1. Introduction
With the rapid development of the Earth Observing Satellite Technique, more high-resolution optical remote sensing (ORS) data become available, which enlarges the potential of ORS data for image analysis. Automatic ship detection is of great importance to military and civilian applications. This is a challenging task in the field of ORS image processing due to the variable appearances of ships and complex sea backgrounds. More specifically, ship targets in ORS images can vary greatly in illumination, color, texture, and other visual properties. Due to the overhead view, they are relatively small in size. Meanwhile, they often appear in very different scales and directions. Besides, ships are easily confused with the interferences introduced by heavy clouds, islands, coastlines, ocean waves, and other uncertain sea state conditions, which further increases the difficulty of ship detection. Therefore, how to detect various types of ships quickly and precisely from ORS images with cluttered scenes has become an urgent problem to be solved.
According to the geographical location of ship targets, existing detection algorithms fall into two categories, inshore ship detection and offshore ship detection. Note that land areas can be eliminated by using sea-land segmentation or prior geographic information, for instance, a Geographic Information System (GIS) database. We consider the problem of detecting and localizing offshore ships in ORS images in this paper. Over the last decades, numerous ship detection algorithms have been investigated. Most current existing methods adopt a two-stage detection mechanism, namely, region proposal and ship target identification. The goal of the region proposal stage is to separate regions of interest (ROIs) from the background for the subsequent target identification. The first type of methods used the threshold segmentation techniques [
1,
2], which set an optimal threshold and regarded pixels with gray value beyond the threshold as the target pixels. Zhu et al. [
1] applied the Otsu segmentation followed by a level set to extract candidate regions. Leng et al. [
2] employed the same segmentation algorithm to distinguish potential target and clutter pixels. These methods have a small computational effort and work well on the simple ocean scenes. Nevertheless, they perform poorly when the target’s intensity is similar to or even lower than the clutter. Besides, massive clouds are easily mistaken for targets because they are usually brighter than the background. This would generate plenty of false alarms in the candidate extraction stage. The second type of methods performed the sliding window where every location within the target image was examined in order not to miss any potential target location. For instance, Zhou et al. [
3] used the multi-scale sliding window to obtain patches from the test images and employed the sparse code and support vector machine (SVM) classification in the ship validation stage. However, the exhaustive search has several drawbacks. First, lack of prior information of target size, the multiple scales, and multiple aspect ratios are needed to guarantee the detection accuracy. The number of windows to visiting remains huge. On the other hand, the captured ship targets only take up a few pixels in large sea images, that is to say, only a few windows contain real ship targets. It is inappropriate for remote sensing images to use sliding window detection mechanism, which is time-consuming and computationally complex. Since the ships in the visible remote sensing (VRS) image of the sea are salient objects, they are usually sparsely distributed and can easily be identified by the human visual attention system. Recently, the saliency model, which can extract ROIs efficiently, has become a hot spot in ORS image processing. There is a significant body of work on the saliency model, including several kinds of spatial-domain models and a variety of transform-domain models. One of the classical spatial-domain models is the one proposed by Itti et al. in 1998 [
4]. This model extracted simple visual features, including color, intensity, and orientation, by the center-surround strategy. Then, the conspicuity maps of each feature were obtained by performing the across-scale combination. The final saliency map was generated by fusing these conspicuity maps. Subsequently, a large number of models have been proposed to predict salient pixels. We refer readers to [
5] for more details. The transform-domain saliency model, which requires a small amount of computation, plays an important role in ship detection. Zhuang et al. [
6] came up with an extended version of the spectral residual model to rapidly complete ship candidate extraction. Zhang et al. [
7] extracted the ROIs in HSI color space based on quaternion Fourier transform. In addition, Xu et al. [
8] designed another saliency model based on wavelet transform for obtaining the ship targets. The saliency models mentioned above can quickly remove redundant information and restrain the complex and various backgrounds. They achieve considerable detection results even in the presence of cloud, fog, sea clutter, etc. However, the existing salient-region based methods are sensitive to the variety of target size. They are not suitable for dealing with situations where ship targets have a large difference in size. Moreover, there is usually a threshold segmentation step to segment saliency map and obtain the binary image, which can distinguish the target from the sea background. This, however, is not wise because there may not be any ROI present in the target image. In summary, a practical region proposal algorithm should be robust to the variety of target size. Of equal importance, it should detect the targets accurately and suppress false alarms under complex backgrounds. Based on the challenges mentioned above, there still remains room for improvement in saliency detection from ORS images.
