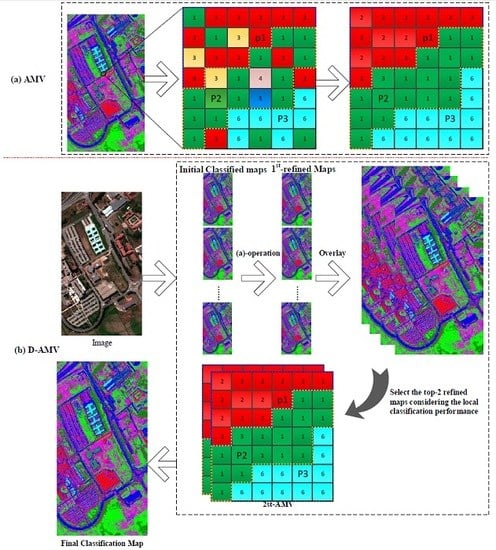
Figure 1.
General scheme of the proposed dual-adaptive majority voting strategy (D-AMVS): (a) process of adaptive majority voting (AMV) for refining one initial classification map and (b) flowchart of the proposed D-AMVS.
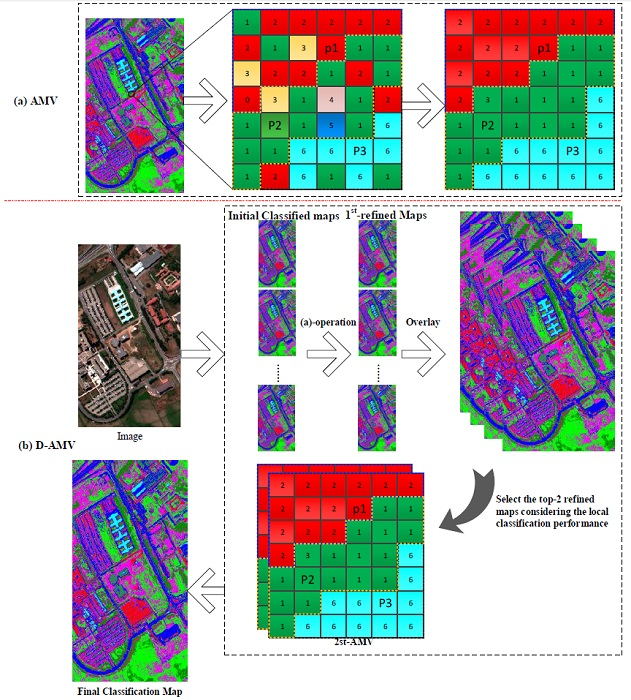
Figure 1.
General scheme of the proposed dual-adaptive majority voting strategy (D-AMVS): (a) process of adaptive majority voting (AMV) for refining one initial classification map and (b) flowchart of the proposed D-AMVS.
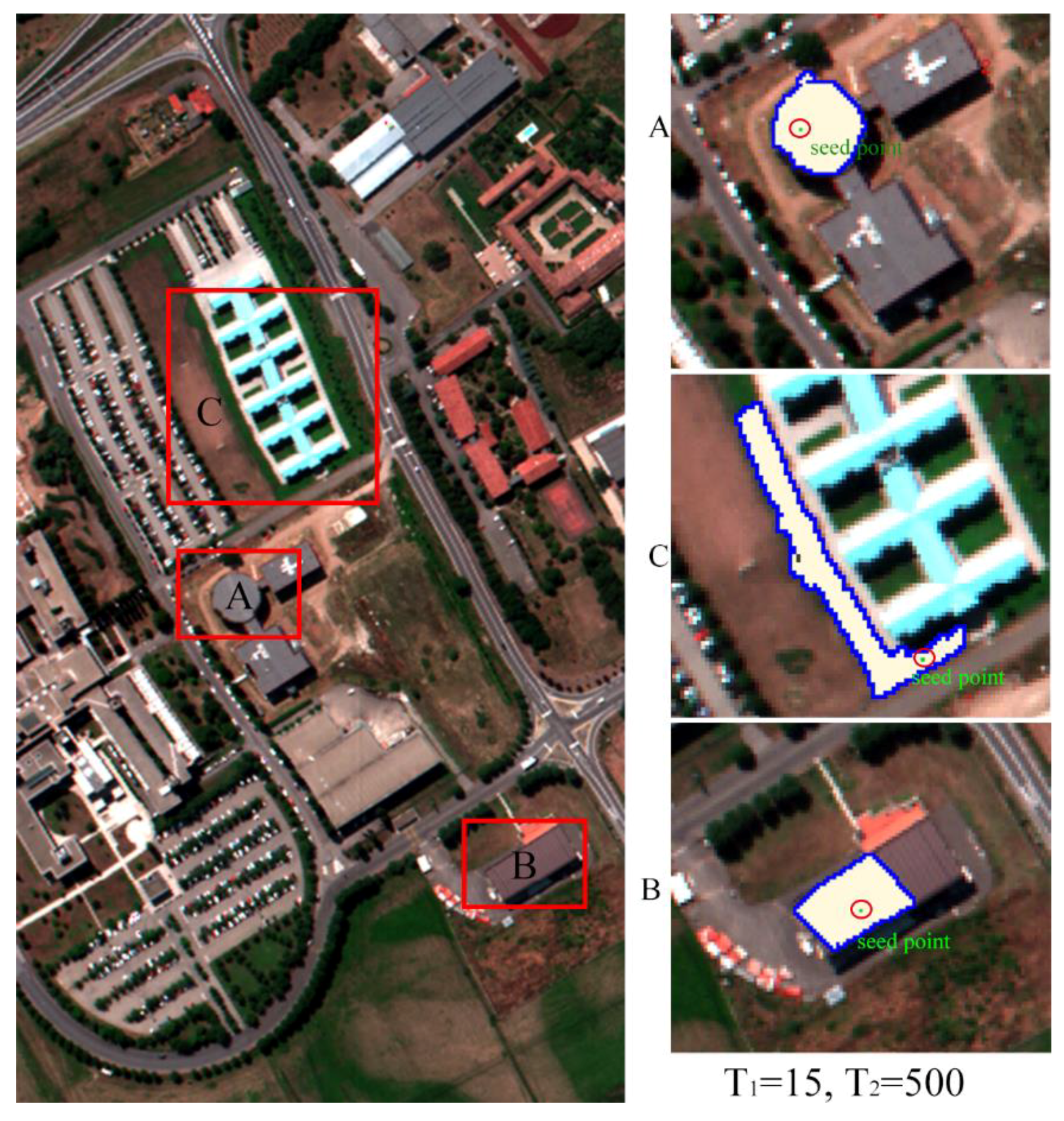
Figure 2.
Examples of adaptive regions for the proposed D-AMVS. The green points inside the red circles are the central pixels of each extension, and the blue borders define the shape of the adaptive region: (A,B) are the examples of adaptive region when the central point in the buildings with different shape; (C) is the example of adaptive region when the central point in the meadows.
