Table 5.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on ROSIS Pavia University data with 5, 10, 15 and 20 labeled samples per class.
Table 5.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on ROSIS Pavia University data with 5, 10, 15 and 20 labeled samples per class.
| Algorithm | | Labeled Samples Per Class |
|---|
| 5 | 10 | 15 | 20 |
|---|
| CNN | OA | 55.40 ± 3.89 | 69.02 ± 2.26 | 72.38 ± 1.26 | 79.34 ± 0.51 |
| AA | 55.89 ± 3.31 | 63.13 ± 1.77 | 69.79 ± 1.37 | 77.52 ± 0.58 |
| 44.16 ± 3.84 | 59.86 ± 1.95 | 64.62 ± 1.48 | 73.84 ± 0.43 |
| CDL-MD-L | OA | 72.85 | 82.61 ± 2.95 | 88.04 | 91.89 |
| AA | 78.58 | 85.10 ± 2.45 | 89.12 | 91.32 |
| 63.71 | 0.7807 ± 0.03 | 83.64 | 88.42 |
| Co-DC-CNN | OA | 83.47 ± 3.01 | 94.99 ± 1.49 | 95.33 ± 0.32 | 97.45 ± 0.45 |
| AA | 88.52 ± 1.39 | 95.51 ± 1.13 | 96.68 ± 0.27 | 98.72 ± 0.23 |
| 81.78 ± 3.81 | 93.63 ± 1.31 | 95.72 ± 0.49 | 98.67 ± 0.40 |
| Proposed | OA | 86.69 ± 2.94 | 96.16 ± 1.05 | 98.64 ± 0.21 | 99.16 ± 0.24 |
| AA | 91.99 ± 1.04 | 97.01 ± 0.66 | 98.89 ± 0.12 | 99.30 ± 0.14 |
| 82.94 ± 3.57 | 94.95 ± 1.36 | 98.21 ± 0.27 | 98.89 ± 0.32 |
Table 6.
Classification accuracy (%) of semi-supervised classifiers algorithms on ROSIS Pavia University data with 5, 10, 15 and 20 labeled samples per class.
Table 6.
Classification accuracy (%) of semi-supervised classifiers algorithms on ROSIS Pavia University data with 5, 10, 15 and 20 labeled samples per class.
| Algorithm | | Labeled Samples Per Class |
|---|
| 5 | 10 | 15 | 20 |
|---|
| PNGrow | OA | 88.11 ± 2.87 | 93.85 ± 2.23 | 93.77 ± 3.42 | 96.90 ± 0.90 |
| AA | 91.53 ± 1.3 | 95.32 ± 0.6 | 95.96 ± 1.1 | 97.47 ± 0.4 |
| 84.64 ± 3.5 | 91.95 ± 2.8 | 91.89 ± 4.3 | 95.90 ± 1.2 |
| TT-AL-MSH-MKE | OA | 79.04 ± 3.95 | 86.00 ± 3.04 | 90.20 ± 2.51 | n/d |
| AA | 85.99 ± 3.84 | 89.80 ± 2.74 | 92.16 ± 1.92 | n/d |
| 85.99 ± 3.84 | 82.05 ± 3.87 | 87.24 ± 3.20 | n/d |
| S2CoTraC | OA | 50.76 ± 1.68 | 80.75 ± 0.35 | 82.87 ± 1.42 | 93.67 ± 1.51 |
| AA | 62.37 ± 1.96 | 82.37 ± 1.29 | 90.06 ± 0.84 | 92.45 ± 0.30 |
| 42.62 ± 1.81 | 75.11 ± 1.21 | 78.56 ± 1.73 | 91.69 ± 1.88 |
| Proposed | OA | 86.69 ± 2.94 | 96.16 ± 1.05 | 98.64 ± 0.21 | 99.16 ± 0.24 |
| AA | 91.99 ± 1.04 | 97.01 ± 0.66 | 98.89 ± 0.12 | 99.30 ± 0.14 |
| 82.94 ± 3.57 | 94.95 ± 1.36 | 98.21 ± 0.27 | 98.89 ± 0.32 |
Table 7.
Classification accuracy (%) of the proposed algorithm for AVIRIS Salinas Valley with 5, 10, 15 and 20 initial labeled samples per class and iterations of co-training.
Table 7.
