1. Introduction
During the acquisition of optical satellite images, light reflected from the surface is usually scattered in the process of propagation due to the presence of water vapor, ice, fog, sand, dust, smoke, or other small particles in the atmosphere. This process reduces the image contrast and blurs the surface colors, leading to difficulties in many fields including cartography and web mapping, land use planning, archaeology, and environmental studies. Therefore, an effective haze removal method is of great importance to improve the capability and accuracy of applications that use satellite images. Haze removal aims at eliminating haze effects on at-sensor radiance data prior to the physically based image correction that converts at-sensor radiance to surface reflectance. In cloudy areas, there is no information about the ground surface, whereas in areas affected by haze the image still contains valuable spectral information. Although haze transparency presents an opportunity for image restoration, an efficient and widely applicable haze removal method for handling various haze or thin clouds is still a great challenge, especially when only a single hazy image is available.
Single-image based haze removal has made significant progress recently by relying on different assumptions and prior information. Chavez [
1,
2] presented an improved dark object subtraction (DOS) technique to correct optical data for atmospheric scattering, assuming a constant haze over the whole scene. Liang et al. [
3,
4] proposed a cluster matching technique for Landsat TM data, assuming that each land cover cluster has the same visible reflectance in both clear and hazy regions. The demand for existing aerosol transparent bands makes it impractical in some situations, as visible and near-infrared bands are usually contaminated by haze. Zhang et al. [
5] proposed a haze optimized transformation (HOT) to characterize the spatial distribution of haze based on the assumption that the radiances of the red and blue band are highly correlated for pixels within the clearest portions of a scene and that this relationship holds for all surface types. However, the sensitivity of HOT to water bodies, snow cover, bare soil, and urban targets limits its application. To reduce the impact of spurious HOT responses, various strategies are proposed in the literature [
6,
7,
8,
9]. Liu et al. [
10] developed a background suppressed haze thickness index (BSHTI) to estimate the relative haze thickness and used a virtual cloud point method to remove haze. Makarau et al. [
11,
12] utilized a haze thickness map (HTM) for haze evaluation, based on the premise that a local dark object reflects the haze thickness of the image. Shen et al. [
13] developed a simple and effective method by using a homomorphic filter [
14] for the removal of thin clouds in visible remote sensing (RS) images.
He et al. [
15] discovered the dark channel prior (DCP) that in most of the non-sky patches of haze-free outdoor images, at least one color channel has very low intensity at some pixels. DCP combined with an image degradation model has proved to be simple and effective enough for haze removal. However, it is computationally intensive and may be invalid in special cases. Some improved algorithms [
16,
17,
18,
19,
20] are proposed to overcome these limitations. The great success of DCP in computer vision attracted the attention of researchers working on satellite application. Long et al. [
21] redefined the transmission of DCP and used a low-pass Gaussian filter to refine the atmospheric veil instead of using soft matting method. Pan et al. [
22] noted that the average intensity of remote sensing images’ dark channel is low, but not close to zero. Thus, they added a constant term into the image degradation model for haze removal. Jiang et al. [
23] utilized a proportional strategy to gain accurate haze thickness maps for all bands from the original dark channel in order to prevent underestimation. These methods succeed in solving specific scenarios in practical applications. However, adjustable parameters in an algorithm must be well designed for various situations to obtain ideal results, which requires a considerable number of experiments on a wide variety of selected images. In addition, these algorithms are effective for local operations, but cannot handle a whole satellite image properly.
In recent years, haze removal methods were developed in the machine learning framework. Tang et al. [
24] combined four types of haze-relevant features with random forests [
25] to estimate the haze transmission. Zhu et al. [
26] created a linear model to evaluate the scene depth of a hazy image, depending on a prior color attenuation. The parameters of the model are learned with a supervised learning method. Despite the remarkable progress, the limitation of these methods lies in the fact that the haze-relevant features or heuristic cues are not effective enough. Following the success of the convolutional neural network (CNN) for image restoration or reconstruction [
27,
28,
29], Cai et al. [
30] proposed DehazeNet, a trainable CNN-based end-to-end system for haze transmission estimation. DehazeNet provides superior performance on natural images over existing methods and maintains efficiency and ease of use. Nevertheless, the “shallow” DehazeNet cannot handle RS images properly due to the dramatic spatial variability of images or haze in it and complicated nonlinear relationship between haze transmission and spectral-spatial information of images [
31]. It is believed that deep learning architectures are generally more robust to the nonlinear input data owing to the ability to extract high-level, hierarchical, and abstract features. In the RS community, large numbers of deep networks are currently developed in the field of hyperspectral image classification [
32,
33], semantic labelling [
34,
35], image segmentation [
36], object detection [
37,
38], change detection [
39], etc. However, to the best of our knowledge, a deep network has not been proposed for haze removal of RS images.