Figure 2.
Examples of adaptive regions for the proposed D-AMVS. The green points inside the red circles are the central pixels of each extension, and the blue borders define the shape of the adaptive region: (A,B) are the examples of adaptive region when the central point in the buildings with different shape; (C) is the example of adaptive region when the central point in the meadows.
Figure 3.
Pavia University image used in the first experiment: (a) false color original image of Pavia University and (b) ground reference data.
Figure 3.
Pavia University image used in the first experiment: (a) false color original image of Pavia University and (b) ground reference data.
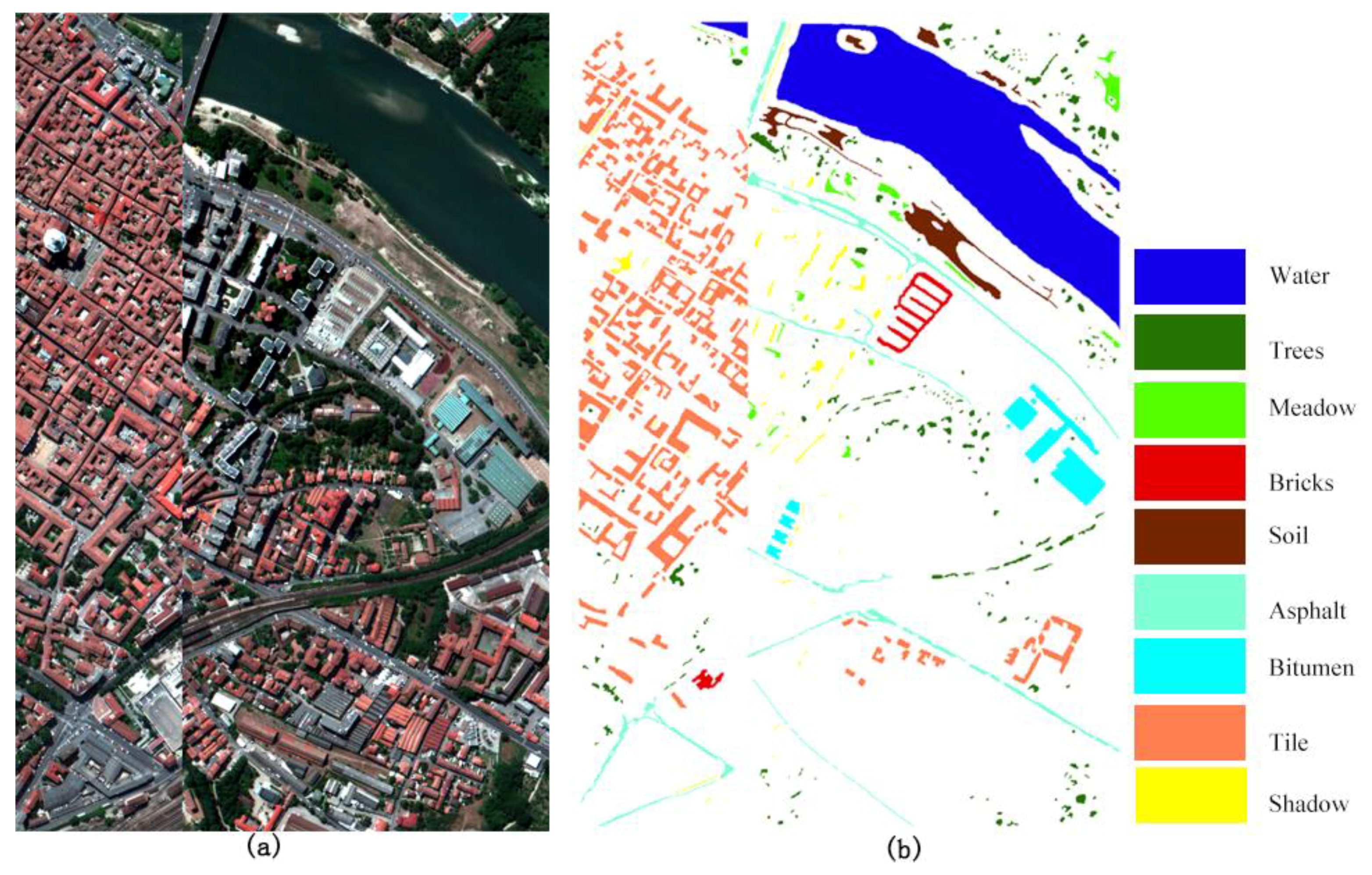
Figure 4.
Pavia Center image used in the second experiment: (a) false color original image of Pavia Center and (b) ground reference data.
Figure 4.
Pavia Center image used in the second experiment: (a) false color original image of Pavia Center and (b) ground reference data.
Figure 5.
Comparison based on the initial classified maps and different post-classification approaches for the Pavia University image: (a) initial classification map based on the MLC classifier, (b) post-classification map acquired by GPCF with a window size, (c) post-classification map acquired by majority voting with a window size, and (d) post-classification map acquired by the proposed D-AMVS with T1 = 60 and T2 = 80.
Figure 5.
Comparison based on the initial classified maps and different post-classification approaches for the Pavia University image: (a) initial classification map based on the MLC classifier, (b) post-classification map acquired by GPCF with a window size, (c) post-classification map acquired by majority voting with a window size, and (d) post-classification map acquired by the proposed D-AMVS with T1 = 60 and T2 = 80.
