Automatic Discovery and Geotagging of Objects from Street View Imagery


Abstract
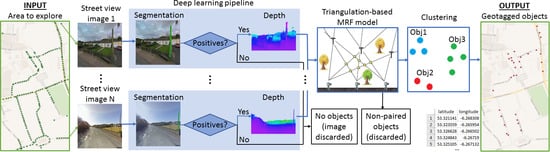
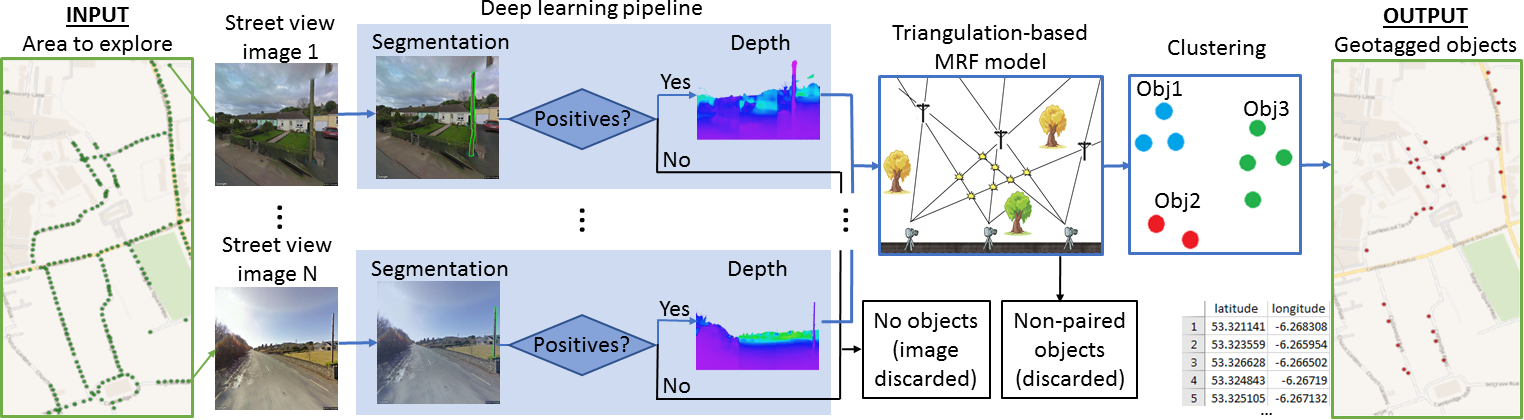
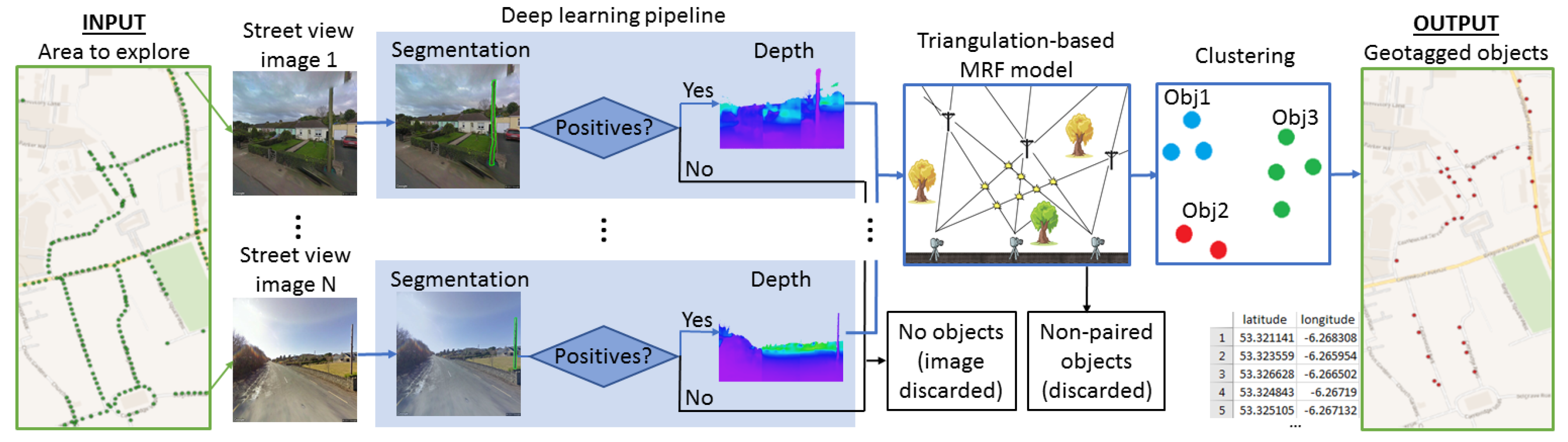
:
1. Introduction
2. Related Work
3. Object Discovery and Geotagging
3.1. Object Segmentation
3.2. Monocular Depth Estimation
3.3. Object Geotagging
3.3.1. Location from Single View
3.3.2. Location from Multiple Views
