1.1. Background
Scene recognition has important applications in inferring information through images, such as automatic driving, human-computer intersection and virtual reality. Semantic segmentation plays an important role in scene recognition and paves the way for the complete understanding of the scene, receiving more and more research and studies.
Traditional image segmentation methods include edge-based [
1], region-based [
2,
3] and hybrid segmentation. Since the convolutional neural networks (CNNs) have outstanding performance in various kinds of computer vision tasks [
4,
5,
6,
7], the ability of CNNs in semantic segmentation has attracted much attention [
8,
9,
10,
11,
12]. The state-of-art semantic segmentation algorithm converts CNNs designed for classification such as AlexNet [
13] and VGG-16 [
6] into fully convolutional network (FCN) [
14]. FCN completes the transformation from classification model to semantic segmentation model by replacing the fully-connected layers with deconvolution ones. Image segmentation models based on CNNs can be divided into three categories: (1) The encoder-decoder neural network, such as SegNet [
15] and U-Net [
16]. In the encoding part, the feature map is generated by removing the last fully connection layer of the network. And then in the decoding part, different structures are utilized to decode the feature map to obtain the image with original size. The decoding part of SegNet consists of up-sampling layers and convolutional layers, each up-sampling layer is determined by its corresponding maximum pooling coefficient of the encoding part. And the convolutional layers are used to generate the dense feature map. (2) The atrous convolution pooling neural network, such as Deeplab [
17]. Deeplab proposes atrous convolution, atrous spatial pyramid pooling (ASPP) model and the fully connected conditional random field (CRF). ASPP replaces the original preprocessing method of resizing the image, thus, the input image can have arbitrary scale. The fully connected CRF optimizes local features of classification by using low-level detail information. (3) The image pyramid neural network, such as PSPNet [
18]. Considering that the features of different scales have different details, fusing the features of different scales to obtain better segmentation results has become a new idea. PSPNet utilizes different pooling proportions to obtain features with different scales, and then combines these features for feature learning.
The label image from CNNs usually lacks structure information, a pixel label can not match the surrounding pixel labels since some small area labels in the image may be incorrect. To solve this problem, some architectures introduce CRF to refine the label image obtained from CNNs by using the similarity of pixels in the image [
19]. Liu et al. [
20] utilized CRF to train the deep features obtained by a pre-trained large CNN. The cross-domain features learned by CNN are utilized to guide the CRF learning based on structured support vector machine(SSVM), and the co-occurrence pairwise potentials are incorporated to the inference to improve the performance. Deeplab [
17] introduced the fully connected CRF to optimize local features of classification. In fully connected CRF, each pixel is modeled as a node, and a pairwise item is established regardless of the distance of the pixel to any other two pixels. Considering the effects of short distance and long distance, the detailed structure lost in CNN can be recovered. To realize multi-class semantic segmentation and robust depth estimation, Liu et al. [
21] developed a general deep continuous CRFs learning framework. This framework first models both unitary and pairwise potentials as CNNs network, and then uses task-specific loss function for CRFs parameters learning. In the above mentioned methods, CNN and CRF are two separate parts. Zheng et al. [
22] proposed a new structure combining FCN and CRF to realize end-to-end network training. This structure solves a pixel-level semantic segmentation problem by formulating mean-field inference of dense CRF with Gaussian pairwise potentials as a recurrent neural network (RNN).
A generative adversarial network (GAN) consists of a generator and a discriminator. The generator generates fake samples and the discriminator identifies them. As the training proceeds, the closer the fake samples of the generator are to the true distribution of the true data, the more difficult it is for the discriminator to distinguish the true from the false. Luc et al. [
23] first applied GAN to semantic segmentation, since the adversarial training approach can realize long-range spatial label contiguity without increasing complexity of the model in testing process. Then, some algorithms using GAN to complete semantic segmentation were proposed [
24,
25,
26,
27,
28,
29]. Phillip et al. [
24] investigated conditional adversarial networks as a general purpose solution to complete semantic segmentation, which called Pixel2pixel. Pixel2pixel applies GANs in the conditional setting and proposes a classifier named patchGAN. Pixel2pixel not only learns a mapping from input image to output image, but also learns a loss function to train the mapping. Zhu et al. [
25] proposed the use of GAN to improve the robustness of small data model and prevent over-fitting. This algorithm uses FCN to classify images at pixel level for low contrast mammographic mass data, and CRF to implement structural learning to capture high-order potentials. For remote sensing images, Ma et al. [
26] presented a weakly supervised algorithm, which combines hierarchical condition generative adversarial nets and CRF, to perform the segmentation for high-resolution Synthetic Aperture Radar (SAR) images. In the condition generative adversarial network, a multi-classifier is added in the original GAN.
