1. Introduction
In the next decades, the climate change and the estimated increase in the global population will have significant impact on the food sector [
1]. In this context, increased agricultural productivity under environmentally friendly practices is an increasingly interesting topic and a top priority for the European Union, manifesting predominantly in the form of the Common Agricultural Policy (CAP) [
2]. The administration and control of subsidy payments, associated with the relevant agrarian policies of the CAP, Cross Compliance (CC) and Greening, require systematic and timely knowledge of the agricultural land cover and land use [
3]. Paying agencies are the Member State (MS) authorities responsible for the fair allocation of the CAP funds, and consequently for the realization of inspections to decide on the farmers’ compliance to their CAP obligations. The farmers submit their subsidy applications to their paying agency, declaring the location and the cultivated crop type for all owned parcels [
4]. In turn, paying agencies are required to inspect at least 5% of declarations, via means of field visits and photointerpretation of Very High Resolution (VHR) and High Resolution (HR) satellite imagery (i.e., SPOT, Worldview, IKONOS) [
4,
5]. However, these methods are time-consuming, complex, and reliant on the skills of the inspector.
Contrariwise, automated remote sensing methods, suitably designed with respect to computational efficiency, large-scale coverage, and spatial resolution, can offer a monitoring alternative with reliable solutions [
2]. In the context of the expected CAP 2020+ reform, there is a clear intention for simplification and a reduction of the administrative burden for both farmers and paying agencies. This study showcases how timely and accurate crop identification can assist the paying agency controls, suggesting an effective and efficient tool towards the required shift from sample inspections to large scale monitoring.
The freely available data and global coverage of Landsat satellites have established them, over the years, as one of the primary data sources for operational agriculture monitoring applications. Landsat data have been exploited in crop type mapping from as early as the 1980s, with Odenweller and Johnson (1984) using Vegetation Index (VI) time-series under threshold-based approaches, while in more recent studies their usage has evolved into non-parametric supervised classification schemes [
2,
6]. However, low (e.g., MODIS 250 m) and moderate (e.g., Landsat 30 m) spatial resolution data, with pixel sizes comparable to the parcel area, provide suboptimal thematic accuracy [
7]. VHR (e.g., QuickBird and IKONOS) and HR (e.g., SPOT 5) satellite imagery has also been extensively used in crop classification studies [
8,
9]. VHR offers an excellent target to pixel ratio and allows for the appropriate exploitation of image processing features, such as texture, context, and tone [
10]. Single-source missions that provide VHR imagery are often associated with high cost and long revisit times. However, the recently introduced small-satellite constellations, such as Planet’s flock of Doves, can offer global coverage at high revisit frequency and unprecedentedly low costs. Nonetheless, the inexpensive, off-the-shelf sensor components used imply suboptimal noise resilience, radiometric performance, and cross-sensor uniformity [
11].
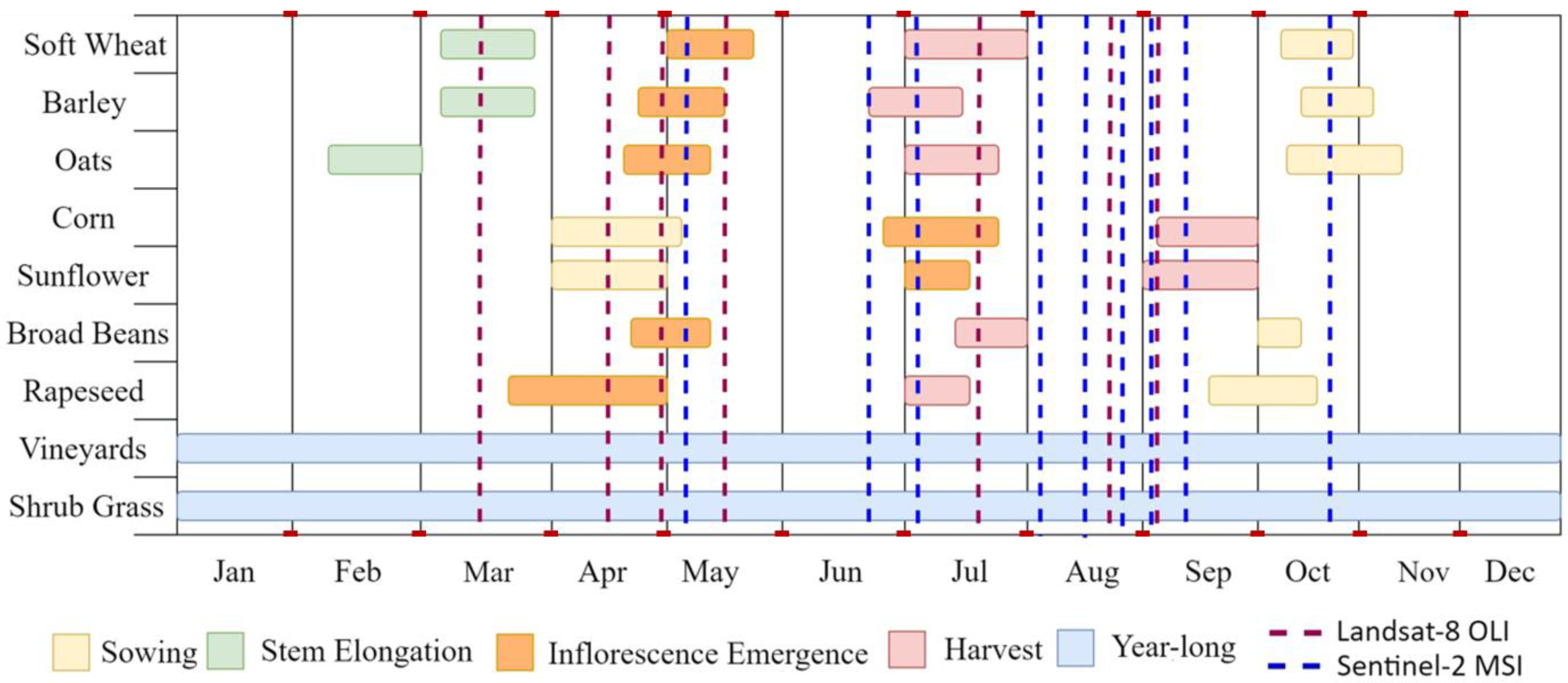
Time-series of multispectral imagery that covers the agricultural cycle, from seeding to harvest, is necessitated for accurate crop identification [
12]. Mature crops are more distinct and carry varying textures, water absorbency, and colors, having greater chances of being detected with remote sensing [
13]. With respect to image processing, literature clearly points to object-based image analysis (OBIA) methods, assuming VHR and HR imagery is in use. Alternative pixel-based analyses often lead to misclassifications due to the canopy’s spectral variability, bare soil background reflectance, and mixed pixels. Grouping pixels into spectrally consistent objects can alleviate such issues [
10].
Non-parametric supervised classifiers such as Support Vector Machines (SVM), decision tree ensembles and artificial neural networks have been successfully employed in crop identification schemes [
14,
15]. In the last ten years, SVM and Random Forest (RF) classifiers have become increasingly popular in land cover mapping publications, doubling their appearances since 2012 [
16]. Their success is attributed to effectively describing the nonlinear relationships between crops’ spectral characteristics and their physical condition [
17]. Both classifiers are resilient to noise and over-fitting and are therefore able to effectively cope with unbalanced data [
16]. SVMs can ably handle small training datasets [
18], while ensemble classifiers like RF are characterized by high computational efficiency [
19]. These constitute ideal classification features for accurate and efficient crop type mapping and specifically for the purposes of the CAP monitoring, where data are big and ground truth information is scarce.
The Sentinel-2 mission introduces a paradigm shift in the quality and quantity of open access Earth Observation (EO) data, opening a new era for operational terrestrial monitoring systems, a fortiori in the agriculture sector. The mission offers unprecedented 10 m and 20 m spatial resolution data at a 5-day revisit time with twin satellites. This, however, introduces the notion of big data and the challenge of their efficient handling. EO data are freely and systematically received over very large areas, which range beyond the limits of one region or a country, as they are nowadays required by the on-going and planned large scale initiatives and funded projects (e.g., GEOGLAM, GEO-CRADLE). In this regard, significant attention has been raised to Sentinels’ potential for agriculture monitoring and particularly in the context of the CAP control scheme [
20,
21,
22,
23]. One indicative example would be the European Space Agency’s (ESA) Sentinel-2 Agriculture project, aiming at the simplification of crop management. The system achieves an overall mapping accuracy of 85% for five major crop types, making up 75% of the regional agricultural zone [
24]. Lebourgeois et al. (2017) have been among the first to use a scheme of mixed OBIA and RF approach for smallholding crop type classification, achieving 64.4% accuracy for 14 crop classes. In both publications, the authors tested their Sentinel specific methods, by simulating Sentinel-2 data using SPOT 5 and SPOT 4 (Take 5 experiment) as proxies. Lebourgeois et al. (2017) additionally incorporated Landsat-8 and VHR imagery, with the latter proving inconsequential in the classification process [
7].