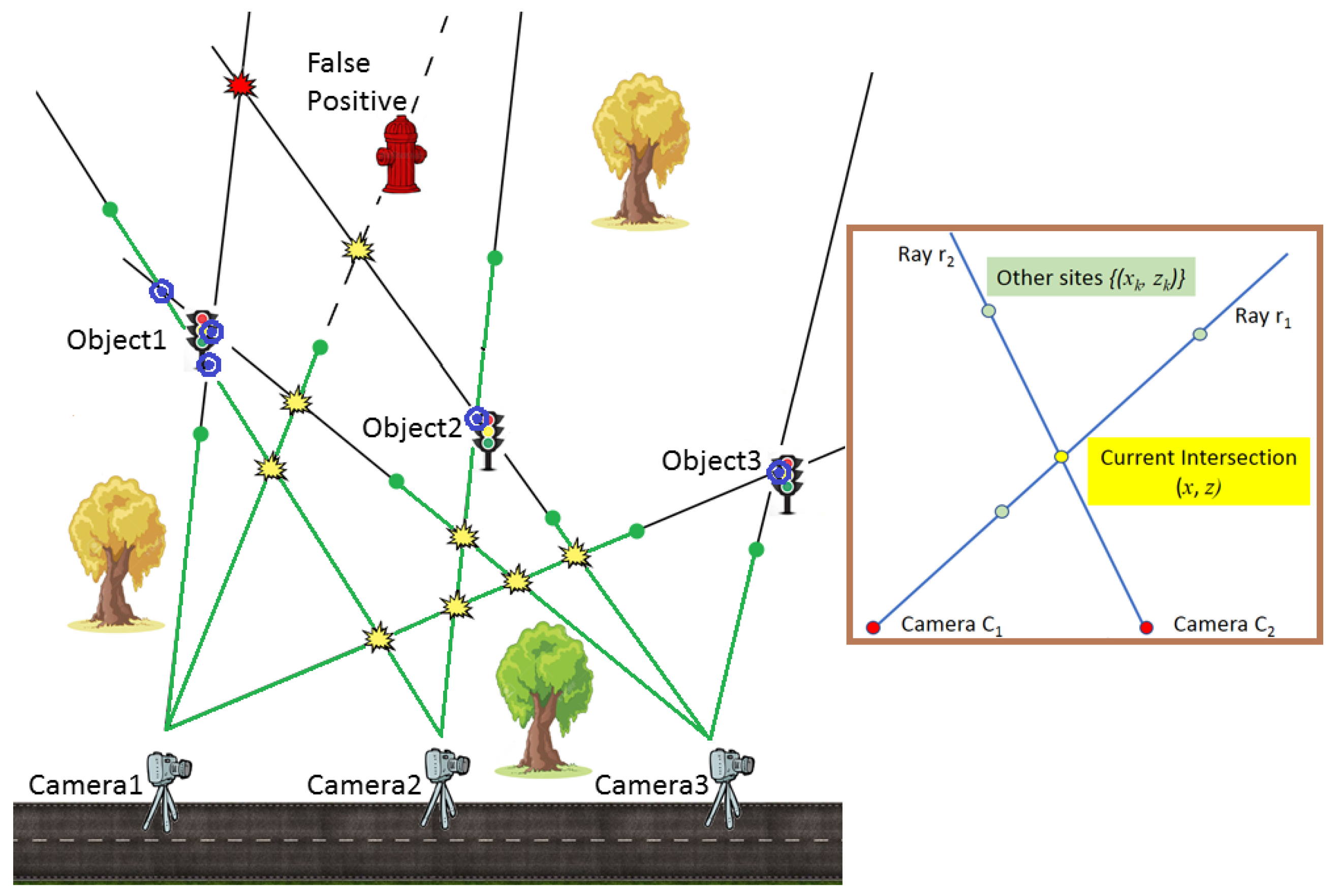
3.3.3. MRF Formulation with Irregular Grid
- To each site x we associate two Euclidean distances and from cameras: , where are the locations of two cameras from which intersection x is observed along the rays and , respectively. Any intersection x is considered in , only if . In Figure 2, the red intersection in the upper part of the scene is rejected as too distant from Camera3.