In recent years, with the increasing research on deep convolutional neural network in image segmentation [
14,
30], more and more studies have been carried out to improve the semantic segmentation methods, which are expected to be applied to the remote sensing images with high resolution [
31,
32]. Zhang et al. [
33] proposed JointNet, which can meet extraction requirements for both roads and buildings. This algorithm proposes a dense atrous convolution block to achieve a larger receptive field and maintain the feature propagation efficiency of dense connectivity. In addition, a focal loss function is introduced to balance the road centerline target and the background. An object-based deep-learning framework for semantic segmentation, which exploits object-based information integrated into a fully convolutional neural network, was proffered by Papadomanolaki et al. [
34]. This algorithm proposes an object-based loss to constrain the semantic labels, and then combines the semantic loss and the object-based loss to produce the final segmentation result. Teerapong et al. [
35] developed a semantic segmentation method on remotely sensed images by using an enhanced global convolutional network with channel attention and domain specific transfer learning. In this method, the global convolutional network is utilized to capture different resolution by extracting multi-scale features from different stages of the network, the channel attention is used to select the most discriminative features, and the domain specific transfer learning is introduced to alleviate the scarcity issue. Pan et al. [
36] proposed a fine segmentation network, which follows the encoder-decoder paradigm and uses multi-layer perceptron to accomplish the multi-sensor fusion in the feature-level. This network utilizes the encoder structure with a main encoder part and a lightweight branch part to achieve the feature extraction of multi-sensor data with a relatively few parameters. At the back end of the structure, the multi-layer perceptron can complete feature-level fusion of multi-sensor remote sensing images effectively.
1.2. Problems and Motivations
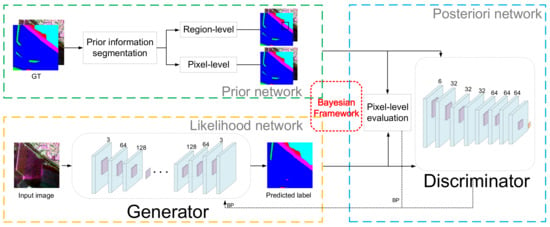
For CNN-based segmentation networks, the original images and their corresponding ground truths in the training set are used to train the segmentation network, and the training of the network is guided by directly comparing the differences between the ground truths and the segmented results. GAN is originally used for image generation, the generator uses noise to generate an image, and the discriminator determines whether the image is real or not. To make further use of the original image and the ground truth to improve accuracy, the adversarial network is considered to be introduced to calculate the similarity between the ground truth and the predicted label graph. When the discriminator cannot distinguish the ground truth and the predicted label graph, it can be considered that good segmentation result is obtained. The original image is corresponding to GT and the predicted label graph, thus, the original image can provide a prior condition for the discriminator. Based on the above considerations, GAN is introduced to implement a complete Bayesian segmentation framework in the proposed method.
FCN has a good performance in image semantic segmentation, however, it does not take the global information into consideration. Integrating local and global information is very important for semantic segmentation because local information can improve pixel-level accuracy, while global information can deal with local ambiguity. To introduce global information into CNNs, Deeplab uses the fully connected CRF as an independent post-processing step. To preserve details and make use of global information as much as possible in high-resolution remote sensing images, the generator adopts the integrated training model in which the skip-connected encoder-decoder network is combined with the CRF layer.