In this study, we propose a multi-scale residual convolutional neural network (MRCNN) for the first time that can learn the mapping relations between hazy images and their associated haze transmission automatically. MRCNN behaves well in predicting accurate haze transmission by extracting spatial–spectral correlation information and high-level abstract features from hazy image blocks. Specifically, the dilated convolution is utilized to obtain local-to-global contexts including details of haze and the trend of haze spatial variations. Technically, residual blocks are introduced into the network to avoid loss of weak information, and dropout is used to improve the generalization ability and prevent overfitting. Experiments on Landsat 8 Operational Land Imager (OLI) data demonstrate the effectiveness of MRCNN for haze removal.
The remaining parts of this paper are organized as follows.
Section 2 briefly introduces the haze degradation model and provides some basic information about CNNs.
Section 3 describes the details of the proposed MRCNN. The experimental results and comparison to other state-of-the-art methods are showed in
Section 4. The model performance, spectral consistency before and after haze removal, and influence on vegetation index are discussed in
Section 5. Finally, our conclusions are outlined in
Section 6.
3. Data and Method
3.1. Data
The remote sensing (RS) images used in this study are Landsat 8 Operational Land Image (OLI) data, obtained from the Earth Explorer of the United States Geological Survey (USGS) (
https://earthexplorer.usgs.gov/). The OLI is an instrument onboard the Landsat 8 satellite, which was launched in February 2013. The satellite collects images of the Earth with a 16-day repeat cycle. The approximate scene size is 170 km north–south by 183 km east–west. In total, the OLI sensor has eight multispectral bands. The spatial resolution of the OLI multispectral bands is 30 m, and the digital numbers (DNs) of the sensor data are 16-bit pixel values. As haze usually has an influence on the visible and near-infrared (NIR) bands, sequentially including band 1 (coastal/aerosol, 0.43–0.45 μm), band 2 (blue, 0.45–0.51 μm), band 3 (green, 0.53–0.59 μm), band 4 (red, 0.64–0.67 μm), and band 5 (NIR, 0.85–0.88 μm), thus just the first five bands of the OLI images are used as inputs of the following network for the prediction of haze transmission.
3.2. CNN Architecture
The haze degradation model in
Section 2.1 suggests that the estimation of the haze transmission map is of the most important task to recover a clear image. To this end, we present a multi-scale residual CNN (MRCNN) to learn the mapping relations between the raw hazy images and their associated haze transmission automatically.
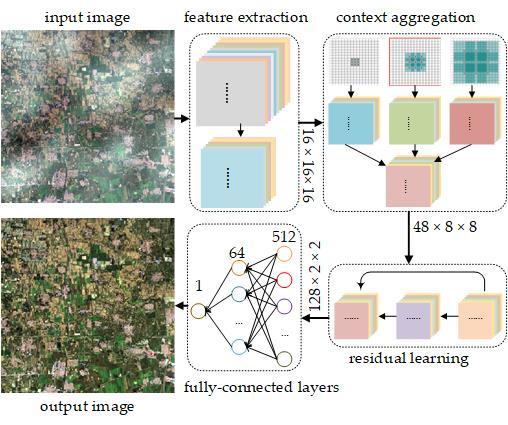
Figure 5 illustrates the architecture of MRCNN, which mainly consists of four modules: spectral–spatial feature extraction, multi-scale context aggregation, residual learning and fully connected layers. The detailed configurations of all layers are summarized in
Table 1, and are explained in the following.