- The neighbourhood of node x is defined as the set of all other locations in on the rays and that generate it. We define the MRF such that the state of each intersection depends only on its neighbours on the rays. Note that the number of neighbours (i.e., neighbourhood size) for each node x in in our MRF varies depending on x.
- Any ray can have at most one positive intersection with rays from any particular camera, but several positive intersections with rays generated from different cameras are allowed, e.g., multiple intersections for Object1 in Figure 2.
- A unary energy term enforces consistency with the depth estimation. Specifically, the deep learning pipeline for depth estimation provides estimates and of distances between camera positions and the detected object at location x. We formulate the term as a penalty for mismatch between triangulated distances and depth estimates:
- A pairwise energy term is introduced to penalize (i) multiple objects of interest occluding each other and (ii) excessive spread, in case an object is characterized as several intersections. In other words, we tolerate several positive intersections on the same ray only when they are in close proximity. This may occur in a multi-view scenario due to segmentation inaccuracies and noise in camera geotags. For example, in Figure 2, Object1 is detected as a triangle of positive intersections (blue dots)—two on each of the three rays.Two distant positive intersections on the same ray correspond to a scenario when an object closer to the camera occludes the second, more distant object. Since we consider compact slim objects, we can assume that this type of occlusion is unlikely.This term depends on the current state z and those of its neighbours . It penalizes proportionally to the distance to any other positive intersections on rays and :