The aim of the ship discrimination stage is to distinguish between the real ships and the false alarms. The discrimination stage commonly contains two stages: feature extraction and classification. Powerful feature extraction is a very important part of constructing a high-performance object detector. Since the target orientation in ORS images is arbitrary, rotation-invariant object detection is of vital significance. Some traditional image features like the histogram of oriented gradients (HOG) feature [
9] and the Haar feature [
10] can achieve excellent detection precision and computation speed. Despite the popularity of these feature representation methods, they are not rotation-invariant due to the definition according to a fixed coordinate system. Great efforts have been made for solving this issue. Method [
11] extracted an extra feature provided with HOG feature and generated four AdaBoost classifiers to detect ships in different orientations. In a similar manner, the method [
12] divided ships into eight subsets according to their orientations and trained eight filters using linear SVM for classification, respectively. Yao et al. [
10] used the Haar feature combined with three AdaBoost classifiers, which are trained for three directions using samples with different directions. Because of the need to train multiple classifiers, which have complex training steps and great computational cost, these methods are not suitable for real-time processing. Another type of method aligned the candidate regions with an estimated dominant orientation. Shi et al. [
13] adopted a radon transform method to rotate the patches in order to make all the candidates distributed in the same direction. Qi et al. [
14] performed the Principal Component Analysis (PCA) transform to obtain the direction of the main axis and rotated the ship candidates to the vertical direction before extracting HOG feature from the ship candidates. Method [
15] obtained the main direction of ships by computing the HOG feature and rotated the ships in the same direction. By pre-rotating the patches to a fixed angle, the subsequent feature extraction does not need to take into account the target rotation problem. However, such methods are obviously sensitive to the incorrect estimates of dominant orientation. Instead of rotation estimation computation, a more elegant line of work focused on the rotation-invariant feature analysis for ship target description. Method [
16] proposed a rotation-invariant matrix for object detection in ORS images. The proposed matrix could incorporate partial angular spatial information in addition to radial spatial information. Method [
17] extracted a rotation-invariant feature describing the shape and the texture information of the targets. Then, a trainable SVM classifier was performed to further remove the false alarms and maintain the real ship targets. In general, the performances of these rotation-invariant features are satisfying in ship target description. After the feature extraction stage, a classifier outputs the predicted label of each candidate, i.e., object or not. Some methods used unsupervised learning in the identification stage. For example, the method [
8] designed an unsupervised multi-level discrimination algorithm based on the improved entropy and pixel distribution to further reduce the false alarms. Method [
18] applied efficient rules based on a novel gradient descriptor to distinguish ships and non-ships. Other methods applied the supervised learning to detect the ship targets, generally using SVM, AdaBoost, etc. Compared with unsupervised learning, these methods are more accurate and more suitable for ship target detection. To sum up, a good ship identification algorithm should not only be highly discriminative to distinguish the ship targets and the false alarms but also be robust to the variable appearances of ships, such as rotation, illumination, scale, and viewpoint changes.
In recent years, a deep learning algorithm has become a powerful tool for remote sensing image analysis. It was initially attempted to represent features in the feature extraction stage. Yang et al. [
12] implemented a deep forest ensemble with a cascade structure to discriminate ship targets. Wu et al. [
19] presented a ship head feature extraction algorithm based on convolutional neural network (CNN). Method [
20] combined the constant false alarm rate (CFAR) detection algorithm with the CNN model to detect ships in Synthetic aperture radar (SAR) images. Method [
21] achieved rotation invariance by introducing and learning a new rotation-invariant layer on the basis of the existing CNN architecture. Method [
22] presented an architecture, which used CNN for extracting features of aerial imagery, and applied a k-Nearest Neighbor method to examine if an aerial image of the visible spectrum contained a ship or not. Due to the strong feature representation power, deep learning algorithms achieved more discriminative data representation compared with hand-engineered features. With the development of deep learning algorithms, the end-to-end data-driven detectors, which consist of a region proposal network (RPN) and an object detection network, have been specially modified to detect the objects in the large remote sensing images. Some end-to-end detection models aim to overcome the problem of the large scale variability. Zhang et al. [
23] proposed a multi-scale Feature Pyramid Network containing a multi-scale potential region generation and a multi-scale object detection network to detect small and dense objects. Li et al. [
24] proposed a modification of faster region-CNN (Faster-RCNN) [
25] by constructing a hierarchical selective filtering layer to accurately detect multi-scale ships. Other end-to-end detection models have been extended to overcome the issue of target rotation. For instance, Liu et al. [
26] designed an arbitrary-oriented ship detection framework based on the YOLOv2 architecture [
27] by adding the orientation loss to the loss function. These models utilized the unified detection framework instead of the multi-stage pipelines and achieved significant improvements in the ship detection task. However, such deep learning methods need a lot of training data as well as complex training phases. Their implementations rely on Graphical Processing Unit (GPU) and parallel operations. For small platforms like Unmanned Airborne Vehicles (UAVs), the use of GPU would increase the load capacity, energy consumption, and economic cost [
28]. Thus, in this condition, the algorithm based on the hand-designed feature is still significant.
There are two typical challenges for ship detection in ORS images. They are scale and rotation, as illustrated in
Figure 1. To overcome these two issues, a robust and practical multi-stage ship detection algorithm is presented in this paper.