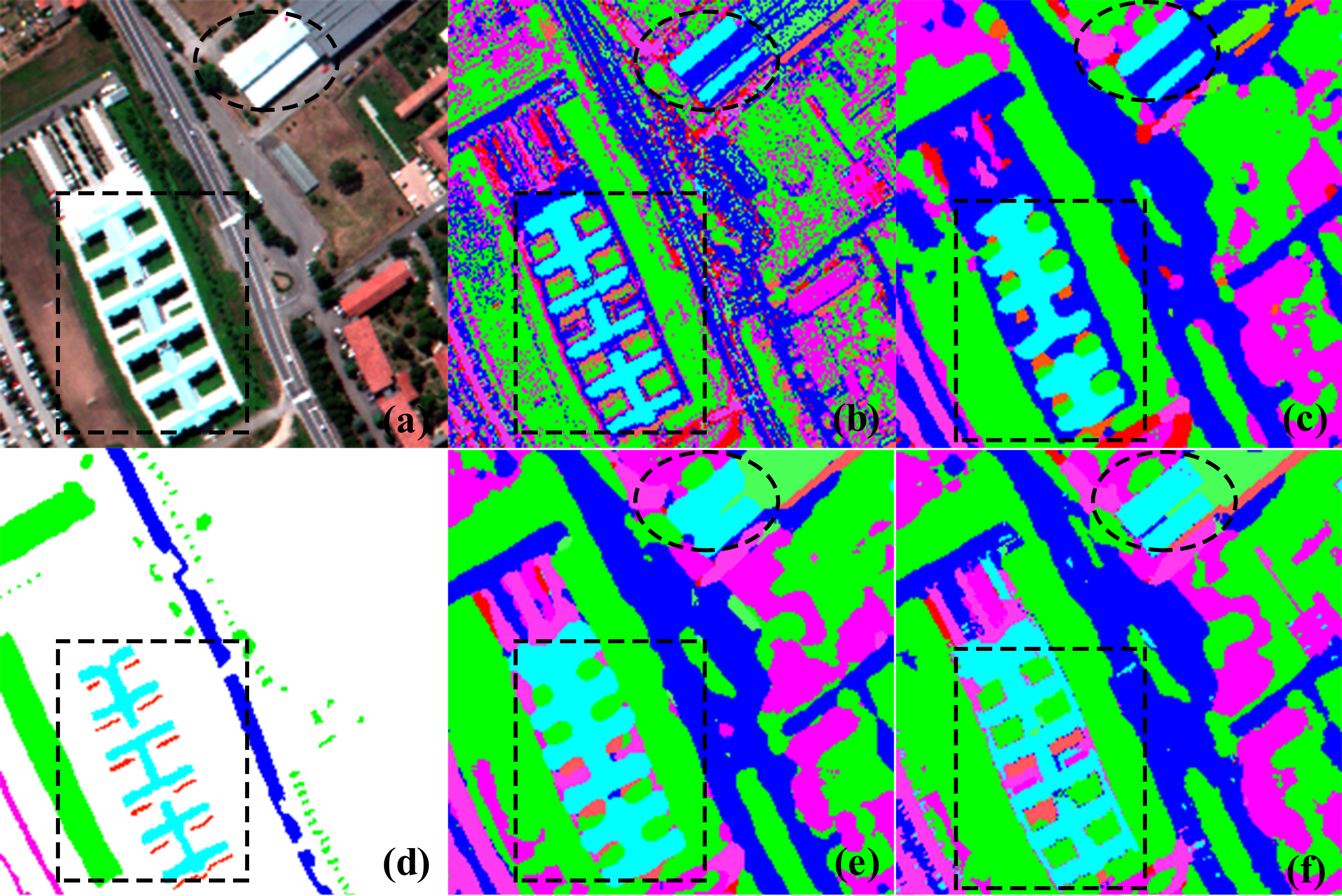
Figure 6.
Zoomed comparisons based on the subfigures: (a) Pavia University image, (b) initial classified map obtained by the MLC classifier, (c) post-classification map obtained by GPCF with a window size, (d) ground reference data, (e) post-classification map acquired by the majority voting approach with a window size, and (f) post-classification map acquired by the proposed D-AMVS with T1 = 60 and T2 = 80.
Figure 6.
Zoomed comparisons based on the subfigures: (a) Pavia University image, (b) initial classified map obtained by the MLC classifier, (c) post-classification map obtained by GPCF with a window size, (d) ground reference data, (e) post-classification map acquired by the majority voting approach with a window size, and (f) post-classification map acquired by the proposed D-AMVS with T1 = 60 and T2 = 80.
Figure 7.
Comparison based on initial classified maps and different post-classification approaches for the Pavia Center image: (a) initial classified map based on RGV spatial–spectral method and SVM classifier, (b) post-classification map acquired by majority voting with a window size, (c) post-classification map acquired by GPCF with a window size, and (d) post-classification map acquired by the proposed D-AMVS with T1 = 70 and T2 = 80.
Figure 7.
Comparison based on initial classified maps and different post-classification approaches for the Pavia Center image: (a) initial classified map based on RGV spatial–spectral method and SVM classifier, (b) post-classification map acquired by majority voting with a window size, (c) post-classification map acquired by GPCF with a window size, and (d) post-classification map acquired by the proposed D-AMVS with T1 = 70 and T2 = 80.
