Mask Sparse Representation Based on Semantic Features for Thermal Infrared Target Tracking

 ,
,
Abstract
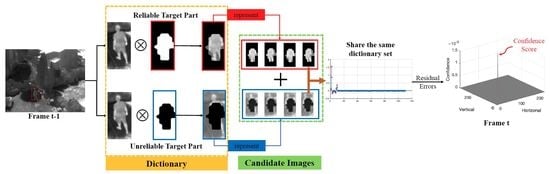
:
1. Introduction
- To improve the ability of distinguishing the target from the clutter background, we propose a mask sparse representation method for target appearance modeling. In this model, the distinguishable and reliable pixels of the target are identified and are utilized to refine the reconstruction output of the unreliable target part.
- With the pixel-wise labeling results of the target and its surrounding background in the last frame, we develop a supervised manner to learn a high-level pixel-wise discriminative map of the target area. The binarized discrimination map is introduced in the MaskSR model to indicate discrimination capabilities of different object parts.
- The proposed MaskSR model is introduced in an improved particle filter framework to achieve TIR target tracking. We achieved state-of-the-art performance on VOT-TIR2016 benchmark, in terms of both robustness and accuracy evaluations.
2. Related Work
2.1. Deep Learning-Based TIR Tracking Method
2.2. Sparse Representation-Based TIR Tracking Method
2.3. Particle Filter for Tracking
3. Proposed Approach
3.1. Target Mask Generation
3.2. Mask Sparse Representation Model
3.3. Optimization Approach
| Algorithm 1 Optimization approach for solving the proposed mask sparse representation model via ADMM |
| Input: dictionary and , candidate and , reliable weight w, regularized parameters , and , penalty parameters , and , relaxation parameters , iteration number 1.35 Initialize: while not converged do Step 1: update variable : Step 2: update variable : Step 3: update auxiliary variables , and : Step 4: update dual variables , , : end while Output: sparse coefficient vectors , |
3.4. Particle Filter Framework with Discriminative Particle Selection
3.5. Algorithm Overview and Update Strategy
| Algorithm 2 The proposed approach for TIR object tracking |
| Input: image sequence target position in the first frame target deep features in the first frame Initialize: construct object dictionary D obtain target mask correlation filter scale filter for to do 1. generate discriminative particles with correlation filter 2. construct the mask sparse representation model according to Eq (4) 3. compute the likelihood value of each particle (candidate) by Eq (14) 4. obtain the optimal target position 5. compute the optimal scale factor by scale filter 6. update object dictionary D 7. update target mask 8. update correlation filter 9. update scale filter end for Output: target states: |
4. Experiments
4.1. Experiment Setup
4.2. Evaluation Metrics
4.3. Parameter Analysis
- (1)
- Effect of , and
- (2)
- Effect of
4.4. Quantitative Comparison
4.5. Qualitative Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Li, C.; Sun, X.; Wang, X.; Zhang, L.; Tang, J. Grayscale-Thermal Object Tracking via Multitask Laplacian Sparse Representation. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 673–681. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared Small Target Detection via Non-Convex Rank Approximation Minimization Joint l2,1 Norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, Z. Infrared Small Target Detection Based on Partial Sum of the Tensor Nuclear Norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, H.; Liu, Y.; Peng, L.; Yang, C.; Peng, Z. Infrared Small Target Detection Based on Non-Convex Optimization with Lp-Norm Constraint. Remote Sens. 2019, 11, 559. [Google Scholar] [CrossRef]
- Yu, X.; Yu, Q.; Shang, Y.; Zhang, H. Dense structural learning for infrared object tracking at 200+ Frames per Second. Pattern Recognit. Lett. 2017, 100, 152–159. [Google Scholar] [CrossRef]
