Automatic Extraction of Gravity Waves from All-Sky Airglow Image Based on Machine Learning


Abstract
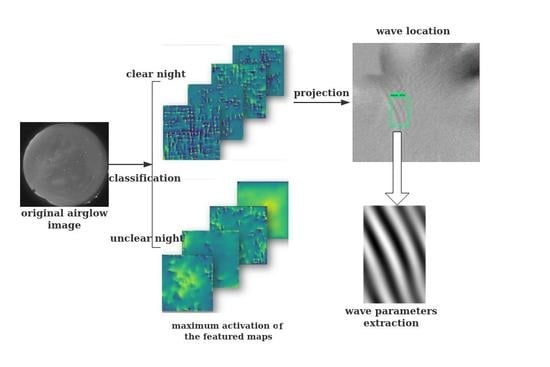
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Instrument and Data Description
3. Frame of the Detection Program
4. Classification
4.1. Architecture of CNN
4.2. Training and Validation with Datasets
4.3. Training Process
4.4. Model Validation
5. GW Location
5.1. Datasets of GW Location
5.2. Training of GW Location Model
6. Calculation of GW Parameters
6.1. Calculation of Wavelength
6.2. Removing the Interference of Mist
7. Manual Validation
8. Discussions
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hodges, R.R. Generation of turbulence in the upper atmosphere by internal gravity waves. J. Geophys. Res. 1967, 72, 3455–3458. [Google Scholar] [CrossRef]
- Snively, J.B. Nonlinear gravity wave forcing as a source of acoustic waves in the mesosphere, thermosphere, and ionosphere. Geophys. Res. Lett. 2017, 44, 12020–12027. [Google Scholar] [CrossRef]
- Fritts, D.C. Gravity wave saturation in the middle atmosphere: A review of theory and observation. Rev. Geophys. 1984, 22, 275–308. [Google Scholar] [CrossRef]
- Fritts, D.C.; Alexander, M.J. Gravity wave dynamics and effects in the middle atmosphere. Rev. Geophys. 2003, 41, 1003. [Google Scholar] [CrossRef]
- Hoffmann, L.; Xue, X.; Alexander, M.J. A global view of stratospheric gravity wavehostspots located with Atmospheric Infrared Sounder observations. J. Geophys. Res. Atmos. 2013, 118, 416–434. [Google Scholar] [CrossRef]
- Peterson, A.W.; Adams, G.W. OH airglow phenomena during the 5–6 July 1982 total lunar eclipse. Appl. Opt. 1983, 22, 2682–2685. [Google Scholar] [CrossRef] [PubMed]
- Taylor, M.J. A review of advances in imaging techniques for measuring short period gravity waves in the mesosphere and lower thermosphere. Adv. Space Res. 1997, 19, 667–676. [Google Scholar] [CrossRef]
- Suzuki, S.; Shiokawa, K.; Otsuka, Y.; Ogawa, T.; Kubota, M.; Tsutsumi, M.; Nakamura, T.; Fritts, D.C. Gravity wave momentum flux in the upper mesosphere derived from OH airglow imaging measurements. Earth Planets Space 2007, 59, 421–427. [Google Scholar] [CrossRef]
- Yue, J.; Sharon, L.; She, C.Y.; Nakamura, T.; Reising, S.C.; Liu, H.L.; Stamus, P.; Krueger, D.A.; Lyons, W.; Li, T. Concentric gravity waves in the mesosphere generated by deep convective plumes in the lower atmosphere near Fort Collins, Colorado. J. Geophys. Res. Atmos. 2009, 114, D06104. [Google Scholar] [CrossRef]
- Xu, J.Y.; Li, Q.Z.; Yue, J.; Hoffmann, L.; Straka, W.C.; Wang, C.; Liu, M.; Yuan, W.; Han, S.; Miller, S.D.; et al. Concentric gravity waves over northern China observed by an airglow imager network and satellites. J. Geophys. Res. Atmos. 2015, 120, 11058–11078. [Google Scholar] [CrossRef]
- Dou, X.K.; Li, T.; Tang, Y.; Yue, J.; Nakamura, T.; Xue, X.; Williams, B.P.; She, C.Y. Variability of gravity wave occurrence frequency and propagation direction in the upper mesosphere observed by the OH imager in Northern Colorado. J. Atmos. Sol. Terr. Phys. 2010, 72, 457–462. [Google Scholar] [CrossRef]
- Li, Q.Z.; Xu, J.Y.; Yue, J.; Yuan, W.; Liu, X. Statistical characteristics of gravity wave activities observed by an OH airglow imager at Xinglong, in northern China. Ann. Geophys. 2011, 29, 1401–1410. [Google Scholar] [CrossRef]
- Tang, Y.H.; Dou, X.K.; Li, T.; Nakamura, T.; Xue, X.; Huang, C.; Manson, A.; Meek, C.; Thorsen, D.; Avery, S. Gravity wave characteristics in the mesopause region revealed from OH airglow imager observations over Northern Colorado. J. Geophys. Res. Space 2014, 119, 630–645. [Google Scholar] [CrossRef]
- Li, Q.Z.; Xu, J.Y.; Liu, X.; Yuan, W.; Chen, J. Characteristics of mesospheric gravity waves over the southeastern Tibetan Plateau region: Mesospheric Gravity waves. J. Geophys. Res. Space 2016, 121, 9204–9221. [Google Scholar] [CrossRef]
- Wang, C. Recent Advances in Observation and Research of the Chinese Meridian Project. Chin. J. Space Sci. 2018, 38, 640–649. [Google Scholar]
- Matsuda, T.S.; Nakamura, T.; Ejiri, M.K.; Tsutsumi, M.; Shiokawa, K. New statistical analysis of the horizontal phase velocity distribution of gravity waves observed by airglow imaging. J. Geophys. Res. Atmos. 2014, 119, 9707–9718. [Google Scholar] [CrossRef]
- Matsuda, T.S.; Nakamura, T.; Ejiri, M.K.; Tsutsumi, M.; Tomikawa, Y.; Taylor, M.J.; Zhao, Y.; Pautet, P.D.; Murphy, D.J.; Moffat-Griffin, T. Characteristics of mesospheric gravity waves over Antarctica observed by Antarctica Gravity Wave Instrument Network imagers using 3-D spectral analyses. J. Geophys. Res. Atmos. 2017, 122, 8969–8981. [Google Scholar] [CrossRef]
