Deep&Dense Convolutional Neural Network for Hyperspectral Image Classification




Abstract
1. Introduction
1.1. Hyperspectral Imaging Concept and Missions
1.2. Hyperspectral Image Classification
1.3. Deep Neural Networks for Hyperspectral Image Classification
1.4. Convolutional Neural Networks and Their Limitations in Hyperspectral Image Classification
- The forward pass, where data is passed through the network until it reaches the final layer, whose output is used to calculate an optimization or cost function (normally the difference between all the desired outputs and the obtained ones , calculated as the cross-entropy of the data )—normally optimized by a stochastic gradient descent method.
- The backward pass, where the obtained gradient signal must be backpropagated through the network in order to ensure that the model’s parameters are properly updated. However, this gradient fades slightly as it passes through each layer of the CNN, which in very deep networks produces its practical disappearance or vanishing. As result, the accuracy of the deep CNNs is saturated and degrades rapidly. To avoid this problem, models implement their optimizer with a really small learning rate, making the training more reliable but forcing the gradient to perform many small steps until convergence.
1.5. Contributions of This Work
- It exploits the rich and diverse amount of information contained in HSI data, integrating the spectral and the spatial-contextual information in the classification process by analyzing, for each sample, its full spectrum and surrounding neighborhood.
- It improves the network generalization while avoiding the vanishing of the model gradient.
- It combines both low-level and high-level features in the classification process. This is done by concatenating the output volume of each convolutional layer with the corresponding inputs of the subsequent high-level layers , , ⋯, .
- It can perform properly in the presence of limited training samples, as will be shown in our experimental assessment.
2. Methodology
2.1. Classification of Hyperspectral Images Using Traditional Neural Networks
2.2. Classification of Hyperspectral Images Using Convolutional Neural Networks
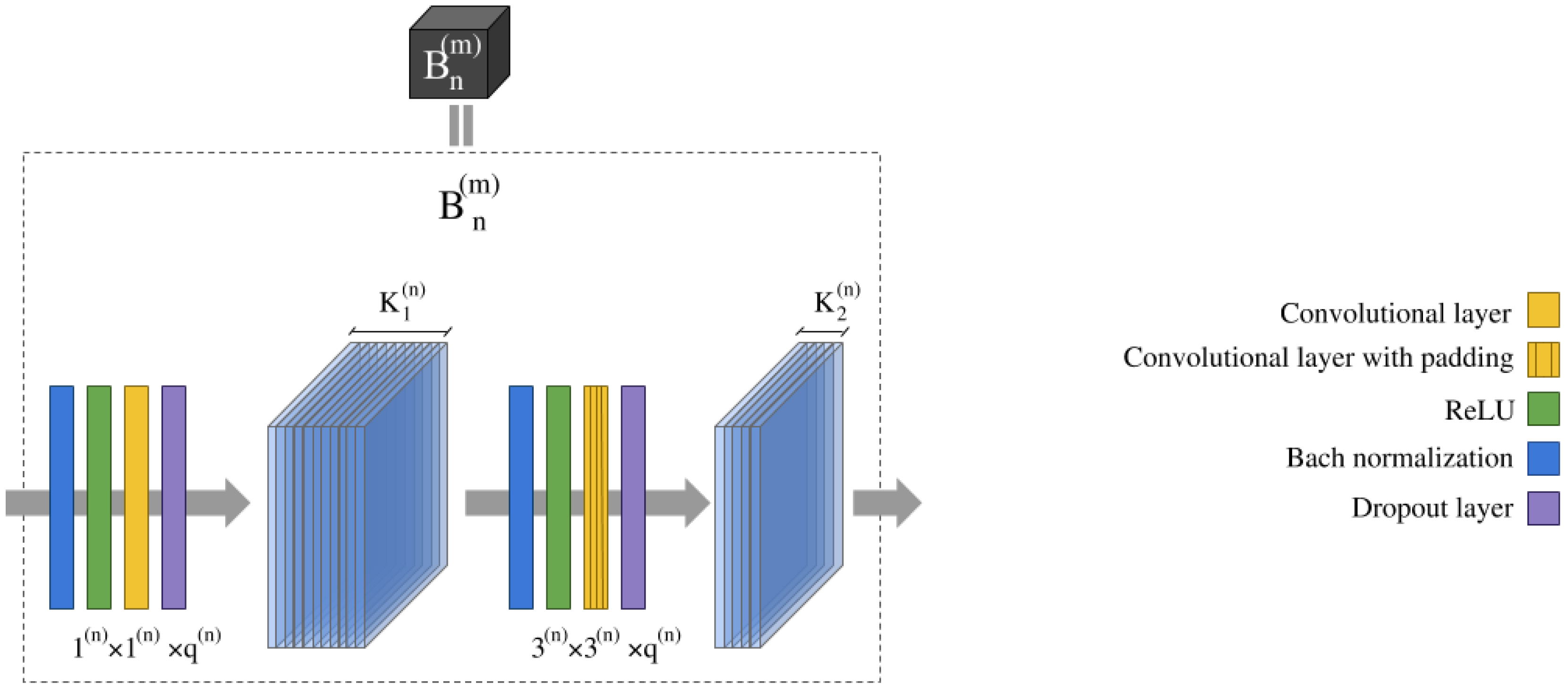
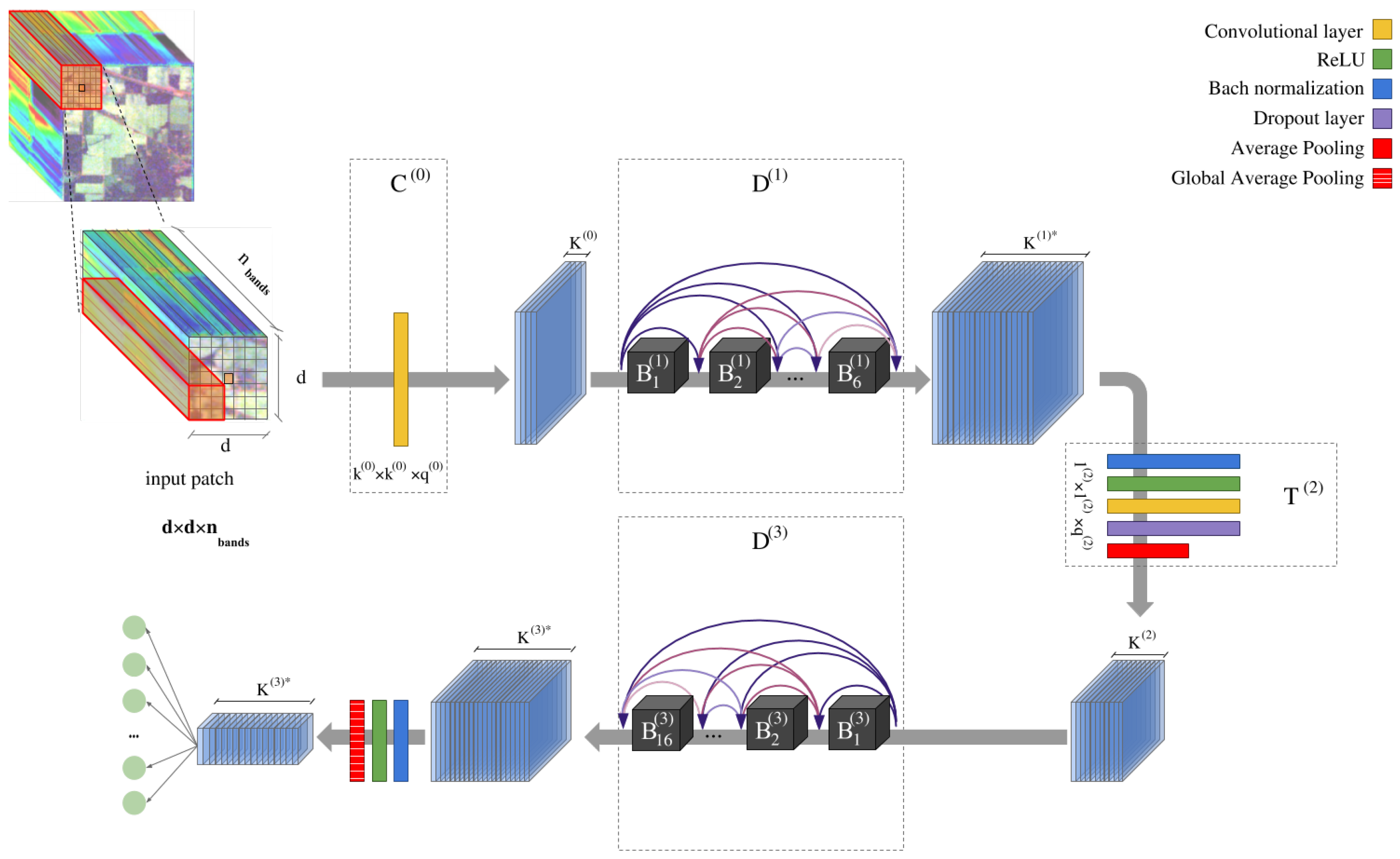
2.3. Proposed Deep&Dense Architecture for Hyperspectral Image Classification
3. Experimental Results and Discussion
3.1. Experimental Settings
3.2. Hyperspectral Datasets
- Indian Pines (IP): It was gathered by the AVIRIS sensor [2] in Northwestern Indiana (United States), capturing a set of agricultural fields. This HSI scene contains pixels of 224 spectral bands in the wavelength range 0.4–2.45 m, with spectral and spatial resolution of 0.01 m and 20 m per pixel (mpp). For experimental purposes, 200 spectral bands have been selected, removing 4 and 20 spectral bands due to noise and water absorption, respectively. About half of the data (10,249 pixels from a total of 21,025) are labeled into 16 different classes.
- University of Pavia (UP): It was captured by the ROSIS sensor [3] University of Pavia campus, located in northern Italy. In this case, the HSI dataset comprises pixels with 103 spectral bands, after discarding certain noisy bands. The remaining bands cover the range 0.43–0.86 m, with spatial resolution of 1.3 mpp. The available ground-truth information comprises about 20% of the pixels (42,776 of 207,400), labeled into 9 different classes.
- Salinas Valley (SV): It was acquired by the AVIRIS sensor over an agricultural area in the Salinas Valley, California (United States). The HSI dataset is composed by pixels with 204 spectral bands after discarding of 20 water absorption bands, i.e., [108–112], [154–167] and 224. The spatial resolution is 3.7 mpp, while the ground-truth is composed by 16 different classes including vegetables, bare soils, and vineyard fields.
- Kennedy Space Center (KSC): It was also collected by the AVIRIS instrument over the Kennedy Space Center in Florida (United States). It is composed by pixels with 176 spectral bands after discarding noisy bands. The remaining bands cover the spectral range 0.4–2.5 m, with spatial resolution of 20 mpp. The dataset contains a total of 5122 ground-truth pixels labeled in 13 different classes.
3.3. Results and Discussion
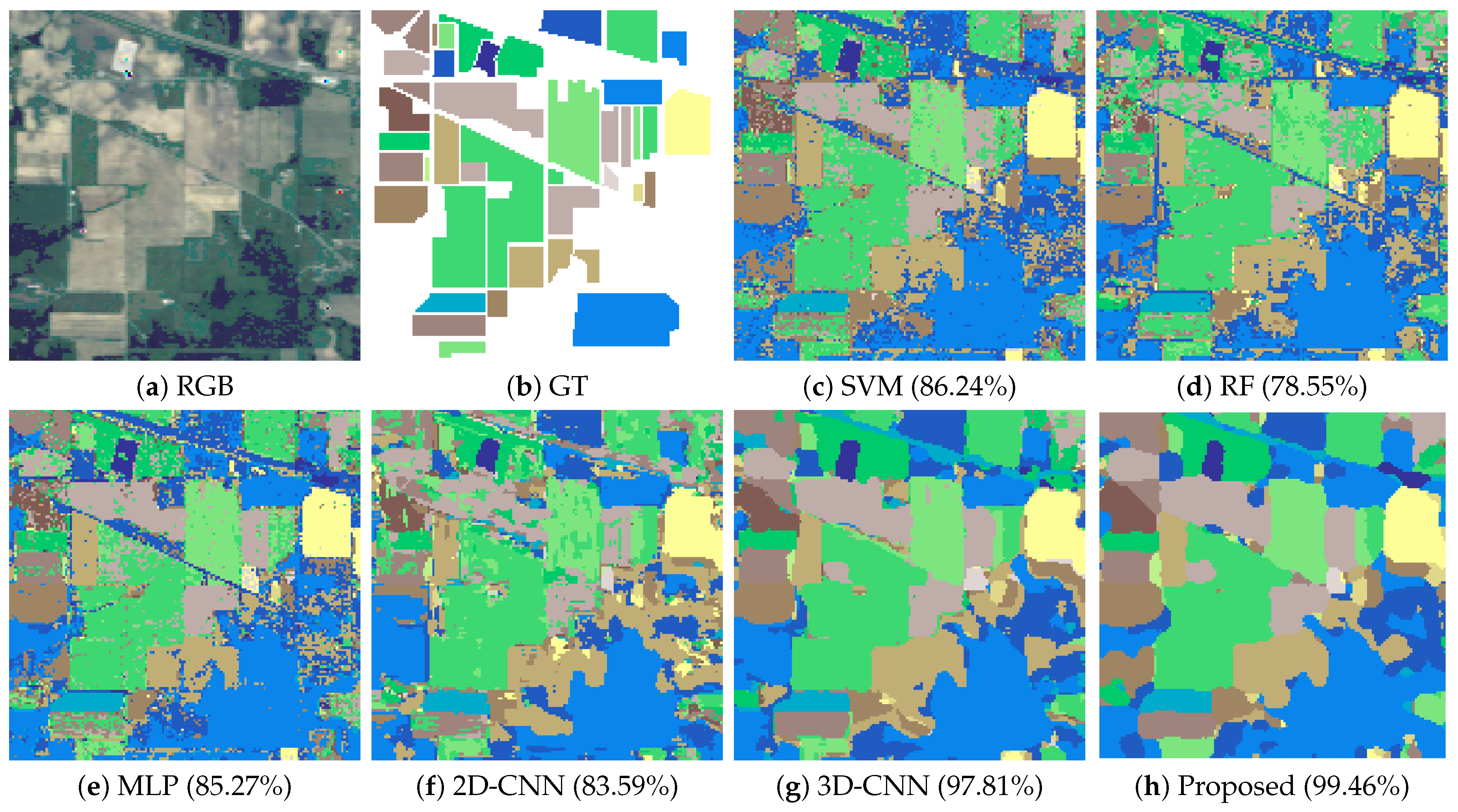