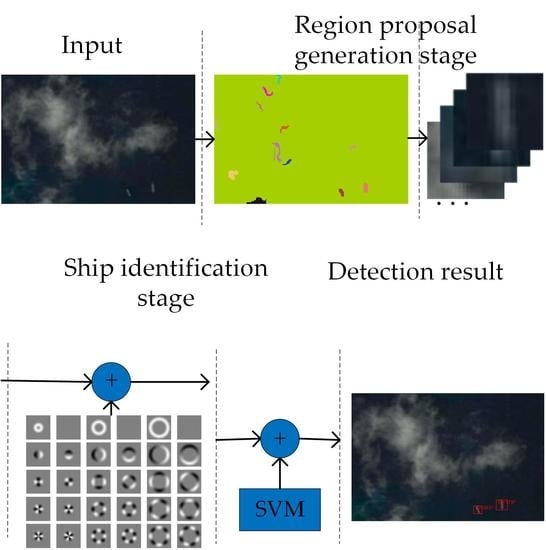
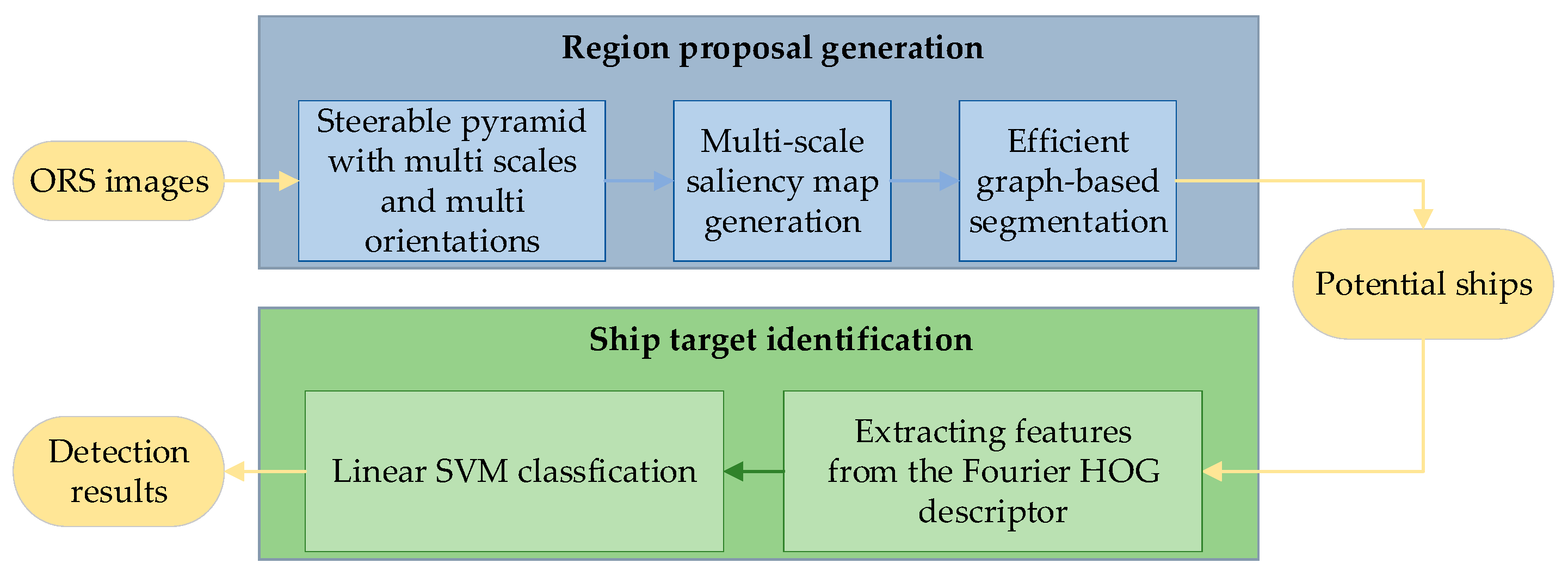
Figure 2 shows the flow chart of the proposed detection scheme.
The scheme contains two stages: region proposal and ship target identification. In the region proposal stage, the luminance channel is decomposed using a steerable pyramid [
29] with six orientations and five scales. The difference between the maximum and minimum output of each filter is used as a criterion for the efficiency of the generated saliency map. Then, some saliency maps that may be related to the direction of sea clutter are removed. Unlike other threshold-based methods, the graph segmentation algorithm [
30] based on multi-scale saliency maps is constructed to overcome the problem of ship scale change and accurately locate candidate regions. In addition, by selecting efficient saliency maps, the region proposal algorithm can suppress the sea clutter to some extent. In the ship identification stage, the rotation-invariant HOG descriptor [
31], using Fourier analysis in polar coordinates, is investigated to distinguish between the targets and the false alarms. Meanwhile, the main direction of the ship can also be estimated in this phase. The proposed detection framework achieves a good detection rate of ship targets in cluttered scenes. In general, our overall detection algorithm may become an effective contributor for improving the performance of the ship detection system.
The remainder of this paper is organized as follows: we state the framework of our candidate region generation algorithm in detail in
Section 2.
Section 3 introduces the techniques of building the rotation-invariant Fourier HOG descriptor. We demonstrate our experimental results based on the ORS image dataset and compare the results with other detection methods in
Section 4. The final Section concludes the paper by summarizing our findings.
2. Region Proposal Algorithm Based on Multi-Scale Analysis
Ship objects in ORS images often appear at very different scales and have large size differences. Besides, they usually have great intensity fluctuations and obvious edges. Based on the above analysis, we can conclude that both the multi-scale decomposition and the differential algorithm are powerful tools for capturing ship characteristics from ORS images. The Steerable Pyramid (SP), which can combine the pyramid decomposition and the derivative operation into a single operation, is introduced to design our region proposal algorithm. In comparison with orthonormal wavelet transform, the SP has some advantages (for example, steerable orientation decomposition; aliasing is eliminated) and is more suitable for detecting targets with different scales and orientations in the cluttered scenes. The SP is an overcomplete, linear, multi-scale, and multi-orientation image decomposition whose filters are derivative operators with different support and orientations. The SP transform is implemented as a filter bank consisting of polar-separable filters in the Fourier domain, to form a tight frame and to prevent spatial aliasing. For simplicity, we describe these filters in the frequency domain.