3.2.1. Spectral–Spatial Feature Extraction
To address the ill-posed nature of the single image dehazing problem, existing methods propose various empirical assumptions or prior knowledge to extract intermediate haze-relevant features, such as dark channel [
15], hue disparity [
47], and color attenuation [
26]. These features reflect different perspectives of the original image and are helpful for the estimation of haze transmission. Inspired by this, we design the first module of (M1) MRCNN for haze-relevant feature extraction. In the field of image classification, it is proved that the usage of spectral features and spatial information in combined fashion can significantly improve the final accuracy [
48]. Thus, we utilize 3D convolutional kernels to extract spectral and spatial features simultaneously in M1. The 3D convolution operation computes each pixel in association with
d ×
d spatial neighborhoods and
n spectral bands to exploit the important discriminative information and take full advantage of the structural characteristics of the 3D input data cubes.
After feature extraction, we apply a Maxout unit [
49] for nonlinear mapping as well as dimension reduction, which is able to eliminate information redundancies and improve the performance of the network by removing multi-collinearity. Maxout generates a new feature map by taking a pixel-wise maximization operation over
k feature maps in the layer below:
where
j indexes the feature map in the
mth layer,
i indexes the feature map in the (
m − 1)th layer,
means the number of feature maps in
mth layer, and
denotes multiplicative operation.
Specifically, M1 connects to the input layer that contains 3D hazy patches of size 5 × 16 × 16 (channels × width × height, similarly hereafter). The inputs are padded with one pixel in the spatial dimensions. We use zero padding in this paper. The convolutional layer filters inputs with 64 kernels of size 5 × 3 × 3. The stride of these kernels, or the distance between the receptive fields’ centers of the neighboring neurons, is one pixel. The 3 × 3 convolutional filter is the smallest kernel to seize patterns in different directions, such as center, up/down, and left/right. Additionally, small convolutional filters will increase the nonlinearities inside the network and thus make the network more discriminative. The Maxout unit takes four feature maps that are generated by the convolutional layer in a non-overlapping manner as input, calculates maximum value at each pixel, and finally outputs one feature map with an unchanged size. Finally, M1 outputs 16 feature maps of size 16 × 16.
3.2.2. Multi-Scale Context Aggregation
When observing an image, we often zoom in or out to recognize its characteristics from local to global. This process demonstrates that features in different scales are important for inference of relative haze thickness from a single image when additional information is lacking. Herein, we design the second module (M2) for multi-scale context aggregation. Basically, there are two approaches to gain the feature in a large receptive field: deepening the network or enlarging the size of the convolutional kernels. Although theoretically, features from high-level layers of a network have a larger receptive field on the input image, in practice, they are much smaller [
37]. Enlarging the convolution kernel size directly can also obtain wider information, but it is always associated with exponential growth of learnable parameters. Dilated convolution [
50] provides us with a new approach to capture multi-scale context by using different dilation rates. Dilated convolution expands the receptive field without extra parameters so that it can efficiently learn more extensive, powerful and abstract information. In addition, dilated convolution is capable of aggregating multi-scale contextual information without losing resolution or analyzing rescaled images.
Figure 6 illustrates an example of 2-dilated convolution. The convolution kernel is of size 3 × 3 and its dilation rate equals 2. Thus, each element in the feature map after dilated convolution has a receptive field of 7 × 7. In general, the size of receptive field
of 3 × 3 filters with different dilation rate
can be computed as follows:
where
represents the set of natural numbers. To make the size of resulting feature map unchanged, the padding rate should be set as
in the corresponding direction. By setting a group of small-to-large dilation rates, a series of feature maps with local-to-global contexts can be obtained. Local contexts record low-level details of haze while global contexts identify the trend of haze spatial variations with its wide visual cues. Meanwhile, generated feature maps with multi-scale contexts can be aligned automatically due to their equal resolution.
Specifically, M2 takes as input the output of M1. It contains three parallel sub-layers using 1-dilated, 2-dilated and 4-dialated convolution, respectively. Each layer has 16 convolution kernels of size 3 × 3. Thus, their actual receptive fields correspond to 3 × 3, 7 × 7 and 15 × 15. To ensure the multi-scale outputs are with the same size, inputs for three sub-layers are padded with 1, 3 and 7 pixels, respectively. Multi-scale feature maps are concatenated to form a 48 × 16 × 16 feature block before being fed into the following OMP layer. The kernel size of the pooling layer is 9 × 9 and its stride is 1 pixel. Therefore, the final output of M2 is 48 feature maps of size 8 × 8.