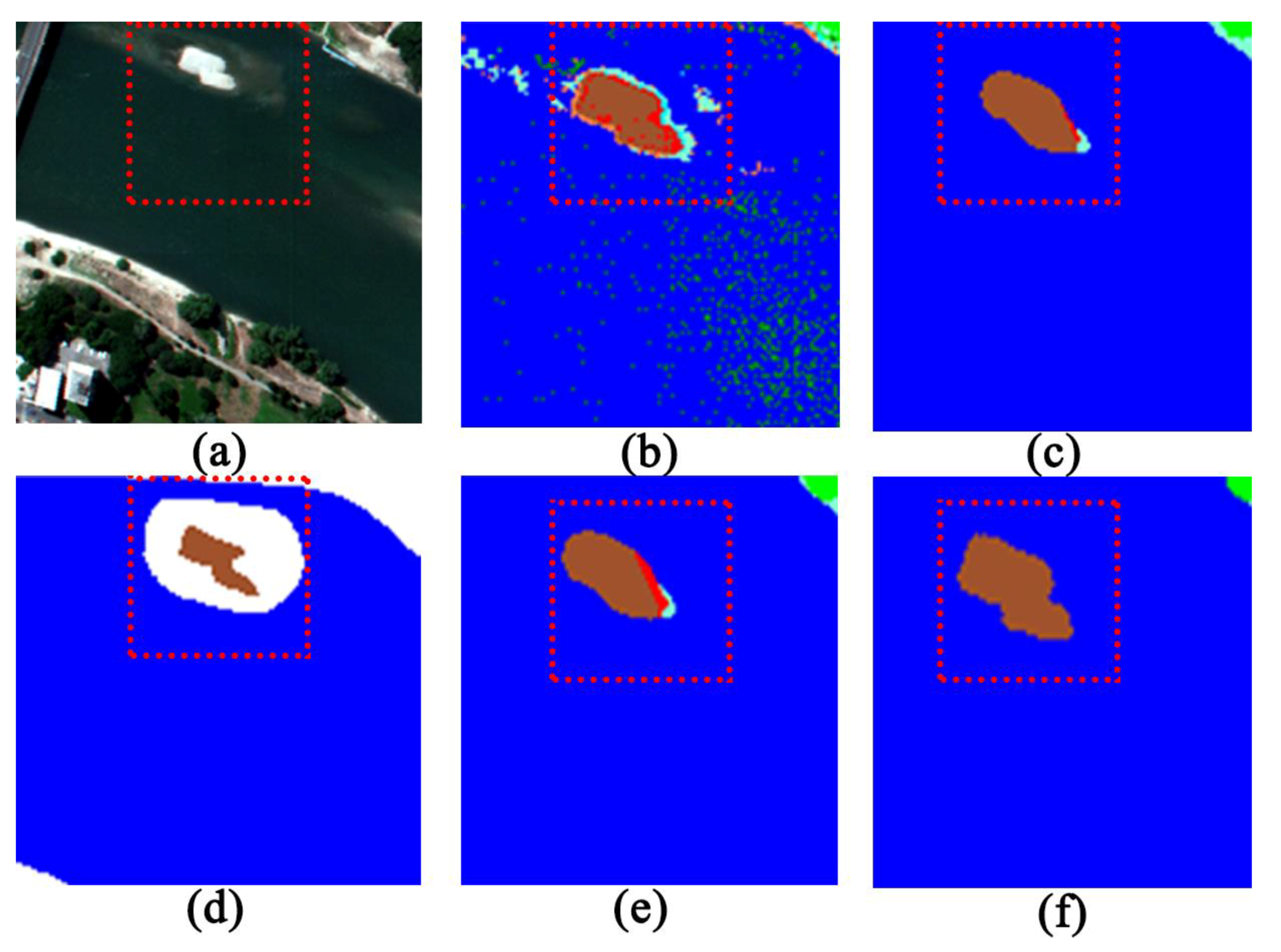
Figure 8.
Zoomed comparisons based on the subfigures: (a) Pavia Center image, (b) initial classified map based on RGV spatial–spectral method and SVM classifier, (c) post-classification map obtained by GPCF with a window size, (d) ground reference data, (e) post-classification map acquired by majority voting with a window size, and (f) post-classification map acquired by the proposed D-AMVS with T1 = 70 and T2 = 80.
Figure 8.