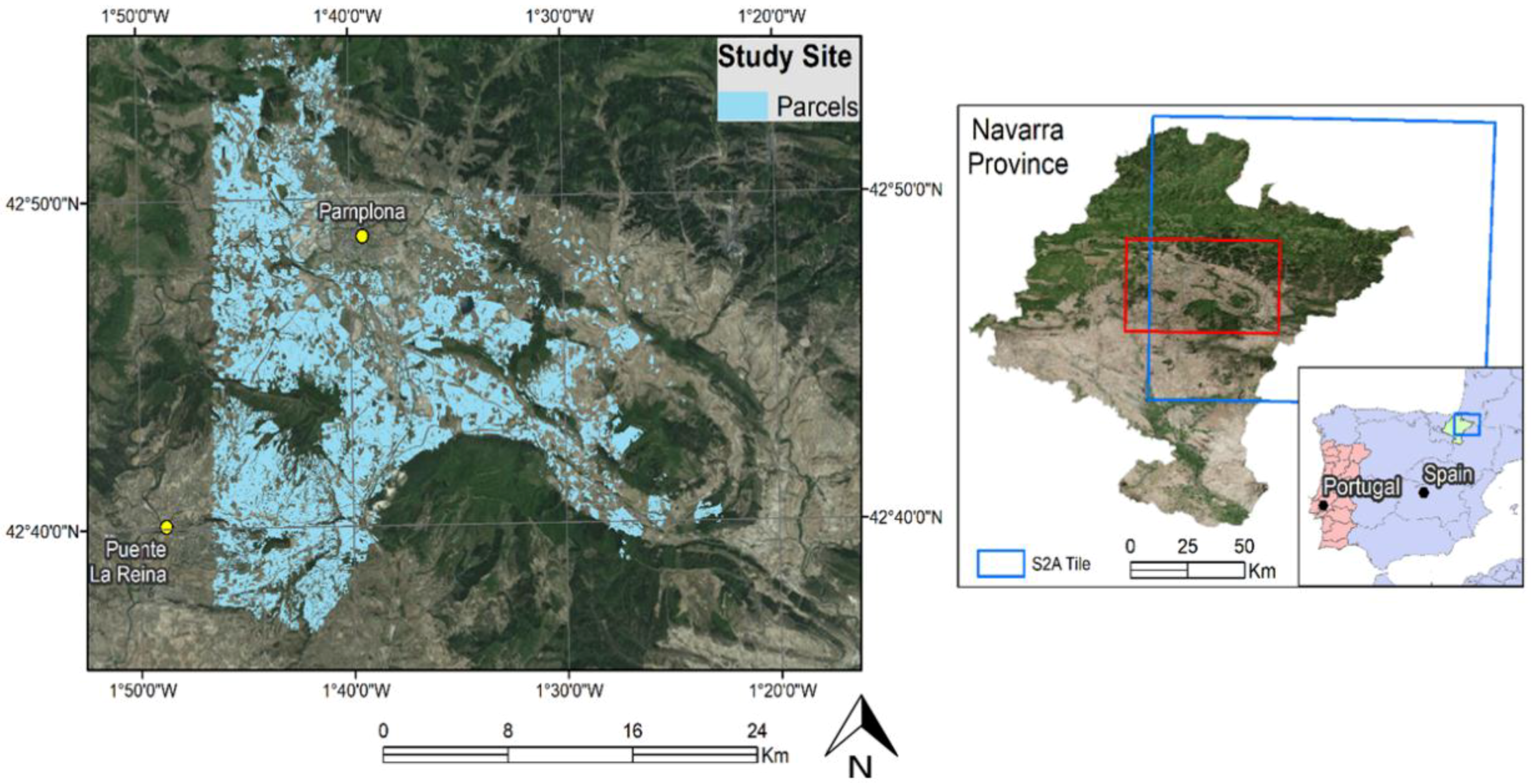
This study attempts to capitalize on the most promising research paradigms discussed above, with a clear operationalization potential. In this context, we seek to suggest, implement, and validate a crop mapping scheme of methods, enabling the identification of nine different crop types and thus provide information on farmer’s compliance, with respect to their CAP requirements. A parcel-based Sentinel-2 MSI time-series approach is used for the construction of the feature space. The utilized imagery captures the growing stages of the various crop types in order to successfully discriminate between them. The local Land-Parcel Identification System (LPIS), which provides the geospatial input for crop delineation and local farmers’ declarations, as part of their CAP subsidy applications, are employed for the object partitioning of the images and the supervised classifiers’ training, respectively.
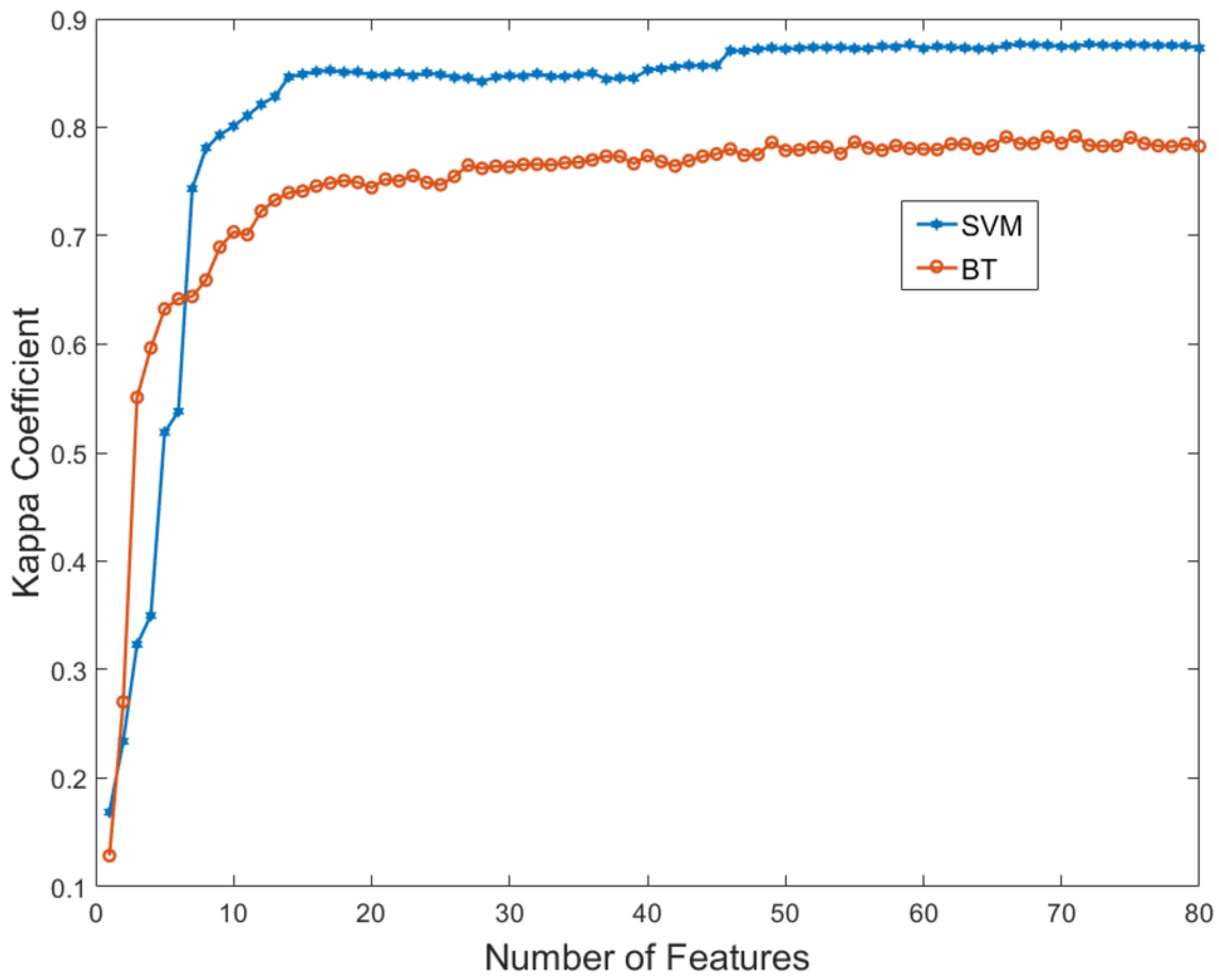
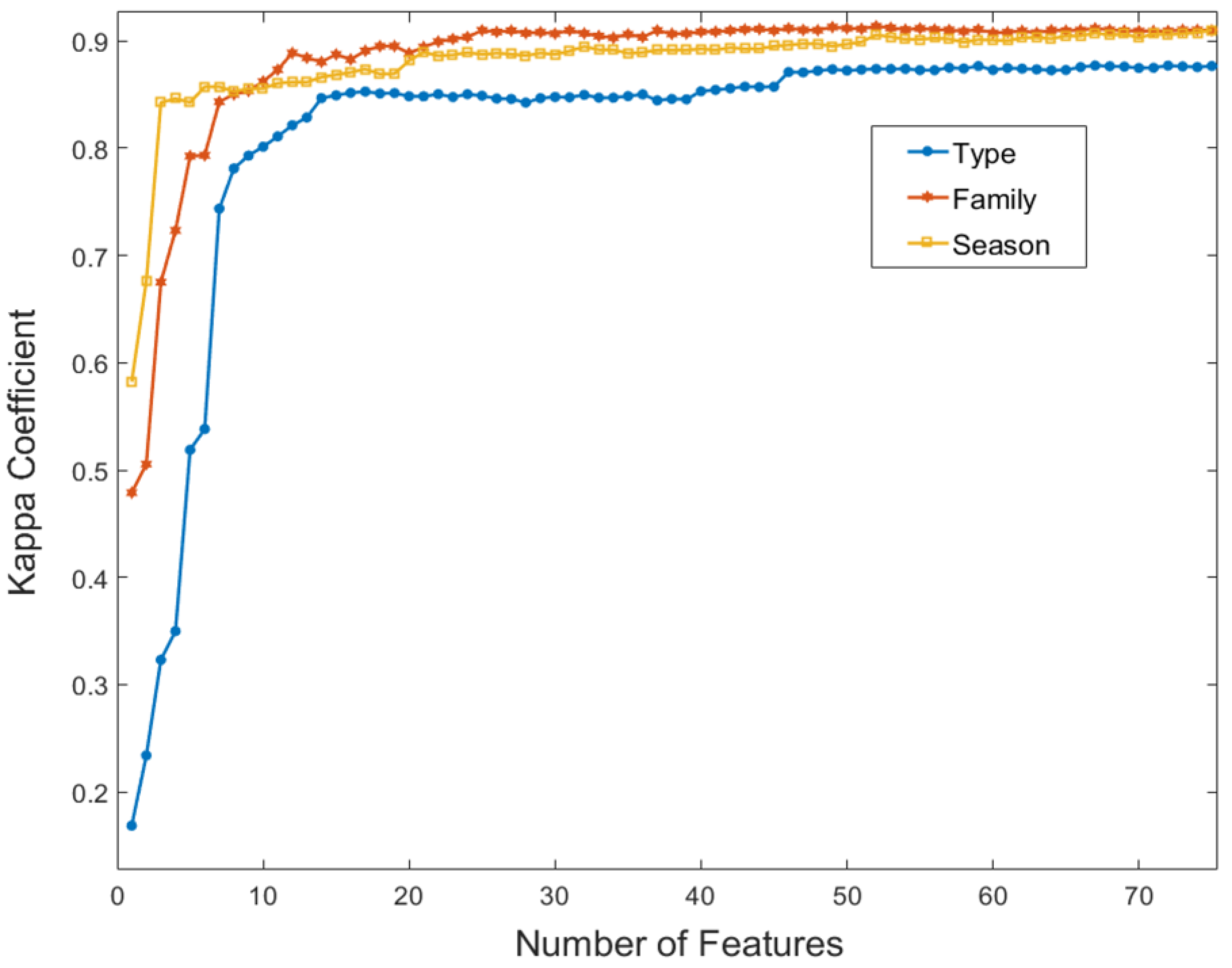
Thematic maps are produced for three different levels of crop nomenclature (crop type, crop family, and season of cultivation), employing separately a quadratic kernel SVM and a RF classifier. SVM and RF are two of the most popular non parametric classifiers in land cover mapping and their comparison has been an increasingly interesting topic in recent publications [