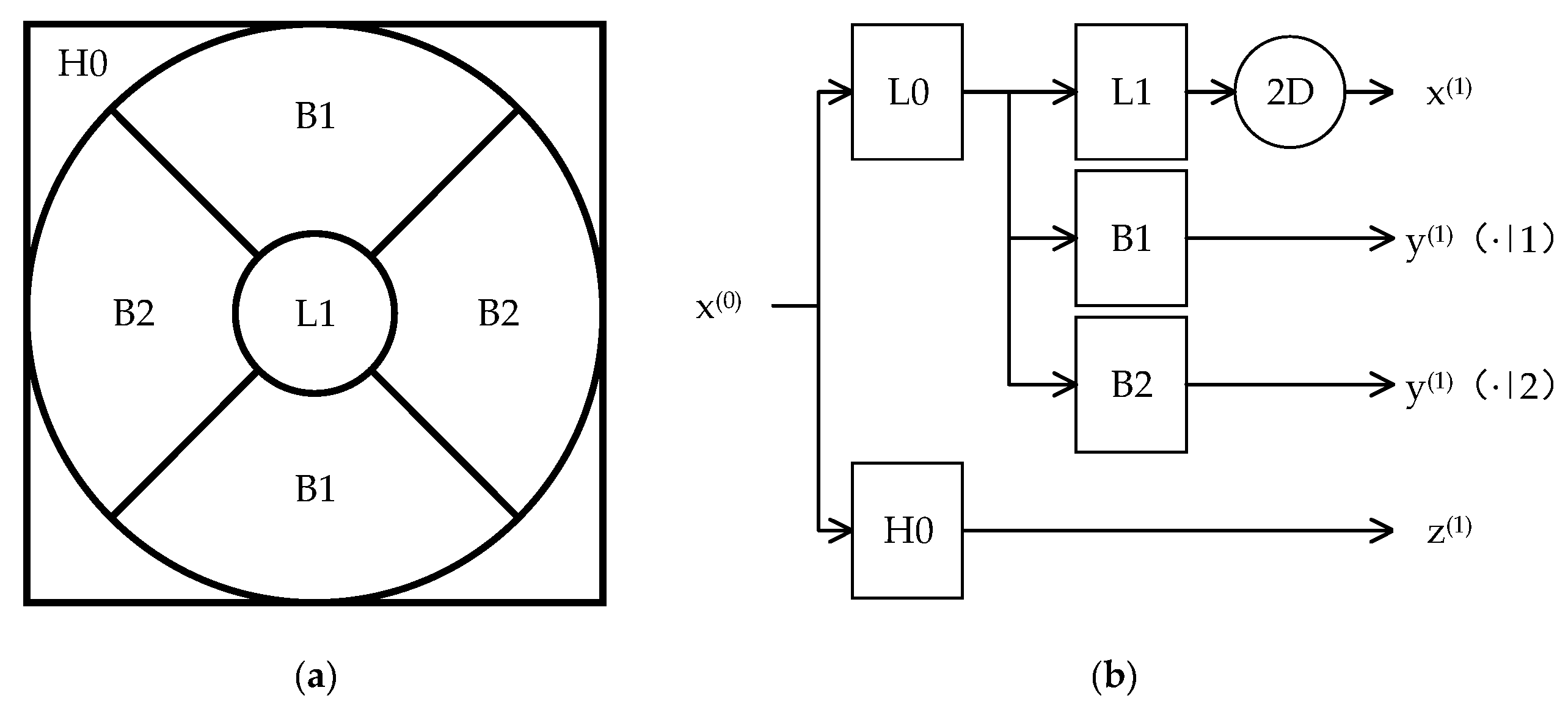
Figure 3 shows the frequency tiling of the first level SP decomposition for the case of two orientation bands (i.e., P = 2) and the corresponding diagram. As illustrated in
Figure 3a, the frequency plane can be divided into three parts: a low-pass band denoted as L1, two oriented band-pass components denoted as B1 and B2, respectively, and a high-pass band denoted as H0.
Figure 3b shows the system diagram for the steerable pyramid. Firstly, the signal x
(0) is pre-separated into the low-pass component by the filter L0 and the high-pass component by the filter H0. The high-pass signal is presented as z
(1). The low-pass component is then divided into a set of P oriented detail images y
(1)(·|
p),
p = 1,…,P and one approximation signal x
(1). The oriented detail images are generated by using the band-pass filters B1,…, BP, while the approximation signal is generated by using the low-pass filter H1 and a dyadic down-sampling process. The approximation signal x
(s−1) can be decomposed into the s-scale oriented images and approximation image.
For a given ORS image, we firstly transform it to the corresponding gray image I
(0) and then define the multi-scale, multi-orientation SP decomposition as follows:
where
s is the decomposition level index, and
. The maximum level S used in decomposition is given by
for the input image I
(0) whose largest dimension is size D.
p denotes the orientation index, and
. To get more details about the oriented maps, we set P = 6 in this paper. The SP provides a direct representation of the local gradient of the image at different scales. The approximation image I
(s) and the oriented detail image
are generated from the
s-th level SP decomposition. Note that the filters must satisfy specific radial and angular frequency constraints [
29]. After the SP decomposition, the feature map
at the S scale and the P orientation is obtained. Let
n denote the pixel index in the feature map, and
. N presents the total pixels in the image. We can define our saliency model as:
where
is the standard deviation of the Gaussian filter, and
denotes the saliency score of pixel
n at scale
s and orientation
p. The current existing ship detection algorithms based on saliency are more effective in quiet sea conditions, and they perform poorly when the scenes include strong sea clutter interferences. It is observed that the sea clutter in an image has the same orientation, and the saliency maps generated by the SP can reflect the orientation information. Based on the above analysis, we design a selection mechanism to eliminate the interference of the sea clutter. According to the selection mechanism, the oriented saliency maps related to the sea clutter are removed, and the remaining saliency maps are used for the subsequent processing.