Zoomed comparisons based on the subfigures: (a) Pavia Center image, (b) initial classified map based on RGV spatial–spectral method and SVM classifier, (c) post-classification map obtained by GPCF with a window size, (d) ground reference data, (e) post-classification map acquired by majority voting with a window size, and (f) post-classification map acquired by the proposed D-AMVS with T1 = 70 and T2 = 80.
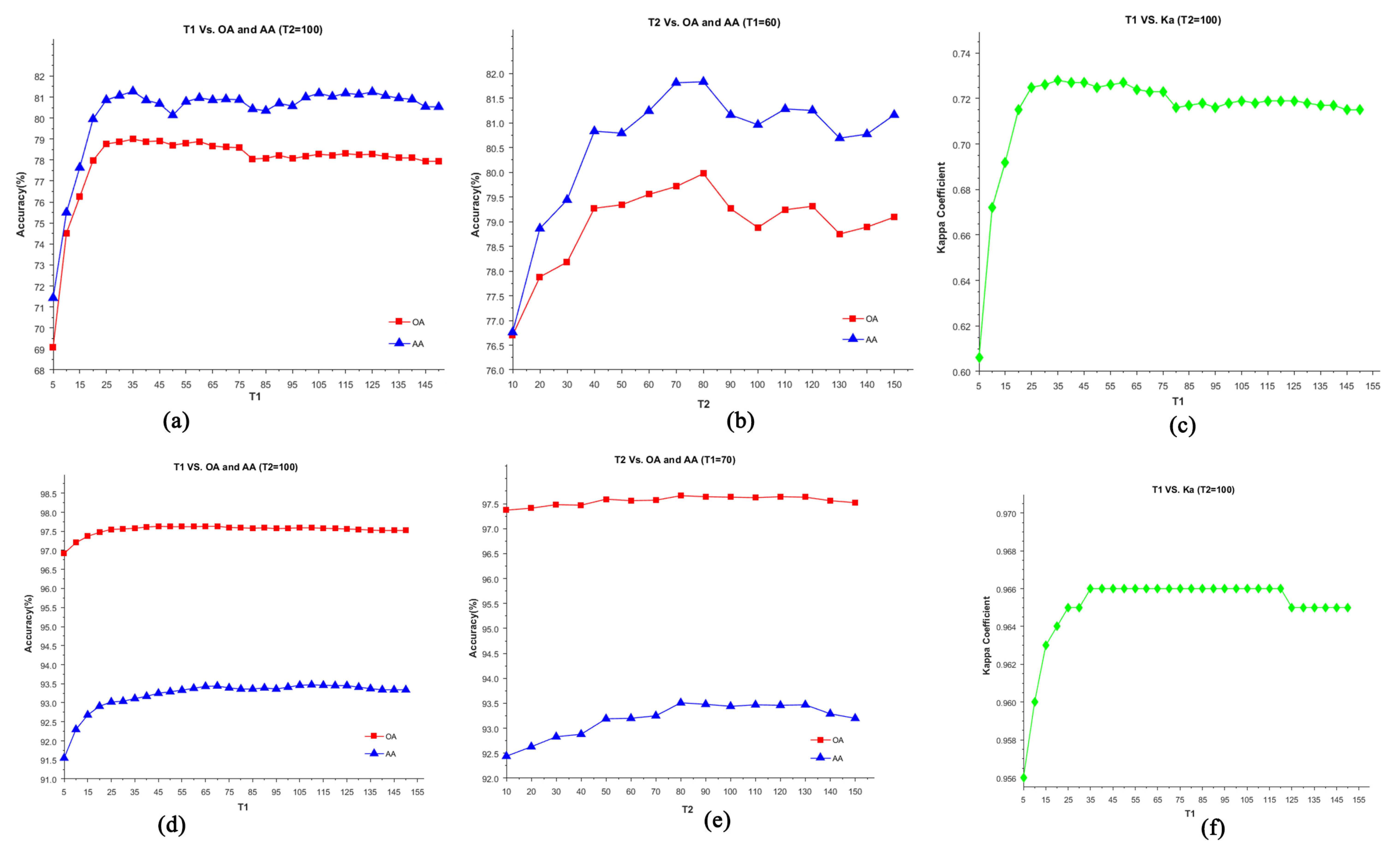
Figure 9.
Relationship between classification maps and parameter settings (T1 and T2) of the proposed D-AMVS method: (a–c) are the relationships between T1, T2, and OA/AA/Ka, respectively, for the Pavia University image, and (d–f) present the relationships between T1, T2, and OA/AA/Ka for the Pavia Center image, respectively.
Figure 9.