- A final energy term penalizes rays that have no positive intersections: false positives or objects discovered from a single camera position (see Figure 2). This can be written aswhere k indexes all other intersections along the two rays defining the current intersection.It is also possible to register rays with no positive intersections as detected objects by applying the depth estimates directly to calculate the geotags. The corresponding positions are of lower spatial accuracy but allow an increase in the recall of object detection. In this study, we discard such rays to increase object detection precision by improving robustness to segmentation false positives.
4. Experimental Results
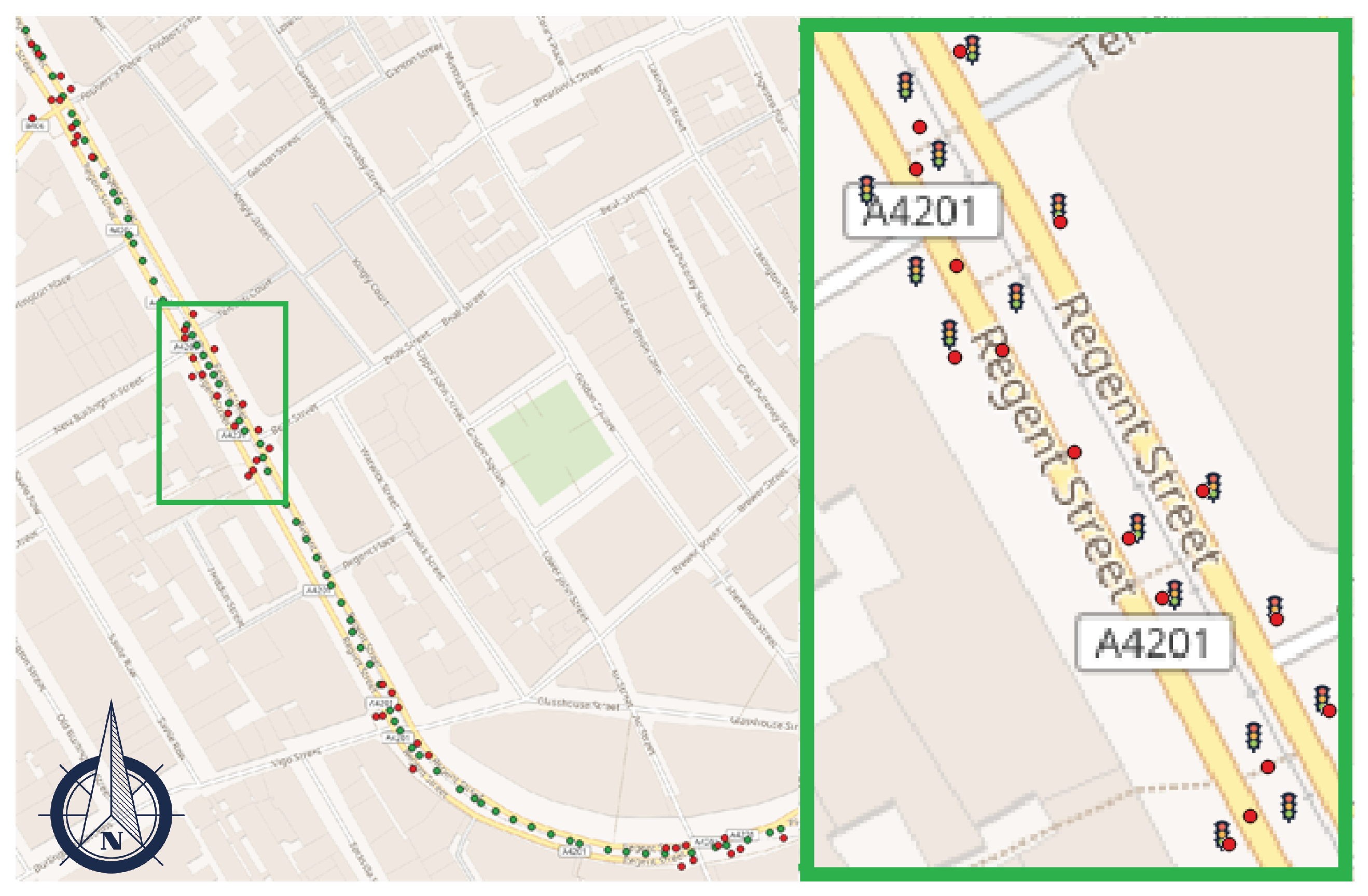
4.1. Geolocation of Traffic Lights
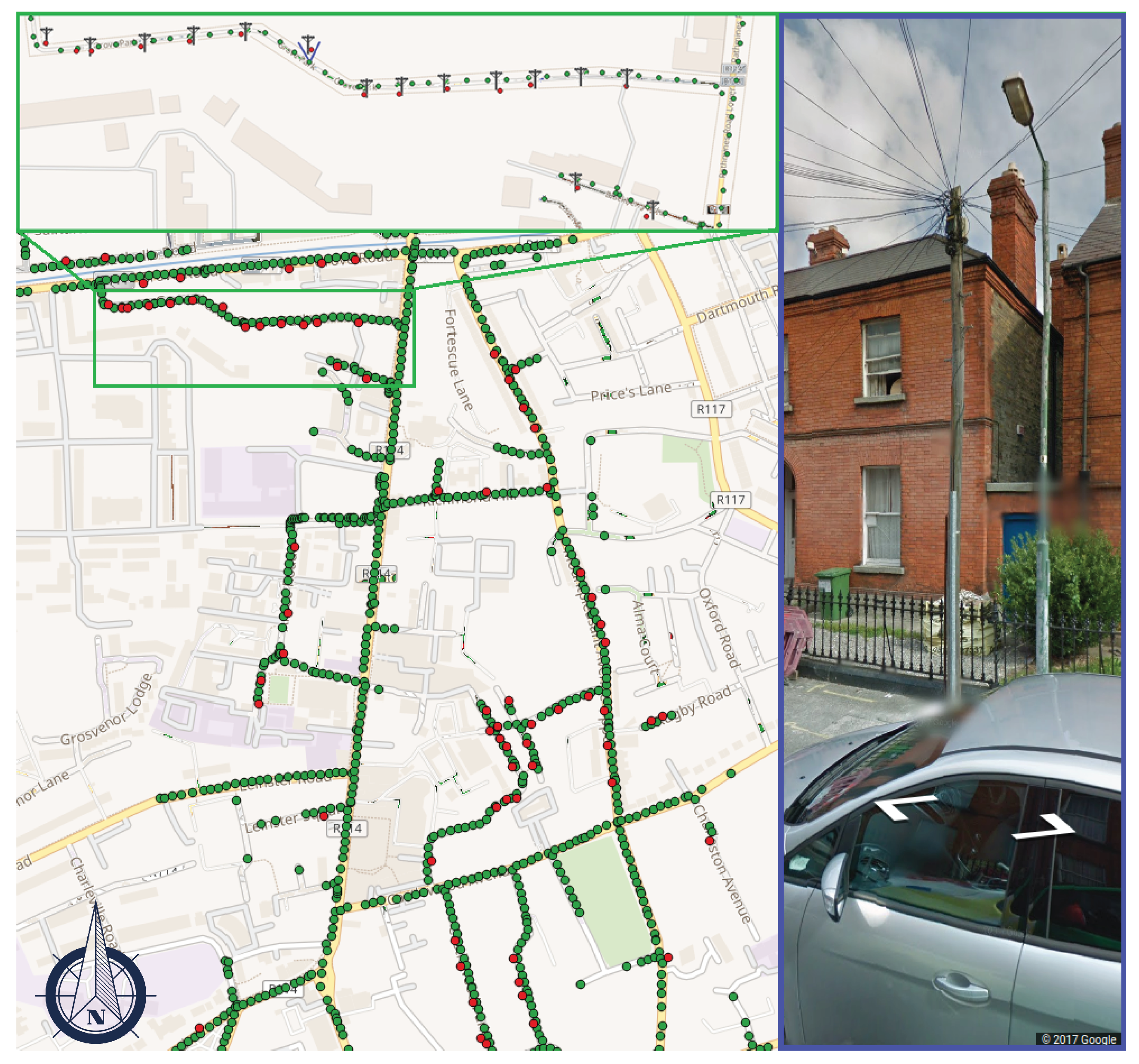
4.2. Geolocation of Telegraph Poles
- Image filtering. We start with a small dataset of 1 K manually chosen GSV images containing telegraph poles. We define a simple filtering procedure to automatically identify the location of poles in the images by a combination of elementary image processing techniques: Sobel vertical edge extraction, Radon maxima extraction, and colour thresholding. We also remove ‘sky’ pixels from the background as identified by the FCNN [35]. This allows us to extract rough bounding boxes around strong vertical features like poles.
- Cascade classifier. We then train a cascade classifier [32] on 1 K bounding boxes produced at the previous step. Experimentally, the recall achieved on poles is about with a precision of . We employ this classifier to put together a larger telegraph pole dataset that can be used to train segmentation FCNN. To this end, we use a training database of telegraph poles’ positions made available to us for this study. Specifically, we extract GSV images closest in locations to the poles in the database whenever GSV imagery is available within a 25 m radius. Due to the inherent position inaccuracy in both pole and GSV positions and frequent occlusions, we cannot expect to observe poles at the view angle calculated purely based on the available coordinates. Instead, we deploy the cascade classifier trained above to identify poles inside panoramas. Since many of the images depict geometry-rich scenes and since some telegraph