3.3.1. Experiment 1: Comparison between the Proposed Model and Standard HSI Classifiers
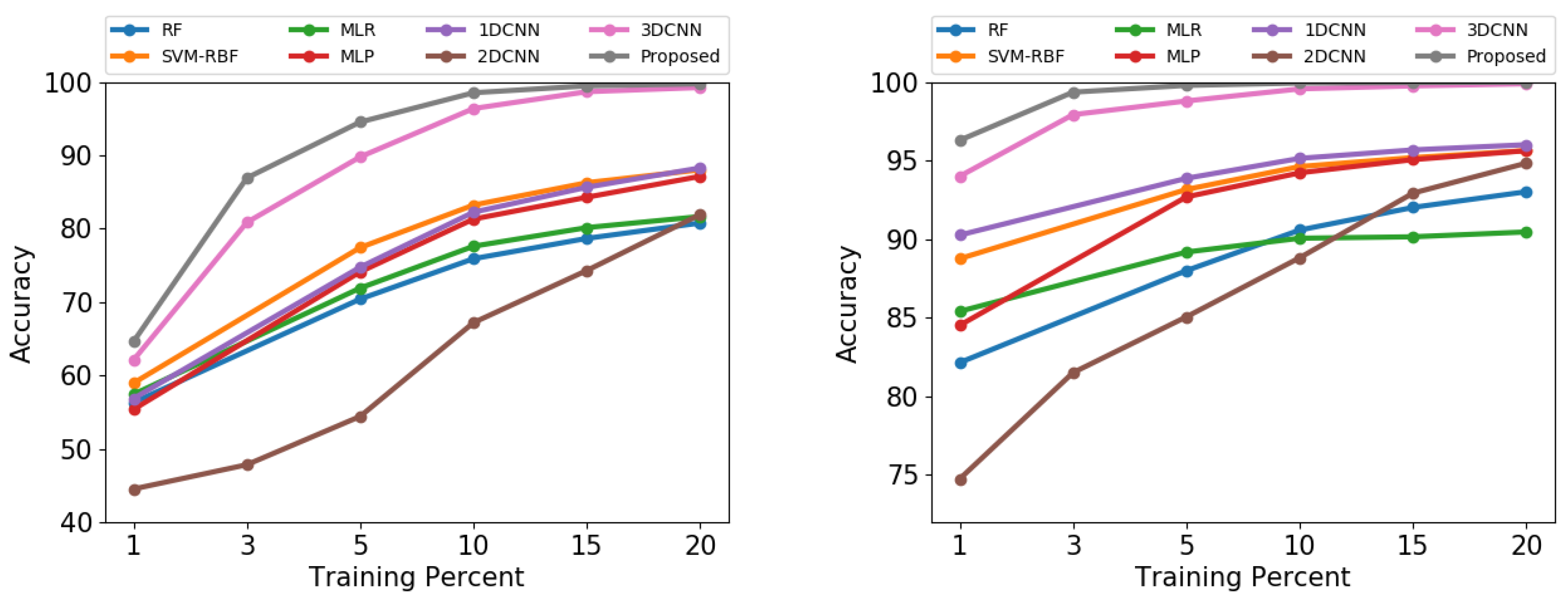
3.3.2. Experiment 2: Sensitivity of the Proposed Model to the Number of Available Labeled Samples
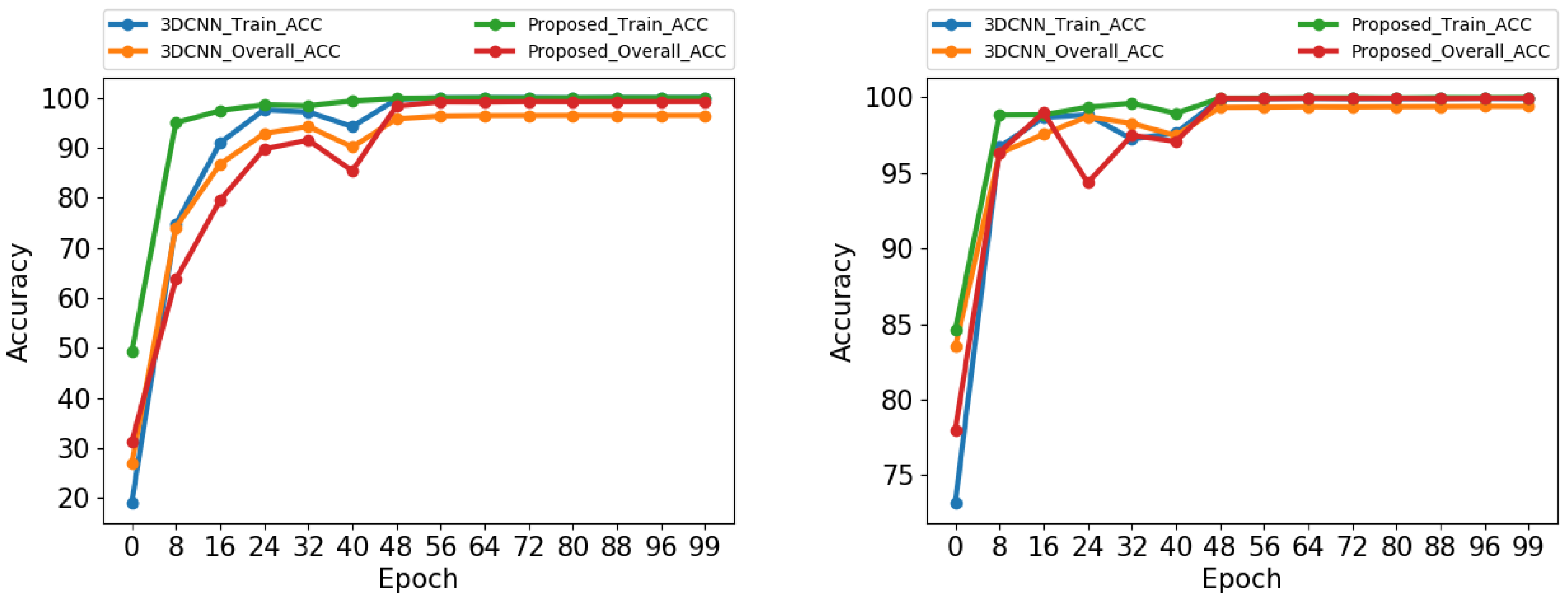
3.3.3. Experiment 3: Deep&Dense Model Learning Procedure
3.3.4. Experiment 4: Comparison between the Proposed Deep&Dense Model and Fast Convolutional Neural Networks for HSI Data Classification
3.3.5. Experiment 5: Comparison between the Proposed Deep&Dense Model and Spectral-Spatial Residual Networks for HSI Data Classification
4. Conclusions and Future Lines
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vorovencii, I. The Hyperspectral Sensors used in Satellite and Aerial Remote Sensing. Bull. Transilvania Univ. Braşov 2009, 2, 51–56. [Google Scholar]
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Kunkel, B.; Blechinger, F.; Lutz, R.; Doerffer, R.; van der Piepen, H.; Schroder, M. ROSIS (Reflective Optics System Imaging Spectrometer)—A candidate instrument for polar platform missions. In Optoelectronic Technologies for Remote Sensing From Space, Proceedings of the 1987 Symposium on the Technologies for Optoelectronics, Cannes, France, 19–20 November 1987; Seeley, J., Bowyer, S., Eds.; SPIE: Bellingham, WA, USA, 1988; p. 8. [Google Scholar] [CrossRef]
- Nischan, M.L.; Kerekes, J.P.; Baum, J.E.; Basedow, R.W. Analysis of HYDICE noise characteristics and their impact on subpixel object detection. SPIE Proc. 1999, 3753. [Google Scholar] [CrossRef]
- Bucher, T.; Lehmann, F. Fusion of HyMap hyperspectral with HRSC-A multispectral and DEM data for geoscientific and environmental applications. In Proceedings of the IEEE 2000 International Geoscience and Remote Sensing Symposium Taking the Pulse of the Planet: The Role of Remote Sensing in Managing the Environment (IGARSS 2000), Honolulu, HI, USA, 24–28 July 2000; Volume 7, pp. 3234–3236. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gomez-Chova, L.; Calpe-Maravilla, J.; Martin-Guerrero, J.D.; Soria-Olivas, E.; Alonso-Chorda, L.; Moreno, J. Robust support vector method for hyperspectral data classification and knowledge discovery. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1530–1542. [Google Scholar] [CrossRef]
- Bannari, A.; Staenz, K. Hyperspectral chlorophyll indices sensitivity analysis to soil backgrounds in agrirultural aplications using field, Probe-1 and Hyperion data. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 7129–7132. [Google Scholar] [CrossRef]
- Chen, J.M.; Leblanc, S.G.; Miller, J.R.; Freemantle, J.; Loechel, S.E.; Walthall, C.L.; Innanen, K.A.; Whit, H.P. Compact Airborne Spectrographic Imager (CASI) used for mapping biophysical parameters of boreal forests. J. Geophys. Res. Atmos. 1999, 104, 27945–27958. [Google Scholar] [CrossRef]
- Xu, Q.; Liu, S.; Ye, F.; Zhang, Z.; Zhang, C. Application of CASI/SASI and fieldspec4 hyperspectral data in exploration of the Baiyanghe uranium deposit, Hebukesaier, Xinjiang, NW China. Int. J. Remote Sens. 2018, 39, 453–469. [Google Scholar] [CrossRef]
- Achal, S.; McFee, J.E.; Ivanco, T.; Anger, C. A thermal infrared hyperspectral imager (tasi) for buried landmine detection. SPIE Proc. 2007, 6553, 655316. [Google Scholar] [CrossRef]
- Pearlman, J.; Carman, S.; Segal, C.; Jarecke, P.; Clancy, P.; Browne, W. Overview of the Hyperion Imaging Spectrometer for the NASA EO-1 mission. In Proceedings of the IEEE 2001 International Geoscience and Remote Sensing Symposium on Scanning the Present and Resolving the Future (IGARSS 2001), Sydney, Australia, 9–13 July 2001; Volume 7, pp. 3036–3038. [Google Scholar] [CrossRef]
- Pearlman, J.S.; Barry, P.S.; Segal, C.C.; Shepanski, J.; Beiso, D.; Carman, S.L. Hyperion, a space-based imaging spectrometer. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1160–1173. [Google Scholar] [CrossRef]
- Cheng, Y.B.; Ustin, S.L.; Riaño, D.; Vanderbilt, V.C. Water content estimation from hyperspectral images and MODIS indexes in Southeastern Arizona. Remote Sens. Environ. 2008, 112, 363–374. [Google Scholar] [CrossRef]
- Yarbrough, S.; Caudill, T.R.; Kouba, E.T.; Osweiler, V.; Arnold, J.; Quarles, R.; Russell, J.; Otten, L.J.; Jones, B.A.; Edwards, A.; et al. MightySat II. 1 Hyperspectral imager: Summary of on-orbit performance. SPIE Proc. 2002, 4480, 12. [Google Scholar] [CrossRef]