It should be noted that no activation function is used in M1 and M2 due to the experimental fact that remote sensing image blocks usually produce large gradients in the early stage. A large gradient flowing through a ReLU neuron could cause the weights to update in such a way that the neuron will never activate on any data point again. If this occurs, then the gradient flowing through the unit will forever be zero from that point on, i.e., the training process would “die”. As the process of extracting features proceeds, the distribution of the feature maps in deeper layers tends to be more stable. Therefore, it is more appropriate to add the ReLU activation function in the deeper convolutional layers instead of the shallow ones.
3.2.3. Residual Learning
Obtaining an accurate estimation of haze is not easily accessible, because surface coverage, not haze, is the dominant information in RS images. The features from high-level layers are likely to lose weak information, such as haze. Deeper networks also face a degradation problem [
51]: with an increase in the network depth, accuracy gets saturated and then degrades rapidly; this outcome is not caused by overfitting. Herein, we introduce residual learning [
52] to resolve these issues. Instead of anticipating that each layer will directly fit a desired underlying mapping, we explicitly allow some layers to fit a residual mapping. Formally, denoting the desired underlying mapping as
, we expect stacked layers to fit another mapping of
. Therefore, the original mapping is recast into
. The residual learning is very effective in deep network, because it is easier to fit
than to directly fit
when the network deepens.
Figure 7 shows the residual block used in the third module (M3). All three convolutional layers have
k kernels of size 3 × 3, equipped with ReLU nonlinear activation function. The first convolutional layer outputs its learned features
, which are sent to the second and third convolutional layer for learning residual features
.
and
are then fused using the
sum operation to form the target features
. The following OMP layer performs local aggregation on
without padding. Specifically, M3 connects to the outputs of M2, which are of size 48 × 8 × 8. The inputs are sent to two sequential residual blocks. The convolutional layer in the first block has 64 kernels while 128 kernels are used in the second block. The kernel size of the OMP layers is 5 × 5 and 3 × 3, respectively. Finally, M3 outputs features of size 128 × 2 × 2.
3.2.4. Fully Connected Layers
At the end of the proposed network, we utilize fully connected (FC) layers to achieve our regressive task, i.e., predicting haze transmission relying on abstract features from stacked convolutional layers. The feature maps of the last convolutional layer are flattened and fed into the FC layers. However, the FC layers are prone to overfitting, thus hampering the generalization ability of the overall network. Dropout, a regularization method proposed by Hinton et al. [
53], randomly sets a portion of the hidden neurons to zero during training. The dropped neurons do not contribute in the forward pass and are not used in the back-propagation procedure. Dropout has been proven to improve the generalization ability and largely prevents overfitting [
54].
Specifically, three FC layers are implemented with 512, 64, and one nodes, respectively. They computes their output as , where are weight matrices, are bias vectors, is the output of the previous layer and represents the ReLU activation function. In addition, we have allowed a 50% dropout in the first FC layer. Finally, the FC layers produce a single value representing the haze transmission at the central pixel of each input of hazy patches.
3.3. Training Process
To train the designed MRCNN, a large number of training samples consisting of hazy patches and their corresponding haze transmissions are required. However, it is challenging to obtain the real haze transmission. Inspired by Tang et al.’s method [
24], we generate training samples from clear image blocks by simulating the haze degradation process according to the model in
Section 2.1. This work is based on two assumptions: first, the image content is independent of transmission, i.e., the same content can appear under any transmission; and second, the transmission is locally constant, i.e., image pixels in a small patch have a similar transmission. Given a clear patch
, the atmospheric light
, and a random transmission
, a simulated hazy patch
is generated as
. As the surface radiances reached the sensor would be too weak when the transmission is lower than 0.3, we restrict
in the range
. To reduce the uncertainty of variables in learning,
is simply set to 1 in all five channels, i.e.,
. Herein, a training pair is composed of the generated
and given
.