poles may be occluded by objects or vegetation, in about of cases, we end up with non-telegraph poles as well as occasional strong vertical features, such as tree trunks, roof drain pipes, and antennas. Thus, we prepare 130 K panoramic images with bounding boxes.We next identify the outlines of poles inside the bounding boxes by relying on the image processing procedures proposed in the first step. This allows us to provide coarse boundaries of telegraph poles for the training of an FCNN. The resulting training dataset consists of an estimated of telegraph poles, about of other types of poles, and about of non-pole objects.
- FCNN training: all poles. We then train our FCNN to detect all tall poles—utilities and lampposts—by combining public datasets Mapillary Vistas [45] and Cityscapes [46] with the dataset prepared in the previous step. The inclusion of public datasets allows us to dramatically increase robustness with respect to background objects, which are largely underrepresented in the dataset prepared above with outlines of poles.The public datasets provide around 20 K images, so the merged dataset contains 150 K images: 130 K training and 20 K validation. This first step of training is run for 100 epochs at a learning rate of to achieve satisfactory discriminative power between poles and non-poles.
- FCNN fine-tuning: telegraph poles. The final second step of FCNN training is performed by fine-tuning the network on our custom pixel-level annotated set of 500 telegraph pole images. To further boost the discriminative power of the FCNN, we add 15 K GSV scenes collected in areas with no telegraph poles but in the presence of lampposts and electricity poles. The fine-tuning phase is run for another 200 epochs at a learning rate of .
4.2.1. Study A: Small-Scale, Urban
4.2.2. Study B: Large-Scale, Rural
5. Discussion
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- BBC News. Google’s Street View Cameras Get Quality Boost. 6 September 2017. Available online: http://www.bbc.com/news/technology-41082920 (accessed on 20 April 2018).