- Duca, R.; Frate, F.D. Hyperspectral and Multiangle CHRIS–PROBA Images for the Generation of Land Cover Maps. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2857–2866. [Google Scholar] [CrossRef]
- Kaufmann, H.; Guanter, L.; Segl, K.; Hofer, S.; Foerster, K.P.; Stuffler, T.; Mueller, A.; Richter, R.; Bach, H.; Hostert, P. Environmental Mapping and Analysis Program (EnMAP)—Recent Advances and Status. IEEE Int. Geosci. Remote Sens. Symp. IGARSS 2008, 4, 109–112. [Google Scholar]
- Galeazzi, C.; Sacchetti, A.; Cisbani, A.; Babini, G. The PRISMA Program. In Proceedings of the IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 6–11 July 2008; pp. IV-105–IV-108. [Google Scholar] [CrossRef]
- Tal, F.; Ben, D. SHALOM—A Commercial Hyperspectral Space Mission. In Optical Payloads for Space Missions; Wiley-Blackwell: New York, NY, USA, 2015; Chapter 11; pp. 247–263. [Google Scholar] [CrossRef]
- Abrams, M.J.; Hook, S.J. NASA’s Hyperspectral Infrared Imager (HyspIRI). In Thermal Infrared Remote Sensing: Sensors, Methods, Applications; Kuenzer, C., Dech, S., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 117–130. [Google Scholar] [CrossRef]
- Iwasaki, A.; Ohgi, N.; Tanii, J.; Kawashima, T.; Inada, H. Hyperspectral Imager Suite (HISUI)—Japanese hyper-multi spectral radiometer. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 1025–1028. [Google Scholar] [CrossRef]
- Haut, J.; Paoletti, M.; Plaza, J.; Plaza, A. Cloud implementation of the K-means algorithm for hyperspectral image analysis. J. Supercomput. 2017, 73. [Google Scholar] [CrossRef]
- Molero, J.M.; Paz, A.; Garzón, E.M.; Martínez, J.A.; Plaza, A.; García, I. Fast anomaly detection in hyperspectral images with RX method on heterogeneous clusters. J. Supercomput. 2011, 58, 411–419. [Google Scholar] [CrossRef]
- Sevilla, J.; Plaza, A. A New Digital Repository for Hyperspectral Imagery With Unmixing-Based Retrieval Functionality Implemented on GPUs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2267–2280. [Google Scholar] [CrossRef]
- Goetz, A.F.H.; Vane, G.; Solomon, J.E.; Rock, B.N. Imaging Spectrometry for Earth Remote Sensing. Science 1985, 228, 1147–1153. [Google Scholar] [CrossRef] [PubMed]
- Falco, N. Advanced Spectral and Spatial Techniques for Hyperspectral Image Analysis and Classification. Ph.D. Thesis, Information and Communication Technology, University of Trento, Trento, Italy, University of Iceland, Reykjavík, Iceland, 2015. [Google Scholar]
- Plaza, A.; Plaza, J.; Paz, A.; Sanchez, S. Parallel Hyperspectral Image and Signal Processing [Applications Corner]. IEEE Signal Proc. Mag. 2011, 28, 119–126. [Google Scholar] [CrossRef]
- Teke, M.; Deveci, H.S.; Haliloğlu, O.; Zübeyde Gürbüz, S.; Sakarya, U. A Short Survey of Hyperspectral Remote Sensing Applications in Agriculture. In Proceedings of the 2013 6th International Conference on Recent Advances in Space Technologies (RAST), Istanbul, Turkey, 12–14 June 2013. [Google Scholar] [CrossRef]
- Lu, X.; Li, X.; Mou, L. Semi-Supervised Multitask Learning for Scene Recognition. IEEE Trans. Cybern. 2015, 45, 1967–1976. [Google Scholar] [CrossRef] [PubMed]
- Ghamisi, P.; Plaza, J.; Chen, Y.; Li, J.; Plaza, A. Advanced Spectral Classifiers for Hyperspectral Images: A Review. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–32. [Google Scholar] [CrossRef]
- Chutia, D.; Bhattacharyya, D.K.; Sarma, K.K.; Kalita, R.; Sudhakar, S. Hyperspectral Remote Sensing Classifications: A Perspective Survey. Trans. GIS 2016, 20, 463–490. [Google Scholar] [CrossRef]
- Plaza, A.; Du, Q.; Chang, Y.L.; King, R.L. High Performance Computing for Hyperspectral Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 528–544. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Lopez, S.; Vladimirova, T.; Gonzalez, C.; Resano, J.; Mozos, D.; Plaza, A. The Promise of Reconfigurable Computing for Hyperspectral Imaging Onboard Systems: A Review and Trends. Proc. IEEE 2013, 101, 698–722. [Google Scholar] [CrossRef]
- Heylen, R.; Parente, M.; Gader, P. A Review of Nonlinear Hyperspectral Unmixing Methods. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1844–1868. [Google Scholar] [CrossRef]
- Matteoli, S.; Diani, M.; Theiler, J. An Overview of Background Modeling for Detection of Targets and Anomalies in Hyperspectral Remotely Sensed Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2317–2336. [Google Scholar] [CrossRef]