Relationship between classification maps and parameter settings (T1 and T2) of the proposed D-AMVS method: (a–c) are the relationships between T1, T2, and OA/AA/Ka, respectively, for the Pavia University image, and (d–f) present the relationships between T1, T2, and OA/AA/Ka for the Pavia Center image, respectively.
Table 1.
Number of training samples and reference data for the Pavia University image.
Table 1.
Number of training samples and reference data for the Pavia University image.
| Class | Training Samples | Test Samples |
|---|
| Asphalt | 603 | 6631 |
| Meadows | 396 | 18,649 |
| Gravel | 182 | 2099 |
| Trees | 382 | 3064 |
| Painted metal | 46 | 1345 |
| Bare soil | 680 | 5029 |
| Bitumen | 189 | 1330 |
| Self-blocking bricks | 414 | 3682 |
| Shadows | 88 | 847 |
Table 2.
Number of training samples and reference data for the Pavia Center image.
Table 2.
Number of training samples and reference data for the Pavia Center image.
| Class | Training Samples | Test Samples |
|---|
| Water | 623 | 65,971 |
| Trees | 336 | 7598 |
| Meadows | 123 | 3090 |
| Bricks | 293 | 2685 |
| Soil | 289 | 6584 |
| Asphalt | 400 | 9248 |
| Bitumen | 221 | 7287 |
| Tiles | 638 | 42,826 |
| Shadows | 379 | 2863 |
Table 3.
Initial classification results acquired by different classifiers for the Pavia University image. OA: overall accuracy, Ka: Kappa coefficient, AA: average accuracies, NN: neural network, MLC: maximum likelihood classification, MD: Mahalanobis distance, SVM: support vector machine.
Table 3.
Initial classification results acquired by different classifiers for the Pavia University image. OA: overall accuracy, Ka: Kappa coefficient, AA: average accuracies, NN: neural network, MLC: maximum likelihood classification, MD: Mahalanobis distance, SVM: support vector machine.
| | NN | MLC | MD | SVM |
|---|
| OA (%) | 47.21 | 67.59 | 53.66 | 60.92 |
| Ka | 0.3824 | 0.5898 | 0.4260 | 0.517 |
| AA (%) | 51.58 | 69.22 | 56.63 | 65.39 |
Table 4.
Comparison of the proposed D-AMVS and different post-classification approaches for the Pavia University image. GPCF: general post-classification framework.
Table 4.
Comparison of the proposed D-AMVS and different post-classification approaches for the Pavia University image. GPCF: general post-classification framework.
| Window Size | Majority Voting | GPCF | Proposed D-AMVS |
|---|
| 3 | 5 | 7 | 9 | 3 | 5 | 7 | 9 | T1 = 60, T2 = 80 |
|---|
| OA (%) | 73.24 | 75.68 | 77.08 | 78.11 | 70.25 | 71.96 | 72.73 | 73.2 | 79.97 |
| Ka | 0.659 | 0.689 | 0.707 | 0.72 | 0.626 | 0.647 | 0.657 | 0.663 | 0.741 |
| AA (%) | 74.63 | 77.26 | 78.81 | 80.08 | 72.48 | 75.47 | 77.38 | 78.46 | 81.83 |
Table 5.
Class-specific user accuracy (%) of the Pavia University image for the different methods.
Table 5.
Class-specific user accuracy (%) of the Pavia University image for the different methods.
| | MLC | MV
| GPCF
| D-AMVs
(T1 = 60, T2 = 80) |
|---|
| Asphalt | 79.0 | 86.2 | 92.9 | 90.9 |
| Meadows | 83.8 | 86.8 | 95.0 | 87.9 |
| Gravel | 44.1 | 64.3 | 78.0 | 89.1 |
| Trees | 61.0 | 66.9 | 52.9 | 60.2 |
| Painted metal | 95.8 | 96.0 | 93.5 | 93.7 |
| Bare soil | 33.0 | 40.7 | 36.1 | 51.3 |
| Bitumen | 54.5 | 72.5 | 67.7 | 82.9 |
| Self-blocking bricks | 74.2 | 82.6 | 73.3 | 80.5 |
| Shadows | 97.5 | 99.4 | 99.8 | 100 |
Table 6.
Initial classified image acquired by different spectral–spatial approaches and the SVM classifier for the Pavia Center image. EMPs: extended morphological profiles, M-EMPs: multi-shape extended morphological profiles, RF: recursive filter, RGF: rolling guidance filter.
Table 6.