16]. However, there is limited literature on their performance comparison under a Sentinel-2 based scheme, and even more under computational efficiency considerations that the Sentinel-induced big data shift demands. Differences between the two classifiers are evaluated in terms of execution time, classification accuracy, and relevance to the crop identification issue. Further, the size of the variable space and the importance of individual variables are quantified and accordingly evaluated. The proposed methodology is finally applied to Landsat-8 OLI and down-sampled Sentinel-2 MSI equivalent variable spaces, for the comparison of spatial, temporal, and spectral characteristics between the two sensors. Lastly, we performed a compliance check analysis for the CAP Crop Diversification requirement to showcase the scheme’s capacity for effective decision making within the context of the control of CAP subsidies.
3. Methods
Several machine learning algorithms of the supervised classification families of decisions trees, discriminant analysis, SVM, nearest neighbors, and tree ensembles were tested in a preliminary analysis. The analysis showed that the quadratic kernel SVM was the most accurate classifier, while RF came second best but with considerably improved computational efficiency. Hence, the implementation and comparison of these two classifiers was considered of great interest.
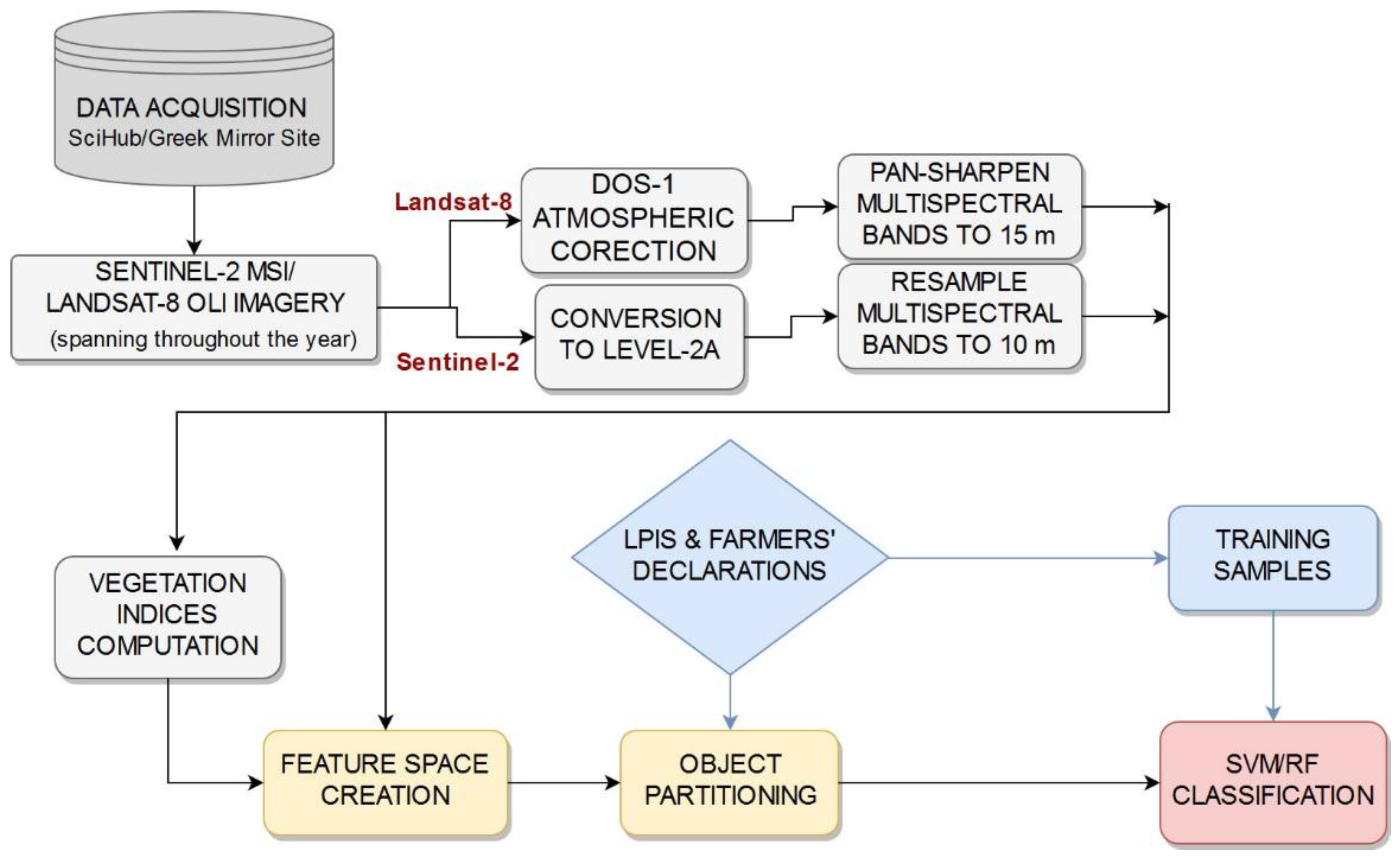
Crop type maps were produced via applying separately the SVM and RF classifiers to the Sentinel-2A MSI and Landsat-8 OLI imagery, under a parcel-based approach. An overview of the processing chain is shown in
Figure 4, with a brief description of the steps in the following subsections.