- Frontera-Pons, J.; Veganzones, M.A.; Pascal, F.; Ovarlez, J.P. Hyperspectral Anomaly Detectors Using Robust Estimators. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 720–731. [Google Scholar] [CrossRef]
- Poojary, N.; D’Souza, H.; Puttaswamy, M.R.; Kumar, G.H. Automatic target detection in hyperspectral image processing: A review of algorithms. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 1991–1996. [Google Scholar] [CrossRef]
- Zhao, C.; Li, X.; Ren, J.; Marshall, S. Improved sparse representation using adaptive spatial support for effective target detection in hyperspectral imagery. Int. J. Remote Sens. 2013, 34, 8669–8684. [Google Scholar] [CrossRef]
- Landgrebe, D.A. Pattern Recognition in Remote Sensing. In Signal Theory Methods in Multispectral Remote Sensing; Wiley-Blackwell: New York, NY, USA, 2005; pp. 91–192. ISBN 9780471723806. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Ghamisi, P.; Yokoya, N.; Li, J.; Liao, W.; Liu, S.; Plaza, J.; Rasti, B.; Plaza, A. Advances in Hyperspectral Image and Signal Processing: A Comprehensive Overview of the State of the Art. IEEE Geosci. Remote Sens. Mag. 2017, 5, 37–78. [Google Scholar] [CrossRef]
- Cariou, C.; Chehdi, K. Unsupervised Nearest Neighbors Clustering With Application to Hyperspectral Images. IEEE J. Sel. Top. Signal Proc. 2015, 9, 1105–1116. [Google Scholar] [CrossRef]
- Abbas, A.W.; Minallh, N.; Ahmad, N.; Abid, S.A.R.; Khan, M.A.A. K-Means and ISODATA Clustering Algorithms for Land cover Classification Using Remote Sensing. Sindh Univ. Res. J. (Sci. Ser.) 2016, 48, 315–318. [Google Scholar]
- El-Rahman, S.A. Hyperspectral imaging classification using ISODATA algorithm: Big data challenge. In Proceedings of the 2015 Fifth International Conference on e-Learning (econf), Manama, Bahrain, 18–20 October 2015; pp. 247–250. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Q.; Liu, H.; Wang, Y.; Zhu, J. An improved ISODATA algorithm for hyperspectral image classification. In Proceedings of the 2014 7th International Congress on Image and Signal Processing, Dailan, China, 14–16 October 2014; pp. 660–664. [Google Scholar] [CrossRef]
- Goel, P.; Prasher, S.; Patel, R.; Landry, J.; Bonnell, R.; Viau, A. Classification of hyperspectral data by decision trees and artificial neural networks to identify weed stress and nitrogen status of corn. Comput. Electron. Agric. 2003, 39, 67–93. [Google Scholar] [CrossRef]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef]
- Joelsson, S.R.; Benediktsson, J.A.; Sveinsson, J.R. Random forest classifiers for hyperspectral data. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium (IGARSS’05), Seoul, Korea, 29 July 2005; Volume 1, p. 4. [Google Scholar] [CrossRef]
- Haut, J.; Paoletti, M.; Paz-Gallardo, A.; Plaza, J.; Plaza, A. Cloud implementation of logistic regression for hyperspectral image classification. In Proceedings of the 17th International Conference on Computational and Mathematical Methods in Science and Engineering (CMMSE 2017), Cadiz, Spain, 4–July 2017; Vigo-Aguiar, J., Ed.; pp. 1063–2321, ISBN 978-84-617-8694-7. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogram. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Landgrebe, D. Signal Theory Methods in Multispectral Remote Sensing; Wiley Series in Remote Sensing and Image Processing; Wiley: New York, NY, USA, 2005. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Plaza, A.; Benediktsson, J.A.; Boardman, J.W.; Brazile, J.; Bruzzone, L.; Camps-Valls, G.; Chanussot, J.; Fauvel, M.; Gamba, P.; Gualtieri, A.; et al. Recent advances in techniques for hyperspectral image processing. Remote Sens. Environ. 2009, 113, S110–S122. [Google Scholar] [CrossRef]
- Gurram, P.; Kwon, H. Optimal sparse kernel learning in the Empirical Kernel Feature Space for hyperspectral classification. In Proceedings of the 2012 4th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Shanghai, China, 4–7 June 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Plaza, A. Fast dimensionality reduction and classification of hyperspectral images with extreme learning machines. J. Real-Time Image Proc. 2018. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Donoho, D.L. High-dimensional data analysis: The curses and blessings of dimensionality. In Proceedings of the AMS Conference on Math Challenges of the 21st Century, Los Angeles, CA, USA, 7–12 August 2000. [Google Scholar]