Initial classified image acquired by different spectral–spatial approaches and the SVM classifier for the Pavia Center image. EMPs: extended morphological profiles, M-EMPs: multi-shape extended morphological profiles, RF: recursive filter, RGF: rolling guidance filter.
| | EMPs [26] | M-EMPs [25] | RF [28] | RGF [43] |
|---|
| OA (%) | 96.04 | 95.51 | 93.51 | 96.72 |
| Ka | 0.944 | 0.937 | 0.909 | 0.954 |
| AA (%) | 88.82 | 87.2 | 82.25 | 91.06 |
Table 7.
Comparisons of the proposed D-AMVS and different post-classification approaches for the Pavia Center image.
Table 7.
Comparisons of the proposed D-AMVS and different post-classification approaches for the Pavia Center image.
| Window Size | Majority Voting | GPCF | Proposed D-AMVS |
|---|
| 3 | 5 | 7 | 9 | 3 | 5 | 7 | 9 | T1 = 70, T2 = 80 |
|---|
| OA (%) | 96.84 | 96.96 | 97.02 | 97.04 | 97.41 | 97.46 | 97.5 | 97.55 | 97.66 |
| Ka | 0.955 | 0.957 | 0.958 | 0.958 | 0.963 | 0.964 | 0.965 | 0.965 | 0.967 |
| AA (%) | 91.42 | 91.81 | 92.02 | 92.15 | 92.47 | 92.63 | 92.84 | 93.09 | 93.51 |
Table 8.
Class-specific user accuracy of the Pavia Center image for the different methods.
Table 8.
Class-specific user accuracy of the Pavia Center image for the different methods.
| | RGF [43] | Majority Voting
| GPCF
| D-AMVS
(T1 = 70, T2 = 80) |
|---|
| Water | 99.2 | 99.1 | 99.6 | 99.7 |
| Trees | 97.5 | 97.3 | 98.6 | 97.7 |
| Meadows | 88.8 | 89.7 | 88.0 | 91.5 |
| Bricks | 66.0 | 67.8 | 67.1 | 71.0 |
| Soil | 89.1 | 91.9 | 97.9 | 97.7 |
| Asphalt | 86.4 | 86.8 | 88.1 | 88.8 |
| Bitumen | 93.2 | 94.3 | 95.8 | 98.0 |
| Tiles | 99.9 | 99.9 | 99.7 | 99.3 |
| Shadows | 99.5 | 99.6 | 98.8 | 98.0 |
Table 9.
Error estimation among the different methods for the Pavia Center image data.
Table 9.
Error estimation among the different methods for the Pavia Center image data.
| | D-AMVS |
|---|
| OA (%) | Kappa | AA (%) |
|---|
| RGF | 0.94 | 0.013 | 2.45 |
| Majority Voting | 0.82 | 0.012 | 2.09 |
| GPCF | 0.25 | 0.004 | 1.04 |
Table 10.
Error estimation between the proposed D-AMVS and majority voting approach in terms of user accuracy for the Pavia Center image data.
Table 10.
Error estimation between the proposed D-AMVS and majority voting approach in terms of user accuracy for the Pavia Center image data.
| | D-AMVS (T1 = 70, T2 = 80) |
|---|
| Water | Trees | Meadows | Bricks | Soil | Asphalt | Bitumen | Tiles | Shadow |
|---|
Majority Voting
() | Water | 246 | 0 | 0 | 0 | 0 | −246 | 0 | 0 | 0 |
| Trees | −53 | 22 | −62 | 0 | 5 | 27 | 0 | 29 | 32 |
| Meadows | −23 | 17 | −17 | 0 | 0 | 8 | −4 | 10 | 9 |
| Bricks | 0 | 0 | 0 | 269 | −263 | 4 | −10 | 0 | 0 |
| Soil | 0 | −1 | 0 | 191 | −176 | −4 | −12 | 0 | 0 |
| Asphalt | −93 | 0 | 0 | 6 | 2 | 311 | −230 | 4 | 0 |
| Bitumen | −11 | 0 | 0 | −243 | 15 | 19 | 209 | 11 | 0 |
| Tiles | −6 | −23 | 0 | 4 | −142 | −11 | 0 | 178 | 0 |
| Shadows | −192 | −21 | 0 | 0 | 0 | 16 | 0 | 203 | −6 |
| User accuracy error (%) | 0.6 | 0.4 | 1.8 | 3.2 | 5.8 | 2 | 3.7 | −0.6 | −1.6 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}