3.1. Pre-Processing
Sentinel-2A tiles were downloaded at Level 1C, which refers to 100 × 100 km
2 ortho-images projected to cartographic geometry based on a Digital Elevation Model (DEM). Level 1C products are then transformed to Level-2A Bottom of Atmosphere (BOA) reflectances, using the Sen2Cor tool. Sentinel-2 bands of 20 m spatial resolution are resampled to 10 m spatial resolution, using the Nearest Neighbor (NN) resampling algorithm. Landsat-8 OLI imagery was acquired in GeoTiff format at Level 1TP, having been radiometrically calibrated and ortho-rectified. Image pixels have then been converted from digital numbers (DN) to radiances, to Top of Atmosphere (TOA) reflectances, using the Semi-Automatic Classification plugin in the geographic information system application QGIS [
27]. DOS-1 atmospheric correction has been additionally applied, converting data to surface reflectances.
Pan-sharpening was then performed by merging the moderate resolution (30 m) multispectral data with the higher resolution panchrormatic (15 m), providing multispectral imagery of higher resolution features. The employed technique implements a Brovey Transform, where the pan-sharpened values of the multispectral bands are calculated as in Equation (1) [
27].
where I is the intensity, while MS is the multispectral, and PAN is the respective panchromatic pixel values. Intensity weights are a function of the multispectral data and are defined as in Equation (2) [
27].
3.2. Vegetation Indices
Vegetation indices (VIs) attempt to accentuate the vegetation signal, while diminishing soil background and solar irradiance contributions [
28]. NDVI and Normalized Difference Water Index (NDWI) have been widely used in crop monitoring and crop mapping applications [
7,
29,
30]. In this study, NDWI is used as defined by Gao (1996), utilizing the SWIR and NIR parts of the electromagnetic spectrum to correlate to plants’ water content [
31]. SWIR is sensitive to dry matter content, leaf structure, and water content, while NIR only accounts for the first two; hence the water content property is set apart. VIs can be fully exploited in multi-temporal schemes, since crop types’ unique phenology calendars enable accurate crop discrimination. In this regard the Plant Senescence Reflectance Index (PSRI), which is defined as (Red-Green)/NIR, can form dissimilar spectral signatures for the different crop types, being particularly sensitive to their senescence phase [
28].
3.3. Image Partioning to Parcel Objects and Feature Space Creation
Image segmentation that makes use of the spatial, temporal, and spectral features of satellite imagery is a complex and computationally demanding process, requiring fine-tuning that depends on the region and involved crop types [