Classification accuracy (%) of the proposed algorithm for AVIRIS Salinas Valley with 5, 10, 15 and 20 initial labeled samples per class and iterations of co-training.
| Class | Labeled Samples Per Class |
|---|
| No. | Number of Samples | 5 | 10 | 15 | 20 |
|---|
| 1 | 2009 | 99.80 ± 0.15 | 99.68 ± 0.75 | 99.89 ± 0.26 | 99.92 ± 0.07 |
| 2 | 3726 | 98.80 ± 1.80 | 99.96 ± 0.09 | 99.76 ± 0.64 | 100.00 ± 0.00 |
| 3 | 1976 | 99.98 ± 0.04 | 99.99 ± 0.02 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 4 | 1394 | 99.89 ± 0.08 | 99.98 ± 0.04 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 5 | 2678 | 99.15 ± 0.39 | 99.21 ± 0.33 | 99.45 ± 0.19 | 99.69 ± 0.29 |
| 6 | 3959 | 99.91 ± 0.23 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 7 | 3579 | 99.62 ± 0.35 | 99.92 ± 0.13 | 99.99 ± 0.02 | 100.00 ± 0.00 |
| 8 | 11,271 | 84.79 ± 5.97 | 91.39 ± 3.77 | 94.11 ± 1.77 | 95.45 ± 0.85 |
| 9 | 6203 | 99.38 ± 0.46 | 99.75 ± 0.16 | 99.84 ± 0.12 | 99.89 ± 0.12 |
| 10 | 3278 | 98.46 ± 0.61 | 99.34 ± 0.27 | 99.62 ± 0.25 | 99.35 ± 0.26 |
| 11 | 1068 | 99.87 ± 0.16 | 99.91 ± 0.09 | 99.91 ± 0.11 | 99.81 ± 0.21 |
| 12 | 1927 | 99.98 ± 0.03 | 99.76 ± 0.41 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 13 | 916 | 99.73 ± 0.39 | 99.85 ± 0.17 | 99.91 ± 0.10 | 99.80 ± 0.22 |
| 14 | 1070 | 98.51 ± 1.54 | 99.51 ± 0.27 | 99.80 ± 0.17 | 99.84 ± 0.18 |
| 15 | 7268 | 78.20 ± 13.77 | 94.55 ± 2.20 | 96.77 ± 3.88 | 98.42 ± 0.80 |
| 16 | 1807 | 99.10 ± 0.52 | 99.74 ± 0.35 | 99.83 ± 0.29 | 99.90 ± 0.17 |
| OA | 93.50 ± 1.40 | 97.31 ± 0.60 | 98.23 ± 0.39 | 98.75 ± 0.22 |
| AA | 97.20 ± 0.62 | 98.91 ± 0.18 | 99.30 ± 0.20 | 99.50 ± 0.10 |
| 92.77 ± 1.57 | 97.01 ± 0.66 | 98.03 ± 0.43 | 98.61 ± 0.24 |
| F1-measure | 96.11 ± 0.01 | 98.53 ± 0.01 | 99.03 ± 0.01 | 99.46 ± 0.01 |
Table 8.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on AVIRIS Salinas Valley with 5, 10, 15 and 20 initial training samples per class.
Table 8.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on AVIRIS Salinas Valley with 5, 10, 15 and 20 initial training samples per class.
| Algorithm | | Labeled Samples Per Class |
|---|
| 5 | 10 | 15 | 20 |
|---|
| CNN | OA | 75.96 ± 2.48 | 76.33 ± 1.24 | 86.89 ± 0.98 | 87.67 ± 0.33 |
| AA | 80.19 ± 2.19 | 85.91 ± 1.75 | 92.82 ± 0.87 | 94.4 ± 0.48 |
| 73.26 ± 2.51 | 73.79 ± 1.51 | 85.46 ± 0.93 | 86.38 ± 0.31 |
| Co-DC-CNN | OA | 90.18 ± 1.59 | 94.45 ± 1.12 | 95.16 ± 0.34 | 95.72 ± 0.29 |
| AA | 93.63 ± 1.22 | 95.60 ± 0.68 | 96.54 ± 0.31 | 96.68 ± 0.15 |
| 89.87 ± 1.21 | 94.64 ± 1.03 | 94.99 ± 0.54 | 95.70 ± 0.55 |
| Proposed | OA | 93.50 ± 1.40 | 97.31 ± 0.60 | 98.23 ± 0.39 | 98.75 ± 0.22 |
| AA | 97.20 ± 0.62 | 98.91 ± 0.18 | 99.30 ± 0.20 | 99.50 ± 0.10 |
| 92.77 ± 1.57 | 97.01 ± 0.66 | 98.03 ± 0.43 | 98.61 ± 0.24 |
Table 9.