- Mapillary: Celebrating 200 Million Images. 5 October 2017. Available online: https://blog.mapillary.com/update/2017/10/05/200-million-images.html (accessed on 20 April 2018).
- Mattyus, G.; Wang, S.; Fidler, S.; Urtasun, R. HD maps: Fine-grained road segmentation by parsing ground and aerial images. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3611–3619. [Google Scholar]
- Wegner, J.D.; Branson, S.; Hall, D.; Schindler, K.; Perona, P. Cataloging public objects using aerial and street-level images-urban trees. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 6014–6023. [Google Scholar]
- Workman, S.; Zhai, M.; Crandall, D.J.; Jacobs, N. A unified model for near and remote sensing. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 7. [Google Scholar]
- Hara, K.; Azenkot, S.; Campbell, M.; Bennett, C.L.; Le, V.; Pannella, S.; Moore, R.; Minckler, K.; Ng, R.H.; Froehlich, J.E. Improving public transit accessibility for blind riders by crowdsourcing bus stop landmark locations with Google Street View: An extended analysis. ACM Trans. Access. Comput. 2015, 6, 5. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, X.; Zhang, Q.; Wang, T.; Shen, D. Crowdsourcing in ITS: The state of the work and the networking. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1596–1605. [Google Scholar] [CrossRef]
- Wired. Google’s New Street View Cameras will Help Algorithms Index the Real World. 9 May 2017. Available online: https://www.wired.com/story/googles-new-street-view-cameras-will-help-algorithms-index-the-real-world/ (accessed on 20 April 2018).
- Seamless Google Street View Panoramas. 9 November 2017. Available online: https://research.googleblog.com/2017/11/seamless-google-street-view-panoramas.html (accessed on 20 April 2018).
- Hebbalaguppe, R.; Garg, G.; Hassan, E.; Ghosh, H.; Verma, A. Telecom Inventory management via object recognition and localisation on Google Street View Images. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 725–733. [Google Scholar]
- Federal Aviation Administration. Global Positioning System (GPS) Standard Positioning Service (SPS) Performance Analysis Report #100; Technical Report; Federal Aviation Administration: Washington, DC, USA, January 2018.
- Timofte, R.; Van Gool, L. Multi-view manhole detection, recognition, and 3D localisation. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 188–195. [Google Scholar]
- Lefèvre, S.; Tuia, D.; Wegner, J.D.; Produit, T.; Nassaar, A.S. Toward Seamless Multiview Scene Analysis From Satellite to Street Level. Proc. IEEE 2017, 105, 1884–1899. [Google Scholar] [CrossRef]
- Hays, J.; Efros, A.A. IM2GPS: Estimating geographic information from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, Alaska, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Li, X.; Zhang, C.; Li, W.; Ricard, R.; Meng, Q.; Zhang, W. Assessing street-level urban greenery using Google Street View and a modified green view index. Urban For. Urban Green. 2015, 14, 675–685. [Google Scholar] [CrossRef]
- Bulbul, A.; Dahyot, R. Social media based 3D visual popularity. Comput. Graph. 2017, 63, 28–36. [Google Scholar] [CrossRef]
- Du, R.; Varshney, A. Social Street View: Blending Immersive Street Views with Geo-tagged Social Media. In Proceedings of the International Conference on Web3D Technology, Anaheim, CA, USA, 22–24 July 2016; pp. 77–85. [Google Scholar]
- Zhang, W.; Li, W.; Zhang, C.; Hanink, D.M.; Li, X.; Wang, W. Parcel-based urban land use classification in megacity using airborne LiDAR, high resolution orthoimagery, and Google Street View. Comput. Environ. Urban Syst. 2017, 64, 215–228. [Google Scholar] [CrossRef]
- Babahajiani, P.; Fan, L.; Kämäräinen, J.K.; Gabbouj, M. Urban 3D segmentation and modelling from street view images and LiDAR point clouds. Mach. Vis. Appl. 2017, 28, 679–694. [Google Scholar] [CrossRef]
- Qin, R.; Gruen, A. 3D change detection at street level using mobile laser scanning point clouds and terrestrial images. ISPRS J. Photogramm. Remote Sens. 2014, 90, 23–35. [Google Scholar] [CrossRef]
- Piasco, N.; Sidibé, D.; Demonceaux, C.; Gouet-Brunet, V. A survey on Visual-Based Localization: On the benefit of heterogeneous data. Pattern Recognit. 2018, 74, 90–109. [Google Scholar] [CrossRef]
- Ardeshir, S.; Zamir, A.R.; Torroella, A.; Shah, M. GIS-assisted object detection and geospatial localization. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 602–617. [Google Scholar]