24]. Consequently, the adoption of image segmentation for partitioning the image time-series into parcels would not have supported the considerations of operationalization, transferability, and scalability, which the proposed methodology aspires to respect. The study assumes the viewpoint of a paying agency that is in charge of the management and control of CAP payments. The LPIS is one essential computerized database that paying agencies use within their operations and are mandated to frequently update. It should be noted that the reliability of the LPIS data is dependent on the update frequency, given that the evolution of the field limits can be significant over the years. However, in an attempt to exploit the benefits of an object-based approach, while at the same time preserving the scheme’s simplicity, it was decided that following a LPIS-based object partitioning approach is an acceptable trade off.
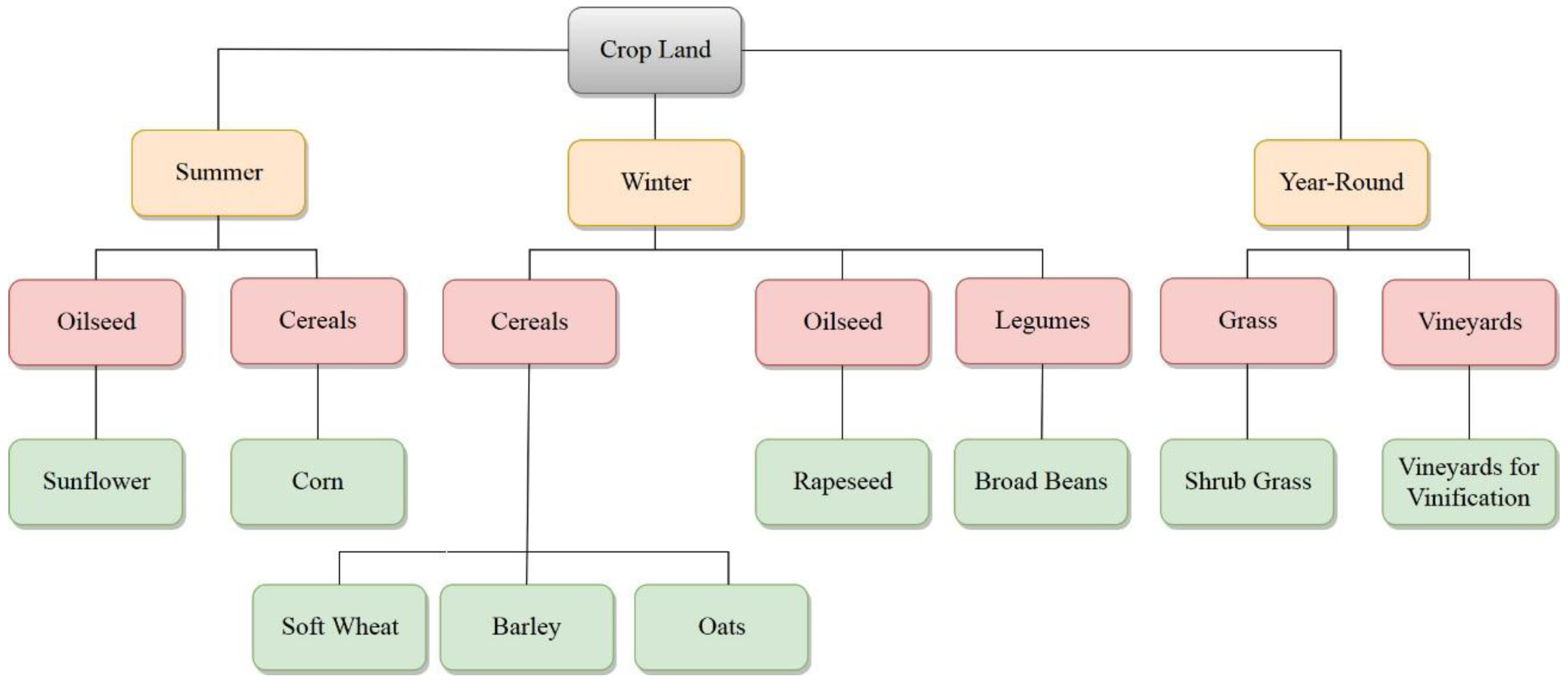
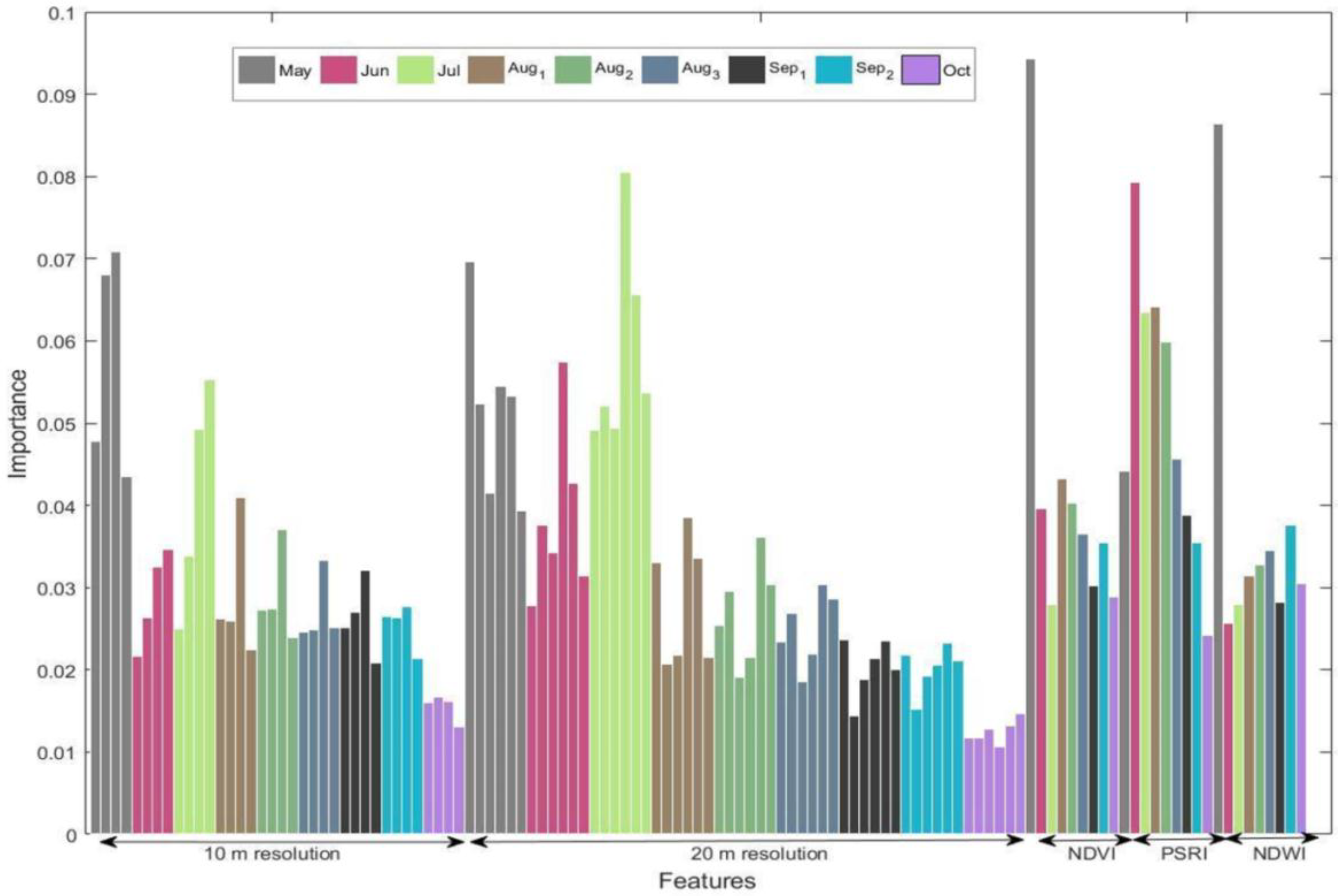
Table 1 lists the variables that make up the Landsat- and Sentinel-based datasets. The Sentinel-2 feature space, initially, comprises of all multispectral bands, for each individual scene employed (90 variables). In turn, VIs (NDVI, NDWI, and PSRI) for all temporal instances (27 variables) are calculated at pixel level and thereafter incorporated into the feature space (117 variables). In the same manner the Landsat-8 feature space includes a total of 63 variables, including the pan-sharpened multispectral data (42 variables) and the equivalent VIs (21 variables). Then the time-series of imagery is partitioned into parcels via utilizing the geometry of the LPIS vector data. Specifically, the pixel values that fall within the boundaries of the LPIS polygons are averaged, giving a single parcel value for every variable.
3.4. Supervised Classification
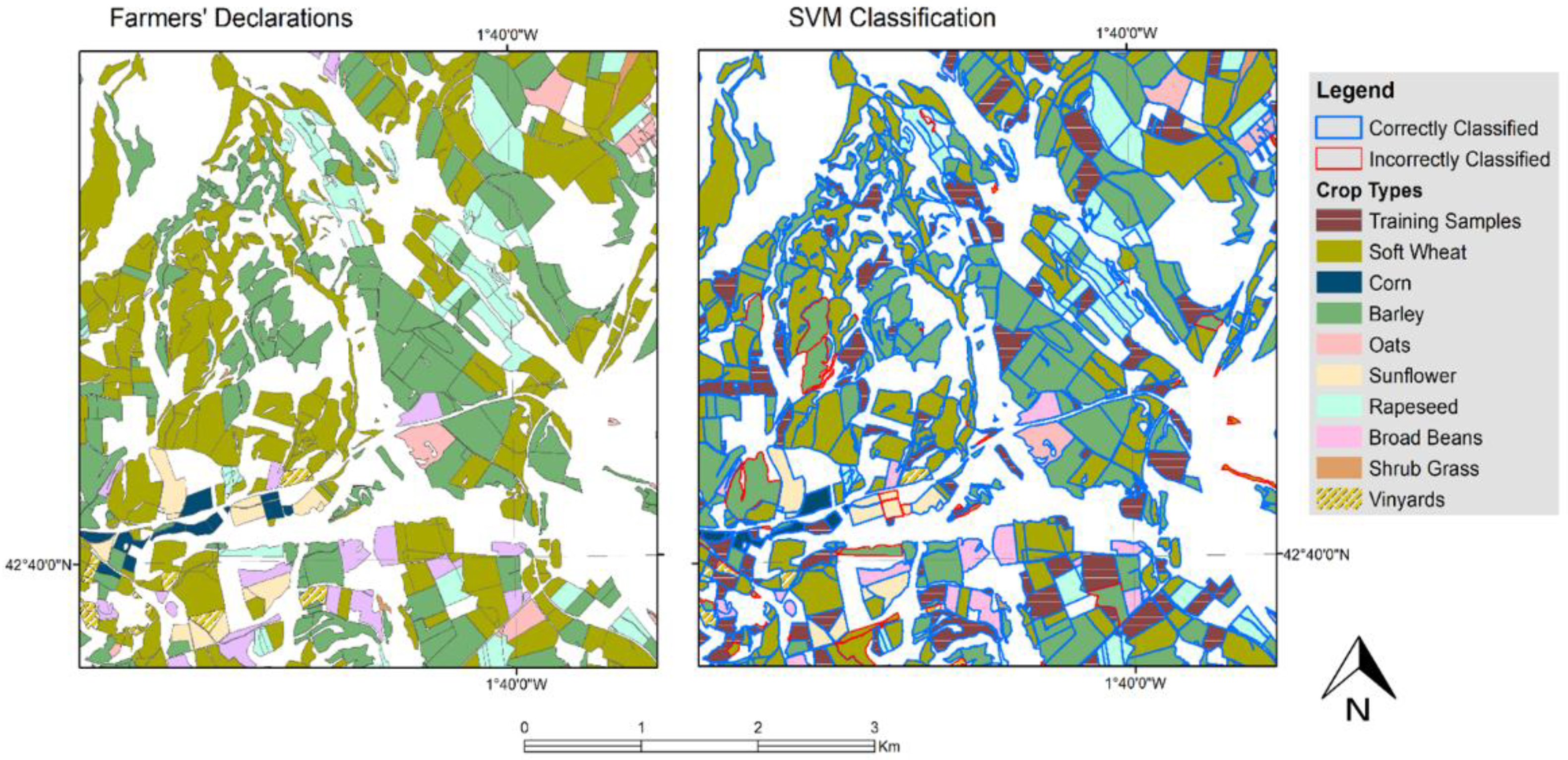
We trained the classifiers based on a subset of the farmers’ declarations. Validated ground truth data were available but limited in number, as such information can only be acquired via field inspections. Therefore, we have assumed that the farmers’ declarations for 2016, as we received them, are valid in their majority. This is a fair assumption that is supported by INTIA inspectors, the workforce in charge of the field controls of the regional paying agency. In fact, cross-checking the validated data with the declarations showed that 99% of the farmers stated truthfully the cultivated crop type, out of 464 validated parcels.
The dataset was separated into randomly selected training and test sets. Multiple such splits were used in order to showcase the sensitivity of the models to the training data. Accordingly, the classification estimations were evaluated against the respective test subsets of the farmers’ declarations. The number of training samples taken for each individual crop class was finalized at 20% of the total crop parcels of that class. When experimenting with samples higher than 20% for training, we encountered only a marginal increase in accuracy.
3.4.1. Support Vector Machines
Binary SVMs set a hyperplane by exploiting the feature information of each entity in the training set. This hyperplane would be the decision boundary in the classification process. Optimally, it is defined to maximize the distance between itself and the nearest training entity of any class (functional margin), with larger margins relating to lower generalization errors [
18]. In this case, multiple binary classifiers for all different 36 class pairs (1-to-1 mapping) are combined to construct a single multi-class classifier.