Figure 4 shows the generated saliency maps based on the 3-level SP decomposition. The first column presents the test ORS images with strong sea clutter. The remaining columns present their corresponding orientation saliency maps. An efficiency weight
is calculated for each saliency map
, which is estimated by the difference between the maximum and minimum values of
:
If the orientation parameter p is consistent with the direction of the sea clutter, the corresponding efficiency weight
is lower compared to the weights of other orientation saliency maps. Given a set of orientation saliency maps with fixed scale s, we rank them in descending order according to their weights and then preserve the first three saliency maps denoted as
for subsequent segmentation and region extraction. The remaining saliency maps are marked with red boxes, as shown in
Figure 4. These saliency maps can detect the ship targets accurately, even in a highly cluttered background.
In order to extract candidate regions, most existing methods adopt the Otsu segmentation algorithm. The saliency map is binarized by setting any pixels larger than the optimal threshold generated by the Otsu algorithm to one and the rest of pixels to zero. According to the binary map, the regions covered by the bounding rectangles of each connected area are defined as the suspected target regions. However, the threshold segmentation algorithm has two main drawbacks:
Due to the lack of the spatial structure information, it may introduce the inner holes and could not maintain the integrity for targets.
There may not be any object of interest present in the target image, so the threshold segmentation may lead to false alarms for such images.
In consideration of these drawbacks, we modify the graph-based segmentation [
30] to extract the ship candidates. The proposed graph-based segmentation algorithm can accurately separate the ship targets and backgrounds. Moreover, it can generate a rather smaller set of candidates in comparison with other region proposal algorithms. We describe the modified segmentation algorithm in detail.
Firstly, let G = (V, E) be an undirected graph with vertices
, the set of elements to be segmented, and edges
corresponding to pairs of neighboring vertices. We define a corresponding weight
for each edge, which represents the dissimilarity between
and
. In the case of the saliency map segmentation, the set V denotes all the pixels in the saliency map. Let us define the dissimilarity of
and
as:
Note that the saliency map at each scale is resized to the scale of the original image. The more similar the salient values of the two pixels are, the more likely they are to be segmented into the same component. The internal difference of component C is defined as the largest weight in the minimum spanning tree of the component and is denoted as D
int(C). The difference between two components, C and C’, is the minimum weight edge connecting the two components and is denoted as D
ext (C,C’). Besides, the minimum internal difference, MD
int (C,C’), is defined as:
where
is the size of component C and
is the size of component C’. k is the constant parameter. Generally speaking, too small k value may cause the over-segmentation. We empirically set k = 800 based on the analysis of [
30]. To determine whether C and C1 should be merged into one component, a threshold function is defined as:
If
, then the component C and C’ are merged into one component. By performing this strategy, the segmentation is neither too coarse nor too fine. Since the ship region accounts for a small proportion of the ORS image, we regard the segmented component whose size accounts for more than 40% of the image as the background. As shown in the first column of
Figure 5, given the ship targets with uneven brightness and low contrast, the segmentation results can still maintain the integrity for the ships. The second column shows that the proposed region proposal algorithm can detect all ship targets accurately, even under the cloud disturbance. In addition, the algorithm can suppress false alarms to some extent when there is only a quiet sea background and no ship targets in the ORS image, as shown in the last column. To sum up, the modified graph-based segmentation algorithm based on the multi-scale saliency maps can overcome the shortcomings of the low target integrity, the missed detection, and the high false alarm rate. However, due to the lack of prior information in the region proposal algorithm, we need to design the target identification algorithm, which can further remove the false alarms, such as clouds, islands, and strong sea clutters.
3. Rotation-Invariant Feature Extraction Using Fourier Analysis
After performing the region proposal algorithm, the candidate regions can be obtained. They fall into two categories: real ships and false alarms. The aim of the discrimination stage is to distinguish between the real targets and false alarms. Since ship candidates appear in very different directions, we use a rotation-invariant gradient descriptor based on Fourier analysis combined with linear SVM classifier to identify ship targets at arbitrary orientations. This descriptor treats the orientation histograms as continuous functions defined on a circle and uses the Fourier analysis [
31] to represent them. Besides, according to the Fourier smoothing histogram, the main orientation of the ship can also be obtained.