Classification accuracy (%) of state-of-the-art semi-supervised classifiers algorithms on AVIRIS Salinas Valley with 5, 10, 15 and 20 initial training samples per class.
Table 9.
Classification accuracy (%) of state-of-the-art semi-supervised classifiers algorithms on AVIRIS Salinas Valley with 5, 10, 15 and 20 initial training samples per class.
| Algorithm | | Labeled Samples Per Class |
|---|
| 5 | 10 | 15 | 20 |
|---|
| PNGrow | OA | 95.35 ± 1.3 | 97.36 ± 0.5 | 98.30 ± 0.4 | 98.61 ± 0.2 |
| AA | 96.48 ± 1.0 | 98.13 ± 0.4 | 98.60 ± 0.3 | 98.75 ± 0.2 |
| 94.83 ± 1.5 | 97.06 ± 0.5 | 98.11 ± 0.5 | 98.45 ± 0.2 |
| TT-AL-MSH-MKE | OA | 89.32 ± 2.02 | 90.72 ± 1.38 | 92.34 ± 1.00 | n/d |
| AA | 93.88 ± 1.11 | 94.79 ± 0.77 | 95.67 ± 0.49 | n/d |
| 88.14 ± 3.84 | 89.68 ± 1.53 | 91.48 ± 1.11 | n/d |
| S2CoTraC | OA | 77.46 ± 1.06 | 82.22 ± 0.85 | 95.82 ± 1.39 | 94.62 ± 1.17 |
| AA | 89.14 ± 2.16 | 92.88 ± 2.04 | 98.59 ± 0.34 | 98.00 ± 0.66 |
| 75.61 ± 1.21 | 80.51 ± 0.91 | 95.36 ± 1.54 | 94.02 ± 1.31 |
| Proposed | OA | 93.50 ± 1.40 | 97.31 ± 0.60 | 98.23 ± 0.39 | 98.75 ± 0.22 |
| AA | 97.20 ± 0.62 | 98.91 ± 0.18 | 99.30 ± 0.20 | 99.50 ± 0.10 |
| 92.77 ± 1.57 | 97.01 ± 0.66 | 98.03 ± 0.43 | 98.61 ± 0.24 |
Table 10.
Classification accuracy (%) of the proposed algorithm for Hyperion data with 5, 10 and 15 initial training samples per class and iterations of co-training.
Table 10.
Classification accuracy (%) of the proposed algorithm for Hyperion data with 5, 10 and 15 initial training samples per class and iterations of co-training.
| Class | Labeled Samples Per Class |
|---|
| No. | Number of Samples | 5 | 10 | 15 |
|---|
| 1 | 24 | 86.84 ± 11.89 | 89.80 ± 9.09 | 91.11 ± 14.49 |
| 2 | 61 | 68.45 ± 14.49 | 84.87 ± 9.72 | 89.13 ± 2.66 |
| 3 | 54 | 62.92 ± 28.32 | 77.92 ± 2.16 | 86.67 ± 4.21 |
| 4 | 51 | 79.06 ± 35.51 | 90.86 ± 5.36 | 98.33 ± 1.52 |
| 5 | 32 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 6 | 148 | 63.29 ± 13.17 | 76.71 ± 2.76 | 85.71 ± 1.68 |
| 7 | 49 | 86.36 ± 7.04 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 8 | 39 | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 9 | 82 | 83.34 ± 11.18 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 10 | 67 | 90.59 ± 17.74 | 99.25 ± 1.38 | 100.00 ± 0.00 |
| 11 | 20 | 72.23 ± 13.61 | 91.43 ± 12.15 | 100.00 ± 0.00 |
| 12 | 53 | 68.75 ± 12.29 | 100.00 ± 0.00 | 100.00 ± 0.00 |
| 13 | 79 | 64.64 ± 12.66 | 82.19 ± 8.99 | 88.44 ± 1.408 |
| OA | 77.04 ± 4.48 | 89.17 ± 1.68 | 93.26 ± 0.83 |
| AA | 80.71 ± 4.01 | 91.80 ± 1.48 | 95.34 ± 0.89 |
| 74.66 ± 4.90 | 87.92 ± 1.85 | 92.40 ± 0.93 |
| F1-measure | 78.30 ± 0.05 | 89.77 ± 0.03 | 94.57 ± 0.00 |
Table 11.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on Hyperion data with 5, 10 and 15 initial training samples per class.