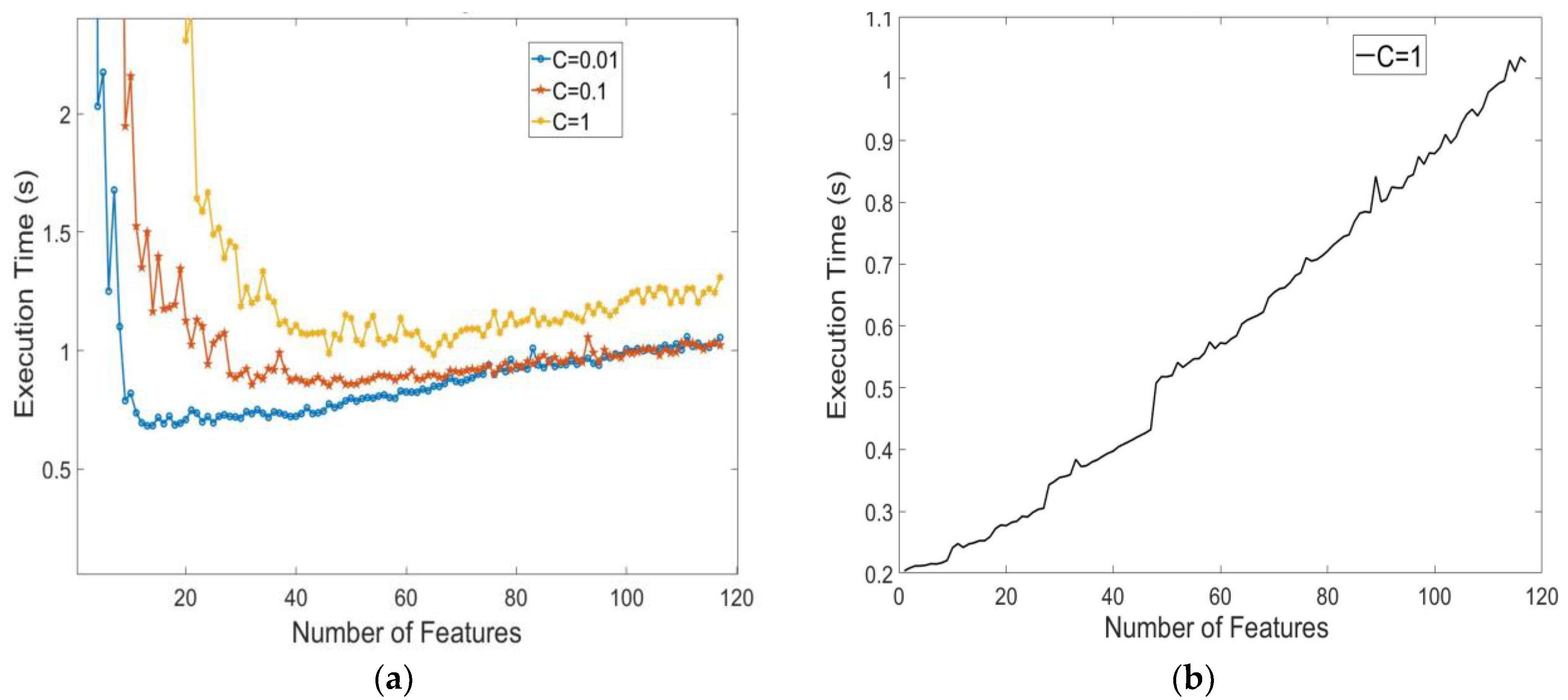
Since the classification problem in this study is not linearly solvable, a quadratic kernel is used to transform the original feature space onto higher dimensions where the crop classes become linearly separable. However, the data are not perfectly separable and the algorithm allows for some misclassification in the training set, which is applied by the box constraint parameter (C). Specifically, higher box constraint values suggest stricter data separation. The model was built using the MATLAB function
fitcecoc, where the kernel scale parameter was set to ‘auto’ mode for optimization. The box constraint parameter was selected via hyperparameter optimization, based on the minimization of the 10-fold cross-validation loss, as shown in
Table 2. Thirty different objective evaluations were performed, of which an indicative subset is presented. The final selection was made under both cross-validation loss minimization and processing time considerations.
It is evident that a box constraint of approximately 1, as in the 1st Evaluation, provides the optimal 10-fold cross-validation loss, while it also proves superior in terms of processing efficiency, as compared to the evaluations of comparable cross-validation loss (i.e., Evaluations 2–5).
3.4.2. Random Forest
Ensemble classifiers, such as RF, increasingly gain popularity in EO applications using high spatial resolution imagery, as they can effectively manage large volumes of data [
7]. RF starts with forming an ensemble of standard decision trees, also known as weak learners. In a simple decision tree, the input entity is entered at the top and as it moves towards the bottom it gets grouped into progressively smaller subsets. The labels are then assigned to parcels based on the maximum number of votes among the ensemble of weak learners [
19,
32]. The RF model was built using the MATLAB function
fitensemble, under the “Bag” method. Bagging refers to the repeated selection of random samples from the entirety of the training set, on which the weak learners train separately. Even though the estimates of a single decision tree would be noisy, the mean estimates over multiple decision trees are both unbiased and resilient to over-fitting [
19]. In the same manner as for the SVM classification, the minimization of 10-fold cross-validation loss is used for the optimal hypermeter tuning. Once again, thirty different objective evaluations were performed, of which an indicative subset is presented in
Table 3.
The hyperparameters “number of weak learners” and “maximum number of splits” were varied and evaluated against the minimization of the objective function. The third evaluation of 30 decision trees was selected as the optimal set of parameters. Nonetheless, it is observed that the first evaluation that uses 479 weak learners gives a lower 10-fold cross-validation loss, but this marginal increase in accuracy cannot excuse the additional processing effort required.
3.5. Accuracy Assessment
Classification performance was assessed according to producer’s accuracy (PA), user’s accuracy (UA), and Cohen’s kappa coefficient (K
c), computed as shown in Equations (3)–(5). PA is the ratio of correctly classified parcels over the total number of parcels for a ground truth class. Alternatively, UA is the ratio of correctly classified parcels for a given class to the total number of parcels predicted to belong to that class [
33]. Statistical metric kappa is used to describe the overall classification accuracy and it is generally preferred over simple accuracy metrics, as it accounts for random agreement between truth and estimation [
34]. Hence, K
c better showcases the capacity of both input data and classification techniques [
35].
where n
ii is the number of parcels correctly classified in a particular crop type class; N is the total number of parcels in the confusion matrix; r is the number of rows; n
icol and n
irow are the column (predicted class labels) and row (ground truth) total, respectively [
36].
5. Discussion
5.1. Sentinel-2 MSI and Landsat-8 OLI
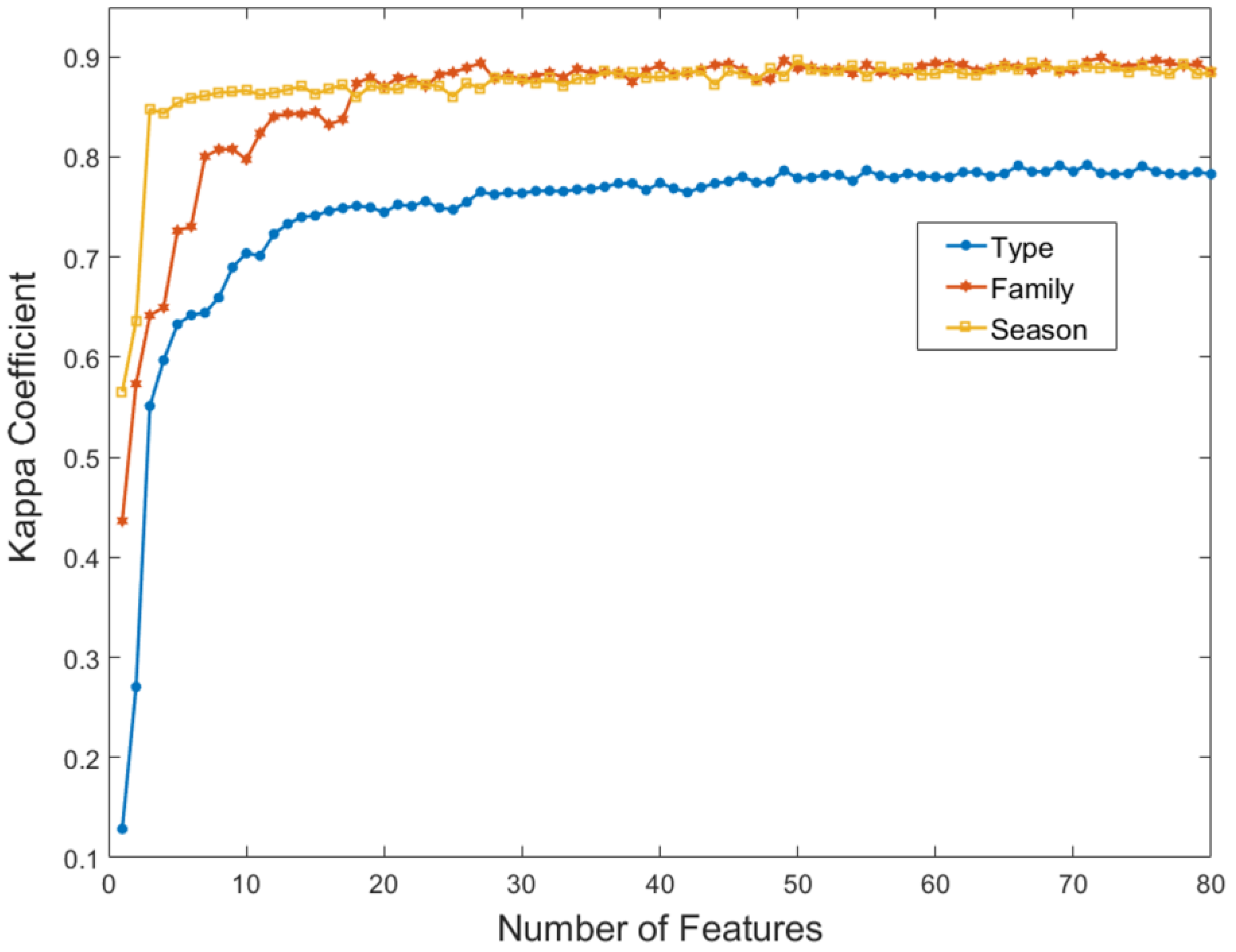
We tested the performance of our processing workflow using Landsat data as input, as well. The aim is to highlight the performance improvement, if any, achieved with Sentinel-2 data, based on the unique spatial and temporal resolution, and the spectral characteristics in utilizing parts of the spectrum of key significance in discriminating between types of vegetation. The values in
Table 7 have been averaged over 20 iterations of random training sample splits.