Simply, the HOG feature uses a discrete orientation histogram of an image to describe the shape of the object. In order to obtain the discrete orientation histogram, the gradient magnitude and orientation of each pixel in the image are calculated. Then, the
angle range is quantified into several angle intervals. According to the gradient orientation of the pixel, the sum of gradient magnitude of all the pixels falling in the angle interval is counted. Finally, a discrete magnitude-weighted orientation histogram is formed to describe the approximate shape of an object. However, when the image patch rotates, the discrete orientation histogram changes in a complex manner (
Figure 6b). Since the continuous orientation histogram
is a period of orientation with a period of
,
can be expressed by using its Fourier series coefficients:
with coefficients
, where
. Let the gradient estimated for each pixel
x in the candidate image
be
, then the gradient distribution function of angle
for this pixel can be expressed as a Dirac function with magnitude
and orientation
. According to Equation (7), the Fourier coefficients for
read as
where
, M is the largest order used to describe the image gradient. According to the gradient images, a set of complex-valued coefficient images
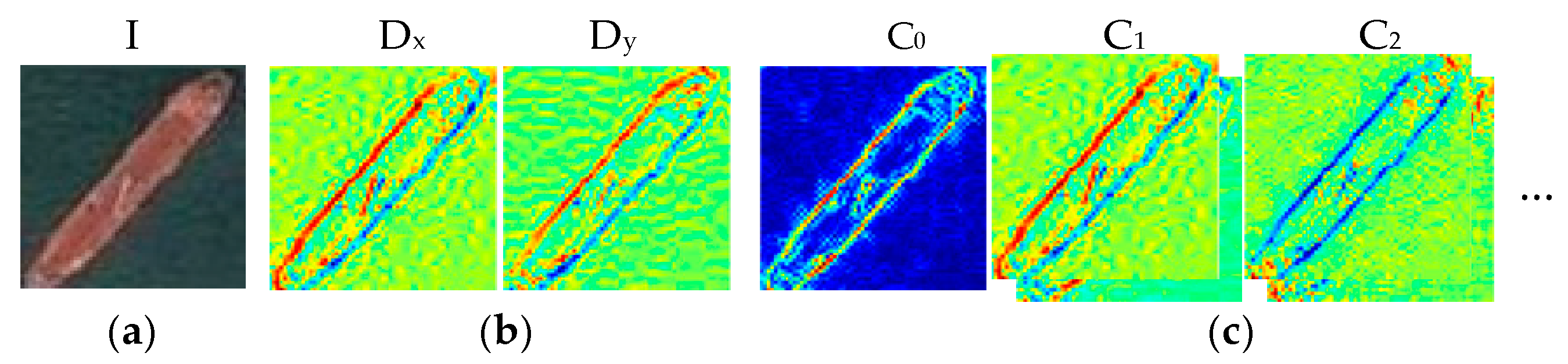
is produced. An example of this expansion is shown in
Figure 7.
In practice, the maximum frequency order M is limited to represent the gradient function more smoothly, which can improve the robustness of the gradient histogram when the appearance of the target changes. The orientation histogram of the images can be obtained by summing the orientation histograms of all the individual pixels in the images. Due to the linearity of the Fourier series representation, this can be achieved directly by accumulating coefficients on each extended coefficient image. That is to say, by limiting the value of M, we can get the smoothed orientation histogram
, which is defined as follows:
In our implementation, we set M = 4. The vertical direction is defined as zero degrees, and the orientation range is [0,360]. Then, the Fourier smoothing histogram can be obtained, as shown in
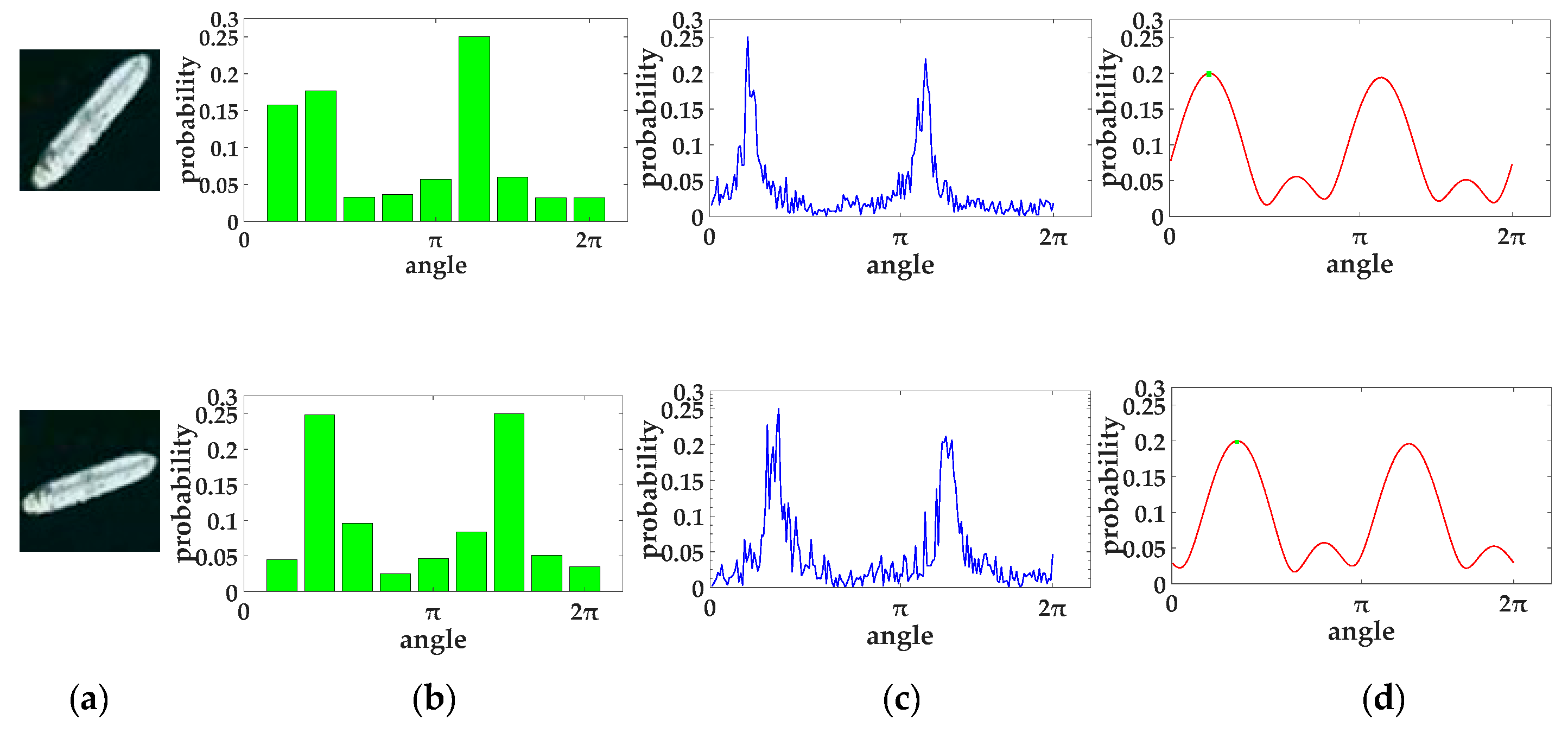
Figure 6d. Then, the main direction
can be estimated as:
If the discrete gradient histogram is used to calculate the main direction, only the approximate angle interval of the main direction can be obtained (as shown in
Figure 6b). If the continuous gradient histogram is directly used to calculate the main direction, the results are easily disturbed by noise and small deformation (as shown in
Figure 6c). Some degree of smoothing is beneficial because it increases the robustness of the description to small changes in appearance. Therefore, the smoothed orientation histogram is employed to estimate the main orientation of the ship, which makes the result more stable and accurate (as shown in
Figure 6d).