- Ma, W.; Gong, C.; Hu, Y.; Meng, P.; Xu, F. The Hughes phenomenon in hyperspectral classification based on the ground spectrum of grasslands in the region around Qinghai Lake. In Proceedings of the International Symposium on Photoelectronic Detection and Imaging 2013: Imaging Spectrometer Technologies and Applications, Beijing, China, 25–27 June 2013; Volume 8910. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemometr. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Fernandez, D.; Gonzalez, C.; Mozos, D.; Lopez, S. FPGA implementation of the principal component analysis algorithm for dimensionality reduction of hyperspectral images. J. Real-Time Image Proc. 2016, 1–12. [Google Scholar] [CrossRef]
- Villa, A.; Chanussot, J.; Jutten, C.; Benediktsson, J.A.; Moussaoui, S. On the use of ICA for hyperspectral image analysis. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 4, pp. IV-97–IV-100. [Google Scholar] [CrossRef]
- Iyer, R.P.; Raveendran, A.; Bhuvana, S.K.T.; Kavitha, R. Hyperspectral image analysis techniques on remote sensing. In Proceedings of the 2017 Third International Conference on Sensing, Signal Processing and Security (ICSSS), Chennai, India, 4–5 May 2017; pp. 392–396. [Google Scholar] [CrossRef]
- Gao, L.; Zhang, B.; Sun, X.; Li, S.; Du, Q.; Wu, C. Optimized maximum noise fraction for dimensionality reduction of Chinese HJ-1A hyperspectral data. EURASIP J. Adv. Signal Proc. 2013, 2013, 65. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, L.; Li, J.; Wang, Q.; Sun, L.; Wei, Z.; Plaza, J.; Plaza, A. GPU Parallel Implementation of Spatially Adaptive Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1131–1143. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Swain, P.H.; States, U. Statistical Methods and Neural Network Approaches For Classification of Data From Multiple Sources; Laboratory for Applications of Remote Sensing, School of Electrical Engineering, Purdue University: West Lafayette, IN, USA, 1990. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications. Found. Trends Signal Proc. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. A new deep convolutional neural network for fast hyperspectral image classification. ISPRS J. Photogram. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing Data Reconstruction in Remote Sensing Image With a Unified Spatial-Temporal-Spectral Deep Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature Extraction With Multiscale Covariance Maps for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 1–15. [Google Scholar] [CrossRef]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training Very Deep Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2015; pp. 2377–2385. [Google Scholar]
- Yu, D.; Seltzer, M.L.; Li, J.; Huang, J.; Seide, F. Feature Learning in Deep Neural Networks—A Study on Speech Recognition Tasks. arXiv, 2013; arXiv:1301.3605. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features From Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2012. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Teh, Y.W., Titterington, M., Eds.; PMLR: Chia Laguna Resort, Sardinia, Italy, 2010; Volume 9, pp. 249–256. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification With Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2014; pp. 3320–3328. [Google Scholar]
- Caruana, R.; Lawrence, S.; Giles, C.L. Overfitting in Neural Nets: Backpropagation, Conjugate Gradient, and Early Stopping. In Advances in Neural Information Processing Systems 13; Leen, T.K., Dietterich, T.G., Tresp, V., Eds.; MIT Press: Cambridge, MA, USA, 2001; pp. 402–408. [Google Scholar]
- Cogswell, M.; Ahmed, F.; Girshick, R.; Zitnick, L.; Batra, D. Reducing overfitting in deep networks by decorrelating representations. arXiv, 2015; arXiv:1511.06068. [Google Scholar]
- Acquarelli, J.; Marchiori, E.; Buydens, L.M.C.; Tran, T.; Van Laarhoven, T. Convolutional Neural Networks and Data Augmentation for Spectral-Spatial Classification of Hyperspectral Images. arXiv, 2017; arXiv:1711.05512. [Google Scholar]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Li, J.; Plaza, A. Active Learning With Convolutional Neural Networks for Hyperspectral Image Classification Using a New Bayesian Approach. IEEE Trans. Geosci. Remote Sens. 2018, 1–22. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Koturwar, S.; Merchant, S. Weight Initialization of Deep Neural Networks(DNNs) using Data Statistics. arXiv, 2017; arXiv:1710.10570. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Manzagol, P.A.; Vincent, P.; Bengio, S. Why Does Unsupervised Pre-training Help Deep Learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv, 2015; arXiv:1502.01852. [Google Scholar]