- Wang, S.; Fidler, S.; Urtasun, R. Holistic 3D scene understanding from a single geo-tagged image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3964–3972. [Google Scholar]
- Zhen, Z.; Quackenbush, L.J.; Zhang, L. Trends in automatic individual tree crown detection and delineation—Evolution of lidar data. Remote Sens. 2016, 8, 333. [Google Scholar] [CrossRef]
- Ordóñez, C.; Cabo, C.; Sanz-Ablanedo, E. Automatic Detection and Classification of Pole-Like Objects for Urban Cartography Using Mobile Laser Scanning Data. Sensors 2017, 17, 1465. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Yu, J. Semiautomated extraction of street light poles from mobile LiDAR point-clouds. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1374–1386. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Automatic car counting method for unmanned aerial vehicle images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1635–1647. [Google Scholar] [CrossRef]
- Feng, Q.; Liu, J.; Gong, J. UAV remote sensing for urban vegetation mapping using random forest and texture analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef]
- Soheilian, B.; Paparoditis, N.; Vallet, B. Detection and 3D reconstruction of traffic signs from multiple view color images. ISPRS J. Photogramm. Remote Sens. 2013, 77, 1–20. [Google Scholar] [CrossRef]
- Trehard, G.; Pollard, E.; Bradai, B.; Nashashibi, F. Tracking both pose and status of a traffic light via an interacting multiple model filter. In Proceedings of the International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–7. [Google Scholar]
- Jensen, M.B.; Philipsen, M.P.; Møgelmose, A.; Moeslund, T.B.; Trivedi, M.M. Vision for looking at traffic lights: Issues, survey, and perspectives. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1800–1815. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. I-511–I-518. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE T-PAMI 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE T-PAMI 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1529–1537. [Google Scholar]
- Seitz, S.M.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A comparison and evaluation of multi-view stereo reconstruction algorithms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; Volume 1, pp. 519–528. [Google Scholar]
- Tron, R.; Zhou, X.; Daniilidis, K. A survey on rotation optimization in structure from motion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 77–85. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the International Conference on 3D Vision, Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Li, B.; Shen, C.; Dai, Y.; van den Hengel, A.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- Kato, Z.; Zerubia, J. Markov random fields in image segmentation. Found. Trends Signal Process. 2012, 5, 1–155. [Google Scholar] [CrossRef]
- Mapillary Vistas Dataset. Available online: https://www.mapillary.com/dataset/vistas (accessed on 20 April 2018).
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Extent | #Actual | #Detected | True Positives | False Positives | False Negatives | Recall | Precision | ||
|---|---|---|---|---|---|---|---|---|---|
 | 0.8 km | 50 | 51 | 47 | 4 | 3 | 0.940 | 0.922 | |
 | Study A | 8 km | 77 | 75 | 72 | 3 | 5 | 0.935 | 0.960 |
 | Study B | 120 km | 2696 | 2565 | 2497 | 68 | 199 | 0.926 | 0.973 |
| Method | Mean | Median | Variance | 95% e.c.i. |
|---|---|---|---|---|
| MRF-triangulation | 0.98 | 1.04 | 0.65 | 2.07 |
| depth FCNN | 3.2 | 2.9 | 2.1 | 6.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krylov, V.A.; Kenny, E.; Dahyot, R. Automatic Discovery and Geotagging of Objects from Street View Imagery. Remote Sens. 2018, 10, 661. https://doi.org/10.3390/rs10050661
Krylov VA, Kenny E, Dahyot R. Automatic Discovery and Geotagging of Objects from Street View Imagery. Remote Sensing. 2018; 10(5):661. https://doi.org/10.3390/rs10050661
Chicago/Turabian StyleKrylov, Vladimir A., Eamonn Kenny, and Rozenn Dahyot. 2018. "Automatic Discovery and Geotagging of Objects from Street View Imagery" Remote Sensing 10, no. 5: 661. https://doi.org/10.3390/rs10050661
APA StyleKrylov, V. A., Kenny, E., & Dahyot, R. (2018). Automatic Discovery and Geotagging of Objects from Street View Imagery. Remote Sensing, 10(5), 661. https://doi.org/10.3390/rs10050661