Considering the difficulty of building a complete dataset containing various kinds of surface cover types, clear samples are collected in a local clear region of a single scene of Landsat 8 OLI data (path 123, row 032, acquisition date 23 September 2015) in our experiments. In addition, if too many surface types are selected for training, the dataset would become extremely large when ensuring sufficient samples for each type, which requires a considerable amount of computer memory and training time. In total, 60 clear blocks of size 240 × 240 are sampled from the test scene. Some examples are shown in
Figure 8. All original clear blocks are normalized using the max-min method to ensure identical scale and that the atmospheric light equals 1. For each block, we uniformly generate 20 random transmissions to generate hazy blocks, which are then tiled into patches with a size of 16 × 16. Thus, 270,000 simulated hazy patches are collected. To ensure the robustness, these patches are shuffled to break potential correlation. Finally, all patches are sorted into a 90% training set and a 10% testing set, whose numbers are 243,000 and 27,000, respectively. Hereafter, we refer to this dataset as D1. It is important to note that the simulated patches are directly used as input of the training network without additional normalization, which would change the real haze depth.
The MRCNN is trained through mini-batch stochastic gradient descent (MSGD) and an early-stopping mechanism. Gradient descent is a simple algorithm in which we repeatedly make small steps downward on an error surface defined by a loss function of some parameters. MSGD estimates the gradient from a mini-batch of examples to proceed more quickly. The batch size is set to 500 in our training. As the predicted variable is continuous, we use the mean squared error as the loss function:
where
refers to the real transmission value,
represents the predicted value, and
is the batch size. Early-stopping combats overfitting by monitoring the network’s performance on a validation set. This technique relinquishes on further optimization when the network’s performance ceases to improve sufficiently on the validation set, or even degrades with further optimization. During training, we randomly chose 80% of the training samples to learn the parameters and the remaining 20% of the training samples were used as the validation set to identify if the network was overfitting. In our experiments, if the validation score is not improved by 1.0 × 10
−5 within 10 epochs, the training process is terminated. The testing set is used to assess the final prediction performance of the trained network with the best validation score. The filter weights of each convolutional layer are initialized through the Xavier initializer [
45], which uniformly samples from a symmetric interval:
where
is the number of input units, and
is the number of output units. For the first convolutional layer,
equals 45 (5 × 3 × 3) and
equals 576 (64 × 3 × 3). The biases are set to 0. The learning rate is 0.01 and is decreased by 0.5 when reaching a learning plateau. We implement our model using the
keras [
55] package with the
theano backend [
56]. Based on the parameters above, the best validation score is 0.0289% obtained at epoch 198, with a test performance of 0.0288%. It takes 145.68 min to finish training using an NVIDIA Quadro K620 GPU. Hereafter, we refer to this trained MRCNN as MODEL-O.
3.4. Dehazing and Post-Processing
After finishing training, we can predict the haze transmission given a new hazy patch. It is feasible to feed a small block into the network at one time for prediction. For each pixel in the block, its 16 × 16 surrounding neighborhood is used for prediction of haze transmission. While for the pixels belonging to the borders of the block, a 16 × 16 surrounding neighborhood cannot be defined. We have implemented a simple algorithm to replicate borders that allows us to handle all the border pixels as any other pixel in the block, i.e., mirroring eight pixels, half of the patch size, of the border outwards, to create the corresponding patches of the original border pixels. When handling a full-size image that occupies considerable physical memory, it is necessary to slice the original image and mosaic the output tiles to avoid running out of computer memory. The adjacent tiles overlap each other with pixels whose number equals the size of training patch, i.e., 16 pixels in our test, to prevent visual disruption. Furthermore, the original hazy image should multiply a scale factor depending on the pixel depth of the original data to ensure that the input values are in [0, 1]. In this way, we can predict the complete haze transmission map of the input block or full-size image. Finally, the clear image can be recovered according to Equations (4) and (5). The lowest decile of predicted transmission map is used as the threshold in Equation (4).
Generally, the radiances of directed dehazing results are lower than that of the clear scenes, as both haze contribution and clear scene aerosol are removed entirely. Meanwhile, the inaccurate estimation of the atmospheric light might lead to potential residual of radiances. Herein, we utilize clear regions, least influenced by haze, as a reference for the compensation of scene aerosol or correction of the residual. We slice the predicted transmission map into tiles of size 200 × 200. The tile with the maximum mean is considered as the clear region. The aim of compensating is to ensure mean radiance of the dehazed block corresponding to the clear region equals to that of the original block in all bands. The process of compensation can be expressed as:
where
is the band number,
is the final radiance,
is the directed recovered value,
represents the mean value of the original clear image block, and
represents the mean value of the directed recovered image block corresponding to the clear region.