- Berg, A.; Ahlberg, J.; Felsberg, M. Channel coded distribution field tracking for thermal infrared imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 9–17. [Google Scholar]
- Liu, Q.; Lu, X.; He, Z.; Zhang, C.; Chen, W.S. Deep convolutional neural networks for thermal infrared object tracking. Knowl. Based Syst. 2017, 134, 189–198. [Google Scholar] [CrossRef]
- Li, X.; Liu, Q.; Fan, N.; He, Z.; Wang, H. Hierarchical spatial-aware Siamese network for thermal infrared object tracking. Knowl. Based Syst. 2019, 166, 71–81. [Google Scholar] [CrossRef]
- Qian, K.; Zhou, H.; Wang, B.; Song, S.; Zhao, D. Infrared dim moving target tracking via sparsity-based discriminative classifier and convolutional network. Infrared Phys. Technol. 2017, 86, 103–115. [Google Scholar] [CrossRef]
- Zulkifley, M.A.; Trigoni, N. Multiple-Model Fully Convolutional Neural Networks for Single Object Tracking on Thermal Infrared Video. IEEE Access 2018, 6, 42790–42799. [Google Scholar] [CrossRef]
- Zhang, L.; Gonzalez-Garcia, A.; Weijer, J.V.d.; Danelljan, M.; Khan, F.S. Synthetic Data Generation for End-to-End Thermal Infrared Tracking. IEEE Trans. Image Process. 2019, 28, 1837–1850. [Google Scholar] [CrossRef] [PubMed]
- Shi, Z.; Wei, C.; Fu, P.; Jiang, S. A Parallel Search Strategy Based on Sparse Representation for Infrared Target Tracking. Algorithms 2015, 8, 529–540. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Li, M.; Zhang, J.; Yao, J. Infrared Target Tracking Based on Robust Low-Rank Sparse Learning. IEEE Geosci. Remote Sens. Lett. 2016, 13, 232–236. [Google Scholar] [CrossRef]
- Gao, S.J.; Jhang, S.T. Infrared Target Tracking Using Multi-Feature Joint Sparse Representation. In Proceedings of the International Conference on Research in Adaptive and Convergent Systems, Odense, Denmark, 11–14 October 2016; pp. 40–45. [Google Scholar] [CrossRef]
- Zhang, X.; Ren, K.; Wan, M.; Gu, G.; Chen, Q. Infrared small target tracking based on sample constrained particle filtering and sparse representation. Infrared Phys. Technol. 2017, 87, 72–82. [Google Scholar] [CrossRef]
- Lan, X.; Ye, M.; Zhang, S.; Zhou, H.; Yuen, P.C. Modality-correlation-aware sparse representation for RGB-infrared object tracking. Pattern Recognit. Lett. 2018, in press. [Google Scholar] [CrossRef]
- Li, Y.; Li, P.; Shen, Q. Real-time infrared target tracking based on l1 minimization and compressive features. Appl. Opt. 2014, 53, 6518–6526. [Google Scholar] [CrossRef]
- Wan, M.; Gu, G.; Qian, W.; Ren, K.; Chen, Q.; Zhang, H.; Maldague, X. Total Variation Regularization Term-Based Low-Rank and Sparse Matrix Representation Model for Infrared Moving Target Tracking. Remote Sens. 2018, 10, 510. [Google Scholar] [CrossRef]
- Bao, C.; Wu, Y.; Ling, H.; Ji, H. Real time robust l1 tracker using accelerated proximal gradient approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1830–1837. [Google Scholar]
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Robust visual tracking via multi-task sparse learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2042–2049. [Google Scholar] [CrossRef]
- Jia, X.; Lu, H.; Yang, M. Visual tracking via adaptive structural local sparse appearance model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1822–1829. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, J.; Zhang, K.; Li, Z. Visual Tracking With Weighted Adaptive Local Sparse Appearance Model via Spatio-Temporal Context Learning. IEEE Trans. Image Process. 2018, 27, 4478–4489. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, C.; Yang, M. Robust Structural Sparse Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 473–486. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE international conference on computer vision (ICCV), Santiago, Chile, 7–13 December 2015; pp; pp. 3074–3082. [Google Scholar]