- Pedamonti, D. Comparison of non-linear activation functions for deep neural networks on MNIST classification task. arXiv, 2018; arXiv:1804.02763. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. arXiv, 2017; arXiv:1706.02515. [Google Scholar]
- Martens, J.; Sutskever, I. Training Deep and Recurrent Networks with Hessian-Free Optimization. In Neural Networks: Tricks of the Trade, 2nd ed.; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 479–535. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, Georgia, USA, 16–21 June 2013; Dasgupta, S., McAllester, D., Eds.; PMLR: Atlanta, Georgia, USA, 2013; Volume 28, pp. 1139–1147. [Google Scholar]
- Dauphin, Y.; Pascanu, R.; Gülçehre, Ç.; Cho, K.; Ganguli, S.; Bengio, Y. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. arXiv, 2014; arXiv:1406.2572. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv, 2013; arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv, 2014; arXiv:1409.4842. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the Accuracy of Multispectral Image Pansharpening by Learning a Deep Residual Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv, 2016; arXiv:1611.05431. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. A New Deep Generative Network for Unsupervised Remote Sensing Single-Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2018. [Google Scholar] [CrossRef]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in Resnet: Generalizing Residual Architectures. arXiv, 2016; arXiv:1603.08029. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks without Residuals. arXiv, 2016; arXiv:1605.07648. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks. arXiv, 2015; arXiv:1505.00387. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Schmidhuber, J. Highway and Residual Networks learn Unrolled Iterative Estimation. arXiv, 2016; arXiv:1612.07771. [Google Scholar]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Unsupervised Spectral-Spatial Feature Learning via Deep Residual Conv-Deconv Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 391–406. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Contextual deep CNN based hyperspectral classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 3322–3325. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Going Deeper With Contextual CNN for Hyperspectral Image Classification. IEEE Trans. Image Proc. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Proc. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv, 2016; arXiv:1608.06993. [Google Scholar]
- Merényi, E.; Farrand, W.H.; Taranik, J.V.; Minor, T.B. Classification of hyperspectral imagery with neural networks: comparison to conventional tools. EURASIP J. Adv. Signal Proc. 2014, 2014, 71. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10); Fürnkranz, J., Joachims, T., Eds.; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Kingma, D.P.; Ba, J. ADAM: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 10 September 2018).
- Waske, B.; van der Linden, S.; Benediktsson, J.A.; Rabe, A.; Hostert, P. Sensitivity of support vector machines to random feature selection in classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2880–2889. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Convolutional Layer | |
| kernels = , | |
| First dense block | |
| kernels = with , , ReLU, dropout = | |
| Transition layer | |
| kernels = , with , , ReLU, dropout = | |
| Average Pooling , | |
| Second dense block | |
| kernels = with , , ReLU, dropout = | |
| Classification layers | |
| ReLU, Global Average Pooling with output , with | |
| Fully connected of layers, with softmax | |

| Class | SVM | RF | MLP | 2D-CNN | 3D-CNN | Proposed |
|---|---|---|---|---|---|---|
| 1 | 68.04 ± 6.95 | 33.04 ± 7.45 | 62.39 ± 13.96 | 65.87 ± 10.34 | 89.13 ± 7.28 | 93.91 ± 4.64 |
| 2 | 83.55 ± 1.31 | 66.68 ± 1.67 | 83.84 ± 2.46 | 81.04 ± 3.28 | 98.33 ± 0.71 | 99.38 ± 0.44 |