Landsat crop-type classification proves to perform significantly worse than the Sentinel equivalent (
Table 7). A combination of Landsat and Sentinel feature spaces marginally increases the overall accuracy and thus does not justify the higher complexity introduced. This is expected as the two feature spaces are highly correlated.
We used McNemar’s test to evaluate the statistical significance in the classification accuracy between (i) the two classifiers in the Sentinel scenario and (ii) Sentinel-Landsat pairs in the SVM scenario. This is an interpretable statistical test that quantifies the superiority between two thematic maps [
40]. McNemar’s test is essentially a standardized normal chi-square statistic, computed from a two by two matrix based on correctly and incorrectly classified parcels in both classifications, as shown in Equation (6).
where n
ab is the number of parcels correctly classified by classifier one but incorrectly classified by classifier two; n
ba is the number of parcels correctly classified by classifier two but incorrectly classified by classifier one [
36].
The difference between all pairs, shown in
Table 8, proves to be statistically significant at a 99.99% confidence level. In this table, higher χ
2 values indicate better accuracy performance for the first item in the “pairs” column. These results further support the argument of SVM’s dominance over RF (pair 5) and similarly MSI’s dominance over OLI (pairs 1, 2 and 4). Relative χ
2 differences among the pairs can in ways determine the importance of parameters such as spatial resolution, spectral characteristics, and choice of classifier.
OLI’s data pan-sharpening and MSI’s data down-sampling, in pairs (1) and (4) respectively, attempt to reduce the effect of the spatial resolution difference and thus isolate and quantify the importance of other sensor attributes. The difference in accuracy is significant for both scenarios, which can be attributed to Sentinel-2’s superiority in spectral characteristics, specifically having four vegetation red-edge bands (B05, B06 and B07). The difference for pair (3) is statistically significant but, nonetheless, implies a marginal increase in accuracy. In other words, pan-sharpening proves indeed useful for Landsat-8 but cannot be compared with the higher spatial resolution, in which Sentinel-2 multispectral bands sense directly.
Moreover, pair (2) depicts the maximum difference between the two sensors, accounting for the impact of both spatial resolution and spectral characteristics. Sentinel’s superiority in temporal resolution could not be adequately exhibited for the present case study, as the cloud free images for the two sensors are comparable in both number and temporal span. Nevertheless, the sensors’ difference in temporal resolution is significant and even larger performance differences are expected in most of relevant scenarios.
5.2. Relevance of Methods
The overall performance of the proposed scheme is in accordance with the requirements of an operational agriculture monitoring system. Discrimination and characterization of the cultivated crop types, is of paramount importance in the development, conservation, and management of natural resources at both macro- and micro-scales [
41]. The identification of crops, along with their distribution, management practices, and annual rotation schemes provide essential information for the implementation, control, and monitoring of agricultural policies and environmental measures imposed by the CAP [
3].
Open access to the unmatched features of the Sentinel mission, in temporal and spatial resolution, and their efficient exploitation, signal a new era in the field. A revisit time of five days ensures the proper construction of imagery time-series, able for the consistent and timely monitoring of the agricultural landscape. Additionally, the alternative Landsat data, featuring a three-fold reduction in temporal resolution, can offer inadequate number of quality images, particularly in heavily clouded regions.
On the other hand, Sentinel-2’s high resolution multispectral data enable the successful employment of a parcel-based approach and the generation of parcel-specific thematic information. Besides, alternative VHR imagery is unrealistically costly for operational, large-scale, and consistent monitoring. The proposed methods, which effectively take advantage of the Sentinel-2 attributes, could ably function as the backbone for the EO-assisted compliance validation of CAP requirements, especially to what concerns the enhancement of transparency and the simplification of subsidy administration. The scheme was designed to directly assist the CAP paying agencies in their compliance inspections, by utilizing the data used (LPIS and farmers’ declarations) in their existing operations, to offer a monitoring alternative to their inefficient sample-based controls. The scheme is finally characterized by robustness, in the sense that it is largely independent of manual fine-tuning or case-specific optimizations and is thereby reproducible.
5.3. Relevance in Operational Scenarios
The notion of transferability, although addressed in the design process and the selection of input data, remains to be validated by applying the scheme to other agricultural landscapes in the European Union (EU). An evident issue of transferability is the absence of standardization and the dissimilarity of the LPIS data and farmers’ declaration among the different EU countries. There are significant differences in the definition and description of cultivation practices and crop types. Dealing with this variability requires manual pre-processing and polishing of the input data and entails the appropriate definition of the crop types to be classified, merging or breaking them down to classes that describe spectrally coherent vegetation types.
In this study, it was shown that a time-series of multispectral imagery is required for accurate crop classification, as capturing the growing of crops exposes the most significant differences in their spectral signatures and thus enables their successful discrimination. Nonetheless, it was also exhibited that only a handful of images, appropriately distributed in time, is required to offer high thematic accuracy. The twin Sentinel-2 satellites offer a combined revisit time of five days, amounting to more than 70 images throughout the year. It is expected that in most cases this is a sufficient number of images to produce several quality cloud-free images within the year. However, in northern countries, where cloud-free imagery is scarce, Landsat-8 OLI data can be employed to enrich the feature space. Alternatively, fusion techniques with weather independent Sentinel-1 SAR data could also be explored.