- Zhang, X.; Ma, D.; Ouyang, X.; Jiang, S.; Gan, L.; Agam, G. Layered optical flow estimation using a deep neural network with a soft mask. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI), Morgan Kaufmann, Stockholm, Sweden, 13–19 July 2018; pp. 1170–1176. [Google Scholar]
- Liu, Q.; Yuan, D.; He, Z. Thermal infrared object tracking via Siamese convolutional neural networks. In Proceedings of the International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Shenzhen, China, 15–17 December 2017; pp. 1–6. [Google Scholar]
- Gundogdu, E.; Koc, A.; Solmaz, B.; Hammoud, R.I.; Aydin Alatan, A. Evaluation of feature channels for correlation-filter-based visual object tracking in infrared spectrum. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 24–32. [Google Scholar]
- Li, Z.; Li, J.; Ge, F.; Shao, W.; Liu, B.; Jin, G. Dim moving target tracking algorithm based on particle discriminative sparse representation. Infrared Phys. Technol. 2016, 75, 100–106. [Google Scholar] [CrossRef]
- Li, M.; Lin, Z.; Long, Y.; An, W.; Zhou, Y. Joint detection and tracking of size-varying infrared targets based on block-wise sparse decomposition. Infrared Phys. Technol. 2016, 76, 131–138. [Google Scholar] [CrossRef]
- Li, C.; Zhao, N.; Lu, Y.; Zhu, C.; Tang, J. Weighted Sparse Representation Regularized Graph Learning for RGB-T Object Tracking. In Proceedings of the 25th ACM International Conference on Multimedia, New York, NY, USA, 23–27 October 2017; pp. 1856–1864. [Google Scholar] [CrossRef]
- Lan, X.; Ye, M.; Shao, R.; Zhong, B.; Jain, D.K.; Zhou, H. Online Non-negative Multi-modality Feature Template Learning for RGB-assisted Infrared Tracking. IEEE Access 2019, 7, 67761–67771. [Google Scholar] [CrossRef]
- Lan, X.; Ye, M.; Shao, R.; Zhong, B.; Yuen, P.C.; Zhou, H. Learning Modality-Consistency Feature Templates: A Robust RGB-Infrared Tracking System. IEEE Trans. Ind. Electron. 2019, 66, 9887–9897. [Google Scholar] [CrossRef]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning Collaborative Sparse Representation for Grayscale-Thermal Tracking. IEEE Trans. Image Process. 2016, 25, 5743–5756. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhu, J.; Hoi, S.C. Real-Time Part-Based Visual Tracking via Adaptive Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4902–4912. [Google Scholar]
- Wang, F.; Zhen, Y.; Zhong, B.; Ji, R. Robust infrared target tracking based on particle filter with embedded saliency detection. Inf. Sci. 2015, 301, 215–226. [Google Scholar] [CrossRef]
- Shi, Z.; Wei, C.; Li, J.; Fu, P.; Jiang, S. Hierarchical search strategy in particle filter framework to track infrared target. Neural Comput. Appl. 2018, 29, 469–481. [Google Scholar] [CrossRef]
- Chiranjeevi, P.; Sengupta, S. Rough-Set-Theoretic Fuzzy Cues-Based Object Tracking Under Improved Particle Filter Framework. IEEE Trans. Fuzzy Syst. 2016, 24, 695–707. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, C.; Yang, M. Learning Multi-Task Correlation Particle Filters for Visual Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 365–378. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, J.; Hoi, S.C. Reliable patch trackers: Robust visual tracking by exploiting reliable patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 353–361. [Google Scholar]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.H. Hedged deep tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June 2016; pp. 4303–4311. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef]
- Felsberg, M.; Kristan, M.; Matas, J.; Leonardis, A.; Pflugfelder, R.; Häger, G.; Berg, A.; Eldesokey, A.; Ahlberg, J.; Čehovin, L. The Thermal Infrared Visual Object Tracking VOT-TIR2016 Challenge Results. In Proceedings of the International Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 824–849. [Google Scholar]