In order to obtain more abundant representations of a circular coefficient image patch, it is integrated against different circular basis functions. Then, the rotation invariance analysis is carried out to extract the final rotation-invariant features.
Since the polar coordinates can separate the angular part from the radial part, which is naturally invariant to rotations, we use polar coordinates to represent each pixel in the image to ensure that the spatial aggregation process is rotation-invariant. Let r denote radial coordinate, let
denote angular coordinate; thus, the Fourier coefficient image can be denoted as
. For simplicity, we set the center of the image as the origin of polar coordinates. The basis function
is the product of an arbitrary radial profile and a Fourier series basis. The general form is as follows:
where the integer k denotes the rotation order of the basis function,
. The integer j denotes the index of the triangular profile,
. Let R denote the largest radius of basis function, let J denote the number of different profiles, then a set of J profile is defined by:
A set of the circular basis functions is created by using different profiles and Fourier series, an example set of rotation-invariant basis functions with J = 3 and K = 4 is shown in
Figure 8.
Next, each basis function
is convolved with the Fourier coefficient images
. The result of convolution can be expressed as:
In practice, only the feature set
of the center point
in the candidate region need to be extracted for further classification. When the underlying image patch rotates by an angle
, the resulting complex feature value undergoes a phase shift of
, where the feature rotation order
. Consequently, the complex magnitudes of these complex feature values are rotation-invariant. Note that for m = 0,
is a real-valued quantity,
and, therefore, only the basic functions with
are adopted to avoid redundancy in the feature set. The final rotation invariant feature vector consists of four parts: the real and imaginary parts of complex features where
and
, the purely real features with m = k = 0, the magnitude of all other features
, and the derived features created by coupling the raw features to give quantities that encode relative phase information [
31]. Note that only the lower degrees
are considered. In our experiment, we set the training set patch size to 63✕63,
.
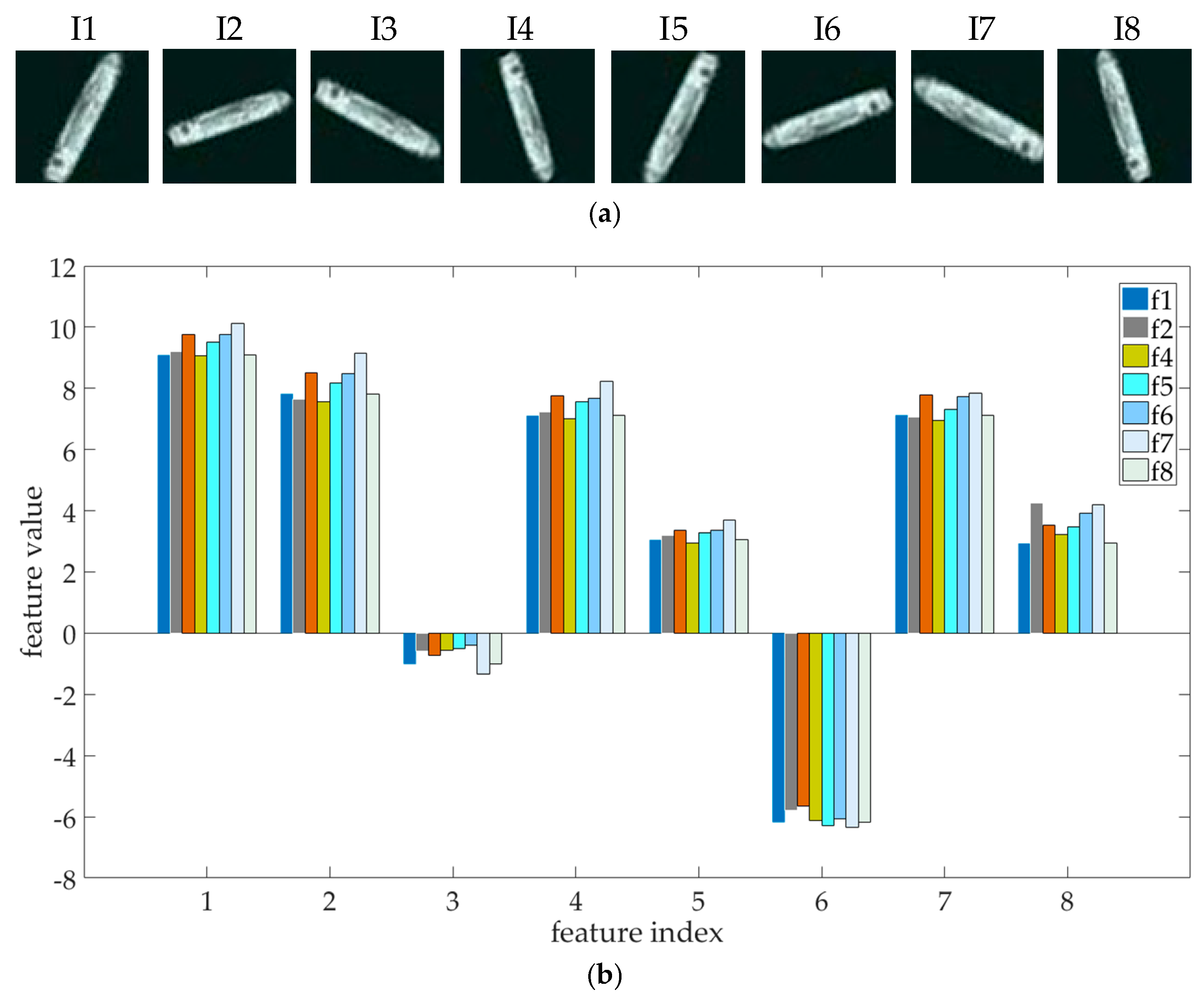
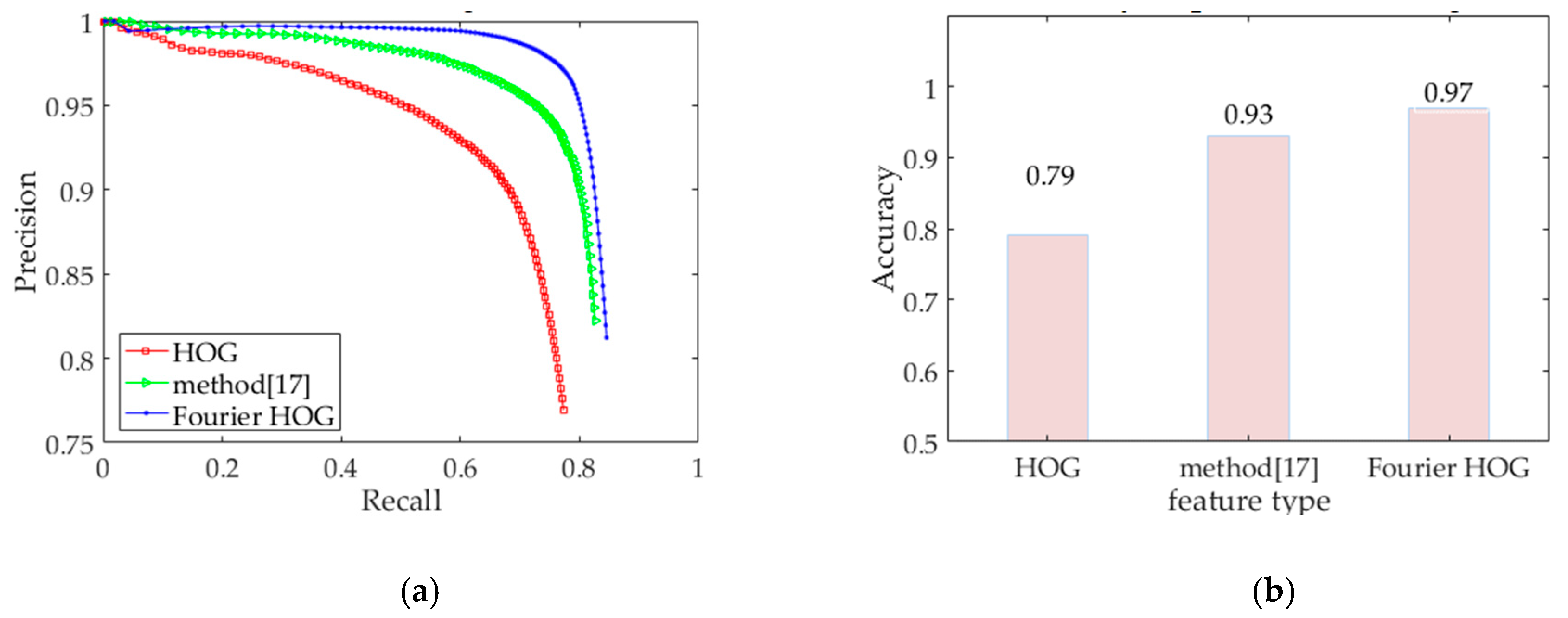
Figure 9 demonstrates the effectiveness and robustness of the extracted rotation-invariant feature vector.
After extracting the rotation-invariant feature vector of the candidate image, a linear SVM classifier [
31] is adapted to determine whether the candidate region is a ship or a false alarm. To work with the linear SVM, each feature dimension is normalized into the range [−1,1].



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}