| 3 | 73.82 ± 1.44 | 56.20 ± 2.41 | 76.37 ± 5.03 | 79.07 ± 6.75 | 98.05 ± 1.40 | 99.4 ± 0.31 |
| 4 | 71.98 ± 3.86 | 41.10 ± 2.50 | 68.35 ± 6.12 | 82.70 ± 8.34 | 98.23 ± 0.62 | 99.49 ± 0.62 |
| 5 | 94.29 ± 0.97 | 87.12 ± 1.73 | 90.87 ± 2.09 | 69.25 ± 10.58 | 97.56 ± 2.84 | 98.84 ± 0.59 |
| 6 | 97.32 ± 0.97 | 95.32 ± 1.79 | 96.95 ± 1.10 | 88.29 ± 5.51 | 98.93 ± 1.14 | 99.84 ± 0.16 |
| 7 | 88.21 ± 5.06 | 32.86 ± 12.66 | 78.21 ± 10.28 | 67.86 ± 25.65 | 83.57 ± 19.51 | 99.29 ± 1.43 |
| 8 | 98.16 ± 0.75 | 98.49 ± 0.81 | 98.08 ± 0.90 | 96.26 ± 1.60 | 99.41 ± 0.61 | 99.96 ± 0.08 |
| 9 | 52.00 ± 8.43 | 13.00 ± 3.32 | 72.00 ± 8.12 | 67.00 ± 27.68 | 65.00 ± 21.68 | 100.0 ± 0.0 |
| 10 | 79.49 ± 2.76 | 69.95 ± 4.31 | 82.17 ± 5.41 | 68.82 ± 9.80 | 97.22 ± 0.31 | 99.36 ± 0.35 |
| 11 | 86.83 ± 1.05 | 90.66 ± 1.18 | 83.66 ± 2.85 | 86.55 ± 3.14 | 98.12 ± 2.16 | 99.47 ± 0.29 |
| 12 | 83.41 ± 2.26 | 55.43 ± 4.80 | 75.89 ± 3.33 | 73.41 ± 6.07 | 93.09 ± 5.85 | 99.33 ± 0.44 |
| 13 | 97.41 ± 2.99 | 93.32 ± 2.04 | 98.68 ± 0.54 | 94.54 ± 4.80 | 99.80 ± 0.39 | 100.0 ± 0.0 |
| 14 | 96.14 ± 0.97 | 96.45 ± 0.76 | 96.17 ± 1.02 | 96.24 ± 2.33 | 99.43 ± 0.33 | 99.76 ± 0.34 |
| 15 | 67.31 ± 3.05 | 50.44 ± 2.44 | 67.80 ± 3.56 | 85.39 ± 7.71 | 96.58 ± 2.81 | 99.17 ± 0.72 |
| 16 | 92.47 ± 4.14 | 85.27 ± 3.37 | 88.71 ± 2.77 | 92.90 ± 3.97 | 93.12 ± 3.82 | 98.49 ± 1.1 |
| OA (%) | 86.24 ± 0.38 | 78.55 ± 0.68 | 85.27 ± 0.47 | 83.59 ± 0.88 | 97.81 ± 0.56 | 99.46 ± 0.07 |
| AA (%) | 83.15 ± 1.10 | 66.58 ± 0.93 | 82.51 ± 1.04 | 80.95 ± 1.55 | 94.10 ± 2.00 | 99.11 ± 0.26 |
| Kappa | 84.27 ± 0.45 | 75.20 ± 0.81 | 83.20 ± 0.53 | 81.23 ± 1.04 | 97.50 ± 0.64 | 99.38 ± 0.08 |
| Time(s) | 208.98 ± 1.70 | 1301.68 ± 45.94 | 7.31 ± 0.15 | 56.45 ± 0.19 | 39.62 ± 0.67 | 160.60 ± 1.68 |
| Class | SVM | RF | MLP | 2D-CNN | 3D-CNN | Proposed |
|---|---|---|---|---|---|---|
| 1 | 95.36 ± 0.30 | 93.52 ± 0.45 | 94.17 ± 1.73 | 93.43 ± 2.70 | 99.16 ± 0.25 | 99.95 ± 0.06 |
| 2 | 98.25 ± 0.16 | 98.29 ± 0.18 | 98.06 ± 0.50 | 97.59 ± 0.88 | 99.77 ± 0.17 | 99.99 ± 0.02 |
| 3 | 82.93 ± 0.91 | 75.56 ± 1.86 | 79.27 ± 7.04 | 89.96 ± 3.30 | 96.95 ± 1.78 | 99.74 ± 0.35 |
| 4 | 95.93 ± 0.70 | 91.68 ± 0.63 | 94.61 ± 2.58 | 94.16 ± 3.24 | 98.80 ± 0.69 | 99.83 ± 0.12 |
| 5 | 99.46 ± 0.36 | 98.88 ± 0.49 | 99.63 ± 0.27 | 97.97 ± 2.69 | 99.90 ± 0.17 | 99.97 ± 0.06 |
| 6 | 91.76 ± 0.60 | 74.54 ± 0.97 | 93.60 ± 1.70 | 89.62 ± 4.10 | 99.88 ± 0.12 | 100.0 ± 0.0 |
| 7 | 88.59 ± 0.65 | 81.01 ± 1.74 | 88.53 ± 3.47 | 80.20 ± 4.82 | 96.54 ± 1.41 | 99.95 ± 0.06 |
| 8 | 90.14 ± 0.54 | 90.70 ± 0.75 | 89.59 ± 4.56 | 96.05 ± 1.88 | 98.56 ± 0.78 | 99.99 ± 0.01 |
| 9 | 99.97 ± 0.05 | 99.75 ± 0.26 | 99.63 ± 0.28 | 99.48 ± 0.27 | 99.79 ± 0.19 | 99.89 ± 0.16 |
| OA (%) | 95.20 ± 0.13 | 92.03 ± 0.21 | 94.82 ± 0.26 | 94.77 ± 0.72 | 99.28 ± 0.25 | 99.96 ± 0.03 |
| AA (%) | 93.60 ± 0.14 | 89.33 ± 0.33 | 93.01 ± 0.60 | 93.16 ± 1.23 | 98.81 ± 0.33 | 99.93 ± 0.07 |
| Kappa | 93.63 ± 0.17 | 89.30 ± 0.28 | 93.13 ± 0.34 | 93.05 ± 0.97 | 99.04 ± 0.32 | 99.94 ± 0.04 |
| Time(s) | 6084.92 ± 55.64 | 6188.75 ± 35.16 | 29.10 ± 0.92 | 172.29 ± 0.71 | 140.09 ± 1.63 | 544.59 ± 4.57 |
| Class | SVM | RF | MLP | 2D-CNN | 3D-CNN | Proposed |
|---|---|---|---|---|---|---|
| 1 | 99.68 ± 0.21 | 99.61 ± 0.12 | 99.72 ± 0.42 | 87.99 ± 17.62 | 100.00 ± 0.00 | 100.00 ± 0.0 |
| 2 | 99.87 ± 0.12 | 99.86 ± 0.07 | 99.88 ± 0.15 | 99.75 ± 0.23 | 99.99 ± 0.01 | 100.00 ± 0.0 |
| 3 | 99.74 ± 0.11 | 99.22 ± 0.51 | 99.43 ± 0.44 | 81.40 ± 10.85 | 99.94 ± 0.07 | 100.00 ± 0.0 |
| 4 | 99.48 ± 0.18 | 99.28 ± 0.44 | 99.61 ± 0.27 | 95.11 ± 5.51 | 99.83 ± 0.23 | 99.97 ± 0.06 |
| 5 | 99.24 ± 0.31 | 98.46 ± 0.21 | 99.25 ± 0.48 | 64.31 ± 12.09 | 99.90 ± 0.09 | 99.97 ± 0.06 |
| 6 | 99.92 ± 0.06 | 99.80 ± 0.09 | 99.92 ± 0.07 | 99.60 ± 0.11 | 100.00 ± 0.00 | 100.00 ± 0.0 |
| 7 | 99.70 ± 0.15 | 99.58 ± 0.09 | 99.82 ± 0.12 | 98.01 ± 4.54 | 99.90 ± 0.15 | 100.00 ± 0.0 |
| 8 | 90.87 ± 0.39 | 84.41 ± 1.34 | 85.41 ± 8.00 | 91.89 ± 2.44 | 90.67 ± 6.83 | 99.92 ± 0.1 |
| 9 | 99.94 ± 0.02 | 99.07 ± 0.17 | 99.86 ± 0.07 | 98.02 ± 1.56 | 99.99 ± 0.01 | 100.00 ± 0.0 |
| 10 | 98.26 ± 0.27 | 93.40 ± 0.58 | 97.15 ± 0.77 | 97.05 ± 0.67 | 99.27 ± 0.43 | 99.99 ± 0.01 |
| 11 | 99.61 ± 0.34 | 94.79 ± 0.59 | 97.42 ± 2.29 | 94.58 ± 3.59 | 99.48 ± 0.73 | 99.91 ± 0.19 |
| 12 | 99.93 ± 0.05 | 99.08 ± 0.29 | 99.80 ± 0.14 | 92.67 ± 5.75 | 99.76 ± 0.38 | 100.00 ± 0.0 |