3.5. Transferring Application
To reduce the demand for computer memory and time consumption, MODEL-O is trained on a limited dataset. It is feasible to apply MODEL-O for haze removal of surrounding areas that covers the similar surface types. When handling images in another region, a new trained network is required. Learning from the beginning usually costs too much and is unnecessary. Transfer learning is an effective approach to apply stored knowledge gained while solving one problem to a different but related problem. The core of haze removal in different areas is essentially the same, but the surface types are dissimilar. Thus, the new MRCNN can be retrained on the basis of MODEL-O.
We choose another scene (path 119, row 038; acquisition date 14 April 2013) to collect new training samples. In total, 40 blocks of size 240 × 240 are sampled and then 180,000 simulated hazy patches are generated for training. Hereafter, we refer to this dataset as D2. The filter weights and biases are initialized using the learned parameters of MODEL-O, and other settings remain unchanged. The best validation score is 0.0128% obtained at epoch 43, with a test performance of 0.0168%. It takes 31.32 min to complete the optimization. Herein, the retrained MRCNN is named MODEL-T.
After fine-tuning, MODEL-T gains the ability to handle images covering this new type of surface coverage and theoretically still owns the ability of the previous network. The trained network can extend its applicability constantly through transferring learning. The more new types of samples are used for fine-tuning, the stronger the network will be. We expect that the network will finally be capable of addressing various complex situations after several cycles.
6. Conclusions
We present a multi-scale residual convolutional neural network (MRCNN), which takes advantage of both spatial and spectral information for haze removal of remote sensing images. The overall architecture mainly contains four sequential modules: (1) spectral–spatial feature extraction, which utilizes 3D convolutional kernels to extract spatial–spectral correlation information; (2) multi-scale context aggregation, which uses dilated convolution is used to capture abstract features in different receptive fields and aggregate multi-scale contextual information without losing resolution; (3) residual learning, which avoids the loss of weak information while deepening the network for high-level features; and (4) fully connected layers, which take advantage of dropout to improve the generalization ability and prevent overfitting. The network takes hazy patches as input and outputs haze transmission. The training datasets are generated from clear image blocks by simulating the haze degradation process. Considering the difficulty of building a complete dataset containing various kinds of surface cover types, clear samples are collected in a local clear region of a single scene in our experiments. MRCNN is trained through mini-batch stochastic gradient descent (MSGD) and an early-stopping mechanism to minimize the mean squared error between the predicted values and truth haze transmissions. After finishing training, the network is capable of predicting the haze transmission of hazy images in surrounding areas. Post-processing is necessary for the correction of the latent residual of dehazed images. The trained network can be reinforced and fine-tuned by means of further learning from new samples collected in other areas during the transferring application. The optimization costs little time since the initialized parameters have learned sufficient knowledge in the previous stage. The fine-tuned network not only gains the ability to solve new problems but also inherits the ability of the previous network. The trained network can extend its applicability constantly through transferring learning.
Experiments show that the trained network can achieve a validation score of 0.0289% and testing performance of 0.0288% during the original training, and 0.1455% validation error during transferring application, which can reach 0.0168% with further fine-tuning. Taking advantage of the multi-scale context aggregation and residual learning, MRCNN converges faster and can achieve a higher prediction accuracy compared with DehazeNet [
30] and VGGNet [
57]. We selected several scenes of Landsat 8 OLI data for haze removal. The result of image quality assessment indicates that the trained MRCNN is state-of-the-art to obtain dehazed images, whose color is consistent with the actual scene. Compared with the traditional methods based on different priors, the proposed MRCNN owns more powerful generalization ability. Since MRCNN extracts high-level, hierarchical, and abstract features for haze transmission estimation, it hardly suffers from different surface types and various haze or thin clouds. Meanwhile, MRCNN is able to preserve structural information, and prevent the loss of correlation, luminance distortion and contrast distortion of images.
A comparison to haze-free reference data reveals that the dehazing process maintains the proper similarity in clear regions and produces a noticeable enhancement in hazy regions. In addition, the spectral consistency of dehazing results ensures that haze removal would not affect algorithms that rely on the spectral information of remote sensing images.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}