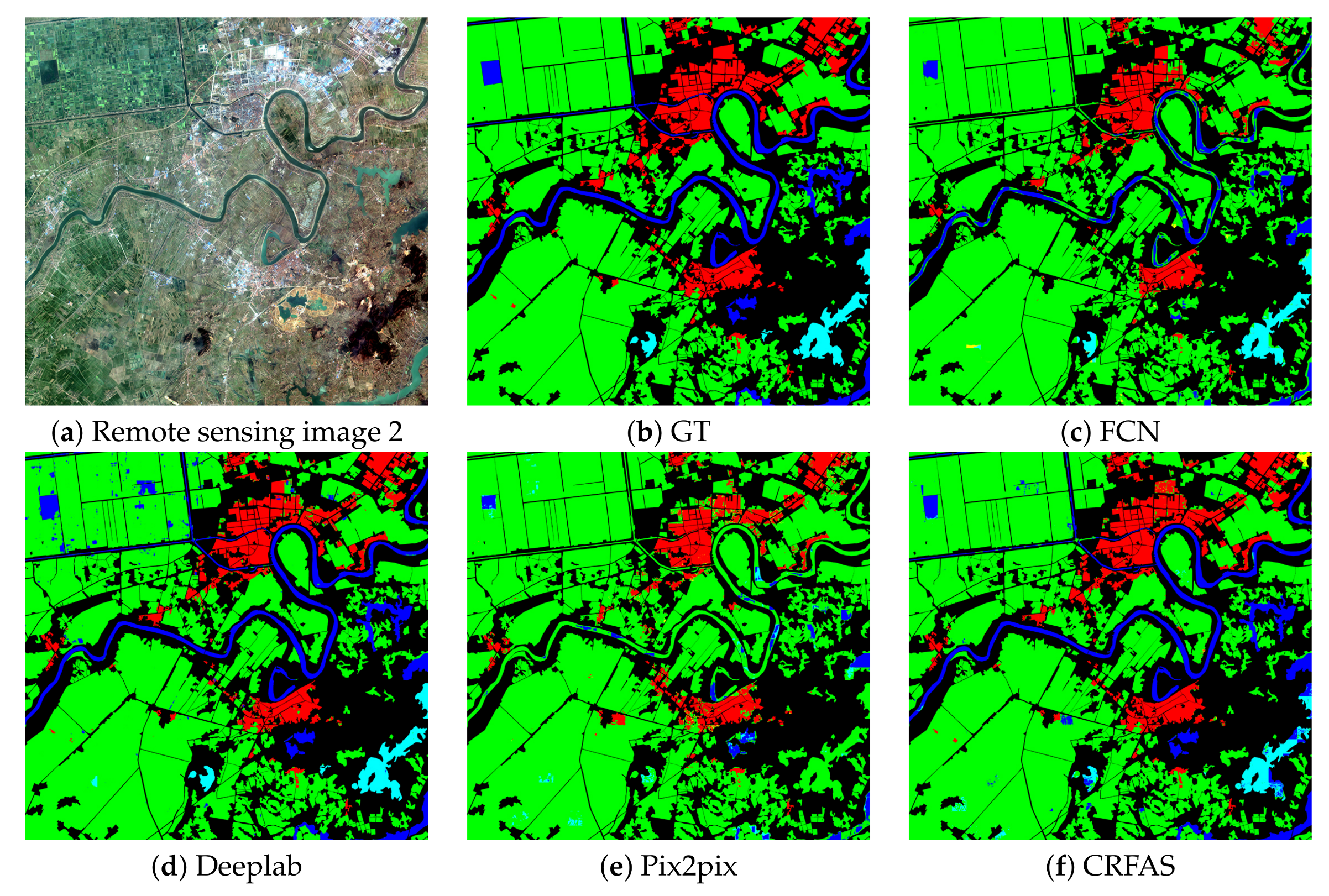
The loss function of classical segmentation network usually adopts the pixel-level calculation method, such as calculating the cross-entropy loss of all the pixels between predicted label graph and ground truth. This pixel-level evaluation method lacks the ability to discriminate spatial structure. When pixels of scene and background are mixed together or the object is small, the segmentation results will be not good. However, GAN evaluates the similarity between the ground truth and the predicted label graph by discriminator which only considers the differences in the view of the entire image or a large portion. To solve this problem, this paper considers to combine pixel-level and region-level estimation methods. In the proposed method, the similarity between the predicted label graph and the ground truth is evaluated by the adversarial network and the evaluation results are used as the adversarial loss. The loss function consisting of adversarial loss and cross-entropy loss guides the training of the segmentation network through back propagation.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}