| 13 | 99.07 ± 0.72 | 98.23 ± 0.69 | 99.40 ± 0.28 | 98.10 ± 0.76 | 99.63 ± 0.58 | 100.00 ± 0.0 |
| 14 | 98.08 ± 1.00 | 92.81 ± 1.04 | 97.58 ± 0.94 | 95.25 ± 5.74 | 99.94 ± 0.11 | 100.00 ± 0.0 |
| 15 | 72.83 ± 0.78 | 63.32 ± 1.82 | 80.27 ± 8.41 | 87.36 ± 3.87 | 96.18 ± 1.52 | 99.94 ± 0.05 |
| 16 | 99.45 ± 0.25 | 98.17 ± 0.36 | 98.97 ± 0.38 | 93.72 ± 1.66 | 99.39 ± 0.42 | 99.75 ± 0.4 |
| OA (%) | 94.15 ± 0.10 | 90.76 ± 0.24 | 93.87 ± 0.70 | 92.31 ± 1.62 | 97.44 ± 1.28 | 99.96 ± 0.03 |
| AA (%) | 97.23 ± 0.11 | 94.94 ± 0.12 | 97.09 ± 0.33 | 92.18 ± 2.72 | 98.99 ± 0.40 | 99.97 ± 0.05 |
| Kappa | 93.48 ± 0.11 | 89.70 ± 0.26 | 93.18 ± 0.77 | 91.43 ± 1.81 | 97.15 ± 1.42 | 99.96 ± 0.03 |
| Time(s) | 3110.30 ± 29.20 | 4694.29 ± 158.39 | 36.42 ± 0.11 | 296.62 ± 3.52 | 260.41 ± 6.09 | 742.09 ± 8.22 |
| Classes | Samples | d = 9 | d = 19 | d = 29 | Proposed d = 9 | |
|---|---|---|---|---|---|---|
| 1 | Alfalfa | 30 | 100.00 | 100.00 | 100.00 | 100.00 |
| 2 | Corn-notill | 150 | 90.57 | 94.06 | 97.17 | 98.24 |
| 3 | Corn-min | 150 | 97.69 | 96.43 | 98.17 | 99.37 |
| 4 | Corn | 100 | 99.92 | 100.00 | 100.00 | 100.00 |
| 5 | Grass/Pasture | 150 | 98.10 | 98.72 | 98.76 | 99.67 |
| 6 | Grass/Trees | 150 | 99.34 | 99.67 | 100.00 | 99.73 |
| 7 | Grass/pasture-mowed | 20 | 100.00 | 100.00 | 100.00 | 100.00 |
| 8 | Hay-windrowed | 150 | 99.58 | 99.92 | 100.00 | 100.00 |
| 9 | Oats | 15 | 100.00 | 100.00 | 100.00 | 100.00 |
| 10 | Soybeans-notill | 150 | 94.28 | 97.63 | 99.14 | 99.65 |
| 11 | Soybeans-min | 150 | 87.75 | 92.93 | 94.59 | 96.89 |
| 12 | Soybean-clean | 150 | 94.81 | 97.17 | 99.06 | 99.53 |
| 13 | Wheat | 150 | 100.00 | 100.00 | 100.00 | 100.00 |
| 14 | Woods | 150 | 98.09 | 97.88 | 99.76 | 98.85 |
| 15 | Bldg-Grass-Tree-Drives | 50 | 89.79 | 95.80 | 98.39 | 98.24 |
| 16 | Stone-steel towers | 50 | 100.00 | 99.57 | 98.92 | 99.57 |
| Overall Accuracy (OA) | 93.94 | 96.29 | 97.87 | 98.65 | ||
| Average Accuracy (AA) | 96.87 | 98.11 | 99.00 | 99.36 | ||
| Kappa | 93.12 | 95.78 | 97.57 | 98.46 | ||
| Runtime (s) | 74.47 | 189.51 | 158.42 | 132.04 | ||
| Classes | Samples | d = 15 | d = 21 | d = 23 | Proposed d = 15 | |
|---|---|---|---|---|---|---|
| 1 | Asphalt | 548 | 97.53 | 98.80 | 98.59 | 99.97 |
| 2 | Meadows | 540 | 98.98 | 99.46 | 99.60 | 99.96 |
| 3 | Gravel | 392 | 98.96 | 99.59 | 99.45 | 100.00 |
| 4 | Trees | 542 | 99.75 | 99.68 | 99.57 | 99.75 |
| 5 | Painted metal sheets | 256 | 99.93 | 99.78 | 99.61 | 99.94 |
| 6 | Bare Soil | 532 | 99.42 | 99.93 | 99.84 | 100.00 |
| 7 | Bitumen | 375 | 98.71 | 99.88 | 100.00 | 100.00 |
| 8 | Self-Blocking Bricks | 514 | 98.58 | 99.53 | 99.67 | 99.99 |
| 9 | Shadows | 231 | 99.87 | 99.79 | 99.83 | 100.00 |
| Overall Accuracy (OA) | 98.87 | 99.47 | 99.48 | 99.96 | ||
| Average Accuracy (AA) | 99.08 | 99.60 | 99.57 | 99.96 | ||
| Kappa | 98.51 | 99.30 | 99.32 | 99.94 | ||
| Runtime (s) | 43.16 | 94.57 | 107.56 | 519.09 | ||
| Spatial Size | Indian Pines (IP) | Kennedy Space Center (KSC) | University of Pavia (UP) | |||
|---|---|---|---|---|---|---|
| SSRN [119] | Proposed | SSRN [119] | Proposed | SSRN [119] | Proposed | |
| 5×5 | 92.83 (0.66) | 97.85 (0.28) | 96.99 (0.55) | 97.11 (0.48) | 98.72 (0.17) | 99.13 (0.08) |
| 7×7 | 97.81 (0.34) | 99.24 (0.14) | 99.01 (0.31) | 98.81 (0.23) | 99.54 (0.11) | 99.71 (0.10) |
| 9×9 | 98.68 (0.29) | 99.58 (0.09) | 99.51 (0.25) | 99.52 (0.19) | 99.73 (0.15) | 99.82 (0.07) |
| 11×11 | 98.70 (0.21) | 99.74 (0.08) | 99.57 (0.54) | 99.73 (0.15) | 99.79 (0.08) | 99.93 (0.03) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep&Dense Convolutional Neural Network for Hyperspectral Image Classification. Remote Sens. 2018, 10, 1454. https://doi.org/10.3390/rs10091454
Paoletti ME, Haut JM, Plaza J, Plaza A. Deep&Dense Convolutional Neural Network for Hyperspectral Image Classification. Remote Sensing. 2018; 10(9):1454. https://doi.org/10.3390/rs10091454
Chicago/Turabian StylePaoletti, Mercedes E., Juan M. Haut, Javier Plaza, and Antonio Plaza. 2018. "Deep&Dense Convolutional Neural Network for Hyperspectral Image Classification" Remote Sensing 10, no. 9: 1454. https://doi.org/10.3390/rs10091454
APA StylePaoletti, M. E., Haut, J. M., Plaza, J., & Plaza, A. (2018). Deep&Dense Convolutional Neural Network for Hyperspectral Image Classification. Remote Sensing, 10(9), 1454. https://doi.org/10.3390/rs10091454