- Hu, S.; Ma, S.; Yan, W.; Hindley, N.P.; Xu, K.; Jiang, J. Measuring gravity wave parameters from a nighttime satellite low-light image based on two-dimensional Stockwell transform. J. Atmos. Ocean. Technol. 2019, 36, 41–51. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef]
- LeCun, Y. Generalization and network design strategies. In Connectionism in Perspective, Proceedings of the International Conference Connectionism in Perspective, University of Zürich, Zürich, Switzerland, 10–13 October 1988; Pfeifer, R., Schreter, Z., Eds.; Elsevier: Amsterdam, The Netherlands, 1989. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Clausen, L.B.N.; Nickisch, H. Automatic classification of auroral images from the Oslo Auroral THEMIS (OATH) data set using machine learning. J. Geophys. Res. Space 2018, 123, 5640–5647. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. Oper. Syst. Des. Implement. 2016, 16, 265–283. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: London, UK, 2016; p. 184. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- de Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Bharath, R. Data Augmentation|How to Use Deep Learning When You Have Limited Data. Available online: https://medium.com/nanonets/how-to-use-deep-learning-when-you-have-limited-data-part-2-data-augmentation-c26971dc8ced (accessed on 11 April 2018).
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient mini-batch training for stochastic optimization. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, New York, NY, USA, 24–27 August 2014; pp. 661–670. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Erhan, D.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing Higher-Layer Features of a Deep Network; Technical Report 1341; University of Montreal: Montreal, QC, Canada, 2009. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2014, arXiv:1312.6034. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 3296–3297. Available online: https://dblp.org/rec/conf/cvpr/HuangRSZKFFWSG017 (accessed on 14 November 2017).
- Tang, J.; Swenson, G.R.; Liu, A.Z.; Kamalabadi, F. Observational investigations of gravity waves momentum flux with spectroscopic imaging. J. Geophys. Res. Atmo. 2005, 110, D09S09. [Google Scholar] [CrossRef]
- Baker, D.J.; Stair, A.T. Rocket measurements of the altitude distributions of the hydroxyl airglow. Phys. Scr. 1988, 37, 611–622. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Los Alamitos, CA, USA, 2014; pp. 580–587. Available online: https://www.onacademic.com/detail/journal_1000037205494010_96ad.html (accessed on 25 June 2019).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In ECCV 2014; Lecture Notes in Computer Science; Springer: Zürich, Switzerland, 2014; Volume 8692. [Google Scholar] [CrossRef]
- GitHub. Available online: https://github.com/tensorflow/models/blob/master/research/object_detection/samples/configs/faster_rcnn_resnet101_voc07.config (accessed on 4 November 2016).
- Garcia, F.J.; Taylor, M.J.; Kelley, M.C. Two-dimensional spectral analysis of mesospheric airglow image data. Appl. Opt. 1997, 36, 7374–7385. [Google Scholar] [CrossRef] [PubMed]
- Swenson, G.; Alexander, M.; Haque, R. Dispersion imposed limits on atmospheric gravity waves in the mesosphere: Observations from OH airglow. Geophys. Res. Lett. 2000, 27, 875–878. [Google Scholar] [CrossRef]
- Wang, C.M.; Li, Q.Z.; Xu, J. Gravity wave characteristics from multi-stations observation with OH all-sky airglow imagers over mid-latitude regions of China. Chin. J. Geophys. 2016, 59, 1566–1577. [Google Scholar] [CrossRef]














© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, C.; Xu, J.; Yue, J.; Yuan, W.; Liu, X.; Li, W.; Li, Q. Automatic Extraction of Gravity Waves from All-Sky Airglow Image Based on Machine Learning. Remote Sens. 2019, 11, 1516. https://doi.org/10.3390/rs11131516
Lai C, Xu J, Yue J, Yuan W, Liu X, Li W, Li Q. Automatic Extraction of Gravity Waves from All-Sky Airglow Image Based on Machine Learning. Remote Sensing. 2019; 11(13):1516. https://doi.org/10.3390/rs11131516
Chicago/Turabian StyleLai, Chang, Jiyao Xu, Jia Yue, Wei Yuan, Xiao Liu, Wei Li, and Qinzeng Li. 2019. "Automatic Extraction of Gravity Waves from All-Sky Airglow Image Based on Machine Learning" Remote Sensing 11, no. 13: 1516. https://doi.org/10.3390/rs11131516
APA StyleLai, C., Xu, J., Yue, J., Yuan, W., Liu, X., Li, W., & Li, Q. (2019). Automatic Extraction of Gravity Waves from All-Sky Airglow Image Based on Machine Learning. Remote Sensing, 11(13), 1516. https://doi.org/10.3390/rs11131516