- Tang, M.; Feng, J. Multi-kernel correlation filter for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3038–3046. [Google Scholar]
- Li, X.; Liu, Q.; He, Z.; Wang, H.; Zhang, C.; Chen, W.S. A multi-view model for visual tracking via correlation filters. Knowl. Based Syst. 2016, 113, 88–99. [Google Scholar] [CrossRef]
- Possegger, H.; Mauthner, T.; Bischof, H. In defense of color-based model-free tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2113–2120. [Google Scholar]
- Montero, A.S.; Lang, J.; Laganiere, R. Scalable kernel correlation filter with sparse feature integration. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 587–594. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning Spatially Regularized Correlation Filters for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Felsberg, M.; Berg, A.; Hager, G.; Ahlberg, J.; Kristan, M.; Matas, J.; Leonardis, A.; Cehovin, L.; Fernandez, G.; Vojír, T.; et al. The thermal infrared visual object tracking VOT-TIR2015 challenge results. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 76–88. [Google Scholar]
- Akin, O.; Erdem, E.; Erdem, A.; Mikolajczyk, K. Deformable part-based tracking by coupled global and local correlation filters. J. Vis. Commun. Image Represent. 2016, 38, 763–774. [Google Scholar] [CrossRef]
- Lukežič, A.; Zajc, L.Č.; Kristan, M. Deformable parts correlation filters for robust visual tracking. IEEE Trans. Cybern. 2017, 48, 1849–1861. [Google Scholar] [CrossRef] [PubMed]
- Du, D.; Qi, H.; Wen, L.; Tian, Q.; Huang, Q.; Lyu, S. Geometric Hypergraph Learning for Visual Tracking. IEEE Trans. Cybern. 2017, 47, 4182–4195. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurements | Staple+ | MDNet_N | DSST | MVCFT | DPT | deepMKCF | MAD | Ours | |
|---|---|---|---|---|---|---|---|---|---|
| ALL | EAO | 0.241 ** | 0.240 *** | 0.237 | 0.231 | 0.216 | 0.213 | 0.200 | 0.260 * |
| Camera Motion | A | 0.584 *** | 0.611 ** | 0.559 | 0.520 | 0.561 | 0.623 * | 0.494 | 0.517 |
| R | 0.517** | 0.496*** | 0.410 | 0.465 | 0.418 | 0.490 | 0.382 | 0.586* | |
| Dynamics Change | A | 0.568 *** | 0.518 | 0.574 ** | 0.467 | 0.523 | 0.612 * | 0.483 | 0.522 |
| R | 0.389 *** | 0.532** | 0.322 | 0.322 | 0.389 *** | 0.182 | 0.266 | 0.576 * | |
| Empty | A | 0.544 | 0.624 * | 0.579 | 0.522 | 0.585 | 0.589 *** | 0.542 | 0.613 ** |
| R | 0.460 | 0.473 | 0.404 | 0.480 * | 0.480 * | 0.422 | 0.480 * | 0.480 * | |
| Motion Change | A | 0.514 | 0.613 * | 0.551 *** | 0.509 | 0.474 | 0.592 ** | 0.490 | 0.521 |
| R | 0.867 * | 0.848 ** | 0.684 | 0.789 *** | 0.684 | 0.717 | 0.752 | 0.752 | |
| Occlusion | A | 0.658 * | 0.627 ** | 0.625 *** | 0.562 | 0.573 | 0.607 | 0.570 | 0.520 |
| R | 0.591 ** | 0.664 * | 0.349 | 0.468 | 0.496 | 0.468 | 0.392 | 0.557 *** | |
| Size Change | A | 0.595 | 0.654 * | 0.612 *** | 0.544 | 0.474 | 0.643 ** | 0.520 | 0.596 |
| R | 0.627 | 0.682 ** | 0.607 | 0.627 | 0.607 | 0.637 *** | 0.560 | 0.713 * | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Peng, L.; Chen, Y.; Huang, S.; Qin, F.; Peng, Z. Mask Sparse Representation Based on Semantic Features for Thermal Infrared Target Tracking. Remote Sens. 2019, 11, 1967. https://doi.org/10.3390/rs11171967
Li M, Peng L, Chen Y, Huang S, Qin F, Peng Z. Mask Sparse Representation Based on Semantic Features for Thermal Infrared Target Tracking. Remote Sensing. 2019; 11(17):1967. https://doi.org/10.3390/rs11171967
Chicago/Turabian StyleLi, Meihui, Lingbing Peng, Yingpin Chen, Suqi Huang, Feiyi Qin, and Zhenming Peng. 2019. "Mask Sparse Representation Based on Semantic Features for Thermal Infrared Target Tracking" Remote Sensing 11, no. 17: 1967. https://doi.org/10.3390/rs11171967