Table 11.
Classification accuracy (%) of state-of-the-art HSI classifiers algorithms on Hyperion data with 5, 10 and 15 initial training samples per class.
| Algorithm | | Labeled Samples Per Class |
|---|
| 5 | 10 | 15 |
|---|
| CNN | OA | 39.77 ± 4.84 | 74.56 ± 3.14 | 72.16 ± 2.26 |
| AA | 37.70 ± 4.61 | 77.78 ± 2.98 | 78.72 ± 1.99 |
| 33.09 ± 5.22 | 71.71 ± 3.27 | 68.89 ± 2.17 |
| Co-DC-CNN | OA | 72.58 ± 4.27 | 82.47 ± 2.14 | 90.84 ± 1.30 |
| AA | 75.63 ± 4.09 | 84.70 ± 1.95 | 92.63 ± 1.28 |
| 70.44 ± 4.95 | 81.99 ± 1.89 | 91.87 ± 1.34 |
| S2CoTraC | OA | 61.35 ± 1.06 | 79.54 ± 0.85 | 84.49 ± 1.39 |
| AA | 47.85 ± 2.16 | 70.51 ± 2.04 | 79.59 ± 0.34 |
| 56.50 ± 1.21 | 77.26 ± 0.91 | 82.71 ± 1.54 |
| Proposed | OA | 77.04 ± 4.48 | 89.17 ± 1.68 | 93.26 ± 0.83 |
| AA | 80.71 ± 4.01 | 91.80 ± 1.48 | 95.34 ± 0.89 |
| 74.66 ± 4.90 | 87.92 ± 1.85 | 92.40 ± 0.93 |
Table 12.
Sample selection mechanism analysis on ROSIS Pavia University data.
Table 12.
Sample selection mechanism analysis on ROSIS Pavia University data.
| | Iteration 1 | Iteration 2 | Iteration 3 | Iteration 4 |
|---|
| training samples (spectral) | 45 ± 0.00 | 108 ± 3 | 537 ± 8 | 1136 ± 8 |
| training samples (spatial) | 45 ± 0.00 | 215 ± 1 | 462 ± 12 | 1439 ± 43 |
| selected samples (spectral) | 170 ± 1 (99.19%) | 248 ± 13 (99.45%) | 977 ± 55 (99.88%) | 1167 ± 47 (99.98%) |
| selected samples (spatial) | 63 ± 3 (100.00%) | 429 ± 11 (99.83%) | 598 ± 16 (99.96%) | 1459 ± 76 (99.91%) |
| OA (%) | 54.2 ± 2.12 | 67.81 ± 4.85 | 86.69 ± 2.94 | 97.58 ± 0.13 |
Table 13.
Sample selection mechanism analysis on the AVIRIS Salinas Valley.
Table 13.
Sample selection mechanism analysis on the AVIRIS Salinas Valley.
| | Iteration 1 | Iteration 2 | Iteration 3 | Iteration 4 |
|---|
| training samples (spectral) | 80 ± 0.00 | 462 ± 66 | 1510 ± 19 | 3659 ± 149 |
| training samples (spatial) | 80 ± 0.00 | 557 ± 18 | 1473 ± 13 | 3936 ± 105 |
| selected samples (spectral) | 477 ± 18 (99.26%) | 916 ± 31 (99.52%) | 2463 ± 115 (99.48%) | 3552 ± 102 (99.84%) |
| selected samples (spatial) | 382 ± 66 (100.00%) | 1048 ± 47 (99.79%) | 2149 ± 130 (99.93%) | 3816 ± 80 (99.87%) |
| OA (%) | 67.02 ± 2.29 | 80.44 ± 1.87 | 93.5 ± 1.42 | 98.32 ± 0.52 |



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}