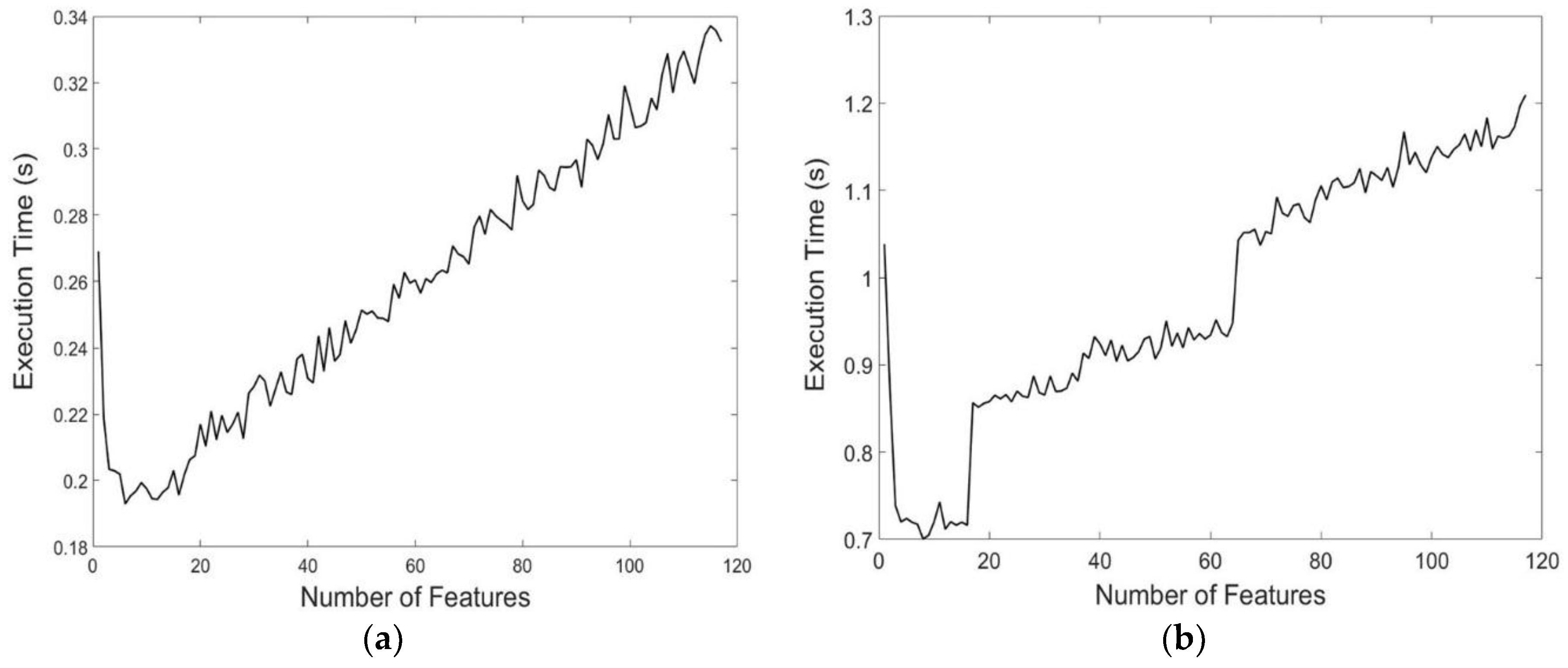
When applying the scheme over large areas, the corresponding Sentinel-2 tiles can cover multiple adjacent satellite tracks, thus having different sensing dates. To overcome this issue, all tracks should be resampled with respect to a common temporal frame of reference, as proposed in [
24]. Starting from the first image acquisition, a sampling step of five days, namely the Sentinel-2 revisit time, is set to create a grid of virtual sensing dates [
24,
42]. Then all images from all tracks are linearly interpolated to these predefined sample instances. The temporal interpolation was shown to marginally affect the classification accuracy [
24].
Since the methodology introduced was designed to be fully transferable by making use of predominantly open access data and data provided by the targeted end-users, the concept of scalability in regional or national scales is of great interest. Scaling up comes against certain trade-offs, mainly regarding the computational complexity, overall accuracy performance, and geographic scale—which in ways can be addressed based on this study’s results. Processing should be performed in adequately small regional extents, such as the one exhibited in the present study, in order to avoid the geographic variability of the crop type spectral signatures. Thereby, the difference in processing time between SVM and RF application, as presented in
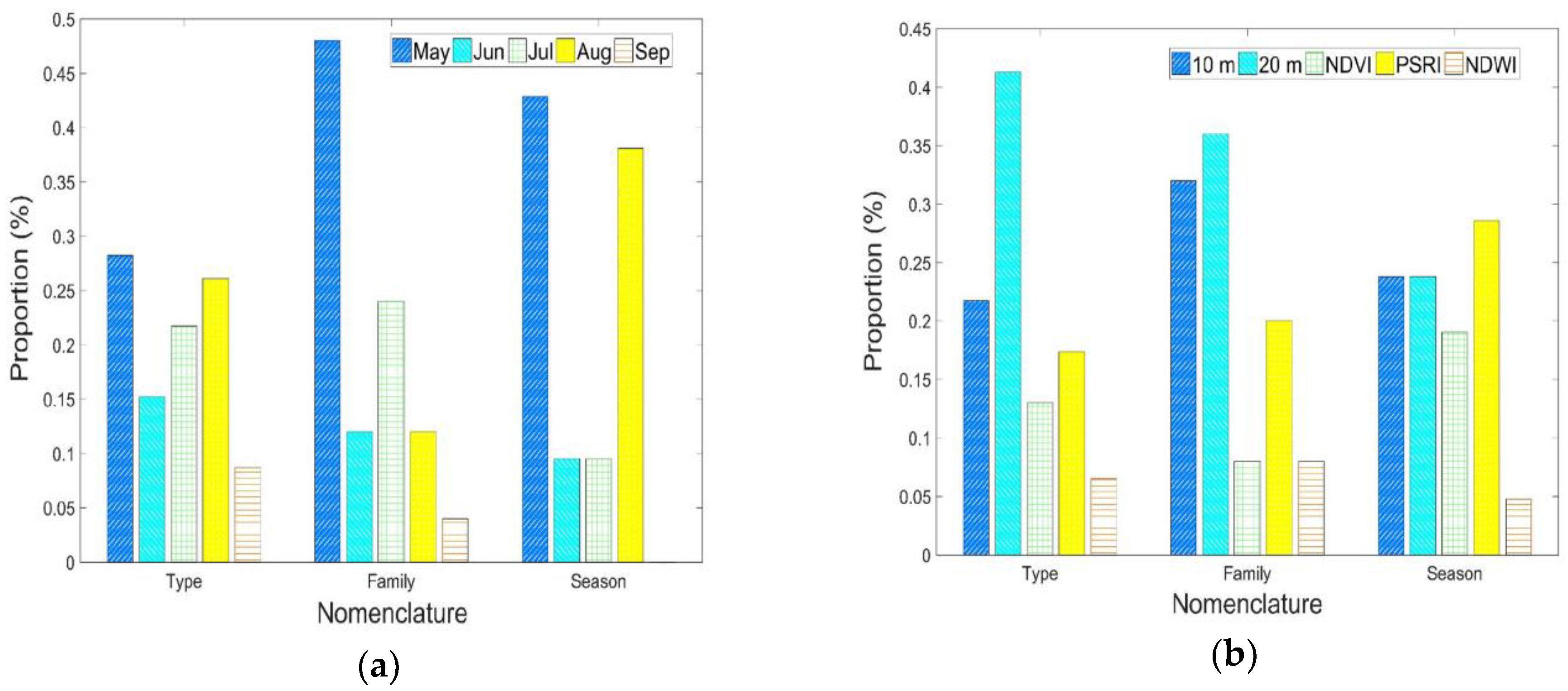
Section 4.4, can be thought of as linearly increasing in scaling up scenarios. SVM usage would indeed compromise computational economy, but not significantly. In that respect, accuracy is favored over computational complexity, as the relevant differences are less important. Nevertheless, in cases where the lowest level of nomenclature is not required, RF functions as an excellent alternative. It performs exceptionally for crop family and season of cultivation classifications, where it deals with fewer classes, of more distinct spectral profiles. All in all, it could be argued that both classifiers provide excellent results for a large number of classes, under an overall computationally efficient scheme.
Finally, the dependability of the methodology relies on the assumption that farmers’ declarations are truthful. In this study, it was shown that declarations were correct in their vast majority (99%), which might not be the case for every relevant scenario. In [
43] the authors have analyzed the effect of training class label noise for SVM (linear and radial basis function kernels) and RF classifiers that were applied on simulated vegetation profiles for 10 crop type classes. The results showed that SVM and particularly RF are robust for low noise levels (up to 20%), with a marginal decrease in the OA. The robustness of the RF can be attributed to it excellent generalization ability. Multiple uncorrelated weak learners are trained with a random subset of the training set and then decisions are made based on the majority vote of the ensemble, making the classifier resistant to overfitting [
43]. All in all, it can be argued that the original assumption is fair and that it can ultimately shape a robust scheme, even for cases where incorrect declarations amount to a considerable percentage of the training set.
5.4. Greening 1: Crop Diversification
Monitoring of compliance to CAP’s Greening 1: Crop Diversification requirement is one example of the proposed scheme’s direct application. Crop diversification entails the growing of different crop types based on farmers’ total land area, aiming to improve biodiversity and reduce soil erosion. Farmers owning land of less than 10 ha are automatically exempted from the rule. If however, their land extends between 10 and 30 ha, at least two different crop types must be cultivated, with the main one not exceeding 75% of the total land. Similarly, arable land larger than 30 ha should involve at least three different crop types, with the main one occupying up to 75% and the main two occupying less than 95% of total land [
44]. Based on the SVM crop type classification, 42.6% of farmers were exempted by having total arable land smaller than 10 ha, while only 2.2% were found to not comply with the requirement
The Greening 1 requirement considers the total arable land owned by the farmer in order to decide on their compliance. Since our knowledge was limited to this particular dataset, we assumed that every farmer’s total land is in fact encompassed within the borders of the study area. Therefore, the results are not representative of local farmers’ compliance to Greening 1 but merely exhibit the ease of decision making based on the crop identification product.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}